1. Introduction
Health disparities research often focuses on race, which is non-modifiable, as a driver of differential outcomes. In this paper, we attempt to shift the conversation to the experience of racial minorities, which is modifiable, as a key driver of health outcomes, and provide tools to other public health researchers and policymakers. Our particular focus within the experience of racial minorities is on their relative racial and educational isolation.
Racial residential segregation (RRS) of blacks refers to the geographic separation of blacks from other racial/ethnic groups [
1]. Through the concentration of poverty and poor physical and social environments, RRS results in distinctive environments that may underlie racial disparities in health outcomes [
1]. Research has linked RRS with infant and adult mortality [
2,
3], poor pregnancy outcomes [
4,
5], type 2 diabetes [
6], hypertension [
7,
8], and poor cardiovascular health [
9]. Despite legal measures to address segregation, segregation and its consequences persist in the United States [
10].
RRS is a multidimensional phenomenon, which has been characterized by five distinct dimensions: evenness, isolation, concentration, centralization, and clustering [
11]. Racial isolation (RI) is defined as the extent to which minorities are exposed to majority group members by sharing a residential neighborhood. Importantly, it is not the exposure to other racial groups that is posited to improve outcomes, but rather the accumulation of social and environmental stressors in isolated neighborhoods that is posited to lead to poorer outcomes.
RRS measures have commonly been conceived at the Metropolitan Statistical Area (MSA) [
12,
13,
14], although recently, researchers have started considering smaller analytical units, including next-door neighbors [
15]. A review article of segregation and health identified two ways in which studies of RRS and health have conceptualized segregation [
16]: (1) a formal measure of geographical segregation of racial groups with indices reflecting either exposure/isolation, evenness, concentration, centralization, or clustering [
11]; and (2) a proxy measure, e.g., Black racial composition, % non-Hispanic Black (NHB). Prior assessments of segregation and health have found it conceptually problematic to conflate formal vs. proxy measures [
17]. Of studies using a formal measure of segregation (as we do here), 33 studies measured segregation at the MSA or city level; 3 studies measured segregation at the county level; 1 study was at the state level; and no studies were conducted at the census tract level, although one study examined the proxy measure, racial composition, at the tract level. For example, MSA and city-level measures can assess whether Detroit is more segregated than Atlanta but not whether a particular neighborhood or other small area is more segregated than another within the same larger geographic region nor do they allow an assessment of whether a neighborhood or other small area has become more or less segregated over time.
Furthermore, of the studies examined in the review article described above, 18 used a measure of evenness to assess RRS, compared to 12 studies using exposure/isolation, 2 studies using concentration and clustering, and 1 study using centralization [
16]. There is an extensive literature on residential segregation and its causes [
11,
18,
19,
20,
21,
22] as well as methodological issues (e.g., formal vs. proxy measures of segregation, uses, and advantages of different types of indices such as exposure/isolation vs. dissimilarity) [
16,
17,
23,
24,
25]. In this literature, some researchers argued that compared to the commonly employed dimension of evenness (dissimilarity), exposure/isolation may be more closely linked to health by serving as a proxy for the concentration of multiple disadvantages into a single ecological space [
17,
26]. With this literature as context, we developed a local, spatial measure of RI in previous work [
4]. The local RI index, which we implement here at the census tract level, may be more directly linked to individual health than measures of segregation at the city or metropolitan area levels [
4]. Unlike aspatial measures of segregation, our spatial index accounts for relationships among nearby census tracts.
In this paper, we apply the isolation concept to educational attainment. Using the same methodological approach as that used for RI, we develop a measure of educational isolation (EI) that evaluates to what extent individuals without a college degree are exposed only to other individuals without a college degree. Educational attainment has been consistently linked to health outcomes [
27,
28,
29,
30,
31,
32].The current literature around education and segregation is more focused on racial/ethnic and/or socioeconomic segregation in public schools [
33,
34,
35], which is driven, at least in part, by racial/ethnic and socioeconomic residential segregation [
36]. School segregation and poverty, as well as its drivers and consequences, is an important topic [
37] because it is strongly associated with the magnitude of achievement gaps in early childhood and with the rate at which gaps grow over time [
38]. Yet there is little information on residential segregation by educational attainment, which we examine here. Our EI index allows researchers to assess the importance of access to those with higher educational attainment along with the more traditional individual-level educational attainment measures. This approach extends the arguments laid out by Charles Putnam in Chapter 4 of
Our Kids [
39].
Furthermore, an ongoing debate in the US (and elsewhere) revolves around whether race serves as a proxy for socioeconomic status or whether race and socioeconomic status individually and jointly drive disparate outcomes [
40,
41]. Thus, this paper also explores the relationship between EI and RI, given that educational attainment is one important component of socioeconomic status. This dual approach is especially important given the enduring legacy of racism in the US. To evaluate the relationship between RI and EI, we propose a novel measure of local correlation. This novel measure assesses if and how the correlation between EI and RI varies across space. Widely used measures of global correlation (e.g., Pearson correlation coefficient) provide an area-wide measure of correlation which, while useful, does not indicate whether and to what degree the relationship between the variables of interest is uniform versus heterogeneous over the study area. Using the local measure of correlation, we evaluate the presence and nature of spatial variability in the relationship between RI and EI. Critically, this measure of local correlation can be applied to any combination of variables and will be useful to researchers or policymakers examining relationships between variables reported at an areal unit (e.g., poverty, crime, environmental exposures such as air pollution, health outcomes, reported at block, block group, census tract, zip code, county, neighborhood).
In this work, we (1) develop a local, spatial measure of EI; (2) calculate local, spatial measures of RI and EI, at the census tract level, across the continental US; (3) characterize the relationship between EI and RI using a standard measure of global correlation and a novel measure of local correlation, and by urbanicity and region within the US; and (4) assess the relationship between RI, EI, and pregnancy outcomes using detailed birth records from the State of Michigan. This work provides new tools for health disparity and policy researchers as well as actionable information for policymakers.
2. Materials and Methods
2.1. Study Area
We focus on the 48 states of the continental US, assessing RI and EI in the 72,706 census tracts designated in the 2010 U.S. Census. Of these tracts, 496 had no population and were excluded from the analysis, resulting in an analysis dataset of 72,210 census tracts with a mean (standard deviation) and median population size of 4257 (1955) and 4012, respectively. The population of census tracts ranged from a minimum of 1 to a maximum of 37,452 individuals.
Of 327 million people in the US, approximately 77% are non-Hispanic white (NHW), 13% are NHB, and 31% have a college degree. These statistics mask substantial heterogeneity in racial/ethnic composition and educational attainment across the country. For example, approximately 38% of the population in Mississippi is NHB, compared to just under 1% in Idaho. In West Virginia; meanwhile, fewer than 20% of adults have a college degree, compared to 42% in Massachusetts [
42].
2.2. Data
We obtain count data on race/ethnicity and educational attainment at the tract level from the 2010 Census and American Community Survey (ACS) [
42].
Urbanicity is determined using primary and secondary rural–urban commuting area (RUCA) codes, which are assigned by the US Department of Agriculture based on population density, urbanization, and the size and direction of daily commuting flows [
43]. We use RUCA codes to classify tracts into urban, suburban, and rural categories. RUCA codes are based on the 2010 decennial census data and the 2006–2010 ACS data (see
Table S1).
2.3. Isolation Measures
2.3.1. Racial Isolation
We calculate our previously developed local, spatial measure of RI of self-identifying NHB individuals (compared with all other racial/ethnic groups, including Hispanics) in each tract for the continental US [
4]:
In Equation (1), denotes the set of index unit () and its neighbors (i.e., tracts that are adjacent to the index tract). Given mutually exclusive racial subgroups, indexes the subgroups of (e.g., NHB). denotes the total population in region , and denotes the population of subgroup in region . denotes a first-order adjacency matrix, where n is the number of census tracts in the study area. First-order adjacency means that the entries in the matrix, , are set to 1 if a boundary is shared by region and region , and 0 otherwise. Entries of the main diagonal (since when ) of are set to 1.5, such that the weight of the index unit, , is larger than the weights assigned to adjacent tracts. Since we are more interested in the spatial patterns rather than the aspatial patterns, should not be set to too high. For neighbors of any index unit with 0 population, the corresponding and are 0, so that the value of , the RI index of unit for subgroup , would not be affected. We note that in calculating spatial indices, edge tracts (e.g., tracts along a coastline or bordering Canada or Mexico) may have few neighboring tracts; index values in these tracts may be unstable.
The resulting RI index ranges from 0 to 1. A neighborhood environment that is nearly all non-NHB will have an RI value that is close to 0. In contrast, a neighborhood environment that is nearly all NHB will have an RI value that is close to 1 [
44].
2.3.2. Educational Isolation
We develop an analogous local, spatial measure of EI, assessing likelihood of living in the same neighborhood of individuals without a college degree to those with a college degree. We calculate tract-level EI scores by accounting for the population composition in the index tract along with adjacent tracts.
In Equation (2), the value of
, the educational isolation index of unit
for subgroup
, is calculated in the same way as
, except
indexes mutually exclusive subgroups of educational attainment categories (e.g., individuals with a four-year college degree, individuals without a four-year college degree). Note that the right-hand sides of Equations (1) and (2) are identical. These equations only differ in terms of how subgroup
m is defined. The EI index ranges from 0 to 1. A neighborhood environment that is nearly all college educated will have an educational isolation value that is close to 0. In contrast, a neighborhood environment that is nearly all non-college educated will have an educational isolation value that is close to 1 [
45].
The resulting RI or EI value represents a weighted average proportion of the population that is NHB, in the case of RI, or that is not college educated, in the case of EI. As presented here, RI and EI assign greater weight to the index census tract (i.e., the census tract for which the value is being calculated) and somewhat less weight to census tracts that are adjacent to the index tract.
2.4. Relationships between RI and EI
2.4.1. Measures of Correlation
We calculate global and local measures of correlation between RI and EI. The Pearson correlation coefficient is used to measure correlations at the national level (Equation (3)).
In Equation (3), and denote the value of variables (e.g., RI) and (e.g., EI) for areal unit (census tract) , respectively. and denote the average of the s and s across the study area. We present this widely known representation of the Pearson correlation coefficient to provide ease of interpretability of the local spatial measure of correlation presented below.
The Pearson correlation coefficient is aspatial and fails to capture how the relationship between RI and EI may vary across space. Thus, we propose a local measure of correlation (Equation (4)).
Similar to Equation (1), in Equation (4), denotes the set of index unit ) and its neighbors. Here, we choose to include first-order neighbors (i.e., tracts adjacent to the index tract) and second-order neighbors (i.e., tracts adjacent to first-order neighbors of the index tract) in . If we only include first-order neighbors in , for each unit , with only a few of the , the local correlations are computed using few values (neighbors), producing a potentially unstable result. and denote the weighted average of the s and s over unit i and its neighbors.
Given ( matrix) denoting the matrix that we use to calculate , entries are set to a positive value if, for a given unit , unit , i.e., is a first or second-order neighbor of unit , or if i = j. Note that the term allows us to specify different weights for different neighbors. Intuitively, the index unit (census tract) has the greatest influence on itself, so is set to a larger value (); first-order neighbors of unit have less influence on unit than unit itself, so the corresponding are set smaller than (). Second-order neighbors of unit have less influence on tract than the first-order neighbors; so the corresponding are set smaller than the of the first-order neighbors (). and can be adjusted according to spatial scale, research question of interest, or the interactions between and within areal units.
This local measure of correlation describes the relationship between the neighborhood environment of an index tract with respect to two different variables. In this case, the neighborhood environment is defined as tracts that are adjacent to the index tract (first-order neighbors) as well as tracts adjacent to the first-order neighbors of the index tract (second-order neighbors). In calculating the local measure of correlation, greater weight is assigned to first-order neighbor tracts, and less weight is assigned to second-order neighbor tracts. The resulting local correlation measure ranges from −1 to 1. A local correlation value of 0 indicates no relationship between variable values—in this case, RI and EI—in the neighborhood environment (defined as first and second-order neighbors). A local correlation value near 1 indicates that RI and EI in the defined neighborhood environment are strongly positively correlated with one another. For example, this would occur when the RI values of a given neighborhood are similar to the EI values of the neighborhood. A local correlation value approaching −1 indicates that RI and EI values in the neighborhood are strongly negatively correlated with one another. This indicates that RI and EI values in the neighborhood environment are very different from one another. Thus, the measure of local correlation provides information regarding whether RI and EI values in a neighborhood are similar to (, unrelated to (, or different from ( one another. In this work, we calculate local correlation between RI and EI, but this measure can be applied to other variables as well.
2.4.2. Urbanicity
Using RUCA codes to assign urbanicity [
43], we examine the relationship between RI and EI separately for urban, suburban, and rural tracts. The RUCA code classification scheme is provided in the
Supplemental Material (SM), Table S1.
2.5. Public Health Relevance: RI, EI, and Pregnancy Outcomes
We examined associations between RI, EI, and gestational age and preterm birth (PTB) in the State of Michigan. We obtained detailed birth records from the Michigan Department of Community Health Vital Records, which included 1,608,537 births between 2000 and 2012. We restricted the dataset to births between 1 January 2005 and 31 December 2012 (n = 954,455) that were geocoded to a 2010 census tract (n = 942,422). Then, we restricted the dataset to singleton births (i.e., no plural births), without known congenital anomalies, birthweight >400 g, clinical estimate of gestational age 24–42 weeks, birth-order <4, maternal age range 15–44 years (y), and maternal race of NHB or NHW (n = 822,290). We also removed 14,299 records with missing values, such as maternal educational attainment, age, tobacco use during pregnancy, marital status, and census tract RI or EI. The final analysis dataset included 807,991 infants.
Infants were assigned RI and EI values based on the maternal census tract of residence at time of birth (using RI and EI calculated from 2010 Census data). The birth outcomes of interest were gestational age in weeks and PTB (0/1), defined as a birth occurring prior to 37 weeks gestation, based on the clinical estimate of gestational age. Race-stratified, multi-level models of birth outcomes were adjusted for individual-level characteristics, including maternal age, educational attainment, marital status, tobacco use during pregnancy, and infant sex, as well as census tract level RI and EI. Census tract of maternal residence at time of birth was included as random effects to account for potential unobserved heterogeneity. As a sensitivity analysis, we also fit models that included percentage NHB instead of RI and percentage non-college educated instead of EI to assess if and how these associations differed from one another.
This research was approved by the Institutional Review Boards at University of Notre Dame and the Michigan Department of Health and Human Services.
4. Discussion
In the US, people are increasingly being spatially sorted by where they live and with whom they interact. A by-product of increasing inequality and the shrinking of the middle class, this phenomenon has profound consequences for opportunities and choices, especially so for our most vulnerable populations. Richard Rothstein has written eloquently about how policies have relentlessly promoted this spatial sorting in
The Color of Law [
48].
A burgeoning literature has highlighted the staggering growth and deleterious consequences of individuals and subpopulations becoming geographically and socially marginalized.
Evicted,
Our Kids, and
$2.00 a Day, as well as a growing body of scholarship by Raj Chetty et al., all underscore the fact that the American Dream of upward mobility is becoming out of reach for many in our country [
39,
49,
50,
51]. Systematic measures of residential segregation over space and time, for both urban and non-urban areas, provide a critical tool for assessing the impact of past policy interventions and for identifying new policy approaches.
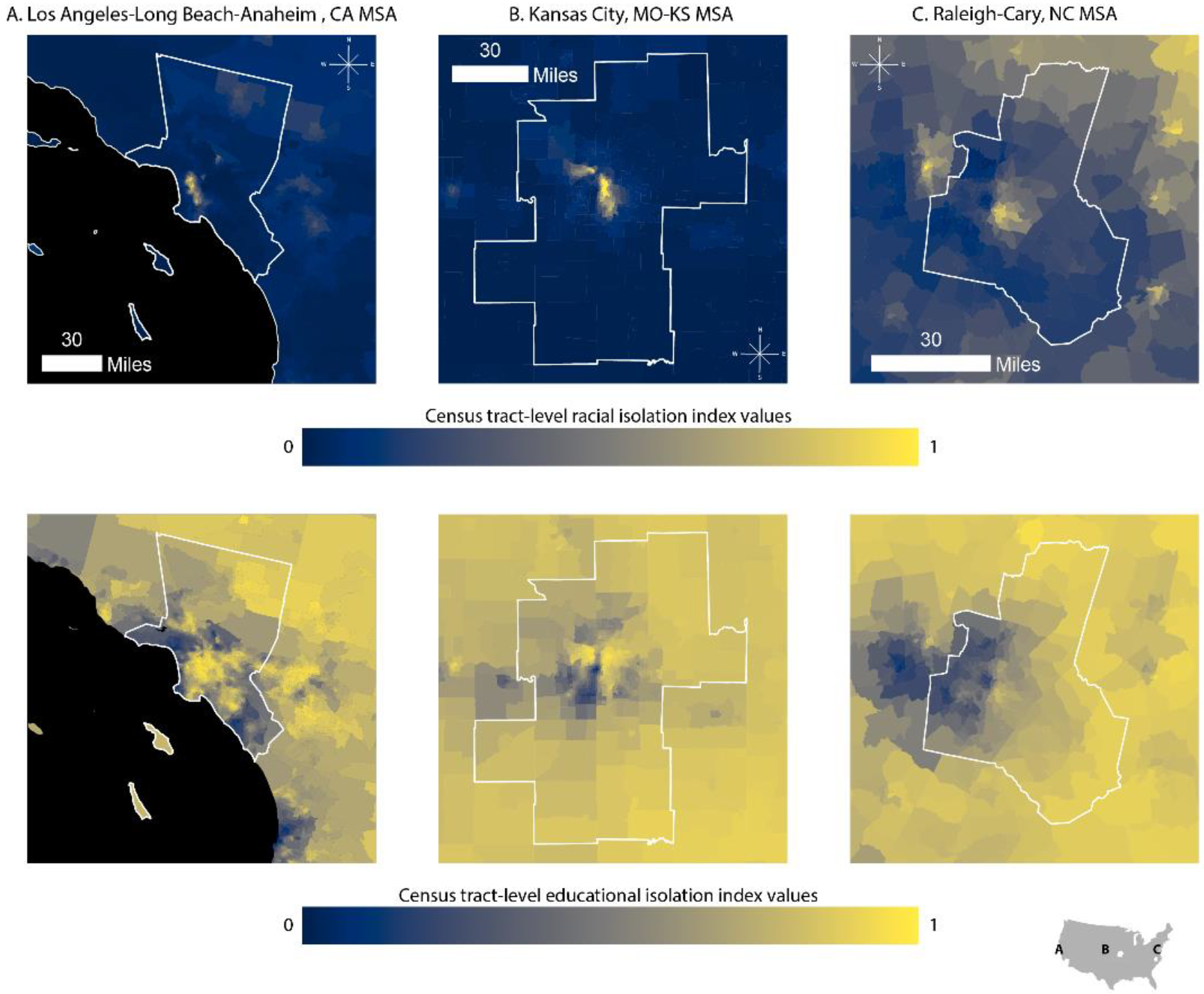
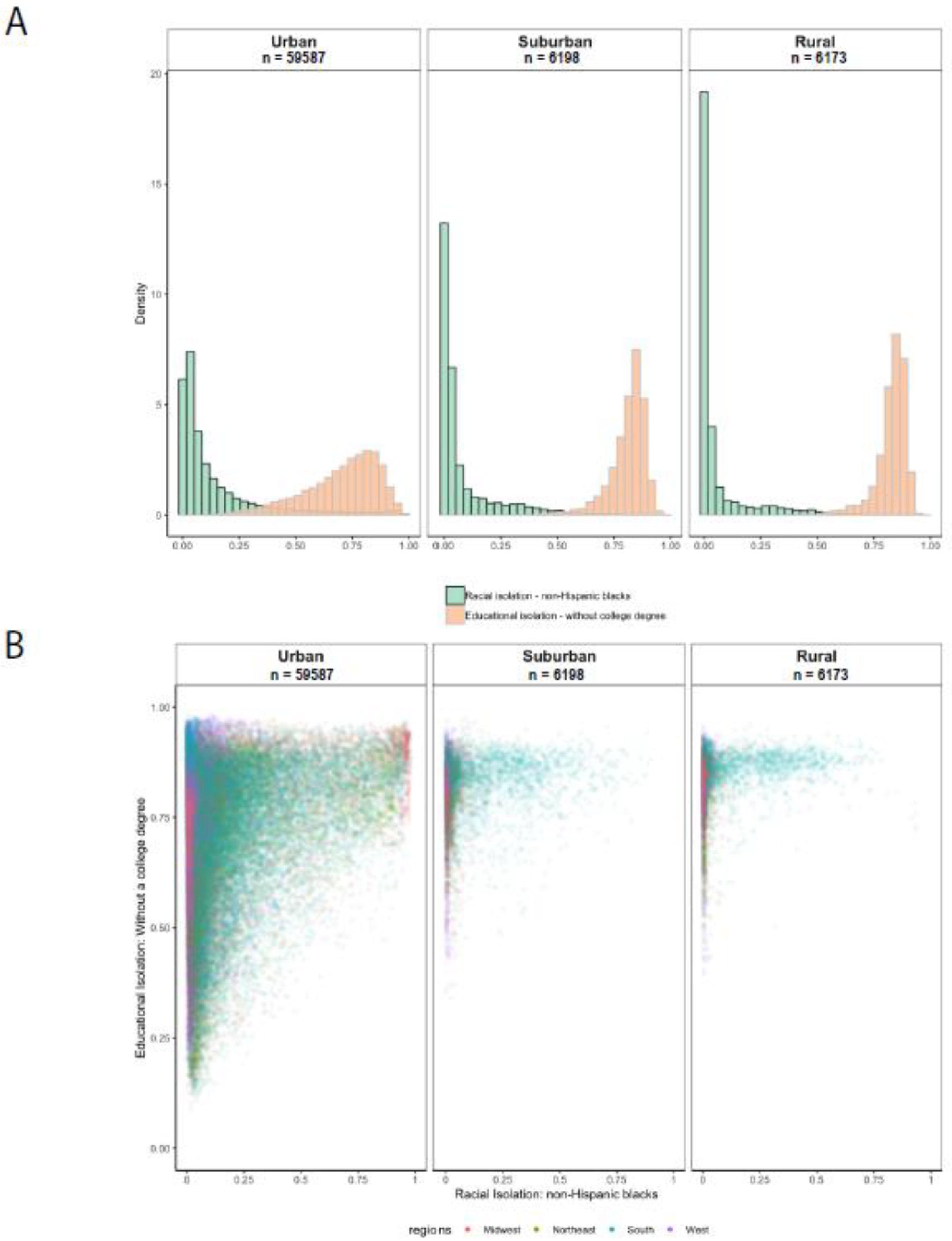
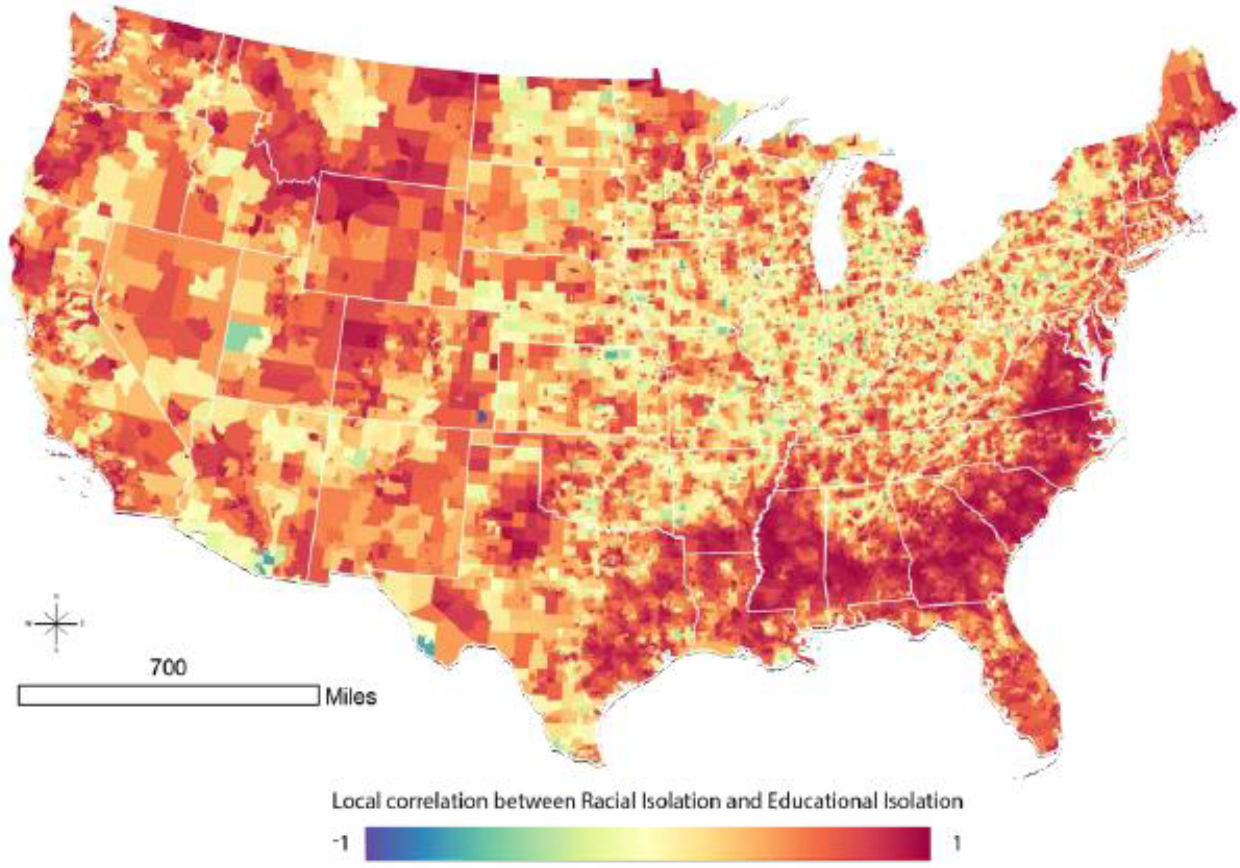
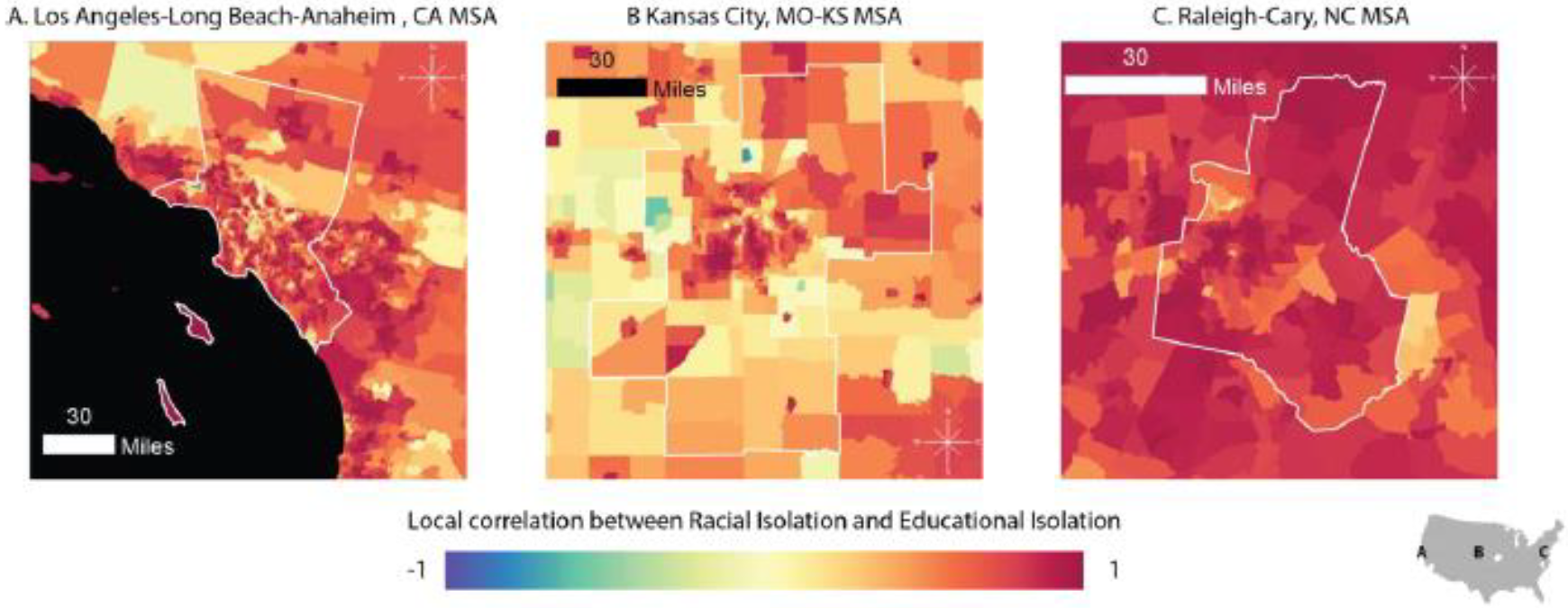
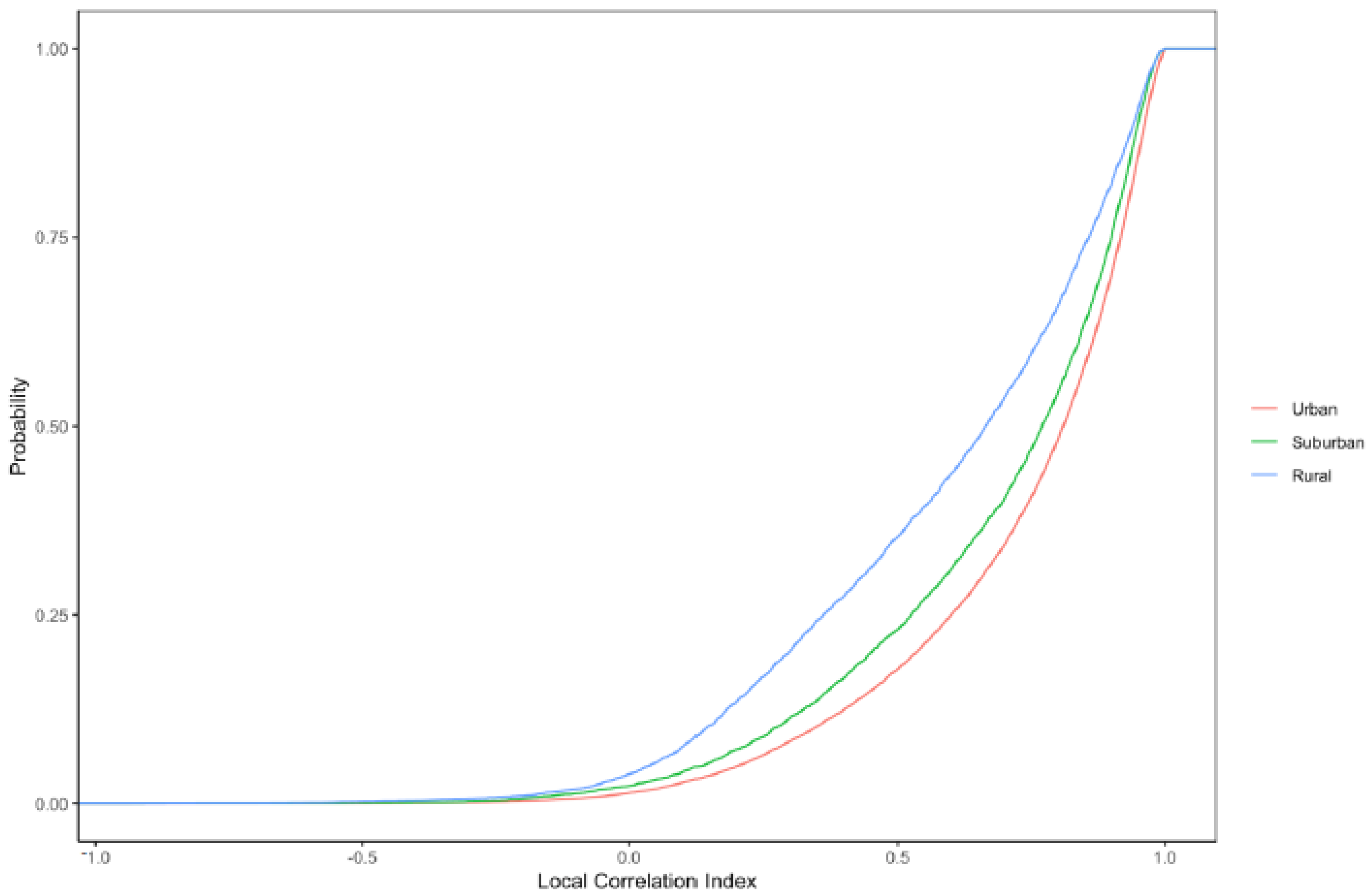
Our objective was to develop parallel racial and educational isolation indices to serve as tools for health disparities researchers and for those developing intervention programs. Traditional wisdom assumes that race and socioeconomic status are highly correlated. In fact, the global correlation between racial and educational isolation was 0.21. However, we show that this global measure masks local heterogeneity in EI and RI correlation. The pattern of racial and educational isolation differs dramatically across the geography of the US, with notable differences among urban, suburban, and rural areas. At low levels of RI, we observed a relatively wide range of corresponding EI values, but at high levels of RI, the range of EI values narrows to predominantly high EI values. Thus, residents who reside in racially isolated communities are very likely to also experience educational isolation. Additionally, although we have only demonstrated this descriptively in maps, the south is unique in having high RI values in rural settings; elsewhere in the country, high RI values primarily or exclusively occur in urban and suburban areas. Thus, residents of suburban and rural tracts in the South are more likely to experience a “double” exposure to high RI and high EI, compared to other regions of the US, in which suburban and rural tracts may have high EI values but typically have low RI values.
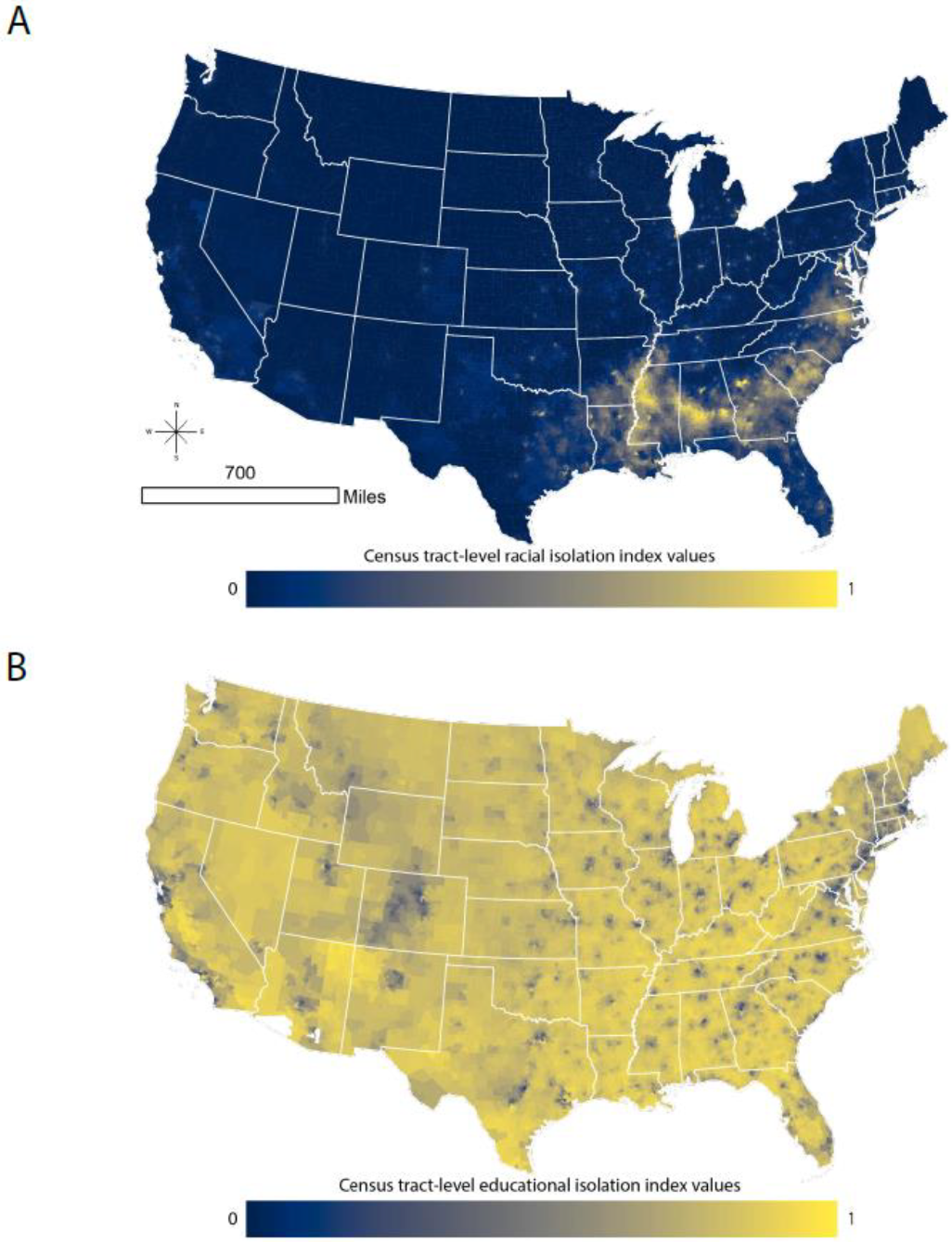
The distributions and spatial patterns of RI and EI differ from one another. We purposefully calculated RI and EI such that high values of each index indicated greater adversity: high levels of RI indicate greater segregation of NHB relative to the rest of the population, and high levels of EI indicate greater segregation of non-college educated individuals from college educated individuals. However, RI distributions across all levels of urbanicity were right skewed, with more places having low values of RI, while EI was left skewed, with more places tending to have high values of EI. Based on the local correlation coefficient between RI and EI, we find that the coefficients are positive in most census tracts in the continental US. Importantly, values of EI and RI can be highly correlated if EI and RI are both high in an area (e.g., in the southeastern crescent apparent in
Figure 1A,B, as well as
Figure 4) or because EI and RI are both low in an area (e.g., in parts of the intermountain west).
A local, spatial measure of residential segregation has several advantages over global, aspatial measures. First, residential segregation is an inherently spatial phenomenon, and, therefore, aspatial measures of residential segregation pose methodological concerns, with notable issues related to neighboring communities (i.e., “checkboard problem”) [
23]. Since surrounding communities can influence an individual’s neighborhood, a spatial approach enhances the capability of estimating the actual environment where a person lives. This is especially important when considering individuals who reside near bordering geographies.
Second, a local scale is important to understanding residential segregation because many resources are distributed and accessed at a community level [
52]. Indeed, many mechanisms of residential segregation, such as school districts, grocery store access, social networks, and air pollution, are geographically constrained. A local measure of residential segregation allows researchers to tap into more proximal environmental influences, whereas the spatial component simultaneously considers the influence of the surrounding environment. Taken together, a local, spatial measure of residential segregation captures the spatial structure of residential segregation at a more relevant and more resolved scale compared to global, aspatial residential segregation measures.
Third, implementing a local, spatial measure at the census tract level, a highly resolved spatial scale, enabled us to distinguish between urban and non-urban census tracts and assess residential segregation in both urban and non-urban areas. There is often an urban bias in segregation and health research, resulting from the predominant focus on MSAs [
10]. Although urban areas are important to residential segregation research, segregation also occurs within non-urban areas [
10] and has been linked to environmental health risks, regardless of urbanicity [
4,
6,
7,
53]. Indices that can measure residential segregation in various regions, including non-urban areas, are a valuable, albeit under-researched, component of residential segregation research.
Finally, a local, spatial measure of residential segregation can also be calculated at or aggregated to different geographic scales, capturing residential segregation at different scales. Depending on the research questions and variables of interest, different geographic scales may be more relevant. Data availability may be a constraint in some cases. For example, the block level is the most highly resolved census geography and serves as the “building blocks” for all other census geographies. Racial composition data are available at the block level, but educational attainment composition data are not, due to privacy considerations.
To illustrate the utility and relevance of EI and RI, we used eight years of detailed birth records in Michigan to estimate associations with gestation length and preterm birth, which is a leading cause of infant mortality and morbidity that in the US is characterized by stark racial/ethnic disparities. We observed statistically significant associations between RI, EI, and birth outcomes. Specifically, both RI and EI were associated with decrements in gestational length among NHB and NHW women. RI was associated with PTB among NHB and NHW women, while EI was associated with PTB among NHB women only.
Several points merit discussion. First, racial and educational isolation have adverse effects for both NHB and NHW women. Second, the vast majority of NHB women give birth in highly racially isolated neighborhoods. Third, the patterns of co-exposure to RI and EI differ by race/ethnicity. Compared to NHW women, NHB women in Michigan tended to live in neighborhoods that are both racially and educationally isolated, indicating that NHB women are more likely to be co-exposed to EI and RI. Fourth, although the cross-sectional associations reported here are not large in magnitude, these are population-level estimates that apply to a large number of people and therefore translate into substantial public health effects for more racially and educationally isolated populations.
This paper has several limitations. We dichotomized EI to calculate the isolation of non-college educated from college educated individuals, but there are of course other possible groupings (e.g., non-high school educated vs. high school educated). We also recognize the Modifiable Areal Unit Problem, which introduces bias resulting from the aggregation of point-based measures of spatial phenomena into areal units [
54]. In short, the summary values produced from areal/zonal aggregation are arbitrarily determined by both the size and geometry of the aggregation unit [
55].
Furthermore, in calculating spatial indices, edge effects may occur when neighboring spatial units, in this case census tracts, located outside the study area are ignored, thus distorting the index values assigned to bordering tracts within the study area. For this reason, we calculated RI and EI for the entire US, ignoring state borders. Nonetheless, there is still potential for “edge effects” along coastlines and international borders with Canada and Mexico. Values and patterns of local correlation coefficients may differ at finer or coarser spatial scales, and they also differ depending on how index and neighboring tracts are weighted in the calculation of the local correlation index. Furthermore, census-defined areal units may not accurately represent any given individual’s neighborhood boundaries. The first-order adjacency structure may not accurately represent an individual’s residential environment. Results may be sensitive to our choice regarding the weighting of first-order neighbors in the calculation of EI and RI, and first and second-order neighbors in the calculation of local correlation between EI and RI. The weights are set globally, even though it might be more appropriate to change weights based on local context. These novel local measures can be calculated at varying spatial resolutions, and results could be evaluated for sensitivity regarding the selection of weights. Finally, there are multiple approaches to assessing segregation [
16], and no single measure is perfect. Thus, future work to understand how segregation measures relate to one another, as well socioeconomic characteristics, is warranted.
5. Conclusions
Racial residential segregation, and racial isolation as a measure of segregation, has been linked to health [
1,
4,
6,
7,
8]; although the measure of EI that we introduce here is new, educational attainment is associated with poverty, employment, and income, all of which are unequivocally linked with health [
56,
57]. Increasingly, the United States is segregated by income [
58] and race [
11]. A premise of this work is that place-based exposures, including EI and RI, may underlie health and health disparities, and should both be considered and evaluated as possible adverse exposures. A key takeaway of this research is that RI and EI do not exhibit a uniform or random relationship across the United States; rather, we see differences in the relationship between RI and EI across geographic space and urbanicity levels. Specifically, in the south, we observe census tracts that are educationally isolated, racially isolated, and non-urban; elsewhere in the US, tracts that are educationally and racially isolated are found only in urban areas. For example, the health disparities and poor health outcomes that have been documented in the “Stroke Belt” [
59] could relate to multiple-jeopardy situations in which adverse exposures (racial isolation, educational isolation, rurality, pollution, access to health care, among others) accumulate to specific populations, by virtue of exposures sustained, in part, due to where they live.
The RI and EI indices described here are available (
https://www.cehidatahub.org/hub) and immediately useful to both public health researchers and to policymakers. For researchers, initial work has already linked RI to health outcomes. Further work, including examining the impact of RI and EI separately and jointly, and whether their impact differs by race or geography, is warranted. The local correlation measure developed here can be used to evaluate relationships between other widely used socioeconomic variables measured at various spatial resolutions, which overcomes the tendency of the standardly used global correlation coefficient to mask substantial local heterogeneity in correlation patterns.
In addition, information on RI and EI can help policymakers identify potentially disadvantaged communities and the nature of the disadvantage. Specifically, different intervention strategies may be more appropriate and/or effective depending on whether a community is racially isolated versus educationally isolated, or both. For example, in communities in which few people have a college degree, community leaders may want to first understand whether youth in these communities are not pursuing college degrees or whether they are pursuing and receiving a college education and choosing not to return to the community. Depending on the answer, in such communities, designing policies or programs that identify barriers to college education, emphasize the benefits of college education, or help connect students with mentors or financial resources may be important steps.
For policymakers, to the extent that RI and EI are linked to health disparities, policy choices can be evaluated for their impact on RI and EI. This is more straightforward than linking to health outcomes directly and thus may get critical information into the policy process more quickly. We note finally that these measures of isolation are not meant to be causal in and of themselves but rather represent the likely accumulation of dis-amenities and overall disinvestment in communities that are racially and educationally isolated. Thus, patterns of RI and EI over time may also represent a way to assess the overall health of a community or specific areas that warrant additional attention or investment. Finally, we argue for shifting the conversation from race (non-modifiable) as a driver of outcomes to the experience and exposures of minorities in segregated communities (modifiable) as a driver of outcomes.










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}