
Mortality-Risk Prediction Model from Road-Traffic Injury in Drunk Drivers: Machine Learning Approach




Abstract
:1. Introduction
2. Materials and Methods
2.1. Derivation Dataset (Thai Governmental Road Safety Evaluation Project from 2002–2004)
2.1.1. Data Collection
2.1.2. Study Population
2.1.3. Predictors
2.1.4. Outcomes
2.2. Missing Data and Imputation
2.3. Model Development
2.3.1. K-Nearest Neighbors (KNN)
2.3.2. Random Forest Classifier (RF)
2.3.3. Stochastic Gradient Boosting Classifier (GBC)
2.3.4. Multilayer Perceptron Artificial Neural Network (MLP)
2.3.5. Logistic Regression Model (Logit)
2.4. Internal Validation, Discrimination Performance and Calibration
2.5. Statistical Analysis
3. Results
3.1. Baseline Characteristics of Drivers
3.2. Model Development
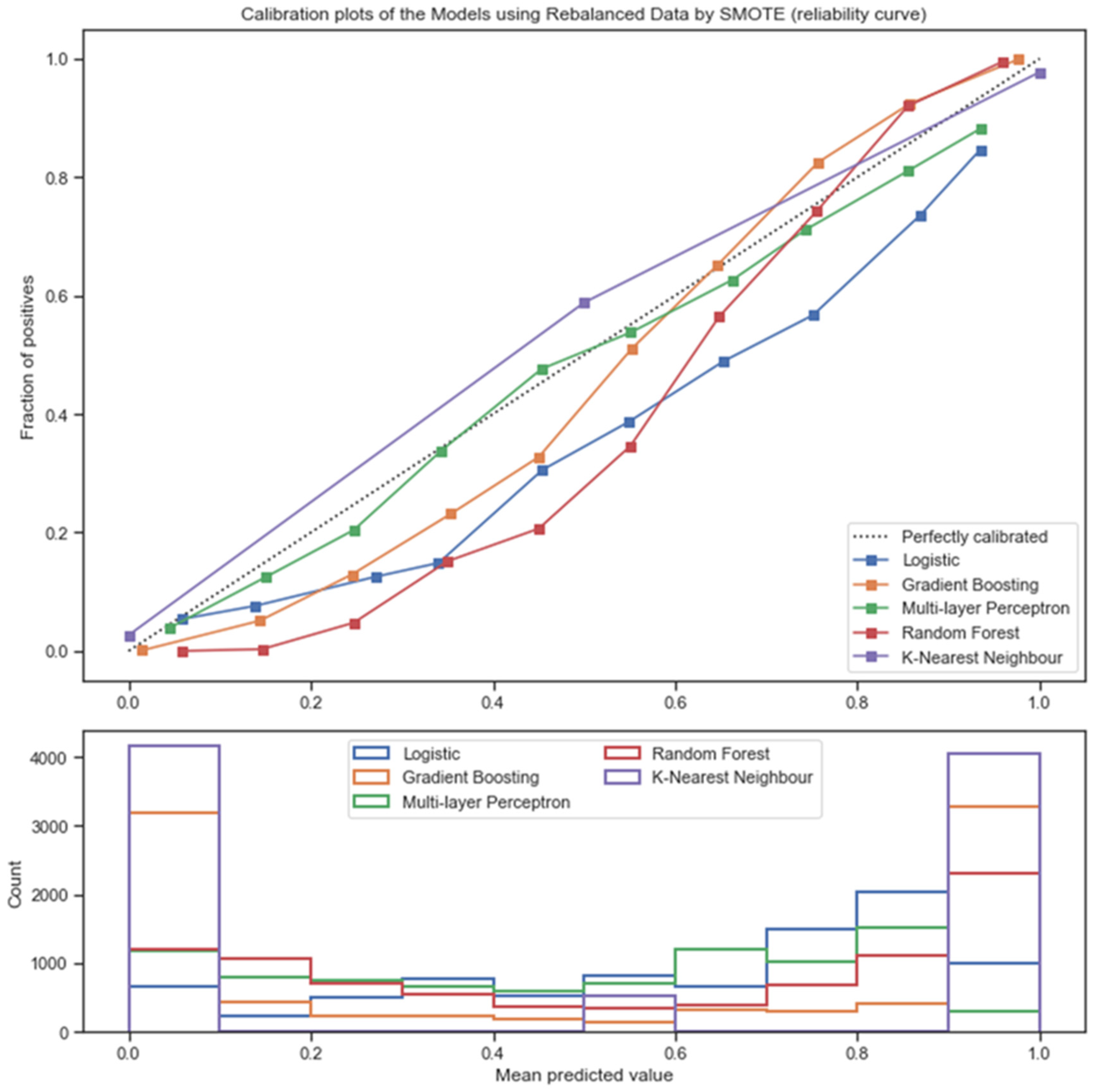
3.3. Discrimination Performance and Model Calibration
4. Discussion
4.1. Limitations
4.2. Interpretations
4.3. Implications
5. Conclusions
Supplementary Materials
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Jeanne, B.; Meleckidzedeck, K.; Rob, M.; Anesh, S.; Tamitza, T.; David, W.; Kacem, I.; Joëlle, A. The global burden of road traffic deaths. In Global Status Report on Road Safety 2018; World Health Organization: Geneva, Switzerland, 2018; pp. 3–14. [Google Scholar]
- Road Traffic Injuries: Key Facts, World Health Organization. Available online: https://www.who.int/news-room/fact-sheets/detail/road-traffic-injuries (accessed on 3 September 2021).
- Thai Road Safety Collaboration. New Year and Songkran Statistical Data 2015–2017 [In Thai]. Available online: http://www.thairsc.com/TH/stataccidentonfestival (accessed on 3 September 2021).
- Jeanne, B. Risk factors. In World Report on Road Traffic Injury Prevention; Margie, P., Richard, S., David, S., Dinesh, M., Adnan, A.H., Eva, J., Colin, M., Eds.; World Health Organization: Geneva, Switzerland, 2004; pp. 69–95. [Google Scholar]
- Stübig, T.; Petri, M.; Zeckey, C.; Brand, S.; Müller, C.; Otte, D.; Krettek, C.; Haasper, C. Alcohol intoxication in road traffic accidents leads to higher impact speed difference, higher ISS and MAIS, and higher preclinical mortality. Alcohol 2012, 46, 681–686. [Google Scholar] [CrossRef]
- Seesen, M.; Siviroj, P.; Sapbamrer, R.; Morarit, S. High blood alcohol concentration associated with traumatic brain injury among traffic injury patients during New Year festivals in Thailand. Traffic Inj. Prev. 2019, 20, 115–121. [Google Scholar] [CrossRef] [PubMed]
- Herbert, M.; Dary, F. A Review of the Literature on the Effects of Low Doses of Alcohol on Driving-Related Skills; National Highway Traffic Safety Administration (NHTSA): Washington, DC, USA, 2000.
- Peden, M.; van der Spuy, J.; Smith, P.; Bautz, P. Substance abuse and trauma in Cape Town. S. Afr. Med. J. 2000, 90, 251–255. [Google Scholar] [PubMed]
- Erke, A.; Goldenbeld, C.; Vaa, T. The effects of drink-driving checkpoints on crashes—A meta-analysis. Accid. Anal. Prev. 2009, 41, 914–923. [Google Scholar] [CrossRef] [PubMed]
- Elder, R.W.; Shults, R.A.; Sleet, D.A.; Nichols, J.L.; Zaza, S.; Thompson, R.S. Effectiveness of Sobriety Checkpoints for Reducing Alcohol-Involved Crashes. Traffic Inj. Prev. 2002, 3, 266–274. [Google Scholar] [CrossRef]
- Elder, R.W.; Shults, R.A.; Sleet, D.A.; Nichols, J.L.; Thompson, R.S.; Rajab, W. Effectiveness of mass media campaigns for reducing drinking and driving and alcohol-involved crashes: A systematic review. Am. J. Prev. Med. 2004, 27, 57–65. [Google Scholar] [CrossRef]
- Sloan, F.A.; McCutchan, S.A.; Eldred, L.M. Alcohol-Impaired Driving and Perceived Risks of Legal Consequences. Alcohol. Clin. Exp. Res. 2017, 41, 432–442. [Google Scholar] [CrossRef] [Green Version]
- Ditsuwan, V.; Lennert Veerman, J.; Bertram, M.; Vos, T. Cost-Effectiveness of Interventions for Reducing Road Traffic Injuries Related to Driving under the Influence of Alcohol. Value Health 2013, 16, 23–30. [Google Scholar] [CrossRef] [Green Version]
- Zador, P.L. Alcohol-related relative risk of fatal driver injuries in relation to driver age and sex. J. Stud. Alcohol 1991, 52, 302–310. [Google Scholar] [CrossRef]
- Keall, M.D.; Frith, W.J.; Patterson, T.L. The influence of alcohol, age and number of passengers on the night-time risk of driver fatal injury in New Zealand. Accid. Anal. Prev. 2004, 36, 49–61. [Google Scholar] [CrossRef]
- World Report on Road Traffic Injury Prevention; World Health Organization: Geneva, Switzerland, 2004; pp. 88–93.
- Moons, K.G.M.; Royston, P.; Vergouwe, Y.; Grobbee, D.E.; Altman, D.G. Prognosis and prognostic research: What, why, and how? BMJ 2009, 338, b375. [Google Scholar] [CrossRef] [PubMed]
- Steyerberg, E.W. Introduction. In Clinical Prediction Models: A Practical Approach to Development, Validation, and Updating; Springer: New York, NY, USA, 2009; pp. 1–7. [Google Scholar]
- Morgenstern, J.D.; Buajitti, E.; O’Neill, M.; Piggott, T.; Goel, V.; Fridman, D.; Kornas, K.; Rosella, L.C. Predicting population health with machine learning: A scoping review. BMJ Open 2020, 10, e037860. [Google Scholar] [CrossRef] [PubMed]
- Ngiam, K.Y.; Khor, I.W. Big data and machine learning algorithms for health-care delivery. Lancet Oncol. 2019, 20, e262–e273. [Google Scholar] [CrossRef]
- Kunt, M.; Aghayan, I.; Noii, N. Prediction for traffic accident severity: Comparing the artificial neural network, genetic algorithm, combined genetic algorithm and pattern search methods. Transport 2011, 26, 353–366. [Google Scholar] [CrossRef] [Green Version]
- Sameen, M.I.; Pradhan, B. Severity Prediction of Traffic Accidents with Recurrent Neural Networks. Appl. Sci. 2017, 7, 476. [Google Scholar] [CrossRef] [Green Version]
- Yassin, S.S. Road accident prediction and model interpretation using a hybrid K-means and random forest algorithm approach. SN Appl. Sci. 2020, 2, 1576. [Google Scholar] [CrossRef]
- Assi, K.; Rahman, S.M.; Mansoor, U.; Ratrout, N. Predicting Crash Injury Severity with Machine Learning Algorithm Synergized with Clustering Technique: A Promising Protocol. Int. J. Environ. Res. Public Health 2020, 17, 5497. [Google Scholar] [CrossRef]
- Hlastala, M. The alcohol breath test—A review. J. Appl. Physiol. 1998, 84, 401–408. [Google Scholar] [CrossRef]
- Hlastala, M.P. Paradigm Shift for the Alcohol Breath Test. J. Forensic Sci. 2010, 55, 451–456. [Google Scholar] [CrossRef]
- Thailand Crash Data Collection for Asia and the Pacific Road Safety Observatory. In Proceedings of the Regional Seminar on Tackling Main Causes of Road Traffic Crashes, Fatalities and Injuries in Asia-Pacific Countries to Achieve Road Safety Targets of the Sustainable Development Goals, New Deli, India, 3–4 December 2019; pp. 31–32.
- Tackling Main Causes of Road Traffic Crashes—ESCAP. In Proceedings of the Regional Seminar on Tackling Main Causes of Road Traffic Crashes, Fatalities and Injuries in Asia-Pacific Countries to Achieve Road Safety Targets of the Sustainable Development Goals, New Deli, India, 24–25 December 2019; pp. 14–17.
- Zhao, Y.; Wong, Z.S.-Y.; Tsui, K.L. A Framework of Rebalancing Imbalanced Healthcare Data for Rare Events’ Classification: A Case of Look-Alike Sound-Alike Mix-Up Incident Detection. J. Healthc. Eng. 2018, 2018, 6275435. [Google Scholar] [CrossRef] [PubMed]
- Belarouci, S.; Chikh, M. Medical imbalanced data classification. Adv. Sci. Technol. Eng. Syst. J. 2017, 2, 116–124. [Google Scholar] [CrossRef] [Green Version]
- Strategies to Reduce Impaired Driving for Road Safety in the Asia Pacific Region. In Proceedings of the Regional Seminar on Tackling Main Causes of Road Traffic Crashes, Fatalities and Injuries in Asia-Pacific Countries to Achieve Road Safety Targets of the Sustainable Development Goals, New Deli, India, 24–25 December 2019; pp. 21–22.




{kind=link}
{kind=link}
{kind=link}
| Characteristics | Total (n = 4794) | p-Value | |||
|---|---|---|---|---|---|
| Death (n = 429) | Survive (n = 4365) | ||||
| n | % | n | % | ||
| Age, median (IQR), years | 26 | (19) | 30 | (6) | <0.001 * |
| Gender | |||||
| Male | 393 | 91.61 | 3804 | 87.15 | 0.008 |
| Female | 36 | 8.39 | 561 | 12.85 | |
| Alcohol | |||||
| BAC level, median (IQR), mg% | 15 | 156.70 | 1 | 130.00 | 0.051 * |
| Alcohol odor on breath | 321 | 74.83 | 2915 | 66.78 | <0.001 |
| Type of vehicle | |||||
| Bicycle | 20 | 4.66 | 133 | 3.05 | 0.069 |
| Motorcycle | 378 | 88.11 | 3978 | 91.38 | 0.038 |
| 4-wheel car | 26 | 6.06 | 210 | 4.81 | 0.254 |
| Commercial truck, semitrailer, and trailer | 5 | 1.17 | 37 | 0.85 | 0.500 |
| Safety belt used a | (n = 31) | (n = 247) | |||
| Yes | 3 | 9.68 | 79 | 31.98 | 0.010 |
| No | 28 | 90.32 | 168 | 68.02 | |
| Helmet used b | (n = 398) | (n = 4111) | |||
| Yes | 40 | 10.05 | 709 | 17.25 | <0.001 |
| No | 358 | 89.95 | 3402 | 82.75 | |
| Place of accident | |||||
| Urban | 50 | 11.66 | 822 | 18.83 | <0.001 |
| Suburban | 148 | 34.50 | 1480 | 33.91 | 0.805 |
| Rural | 231 | 53.85 | 2063 | 47.26 | 0.009 |
| Driving across provinces | 111 | 25.87 | 587 | 13.45 | <0.001 |
| Time of accident | |||||
| 8:01 a.m. to 4:00 p.m. | 106 | 24.71 | 1208 | 27.67 | 0.189 |
| 4:01 p.m. to 12:00 a.m. | 97 | 22.61 | 1198 | 27.45 | 0.031 |
| 12:01 a.m. to 8:00 a.m. | 226 | 52.68 | 1959 | 44.88 | 0.002 |
| Characteristic | OR | p-Value | aOR | p-Value | AUC | 95% CI |
|---|---|---|---|---|---|---|
| Age, years (median, IQR) | 1.01 | <0.001 | 1.01 | <0.001 | 0.56 | 0.53–0.58 |
| Male | 1.60 | 0.008 | 1.42 | 0.059 | 0.52 | 0.51–0.54 |
| BAC level, mg% (median, IQR) | 1.00 | 0.051 | 1.00 | 0.052 | 0.53 | 0.49–0.55 |
| Motorcycle | 0.72 | 0.038 | 0.74 | 0.071 | 0.48 | 0.46–0.50 |
| Safety belt used | 0.38 | 0.010 | 0.18 | 0.005 | 0.49 | 0.49–0.50 |
| Helmet used | 0.53 | <0.001 | 0.55 | <0.001 | 0.46 | 0.45–0.48 |
| Place of accident: Suburban | 1.03 | 0.805 | 1.57 | 0.008 | 0.50 | 0.48–0.53 |
| Place of accident: Rural | 1.30 | 0.009 | 1.74 | 0.001 | 0.53 | 0.51–0.55 |
| Driving across provinces | 2.25 | <0.001 | 2.12 | <0.001 | 0.56 | 0.54–0.58 |
| Driving at night (12:01 a.m. to 8:00 a.m.) | 1.37 | 0.002 | 1.25 | 0.035 | 0.53 | 0.51–0.56 |
| Models | Model Prediction | (Death/ Survival) | AUC | Likelihood Ratio | Sensitivity | Specificity | ||
|---|---|---|---|---|---|---|---|---|
| Mean | 95% CI | Positive | Negative | |||||
| GBC | Death | (3946/594) | 0.95 | 0.90–1.00 | 6.64 | 0.11 | 90.4 | 86.39 |
| Survival | (419/3771) | |||||||
| RF | Death | (4001/1086) | 0.92 | 0.87–0.97 | 3.68 | 0.11 | 91.66 | 75.12 |
| Survival | (364/3279) | |||||||
| MLP | Death | (3462/1299) | 0.83 | 0.78–0.88 | 2.67 | 0.29 | 79.31 | 70.24 |
| Survival | (903/3066) | |||||||
| Logit | Death | (3929/2148) | 0.81 | 0.75–0.87 | 1.83 | 0.2 | 90.01 | 50.79 |
| Survival | (436/2217) | |||||||
| KNN | Death | (3573/824) | 0.86 | 0.83–0.89 | 4.34 | 0.22 | 81.86 | 81.12 |
| Survival | (792/3541) | |||||||
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Sirikul, W.; Buawangpong, N.; Sapbamrer, R.; Siviroj, P. Mortality-Risk Prediction Model from Road-Traffic Injury in Drunk Drivers: Machine Learning Approach. Int. J. Environ. Res. Public Health 2021, 18, 10540. https://doi.org/10.3390/ijerph181910540
Sirikul W, Buawangpong N, Sapbamrer R, Siviroj P. Mortality-Risk Prediction Model from Road-Traffic Injury in Drunk Drivers: Machine Learning Approach. International Journal of Environmental Research and Public Health. 2021; 18(19):10540. https://doi.org/10.3390/ijerph181910540
Chicago/Turabian StyleSirikul, Wachiranun, Nida Buawangpong, Ratana Sapbamrer, and Penprapa Siviroj. 2021. "Mortality-Risk Prediction Model from Road-Traffic Injury in Drunk Drivers: Machine Learning Approach" International Journal of Environmental Research and Public Health 18, no. 19: 10540. https://doi.org/10.3390/ijerph181910540
APA StyleSirikul, W., Buawangpong, N., Sapbamrer, R., & Siviroj, P. (2021). Mortality-Risk Prediction Model from Road-Traffic Injury in Drunk Drivers: Machine Learning Approach. International Journal of Environmental Research and Public Health, 18(19), 10540. https://doi.org/10.3390/ijerph181910540