
Bayesian Methods for Meta-Analyses of Binary Outcomes: Implementations, Examples, and Impact of Priors


Abstract
:1. Introduction
2. Materials and Methods
2.1. Bayesian Meta-Analysis of Odds Ratios
2.2. Priors for Heterogeneity
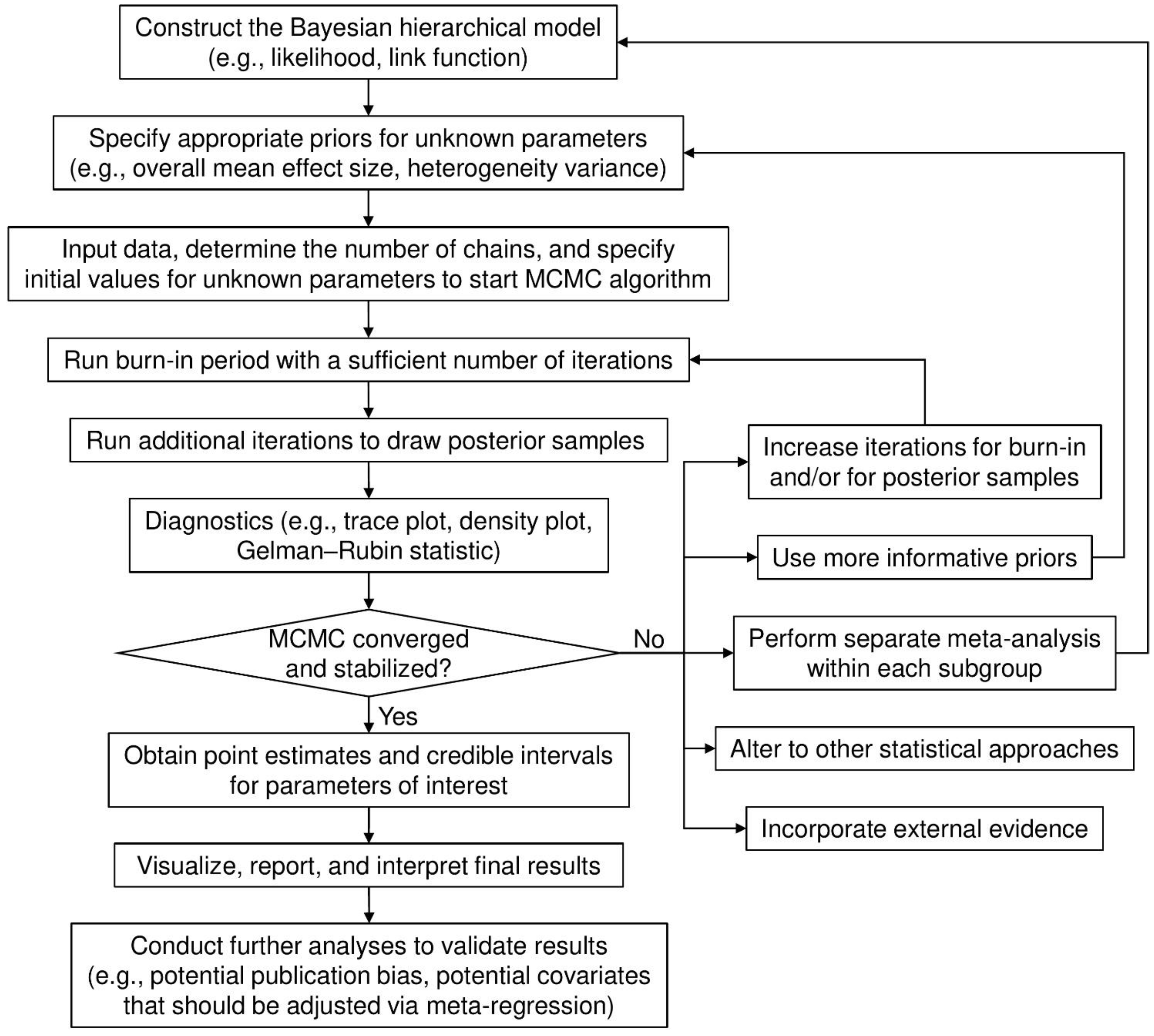
2.3. Implementation
2.4. Application to Real Data
2.5. Statistical Analyses
3. Results
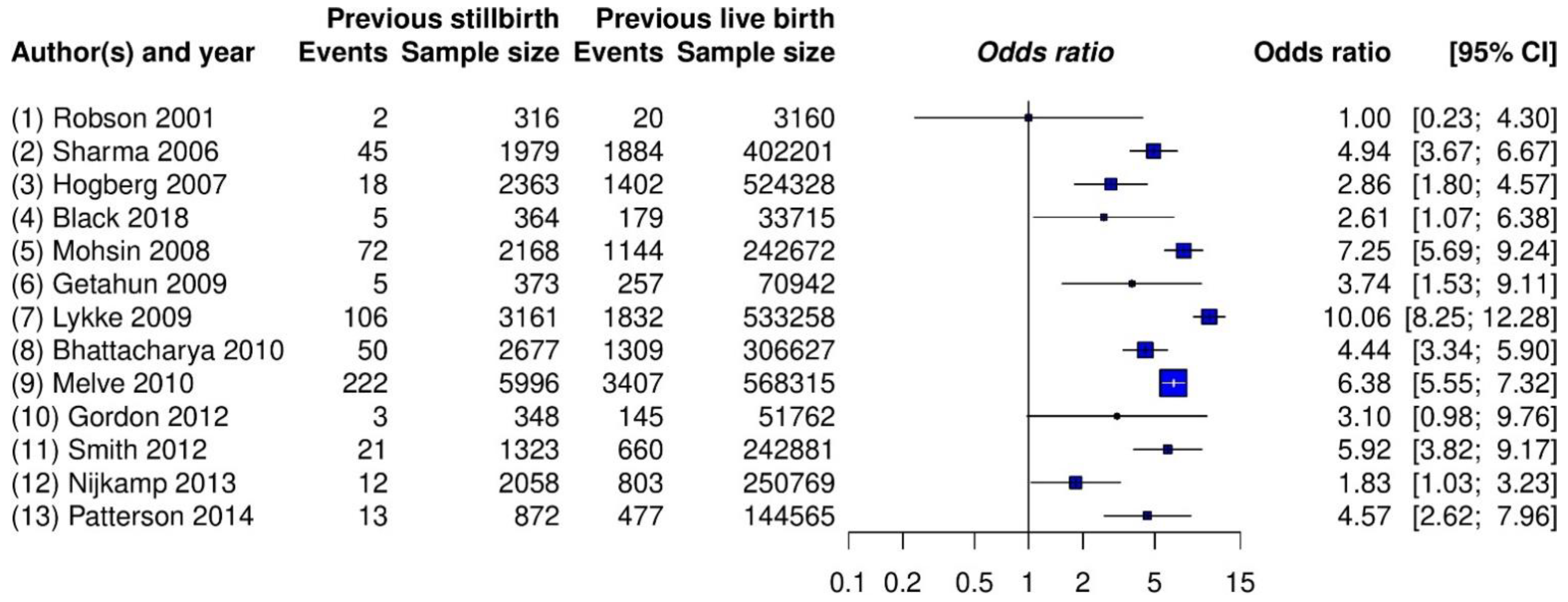
3.1. Example 1: Meta-Analysis on Stillbirth
3.2. Example 2: Meta-Analysis on Patient Enrollment in Clinical Trials
3.3. Example 3: Meta-Analysis on Colitis
3.4. Example 4: Meta-Analysis on Hepatitis
3.5. Example 5: Meta-Analysis on Acute Respiratory Tract Infection
4. Conclusions
Supplementary Materials
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Niforatos, J.D.; Weaver, M.; Johansen, M.E. Assessment of publication trends of systematic reviews and randomized clinical trials, 1995 to 2017. JAMA Intern. Med. 2019, 179, 1593–1594. [Google Scholar] [CrossRef]
- Requia, W.J.; Adams, M.D.; Arain, A.; Papatheodorou, S.; Koutrakis, P.; Mahmoud, M. Global association of air pollution and cardiorespiratory diseases: A systematic review, meta-analysis, and investigation of modifier variables. Am. J. Public Health 2018, 108, S123–S130. [Google Scholar] [CrossRef]
- Hoffmann, R.; Dimitrova, A.; Muttarak, R.; Crespo Cuaresma, J.; Peisker, J. A meta-analysis of country-level studies on environmental change and migration. Nat. Clim. Chang. 2020, 10, 904–912. [Google Scholar] [CrossRef]
- Ioannidis, J.P.A. The mass production of redundant, misleading, and conflicted systematic reviews and meta-analyses. Milbank Q. 2016, 94, 485–514. [Google Scholar] [CrossRef] [Green Version]
- DerSimonian, R.; Laird, N. Meta-analysis in clinical trials. Control. Clin. Trials 1986, 7, 177–188. [Google Scholar] [CrossRef]
- Cornell, J.E.; Mulrow, C.D.; Localio, R.; Stack, C.B.; Meibohm, A.R.; Guallar, E.; Goodman, S.N. Random-effects meta-analysis of inconsistent effects: A time for change. Ann. Intern. Med. 2014, 160, 267–270. [Google Scholar] [CrossRef] [PubMed]
- Langan, D.; Higgins, J.P.T.; Jackson, D.; Bowden, J.; Veroniki, A.A.; Kontopantelis, E.; Viechtbauer, W.; Simmonds, M. A comparison of heterogeneity variance estimators in simulated random-effects meta-analyses. Res. Synth. Methods 2019, 10, 83–98. [Google Scholar] [CrossRef] [PubMed]
- Doncaster, C.P.; Spake, R. Correction for bias in meta-analysis of little-replicated studies. Methods Ecol. Evol. 2018, 9, 634–644. [Google Scholar] [CrossRef] [Green Version]
- Lin, L. Bias caused by sampling error in meta-analysis with small sample sizes. PLoS ONE 2018, 13, e0204056. [Google Scholar] [CrossRef] [Green Version]
- Jackson, D.; Law, M.; Stijnen, T.; Viechtbauer, W.; White, I.R. A comparison of seven random-effects models for meta-analyses that estimate the summary odds ratio. Stat. Med. 2018, 37, 1059–1085. [Google Scholar] [CrossRef] [PubMed]
- Hartung, J.; Knapp, G. A refined method for the meta-analysis of controlled clinical trials with binary outcome. Stat. Med. 2001, 20, 3875–3889. [Google Scholar] [CrossRef]
- Bhaumik, D.K.; Amatya, A.; Normand, S.-L.T.; Greenhouse, J.; Kaizar, E.; Neelon, B.; Gibbons, R.D. Meta-analysis of rare binary adverse event data. J. Am. Stat. Assoc. 2012, 107, 555–567. [Google Scholar] [CrossRef] [Green Version]
- Riley, R.D.; Steyerberg, E.W. Meta-analysis of a binary outcome using individual participant data and aggregate data. Res. Synth. Methods 2010, 1, 2–19. [Google Scholar] [CrossRef] [PubMed]
- Mathes, T.; Kuss, O. A comparison of methods for meta-analysis of a small number of studies with binary outcomes. Res. Synth. Methods 2018, 9, 366–381. [Google Scholar] [CrossRef]
- Bakbergenuly, I.; Kulinskaya, E. Meta-analysis of binary outcomes via generalized linear mixed models: A simulation study. BMC Med. Res. Methodol. 2018, 18, 70. [Google Scholar] [CrossRef] [PubMed]
- Beisemann, M.; Doebler, P.; Holling, H. Comparison of random-effects meta-analysis models for the relative risk in the case of rare events: A simulation study. Biom. J. 2020, 62, 1597–1630. [Google Scholar] [CrossRef]
- Kuss, O. Statistical methods for meta-analyses including information from studies without any events—add nothing to nothing and succeed nevertheless. Stat. Med. 2015, 34, 1097–1116. [Google Scholar] [CrossRef] [PubMed]
- Schmid, C.H. Using Bayesian inference to perform meta-analysis. Eval. Health Prof. 2001, 24, 165–189. [Google Scholar] [CrossRef]
- McGlothlin, A.E.; Viele, K. Bayesian hierarchical models. JAMA 2018, 320, 2365–2366. [Google Scholar] [CrossRef] [PubMed]
- Ashby, D. Bayesian statistics in medicine: A 25 year review. Stat. Med. 2006, 25, 3589–3631. [Google Scholar] [CrossRef]
- Pullenayegum, E.M.; Thabane, L. Teaching Bayesian statistics in a health research methodology program. J. Stat. Educ. 2009, 17, 3. [Google Scholar] [CrossRef]
- Bittl, J.A.; He, Y. Bayesian analysis: A practical approach to interpret clinical trials and create clinical practice guidelines. Circ. Cardiovasc. Qual. Outcomes 2017, 10, e003563. [Google Scholar] [CrossRef]
- Negrín-Hernández, M.-A.; Martel-Escobar, M.; Vázquez-Polo, F.-J. Bayesian meta-analysis for binary data and prior distribution on models. Int. J. Environ. Res. Public Health 2021, 18, 809. [Google Scholar] [CrossRef]
- Pullenayegum, E.M. An informed reference prior for between-study heterogeneity in meta-analyses of binary outcomes. Stat. Med. 2011, 30, 3082–3094. [Google Scholar] [CrossRef]
- Quintana, M.; Viele, K.; Lewis, R.J. Bayesian analysis: Using prior information to interpret the results of clinical trials. JAMA 2017, 318, 1605–1606. [Google Scholar] [CrossRef]
- Wei, Y.; Higgins, J.P.T. Bayesian multivariate meta-analysis with multiple outcomes. Stat. Med. 2013, 32, 2911–2934. [Google Scholar] [CrossRef] [PubMed]
- Lin, L.; Chu, H. Bayesian multivariate meta-analysis of multiple factors. Res. Synth. Methods 2018, 9, 261–272. [Google Scholar] [CrossRef]
- Grant, R.L. The uptake of Bayesian methods in biomedical meta-analyses: A scoping review (2005–2016). J. Evid. Based Med. 2019, 12, 69–75. [Google Scholar] [CrossRef]
- Borenstein, M.; Hedges, L.V.; Higgins, J.P.T.; Rothstein, H.R. Introduction to Meta-Analysis; John Wiley & Sons: Chichester, UK, 2009. [Google Scholar]
- Röver, C. Bayesian random-effects meta-analysis using the bayesmeta R package. J. Stat. Softw. 2020, 93, 1–51. [Google Scholar] [CrossRef]
- Bürkner, P.-C. brms: An R package for Bayesian multilevel models using Stan. J. Stat. Softw. 2017, 80, 1–28. [Google Scholar] [CrossRef] [Green Version]
- Van Valkenhoef, G.; Lu, G.; de Brock, B.; Hillege, H.; Ades, A.E.; Welton, N.J. Automating network meta-analysis. Res. Synth. Methods 2012, 3, 285–299. [Google Scholar] [CrossRef]
- Lin, L.; Zhang, J.; Hodges, J.S.; Chu, H. Performing arm-based network meta-analysis in R with the pcnetmeta package. J. Stat. Softw. 2017, 80, 1–25. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Muthén, B.; Asparouhov, T. Bayesian structural equation modeling: A more flexible representation of substantive theory. Psychol. Methods 2012, 17, 313–335. [Google Scholar] [CrossRef]
- Higgins, J.P.T.; Thompson, S.G.; Spiegelhalter, D.J. A re-evaluation of random-effects meta-analysis. J. R. Stat. Soc. Ser. A 2009, 172, 137–159. [Google Scholar] [CrossRef] [Green Version]
- Depaoli, S.; Clifton, J.P. A Bayesian approach to multilevel structural equation modeling with continuous and dichotomous outcomes. Struct. Equ. Modeling Multidiscip. J. 2015, 22, 327–351. [Google Scholar] [CrossRef]
- Depaoli, S. Mixture class recovery in GMM under varying degrees of class separation: Frequentist versus Bayesian estimation. Psychol. Methods 2013, 18, 186–219. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Friede, T.; Röver, C.; Wandel, S.; Neuenschwander, B. Meta-analysis of few small studies in orphan diseases. Res. Synth. Methods 2017, 8, 79–91. [Google Scholar] [CrossRef] [PubMed]
- Kruschke, J.K.; Liddell, T.M. The Bayesian new statistics: Hypothesis testing, estimation, meta-analysis, and power analysis from a Bayesian perspective. Psychon. Bull. Rev. 2018, 25, 178–206. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Carlin, B.P.; Louis, T.A. Bayesian Methods for Data Analysis, 3rd ed.; CRC Press: Boca Raton, FL, USA, 2009. [Google Scholar]
- Smith, T.C.; Spiegelhalter, D.J.; Thomas, A. Bayesian approaches to random-effects meta-analysis: A comparative study. Stat. Med. 1995, 14, 2685–2699. [Google Scholar] [CrossRef] [PubMed]
- Warn, D.E.; Thompson, S.G.; Spiegelhalter, D.J. Bayesian random effects meta-analysis of trials with binary outcomes: Methods for the absolute risk difference and relative risk scales. Stat. Med. 2002, 21, 1601–1623. [Google Scholar] [CrossRef]
- Thompson, S.G.; Smith, T.C.; Sharp, S.J. Investigating underlying risk as a source of heterogeneity in meta-analysis. Stat. Med. 1997, 16, 2741–2758. [Google Scholar] [CrossRef]
- Sutton, A.J.; Abrams, K.R. Bayesian methods in meta-analysis and evidence synthesis. Stat. Methods Med. Res. 2001, 10, 277–303. [Google Scholar] [CrossRef]
- Dias, S.; Ades, A.E. Absolute or relative effects? Arm-based synthesis of trial data. Res. Synth. Methods 2016, 7, 23–28. [Google Scholar] [CrossRef] [Green Version]
- Hong, H.; Chu, H.; Zhang, J.; Carlin, B.P. Rejoinder to the discussion of “a Bayesian missing data framework for generalized multiple outcome mixed treatment comparisons” by S. Dias and A. E. Ades. Res. Synth. Methods 2016, 7, 29–33. [Google Scholar] [CrossRef] [Green Version]
- White, I.R.; Turner, R.M.; Karahalios, A.; Salanti, G. A comparison of arm-based and contrast-based models for network meta-analysis. Stat. Med. 2019, 38, 5197–5213. [Google Scholar] [CrossRef]
- Turner, R.M.; Jackson, D.; Wei, Y.; Thompson, S.G.; Higgins, J.P.T. Predictive distributions for between-study heterogeneity and simple methods for their application in Bayesian meta-analysis. Stat. Med. 2015, 34, 984–998. [Google Scholar] [CrossRef] [Green Version]
- Elmariah, S.; Mauri, L.; Doros, G.; Galper, B.Z.; O’Neill, K.E.; Steg, P.G.; Kereiakes, D.J.; Yeh, R.W. Extended duration dual antiplatelet therapy and mortality: A systematic review and meta-analysis. Lancet 2015, 385, 792–798. [Google Scholar] [CrossRef] [Green Version]
- Greco, T.; Landoni, G.; Biondi-Zoccai, G.; D’Ascenzo, F.; Zangrillo, A. A Bayesian network meta-analysis for binary outcome: How to do it. Stat. Methods Med. Res. 2016, 25, 1757–1773. [Google Scholar] [CrossRef]
- Gelman, A. Prior distributions for variance parameters in hierarchical models (comment on article by Browne and Draper). Bayesian Anal. 2006, 1, 515–534. [Google Scholar] [CrossRef]
- Hartling, L.; Fernandes, R.M.; Bialy, L.; Milne, A.; Johnson, D.; Plint, A.; Klassen, T.P.; Vandermeer, B. Steroids and bronchodilators for acute bronchiolitis in the first two years of life: Systematic review and meta-analysis. BMJ 2011, 342, d1714. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Spiegelhalter, D.J.; Abrams, K.R.; Myles, J.P. Bayesian Approaches to Clinical Trials and Health-Care Evaluation; John Wiley & Sons: Chichester, UK, 2004. [Google Scholar]
- Turner, R.M.; Davey, J.; Clarke, M.J.; Thompson, S.G.; Higgins, J.P.T. Predicting the extent of heterogeneity in meta-analysis, using empirical data from the Cochrane Database of Systematic Reviews. Int. J. Epidemiol. 2012, 41, 818–827. [Google Scholar] [CrossRef] [Green Version]
- Lamont, K.; Scott, N.W.; Jones, G.T.; Bhattacharya, S. Risk of recurrent stillbirth: Systematic review and meta-analysis. BMJ 2015, 350, h3080. [Google Scholar] [CrossRef] [Green Version]
- Crocker, J.C.; Ricci-Cabello, I.; Parker, A.; Hirst, J.A.; Chant, A.; Petit-Zeman, S.; Evans, D.; Rees, S. Impact of patient and public involvement on enrolment and retention in clinical trials: Systematic review and meta-analysis. BMJ 2018, 363, k4738. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Baxi, S.; Yang, A.; Gennarelli, R.L.; Khan, N.; Wang, Z.; Boyce, L.; Korenstein, D. Immune-related adverse events for anti-PD-1 and anti-PD-L1 drugs: Systematic review and meta-analysis. BMJ 2018, 360, k793. [Google Scholar] [CrossRef] [Green Version]
- Martineau, A.R.; Jolliffe, D.A.; Hooper, R.L.; Greenberg, L.; Aloia, J.F.; Bergman, P.; Dubnov-Raz, G.; Esposito, S.; Ganmaa, D.; Ginde, A.A.; et al. Vitamin D supplementation to prevent acute respiratory tract infections: Systematic review and meta-analysis of individual participant data. BMJ 2017, 356, i6583. [Google Scholar] [CrossRef] [Green Version]
- Normand, S.-L.T. Meta-analysis: Formulating, evaluating, combining, and reporting. Stat. Med. 1999, 18, 321–359. [Google Scholar] [CrossRef]
- Viechtbauer, W. Conducting meta-analyses in R with the metafor package. J. Stat. Softw. 2010, 36, 3. [Google Scholar] [CrossRef] [Green Version]
- Viechtbauer, W. Confidence intervals for the amount of heterogeneity in meta-analysis. Stat. Med. 2007, 26, 37–52. [Google Scholar] [CrossRef]
- Veroniki, A.A.; Jackson, D.; Viechtbauer, W.; Bender, R.; Bowden, J.; Knapp, G.; Kuss, O.; Higgins, J.P.T.; Langan, D.; Salanti, G. Methods to estimate the between-study variance and its uncertainty in meta-analysis. Res. Synth. Methods 2016, 7, 55–79. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Ju, K.; Lin, L.; Chu, H.; Cheng, L.-L.; Xu, C. Laplace approximation, penalized quasi-likelihood, and adaptive Gauss–Hermite quadrature for generalized linear mixed models: Towards meta-analysis of binary outcome with sparse data. BMC Med. Res. Methodol. 2020, 20, 152. [Google Scholar] [CrossRef] [PubMed]
- Bender, R.; Friede, T.; Koch, A.; Kuss, O.; Schlattmann, P.; Schwarzer, G.; Skipka, G. Methods for evidence synthesis in the case of very few studies. Res. Synth. Methods 2018, 9, 382–392. [Google Scholar] [CrossRef] [PubMed]
- Michael, H.; Thornton, S.; Xie, M.; Tian, L. Exact inference on the random-effects model for meta-analyses with few studies. Biometrics 2019, 75, 485–493. [Google Scholar] [CrossRef] [PubMed]
- Seide, S.E.; Röver, C.; Friede, T. Likelihood-based random-effects meta-analysis with few studies: Empirical and simulation studies. BMC Med. Res. Methodol. 2019, 19, 16. [Google Scholar] [CrossRef] [PubMed]
- Röver, C.; Knapp, G.; Friede, T. Hartung-Knapp-Sidik-Jonkman approach and its modification for random-effects meta-analysis with few studies. BMC Med. Res. Methodol. 2015, 15, 99. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Günhan, B.K.; Röver, C.; Friede, T. Random-effects meta-analysis of few studies involving rare events. Res. Synth. Methods 2020, 11, 74–90. [Google Scholar] [CrossRef] [Green Version]
- Cai, T.; Parast, L.; Ryan, L. Meta-analysis for rare events. Stat. Med. 2010, 29, 2078–2089. [Google Scholar] [CrossRef] [Green Version]
- Friede, T.; Röver, C.; Wandel, S.; Neuenschwander, B. Meta-analysis of two studies in the presence of heterogeneity with applications in rare diseases. Biom. J. 2017, 59, 658–671. [Google Scholar] [CrossRef] [PubMed]
- Gronsbell, J.; Hong, C.; Nie, L.; Lu, Y.; Tian, L. Exact inference for the random-effect model for meta-analyses with rare events. Stat. Med. 2020, 39, 252–264. [Google Scholar] [CrossRef]
- Ren, Y.; Lin, L.; Lian, Q.; Zou, H.; Chu, H. Real-world performance of meta-analysis methods for rare events using the Cochrane Database of Systematic Reviews. J. Gen. Intern. Med. 2019, 34, 960–968. [Google Scholar] [CrossRef] [Green Version]
- Xu, C.; Furuya-Kanamori, L.; Zorzela, L.; Lin, L.; Vohra, S. A proposed framework to guide evidence synthesis practice for meta-analysis with zero-events studies. J. Clin. Epidemiol. 2021, 135, 70–78. [Google Scholar] [CrossRef] [PubMed]
- Hong, H.; Wang, C.; Rosner, G.L. Meta-analysis of rare adverse events in randomized clinical trials: Bayesian and frequentist methods. Clin. Trials 2021, 18, 3–16. [Google Scholar] [CrossRef]
- Efthimiou, O. Practical guide to the meta-analysis of rare events. Evid. Based Ment. Health 2018, 21, 72–76. [Google Scholar] [CrossRef]
- Riley, R.D.; Simmonds, M.C.; Look, M.P. Evidence synthesis combining individual patient data and aggregate data: A systematic review identified current practice and possible methods. J. Clin. Epidemiol. 2007, 60, 431–439. [Google Scholar] [CrossRef]
- Riley, R.D.; Lambert, P.C.; Abo-Zaid, G. Meta-analysis of individual participant data: Rationale, conduct, and reporting. BMJ 2010, 340, c221. [Google Scholar] [CrossRef] [Green Version]
- Tierney, J.F.; Fisher, D.J.; Burdett, S.; Stewart, L.A.; Parmar, M.K.B. Comparison of aggregate and individual participant data approaches to meta-analysis of randomised trials: An observational study. PLOS Med. 2020, 17, e1003019. [Google Scholar] [CrossRef] [Green Version]
- Hong, H.; Carlin, B.P.; Shamliyan, T.A.; Wyman, J.F.; Ramakrishnan, R.; Sainfort, F.; Kane, R.L. Comparing Bayesian and frequentist approaches for multiple outcome mixed treatment comparisons. Med. Decis. Mak. 2013, 33, 702–714. [Google Scholar] [CrossRef] [PubMed]
- Seide, S.E.; Jensen, K.; Kieser, M. A comparison of Bayesian and frequentist methods in random-effects network meta-analysis of binary data. Res. Synth. Methods 2020, 11, 363–378. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Thompson, C.G.; Semma, B. An alternative approach to frequentist meta-analysis: A demonstration of Bayesian meta-analysis in adolescent development research. J. Adolesc. 2020, 82, 86–102. [Google Scholar] [CrossRef] [PubMed]
- Bennett, M.M.; Crowe, B.J.; Price, K.L.; Stamey, J.D.; Seaman, J.W. Comparison of Bayesian and frequentist meta-analytical approaches for analyzing time to event data. J. Biopharm. Stat. 2013, 23, 129–145. [Google Scholar] [CrossRef]
- Pappalardo, P.; Ogle, K.; Hamman, E.A.; Bence, J.R.; Hungate, B.A.; Osenberg, C.W. Comparing traditional and Bayesian approaches to ecological meta-analysis. Methods Ecol. Evol. 2020, 11, 1286–1295. [Google Scholar] [CrossRef]
- Weber, F.; Knapp, G.; Glass, Ä.; Kundt, G.; Ickstadt, K. Interval estimation of the overall treatment effect in random-effects meta-analyses: Recommendations from a simulation study comparing frequentist, Bayesian, and bootstrap methods. Res. Synth. Methods 2021, in press. [Google Scholar]
- Rhodes, K.M.; Turner, R.M.; Higgins, J.P.T. Predictive distributions were developed for the extent of heterogeneity in meta-analyses of continuous outcome data. J. Clin. Epidemiol. 2015, 68, 52–60. [Google Scholar] [CrossRef] [PubMed] [Green Version]



{kind=link}
{kind=link}
| Prior Distribution | Used for | Hyper-Parameter |
|---|---|---|
| Inverse-gamma, | = = 0.1; or | |
| = = 0.01; or | ||
| = = 0.001. | ||
| Uniform, | = 2; or | |
| = 10; or | ||
| = 100. | ||
| Half-normal, | = 0.1; or | |
| = 1; or | ||
| = 2. | ||
| Log-normal, | Pharmacological vs. placebo/control comparison: = 4.06, = 1.45 (all-cause mortality); = 3.02, = 1.85 (semi-objective outcome); = 2.13, = 1.58 (subjective outcome). Pharmacological vs. pharmacological comparison: = 4.27, = 1.48 (all-cause mortality); = 3.23, = 1.88 (semi-objective outcome); = 2.34, = 1.62 (subjective outcome). Non-pharmacological comparison: = 3.93, = 1.51 (all-cause mortality); = 2.89, = 1.91 (semi-objective outcome); = 2.01, = 1.64 (subjective outcome). |
| Bayesian Method | Frequentist Method e | ||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Estimate | Inverse-Gamma Prior a | Uniform Prior b | Half-Normal Prior c | Log-Normal Prior d | DL | ML | REML | ||||||||
| IG1 | IG2 | IG3 | U1 | U2 | U3 | HN1 | HN2 | HN3 | LN1 | LN2 | LN3 | ||||
| Example 1: meta-analysis on stillbirth | |||||||||||||||
| OR | 4.30 (2.95, 5.86) | 4.30 (2.95, 5.87) | 4.26 (2.90, 5.90) | 4.26 (2.85, 5.95) | 4.25 (2.85, 5.94) | 4.25 (2.85, 5.95) | 4.35 (3.13, 5.78) | 4.26 (2.89, 5.91) | 4.26 (2.86, 5.92) | 4.39 (3.16, 5.76) | 4.33 (3.04, 5.82) | 4.31 (3.01, 5.83) | 4.59 (3.56, 5.93) | 4.52 (3.42, 5.96) | 4.47 (3.34, 5.99) |
| Tau | 0.49 (0.29, 0.89) | 0.50 (0.30, 0.89) | 0.52 (0.32, 0.91) | 0.53 (0.31, 0.98) | 0.54 (0.31, 0.98) | 0.54 (0.31, 0.98) | 0.45 (0.28, 0.71) | 0.52 (0.31, 0.93) | 0.53 (0.31, 0.95) | 0.43 (0.26, 0.72) | 0.47 (0.28, 0.80) | 0.48 (0.29, 0.82) | 0.38 (0.28, 0.91) | 0.43 (0.28, 0.91) | 0.46 (0.28, 0.91) |
| Example 2: meta-analysis on patient enrollment in clinical trials | |||||||||||||||
| OR | 1.17 (0.99, 1.39) | 1.17 (0.95, 1.44) | 1.17 (0.87, 1.57) | 1.17 (0.96, 1.43) | 1.17 (0.96, 1.43) | 1.17 (0.96, 1.43) | 1.17 (0.98, 1.41) | 1.17 (0.96, 1.42) | 1.17 (0.98, 1.41) | 1.17 (0.99, 1.39) | 1.17 (0.97, 1.41) | 1.17 (0.95, 1.45) | 1.16 (1.03, 1.30) | 1.16 (1.03, 1.30) | 1.16 (1.03, 1.30) |
| Tau | 0.09 (0.02, 0.34) | 0.15 (0.06, 0.42) | 0.29 (0.16, 0.63) | 0.11 (0.01, 0.46) | 0.12 (0.01, 0.47) | 0.11 (0.01, 0.47) | 0.10 (0.01, 0.36) | 0.10 (0.01, 0.44) | 0.11 (0.00, 0.45) | 0.10 (0.03, 0.28) | 0.12 (0.03, 0.36) | 0.16 (0.05, 0.43) | 0.00 (0.00, 0.46) | 0.00 (0.00, 0.46) | 0.00 (0.00, 0.46) |
| Example 3: meta-analysis on colitisf | |||||||||||||||
| OR | 6.90 (2.28, 102) | 7.15 (2.25, 84.30) | 7.99 (2.25, 141) | 7.59 (2.24, 47.85) | 9.83 (2.24, 2008) | 11.37 (2.25, 105) | 6.09 (2.23, 22.46) | 6.88 (2.23, 35.32) | 7.62 (2.28, 56.53) | 5.89 (2.25, 21.04) | 5.95 (2.18, 23.08) | 6.34 (2.20, 26.20) | 3.39 (1.45, 7.95) | 3.39 (1.45, 7.95) | 3.39 (1.45, 7.95) |
| Tau | 0.25 (0.03, 3.89) | 0.44 (0.08, 3.37) | 0.73 (0.22, 3.98) | 0.74 (0.03, 1.90) | 1.13 (0.05, 7.32) | 1.33 (0.05, 12.84) | 0.20 (0.01, 0.68) | 0.51 (0.02, 1.78) | 0.66 (0.03, 2.45) | 0.13 (0.03, 0.49) | 0.21 (0.04, 1.02) | 0.31 (0.07, 1.26) | 0.00 (0.00, 0.00) | 0.00 (0.00, 0.00) | 0.00 (0.00, 0.00) |
| Example 4: meta-analysis on hepatitisg | |||||||||||||||
| OR | NA | NA | NA | NA | NA | NA | NA | NA | NA | NA | NA | NA | 3.14 (0.76, 12.98) | 3.14 (0.76, 12.98) | 3.14 (0.76, 12.98) |
| Tau | NA | NA | NA | NA | NA | NA | NA | NA | NA | NA | NA | NA | 0.00 (0.00, 0.00) | 0.00 (0.00, 0.00) | 0.00 (0.00, 0.00) |
| Example 5: meta-analysis on acute respiratory tract infection | |||||||||||||||
| OR | 0.83 (0.70, 0.95) | 0.82 (0.69, 0.95) | 0.81 (0.67, 0.95) | 0.82 (0.68, 0.95) | 0.82 (0.68, 0.95) | 0.82 (0.68, 0.95) | 0.82 (0.69, 0.95) | 0.82 (0.69, 0.95) | 0.82 (0.69, 0.95) | 0.83 (0.71, 0.95) | 0.83 (0.70, 0.95) | 0.82 (0.70, 0.95) | 0.83 (0.72, 0.95) | 0.83 (0.72, 0.95) | 0.83 (0.71, 0.95) |
| Tau | 0.21 (0.05, 0.41) | 0.23 (0.10, 0.43) | 0.29 (0.18, 0.48) | 0.25 (0.08, 0.46) | 0.25 (0.08, 0.45) | 0.25 (0.08, 0.46) | 0.23 (0.07, 0.41) | 0.25 (0.08, 0.45) | 0.25 (0.08, 0.45) | 0.19 (0.06, 0.36) | 0.22 (0.08, 0.40) | 0.24 (0.10, 0.42) | 0.21 (0.08, 0.47) | 0.21 (0.08, 0.47) | 0.23 (0.08, 0.47) |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Al Amer, F.M.; Thompson, C.G.; Lin, L. Bayesian Methods for Meta-Analyses of Binary Outcomes: Implementations, Examples, and Impact of Priors. Int. J. Environ. Res. Public Health 2021, 18, 3492. https://doi.org/10.3390/ijerph18073492
Al Amer FM, Thompson CG, Lin L. Bayesian Methods for Meta-Analyses of Binary Outcomes: Implementations, Examples, and Impact of Priors. International Journal of Environmental Research and Public Health. 2021; 18(7):3492. https://doi.org/10.3390/ijerph18073492
Chicago/Turabian StyleAl Amer, Fahad M., Christopher G. Thompson, and Lifeng Lin. 2021. "Bayesian Methods for Meta-Analyses of Binary Outcomes: Implementations, Examples, and Impact of Priors" International Journal of Environmental Research and Public Health 18, no. 7: 3492. https://doi.org/10.3390/ijerph18073492
APA StyleAl Amer, F. M., Thompson, C. G., & Lin, L. (2021). Bayesian Methods for Meta-Analyses of Binary Outcomes: Implementations, Examples, and Impact of Priors. International Journal of Environmental Research and Public Health, 18(7), 3492. https://doi.org/10.3390/ijerph18073492