



Occupational Injury Risk Mitigation: Machine Learning Approach and Feature Optimization for Smart Workplace Surveillance

 , , , , and
, , , , and
Abstract
:1. Introduction
- Firstly, most of the previous related studies focused only a type of industry, however, this study differs as we analyzed a large occupational injury dataset encompassing a wide range of industrial sectors. Incorporating industry-wide data on the severity of occupational injuries into the development of the proposed model may close the gap and enhance its generalizability.
- Secondly, the abovementioned related studies in Table 1 have utilized many input features in producing a prediction model with higher accuracy. Though, our study presented feature optimization techniques motivated by the ability of feature importance algorithms and hyperparameter optimization. We believed that the techniques may enhance the development of the prediction model by reducing the amount of data required for workplace injury prediction and classification.
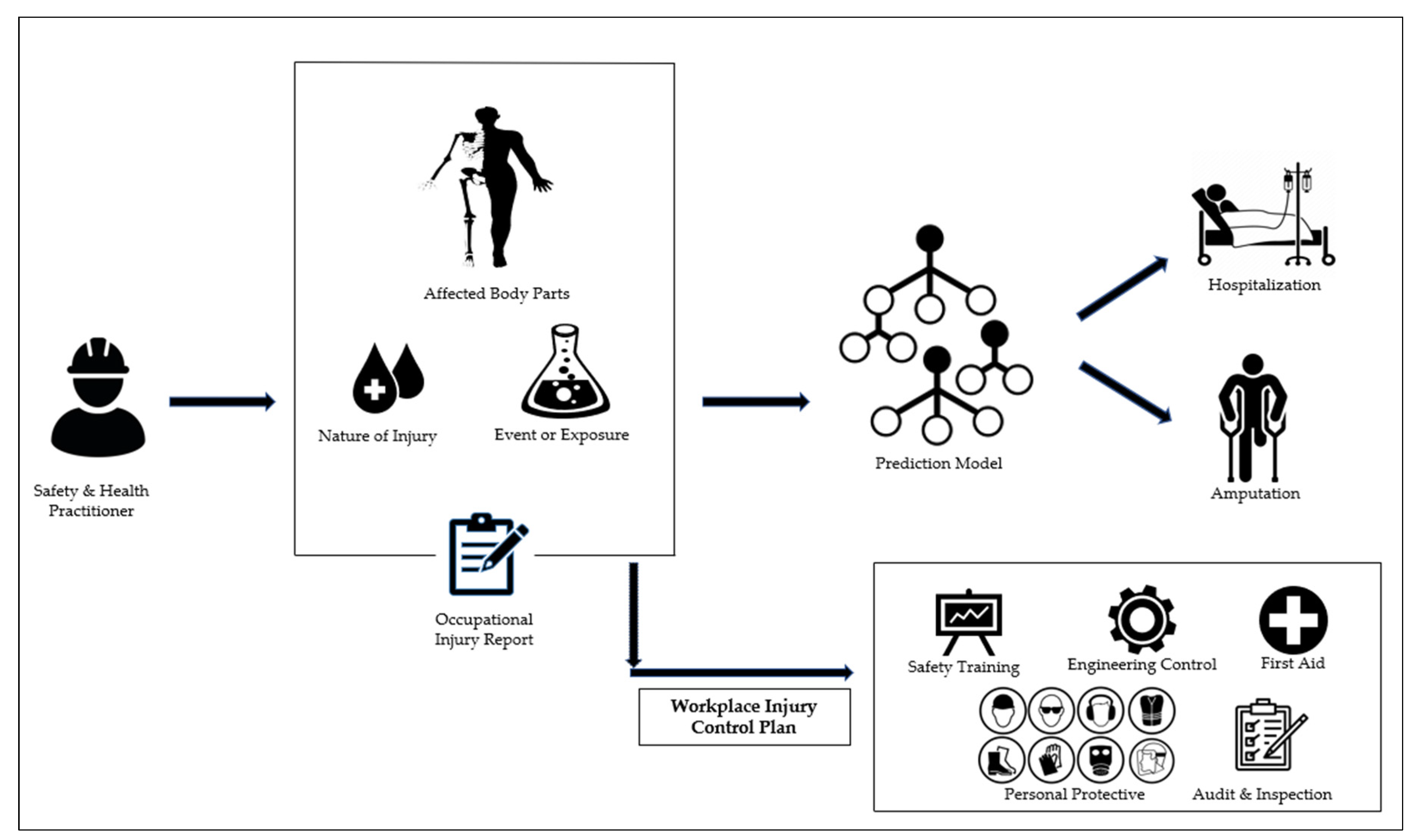
- Moreover, there are growing concerns from the previous research that emphasizes the development of predictive analytics to help safety and health practitioners in anticipating workplace accidents [27,28]. Therefore, this study’s findings will help the International Labour Organization (ILO) and other human-resource-related government sectors better comprehend the likelihood of workplace accidents and injuries, as well as in the planning of workplace injury prevention strategies by safety and health practitioners.
2. Materials and Methods
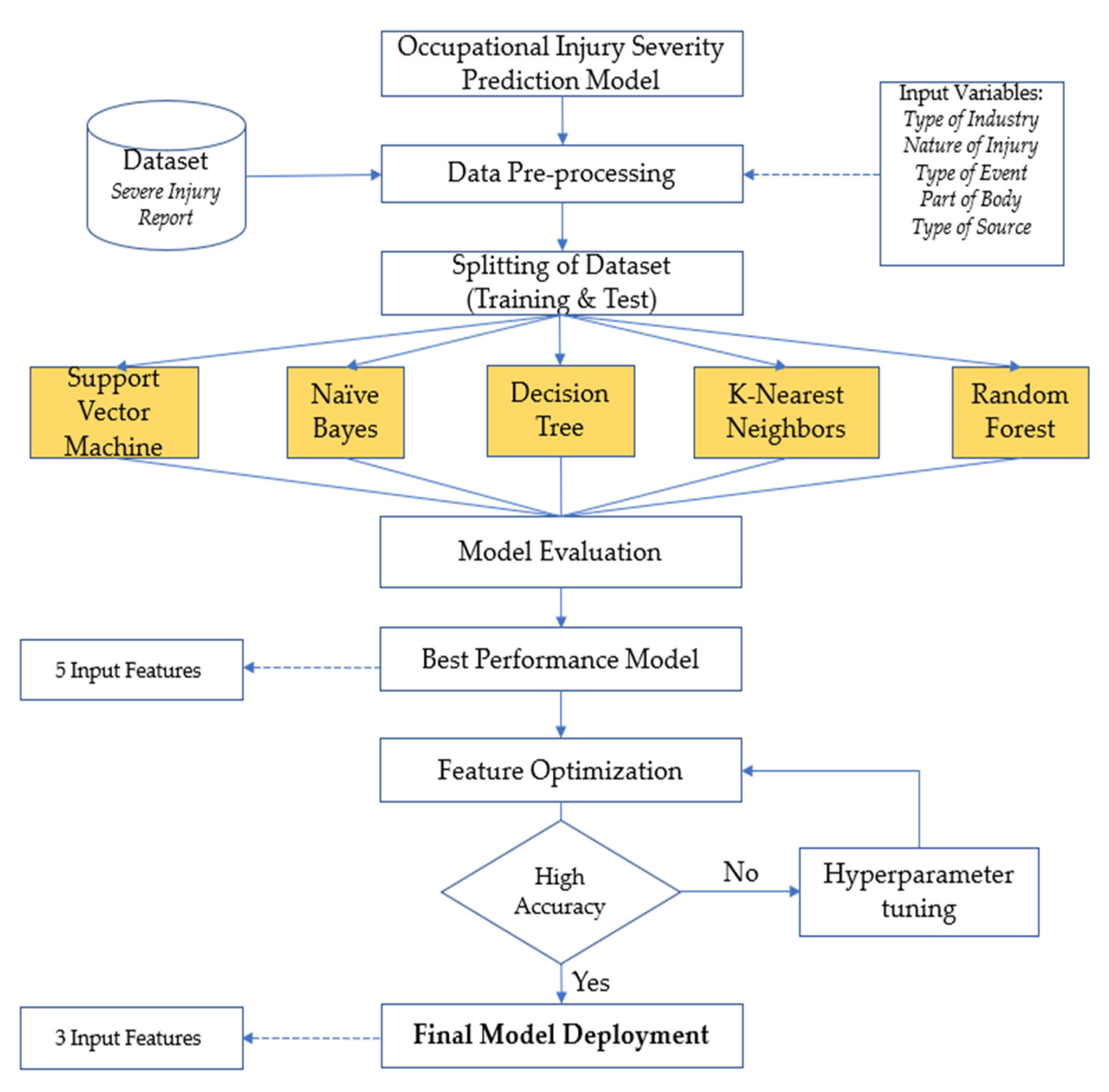
2.1. Dataset
2.2. Data Preparation
2.3. Data Pre-Processing
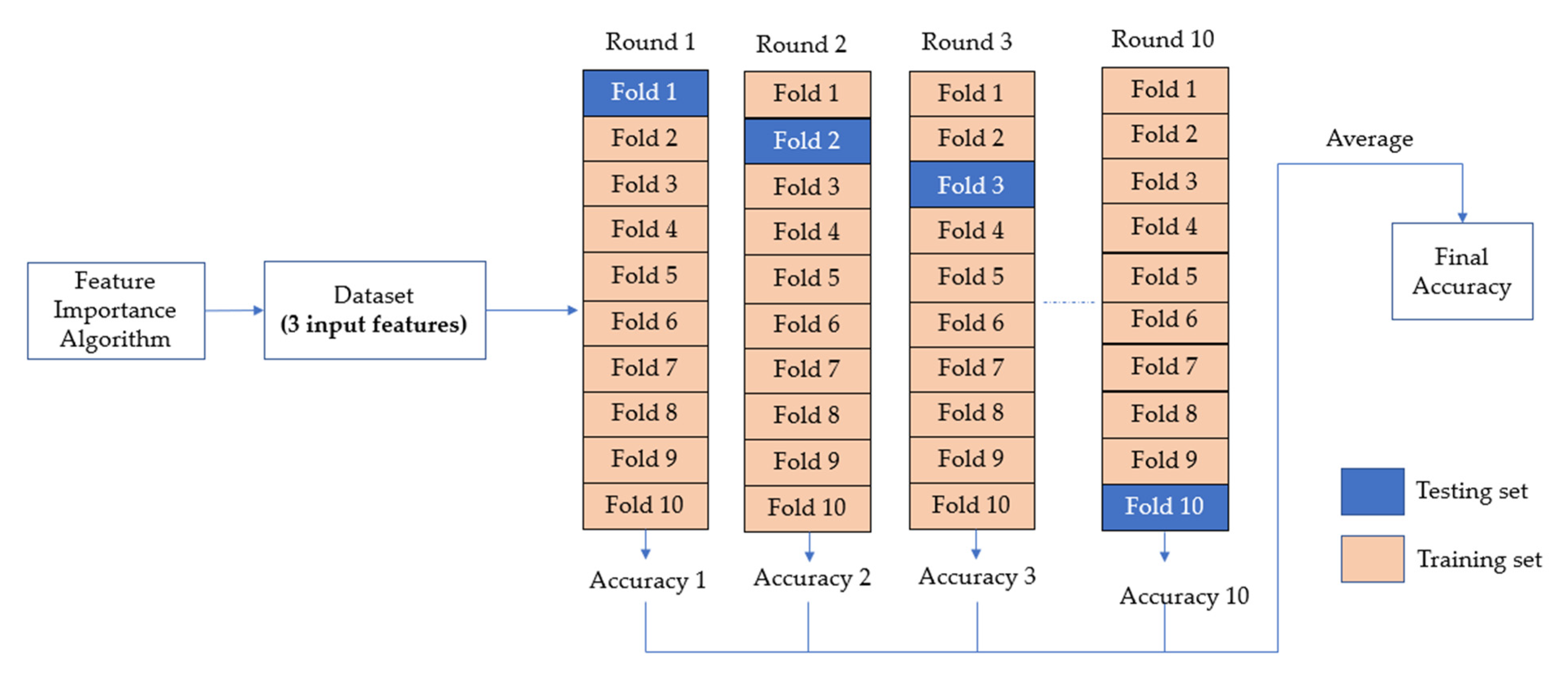
2.4. Data Splitting
2.5. Predictive Modeling
2.5.1. Support Vector Machine
2.5.2. Naïve Bayes
2.5.3. K-Nearest Neighbors
2.5.4. Decision Tree
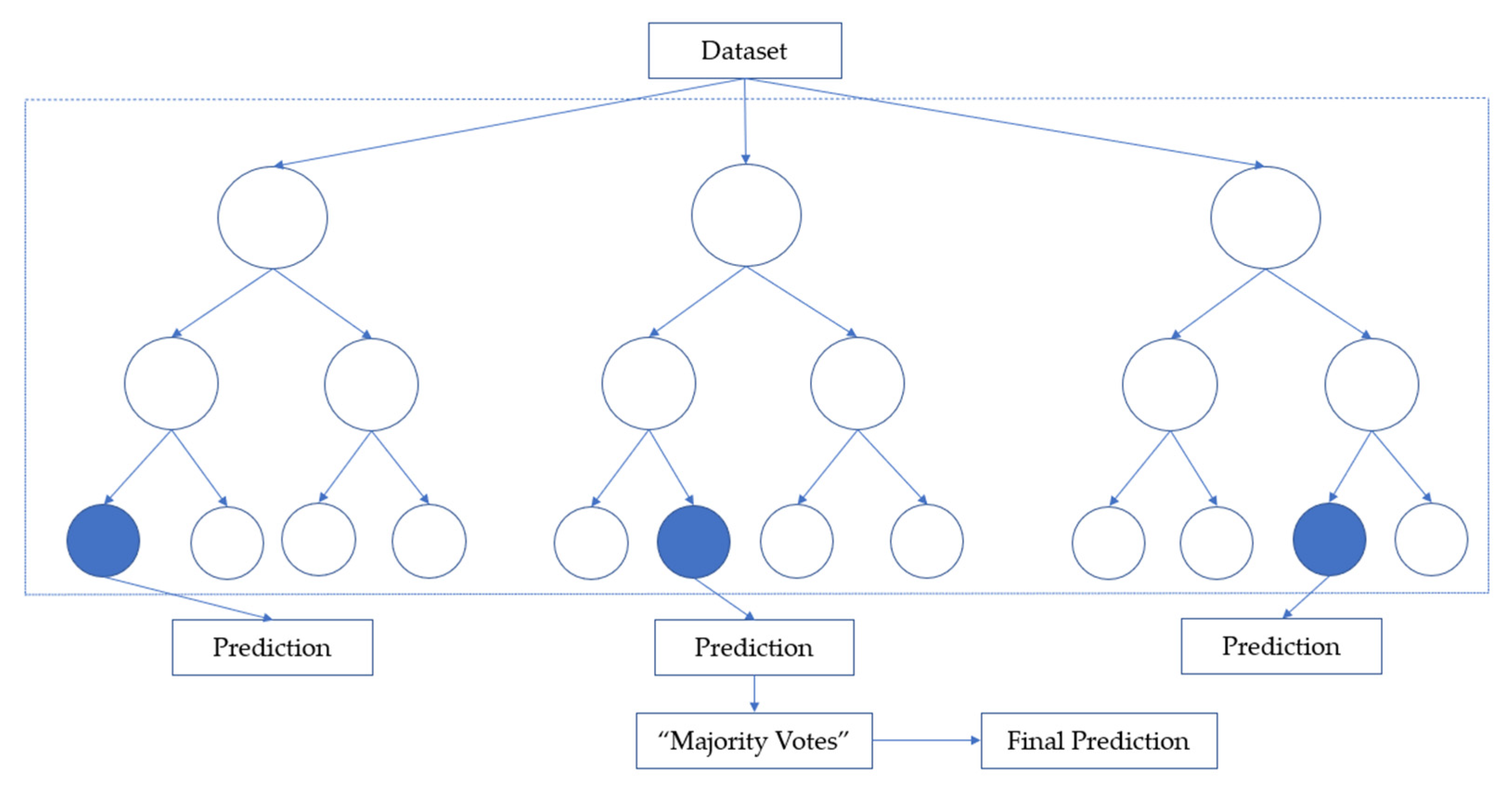
2.5.5. Random Forest
- Naïve Bayes: GaussianNB()
- Support Vector Machines: SVC (kernel = ‘rbf’, random_state = 0)
- Decision Tree: DecisionTreeClassifier (criterion = ‘entropy’, random_state = 0)
- K-Nearest Neighbors: KneighborsClassifier (n_neighbors = 5, metric = ‘minkowski’, p = 2)
- Random Forest: RandomForestClassifier (n_estimators = 50, criterion = ‘entropy’, random_state = 0)
- Numpy (np) is a package for scientific computing and it has time-efficient array processing capabilities [36].
- Pandas (pd) is an important and powerful tool for data writing, data reading, data analysis, and manipulation [37].
- Matplotlib (plt) is a visualization package in python. It helps to create interactive figures and informative visualization of data.
- Sklearn is a robust library for machine learning, especially on predictive analysis. It provides various tools including classification, preprocessing, clustering, regression, and dimensionally reduction. These machine learning algorithms were developed in the Sklearn of Python libraries.
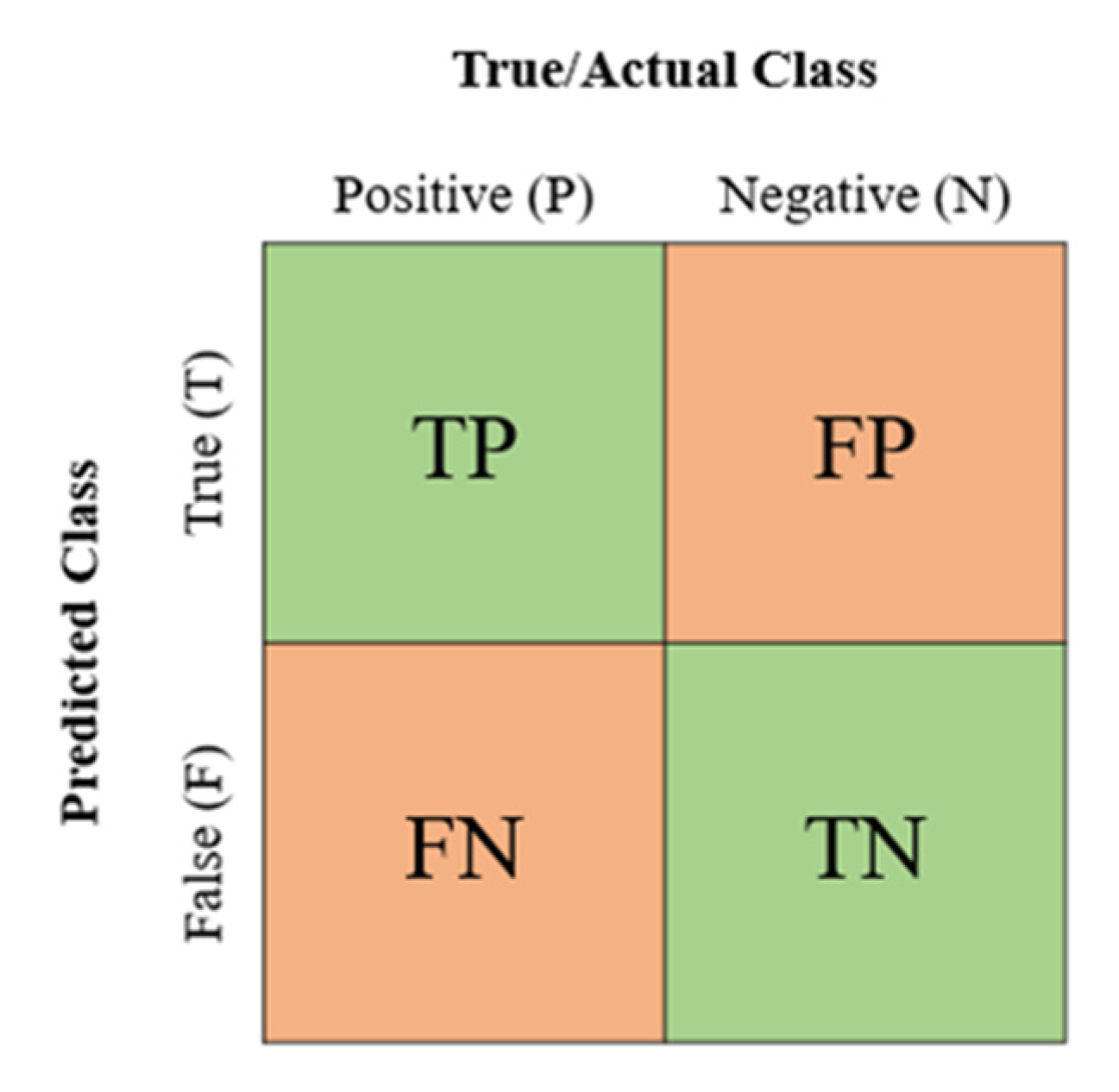
2.6. Machine Learning Models Evaluation
- (TP) is the positive instances of injured workers that are actually hospitalized and correctly predicted as hospitalized.
- (FP) is the negative instances of injured workers that are un-hospitalized but wrongly predicted as hospitalized.
- (FN) is the positive instances of injured workers that are hospitalized but wrongly predicted as un-hospitalized.
- (TN) is the negative instances of injured workers that are actually un-hospitalized and also, correctly predicted as un-hospitalized.

Performance Metrics
- Accuracy is measuring the fraction of the total samples correctly classified. It is expressed as “(TP + TN)/(TP + TN + FP + FN)”. For example, it is a ratio of correctly classified injured workers and hospitalized (TP + TN) to the total number of injured workers.
- Precision is the proportion of correctly classified injured workers and hospitalized to the total workers predicted to be hospitalized. It is calculated by “(TP)/(TP + FP)”.
- Recall or sensitivity is known as measuring the fraction of all positive samples that are correctly predicted as positive and expressed as “(TP)/(TP + FN)”. In this study, it is a ratio of the correctly classified injured workers and hospitalized divided by the total number of injured workers and hospitalized.
- F1-score is the “harmonic mean” of precision and recall. It is obtained by combining precision and recall into a single measure and expressed as:
- Receiver Operator Characteristic (ROC) is extensively used to provide illustrative information on the performance of the ML algorithms. It contains information on a series of thresholds and is summarized in a single value by the ‘Area Under the Curve’ (AUC)
2.7. Feature Optimization
3. Results
3.1. Performance Prediction
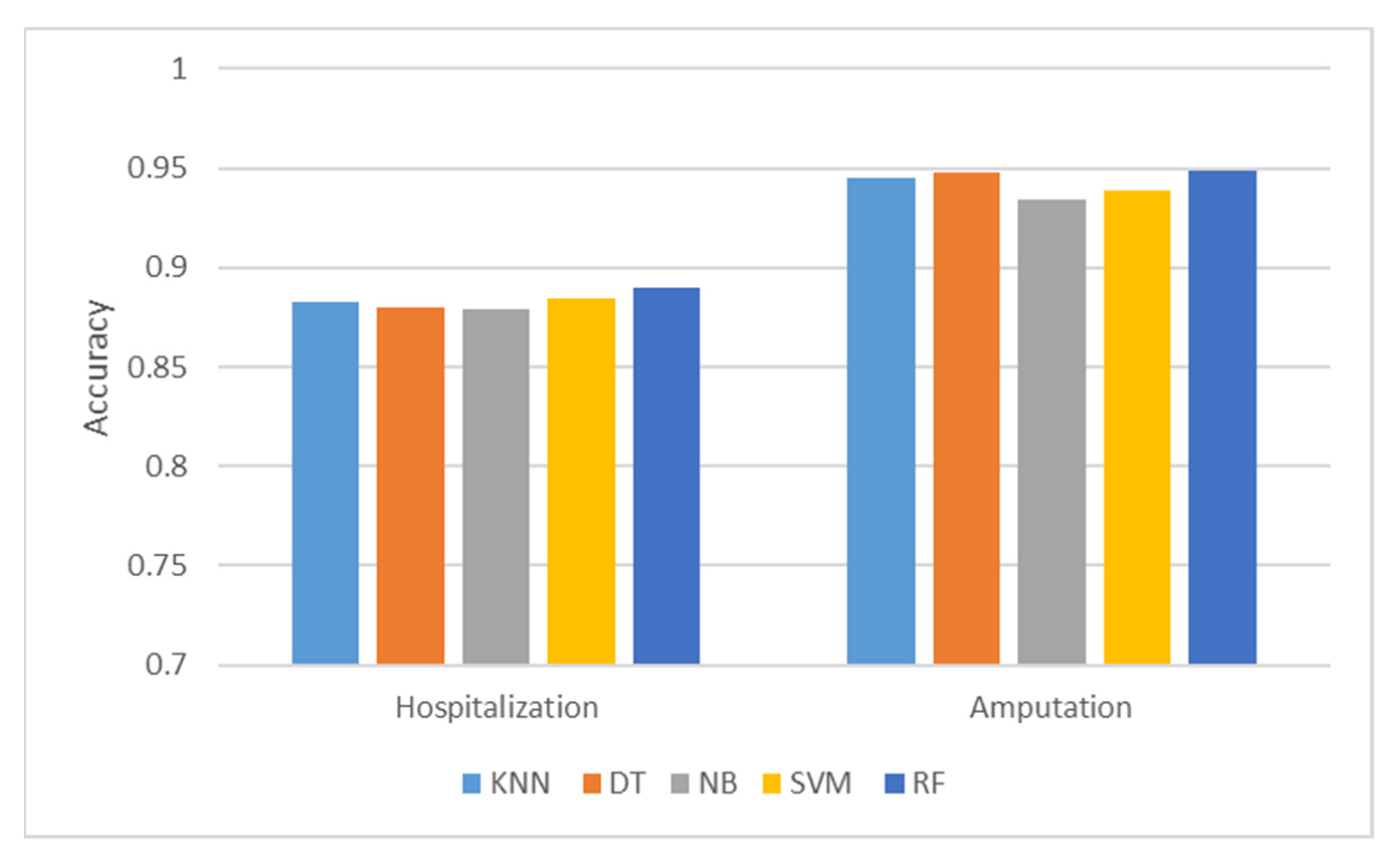
3.1.1. Hospitalization
3.1.2. Amputation
3.2. Performance Comparison
3.3. Feature Optimization
- (1)
- The individual nodes’ importance per tree is calculated using the formula in Equation (4), where importance of node j, = weighted samples reaching node j and = impurity value of the node.
- (2)
- After the nodes’ importance is calculated, the feature importance per tree is determined through Equation (5).
- (3)
- The calculation is normalized as per Equation (6) to a value from 0 to +1.
- (4)
- The calculation from (3) is averaged across the entire forest and divided by total trees by using Equation (7).
- (5)
- The final value is arranged in descending order, in which the most important feature appears in the first rank. The higher the value, the more important the feature.
4. Discussion
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- International Labour Organization. Safety and Health at The Heart of the Future of Work Building on 100 Years of Experience; International Labour Organization: Geneva, Switzerland, 2019. [Google Scholar]
- Hämäläinen, P.; Takala, J.; Tan, B.K. Global Estimates of Occupational Accidents and Work-Related Illnesses 2017; Workplace Safety and Health: Singapore, 2017. [Google Scholar]
- Sarkar, S.; Maiti, J. Machine learning in occupational accident analysis: A review using science mapping approach with citation network analysis. Saf. Sci. 2020, 131, 104900. [Google Scholar] [CrossRef]
- Oyedele, A.O.; Ajayi, A.O.; Oyedele, L.O. Machine learning predictions for lost time injuries in power transmission and distribution projects. Mach. Learn. Appl. 2021, 6, 100158. [Google Scholar] [CrossRef]
- Matías, J.M.; Rivas, T.; Martín, J.E.; Taboada, J. A machine learning methodology for the analysis of workplace accidents. Int. J. Comput. Math. 2008, 85, 559–578. [Google Scholar] [CrossRef]
- Esmaeili, B.; Hallowell, M.R.; Rajagopalan, B. Attribute-Based Safety Risk Assessment. II: Predicting Safety Outcomes Using Generalized Linear Models. J. Constr. Eng. Manag. 2015, 141, 04015022. [Google Scholar] [CrossRef]
- Cheng, C.-W.; Leu, S.-S.; Cheng, Y.-M.; Wu, T.-C.; Lin, C.-C. Applying data mining techniques to explore factors contributing to occupational injuries in Taiwan’s construction industry. Accid. Anal. Prev. 2012, 48, 214–222. [Google Scholar] [CrossRef]
- Papazoglou, I.; Aneziris, O.; Bellamy, L.; Ale, B.; Oh, J. Quantitative occupational risk model: Single hazard. Reliab. Eng. Syst. Saf. 2017, 160, 162–173. [Google Scholar] [CrossRef]
- Uddin, S.; Khan, A.; Hossain, E.; Moni, M.A. Comparing different supervised machine learning algorithms for disease prediction. BMC Med. Inform. Decis. Mak. 2019, 19, 281. [Google Scholar] [CrossRef]
- Dahiwade, D.; Patle, G.; Meshram, E. Designing Disease Prediction Model Using Machine Learning Approach. In Proceedings of the 2019 3rd International Conference on Computing Methodologies and Communication (ICCMC), Erode, India, 27–29 March 2019. [Google Scholar]
- Yeoh, P.S.Q.; Lai, K.W.; Goh, S.L.; Hasikin, K.; Hum, Y.C.; Tee, Y.K.; Dhanalakshmi, S. Emergence of Deep Learning in Knee Osteoarthritis Diagnosis. Comput. Intell. Neurosci. 2021, 2021, 4931437. [Google Scholar] [CrossRef]
- You, S.; Lei, B.; Wang, S.; Chui, C.K.; Cheung, A.C.; Liu, Y.; Gan, M.; Wu, G.; Shen, Y. Fine Perceptive GANs for Brain MR Image Super-Resolution in Wavelet Domain. IEEE Trans. Neural Netw. Learn. Syst. 2022, 1–13. [Google Scholar] [CrossRef]
- Oyedele, A.; Ajayi, A.; Oyedele, L.O.; Delgado, J.M.D.; Akanbi, L.; Akinade, O.; Owolabi, H.; Bilal, M. Deep learning and Boosted trees for injuries prediction in power infrastructure projects. Appl. Soft Comput. 2021, 110, 107587. [Google Scholar] [CrossRef]
- Sarkar, S.; Vinay, S.; Raj, R.; Maiti, J.; Mitra, P. Application of optimized machine learning techniques for prediction of occupational accidents. Comput. Oper. Res. 2019, 106, 210–224. [Google Scholar] [CrossRef]
- Abbasianjahromi, H.; Aghakarimi, M. Safety performance prediction and modification strategies for construction projects via machine learning techniques. Eng. Constr. Arch. Manag. 2021. ahead of print. [Google Scholar] [CrossRef]
- Varghese, B.M.; Hansen, A.; Bi, P.; Pisaniello, D. Are workers at risk of occupational injuries due to heat exposure? A comprehensive literature review. Saf. Sci. 2018, 110, 380–392. [Google Scholar] [CrossRef]
- Noman, M.; Mujahid, N.; Fatima, A. The Assessment of Occupational Injuries of Workers in Pakistan. Saf. Health Work 2021, 12, 452–461. [Google Scholar] [CrossRef]
- Choi, J.; Gu, B.; Chin, S.; Lee, J.-S. Machine learning predictive model based on national data for fatal accidents of construction workers. Autom. Constr. 2020, 110, 102974. [Google Scholar] [CrossRef]
- Lee, J.; Yoon, Y.; Oh, T.; Park, S.; Ryu, S. A Study on Data Pre-Processing and Accident Prediction Modelling for Occupational Accident Analysis in the Construction Industry. Appl. Sci. 2020, 10, 7949. [Google Scholar] [CrossRef]
- Yedla, A.; Kakhki, F.D.; Jannesari, A. Predictive Modeling for Occupational Safety Outcomes and Days Away from Work Analysis in Mining Operations. Int. J. Environ. Res. Public Health 2020, 17, 7054. [Google Scholar] [CrossRef]
- Sukumar, D.; Zhang, J.; Tao, X.; Wang, X.; Zhang, W. Predicting Workplace Injuries Using Machine Learning Algorithms. In Proceedings of the 2020 IEEE 7th International Conference on Data Science and Advanced Analytics (DSAA), Sydney, Australia, 6–9 October 2020. [Google Scholar]
- Zhu, R.; Hu, X.; Hou, J.; Li, X. Application of machine learning techniques for predicting the consequences of construction accidents in China. Process Saf. Environ. Prot. 2021, 145, 293–302. [Google Scholar] [CrossRef]
- Scott, E.; Hirabayashi, L.; Levenstein, A.; Krupa, N.; Jenkins, P. The development of a machine learning algorithm to identify occupational injuries in agriculture using pre-hospital care reports. Heal. Inf. Sci. Syst. 2021, 9, 31. [Google Scholar] [CrossRef] [PubMed]
- Zhong, B.; Pan, X.; Love, P.E.; Ding, L.; Fang, W. Deep learning and network analysis: Classifying and visualizing accident narratives in construction. Autom. Constr. 2020, 113, 103089. [Google Scholar] [CrossRef]
- Tixier, A.J.-P.; Hallowell, M.R.; Rajagopalan, B.; Bowman, D. Application of machine learning to construction injury prediction. Autom. Constr. 2016, 69, 102–114. [Google Scholar] [CrossRef] [Green Version]
- Nanda, G.; Grattan, K.M.; Chu, M.T.; Davis, L.K.; Lehto, M.R. Bayesian decision support for coding occupational injury data. J. Saf. Res. 2016, 57, 71–82. [Google Scholar] [CrossRef]
- Gallego, V.; Sánchez, A.; Martón, I.; Martorell, S. Analysis of occupational accidents in Spain using shrinkage regression methods. Saf. Sci. 2021, 133, 105000. [Google Scholar] [CrossRef]
- Shirali, G.A.; Noroozi, M.V.; Malehi, A.S. Predicting the Outcome of Occupational Accidents by Cart and Chaid Methods at a Steel Factory in Iran. J. Public Health Res. 2018, 7, 1361. [Google Scholar] [CrossRef] [Green Version]
- Goldberg, D.M. Characterizing accident narratives with word embeddings: Improving accuracy, richness, and generalizability. J. Saf. Res. 2022, 80, 441–455. [Google Scholar] [CrossRef]
- Nguyen, Q.H.; Ly, H.-B.; Ho, L.S.; Al-Ansari, N.; Van Le, H.; Tran, V.Q.; Prakash, I.; Pham, B.T. Influence of Data Splitting on Performance of Machine Learning Models in Prediction of Shear Strength of Soil. Math. Probl. Eng. 2021, 2021, 4832864. [Google Scholar] [CrossRef]
- Kakhki, F.D.; Freeman, S.A.; Mosher, G. Evaluating machine learning performance in predicting injury severity in agribusiness industries. Saf. Sci. 2019, 117, 257–262. [Google Scholar] [CrossRef]
- Merembayev, T.; Kurmangaliyev, D.; Bekbauov, B.; Amanbek, Y. A Comparison of Machine Learning Algorithms in Predicting Lithofacies: Case Studies from Norway and Kazakhstan. Energies 2021, 14, 1896. [Google Scholar] [CrossRef]
- Misra, S.; Li, H. Chapter 9–Noninvasive fracture characterization based on the classification of sonic wave travel times. In Machine Learning for Subsurface Characterization; Misra, S., Li, H., He, J., Eds.; Gulf Professional Publishing: Houston, TX, USA, 2020; pp. 243–287. [Google Scholar]
- Rivas, T.; Paz, M.; Martín, J.; Matías, J.; García, J.; Taboada, J. Explaining and predicting workplace accidents using data-mining techniques. Reliab. Eng. Syst. Saf. 2011, 96, 739–747. [Google Scholar] [CrossRef]
- Breiman, L.; Friedman, J.H.; Olshen, R.A.; Stone, C.J. Classification and Regression Trees; Routledge: Oxfordshire, UK, 2017. [Google Scholar]
- McKinney, W. Python for Data Analysis: Data Wrangling with Pandas, NumPy, and IPython; O’Reilly Media: Newton, MA, USA, 2012. [Google Scholar]
- McKinney, W. P.D. Team. Pandas—Powerful Python Data Analysis Toolkit; p. 1625. 2015. Available online: https://pandas.pydata.org/pandas-docs/version/0.7.3/pandas.pdf (accessed on 25 July 2022).
- Jung, Y.; Hu, J. A K-fold Averaging Cross-validation Procedure. J. Nonparametric Stat. 2015, 27, 167–179. [Google Scholar] [CrossRef]
- James, G.; Witten, D.; Hastie, T.; Tibshirani, R. Resampling Methods. In An Introduction to Statistical Learning; Springer: New York, NY, USA, 2013; pp. 175–201. [Google Scholar]
- Kuhn, M.; Johnson, K. Data pre-processing. In Applied Predictive Modeling; Springer Science Business Media: New York, NY, USA, 2013; pp. 27–59. [Google Scholar]
- Daskalaki, S.; Kopanas, I.; Avouris, N. Evaluation of classifiers for an uneven class distribution problem. Appl. Artif. Intell. 2006, 20, 381–417. [Google Scholar] [CrossRef]
- Demšar, J. Statistical Comparisons of Classifiers over Multiple Data Sets. J. Mach. Learn. Res. 2006, 7, 1–30. [Google Scholar]
- Saito, T.; Rehmsmeier, M. The Precision-Recall Plot Is More Informative than the ROC Plot When Evaluating Binary Classifiers on Imbalanced Datasets. PLoS ONE 2015, 10, e0118432. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Moore, P.J.; Lyons, T.J.; Gallacher, J. Random forest prediction of Alzheimer’s disease using pairwise selection from time series data. PLoS ONE 2019, 14, e0211558. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Raman, P.; Kannan, N.; Kumar, S.; Raunak, K. Analysis and Prediction of Industrial Accidents Using Machine Learning. Int. J. Adv. Sci. Technol. 2020, 29, 4990–5000. [Google Scholar]
- Kang, K.; Ryu, H. Predicting types of occupational accidents at construction sites in Korea using random forest model. Saf. Sci. 2019, 120, 226–236. [Google Scholar] [CrossRef]
- Sarkar, S.; Pateshwari, V.; Maiti, J. Predictive model for incident occurrences in steel plant in India. In Proceedings of the 2017 8th International Conference on Computing, Communication and Networking Technologies (ICCCNT), Delhi, India, 3–7 July 2017; pp. 1–5. [Google Scholar] [CrossRef]
- Chadyiwa, M.; Kagura, J.; Stewart, A. Investigating Machine Learning Applications in the Prediction of Occupational Injuries in South African National Parks. Mach. Learn. Knowl. Extr. 2022, 4, 768–778. [Google Scholar] [CrossRef]
- Sarkar, S.; Raj, R.; Vinay, S.; Maiti, J.; Pratihar, D.K. An optimization-based decision tree approach for predicting slip-trip-fall accidents at work. Saf. Sci. 2019, 118, 57–69. [Google Scholar] [CrossRef]
- Saarela, M.; Jauhiainen, S. Comparison of feature importance measures as explanations for classification models. SN Appl. Sci. 2021, 3, 272. [Google Scholar] [CrossRef]
- Yang, C.; Delcher, C.; Shenkman, E.; Ranka, S. Predicting 30-day all-cause readmissions from hospital inpatient discharge data. In Proceedings of the 2016 IEEE 18th International Conference on e-Health Networking, Applications and Services (Healthcom), Munich, Germany, 14–16 September 2016; pp. 1–6. [Google Scholar]
- Tjoa, E.; Guan, C. A Survey on Explainable Artificial Intelligence (XAI): Toward Medical XAI. IEEE Trans. Neural Netw. Learn. Syst. 2021, 32, 4793–4813. [Google Scholar] [CrossRef]
- Chowdhury, M.Z.I.; Turin, T.C. Variable selection strategies and its importance in clinical prediction modelling. Fam. Med. Community Health 2020, 8, e000262. [Google Scholar] [CrossRef]
- Steyerberg, E. Clinical Prediction Models: A Practical Approach to Development, Validation, and Updating; Springer: Berlin/Heidelberg, Germany, 2009; Volume 19. [Google Scholar]
- Amal, S.; Safarnejad, L.; Omiye, J.A.; Ghanzouri, I.; Cabot, J.H.; Ross, E.G. Use of Multi-Modal Data and Machine Learning to Improve Cardiovascular Disease Care. Front. Cardiovasc. Med. 2022, 9, 840262. [Google Scholar] [CrossRef]
- Wang, S.; Wang, X.; Hu, Y.; Shen, Y.; Yang, Z.; Gan, M.; Lei, B. Diabetic Retinopathy Diagnosis Using Multichannel Generative Adversarial Network with Semisupervision. IEEE Trans. Autom. Sci. Eng. 2021, 18, 574–585. [Google Scholar] [CrossRef]
- Kadri, F.; Dairi, A.; Harrou, F.; Sun, Y. Towards accurate prediction of patient length of stay at emergency department: A GAN-driven deep learning framework. J. Ambient Intell. Humaniz. Comput. 2022, 1–15. [Google Scholar] [CrossRef]







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| References. | Industry | Input Variables | ML Models | Findings |
|---|---|---|---|---|
| [18] | Construction | Age, sex, length of service, the type of construction, employer scale, and accident date. | LR, DT, RF, AdaBoost | RF is the best prediction model with the highest accuracy. |
| [19] | Construction | Year, type of work, type of accident, injured part, assailing materials, and cause of the accident. | SVM, Ensemble, PCA | SVM outperformed other models with higher accuracy in injury severity prediction. |
| [20] | Mining | Sub-unit, classification, accident type, occupation, activity, injury source, nature of the injury, injured body part. | DT, RF, ANN | ANN performed better than all other models. |
| [21] | Construction | 15 variables: construction end use, event type, part of the body, cause of the accident (human and environment), and assigned tasks. | KNN, DT, RF | DT outperformed the other techniques with better sensitivity, recall, precision, and F1 score. |
| [22] | Construction | 16 variables such as organization and behavior, technical management, resources support, management of the contract, safety training, and emergency management. | LR, DT, SVM, NB, KNN, RF, MLP, AutoML | NB and LR achieved good performance in F1-Score and AutoML is the best model to predict the severity of occupational injuries. |
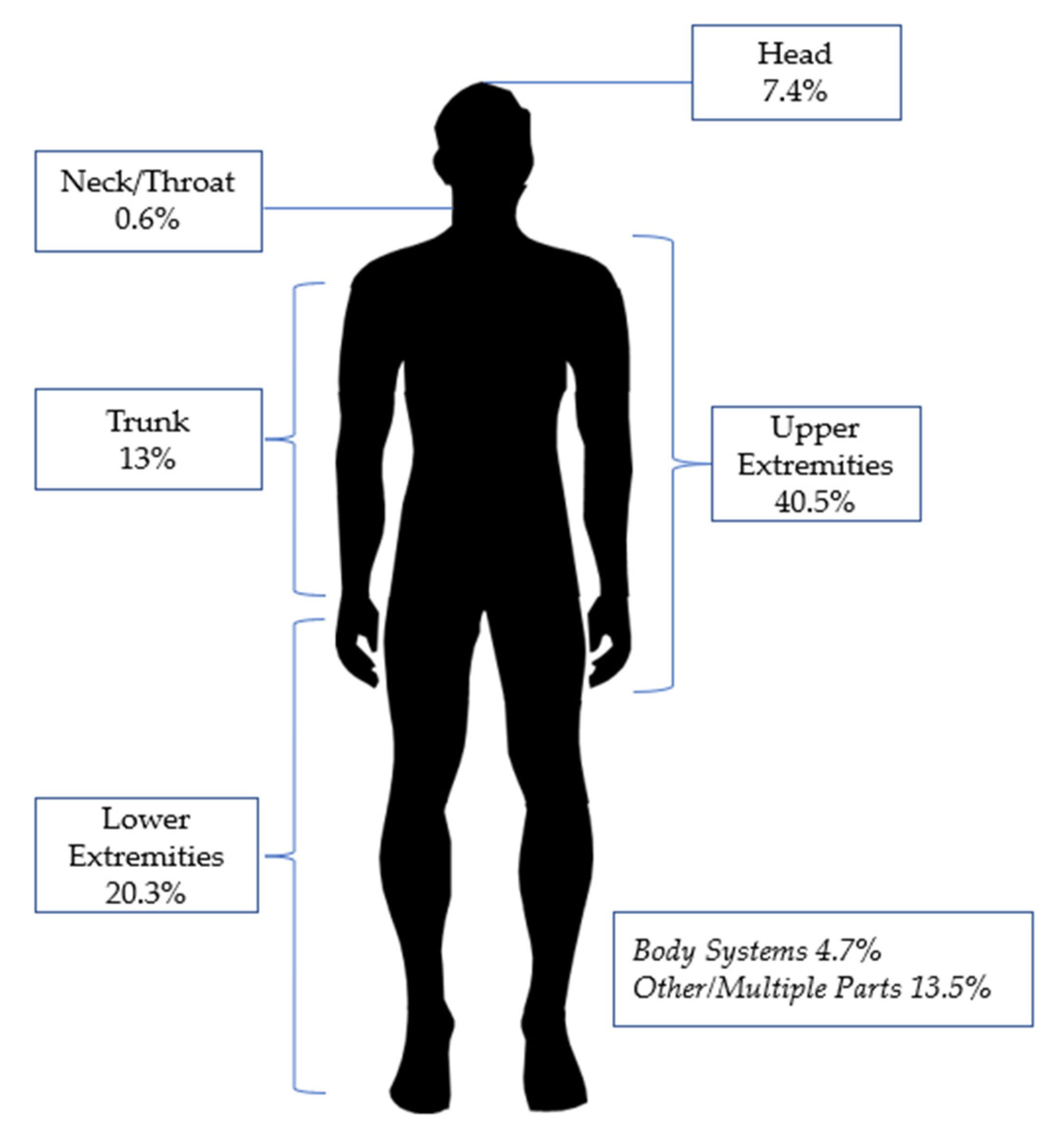
| Variables | Categories | Distributions |
|---|---|---|
| Nature of Injury | N10 Traumatic injuries and disorders | 2.3% |
| N11 Traumatic injuries to bones, nerves, spinal cord | 31.9% | |
| N12 Traumatic injuries to muscles, tendons, ligaments, joints | 1.8% | |
| N13 Open wounds | 34.2% | |
| N14 Surface wounds and bruises | 1.1% | |
| N15 Burns and corrosions | 5.4% | |
| N16 Intracranial injuries | 3.6% | |
| N17 Effects of environmental conditions | 2.6% | |
| N18 Multiple traumatic injuries and disorders | 3.1% | |
| N19 Other traumatic injuries and disorders | 14% | |
| Type of Event | E01 Violence/other injuries by persons or animals | 2.2% |
| E02 Transportation incidents | 8.5% | |
| E03 Fires and explosions | 1.8% | |
| E04 Falls, slips, trips | 30.4% | |
| E05 Exposure to harmful substances or environments | 8.3% | |
| E06 Contact with objects and equipment | 46.3% | |
| E07 Overexertion and bodily reaction | 1.5% | |
| E09 Other(s) | 1% | |
| Source of Injury | S01 Chemicals and chemical products | 2.8% |
| S02 Containers, furniture, and fixtures | 4.4% | |
| S03 Machinery | 25.5% | |
| S04 Parts and materials | 11.1% | |
| S05 Persons, plants, animals, and minerals | 4.3% | |
| S06 Structures and surfaces | 20.7% | |
| S07 Tools, instruments, and equipment | 8.9% | |
| S08 Vehicles | 14.1% | |
| S09 Other(s) | 8.2% | |
| Type of Industry | I11 Agriculture, Forestry, Fishing and Hunting | 1.8% |
| I21 Mining | 2.9% | |
| I22 Utilities | 1.3% | |
| I23 Construction | 18% | |
| I31 Manufacturing | 33% | |
| I42 Wholesale trade | 5.6% | |
| I44 Retail trade | 7.4% | |
| I48 Transportation and Warehousing | 8.8% | |
| I51 Information | 1% | |
| I52 Finance and Insurance | 0.3% | |
| I53 Real Estate Rental and Leasing | 1% | |
| I54 Professional, Scientific, and Technical Services | 1.6% | |
| I55 Management of Companies and Enterprises | 0.1% | |
| I56 Administrative/Waste Management and Remediation | 5.6% | |
| I61 Educational Services | 0.5% | |
| I62 Health Care and Social Assistance | 4.7% | |
| I71 Arts, Entertainment and Recreation | 1.3% | |
| I72 Accommodation and Food Services | 2% | |
| I81 Other Services | 1.9% | |
| I92 Public Administration | 1.2% | |
| Hospitalization | H1 Yes | 80.6% |
| H0 No | 19.4% | |
| Amputation | A1 Yes | 26.4% |
| A0 No | 73.6% |
| ML Models | Accuracy | Precision | Recall | F1-score | AUC |
|---|---|---|---|---|---|
| KNN | 0.883 | 0.957 | 0.895 | 0.925 | 0.86 |
| DT | 0.880 | 0.980 | 0.881 | 0.928 | 0.90 |
| NB | 0.879 | 0.985 | 0.862 | 0.920 | 0.91 |
| SVM | 0.884 | 0.984 | 0.870 | 0.924 | 0.91 |
| RF | 0.890 | 0.978 | 0.883 | 0.928 | 0.90 |
| ML Models | Accuracy | Precision | Recall | F1-Score | AUC |
|---|---|---|---|---|---|
| KNN | 0.945 | 0.869 | 0.948 | 0.902 | 0.95 |
| DT | 0.948 | 0.861 | 0.959 | 0.907 | 0.95 |
| NB | 0.934 | 0.831 | 0.942 | 0.883 | 0.94 |
| SVM | 0.939 | 0.831 | 0.967 | 0.894 | 0.95 |
| RF | 0.949 | 0.860 | 0.963 | 0.909 | 0.95 |
| Feature | Importance Value | Description |
|---|---|---|
| Nature of Injury | 0.406367 | Identifies the main physical characteristic(s) of the occupational injury. |
| Type of Event | 0.254030 | Identifies how the occupational injury was produced. |
| Affected Body Part(s) | 0.243115 | Identifies the part of the body affected by the nature of the occupational injury. |
| Source of Injury | 0.064195 | Identifies the workplace factors such as objects, substances, equipment, and other external factors that were responsible for the occupational injury. |
| Type of Industry | 0.032293 | Identifies the nature of the organization, company, or enterprise |
| Prediction | Criteria | Value |
|---|---|---|
| Hospitalization | Mean | 0.893 |
| SD | 0.0029 | |
| Amputation | Mean | 0.949 |
| SD | 0.0028 |
| Prediction | Criteria | Value |
|---|---|---|
| Hospitalization | Overall Accuracy | 0.895 |
| Amputation | 0.954 | |
| Hospitalization Amputation | Optimized Parameters | ‘n_estimators’: 1200, |
| ‘min_samples_split’: 15, | ||
| ‘min_samples_leaf’: 10, | ||
| ‘max_features’: ‘sqrt’, | ||
| ‘max_depth’: 15 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Khairuddin, M.Z.F.; Lu Hui, P.; Hasikin, K.; Abd Razak, N.A.; Lai, K.W.; Mohd Saudi, A.S.; Ibrahim, S.S. Occupational Injury Risk Mitigation: Machine Learning Approach and Feature Optimization for Smart Workplace Surveillance. Int. J. Environ. Res. Public Health 2022, 19, 13962. https://doi.org/10.3390/ijerph192113962
Khairuddin MZF, Lu Hui P, Hasikin K, Abd Razak NA, Lai KW, Mohd Saudi AS, Ibrahim SS. Occupational Injury Risk Mitigation: Machine Learning Approach and Feature Optimization for Smart Workplace Surveillance. International Journal of Environmental Research and Public Health. 2022; 19(21):13962. https://doi.org/10.3390/ijerph192113962
Chicago/Turabian StyleKhairuddin, Mohamed Zul Fadhli, Puat Lu Hui, Khairunnisa Hasikin, Nasrul Anuar Abd Razak, Khin Wee Lai, Ahmad Shakir Mohd Saudi, and Siti Salwa Ibrahim. 2022. "Occupational Injury Risk Mitigation: Machine Learning Approach and Feature Optimization for Smart Workplace Surveillance" International Journal of Environmental Research and Public Health 19, no. 21: 13962. https://doi.org/10.3390/ijerph192113962
APA StyleKhairuddin, M. Z. F., Lu Hui, P., Hasikin, K., Abd Razak, N. A., Lai, K. W., Mohd Saudi, A. S., & Ibrahim, S. S. (2022). Occupational Injury Risk Mitigation: Machine Learning Approach and Feature Optimization for Smart Workplace Surveillance. International Journal of Environmental Research and Public Health, 19(21), 13962. https://doi.org/10.3390/ijerph192113962