The aim of this paper is to calculate the optimal retention levels by considering the survival probability, expected profit, variance and expected shortfall criteria from the insurer’s point of view. We show how these criteria are calculated under the excess of loss reinsurance arrangement.
2.1. The Exact Finite Time Ruin Probability
The surplus process (insurer’s risk process) comprises three main components: the initial capital
u, the premium income per unit of time and the aggregate claim amount up to time
t, denoted by
. Premium income is assumed as payable with a constant rate
c per unit of time. The insurer’s surplus (or risk) process,
, is defined by:
The aggregate claim amount up to time
t,
, is:
where
denotes the number of claims that occur in the fixed time interval
. The individual claim amounts, modeled as independent and identically distributed (i.i.d.) random variables
with distribution function
, such that
and
is the amount of the
i-th claim. We use notations
f and
to represent the density function and
k-th moment of
, respectively, and it is assumed that
.
The ruin probability in finite time,
, is given by:
where
is the probability that the insurer’s surplus falls below zero in the finite time interval
.
In the classical risk model, the number of claims has a Poisson distribution with rate λ, so that the aggregate claims have a compound Poisson process with Poisson parameter λ, and the individual claim amounts are exponentially distributed with distribution function . For a fixed value of , the random variable has a compound Poisson distribution with Poisson parameter .
In practice,
, where
t is the planning horizon of the company, is more interesting than the infinite time ruin probability. The finite time ruin probability enables the insurance company to develop the risk business or increase the premium if the risk business behaves badly. Especially in non-life insurance, four of five years of finite time planning is reasonable [
13]. Especially, the finite time ruin probability may become useful and significant for the operation risk of the insurance company when the real data are available.
The finite time ruin probability can be calculated analytically for a few special types of the individual claim amount distribution. Prabhu proposes a finite time ruin probability formula [
14], when
, as a function of the distribution of the total claim amount in a specified time interval. Seal develops Prabhu’s formula considering the exponential individual claims [
15]. De Vylder suggests a simple method that approximates a classical risk process
by another classical risk process
[
16]. Segerdahl proposes a formula that extends the Cramer–Lundberg approximation by adding a time factor to obtain the finite time ruin probability [
17]. Iglehart [
18], Grandell [
13] and Asmussen and Albrecher [
19] study the finite time ruin probability by using diffusion approximation techniques. Dufresne et al. investigate the infinite time ruin probability when the aggregate claims process is the standardized gamma process [
20]. Then, Dickson and Waters suggest gamma and the translated gamma process approximations in the classical risk model to calculate the finite time ruin probability [
21]. The finite time ruin probability can also be approximated by using Monte Carlo simulations even though it is a time-consuming procedure.
Asmussen and Albrecher present an exact finite time ruin probability formula when the individual claim amounts are exponentially distributed [
19]. In this formula, it is assumed that the individual claim amounts are distributed exponentially with parameter
β with
, the number of claims have a Poisson distribution with the parameter
λ and the premium rate per unit of time is equal to one (
). Then, the finite time ruin probability is calculated as:
where:
and:
The major drawback of this approach is the limitation of the parameter of the individual claims distribution (
) and premium rate (
). When
, the following equation is applied [
19].
and the following equation is applicable when
[
22].
The Exact Finite Time Ruin Probability on the Excess of Loss Reinsurance
Under the excess of loss reinsurance, a claim is shared between an insurer and a reinsurer according to the fixed amount called the retention level,
M. When a claim
X occurs, the insurer pays
, and the reinsurer pays
with
. Hence, the distribution function of
,
, is:
and the moments of
are:
Similarly, the moments of
are:
Under the excess of loss reinsurance, the aggregate claims for the reinsurer have a compound Poisson distribution with Poisson parameter
, and the individual claim amounts are exponential distributed with parameter
β. In a similar manner, the aggregate claims for the insurer have a compound Poisson parameter
, and the individual claim amounts are exponentially distributed with parameter
β [
23].
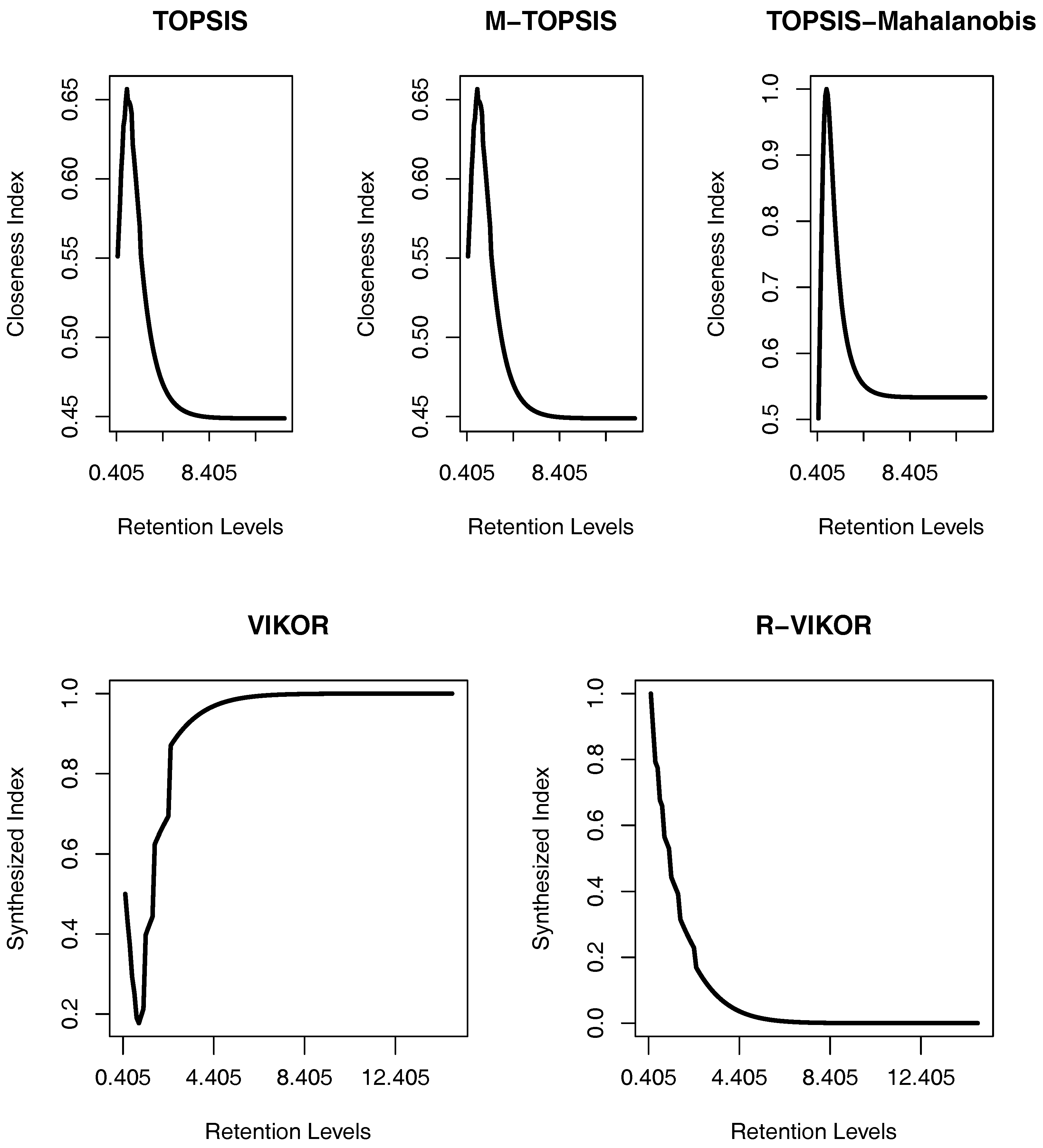
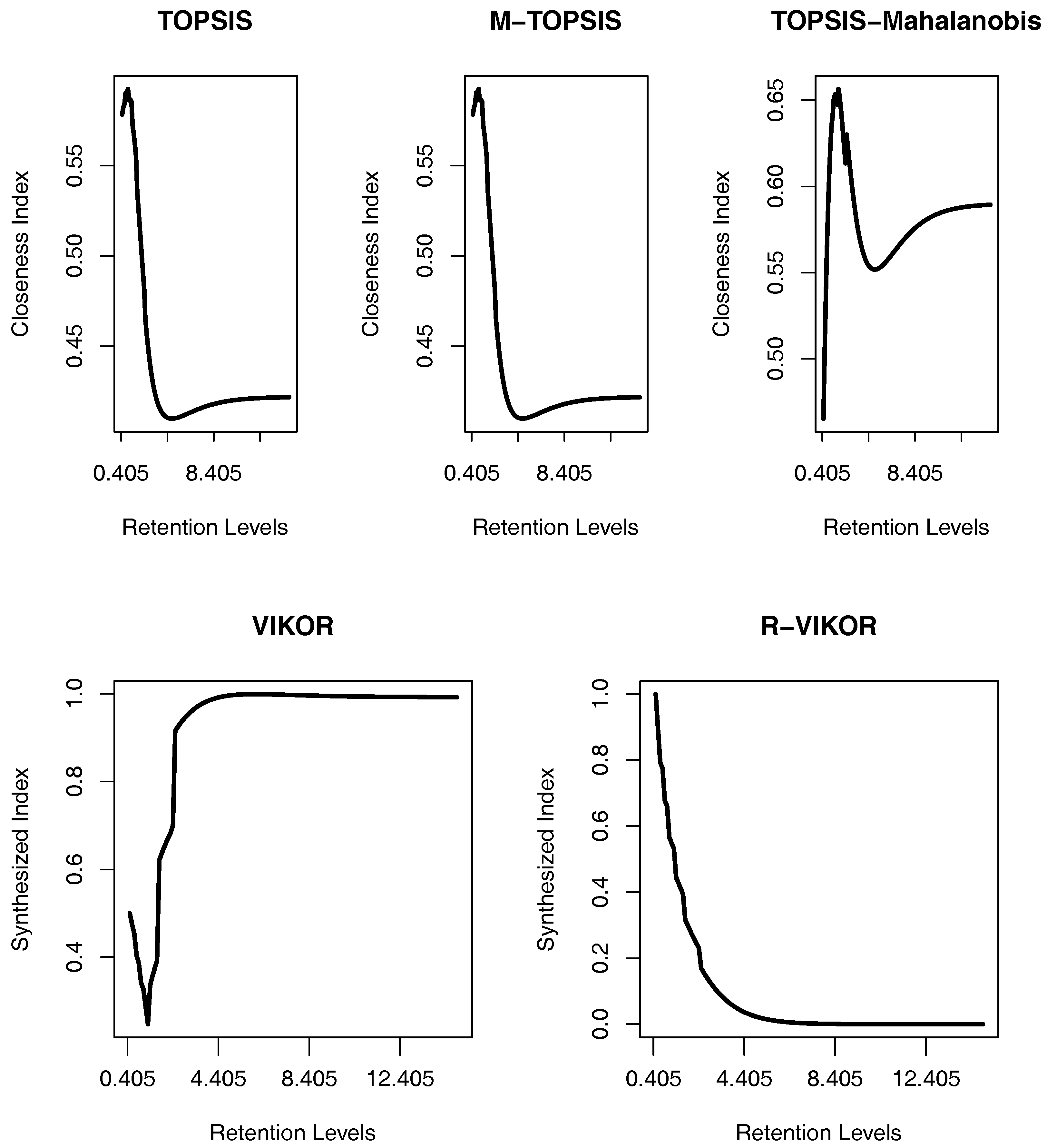
The survival probability is defined as the probability that ruin does not occur in the finite time horizon and is shown as . In this study, we aim to determine the optimal retention level that makes the insurer’s survival probability maximum.
2.3. Expected Profit
In general, the expected profit of the insurance company is determined as the difference between the insurer’s income and liabilities to the policyholders. Insurer’s income is the total premium income, whereas liabilities are the benefit payments. Insurer’s profit is influenced by many factors, such as pure risk premium, total claim amount, reinsurance level, insurance and reinsurance loading factor, investment incomes, taxes, capital gains and dividends. In this study, we assume that the premiums and claims are the main components of the insurance profit. Thus, we ignore the other factors, such as investment incomes, dividend payments and taxes.
Premium principles have a significant influence on the calculation of the expected profit. In this study, we calculate the expected profit according to two basic premium principles. First, we use the expected value premium principle, which is commonly used in the literature. This premium principle depends on the expected aggregate claims, insurance and reinsurance loading factors. The second method is the standard deviation premium principle, which considers the expected value, as well as the standard deviation of the aggregate claims.
In this study, we aim to calculate the optimal retention level that makes the insurer’s expected profit maximum by using the expected and the standard deviation premium principles.
2.3.1. Expected Value Premium Principle
In the classical risk model, it is assumed that the number of claims has a Poisson distribution with parameter
λ. According to the expected value premium principle with the insurance loading factor
θ and the reinsurance loading factor
ξ, the insurer’s premium income per unit of time after the reinsurance premium (i.e., net of reinsurance) is defined as:
where
is the expected aggregate claim and
is the expected aggregate claim paid by the reinsurer. It is also assumed that
and that
.
The net profit of the insurance company after the reinsurance arrangement is obtained by subtracting the expected total claim amount paid by the insurer,
, from the expected net insurance premium income,
.
where
.
2.3.2. Standard Deviation Premium Principle
According to the standard deviation premium principle with loading
α, the insurer’s premium income per unit of time after the reinsurance premium (i.e., net of reinsurance) is defined as:
where
denotes the variance of the aggregate claim amount paid by the reinsurance. This method is preferred when the fluctuation of the aggregate claims is important. Hence, this method enables the insurer to calculate a more accurate premium than the expected value premium principle provides.
2.4. Expected Shortfall
Value at Risk (VaR) is the probability that the loss on the portfolio over the given time horizon exceeds a threshold value. VaR of a portfolio at a confidence level
p∈
is given by the smallest number
l, such that the probability of the loss
L does not exceed
l is at least (
p) [
25].
L is the loss of a portfolio, and it is usually appropriate to assume in insurance contexts that the loss
L is non-negative.
is the level
p-quantile, i.e.:
Expected Shortfall (ES) is one of the financial risk measures to investigate the market risk or credit risk of a portfolio. Expected Shortfall is defined as an average of
of
X at level
p. Expected Shortfall is preferred to VaR, since it is more sensitive to the shape of the loss distribution in the tail of the distribution. Expected Shortfall is also called CVaR, Average Value at Risk (AVaR) or Expected Tail Loss (ETL). The ES at confidence level
is given by the following equation:
The aggregate claims for the insurer have a compound Poisson parameter
, and the individual claim amounts are exponentially distributed with parameter
β under the excess of loss reinsurance. We calculate the ES for the compound Poisson distribution according to the retention level,
M. The ES of a compound Poisson model is calculated by using the R programming language [
26].
An increase in the retention level causes an increase of the insurer’s responsibility, and thus, the ES increases. In this study, we aim to determine the optimal retention level that makes the insurer’s ES minimum.





{kind=link}
{kind=link}