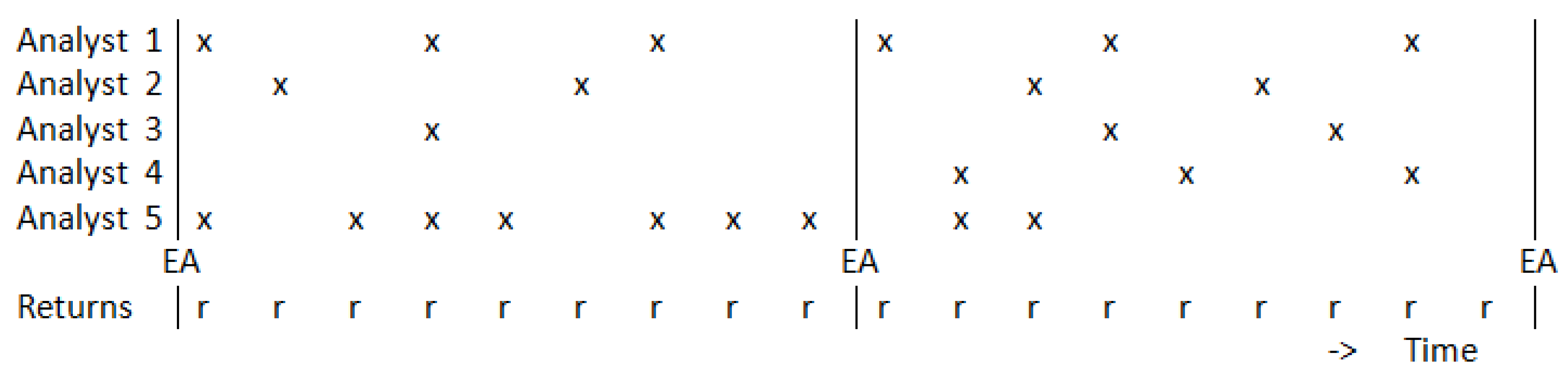
Figure 1.
An example of the data format, with x indicating an earnings forecast and EA indicating when a new yearly earnings announcement takes place. This figure shows for five forecasters for two years a variety of hypothetical patterns of forecasts, including analysts that follow a very regular forecasting pattern, or the opposite, and including forecasters that quit producing forecasts or that joined a later year.
Figure 1.
An example of the data format, with x indicating an earnings forecast and EA indicating when a new yearly earnings announcement takes place. This figure shows for five forecasters for two years a variety of hypothetical patterns of forecasts, including analysts that follow a very regular forecasting pattern, or the opposite, and including forecasters that quit producing forecasts or that joined a later year.
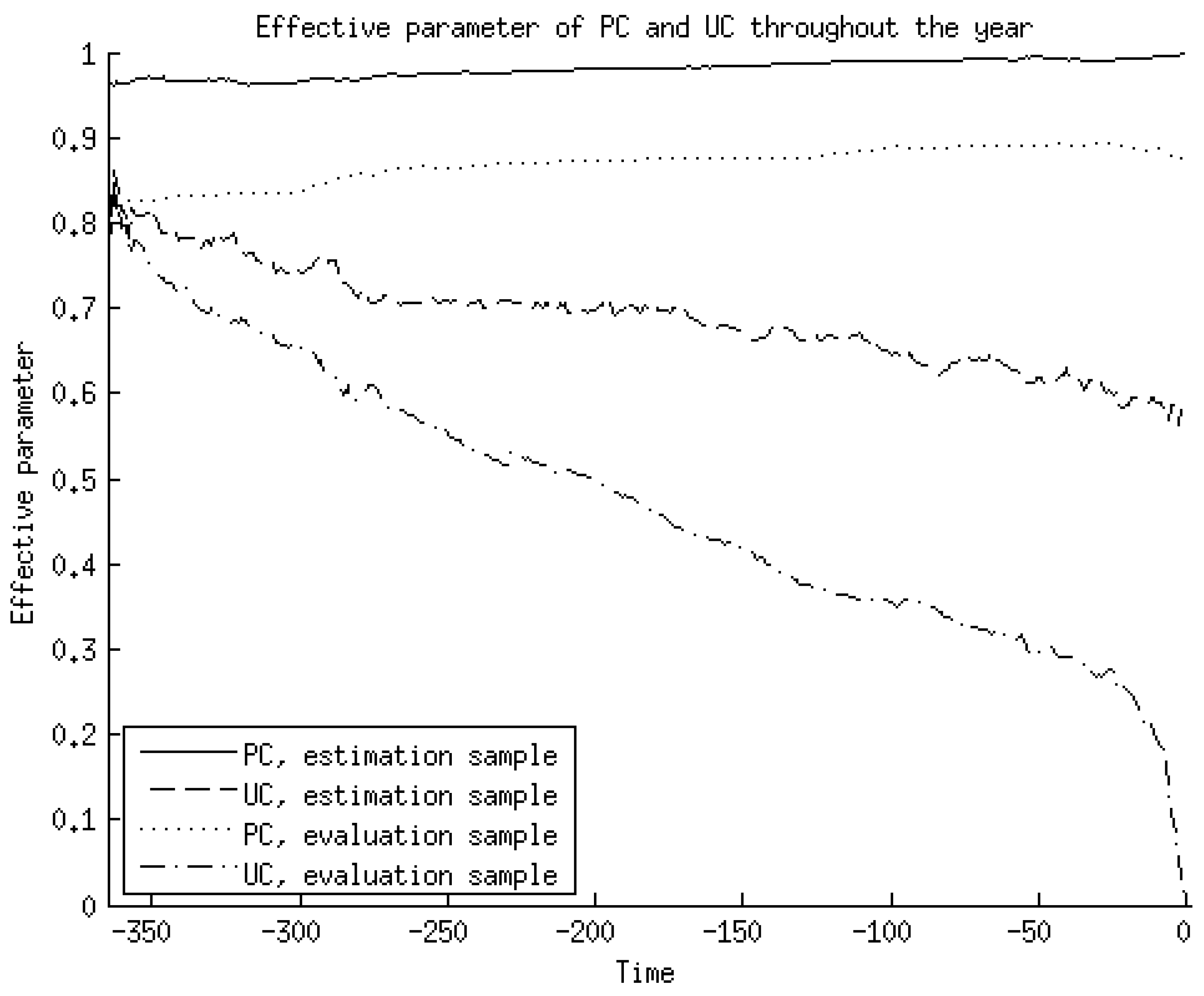
Figure 2.
The effective parameter of the predictable and unpredictable component in forecasting the actual earnings throughout the year (with earnings announcement at t = 0), after filling in average actual values for the number of forecasts and time until announcement across all firms and all years in the estimation or evaluation sample.
Figure 2.
The effective parameter of the predictable and unpredictable component in forecasting the actual earnings throughout the year (with earnings announcement at t = 0), after filling in average actual values for the number of forecasts and time until announcement across all firms and all years in the estimation or evaluation sample.
Table 1.
The number of firms, forecasters and forecasts for each upcoming section and subsection. The number of forecasts is shown separately for the estimation sample, which is up until 2005, and the evaluation sample, which is from 2006 onwards.
Table 1.
The number of firms, forecasters and forecasts for each upcoming section and subsection. The number of forecasts is shown separately for the estimation sample, which is up until 2005, and the evaluation sample, which is from 2006 onwards.
Table 2.
The variables that were used to forecast the earnings forecast. These variables enter a linear model. They all use one-day lagged information. Several variables are based on historic analyst behaviour, while others are based on stock market data.
Table 2.
The variables that were used to forecast the earnings forecast. These variables enter a linear model. They all use one-day lagged information. Several variables are based on historic analyst behaviour, while others are based on stock market data.
| | Variable | Description |
|---|
| | Intercept | |
| Analyst variables | Average Forecast | The average of all most recent forecasts of every forecaster, until the previous day |
| | Average Forecast is also included in a multiplication with two indicator variables: |
| | 1. Whether the number of forecasters is lower than 10 or not |
| | 2. Whether the time until the announcement of the earnings is more than two weeks or not |
| Average Forecast | First difference in Average Active Forecast |
| Previous Forecast | The difference between the previous forecast of the forecaster, and the average active forecast at that time |
| Previous Forecast | The previous forecast of the individual forecaster |
| Stock variables | Stock Index Firm | The stock market index of the firm for which the earnings are forecasted |
| Stock Returns Firm | The stock market daily returns of the firm for which the earnings are forecasted |
| Cumulative Stock Returns Firm | Stock market returns of the firm since the day of the previous forecast by this forecaster |
| Stock Index S&P500 | The stock market index of the S&P500 index |
| Stock Returns S&P500 | The stock market daily returns of the S&P500 index |
| Cumulative Stock Returns S&P500 | Stock market returns of the S&P500 index since the day of the previous forecast by this forecaster |
Table 3.
A summary of estimation results of forecasting earnings forecasts. Results are for the estimation sample, which amounts to 316 firms, 18.338 forecasters and 146.319 forecasts (on average slightly more than 463 forecasts per firm). As variable to be explained, we used the earnings forecasts by the analysts. As explanatory variables, we included the variables mentioned in
Table 2. The regression was run individually for each firm, and the table shows statistics which summarize these results. The first five columns contain summary results on the regular parameter estimates (average, median, standard deviation and bounds of a 90% interval). The last three columns show summarized results for the standardized estimate, which is included to compare contributions to fit. The standardized estimate is defined as the estimate that would have been obtained had the regressor been standardized beforehand (which is a transformation to having an average of zero and a standard deviation of one).
Table 3.
A summary of estimation results of forecasting earnings forecasts. Results are for the estimation sample, which amounts to 316 firms, 18.338 forecasters and 146.319 forecasts (on average slightly more than 463 forecasts per firm). As variable to be explained, we used the earnings forecasts by the analysts. As explanatory variables, we included the variables mentioned in
Table 2. The regression was run individually for each firm, and the table shows statistics which summarize these results. The first five columns contain summary results on the regular parameter estimates (average, median, standard deviation and bounds of a 90% interval). The last three columns show summarized results for the standardized estimate, which is included to compare contributions to fit. The standardized estimate is defined as the estimate that would have been obtained had the regressor been standardized beforehand (which is a transformation to having an average of zero and a standard deviation of one).
| | | Estimate | Standardized Estimate |
|---|
| | | Average | Median | Standard Deviation | Bounds of 90% Interval | Median | Median of Absolute | Contribution to Total Fit |
|---|
| | Intercept | −0.028 | −0.026 | 0.278 | −0.395 | 0.229 | | | |
| Analyst-based | Average Forecast | 1.050 | 1.077 | 0.384 | 0.557 | 1.483 | 0.490 | 0.491 | 96.9% |
| Average Forecast × | 0.018 | 0.005 | 0.172 | −0.053 | 0.078 | 0.001 | 0.004 | 0,0% |
| Average Forecast × | −0.038 | −0.034 | 0.292 | −0.212 | 0.058 | −0.017 | 0.025 | 0.3% |
| Average Forecast | 0.765 | 0.607 | 1.053 | −0.526 | 2.438 | 0.005 | 0.006 | 0.0% |
| Previous Forecast | 0.498 | 0.548 | 0.359 | −0.151 | 1.051 | 0.029 | 0.030 | 0.4% |
| Previous Forecast | −0.046 | −0.078 | 0.273 | −0.388 | 0.375 | −0.028 | 0.076 | 2.3% |
| Stock market | Stock Index Firm | 0.002 | 0.001 | 0.004 | −0.001 | 0.007 | 0.009 | 0.013 | 0.1% |
| Stock Returns Firm | 0.302 | 0.150 | 1.039 | −0.264 | 1.291 | 0.005 | 0.007 | 0.0% |
| Cumulative Stock Returns Firm | 0.054 | 0.018 | 0.206 | −0.092 | 0.285 | 0.003 | 0.005 | 0.0% |
| Stock Index S&P500 | 0.000 | 0.000 | 0.002 | −0.001 | 0.002 | 0.001 | 0.009 | 0.0% |
| Stock Returns S&P500 | −0.214 | −0.096 | 1.226 | -2.155 | 1.421 | −0.001 | 0.004 | 0.0% |
| Cumulative Stock Returns S&P500 | −0.032 | −0.006 | 0.238 | −0.408 | 0.256 | 0.000 | 0.005 | 0.0% |
Table 4.
A summary of
t-Statistics when forecasting earnings forecasts. Results are for the estimation sample, which amounts to 316 firms, 18,338 forecasters and 146,319 forecasts (on average slightly more than 463 forecasts per firm). As variable to be explained, we used the earnings forecasts by the analysts. As explanatory variables, we included the variables mentioned in
Table 2. The regression was run individually for each firm, and the table shows statistics which summarize these results.
Table 4.
A summary of
t-Statistics when forecasting earnings forecasts. Results are for the estimation sample, which amounts to 316 firms, 18,338 forecasters and 146,319 forecasts (on average slightly more than 463 forecasts per firm). As variable to be explained, we used the earnings forecasts by the analysts. As explanatory variables, we included the variables mentioned in
Table 2. The regression was run individually for each firm, and the table shows statistics which summarize these results.
| | | Median t-Statistic | Median Absolute of t-Statistic | Percentage Significant at 5% Level |
|---|
| | Intercept | −0.986 | 1.920 | 48.4% |
| Analyst-based | Average Forecast | 9.865 | 9.865 | 96.4% |
| Average Forecast × | 0.530 | 1.118 | 27.9% |
| Average Forecast × | −1.662 | 2.212 | 51.6% |
| Average Forecast | 1.680 | 1.766 | 47.2% |
| Previous Forecast | 4.794 | 4.794 | 78.0% |
| Previous Forecast | −0.804 | 1.599 | 38,6% |
| Stpck market | Stock Index Firm | 1.928 | 2.402 | 55.8% |
| Stock Returns Firm | 1.378 | 1.653 | 40.1% |
| Cumulative Stock Returns Firm | 0.730 | 1.329 | 32.9% |
| Stock Index S&P500 | 0.151 | 1.928 | 49.3% |
| Stock Returns S&P500 | −0.395 | 1.192 | 24.9% |
| Cumulative Stock Returns S&P500 | −0.110 | 1.196 | 26.7% |
Table 5.
A summary of estimation results of forecasting earnings forecasts, after using the correction method to account for small-sample error. Results are for the estimation sample, which amounts to 316 firms, 18,338 forecasters and 146,319 forecasts (on average slightly more than 463 forecasts per firm). As variable to be explained, we used the earnings forecasts by the analysts. As explanatory variables, we included the variables mentioned in
Table 2. The regression was run individually for each firm, and the table shows statistics which summarize these results. The first five columns contain summary results on the regular parameter estimates (average, median, standard deviation and bounds of a 90% interval). The last three columns show summarized results for the standardized estimate, which is included to compare contributions to fit. The standardized estimate is defined as the estimate that would have been obtained had the regressor been standardized beforehand (which is a transformation to having an average of zero and a standard deviation of one). The correction method is based on the assumption of an underlying distribution out of which each variable (for the different firms) is drawn. This provides additional information on the firm-specific estimate especially in the case when the firm has only a few observations.
Table 5.
A summary of estimation results of forecasting earnings forecasts, after using the correction method to account for small-sample error. Results are for the estimation sample, which amounts to 316 firms, 18,338 forecasters and 146,319 forecasts (on average slightly more than 463 forecasts per firm). As variable to be explained, we used the earnings forecasts by the analysts. As explanatory variables, we included the variables mentioned in
Table 2. The regression was run individually for each firm, and the table shows statistics which summarize these results. The first five columns contain summary results on the regular parameter estimates (average, median, standard deviation and bounds of a 90% interval). The last three columns show summarized results for the standardized estimate, which is included to compare contributions to fit. The standardized estimate is defined as the estimate that would have been obtained had the regressor been standardized beforehand (which is a transformation to having an average of zero and a standard deviation of one). The correction method is based on the assumption of an underlying distribution out of which each variable (for the different firms) is drawn. This provides additional information on the firm-specific estimate especially in the case when the firm has only a few observations.
| | | Estimate | Standardized Estimate |
|---|
| | | Average | Median | Standard Deviation | Bounds of 90% Interval | Median | Median of Absolute | Contribution to Total Fit |
|---|
| Analyst-based | Intercept | −0.019 | −0.021 | 0.051 | −0.113 | 0.068 | | | |
| Average Forecast | 1.097 | 1.094 | 0.134 | 0.880 | 1.287 | 0.479 | 0.479 | 98.5% |
| Average Forecast × | 0.003 | 0.004 | 0.011 | −0.012 | 0.019 | 0.001 | 0.002 | 0.0% |
| Average Forecast × | −0.048 | −0.040 | 0.063 | −0.161 | 0.018 | −0.019 | 0.022 | 0.2% |
| Average Forecast | 0.741 | 0.687 | 0.409 | 0.148 | 1.444 | 0.005 | 0.005 | 0.0% |
| Previous Forecast | 0.553 | 0.564 | 0.192 | 0.206 | 0.865 | 0.029 | 0.029 | 0.4% |
| Previous Forecast | −0.081 | −0.087 | 0.120 | −0.253 | 0.117 | −0.031 | 0.044 | 0.8% |
| Stock market | Stock Index Firm | 0.001 | 0.001 | 0.001 | 0.000 | 0.002 | 0.009 | 0.009 | 0.0% |
| Stock Returns Firm | 0.160 | 0.120 | 0.175 | −0.043 | 0.508 | 0.005 | 0.005 | 0.0% |
| Cumulative Stock Returns Firm | 0.016 | 0.013 | 0.022 | −0.013 | 0.055 | 0.002 | 0.003 | 0.0% |
| Stock Index S&P500 | 0.000 | 0.000 | 0.000 | 0.000 | 0.000 | 0.000 | 0.005 | 0.0% |
| Stock Returns S&P500 | −0.087 | −0.081 | 0.214 | −0.410 | 0.251 | −0.001 | 0.001 | 0.0% |
| Cumulative Stock Returns S&P500 | −0.002 | −0.002 | 0.036 | −0.065 | 0.060 | 0.000 | 0.002 | 0.0% |
Table 6.
A summary of results on median , the median ratio of squared analyst forecast error over squared predictable component error. The analyst forecast is the earnings forecast that is reported by an analyst, while the predictable component error is the error made if we use the part of the earnings forecast that we can predict beforehand as forecast. This ratio shows us whether the inclusion of the unpredictable component results in an improvement. We show results for 18,338 forecasters across 316 firms, separated for the estimation (146,319 forecasts) and evaluation (126,651 forecasts) samples. We take the median ratio per firm to not let a few situations in which the denominator is almost zero influence the measure much.
Table 6.
A summary of results on median , the median ratio of squared analyst forecast error over squared predictable component error. The analyst forecast is the earnings forecast that is reported by an analyst, while the predictable component error is the error made if we use the part of the earnings forecast that we can predict beforehand as forecast. This ratio shows us whether the inclusion of the unpredictable component results in an improvement. We show results for 18,338 forecasters across 316 firms, separated for the estimation (146,319 forecasts) and evaluation (126,651 forecasts) samples. We take the median ratio per firm to not let a few situations in which the denominator is almost zero influence the measure much.
| Period | Estimation Sample | Evaluation Sample |
|---|
| Average | 0.609 | 0.638 |
| Median | 0.655 | 0.631 |
| Standard Deviation | 0.304 | 0.571 |
| 5% percentile | 0.071 | 0.061 |
| 95% percentile | 1.031 | 1.207 |
Table 7.
A summary of results on median , the median ratio of squared analyst forecast error over squared predictable component error. The analyst forecast is the earnings forecast that is reported by an analyst, while the predictable component error is the error made if we use the part of the earnings forecast that we can predict beforehand as forecast. This ratio shows us whether the inclusion of the unpredictable component results in an improvement or not. We show results for 18,338 forecasters across 316 firms, for a total number of 272,970 observations spread over seven periods in the year leading up to the earnings announcement. The seven periods roughly correspond to the periods around the quarterly earnings announcement (excluding the fourth quarter, which coincides with the announcement of the earnings of interest) and the four periods in-between. We take the median ratio per firm to not let a few situations in which the denominator is almost zero influence the measure much.
Table 7.
A summary of results on median , the median ratio of squared analyst forecast error over squared predictable component error. The analyst forecast is the earnings forecast that is reported by an analyst, while the predictable component error is the error made if we use the part of the earnings forecast that we can predict beforehand as forecast. This ratio shows us whether the inclusion of the unpredictable component results in an improvement or not. We show results for 18,338 forecasters across 316 firms, for a total number of 272,970 observations spread over seven periods in the year leading up to the earnings announcement. The seven periods roughly correspond to the periods around the quarterly earnings announcement (excluding the fourth quarter, which coincides with the announcement of the earnings of interest) and the four periods in-between. We take the median ratio per firm to not let a few situations in which the denominator is almost zero influence the measure much.
| | During Q1 | Announcement Q1 | During Q2 | Announcement Q2 | During Q3 | Announcement Q3 | During Q4 |
|---|
| Average | 0.455 | 0.414 | 0.632 | 0.613 | 0.797 | 0.789 | 0.921 |
| Median | 0.335 | 0.350 | 0.640 | 0.625 | 0.808 | 0.750 | 0.887 |
| Standard Deviation | 0.464 | 0.329 | 0.351 | 0.379 | 0.411 | 0.683 | 0.552 |
| 5% percentile | 0.020 | 0.025 | 0.077 | 0.088 | 0.166 | 0.180 | 0.266 |
| 95% percentile | 1.170 | 1.032 | 1.136 | 1.209 | 1.463 | 1.378 | 1.581 |
Table 8.
Regression of squared forecast error of the analyst earnings forecasts on the unpredictable component and its square: . We did this for all 316 firms and 18,338 forecasters simultaneously in two regressions, one for the estimation sample (n = 146,319) and one for the evaluation sample (n = 126,651). Next to the normal least-squares estimation of the above linear model, we also used two standardization methods to account for firm differences in the size of earnings and the uncertainty of earnings. Standardization 1 uses the variance of the predictable component per firm. Standardization 2 uses the variance of the unpredictable component per firm. Standard errors are in parentheses. Short summary: The parameter of is in each case positive and around 1, which indicates that in general forecasts with a large unpredictable component are less accurate. The parameter of is not consistent for the different samples and standardization methods, which shows that there is no clear sign of larger errors for either higher-than-predicted or lower-than-predicted forecasts.
Table 8.
Regression of squared forecast error of the analyst earnings forecasts on the unpredictable component and its square: . We did this for all 316 firms and 18,338 forecasters simultaneously in two regressions, one for the estimation sample (n = 146,319) and one for the evaluation sample (n = 126,651). Next to the normal least-squares estimation of the above linear model, we also used two standardization methods to account for firm differences in the size of earnings and the uncertainty of earnings. Standardization 1 uses the variance of the predictable component per firm. Standardization 2 uses the variance of the unpredictable component per firm. Standard errors are in parentheses. Short summary: The parameter of is in each case positive and around 1, which indicates that in general forecasts with a large unpredictable component are less accurate. The parameter of is not consistent for the different samples and standardization methods, which shows that there is no clear sign of larger errors for either higher-than-predicted or lower-than-predicted forecasts.
| | | No Standardization | Standardization 1 | Standardization 2 |
|---|
| Estimation sample | intercept | 0.116 | (0.003) | 0.079 | (0.002) | 0.419 | (0.005) |
| 0.539 | (0.020) | 0.257 | (0.012) | −0.001 | (0.012) |
| 0.891 | (0.011) | 0.940 | (0.008) | 1.043 | (0.004) |
| 0.044 | | 0.085 | | 0.346 | |
| Evaluation sample | intercept | 0.777 | (0.024) | 0.163 | (0.004) | 1.052 | (0.012) |
| 0.292 | (0.054) | 0.250 | (0.015) | −0.947 | (0.013) |
| 0.980 | (0.002) | 1.006 | (0.001) | 1.006 | (0.001) |
| 0.625 | | 0.810 | | 0.838 | |
Table 9.
A summary of results of the regression of the actual earnings on predictable and unpredictable component variables: . not only includes the predictable component itself, but also multiplications of the predictable component with logNF, the logarithm of the number of forecasts on which Average Forecast is based at that moment, and, with logTUA, the logarithm of the number of days until the announcement. In a similar way, is based on the unpredictable component and multiplications of unpredictable component with logNF and logTUA. We performed these regressions for each firm separately (of the 316 firms) but pooled the results of all 18,338 forecasters. The total number of observations in the regressions across all firms is 146,319 in the estimation sample and 126,651 in the evaluation sample. We show as summary of the results several statistics (average, median, standard deviation, and 90% interval) on the estimated parameters and also the average and median of the standard error of the parameters.
Table 9.
A summary of results of the regression of the actual earnings on predictable and unpredictable component variables: . not only includes the predictable component itself, but also multiplications of the predictable component with logNF, the logarithm of the number of forecasts on which Average Forecast is based at that moment, and, with logTUA, the logarithm of the number of days until the announcement. In a similar way, is based on the unpredictable component and multiplications of unpredictable component with logNF and logTUA. We performed these regressions for each firm separately (of the 316 firms) but pooled the results of all 18,338 forecasters. The total number of observations in the regressions across all firms is 146,319 in the estimation sample and 126,651 in the evaluation sample. We show as summary of the results several statistics (average, median, standard deviation, and 90% interval) on the estimated parameters and also the average and median of the standard error of the parameters.
| | | Estimated Coefficient | Standard Error |
|---|
| | | Average | Median | Standard Deviation | Bounds of 90% Interval | Average | Median |
|---|
| Estimation sample | intercept | 0.067 | 0.021 | 0.348 | −0.243 | 0.509 | 0.034 | 0.020 |
| PC | 1.060 | 1.099 | 3.815 | −3.274 | 4.489 | 0.663 | 0.444 |
| PC*logNF | −0.018 | −0.019 | 1.176 | −0.980 | 1.240 | 0.233 | 0.152 |
| PC*logTUA | −0.020 | −0.016 | 0.704 | −0.582 | 0.834 | 0.122 | 0.081 |
| PC*logNF*logTUA | 0.004 | 0.004 | 0.215 | −0.249 | 0.182 | 0.043 | 0.027 |
| UC | 2.400 | 1.506 | 24.167 | −34.384 | 40.469 | 11.212 | 10.087 |
| UC*logNF | −0.663 | −0.456 | 8.279 | −13.757 | 12.491 | 4.005 | 3.460 |
| UC*logTUA | −0.198 | 0.028 | 4.458 | −7.161 | 6.155 | 2.068 | 1.836 |
| UC*logNF*logTUA | 0.082 | 0.029 | 1.543 | -2.411 | 2.530 | 0.744 | 0.646 |
| Evaluation sample | intercept | 0.394 | 0.278 | 0.972 | −0.498 | 1.704 | 0.067 | 0.046 |
| PC | 0.054 | 0.711 | 5.900 | −8.086 | 5.740 | 0.950 | 0.506 |
| PC*logNF | 0.242 | 0.068 | 1.888 | −1.590 | 2.451 | 0.326 | 0.174 |
| PC*logTUA | 0.084 | 0.027 | 0.988 | −0.959 | 1.272 | 0.172 | 0.095 |
| PC*logNF*logTUA | −0.024 | −0.006 | 0.321 | −0.367 | 0.343 | 0.059 | 0.033 |
| UC | −2.370 | −2.213 | 43.991 | −52.879 | 50.791 | 13.371 | 9.822 |
| UC*logNF | 0.712 | 0.793 | 14.559 | −18.921 | 16.258 | 4.661 | 3.402 |
| UC*logTUA | 0.811 | 0.655 | 7.789 | −9.058 | 9.518 | 2.435 | 1.832 |
| UC*logNF*logTUA | −0.224 | −0.229 | 2.584 | −3.003 | 3.002 | 0.853 | 0.631 |
Table 10.
A summary of results on the comparison between the regressions: of (1) , the actual earnings on only predictable component variables; and (2) , the actual earnings on both the predictable and unpredictable component variables. We performed these regressions for each firm separately (of the 316 firms) but pooled the results of all 18,338 forecasters. The total number of observations in the regressions across all firms is 146,319 in the estimation sample and 126,651 in the evaluation sample. The F-Statistic is based on the test for the joint significance of , the parameters of the unpredictable component variables, and the results for the associated P-value are shown in the column labeled P-value. The summarized results for the values for both the restricted and the unrestricted model are also shown.
Table 10.
A summary of results on the comparison between the regressions: of (1) , the actual earnings on only predictable component variables; and (2) , the actual earnings on both the predictable and unpredictable component variables. We performed these regressions for each firm separately (of the 316 firms) but pooled the results of all 18,338 forecasters. The total number of observations in the regressions across all firms is 146,319 in the estimation sample and 126,651 in the evaluation sample. The F-Statistic is based on the test for the joint significance of , the parameters of the unpredictable component variables, and the results for the associated P-value are shown in the column labeled P-value. The summarized results for the values for both the restricted and the unrestricted model are also shown.
| | Estimation Sample | Evaluation Sample |
|---|
| | F-Statistic | P-Value | without UC | with UC | F-Statistic | P-Value | without UC | with UC |
|---|
| Average | 33.776 | 0.015 | 0.868 | 0.893 | 29.292 | 0.039 | 0.817 | 0.850 |
| Median | 21.554 | 0.000 | 0.918 | 0.935 | 20.794 | 0.000 | 0.878 | 0.901 |
| Standard Deviation | 44.568 | 0.103 | 0.155 | 0.129 | 30.484 | 0.164 | 0.180 | 0.155 |
| 5% percentile | 3.066 | 0.000 | 0.554 | 0.610 | 1.442 | 0.000 | 0.422 | 0.508 |
| 95% percentile | 101.095 | 0.032 | 0.997 | 0.997 | 85.891 | 0.233 | 0.988 | 0.993 |
| Significant at 5% level | 96.2% | | | 91.8% | | |
Table 11.
A summary of results on the median ratios between two squared errors. Used are combinations of the following: , the squared analyst forecast error; , the squared error of using the predictable component as forecast; and , the squared error of the optimal combination of the predictable component and unpredictable component variables. We calculated these median ratios for each firm separately (of the 316 firms) but pooled the ratios of all 18,338 forecasters. The total number of observations across all firms is 146,319 in the estimation sample and 126,651 in the evaluation sample. We calculated some ratios in the evaluation sample twice: once with the weights (used in the construction of the optimal forecast) as estimated in the estimation sample, and once using weights based on the evaluation sample itself.
Table 11.
A summary of results on the median ratios between two squared errors. Used are combinations of the following: , the squared analyst forecast error; , the squared error of using the predictable component as forecast; and , the squared error of the optimal combination of the predictable component and unpredictable component variables. We calculated these median ratios for each firm separately (of the 316 firms) but pooled the ratios of all 18,338 forecasters. The total number of observations across all firms is 146,319 in the estimation sample and 126,651 in the evaluation sample. We calculated some ratios in the evaluation sample twice: once with the weights (used in the construction of the optimal forecast) as estimated in the estimation sample, and once using weights based on the evaluation sample itself.
| | Estimation Sample with Estimation Sample Weights | Evaluation Sample with Estimation Sample Weights | Evaluation Sample with Evaluation Sample Weights |
|---|
| | | | | | | | | |
|---|
| Average | 0.609 | 0.669 | 1.499 | 0.638 | 2.878 | 7.463 | 0.570 | 1.123 |
| Median | 0.655 | 0.532 | 0.877 | 0.631 | 1.107 | 2.165 | 0.311 | 0.591 |
| Standard Deviation | 0.304 | 1.206 | 4.425 | 0.571 | 5.703 | 18.399 | 3.097 | 5.330 |
| 5% percentile | 0.071 | 0.059 | 0.279 | 0.061 | 0.142 | 0.642 | 0.031 | 0.164 |
| 95% percentile | 1.031 | 1.371 | 3.437 | 1.207 | 10.102 | 33.621 | 0.943 | 1.757 |
Table 12.
The results for the regressions to predict better analysts in the evaluation sample using variables in the evaluation sample. This is based on 1835 forecasters (since we only include forecasters with a minimum of 10 observations in both sample periods) with a total of 52,236 forecasts in the estimation sample and 36,403 forecasts in the evaluation sample. We put the data across all firms in one regression. We used two interpretations for what a better analyst is: an analyst that has a smaller forecast error compared to the predicted component (“better performing”) and an analyst whose associated optimally constructed forecasts have smaller forecast errors compared to the predicted component error (“having more information”). These might overlap if the forecasters with more information also used them well (so if the optimal forecast is similar to the analyst forecast), but there could also be forecasters that do not use their information well, which is why we separate these measures. In these regressions we used the balanced relative difference: with x and y being combinations of A (for the analyst forecast error, ), P (for the predictable component error, ), O (for the optimal forecast error, ) and U (for the squared unpredictable component, ). As performance variable, we used , while we used as information variable. The variables to be explained were measured in the evaluation sample, while the regressors were measured in the estimation sample. Standard errors are shown in parentheses. Short conclusion: (1) Better performing forecasters (low value of ) can be predicted by looking at historically better performing forecasters and at forecasters that have relatively small unpredictable components (compared to ); and (2) forecasters that have more usable information (low value of ) can be predicted by looking at forecasters that historically have more information and forecasters that performed better.
Table 12.
The results for the regressions to predict better analysts in the evaluation sample using variables in the evaluation sample. This is based on 1835 forecasters (since we only include forecasters with a minimum of 10 observations in both sample periods) with a total of 52,236 forecasts in the estimation sample and 36,403 forecasts in the evaluation sample. We put the data across all firms in one regression. We used two interpretations for what a better analyst is: an analyst that has a smaller forecast error compared to the predicted component (“better performing”) and an analyst whose associated optimally constructed forecasts have smaller forecast errors compared to the predicted component error (“having more information”). These might overlap if the forecasters with more information also used them well (so if the optimal forecast is similar to the analyst forecast), but there could also be forecasters that do not use their information well, which is why we separate these measures. In these regressions we used the balanced relative difference: with x and y being combinations of A (for the analyst forecast error, ), P (for the predictable component error, ), O (for the optimal forecast error, ) and U (for the squared unpredictable component, ). As performance variable, we used , while we used as information variable. The variables to be explained were measured in the evaluation sample, while the regressors were measured in the estimation sample. Standard errors are shown in parentheses. Short conclusion: (1) Better performing forecasters (low value of ) can be predicted by looking at historically better performing forecasters and at forecasters that have relatively small unpredictable components (compared to ); and (2) forecasters that have more usable information (low value of ) can be predicted by looking at forecasters that historically have more information and forecasters that performed better.
| | Variable to Explain |
|---|
| | | |
|---|
| intercept | −0.174 | (0.020) | −0.003 | (0.022) |
| 1.152 | (0.398) | 0.244 | (0.440) |
| BRD(U,P) | −0.098 | (0.029) | −0.148 | (0.032) |
| BRD(A,P) | 0.407 | (0.035) | 0.302 | (0.038) |
| BRD(O,P) | 0.042 | (0.026) | 0.266 | (0.029) |
Table 13.
A summary of results on the correlation between three balanced relative difference variables and two unpredictable component variables, calculated per individual forecaster. This is based on 4541 forecasters, with 90,190 forecasts in the estimation sample and 28,000 in the evaluation sample. We calculated the correlation of the -variables with three balanced relative difference variables, with the definition with x and y being combinations of A (for the analyst forecast error, ), P (for the predictable component error, ) and O (for the optimal forecast error, ).
Table 13.
A summary of results on the correlation between three balanced relative difference variables and two unpredictable component variables, calculated per individual forecaster. This is based on 4541 forecasters, with 90,190 forecasts in the estimation sample and 28,000 in the evaluation sample. We calculated the correlation of the -variables with three balanced relative difference variables, with the definition with x and y being combinations of A (for the analyst forecast error, ), P (for the predictable component error, ) and O (for the optimal forecast error, ).
| | | Correlation with | Correlation with |
|---|
| | | | | | | | |
|---|
| Estimation sample | Average | −0.096 | −0.185 | −0.116 | −0.069 | −0.166 | −0.121 |
| Median | −0.125 | −0.214 | −0.133 | −0.124 | −0.210 | −0.146 |
| Standard Deviation | 0.322 | 0.279 | 0.273 | 0.335 | 0.278 | 0.272 |
| 5% percentile | −0.582 | −0.598 | −0.535 | −0.559 | −0.556 | −0.526 |
| 95% percentile | 0.454 | 0.324 | 0.359 | 0.506 | 0.354 | 0.358 |
| Evaluation sample | Average | −0.146 | −0.122 | 0.033 | −0.125 | −0.105 | 0.030 |
| Median | −0.173 | −0.129 | 0.049 | −0.177 | −0.116 | 0.046 |
| Standard Deviation | 0.477 | 0.490 | 0.472 | 0.481 | 0.487 | 0.468 |
| 5% percentile | −0.953 | −0.967 | −0.877 | −0.954 | −0.963 | −0.863 |
| 95% percentile | 0.790 | 0.852 | 0.909 | 0.816 | 0.835 | 0.892 |





{kind=link}
{kind=link}