On Combining Evidence from Heteroskedasticity Robust Panel Unit Root Tests in Pooled Regressions

Abstract
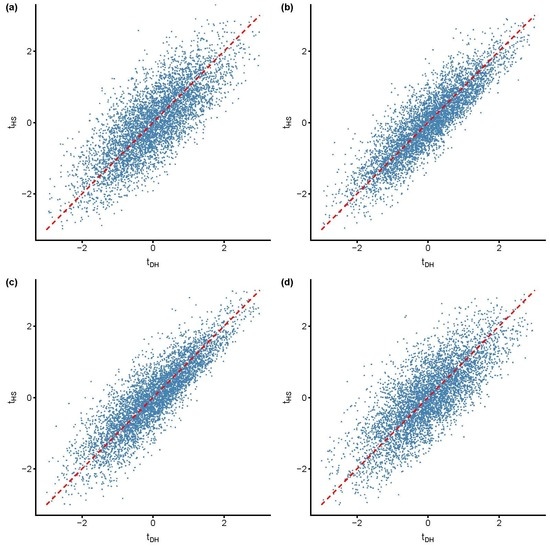
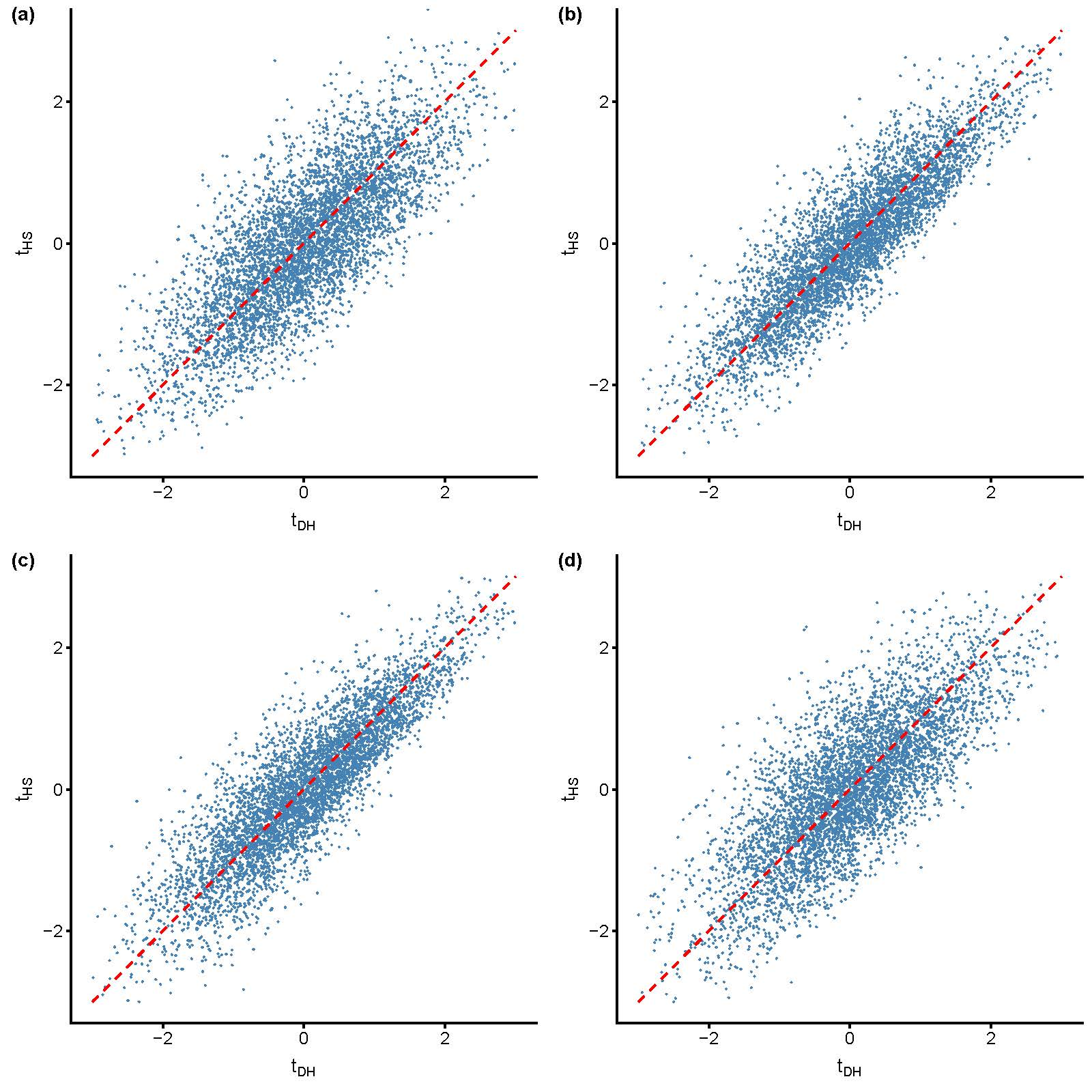
:
1. Introduction
2. Econometric Framework and Robust PURTs
2.1. Panel Model and Assumptions
- (i)
- The are serially uncorrelated with and variance-covariance matrices for all t.
- (ii)
- The are positive definite with positively bounded eigenvalues for all t.
- (iii)
- for all where the u are elements of .
2.2. Volatility-Break Robust Panel Unit Root Tests
2.2.1. The White-Type Test with Cauchy Instrumenting
2.2.2. The White-Type Test
2.2.3. Data Preprocessing
3. Mixed Signals and a Combined Testing Procedure
3.1. Simulation Setup
- Spatial Correlation: Contemporaneous correlation is introduced by a first-order spatial autoregressive (SAR) process in the following innovations:where the scalar spatial AR coefficient governs strength of the dependence. is a symmetric row-normalised spatial weights matrix of the one-ahead-and-one-behind type. Elements of one ahead and one behind the main diagonal are set to and zeros elsewhere; see Baltagi et al. (2007).5 is set to throughout.
3.2. Evidence of Mixed Signals
3.2.1. Results
3.3. A Combined Testing Procedure
- Obtain ordered p-values of n tests
- Reject the global null if
3.3.1. Results
4. Application to Inflation Rates
4.1. Preliminary Analysis
4.2. Results from Robust PURTs
5. Conclusions
Author Contributions
Funding
Conflicts of Interest
Abbreviations
| ADF | augmented Dickey-Fuller |
| CPI | consumer price index |
| DGP | data generating process |
| I(1) | integrated of order one |
| EU | European Union |
| KPSS | Kwiatkowski–Phillips–Schmidt–Shin |
| multivariate totally positive of order 2 | |
| OECD | Organisation for Economic Co-operation and Development |
| PURT | panel unit root test |
| SIC | Schwarz information criterion |
Appendix A

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| DGP A | DGP B | ||||||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Size | Power | Size | Power | ||||||||||||||||
| Homoskedasticity | |||||||||||||||||||
| 10 | 25 | 5.1 | 6.4 | 4.9 | 18.9 | 25.2 | 23.1 | 3.5 | 6.2 | 4.0 | 15.0 | 18.0 | 17.6 | ||||||
| 10 | 50 | 5.4 | 6.6 | 5.2 | 39.8 | 54.4 | 51.5 | 4.0 | 6.4 | 4.4 | 35.4 | 47.0 | 45.0 | ||||||
| 10 | 100 | 5.2 | 7.0 | 5.3 | 76.7 | 85.6 | 86.6 | 4.4 | 6.6 | 4.6 | 72.1 | 82.3 | 83.2 | ||||||
| 10 | 250 | 5.2 | 7.2 | 5.6 | 98.8 | 98.2 | 99.5 | 4.5 | 6.6 | 4.7 | 98.7 | 98.2 | 99.5 | ||||||
| 50 | 25 | 5.2 | 5.5 | 4.5 | 59.0 | 77.0 | 73.8 | 3.1 | 8.8 | 4.9 | 44.5 | 55.5 | 55.5 | ||||||
| 50 | 50 | 4.9 | 5.8 | 4.8 | 96.5 | 99.1 | 99.1 | 3.7 | 7.0 | 4.5 | 91.8 | 97.4 | 97.5 | ||||||
| 50 | 100 | 4.9 | 5.5 | 4.6 | 100.0 | 100.0 | 100.0 | 4.3 | 6.3 | 4.6 | 100.0 | 100.0 | 100.0 | ||||||
| 50 | 250 | 5.0 | 6.0 | 4.9 | 100.0 | 100.0 | 100.0 | 4.3 | 5.6 | 4.3 | 100.0 | 100.0 | 100.0 | ||||||
| Early negative shift | |||||||||||||||||||
| 10 | 25 | 5.0 | 6.0 | 4.3 | 7.7 | 8.9 | 8.7 | 3.7 | 6.7 | 4.1 | 5.9 | 6.0 | 6.0 | ||||||
| 10 | 50 | 4.8 | 6.4 | 4.8 | 15.7 | 20.2 | 18.8 | 3.1 | 6.3 | 3.8 | 13.2 | 15.4 | 14.8 | ||||||
| 10 | 100 | 5.1 | 6.5 | 4.9 | 36.0 | 50.8 | 48.2 | 3.6 | 6.4 | 4.1 | 32.3 | 43.6 | 42.6 | ||||||
| 10 | 250 | 5.1 | 6.9 | 5.3 | 79.0 | 91.7 | 91.4 | 4.1 | 6.5 | 4.7 | 76.2 | 89.8 | 89.6 | ||||||
| 50 | 25 | 5.1 | 5.3 | 4.3 | 13.8 | 18.0 | 16.7 | 3.9 | 10.5 | 6.1 | 6.2 | 3.7 | 4.4 | ||||||
| 50 | 50 | 5.0 | 5.4 | 4.4 | 46.9 | 64.8 | 61.2 | 2.6 | 9.1 | 5.0 | 35.0 | 34.5 | 35.9 | ||||||
| 50 | 100 | 5.0 | 5.5 | 4.5 | 93.2 | 98.9 | 98.7 | 3.0 | 7.4 | 4.5 | 89.2 | 95.8 | 96.7 | ||||||
| 50 | 250 | 4.9 | 5.8 | 4.7 | 100.0 | 100.0 | 100.0 | 3.9 | 6.5 | 4.6 | 100.0 | 100.0 | 100.0 | ||||||
| Late positive shift | |||||||||||||||||||
| 10 | 25 | 5.2 | 5.4 | 4.0 | 15.7 | 17.3 | 17.0 | 4.1 | 4.8 | 3.4 | 11.3 | 13.1 | 12.5 | ||||||
| 10 | 50 | 5.1 | 5.8 | 4.5 | 32.9 | 35.9 | 34.8 | 4.3 | 5.8 | 4.0 | 26.5 | 27.8 | 29.3 | ||||||
| 10 | 100 | 4.9 | 6.3 | 4.7 | 69.6 | 66.9 | 71.8 | 4.9 | 6.5 | 4.9 | 59.1 | 58.8 | 62.8 | ||||||
| 10 | 250 | 4.8 | 6.6 | 5.0 | 98.7 | 94.2 | 98.5 | 4.9 | 6.4 | 4.9 | 97.7 | 92.9 | 97.7 | ||||||
| 50 | 25 | 4.8 | 4.9 | 3.7 | 46.2 | 49.4 | 50.0 | 4.0 | 6.6 | 3.8 | 27.9 | 29.9 | 31.7 | ||||||
| 50 | 50 | 5.2 | 5.6 | 4.4 | 88.4 | 87.1 | 90.1 | 5.2 | 7.8 | 5.2 | 72.8 | 75.3 | 78.8 | ||||||
| 50 | 100 | 5.1 | 5.6 | 4.6 | 100.0 | 99.6 | 100.0 | 5.1 | 6.9 | 5.1 | 99.6 | 99.2 | 99.8 | ||||||
| 50 | 250 | 5.3 | 5.9 | 5.1 | 100.0 | 100.0 | 100.0 | 5.5 | 6.8 | 5.2 | 100.0 | 100.0 | 100.0 | ||||||
| DGP A | DGP B | ||||||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Size | Power | Size | Power | ||||||||||||||||
| Homoskedasticity | |||||||||||||||||||
| 10 | 25 | 5.5 | 7.3 | 5.1 | 11.1 | 12.0 | 11.7 | 3.3 | 5.4 | 3.1 | 10.6 | 11.2 | 11.5 | ||||||
| 10 | 50 | 5.8 | 7.8 | 5.6 | 20.8 | 23.8 | 23.2 | 4.3 | 6.6 | 4.3 | 19.2 | 22.0 | 21.4 | ||||||
| 10 | 100 | 5.8 | 8.1 | 5.9 | 43.2 | 48.2 | 47.4 | 5.2 | 7.7 | 5.4 | 39.2 | 44.2 | 43.4 | ||||||
| 10 | 250 | 5.9 | 8.4 | 6.0 | 80.6 | 83.6 | 84.8 | 5.3 | 8.0 | 5.5 | 78.5 | 81.7 | 82.6 | ||||||
| 50 | 25 | 5.4 | 6.1 | 4.6 | 30.3 | 36.3 | 34.8 | 3.2 | 6.3 | 3.6 | 24.1 | 26.6 | 26.7 | ||||||
| 50 | 50 | 5.4 | 6.4 | 5.0 | 67.3 | 74.4 | 73.5 | 3.9 | 6.3 | 4.2 | 60.2 | 67.1 | 66.4 | ||||||
| 50 | 100 | 5.3 | 6.5 | 5.0 | 96.8 | 97.8 | 98.2 | 4.5 | 6.7 | 4.6 | 94.9 | 96.4 | 96.9 | ||||||
| 50 | 250 | 5.5 | 6.9 | 5.2 | 100 | 100 | 100 | 4.8 | 6.5 | 4.9 | 100 | 100 | 100 | ||||||
| Early negative shift | |||||||||||||||||||
| 10 | 25 | 5.1 | 6.3 | 4.5 | 6.0 | 5.9 | 5.9 | 3.4 | 5.4 | 3.2 | 5.0 | 4.7 | 4.9 | ||||||
| 10 | 50 | 5.6 | 7.1 | 5.0 | 8.6 | 9.6 | 9.4 | 3.3 | 5.4 | 3.1 | 8.6 | 9.2 | 9.2 | ||||||
| 10 | 100 | 5.5 | 7.7 | 5.5 | 18.8 | 21.1 | 20.5 | 4.0 | 6.6 | 4.2 | 17.7 | 19.5 | 19.3 | ||||||
| 10 | 250 | 5.5 | 7.9 | 5.6 | 47.3 | 53.5 | 52.4 | 4.6 | 7.5 | 5.0 | 44.9 | 50.3 | 50.0 | ||||||
| 50 | 25 | 5.1 | 5.9 | 4.4 | 8.8 | 9.3 | 9.3 | 3.4 | 7.1 | 4.1 | 5.7 | 4.5 | 4.8 | ||||||
| 50 | 50 | 5.2 | 6.4 | 4.8 | 23.8 | 28.0 | 26.8 | 2.8 | 6.6 | 3.6 | 20.0 | 19.3 | 19.5 | ||||||
| 50 | 100 | 5.3 | 6.5 | 5.0 | 61.5 | 72.2 | 69.5 | 3.3 | 6.2 | 3.8 | 57.0 | 65.0 | 64.4 | ||||||
| 50 | 250 | 5.3 | 6.5 | 4.9 | 97.4 | 99.5 | 99.3 | 4.2 | 6.5 | 4.5 | 96.3 | 99.2 | 99.1 | ||||||
| Late positive shift | |||||||||||||||||||
| 10 | 25 | 5.3 | 6.1 | 4.4 | 10.5 | 10.3 | 10.5 | 3.4 | 4.0 | 2.6 | 8.3 | 9.0 | 8.8 | ||||||
| 10 | 50 | 5.4 | 6.6 | 4.9 | 18.8 | 18.4 | 18.8 | 4.5 | 5.4 | 3.8 | 14.6 | 15.8 | 15.7 | ||||||
| 10 | 100 | 5.5 | 7.3 | 5.2 | 37.3 | 34.1 | 37.4 | 4.9 | 6.4 | 4.5 | 32.5 | 31.3 | 33.3 | ||||||
| 10 | 250 | 5.7 | 8.1 | 5.8 | 78.0 | 67.5 | 76.2 | 5.6 | 7.7 | 5.4 | 72.6 | 64.0 | 71.5 | ||||||
| 50 | 25 | 5.0 | 5.6 | 4.2 | 24.8 | 22.6 | 24.6 | 3.7 | 4.9 | 3.0 | 16.9 | 17.4 | 17.8 | ||||||
| 50 | 50 | 5.1 | 6.0 | 4.4 | 56.7 | 49.1 | 55.9 | 4.6 | 6.2 | 4.3 | 43.0 | 39.6 | 43.1 | ||||||
| 50 | 100 | 5.4 | 6.4 | 5.0 | 92.0 | 82.9 | 90.6 | 5.2 | 6.6 | 4.9 | 86.1 | 77.8 | 84.8 | ||||||
| 50 | 250 | 5.5 | 6.8 | 5.1 | 100 | 99.6 | 100 | 5.4 | 6.6 | 5.0 | 100 | 99.5 | 100 | ||||||
| DGP A | DGP B | ||||||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Size | Power | Size | Power | ||||||||||||||||
| Homoskedasticity | |||||||||||||||||||
| 10 | 25 | 5.4 | 6.6 | 4.9 | 13.6 | 15.9 | 15.1 | 3.3 | 5.1 | 3.0 | 11.6 | 13.3 | 13.2 | ||||||
| 10 | 50 | 5.7 | 7.4 | 5.3 | 25.2 | 30.4 | 28.9 | 4.4 | 6.4 | 4.3 | 23.1 | 27.1 | 26.4 | ||||||
| 10 | 100 | 5.8 | 7.7 | 5.8 | 48.9 | 54.0 | 53.2 | 4.8 | 7.3 | 5.0 | 46.1 | 50.6 | 50.3 | ||||||
| 10 | 250 | 5.9 | 7.8 | 5.8 | 81.8 | 85.3 | 85.5 | 5.3 | 7.4 | 5.3 | 80.3 | 83.7 | 84.3 | ||||||
| 50 | 25 | 6.1 | 6.9 | 5.1 | 18.7 | 21.0 | 20.6 | 3.3 | 5.5 | 3.2 | 16.1 | 17.5 | 17.2 | ||||||
| 50 | 50 | 6.4 | 7.8 | 5.8 | 35.3 | 37.4 | 37.4 | 4.6 | 6.7 | 4.2 | 32.8 | 35.4 | 34.9 | ||||||
| 50 | 100 | 6.8 | 8.0 | 6.2 | 60.4 | 62.3 | 61.8 | 5.3 | 7.4 | 5.0 | 58.1 | 59.6 | 60.0 | ||||||
| 50 | 250 | 7.0 | 8.5 | 6.5 | 87.2 | 90.5 | 89.8 | 6.4 | 8.2 | 6.1 | 85.9 | 89.3 | 88.4 | ||||||
| Early negative shift | |||||||||||||||||||
| 10 | 25 | 5.1 | 6.3 | 4.4 | 6.2 | 6.6 | 6.6 | 3.4 | 5.6 | 3.3 | 5.3 | 4.8 | 5.1 | ||||||
| 10 | 50 | 5.4 | 6.7 | 4.9 | 10.7 | 12.3 | 11.9 | 3.3 | 5.3 | 3.3 | 9.7 | 10.8 | 10.5 | ||||||
| 10 | 100 | 5.8 | 7.6 | 5.6 | 22.5 | 26.6 | 26.0 | 3.8 | 6.2 | 3.9 | 20.7 | 24.3 | 24.4 | ||||||
| 10 | 250 | 5.7 | 7.6 | 5.6 | 51.8 | 58.7 | 57.9 | 4.7 | 7.1 | 4.8 | 50.3 | 57.5 | 56.4 | ||||||
| 50 | 25 | 5.1 | 5.9 | 4.2 | 7.2 | 7.2 | 7.3 | 3.3 | 5.6 | 3.2 | 4.7 | 3.8 | 4.1 | ||||||
| 50 | 50 | 5.8 | 7.0 | 5.0 | 14.4 | 16.5 | 16.0 | 2.8 | 5.5 | 3.0 | 13.3 | 12.5 | 13.0 | ||||||
| 50 | 100 | 6.3 | 7.3 | 5.6 | 31.5 | 35.7 | 34.4 | 3.8 | 6.6 | 3.9 | 31.0 | 32.6 | 32.7 | ||||||
| 50 | 250 | 6.4 | 7.9 | 5.7 | 63.4 | 68.0 | 67.1 | 5.3 | 7.7 | 5.2 | 61.2 | 65.1 | 64.0 | ||||||
| Late positive shift | |||||||||||||||||||
| 10 | 25 | 5.3 | 5.7 | 4.3 | 11.8 | 12.5 | 12.6 | 3.6 | 3.7 | 2.6 | 8.9 | 10.5 | 10.1 | ||||||
| 10 | 50 | 5.3 | 6.2 | 4.5 | 21.9 | 22.7 | 23.4 | 4.4 | 5.4 | 3.8 | 17.1 | 18.2 | 18.2 | ||||||
| 10 | 100 | 5.8 | 7.3 | 5.4 | 42.0 | 38.7 | 42.3 | 5.1 | 6.5 | 4.6 | 36.1 | 36.0 | 38.1 | ||||||
| 10 | 250 | 5.9 | 7.6 | 5.8 | 79.8 | 71.1 | 78.3 | 5.7 | 7.3 | 5.4 | 76.2 | 68.4 | 75.2 | ||||||
| 50 | 25 | 5.7 | 5.6 | 4.2 | 16.3 | 16.9 | 17.0 | 3.5 | 4.2 | 2.7 | 11.9 | 13.1 | 12.7 | ||||||
| 50 | 50 | 6.3 | 6.5 | 5.0 | 30.1 | 30.1 | 31.0 | 4.6 | 5.5 | 3.8 | 24.3 | 25.6 | 25.6 | ||||||
| 50 | 100 | 6.4 | 7.3 | 5.6 | 53.6 | 48.5 | 52.6 | 5.7 | 6.7 | 4.9 | 47.4 | 44.5 | 47.5 | ||||||
| 50 | 250 | 6.8 | 8.0 | 6.2 | 87.5 | 78.0 | 85.5 | 6.4 | 7.4 | 5.6 | 84.2 | 75.8 | 82.8 | ||||||
| DGP A | DGP B | ||||||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Size | Power | Size | Power | ||||||||||||||||
| Homoskedasticity | |||||||||||||||||||
| 10 | 25 | 4.8 | 6.3 | 4.6 | 20.0 | 25.2 | 24.1 | 3.4 | 6.3 | 3.8 | 15.2 | 18.0 | 18.2 | ||||||
| 10 | 50 | 5.0 | 6.8 | 5.1 | 41.2 | 53.6 | 52.0 | 4.0 | 6.4 | 4.3 | 36.1 | 46.5 | 45.2 | ||||||
| 10 | 100 | 4.9 | 6.7 | 5.1 | 77.7 | 85.9 | 86.9 | 4.3 | 6.4 | 4.7 | 72.9 | 83.1 | 83.5 | ||||||
| 10 | 250 | 5.1 | 6.8 | 5.3 | 99.0 | 98.5 | 99.6 | 4.7 | 6.9 | 5.2 | 98.6 | 98.2 | 99.5 | ||||||
| 50 | 25 | 5.1 | 5.6 | 4.5 | 59.5 | 76.4 | 73.4 | 3.1 | 8.9 | 5.1 | 45.2 | 54.3 | 54.2 | ||||||
| 50 | 50 | 5.0 | 5.8 | 4.5 | 96.2 | 99.1 | 99.2 | 3.8 | 7.1 | 4.5 | 91.8 | 97.5 | 97.5 | ||||||
| 50 | 100 | 5.2 | 5.8 | 4.8 | 100 | 100 | 100 | 3.9 | 6.1 | 4.2 | 100 | 100 | 100 | ||||||
| 50 | 250 | 4.8 | 6.0 | 4.9 | 100 | 100 | 100 | 4.7 | 6.2 | 4.8 | 100 | 100 | 100 | ||||||
| Early negative shift | |||||||||||||||||||
| 10 | 25 | 5.0 | 6.0 | 4.4 | 8.0 | 9.5 | 9.1 | 3.5 | 6.7 | 3.8 | 6.5 | 6.1 | 6.4 | ||||||
| 10 | 50 | 5.1 | 6.6 | 4.9 | 15.8 | 20.7 | 19.5 | 3.2 | 6.5 | 3.9 | 13.6 | 15.4 | 15.9 | ||||||
| 10 | 100 | 4.9 | 6.4 | 4.8 | 37.6 | 52.4 | 49.4 | 3.7 | 6.4 | 4.2 | 32.7 | 45.0 | 43.0 | ||||||
| 10 | 250 | 4.8 | 6.7 | 5.1 | 81.0 | 92.8 | 92.8 | 4.4 | 6.8 | 4.8 | 77.5 | 90.3 | 90.4 | ||||||
| 50 | 25 | 5.1 | 5.6 | 4.3 | 14.7 | 18.0 | 17.5 | 3.7 | 10.6 | 5.9 | 7.2 | 4.4 | 5.3 | ||||||
| 50 | 50 | 5.0 | 5.7 | 4.6 | 48.7 | 64.3 | 61.6 | 2.9 | 8.8 | 5.1 | 35.1 | 37.0 | 38.1 | ||||||
| 50 | 100 | 5.0 | 5.7 | 4.7 | 94.0 | 98.9 | 98.7 | 3.2 | 7.5 | 4.6 | 89.1 | 95.8 | 96.0 | ||||||
| 50 | 250 | 4.9 | 5.8 | 4.8 | 100 | 100 | 100 | 3.9 | 6.7 | 4.6 | 100 | 100 | 100 | ||||||
| Late positive shift | |||||||||||||||||||
| 10 | 25 | 4.9 | 5.5 | 4.0 | 16.5 | 17.6 | 18.3 | 3.7 | 4.6 | 3.1 | 11.9 | 13.2 | 13.1 | ||||||
| 10 | 50 | 4.9 | 6.0 | 4.6 | 33.9 | 35.4 | 37.0 | 4.6 | 5.9 | 4.3 | 24.8 | 27.7 | 28.5 | ||||||
| 10 | 100 | 4.9 | 6.1 | 4.7 | 69.5 | 67.0 | 72.5 | 4.6 | 6.1 | 4.5 | 60.7 | 60.4 | 64.7 | ||||||
| 10 | 250 | 5.0 | 6.9 | 5.1 | 98.6 | 94.0 | 98.6 | 4.9 | 6.8 | 5.1 | 97.6 | 93.1 | 97.7 | ||||||
| 50 | 25 | 5.0 | 5.2 | 3.9 | 45.7 | 48.4 | 51.0 | 4.3 | 6.4 | 4.0 | 26.2 | 30.9 | 30.8 | ||||||
| 50 | 50 | 5.1 | 5.5 | 4.4 | 88.4 | 87.0 | 90.9 | 4.9 | 7.5 | 5.1 | 74.2 | 76.1 | 79.3 | ||||||
| 50 | 100 | 5.1 | 5.7 | 4.7 | 99.9 | 99.7 | 100 | 4.9 | 6.9 | 4.9 | 99.6 | 99.2 | 99.8 | ||||||
| 50 | 250 | 5.1 | 5.8 | 4.8 | 100 | 100 | 100 | 5.2 | 6.7 | 5.3 | 100 | 100 | 100 | ||||||
References
- Ball, Laurence, and Stephen Cecchetti. 1990. Inflation and Uncertainty at Short and Long Horizons. Brookings Papers on Economic Activity 21: 215–54. [Google Scholar] [CrossRef]
- Baltagi, Badi H., Georges Bresson, and Alain Pirotte. 2007. Panel unit root tests and spatial dependence. Journal of Applied Econometrics 22: 339–60. [Google Scholar] [CrossRef]
- Barsky, Robert B. 1987. The Fisher hypothesis and the forecastability and persistence of inflation. Journal of Monetary Economics 19: 3–24. [Google Scholar] [CrossRef] [Green Version]
- Basher, Syed A., and Joakim Westerlund. 2008. Is there really a unit root in the inflation rate? More evidence from panel data models. Applied Economics Letters 15: 161–64. [Google Scholar] [CrossRef]
- Breitung, Jörg, and Samarjit Das. 2005. Panel unit root tests under cross-sectional dependence. Statistica Neerlandica 59: 414–33. [Google Scholar] [CrossRef]
- Breitung, Jörg, and M. Hashem Pesaran. 2008. Unit Roots and Cointegration in Panels. In Advanced Studies in Theoretical and Applied Econometrics. Berlin/Heidelberg: Springer, pp. 279–322. [Google Scholar] [CrossRef] [Green Version]
- Caner, Mehmet, and Lutz Kilian. 2001. Size distortions of tests of the null hypothesis of stationarity: Evidence and implications for the PPP debate. Journal of International Money and Finance 20: 639–57. [Google Scholar] [CrossRef]
- Cavaliere, Giuseppe, and A. M. Robert Taylor. 2007. Testing for unit roots in time series models with non-stationary volatility. Journal of Econometrics 140: 919–47. [Google Scholar] [CrossRef]
- Chang, Yoosoon. 2002. Nonlinear IV unit root tests in panels with cross-sectional dependency. Journal of Econometrics 110: 261–92. [Google Scholar] [CrossRef]
- Culver, Sarah E., and David H. Papell. 1997. Is there a unit root in the inflation rate? Evidence from sequential break and panel data models. Journal of Applied Econometrics 12: 435–44. [Google Scholar] [CrossRef]
- Demetrescu, Matei, and Christoph Hanck. 2012a. A simple nonstationary-volatility robust panel unit root test. Economics Letters 117: 10–13. [Google Scholar] [CrossRef]
- Demetrescu, Matei, and Christoph Hanck. 2012b. Unit Root Testing in Heteroscedastic Panels Using the Cauchy Estimator. Journal of Business & Economic Statistics 30: 256–64. [Google Scholar] [CrossRef]
- Elliott, Graham, Thomas J. Rothenberg, and James H. Stock. 1996. Efficient Tests for an Autoregressive Unit Root. Econometrica 64: 813–36. [Google Scholar] [CrossRef]
- Fisher, R. A. 1932. Statistical Methods for Research Workers. London: Oliver and Boyd. [Google Scholar]
- Gregory, Allan W., Alfred A. Haug, and Nicoletta Lomuto. 2004. Mixed signals among tests for cointegration. Journal of Applied Econometrics 19: 89–98. [Google Scholar] [CrossRef] [Green Version]
- Hanck, Christoph. 2012. Do Panel Cointegration Tests Produce “Mixed Signals”? Annals of Economics and Statistics, 299–310. [Google Scholar] [CrossRef]
- Hanck, Christoph. 2013. An Intersection Test for Panel Unit Roots. Econometric Reviews 32: 183–203. [Google Scholar] [CrossRef]
- Hanck, Christoph, and Robert Czudaj. 2015. Nonstationary-Volatility Robust Panel Unit Root Tests and the Great Moderation. AStA Advances in Statistical Analysis 99: 161–87. [Google Scholar] [CrossRef]
- Hartung, Joachim. 1999. A Note on Combining Dependent Tests of Significance. Biometrical Journal 41: 849–55. [Google Scholar] [CrossRef]
- Harvey, David I., Stephen J. Leybourne, and A. M. Robert Taylor. 2009. Unit Root Testing in Practice: Dealing with Uncertainty over the Trend and Initial Condition. Econometric Theory 25: 587–636. [Google Scholar] [CrossRef]
- Herwartz, Helmut, and Florian Siedenburg. 2008. Homogenous panel unit root tests under cross sectional dependence: Finite sample modifications and the wild bootstrap. Computational Statistics & Data Analysis 53: 137–50. [Google Scholar] [CrossRef]
- Herwartz, Helmut, Florian Siedenburg, and Yabibal Walle. 2016. Heteroskedasticity Robust Panel Unit Root Testing Under Variance Breaks in Pooled Regressions. Econometric Reviews 35: 727–50. [Google Scholar] [CrossRef]
- Herwartz, Helmut, and Yabibal M. Walle. 2018. A powerful wild bootstrap diagnosis of panel unit roots under linear trends and time-varying volatility. Computational Statistics 33: 379–411. [Google Scholar] [CrossRef]
- Hurlin, Christophe. 2010. What would Nelson and Plosser find had they used panel unit root tests? Applied Economics 42: 1515–31. [Google Scholar] [CrossRef]
- Johansen, Soren. 1992. Testing weak exogeneity and the order of cointegration in UK money demand data. Journal of Policy Modeling 14: 313–34. [Google Scholar] [CrossRef]
- Johansen, Soren, and Katarina Juselius. 2001. Controlling Inflation in a Cointegrated Vector Autoregressive Model with an Application to US Data. Discussion Papers 01–03. Copenhagen: Department of Economics, University of Copenhagen. [Google Scholar] [CrossRef]
- Levin, Andrew, Chien-Fu Lin, and Chia-Shang James Chu. 2002. Unit root tests in panel data: Asymptotic and finite-sample properties. Journal of Econometrics 108: 1–24. [Google Scholar] [CrossRef]
- Maddala, G. S., and In-Moo Kim. 1999. Unit Roots, Cointegration, and Structural Change. Cambridge: Cambridge University Press. [Google Scholar] [CrossRef]
- Mullineux, Andy, Victor Murinde, and Rudra Sensarma. 2010. Convergence of Corporate Finance Patterns in Europe. Economic Issues Journal Articles 15: 49–68. [Google Scholar]
- Müller, Ulrich K., and Graham Elliott. 2003. Tests for Unit Roots and the Initial Condition. Econometrica 71: 1269–1286. [Google Scholar] [CrossRef] [Green Version]
- Nelson, Charles R., and Charles I. Plosser. 1982. Trends and random walks in macroeconomic time series: Some evidence and implications. Journal of Monetary Economics 10: 139–162. [Google Scholar] [CrossRef]
- O’Connell, Paul G. 1998. The overvaluation of purchasing power parity. Journal of International Economics 44: 1–19. [Google Scholar] [CrossRef]
- Pesaran, M. Hashem. 2007. A simple panel unit root test in the presence of cross-section dependence. Journal of Applied Econometrics 22: 265–312. [Google Scholar] [CrossRef] [Green Version]
- Rose, Andrew K. 1988. Is the Real Interest Rate Stable? The Journal of Finance 43: 1095–112. [Google Scholar] [CrossRef]
- Sarkar, Sanat K. 1998. Some Probability Inequalities for Ordered MTP2 Random Variables: A Proof of the Simes Conjecture. The Annals of Statistics 26: 494–504. [Google Scholar] [CrossRef]
- Sarkar, Sanat K. 2008. On the Simes inequality and its generalization. In Beyond Parametrics in Interdisciplinary Research: Festschrift in Honor of Professor Pranab K. Sen. Bethesda: Institute of Mathematical Statistics, pp. 231–42. [Google Scholar] [CrossRef]
- Shin, Dong W., and Seungho Kang. 2006. An instrumental variable approach for panel unit root tests under cross-sectional dependence. Journal of Econometrics 134: 215–34. [Google Scholar] [CrossRef]
- Simes, R. John. 1986. An improved Bonferroni procedure for multiple tests of significance. Biometrika 73: 751–54. [Google Scholar] [CrossRef]
- So, Beong S., and Dong W. Shin. 1999. Cauchy Estimators for Autoregressive Processes with Applications to Unit Root Tests and Confidence Intervals. Econometric Theory 15: 165–76. [Google Scholar] [CrossRef]
- So, Beong S., and Dong W. Shin. 2001. Recursive Mean Adjustment for Unit Root Tests. Journal of Time Series Analysis 22: 595–612. [Google Scholar] [CrossRef]
- Stouffer, Samuel A., Edward A. Suchman, Leland C. DeVinney, Shirley A. Star, and Robin M. Williams. 1949. The American Soldier. Vol. 1: Adjustment During Army Life. Studies in Social Psychology in World War II. Princeton: Princeton University Press. [Google Scholar] [CrossRef]
- White, Halbert. 1980. A Heteroskedasticity–Consistent Covariance Matrix Estimator and a Direct Test for Heteroskedasticity. Econometrica 48: 817–38. [Google Scholar] [CrossRef]
| 1 | See, e.g., Hanck and Czudaj (2015) for simulation evidence on the implications of heteroskedasticity for the PURT statistic proposed in Breitung and Das (2005). |
| 2 | As pointed out in Herwartz et al. (2016), does not require synchronous covariance switching and thus permits that, e.g., only a fraction of the series exhibits distinct variance regimes. |
| 3 | Here, ; with from LU decomposing and the are consistent residuals obtained from estimation under the null. |
| 4 | Detrending procedures as proposed by Chang (2002) lead to a nonzero expectation of the numerators in (3) and (4) under forms of heteroskedasticity allowed by such that approximations by a Gaussian distribution are invalid. See Herwartz and Walle (2018) for a more detailed argument and an alternative bootstrap procedure. |
| 5 | A spatial arrangement of economic entities that could be mapped by this choice of is when the correlation between units depends on their economic distance. |
| 6 | Breitung and Pesaran (2008) distinguished between weak dependence, where and strong dependence where, , as . |
| 7 | Gregory et al. (2004) found that common time series cointegration tests tend to produce conflicting test decisions. Hanck (2012) confirmed that the problem persists for panel cointegration tests and does not alleviate with growing sample size. |
| 8 | |
| 9 | Other applications to panel unit root testing we are aware of are Hanck (2013), who suggested a PURT based on combining the significance of augmented Dickey-Fuller (ADF) tests by Equation (13) and provides simulation evidence for the procedure to work well in cross-dependent panels and extensions by Hanck and Czudaj (2015) which additionally accommodate for nonstationary volatility. |
| 10 | ADF and KPSS tests struggle to distinguish between a unit root and stationarity for highly persistent but stationary time series. See, e.g., Maddala and Kim (1999) or Caner and Kilian (2001). |
| 11 | See the notes in Table 2 for groupings. |
| 12 | The are OLS residuals from fitting AR(1) models to the series. |




| CS Independence | SAR(1) | |||||||||||||||||
| Joint | Mixed | Joint | Joint | Mixed | Joint | |||||||||||||
| Homoskedasticity | ||||||||||||||||||
| 10 | 25 | 75.7 | 2.3 | 5.4 | 13.0 | 5.8 | 12.2 | 87.8 | 3.1 | 3.9 | 7.6 | 3.5 | 4.4 | |||||
| 10 | 50 | 75.7 | 2.3 | 5.7 | 34.6 | 6.1 | 21.5 | 87.7 | 3.0 | 4.3 | 17.1 | 4.5 | 8.6 | |||||
| 10 | 100 | 76.0 | 2.4 | 5.6 | 72.8 | 4.1 | 14.4 | 87.6 | 3.0 | 4.5 | 39.0 | 5.5 | 12.4 | |||||
| 10 | 250 | 75.7 | 2.4 | 5.8 | 97.6 | 1.3 | 0.9 | 87.5 | 3.0 | 4.6 | 78.0 | 3.4 | 7.9 | |||||
| 50 | 25 | 74.9 | 2.2 | 5.4 | 54.8 | 4.8 | 20.2 | 85.0 | 3.0 | 3.9 | 23.4 | 6.3 | 9.7 | |||||
| 50 | 50 | 74.6 | 2.3 | 5.2 | 95.7 | 0.5 | 3.4 | 84.6 | 2.8 | 4.2 | 61.5 | 5.4 | 11.5 | |||||
| 50 | 100 | 73.8 | 2.2 | 5.3 | 100 | 0 | 0 | 84.5 | 3.0 | 4.0 | 95.6 | 1.1 | 2.1 | |||||
| 50 | 250 | 74.4 | 2.3 | 5.4 | 100 | 0 | 0 | 84.8 | 2.9 | 4.3 | 100 | 0 | 0 | |||||
| Early negative shift | ||||||||||||||||||
| 10 | 25 | 76.0 | 2.3 | 5.3 | 4.3 | 3.4 | 4.6 | 89.2 | 3.1 | 3.8 | 3.7 | 2.3 | 2.2 | |||||
| 10 | 50 | 75.7 | 2.4 | 5.3 | 10.5 | 5.0 | 10.7 | 88.5 | 3.2 | 4.1 | 6.6 | 3.1 | 4.6 | |||||
| 10 | 100 | 75.7 | 2.4 | 5.5 | 30.6 | 5.8 | 22.7 | 87.6 | 2.9 | 4.8 | 16.2 | 4.0 | 9.0 | |||||
| 10 | 250 | 75.9 | 2.4 | 5.8 | 77.0 | 2.4 | 16.1 | 87.6 | 2.9 | 5.0 | 44.7 | 4.2 | 14.5 | |||||
| 50 | 25 | 75.4 | 2.3 | 5.2 | 8.7 | 5.5 | 7.7 | 85.6 | 3.0 | 3.9 | 5.5 | 3.2 | 3.4 | |||||
| 50 | 50 | 74.4 | 2.3 | 5.3 | 41.2 | 5.8 | 21.7 | 85.5 | 3.0 | 4.3 | 19.0 | 5.4 | 9.9 | |||||
| 50 | 100 | 74.2 | 2.2 | 5.5 | 92.8 | 0 | 0 | 85.0 | 3.1 | 4.1 | 58.2 | 4.3 | 15.2 | |||||
| 50 | 250 | 73.5 | 2.3 | 5.4 | 100 | 0 | 0 | 84.6 | 2.9 | 4.4 | 97.4 | 0.1 | 2.1 | |||||
| Late positive shift | ||||||||||||||||||
| 10 | 25 | 74.9 | 2.2 | 5.5 | 9.1 | 6.3 | 8.2 | 87.3 | 2.9 | 4.2 | 6.4 | 4.1 | 3.9 | |||||
| 10 | 50 | 74.9 | 2.2 | 5.8 | 24.2 | 9.4 | 13.5 | 86.9 | 3.0 | 4.4 | 13.4 | 5.6 | 6.3 | |||||
| 10 | 100 | 75.0 | 2.3 | 5.7 | 85.4 | 10.1 | 11.5 | 87.0 | 2.8 | 4.8 | 29.5 | 8.6 | 9.0 | |||||
| 10 | 250 | 75.5 | 2.3 | 5.8 | 94.4 | 4.1 | 0.7 | 87.0 | 2.9 | 5.2 | 67.9 | 11.1 | 5.0 | |||||
| 50 | 25 | 73.1 | 2.1 | 5.3 | 33.2 | 11.2 | 14.0 | 84.4 | 2.8 | 4.1 | 15.7 | 8.2 | 6.0 | |||||
| 50 | 50 | 73.3 | 2.2 | 5.8 | 81.7 | 6.6 | 5.6 | 84.3 | 2.8 | 4.3 | 42.8 | 13.1 | 6.6 | |||||
| 50 | 100 | 73.6 | 2.1 | 5.9 | 99.7 | 0.2 | 0.0 | 84.6 | 2.9 | 4.5 | 82.6 | 9.7 | 1.6 | |||||
| 50 | 250 | 74.3 | 2.3 | 5.8 | 100 | 0 | 0 | 84.6 | 2.7 | 5.0 | 99.7 | 0.3 | 0 | |||||
| Equicorrelation | Common Factor | |||||||||||||||||
| joint | mixed | joint | joint | mixed | joint | |||||||||||||
| Homoskedasticity | ||||||||||||||||||
| 10 | 25 | 86.5 | 2.8 | 4.5 | 9.7 | 3.9 | 6.2 | 76.1 | 2.3 | 5.4 | 13.6 | 6.3 | 11.6 | |||||
| 10 | 50 | 86.1 | 2.7 | 5.0 | 21.4 | 4.5 | 10.7 | 75.7 | 2.4 | 5.6 | 35.6 | 6.5 | 20.2 | |||||
| 10 | 100 | 85.6 | 2.7 | 5.3 | 45.8 | 4.5 | 11.9 | 75.1 | 2.4 | 5.6 | 73.6 | 4.5 | 13.4 | |||||
| 10 | 250 | 85.8 | 2.6 | 5.4 | 79.8 | 2.9 | 7.5 | 75.7 | 2.3 | 5.6 | 97.9 | 1.2 | 0.8 | |||||
| 50 | 25 | 91.7 | 3.0 | 4.1 | 16.5 | 3.7 | 5.3 | 74.7 | 2.3 | 5.4 | 55.1 | 5.4 | 19.3 | |||||
| 50 | 50 | 91.6 | 3.0 | 4.5 | 33.7 | 4.3 | 6.8 | 74.0 | 2.2 | 5.5 | 95.8 | 0.5 | 3.2 | |||||
| 50 | 100 | 91.2 | 3.0 | 4.8 | 59.8 | 3.8 | 6.0 | 74.2 | 2.3 | 5.5 | 100 | 0 | 0 | |||||
| 50 | 250 | 91.2 | 2.8 | 5.2 | 87.8 | 1.1 | 4.6 | 74.2 | 2.2 | 5.5 | 100 | 0 | 0 | |||||
| Early negative shift | ||||||||||||||||||
| 10 | 25 | 87.3 | 2.6 | 4.7 | 3.6 | 2.6 | 2.9 | 76.1 | 2.3 | 5.3 | 4.5 | 3.5 | 5.0 | |||||
| 10 | 50 | 86.8 | 2.8 | 4.8 | 7.9 | 3.4 | 5.5 | 76.0 | 2.3 | 5.7 | 11.1 | 5.0 | 11.4 | |||||
| 10 | 100 | 86.4 | 2.6 | 5.7 | 20.0 | 4.3 | 10.4 | 76.2 | 2.4 | 5.6 | 31.6 | 5.7 | 22.6 | |||||
| 10 | 250 | 85.8 | 2.6 | 5.6 | 50.0 | 3.5 | 13.0 | 75.8 | 2.4 | 5.6 | 78.2 | 2.1 | 15.7 | |||||
| 50 | 25 | 92.8 | 3.3 | 3.3 | 4.8 | 2.3 | 2.0 | 75.7 | 2.2 | 5.6 | 9.5 | 5.5 | 7.9 | |||||
| 50 | 50 | 92.4 | 3.2 | 4.1 | 13.1 | 3.0 | 4.6 | 75.5 | 2.2 | 5.5 | 42.9 | 5.7 | 20.9 | |||||
| 50 | 100 | 91.8 | 3.1 | 4.4 | 31.7 | 3.2 | 7.3 | 74.7 | 2.3 | 5.4 | 93.6 | 0.4 | 5.2 | |||||
| 50 | 250 | 91.4 | 2.9 | 5.0 | 64.5 | 2.0 | 7.3 | 74.6 | 2.3 | 5.4 | 100 | 0 | 0 | |||||
| Late positive shift | ||||||||||||||||||
| 10 | 25 | 85.2 | 2.7 | 4.6 | 7.5 | 4.4 | 5.0 | 74.9 | 2.2 | 5.6 | 9.8 | 6.7 | 7.8 | |||||
| 10 | 50 | 85.3 | 2.5 | 5.1 | 15.9 | 5.9 | 8.2 | 75.2 | 2.4 | 5.5 | 23.9 | 9.8 | 12.9 | |||||
| 10 | 100 | 85.6 | 2.6 | 5.7 | 34.9 | 8.5 | 9.0 | 75.0 | 2.4 | 5.6 | 58.2 | 11.0 | 10.9 | |||||
| 10 | 250 | 85.7 | 2.6 | 5.8 | 71.5 | 9.4 | 4.3 | 75.5 | 2.4 | 5.9 | 94.4 | 4.2 | 0.6 | |||||
| 50 | 25 | 90.8 | 2.9 | 4.3 | 12.2 | 4.8 | 4.3 | 73.5 | 2.2 | 5.6 | 34.0 | 11.9 | 13.1 | |||||
| 50 | 50 | 90.7 | 2.9 | 4.7 | 26.2 | 6.5 | 5.9 | 73.6 | 2.1 | 5.9 | 81.8 | 7.0 | 5.3 | |||||
| 50 | 100 | 90.7 | 3.0 | 4.9 | 48.2 | 8.7 | 4.9 | 74.2 | 2.1 | 5.9 | 99.6 | 0.3 | 0 | |||||
| 50 | 250 | 90.8 | 3.0 | 5.2 | 80.2 | 8.9 | 1.8 | 74.2 | 2.3 | 5.7 | 100 | 0 | 0 | |||||
| Culver & Papell | OECD Database | |||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 1957-02–1994-09 | 1961-04–2019-03 | 1961-04–1989-12 | 1990-01–2019-03 | |||||||||||||
| Grouping | ||||||||||||||||
| (a) | −3.39 | −3.44 | 0 | −3.63 | −3.16 | 0 | −1.43 | −2.31 | 1 | −0.49 | −1.62 | 1 | ||||
| (0.0004) | (0.0008) | (0.0764) | (0.0104) | (0.3121) | (0.0526) | |||||||||||
| (b) | −3.46 | −3.43 | 0 | −3.50 | −3.15 | 0 | −1.40 | −2.30 | 1 | −0.51 | −1.62 | 1 | ||||
| (0.0002) | (0.0008) | (0.0808) | (0.0107) | (0.3050) | (0.0526) | |||||||||||
| (c) | −3.48 | −3.46 | 0 | −3.51 | −3.08 | 0 | −1.20 | −2.19 | 1 | −0.55 | −1.54 | 1 | ||||
| (0.0004) | (0.0010) | (0.1151) | (0.0143) | (0.2912) | (0.0618) | |||||||||||
| (d) | −3.17 | −3.19 | 0 | −3.68 | −2.99 | 0 | −1.48 | −2.14 | 1 | −0.26 | −1.54 | 1 | ||||
| (0.0004) | (0.0014) | (0.0694) | (0.0162) | (0.3974) | (0.0618) | |||||||||||
| (e) | −3.58 | −3.46 | 0 | −3.35 | −3.04 | 0 | −1.15 | −2.16 | 1 | −0.57 | −1.53 | 1 | ||||
| (0.0004) | (0.0012) | (0.1251) | (0.0154) | (0.2843) | (0.063) | |||||||||||
| (f) | −3.24 | −3.18 | 0 | −3.53 | −2.98 | 0 | −1.45 | −2.12 | 1 | −0.26 | −1.53 | 1 | ||||
| (0.0004) | (0.0014) | (0.0735) | (0.017) | (0.3974) | (0.063) | |||||||||||
| (g) | −3.27 | −3.19 | 0 | −3.56 | −2.89 | 0 | −1.25 | −1.99 | 1 | −0.31 | −1.45 | 1 | ||||
| (0.0002) | (0.0019) | (0.1056) | (0.0233) | (0.3783) | (0.0735) | |||||||||||
| (h) | −3.37 | −3.19 | 0 | −3.39 | −2.85 | 0 | −1.20 | −1.95 | 1 | −0.31 | −1.44 | 1 | ||||
| (0.0003) | (0.0022) | (0.1151) | (0.0256) | (0.3783) | (0.0749) | |||||||||||
| (i) | −1.87 | −1.76 | 0 | −3.85 | −2.44 | 0 | −1.67 | −1.71 | 0 | −0.02 | −1.41 | 1 | ||||
| (0.0001) | (0.0073) | (0.0475) | (0.0436) | (0.4920) | (0.0793) | |||||||||||
| (j) | −3.00 | −3.13 | 0 | −2.09 | −2.60 | 1 | −0.62 | −1.92 | 1 | −0.93 | −1.54 | 1 | ||||
| (0.0183) | (0.0047) | (0.2676) | (0.0274) | (0.1762) | (0.0618) | |||||||||||
| (k) | −2.99 | −2.82 | 0 | −2.97 | −2.28 | 0 | −0.67 | −1.50 | 0 | 0.14 | −1.07 | 1 | ||||
| (0.0015) | (0.0113) | (0.2514) | (0.0668) | (0.5557) | (0.1423) | |||||||||||
| Level | S | S | S | S | S | S | S | |||||||||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Culver & Pappel (1997) data | ||||||||||||||||||||||||||||
| 1% | 23.1 | 30.8 | 23.1 | 11.5 | 28.2 | 23.1 | 26.9 | 30.1 | 26.6 | 42.1 | 30.8 | 36.4 | 57.9 | 40.6 | 48.3 | 72.8 | 57.6 | 64.9 | 83.9 | 74.7 | 79.7 | |||||||
| 5% | 15.4 | 30.8 | 30.8 | 47.4 | 32.1 | 35.9 | 41.6 | 43.4 | 42.7 | 39.2 | 55.0 | 43.8 | 33.3 | 54.8 | 44 | 23.5 | 41.4 | 31.8 | 15.3 | 25.3 | 19.9 | |||||||
| 10% | 23.1 | 7.7 | 7.7 | 12.8 | 19.2 | 15.4 | 13.3 | 17.1 | 14.3 | 11.9 | 11.9 | 14.4 | 6 | 4.6 | 6.1 | 3.5 | 1 | 3.3 | 0.8 | 0 | 0.4 | |||||||
| >10% (no rej.) | 38.5 | 30.8 | 38.5 | 28.2 | 20.5 | 25.6 | 18.2 | 9.4 | 16.4 | 6.9 | 2.4 | 5.5 | 2.8 | 0 | 1.6 | 0.2 | 0 | 0 | 0 | 0 | 0 | |||||||
| 1961-04 to 2019-03 | ||||||||||||||||||||||||||||
| 1% | 7.7 | 0 | 0 | 0.3 | 6.4 | 6.4 | 22.7 | 19.9 | 17.5 | 37.1 | 38.9 | 33.8 | 52.1 | 62.3 | 53.6 | 69.4 | 79.8 | 72.6 | 83.7 | 92.5 | 87.1 | |||||||
| 5% | 15.4 | 38.5 | 30.8 | 30.8 | 48.7 | 33.3 | 40.6 | 59.4 | 49.3 | 44.1 | 55.9 | 52.6 | 40.4 | 36.8 | 42.4 | 28.4 | 20.2 | 26.6 | 16.0 | 7.5 | 12.9 | |||||||
| 10% | 7.7 | 15.4 | 15.4 | 20.5 | 26.9 | 25.6 | 20.3 | 19.2 | 22.7 | 14.1 | 5.2 | 11.9 | 6.5 | 0.9 | 3.8 | 2.2 | 0 | 0.8 | 0.3 | 0 | 0 | |||||||
| >10% (no rej.) | 69.2 | 46.2 | 53.8 | 38.5 | 17.9 | 34.6 | 16.4 | 1.4 | 10.5 | 4.8 | 0 | 1.7 | 1.0 | 0 | 0.2 | 0.1 | 0 | 0 | 0 | 0 | 0 | |||||||
| 1961-04 to 1989-12 | ||||||||||||||||||||||||||||
| 1% | 7.7 | 0 | 0 | 7.7 | 0 | 3.8 | 11.9 | 0.3 | 6.6 | 19.3 | 1.8 | 10.6 | 27.3 | 6.3 | 16.3 | 37.3 | 18.9 | 25.0 | 48.3 | 38.7 | 37.4 | |||||||
| 5% | 15.4 | 7.7 | 15.4 | 20.5 | 17.9 | 19.2 | 32.9 | 37.4 | 29.0 | 40.6 | 66.4 | 44.3 | 45.3 | 80.8 | 56.3 | 46.7 | 76.6 | 62.6 | 43.5 | 60.4 | 58.0 | |||||||
| 10% | 7.7 | 23.1 | 7.7 | 19.2 | 38.5 | 17.9 | 19.9 | 44.1 | 28.0 | 20.6 | 27.1 | 30.6 | 18.3 | 12.2 | 23.9 | 12.3 | 4.5 | 11.7 | 7.3 | 0.9 | 4.6 | |||||||
| >10% (no rej.) | 100 | 84.6 | 92.3 | 52.6 | 43.6 | 59.0 | 35.3 | 18.2 | 36.4 | 19.6 | 4.6 | 14.4 | 9.1 | 0.7 | 3.5 | 3.7 | 0 | 0.8 | 1.0 | 0 | 0 | |||||||
| 1990-01 to 2019-03 | ||||||||||||||||||||||||||||
| 1% | 0 | 0 | 0 | 0 | 3.8 | 1.3 | 0.3 | 4.9 | 2.4 | 0.1 | 4.8 | 1.7 | 0 | 3.9 | 1.2 | 0 | 3.1 | 0.6 | 0 | 2.0 | 0.3 | |||||||
| 5% | 0 | 7.7 | 0 | 13.8 | 12.8 | 9.0 | 4.5 | 14.7 | 9.4 | 2.9 | 18.3 | 10.8 | 2.5 | 20.0 | 11.9 | 1.3 | 20.5 | 10.8 | 0.7 | 20.6 | 9.5 | |||||||
| 10% | 0 | 7.7 | 7.7 | 3.8 | 12.8 | 6.4 | 5.9 | 16.1 | 9.1 | 6.2 | 15.5 | 11.0 | 4.8 | 18.9 | 11.2 | 4.5 | 22.0 | 12.6 | 3.4 | 27.0 | 13.0 | |||||||
| >10% (no rej.) | 100 | 84.6 | 92.3 | 92.3 | 70.5 | 83.3 | 89.2 | 64.3 | 79.0 | 90.8 | 61.4 | 76.5 | 92.7 | 57.3 | 75.8 | 94.1 | 54.4 | 75.9 | 95.9 | 50.3 | 77.2 | |||||||
© 2019 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Arnold, M.C.; Hanck, C. On Combining Evidence from Heteroskedasticity Robust Panel Unit Root Tests in Pooled Regressions. J. Risk Financial Manag. 2019, 12, 117. https://doi.org/10.3390/jrfm12030117
Arnold MC, Hanck C. On Combining Evidence from Heteroskedasticity Robust Panel Unit Root Tests in Pooled Regressions. Journal of Risk and Financial Management. 2019; 12(3):117. https://doi.org/10.3390/jrfm12030117
Chicago/Turabian StyleArnold, Martin C., and Christoph Hanck. 2019. "On Combining Evidence from Heteroskedasticity Robust Panel Unit Root Tests in Pooled Regressions" Journal of Risk and Financial Management 12, no. 3: 117. https://doi.org/10.3390/jrfm12030117
APA StyleArnold, M. C., & Hanck, C. (2019). On Combining Evidence from Heteroskedasticity Robust Panel Unit Root Tests in Pooled Regressions. Journal of Risk and Financial Management, 12(3), 117. https://doi.org/10.3390/jrfm12030117