Main Points of Criticism
The purpose of this note is to clear up some confusion regarding market power, the Lerner index and estimation of marginal cost.
Karadima and Louri (
2020, KL), for example, state that: “In our study, bank market power is measured by the Lerner index (
L), which identifies the degree of monopoly power as the difference between the price (
P) of a firm and its marginal cost (
MC) at the profit-maximizing rate of output”, viz:
KL state incorrectly that: “
The traditional approach of first estimating Equation (3) and then using the derived coefficient values to calculate marginal cost (MC) is based on the unrealistic assumption that all firms are profit maximizers”. However, it is clear that if a cost function is estimated as in their Equation (3), then the only behavioral assumption involved is cost minimization, not profit maximization, and this assumption is, of course, fairly weak.
In turn, KL following
Kumbhakar et al. (
2012) estimate a “return-to-dollar” specification (Equation (7)) to derive a measure of mark up. To understand the methodology, suppose we have a single output,
. Since
, we can write this equivalently as
where
is the output cost elasticity, and total revenue is
. Moreover
is the return to dollar (revenue per unit cost). From this analysis, they proceed to estimate
where
,
is statistical noise and
is a non-negative random variable that can be related to mark up as
from which the Lerner index is computed as
Clearly, KL did not estimate a cost function as claimed but rather a return-to-dollar specification, as in their Equation (7): “Using the maximum likelihood method, Equation (7) is estimated separately for each country in order to account for different banking technologies per country. The estimation procedure is based on the distributional assumption that the non-negative term is independently half-normally distributed [...] while vi is independently normally distributed [...]” (page 9).
It is not clear why one would want the return-to-dollar function in their Equation (7), as we can easily show the following:
Thus, the Lerner index depends exclusively on the output cost elasticity () and return-to-dollar (). Therefore, it would suffice to estimate the cost function in their Equation (3), as they state on page 7 and in the discussion surrounding their Equation (2). As a matter of fact, estimating their (7) ignores the restrictions imposed by the cost function in (2) or (3).
Moreover, their
is, in fact, equal to
Our (6) and (7) are, of course, equivalent, and it follows immediately that . Therefore, the question is: Why would one want to estimate a return-to-dollar specification as in KL Equation (7), ignoring the cost function, from which one can obtain directly ? One answer is that we have , which incorporates the one-sided error term, but this is equivalent (up to statistical noise) to our Equation (7).
Moreover, KL use as a proxy for
the value of total assets but also mention that “In contrast to
, the value of MC is not directly observable”. However, the original motivation in
Kumbhakar et al. (
2012) was that precisely
is often not available. Moreover, KL write that “
is defined as the ratio of total revenues (total interest and non-interest income) to total assets so, in fact, it is not the “price of output” but rather it is
. In turn, presumably, they take the estimate of the one-sided error component in the return-to-dollar specification when the dependent variable is
, which is clearly wrong in view of our (6) and (7).
It must also be pointed out that the methodology of
Kumbhakar et al. (
2012) was developed for industries that produce a single homogeneous product. However, the multi-output nature of production in banking is well understood, and use of a single output is a serious misspecification (see
Malikov et al. 2016 and their cited references). The correct procedure would have been to define carefully the different outputs and derive mark ups for each one of them as, presumably, banks are competing in different markets for different outputs. Therefore, the different Lerner indices for outputs
would have been
where
(
). Even in the single-output case, it is unclear whether
correctly measures market power. As
, one can write this as
where
stands for statistical noise and
is another non-negative random variable. After a little algebra, we obtain:
where
is average cost. Whether one should estimate (9) or a return-to-dollar as in KL Equation (7) is unclear and depends on the researcher’s preferences. If, in fact, (9) is the correct way to proceed, then Equation (7) in KL is misspecified as the composed error (
) is multiplied by the inverse of average cost and is, therefore, heteroskedastic. A battery of tests can be then be provided to convince the reader that KL’s (7) is better than (9).
However, there is an additional mistake in KL. In their Equation (14), they attempt to test for convergence in the “level of competition” (
), defined as the inverse of the Lerner index, viz.
. Their Equation (14) is as follows:
where
denotes fixed effects, and
is an error term. It is easy to show that
where
is the familiar
Jondrow et al. (
1982) estimate of
in the return-to-dollar function. If we omit the caret, we can write (10) as follows.
from which follows
Although further simplification is possible, it is clear from this formulation that there is a serious problem. A researcher that attempts to estimate markups () in order to test for convergence in a model like (13) reveals implicitly that she believes is autocorrelated. But this assumption is clearly inconsistent with the assumption that was assumed to be independent and identically distributed (IID) in the return-to-dollar formulation. Therefore, parameter estimates in both the return-to-dollar equation as well as in (13) will be biased and inconsistent.
Another problem with this formulation is that around
, using the approximation
, from (13), we obtain:
where
, and
is a new error term that includes
as well as approximation errors from the assumption that
and the assumption that
is small enough to justify a Taylor expansion of
. Therefore, at least approximately, “convergence regressions” based on KL’s formulation in (12) imply a strong prior belief about autocorrelation in
as in (14). Again, the initial assumption that
was IID and the latter assumption in (14) are logically inconsistent, thus leading to biased and inconsistent parameter estimators in both the return-to-dollar function (Equation (7) in KL) and the “convergence equation” in (10). If anything, and at best, estimates of
can be used to diagnose whether the return-to-dollar specification is correct. From Table 7 in KL, we see that estimates of
are fairly close to −1, but they are highly statistically significant. Thus,
is close to zero but highly significant, implying autocorrelation in
s based on (14). Therefore, since (14) is correct, the initial IID assumption must be wrong and all estimates are biased and inconsistent.
To illustrate, we use the US banking data set in
Malikov et al. (
2016) where we have five input prices and five outputs, and we include log equity as a quasi-fixed input along with a time trend.
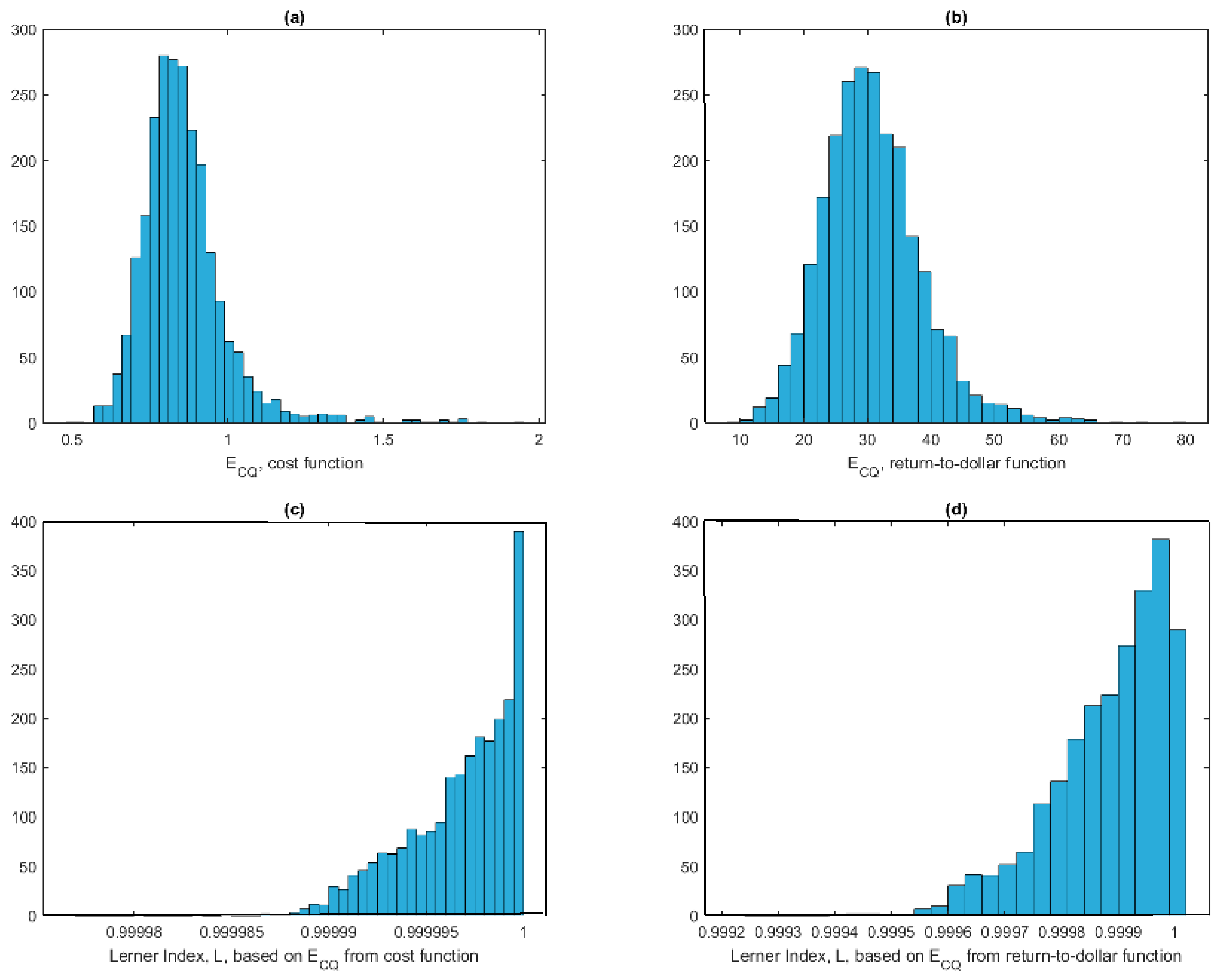
1 In panels (a) and (b) of
Figure 1, we report estimates of
(using the same single output
as in KL) from a translog cost function and the return-to-dollar specification. Quite clearly,
estimates from the latter are non-sensical, whereas estimates from the cost function itself are quite reasonable. Lerner indices computed using the estimates of
as in KL are reported in panels (c) and (d) of
Figure 1 and they make little sense as well.
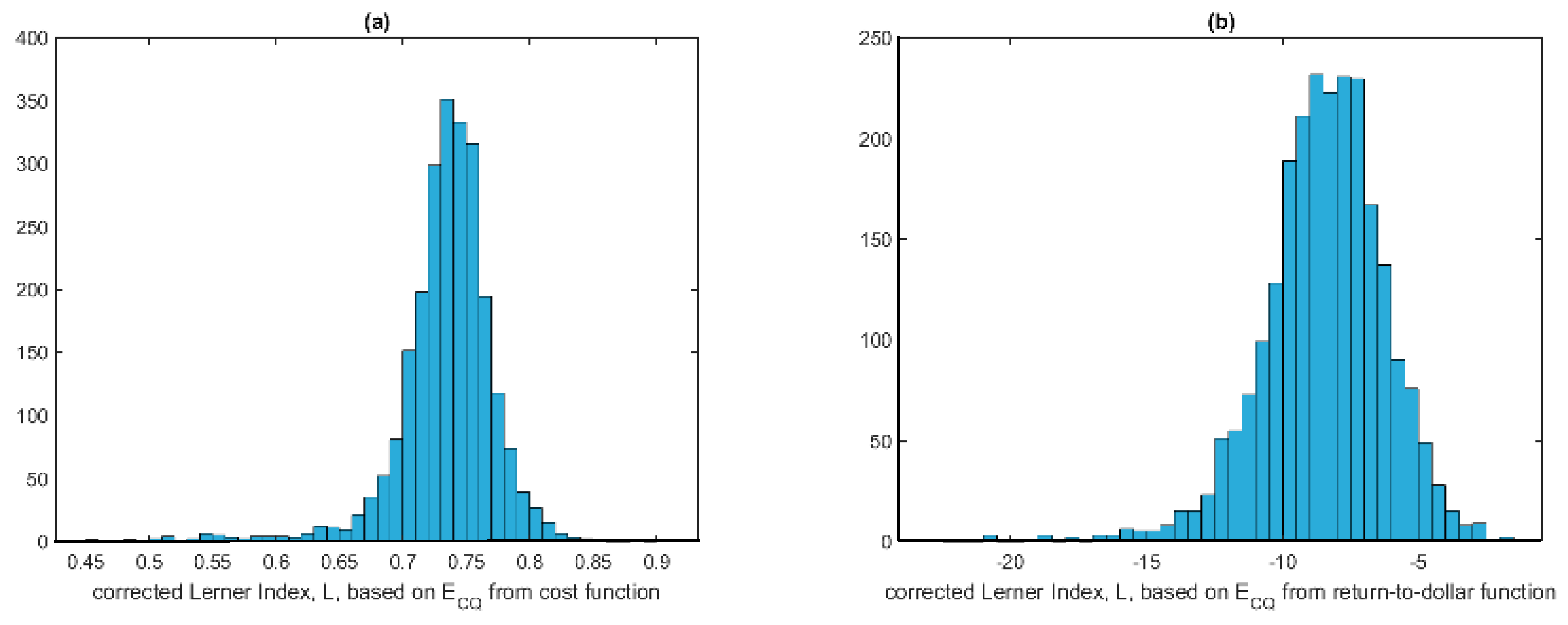
In an attempt to remedy the problem, we report, in
Figure 2, corrected Lerner indices based on the formula
where, again,
is computed as in KL using either the cost function (panel (a)) or the return-to-dollar function (panel (b)). Although the estimates in panel (a) make sense, the Lerner indices reported in panel (b), which are based on estimating
from the return-to-dollar function, make no sense at all, as they are all negative!

{kind=link}
{kind=link}

