
Churn Management in Telecommunications: Hybrid Approach Using Cluster Analysis and Decision Trees



Abstract
:1. Introduction
2. Literature Review
2.1. Market Segmentation Using Cluster Analysis
2.2. Predicting Churn in Telecommunications
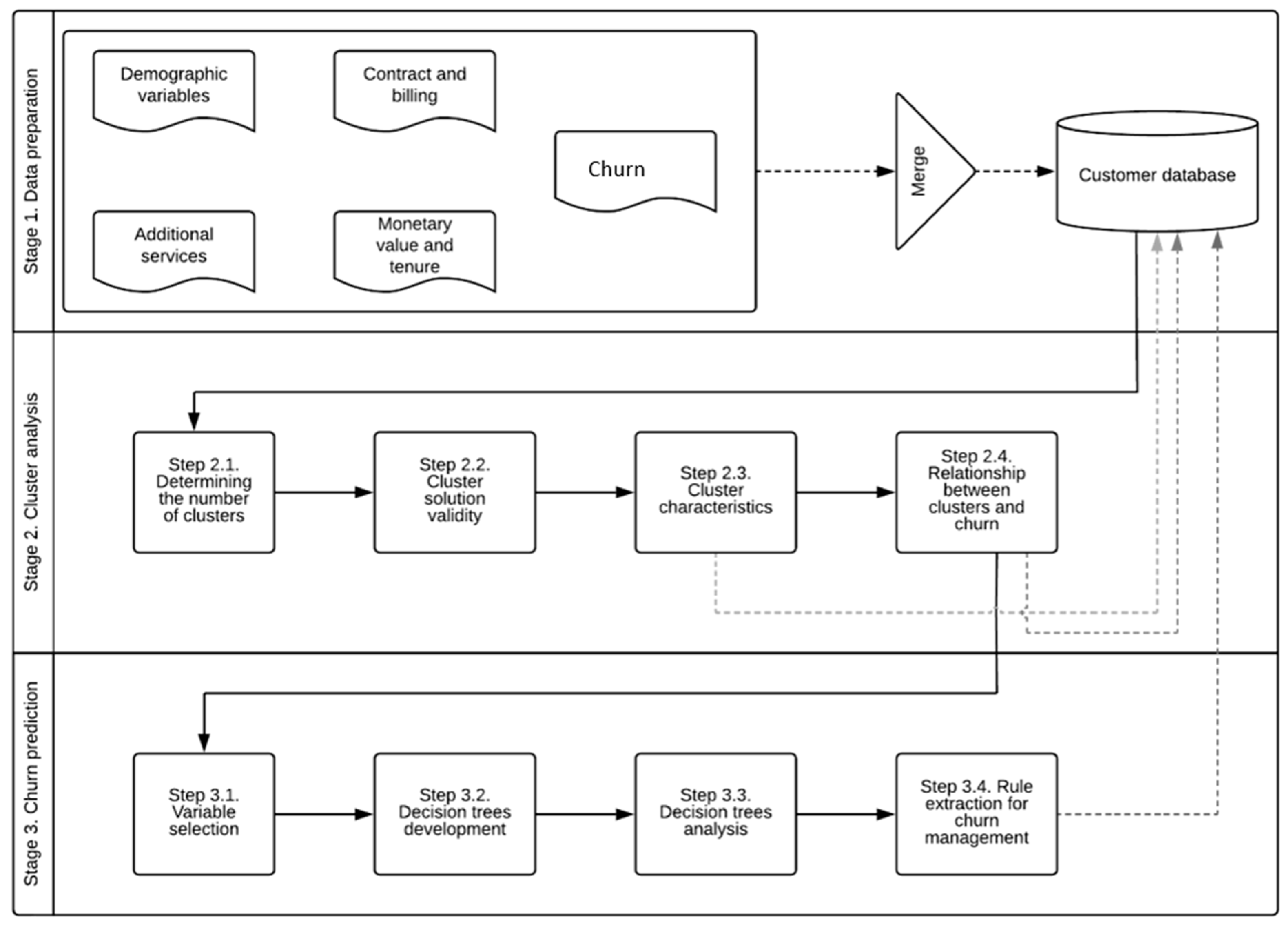
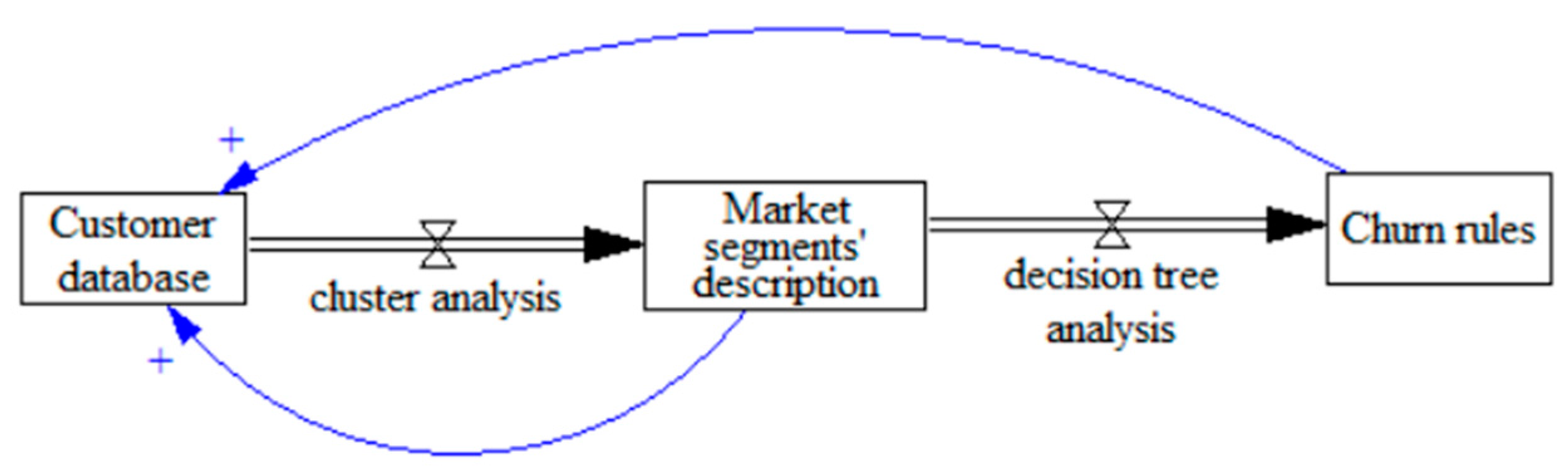
3. Methodology
3.1. Stage 1. Data Preparation
3.2. Stage 2. Cluster Analysis
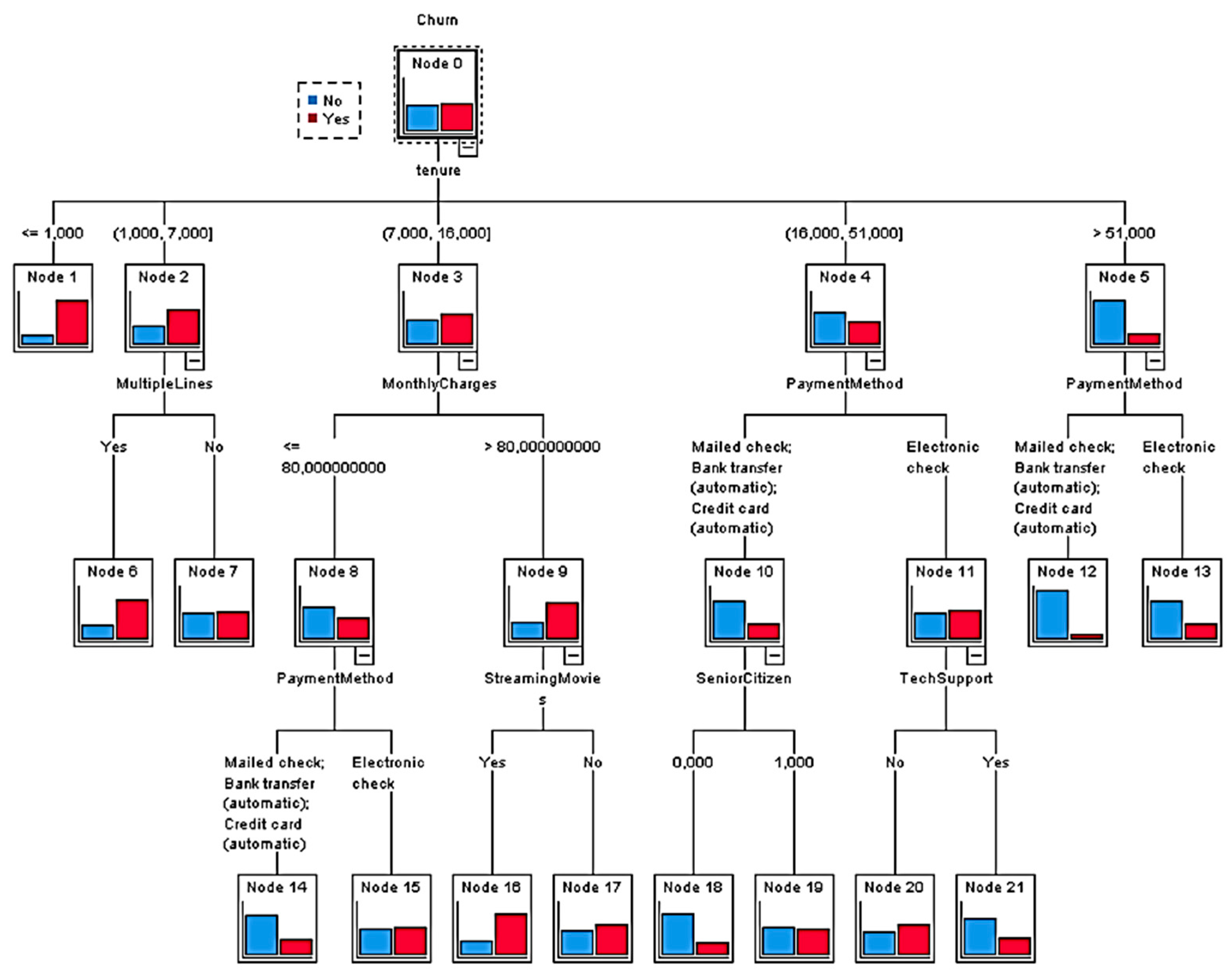
3.3. Stage 3. Churn Prediction
4. Results
4.1. Stage 1. Data Preparation
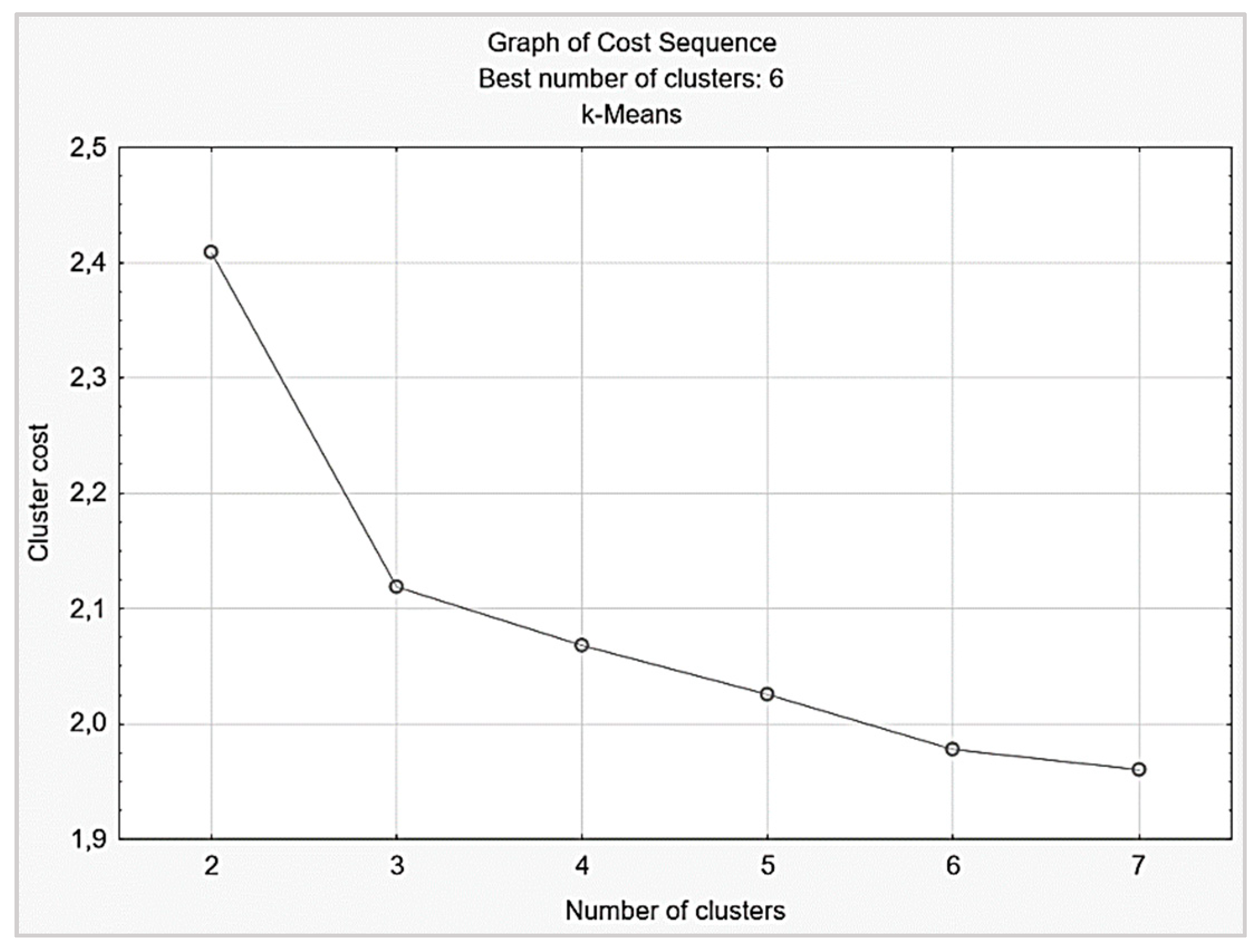
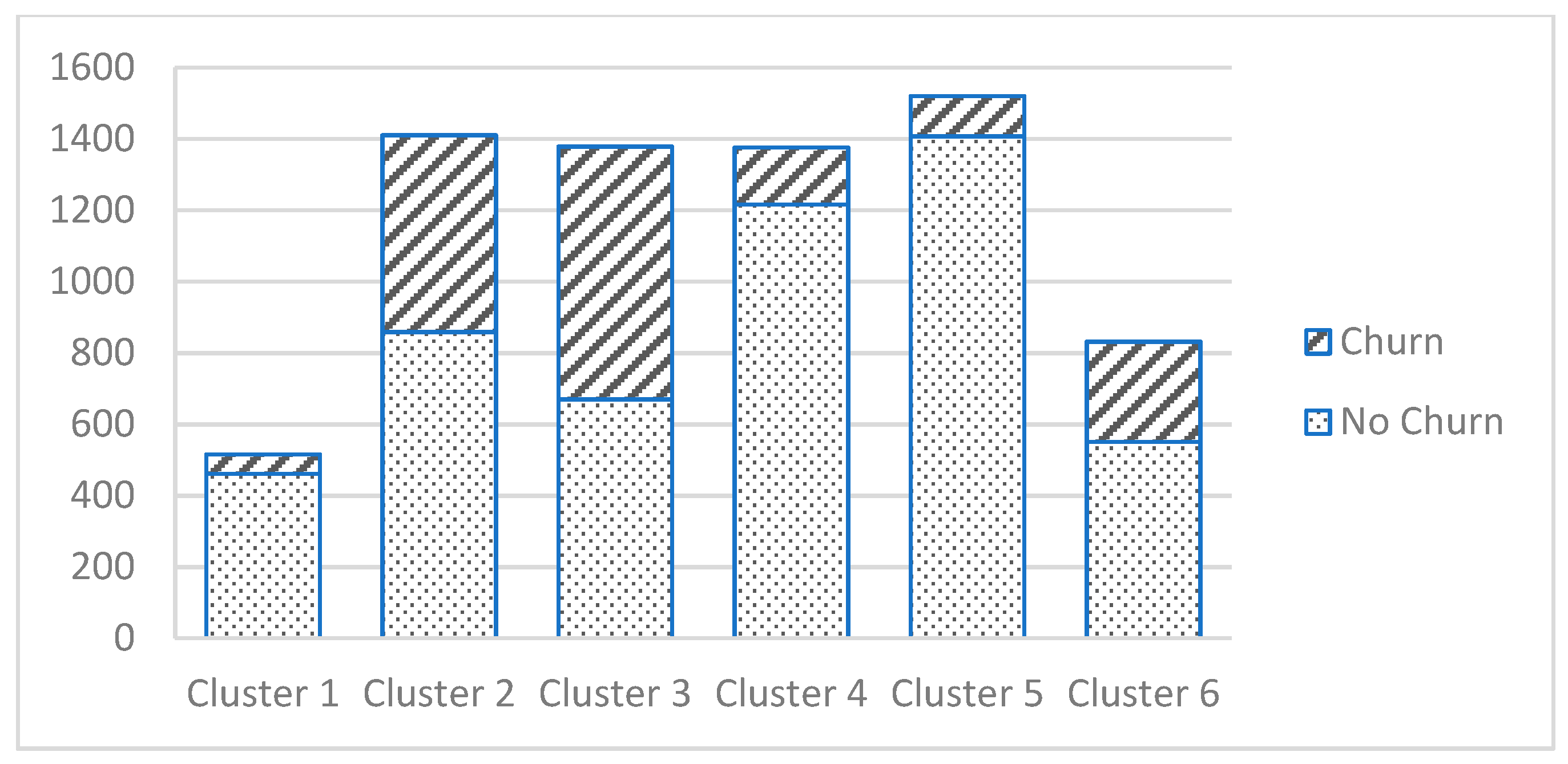
4.2. Stage 2. Cluster Analysis
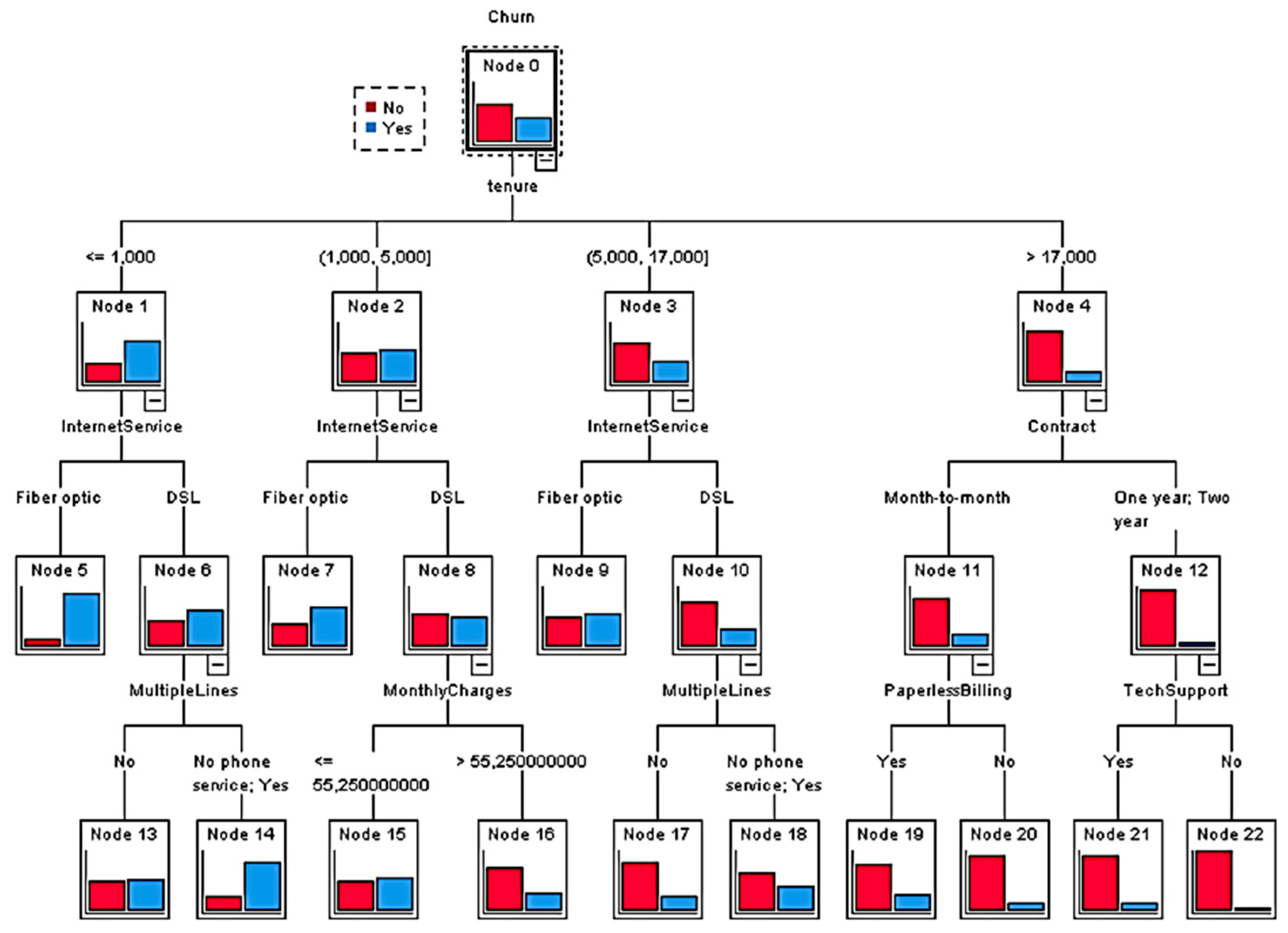
4.3. Stage 3. Churn Prediction
5. Discussion
5.1. Theorethical Implications
5.2. Practical Implications
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
Appendix A. Churn Modelling in the Telecommunications Industry
| Author (Year) | Methodology | Dataset | Identified Variables Relevant for Churn |
| Accuracy-oriented approaches to churn modelling in telecommunications | |||
| Pamina et al. (2019) | Classifiers: k-nearest neighbor, random forest and XG Boost | IBM Watson dataset, released in 2015; the dataset contains 7043 instances and 21 attributes | Type of internet service, monthly charges |
| Ahmad et al. (2019) | Decision tree, random forest, gradient boosted machine tree, XG boost | Syriatel telecommunication company; customers’ information over nine months | Days of last outgoing transactions, total balance, percentage of transactions with other operators, customer age, signal error and dropped calls, GSM age |
| Manďák and Hančlová (2019) | Logistic regression | Two real datasets of approximately 50,000 customers from European Telecommunications | Younger customers, customers with shorter lifetime (tenure), customers who use mobile data and SMS more than traditional calls, customers who have problems with paying bills, student accounts, contracts ending soon |
| Ahmed and Maheswari (2017) | Hybrid firefly-based classification | Orange dataset | N.A. |
| AlOmari and Mehedi Hassan (2016) | Decision tree, neural network, RULES family algorithm-6 | Mobile telecommunication company in Saudi Arabia; 10,000 customers, six variables | N.A. |
| Höppner et al. (2020) | A new classifier that integrates the EMPC metric directly into the model construction | Real-life datasets from various telecommunication service providers | N.A. |
| Faris (2018) | Particle swarm optimization and feedforward neural network | Unknown US mobile operator; contains 20 variables (features) and 3333 customers | Days when calls were made, voicemail messages, customer service calls, cost of international calls, local SMS fees, total consumption, total minutes of use for outgoing calls, total minutes of use for online outgoing calls |
| Swetha and Dayananda (2020) | Improved XgBoost | South Asia GSM (Global System for Mobile) dataset consists of over 64,000 instances and 29 variables | N.A. |
| Sjarif et al. (2019) | Pearson correlation, k nearest neighbor (KNN) algorithm | Public dataset Telco Customer churn available on the Kaggle platform; 7042 rows with 21 attributes | N.A. |
| Azeem et al. (2017) | Neural network, linear regression, C4.5, SVM, AdaBoost, gradient boosting and random forest are compared with fuzzy classifiers | Dataset from a telecommunication company operating in South Asia; it contains 600,000 instances with 722 attributes, all extracted from customer service usage patterns | N.A. |
| Li and Marikannan (2019) | Particle swarm optimization (PSO) as well as extreme learning machine (ELM) | Telecommunication churn dataset obtained from Kaggle; it consists of 3333 records and 21 features | The number of customer service calls, the number of international calls, the number of voicemail messages, night charges and international charges |
| Ahmed et al. (2020) | Boosted-stacked learners and bagged-stacked learners | UCI Churn dataset with 5000 samples and 20 attributes, most of which are related to the call detail records | N.A. |
| Alfumadi et al. (2019) | Convolutional neural networks (CNN) | The Mobile Telephony Churn Prediction Dataset contains data for around 100,000 individuals | N.A. |
| Hybrid approaches to churn modelling in telecommunications | |||
| Ullah et al. (2019) | Classification (various methods), k-means clustering | Two datasets with behavioral variables measuring the number of calls and minutes | Calls and minutes within and outside of network, free and charged minutes |
| Choudhari and Potey (2018) | Hybrid decision tree and logistic regression classifier; fuzzy unordered rule induction algorithm (FURIA) with fuzzy c-means algorithms | Telecommunication dataset with 20 attributes and 2666 entities, with 2278 non-churners and 388 churners | N.A. |
| Olle and Cai (2014) | Logistic regression, voted perceptron | Dataset from Asian mobile telecommunication operator; it recapitulates the 6-month activity of 2000 subscribers, over 23 different data variables | Length of contract, age and total revenue |
| Preetha and Rayapeddi (2018) | Logistic regression, random forests and k-means clustering | Dataset consisting of 3400 entities; 19 attributes are selected out of 22 attributes | N.A. |
Appendix B. Decision Tree Rules Extracted
Appendix B.1. Cluster 2 Rules
Appendix B.2. Cluster 3 Rules
References
- Ahmad, Kasem Ahmad, Assef Jafar, and Kadan Aljoumaa. 2019. Customer churn prediction in telecommunication using machine learning in big data platform. Journal of Big Data 6: 28. [Google Scholar] [CrossRef] [Green Version]
- Ahmed, Ammar A.Q., and D. Maheswari. 2017. Churn prediction on huge telecommunication data using hybrid firefly-based classification. Egyptian Informatics Journal 18: 215–20. [Google Scholar] [CrossRef]
- Ahmed, Mahreen, Hammad Afzal, Imran Siddiqi, Muhammad Faisal Amjad, and Khawar Khurshid. 2020. Exploring nested ensemble learners using overproduction and choose approach for churn prediction in telecommunication industry. Neural Computing and Applications 3: 3237–51. [Google Scholar] [CrossRef]
- Almufadi, Nasebah, Ali Mustafa Qamar, Rehan Ullah Khan, Mohamed Tahar, and Ben Othman. 2019. Deep learning-based churn prediction of telecommunication subscribers. International Journal of Engineering Research and Technology 12: 2743–48. [Google Scholar]
- AlOmari, Diana, and Mohammad Mehedi Hassan. 2016. Predicting Telecommunication Customer Churn Using Data Mining Techniques. In Internet and Distributed Computing Systems. Edited by Wenfeng Li, Shawkat Ali, Gabriel Lodewijks, Giancarlo Fortino, Giuseppe Di Fatta, Zhouping Yin, Mukaddim Pathan, Antonio Guerrieri and Qiang Wang. Cham: Springer, pp. 167–78. [Google Scholar] [CrossRef]
- Al-Refaie, Abbas. 2017. Cluster Analysis of Customer Churn in Telecommunication Industry. International Journal of Business, Human and Social Sciences 11: 1222–26. [Google Scholar] [CrossRef]
- Azeem, Muhammad, Muhammad Usman, and Alvis Cheuk Fong. 2017. A churn prediction model for prepaid customers in telecommunication using fuzzy classifiers. Telecommunication Systems 66: 603–14. [Google Scholar] [CrossRef]
- Bayer, Judy. 2010. Customer segmentation in the telecommunications industry. Journal of Database Marketing & Customer Strategy Management 17: 247–56. [Google Scholar] [CrossRef] [Green Version]
- Bell, David, and Chidozie Mgbemena. 2017. Data-driven agent-based exploration of customer behavior. Simulation: Transactions of the Society for Modeling and Simulation International 94: 195–212. [Google Scholar] [CrossRef] [Green Version]
- Boehmke, Bradley, and Brandon Greenwell. 2020. Hands-On Machine Learning with R. Chapman and Hall/CRC. Available online: https://bradleyboehmke.github.io/HOML/knn.html (accessed on 9 November 2021).
- Bose, Indranil, and Xi Chen. 2015. Detecting the migration of mobile service customers using fuzzy clustering. Information & Management 52: 227–38. [Google Scholar] [CrossRef]
- Calzada-Infante, Laura, María Óskarsdóttir, and Bart Baesens. 2020. Evaluation of customer behavior with temporal centrality metrics for churn prediction of prepaid contracts. Expert Systems with Applications 160: 113553. [Google Scholar] [CrossRef]
- Cheng, Li Chen, Chia-Chi Wu, and Chih-Yi Chen. 2019. Behavior Analysis of Customer Churn for a Customer Relationship System: An Empirical Case Study. Journal of Global Information Management 27: 111–27. [Google Scholar] [CrossRef]
- Choudhari, Atul Sunil, and Manish Potey. 2018. Predictive to Prescriptive Analysis for Customer Churn in Telecommunication Industry Using Hybrid Data Mining Techniques. Paper presented at 2018 Fourth International Conference on Computing Communication Control and Automation (ICCUBEA), Pune, India, August 16–18. [Google Scholar]
- Chouiekh, Alae, and El Hassane El Haj. 2020. Deep Convolutional Neural Networks for Customer Churn Prediction Analysis. International Journal of Cognitive Informatics and Natural Intelligence 14: 1–16. [Google Scholar] [CrossRef]
- Dolnicar, Sara, Bettina Grün, and Friedrich Leisch. 2018. Market Segmentation Analysis. Singapore: Springer. [Google Scholar]
- Droftina, Uroš, Mitja Štular, and Andrej Košir. 2015. Predicting Influential Mobile-Subscriber Churners using Low-level User Features. Automatika 56: 522–34. [Google Scholar] [CrossRef] [Green Version]
- Ernst, Dominik, and Sara Dolnicar. 2018. How to avoid random market segmentation solutions. Journal of Travel Research 57: 69–82. [Google Scholar] [CrossRef] [Green Version]
- Faris, Hossam. 2018. A Hybrid Swarm Intelligent Neural Network Model for Customer Churn Prediction and Identifying the Influencing Factors. Information 9: 288. [Google Scholar] [CrossRef] [Green Version]
- Golubev, Alexey, Ngyuen Anh Tuan, Maxim Shcherbakov, and Tran Van Phu. 2017. Clustering helps to determine the changes in telecommunication subscribers’ behavior. In Advances in Computer Science Research (ACSR), Proceedings of the IV International research conference “Information technologies in Science, Management, Social sphere and Medicine" (ITSMSSM 2017), Russia, Tomsk, 5–8 December 2017. Atlantis Press: pp. 339–43. ISBN 978-94-6252-432-3. [Google Scholar] [CrossRef] [Green Version]
- Höppner, Sebastiaan, Eugen Stripling, Bart Baesens, Seppe vanden Broucke, and Tim Verdonck. 2020. Profit Driven Decision Trees for Churn Prediction. European Journal of Operational Research 284: 920–33. [Google Scholar] [CrossRef] [Green Version]
- Hwang, Hyunseok, Taesoo Jung, and Euiho Suh. 2004. An LTV model and customer segmentation based on customer value: A case study on the wireless telecommunication industry. Expert Systems with Applications 26: 181–88. [Google Scholar] [CrossRef]
- Jin, Xin, and Jiawei Han. 2011. Partitional Clustering. In Encyclopedia of Machine Learning. Edited by Claude Sammut and Geoffrey Webb. Boston: Springer. [Google Scholar] [CrossRef]
- Kassambara, Alboukadel. 2017. Practical Guide to Cluster Analysis in R Edition 1 sthda.com Unsupervised Machine Learning. STHDA Online. [Google Scholar]
- Khalili-Damghani, Kaveh, Farshid Abdi, and Shaghayegh Abolmakarem. 2018. Hybrid soft computing approach based on clustering, rule mining, and decision tree analysis for customer segmentation problem: Real case of customer-centric industries. Applied Soft Computing 73: 816–28. [Google Scholar] [CrossRef]
- Kim, Seungyeon, Younghoon Chang, Siew Fan Wong, and Myeong Cheol Park. 2020. Customer resistance to churn in a mature mobile telecommunications market. International Journal of Mobile Communications 18: 41–66. [Google Scholar] [CrossRef]
- Kisioglu, Pınar, and Y. Ilker Topcu. 2011. Applying Bayesian Belief Network approach to customer churn analysis: A case study on the telecom industry of Turkey. Expert Systems with Applications 38: 7151–57. [Google Scholar] [CrossRef]
- Kodinariya, Trupti M., and Prashant R. Makwana. 2013. Review on determining number of cluster in k-means clustering. International Journal of Advance Research in Computer Science and Management Studies 1: 90–95. [Google Scholar]
- Lee, Samuel Sangkon, and Chia Y. Han. 2012. Finding Good Initial Cluster Center by Using Maximum Average Distance. In JapTAL 2012: Advances in Natural Language Processing. Edited by Hitoshi Isahara and Kyoko Kanzaki. Berlin: Springer, pp. 228–38. [Google Scholar] [CrossRef]
- Li, Koh Guan, and Booma Poolan Marikannan. 2019. Hybrid Particle Swarm Optimization-Extreme Learning Machine Algorithm for Customer Churn Prediction. Journal of Computational and Theoretical Nanoscience 16: 3432–36. [Google Scholar] [CrossRef]
- Lin, Qin, Huailing Zhang, Xizhao Wang, Yun Xue, Hongxin Liu, and Changwei Gong. 2019. A Novel Parallel Biclustering Approach and Its Application to Identify and Segment Highly Profitable Telecommunication Customers. IEEE Access 7: 28696–711. [Google Scholar] [CrossRef]
- Manďák, Jan, and Jana Hančlová. 2019. Use of Logistic Regression for Understanding and Prediction of Customer Churn in Telecommunications. STATISTIKA 99: 129–41. [Google Scholar]
- Marini, Federico, and José Manuel Amigo. 2020. Unsupervised exploration of hyperspectral and multispectral images. In Data Handling in Science and Technology. Amsterdam: Elsevier, vol. 32, pp. 93–114. [Google Scholar] [CrossRef]
- Mu, Qing, and Keun Lee. 2005. Knowledge diffusion, market segmentation and technological catch-up: The case of the telecommunication industry in China. Research Policy 34: 759–83. [Google Scholar] [CrossRef]
- Olle, Georges D., and Shuqin Cai. 2014. A Hybrid Churn Prediction Model in Mobile Telecommunication Industry. International Journal of e-Education, e-Business, e-Management and e-Learning 4: 55–62. [Google Scholar] [CrossRef] [Green Version]
- Pamina, Jeyakumar, Beschi Raja, S. SathyaBama, Selvaraj Soundarya, M. S. Sruthi, S. Kiruthika, V.J. Aiswaryadevi, and G. Priyanka. 2019. Effective Classifier for Predicting Churn in Telecommunication. Journal of Advanced Research in Dynamical & Control Systems 11. Available online: https://ssrn.com/abstract=3399937 (accessed on 9 November 2021).
- Preetha, Shivanna, and Rohit Rayapeddi. 2018. Predicting Customer Churn in the Telecommunication Industry Using Data Analytics. Paper presented at 2018 Second International Conference on Green Computing and Internet of Things (ICGCIoT), Bangalore, India, August 16–18; pp. 38–43. [Google Scholar] [CrossRef]
- Qiu, Yuhang, Pingping Chen, Zhijian Lin, Yongcheng Yang, Lanning Zeng, and Yaqi Fan. 2020. Clustering Analysis for Silent Telecommunication Customers Based on k-means plus. Paper presented at 4th IEEE Information Technology, Networking, Electronic and Automation Control Conference (ITNEC), Chongqing, China, June 12–14; pp. 1023–27. [Google Scholar] [CrossRef]
- Sjarif, Nilam Nur Amir, Muhammad Rusydi, Mohd Yusof, Doris Hooi, Ten Wong, Suraya Ya’akob, Roslina Ibrahim, and Mohd Zamri Osman. 2019. A Customer Churn Prediction using Pearson Correlation Function and K Nearest Neighbor Algorithm for Telecommunication Industry. International Journal of Advances in Soft Computing and Its Applications 11: 46–59. [Google Scholar]
- Swetha, P., and R.B. Dayananda. 2020. Improvised_XgBoost Machine learning Algorithm for Customer Churn Prediction. EAI Endorsed Transactions on Energy Web 7: 1–7. [Google Scholar] [CrossRef]
- Thomassey, Sébastien, and Antonio Fiordaliso. 2006. A hybrid sales forecasting system based on clustering and decision trees. Decisison Support Systems 42: 408–21. [Google Scholar] [CrossRef]
- TIBCO. 2020. Feature Selection and Variable Screening Overview. Available online: https://docs.tibco.com/data-science/GUID-0111ABBC-1B92-4DD0-BBA8-79374F9BE57C.html (accessed on 9 November 2021).
- Tuma, Michael N., Reinhold Decker, and Sören W. Scholz. 2011. A survey of the challenges and pifalls of cluster analysis application in market segmentation. International Journal of Market Research 53: 391–414. [Google Scholar] [CrossRef]
- Ullah, Irfan, Basit Raza, Ahmad Kamran Malik, Muhammad Imran, Saif Ul Islam, and Sung Won Kim. 2019. A Churn Prediction Model Using Random Forest: Analysis of Machine Learning Techniques for Churn Prediction and Factor Identification in Telecommunication Sector. IEEE Access 7: 60134–49. [Google Scholar] [CrossRef]
- Vazirgiannis, Michalis. 2009. Clustering Validity. In Encyclopedia of Database Systems. Edited by Liu Ling and Özsu Tamer. Boston: Springer. [Google Scholar]
- Verbeke, Wouter, Karel Dejaeger, David Martens, Joon Hur, and Bart Baesens. 2012. New insights into churn prediction in the telecommunication sector: A profit driven data mining approach. European Journal of Operational Research 218: 211–29. [Google Scholar] [CrossRef]
- Wang, Shen-Tsu. 2018. Integrating KPSO and C5.0 to analyze the omnichannel solutions for optimizing telecommunication retail. Decision Support Systems 109: 39–49. [Google Scholar] [CrossRef]
- Wei, Chih-Ping, and I-Tang Chiu. 2002. Turning telecommunications call details to churn prediction: A data mining approach. Expert Systems with Applications 23: 103–12. [Google Scholar] [CrossRef]
- Zheng, Feng, and Quanyun Liu. 2020. Anomalous Telecommunication Customer Behavior Detection and Clustering Analysis Based on ISP’s Operating Data. IEEE Access 8: 42734–48. [Google Scholar] [CrossRef]
- Zhou, Jian, Linli Zhai, and Athanasios A. Pantelous. 2020. Market segmentation using high-dimensional sparse consumes data. Expert Systems with Applications 145: 113136. [Google Scholar] [CrossRef]







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Variable Name | Variable Type | Modalities/Min–Max |
|---|---|---|
| Demographic variables | ||
| Gender | Binomial | Female; Male |
| SeniorCitizen | Binomial | No; Yes |
| Dependents | Binomial | No; Yes |
| Partner | Binomial | No; Yes |
| Contracts and billing | ||
| Contract | Nominal | Month-to-month; One year; Two year |
| PaperlessBilling | Binomial | No; Yes |
| PaymentMethod | Nominal | Bank transfer; Credit card; Other |
| Additional services used | ||
| InternetService | Nominal | DLS; Fiber Optic; No |
| DeviceProtection | Nominal | No; No Internet service; Yes |
| MultipleLines | Nominal | No; No phone service; Yes |
| OnlineBackup | Nominal | No; No Internet service; Yes |
| OnlineSecurity | Nominal | No; No Internet service; Yes |
| StreamingMovies | Nominal | No; No Internet service; Yes |
| StreamingTV | Nominal | No; No Internet service; Yes |
| TechSupport | Nominal | No; No Internet service; Yes |
| PhoneService | Binomial | No; Yes |
| Customer monetary value and tenure | ||
| Tenure | Numeric (Months) | [1; 72] |
| TotalCharges | Numeric (USD) | [18,80; 118,75] |
| MonthlyCharges | Numeric (USD) | [18,25; 8684,80] |
| Churn behavior | ||
| Churn | Binomial | No; Yes |
| between SS | df | within SS | df | F | p-Value | |
|---|---|---|---|---|---|---|
| Monetary value and tenure | ||||||
| Tenure | 1,665,336 | 5 | 2,570,629 | 7026 | 910.334 | 0.000 * |
| MonthlyCharges | 5,141,226 | 5 | 1,222,995 | 7026 | 5907.181 | 0.000 * |
| TotalCharges | 22,700,920,000 | 5 | 13,426,130,000 | 7026 | 2375.914 | 0.000 * |
| Variable Name | Variable Type | df | Chi-Square | p-Value | G-Square | p-Value |
|---|---|---|---|---|---|---|
| Demographic variables | ||||||
| Gender | Binomial | 5 | 654.813 | 0.000 * | 673.119 | 0.000 * |
| SeniorCitizen | Binomial | 5 | 388.854 | 0.000 * | 439.816 | 0.000 * |
| Dependents | Binomial | 5 | 786.502 | 0.000 * | 831.807 | 0.000 * |
| Partner | Binomial | 5 | 1225.976 | 0.000 * | 1285.330 | 0.000 * |
| Contracts and billing | ||||||
| Contract | Nominal | 10 | 3354.462 | 0.000 * | 3680.463 | 0.000 * |
| PaperlessBilling | Nominal | 5 | 1126.370 | 0.000 * | 1137.811 | 0.000 * |
| PaymentMethod | Nominal | 15 | 2171.842 | 0.000 * | 2197.449 | 0.000 * |
| Additional services | ||||||
| InternetService | Nominal | 10 | 9689.710 | 0.000 * | 9759.398 | 0.000 * |
| DeviceProtection | Nominal | 10 | 8715.597 | 0.000 * | 8737.442 | 0.000 * |
| MultipleLines | Nominal | 10 | 4229.285 | 0.000 * | 3740.198 | 0.000 * |
| OnlineBackup | Nominal | 10 | 8411.848 | 0.000 * | 8459.180 | 0.000 * |
| OnlineSecurity | Nominal | 10 | 8699.201 | 0.000 * | 8663.085 | 0.000 * |
| StreamingMovies | Nominal | 10 | 8852.166 | 0.000 * | 8854.783 | 0.000 * |
| StreamingTV | Nominal | 10 | 8840.241 | 0.000 * | 8841.567 | 0.000 * |
| TechSupport | Nominal | 10 | 8863.749 | 0.000 * | 8808.242 | 0.000 * |
| PhoneService | Nominal | 5 | 2215.395 | 0.000 * | 1620.087 | 0.000 * |
| Cluster | Cluster 1 | Cluster 2 | Cluster 3 | Cluster 4 | Cluster 5 | Cluster 6 |
|---|---|---|---|---|---|---|
| Demographic variables | ||||||
| Gender | Male | Female | Male | Male | Male | Female |
| SeniorCitizen | No | No | No | No | No | No |
| Partner | No | No | No | Yes | No | Yes |
| Dependents | No | No | No | No | No | Yes |
| Contracts and billing | ||||||
| Contract | One year | Month-to-month | Month-to-month | Two year | Two year | Month-to-month |
| PaperlessBilling | No | Yes | Yes | Yes | No | Yes |
| PaymentMethod | Credit card | Electronic check | Electronic check | Bank transfer | Mailed check | Electronic check |
| Additional services | ||||||
| DeviceProtection | No | No | No | Yes | No internet service | No |
| InternetService | DSL | DSL | Fiber optic | Fiber optic | No | Fiber optic |
| MultipleLines | No phone service | No | Yes | Yes | No | No |
| OnlineBackup | No | No | No | Yes | No internet service | Yes |
| OnlineSecurity | Yes | No | No | Yes | No internet service | No |
| StreamingMovies | No | No | No | Yes | No internet service | Yes |
| StreamingTV | No | No | No | Yes | No internet service | Yes |
| TechSupport | Yes | No | No | Yes | No internet service | No |
| PhoneService | No | Yes | Yes | Yes | Yes | Yes |
| Customer monetary value and tenure | ||||||
| Tenure | 37.85 | 14.28 | 21.55 | 59.47 | 30.67 | 36.28 |
| MonthlyCharges | 49.85 | 57.68 | 82.95 | 93.07 | 21.08 | 89.19 |
| TotalCharges | 1970.03 | 836.81 | 1833.46 | 5552.52 | 665.22 | 3223.34 |
| Cluster members | ||||||
| Number of cases | 516 | 1410 | 1378 | 1376 | 1520 | 832 |
| Percentage (%) | 7.34 | 20.05 | 19.60 | 19.57 | 21.62 | 11.83 |
| No Churn | Churn | Total | Pearson Chi-Square | df | p-Value | |
|---|---|---|---|---|---|---|
| Cluster 1 | 461 | 55 | 516 | 1080.666 | 5 | 0.000 * |
| Cluster 2 | 858 | 552 | 1410 | |||
| Cluster 3 | 670 | 708 | 1378 | |||
| Cluster 4 | 1216 | 160 | 1376 | |||
| Cluster 5 | 1407 | 113 | 1520 | |||
| Cluster 6 | 551 | 281 | 832 | |||
| Total | 5163 | 1869 | 7032 |
| Variable | Chi-Square | p-Value |
|---|---|---|
| Contract | 1179.546 | 0.000 * |
| Tenure | 873.717 | 0.000 * |
| OnlineSecurity | 846.677 | 0.000 * |
| TechSupport | 824.926 | 0.000 * |
| InternetService | 728.696 | 0.000 * |
| PaymentMethod | 645.430 | 0.000 * |
| OnlineBackup | 599.175 | 0.000 * |
| MonthlyCharges | 563.636 | 0.000 * |
| DeviceProtection | 555.880 | 0.000 * |
| TotalCharges | 387.330 | 0.000 * |
| StreamingMovies | 374.268 | 0.000 * |
| StreamingTV | 372.457 | 0.000 * |
| PaperlessBilling | 257.756 | 0.000 * |
| Dependents | 187.128 | 0.000 * |
| SeniorCitizen | 159.364 | 0.000 * |
| Partner | 158.182 | 0.000 * |
| MultipleLines | 11.272 | 0.004 * |
| PhoneService | 0.961 | 0.327 |
| Gender | 0.513 | 0.474 |
| Correct Predictions | Full Database | Cluster 1 | Cluster 2 | Cluster 3 | Cluster 4 | Cluster 5 | Cluster 6 |
|---|---|---|---|---|---|---|---|
| Churn—No | 90.4% | 100.0% | 71.7% | 55.4% | 97.2% | 100.0% | 97.3% |
| Churn—Yes | 49.5% | 0.0% | 70.7% | 81.4% | 23.1% | 0.0% | 18.9% |
| Overall | 79.5% | 89.3% | 71.3% | 68.7% | 88.6% | 92.6% | 70.8% |
| Rank Yes | (3) | (6) | (2) | (1) | (4) | (6) | (5) |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Pejić Bach, M.; Pivar, J.; Jaković, B. Churn Management in Telecommunications: Hybrid Approach Using Cluster Analysis and Decision Trees. J. Risk Financial Manag. 2021, 14, 544. https://doi.org/10.3390/jrfm14110544
Pejić Bach M, Pivar J, Jaković B. Churn Management in Telecommunications: Hybrid Approach Using Cluster Analysis and Decision Trees. Journal of Risk and Financial Management. 2021; 14(11):544. https://doi.org/10.3390/jrfm14110544
Chicago/Turabian StylePejić Bach, Mirjana, Jasmina Pivar, and Božidar Jaković. 2021. "Churn Management in Telecommunications: Hybrid Approach Using Cluster Analysis and Decision Trees" Journal of Risk and Financial Management 14, no. 11: 544. https://doi.org/10.3390/jrfm14110544
APA StylePejić Bach, M., Pivar, J., & Jaković, B. (2021). Churn Management in Telecommunications: Hybrid Approach Using Cluster Analysis and Decision Trees. Journal of Risk and Financial Management, 14(11), 544. https://doi.org/10.3390/jrfm14110544