In what follows, we first introduce five different types of risk measures for count r. v., see
Section 2.1 as well as
Table 1 for a brief summary. When applying these measures to continuously distributed r. v., two of them agree with other measures, i.e., the number of different risk measures reduces to three, see
Table 2. Not only do the number and computation of risk measures differ between the discrete count case and the continuous Gaussian case, there are also considerable differences in their properties, which are discussed in
Section 2.2. We conclude with a first data example in
Section 2.3, which serves as a motivation for the subsequent analyses.
2.1. Definition of Risk Measures
Let
X be a count r. v. referring to an undesirable event (the “loss,” e.g., the number of defects, of infections, or of insolvencies). The relevant types of probability mass function (PMF) are summarized in
Table A1 and
Table A2 in the
Appendix A. For a fixed risk level
, the most basic risk measure is the
value at risk (
), which is defined to be the lower
th quantile of the distribution of
X,
is interpreted as a threshold that is only exceeded in at most
of all cases. Later, we compute the
(as well as any other risk measure considered here) from the conditional distribution of
, given the past
, but to keep our notation simple, we now just write
X. (We do not further stress the term “conditional” here to avoid confusion with another risk measure, which is sometimes referred to as the “conditional VaR” (see
Göb 2011;
Rockafellar and Uryasev 2002) and which corresponds to the tail conditional expectation or expected shortfall, respectively, in our terminology, given that the cumulative distribution function (CDF) of
X is continuous.) Note that since
X is a count r. v., also its VaR can only take non-negative integer values. This differs from the remaining risk measures to be considered here, which can take arbitrary positive real numbers as their outcome.
If
happens, which is referred to as a shortfall, the actual loss will often be larger than the threshold value
itself (i.e.,
with probability
). Therefore, more refined risk measures, obtained by averaging VaRs or exceedances thereof, have been proposed in the literature to express the “typical loss” one has to prepare for if an exceedance of the VaR occurs, see
Chan and Nadarajah (
2019) for a survey.
Artzner et al. (
1999) propose to use the
tail conditional expectation (
), which is defined as the conditional mean loss in the case of reaching or exceeding the
. More precisely,
where the indicator function
takes the value 1 (0) if
A is true (false). The last expression in (
2) is used for computing the value of
, with
being equal to the finite sum
. Note that the event “
” is included in the condition (
2), although some authors use the condition “
” instead (
Göb 2011). For the discrete count r. v. considered here, this makes a difference. For bounded counts, the condition “
” is advantageous if
equals the upper bound
n of the range
. In addition, note that (
2) implies that
.
As shown in Proposition 3.2 of
Acerbi and Tasche (
2002), the
can be computed from
and
as follows:
This shows that
. While
by (
1) for discrete r. v., we have that
for continuously distributed r. v.. So
and
necessarily coincide in the continuous case (also see
Table 2). In the discrete case, it may happen for bounded counts that
agrees with the upper bound
n, in which case
and
agree with
n as well. Otherwise, we have the strict inequality
. Note that (
4) can be rewritten as
which shows that
is a weighted mean of
and
. Later in
Section 2.2, Equation (
5) shall be helpful for explaining some properties of
. The application of the risk measures
,
, and
to count r. v. was also considered by
Göb (
2011) and
Homburg (
2020), but both using a modified definition of
compared to (
2). The integer-valued
was also investigated by
Homburg et al. (
2019) as a non-central point forecast for count time series.
Recently,
expectiles have also been considered as an another type of risk measure, see
Bellini and di Bernardino (
2017) and the references therein. Expectiles were developed by
Newey and Powell (
1987) as an alternative to quantiles. In analogy to the
according to (
1), we define the
expectile- (
) as the
-expectile of
X. The latter, in turn, is defined to be the (unique) minimizer of the following type of asymmetric quadratic loss, provided that the second-order moment of
X exist:
By contrast, the
-quantile (i.e., the
) minimizes
in
q (provided that
exists). While
is integer-valued for count r. v., the
can take any positive real number. The
is also uniquely characterized as the solution to the following equation (commonly referred to as the “first-order condition”):
Equation (
7) shows that the
can be interpreted as that threshold value
e where the ratio of the mean exceedance to the mean shortfall,
, equals the odds ratio
. For computations, it is advantageous to rewrite (
7) as
where the truncated mean is computed as the finite sum
. Equation (
8) also shows that the 0.5-expectile is just equal to the mean
. A critical comparison of all aforementioned risk measures is provided by
Emmer et al. (
2015).
Finally, let us return to the
defined by (
1). For the discrete count r. v. considered here,
behaves fundamentally different to the other considered risk measures: While
,
, and
are real-valued in general,
takes values from the set of non-negative integers. This does not only constitute an additional difficulty if working with a Gaussian approximation (see
Table 2), it also causes problems if estimating the
from given data. For example, we have a degenerate asymptotic distribution for the sample
, see Theorem 6 in
Jentsch and Leucht (
2016). For these reasons, we propose to consider also the following modification of
, which we refer to as the
mid- (
). It is defined as the
-mid-quantile of
X, a concept dating back to
Parzen (
1997) and further investigated by
Ma et al. (
2011) and
Jentsch and Leucht (
2016). Let
(“mid-probability”) for
, and let
n denote the upper limit of the range of
X (with
for unbounded counts). Then, we have that
The last case is only relevant for bounded counts, i.e., if
. By using linear interpolation in (
9),
is positive and real-valued, and much more suitable for statistical inference (
Jentsch and Leucht 2016;
Ma et al. 2011). For a continuously distributed r. v., we set
, in analogy to the equality
. Summaries of the discussed risk measures are provided by
Table 1 and
Table 2.
Remark 1. We are well aware that many further risk measures have been proposed in the literature. For example, several risk measures are related to the three-parameter family proposed by Stone (1973), taking the form with and (for count r. v.). In fact, also the numerator of the TCE in (2), , has to be mentioned in this context, which is obtained by setting , , and . Other examples are the semi-deviations discussed by Ruszczyński (2010, p. 242) in the context of dynamic risk measures, i.e., . To keep the scope of the present article manageable, we refrain from including further risk measures into our study than those five defined before. But we point out that also these Stone measures are easily computed in analogy to (2), i.e., as , where the last term only requires to compute a finite sum. For the sake of a concise presentation, we also dispense with including additional cost considerations, as it was done, for example, by Alwan and Weiß (2017). We may interpret the as assigning constant costs to the risk event , whereas the assumes linearly increasing costs. Power cost schemes could be achieved using adapting the aforementioned Stone approach. 2.2. Some Properties of Risk Measures for Counts
Let us have a first look at some properties of the five risk measures for counts from
Section 2.1 see
Table 1), in contrast to their normal counterparts from
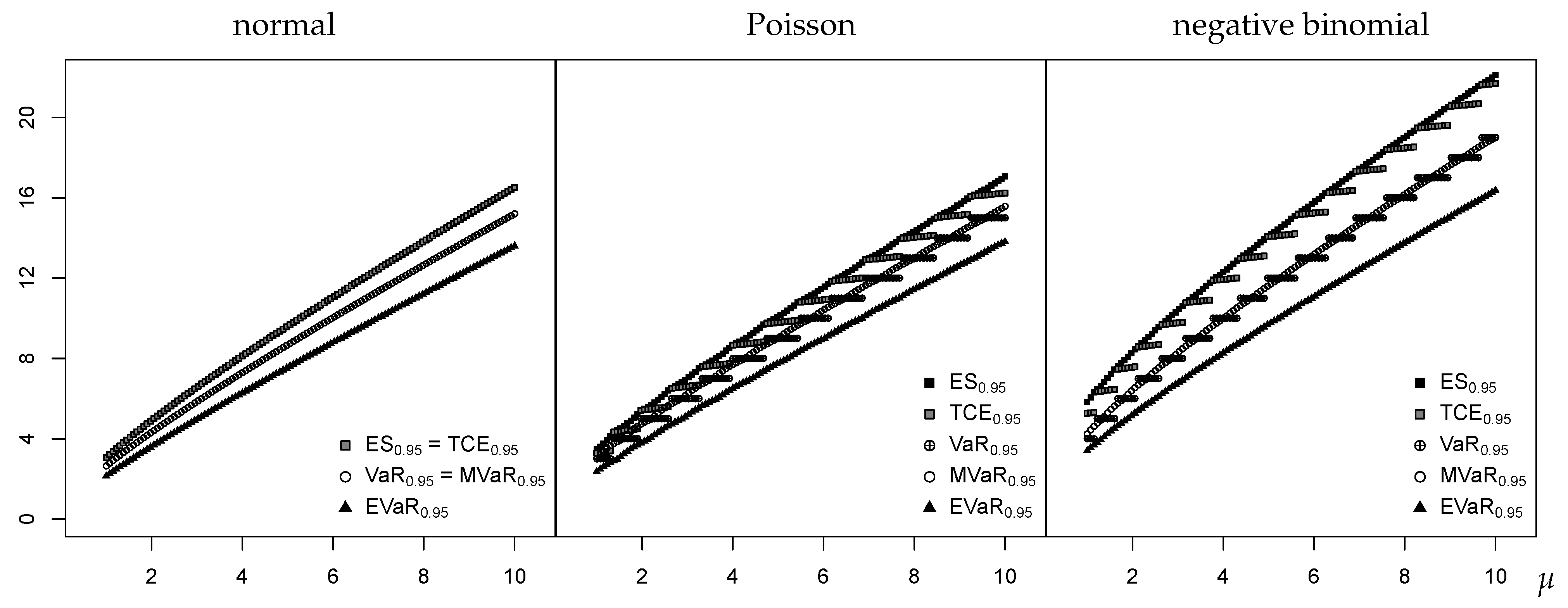
Table 2. We start with the normal case, as this is more familiar to most practitioners. The first graph in
Figure 1 plots the risk measures for a normal distribution with mean
and variance
(the Poisson distribution discussed afterwards has the same equidispersion property), where the risk level is given by
. It can be seen that all risk measures are continuous and strictly increasing functions in
, with
. For the presented scenario, all these measures are also greater than
. Here and in the remaining plots of
Figure 1, we also recognize increasing spread between the different measures for increasing
, which is due to the variance being proportional to
in all scenarios.
Next, we turn to the case of the Poisson (Poi) distribution with mean
,
, which is the most common distribution for unbounded counts (see
Table A1 in
Appendix A for computational details). As is well known, the shape of the
distribution approaches that of the normal distribution
with increasing
. So it is natural to expect that also the risk measures computed for
are close to those for
. This, however, is not true in general as can be seen from the second graph in
Figure 1. First, we recognize that
in contrast to the normal case, and also
in those cases where
does not take an integer value (recall the discussion in
Section 2.1). Second,
is not continuous but a piecewise constant function in
, taking only integer outcomes, whereas the remaining measures are strictly increasing in the Poisson mean
. Third, the
behaves rather different from the normal case. It is only a piecewise continuous function in
, which can be explained by Equation (
5):
is a weighted mean of the continuous
and the piecewise constant
. In addition, the actual values of
are often closer to those of
than of
, which is opposite to the normal case with
. This happens if the weight
in (
5) is much smaller than 1, i.e., if
is much smaller than
. The reason for this phenomenon is given by the rather low dispersion of the Poi distribution (equidispersion): The upper tail of its PMF declines quickly towards 0, so we have rather large gaps between the attainable tail probabilities. Finally, there are also a few analogies between the normal and the Poi-case:
,
, and
behave quite similarly at a first glance. So, while there appears to be some chance that
,
, and
relying on a normal approximation might be close to their actual Poisson values, we cannot expect that such an approximation works well for
and
(
Homburg et al. (
2019) investigate discrete quantile forecasts and apply an additional discretization (ceiling) to the approximate Gaussian quantiles. Nevertheless, the approximation quality turns out to be very poor.).
In the third scenario shown in
Figure 1, we consider counts stemming from a negative binomial (NB) distribution with mean
and dispersion index
, see
Table A1. So, while the Poi distribution is equidispersed (
), the NB distribution exhibits overdispersion. This additional dispersion has the following consequences: We have a stronger discrepancy between
,
, and
, and the measures
and
are now clearly separated. In fact,
is now more close to
than to
, so these measures behave more similar to the normal case in this respect. This is explained by (
5) and by the additional probability mass in the NB’s upper tail, which implies that
is closer to
than in the Poi-case.
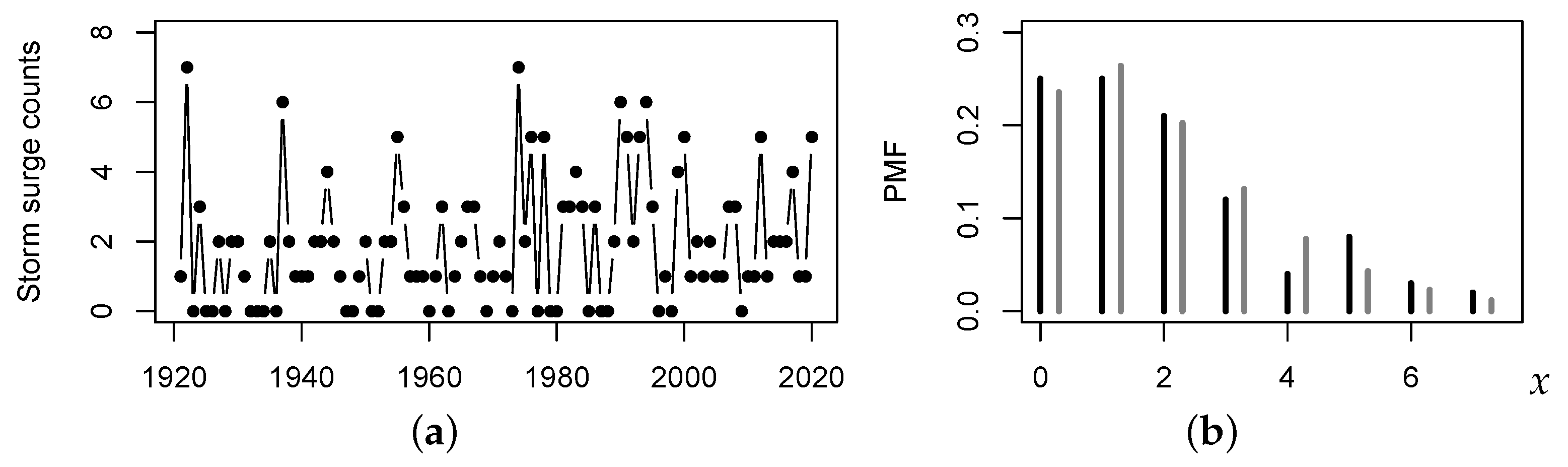
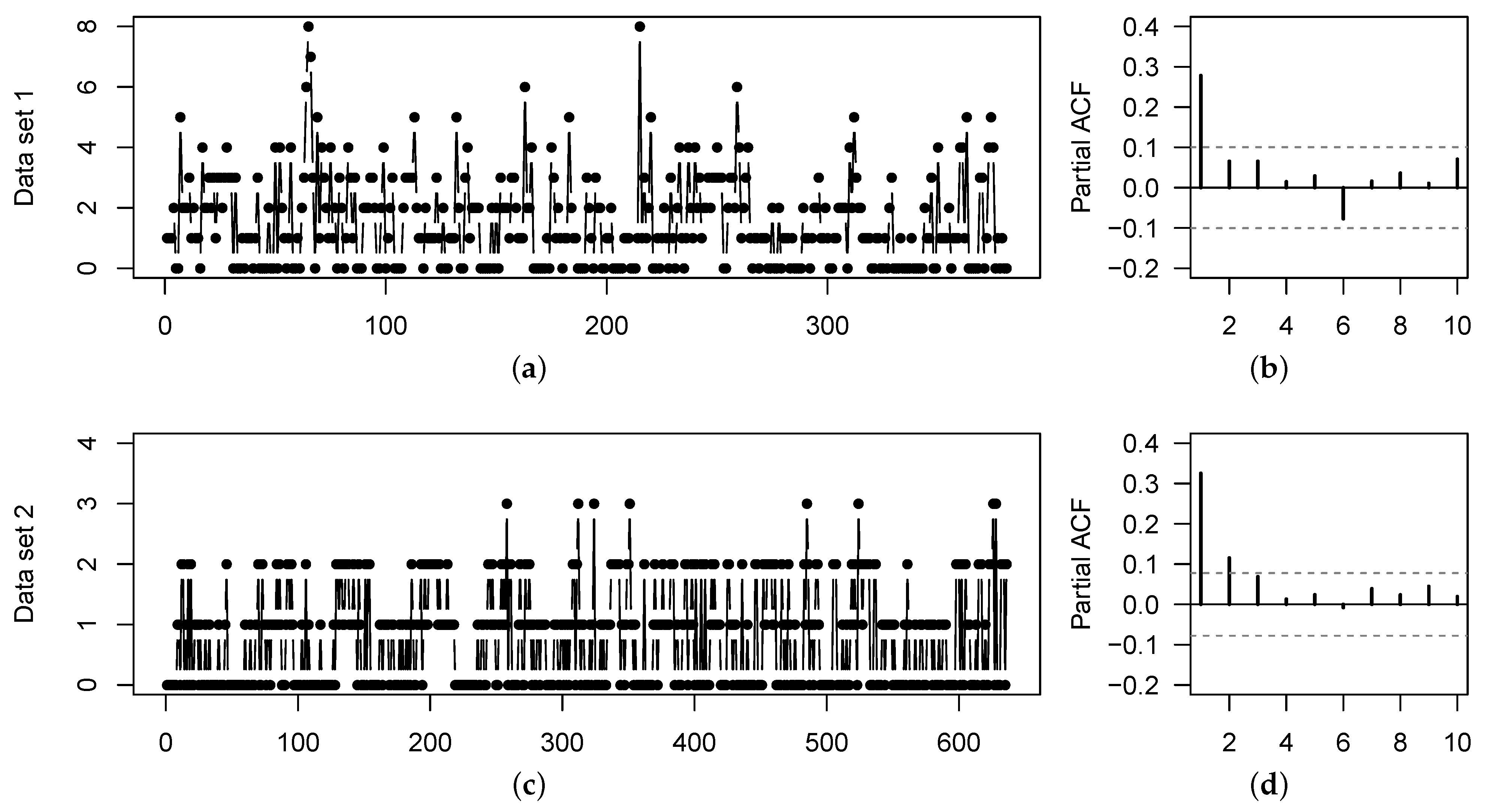
2.3. Data Example: Storm Surges in Norderney
At this point, let us look at a first real-world application. Storm surges have threatened the German coasts since time immemorial, with increasing economic damage because of an intensified use of the coastal areas, see
Jensen and Müller-Navarra (
2008) for a comprehensive survey. The website “Storm Surge Monitor” at
https://www.sturmflut-monitor.de/index.php.en (accessed on 15 December 2020) provides information about the temporal development of storm surges during the last decades at different locations along the North and the Baltic Sea. As an illustrative example, let us analyze the last hundred seasons of storm surges in Norderney (an island in the German Bight, North Sea), where a season extends from July of the previous year to June of the current year. The count time series
with
provides the numbers of storm surges for the seasons 1921–2020, see the plot in
Figure 2a. The corresponding sample autocorrelation function (ACF) does not show significant deviations from 0, so it appears reasonable to model the data as being i. i. d. Their sample mean equals
, their sample dispersion index
. So we are concerned with a considerable degree of overdispersion such that the NB distribution appears to be a plausible candidate model. The PMF
of the fitted
distribution is compared to the sample PMF in
Figure 2b, showing a reasonable agreement. Thus, we shall model the storm surge counts as being i. i. d. according to
.
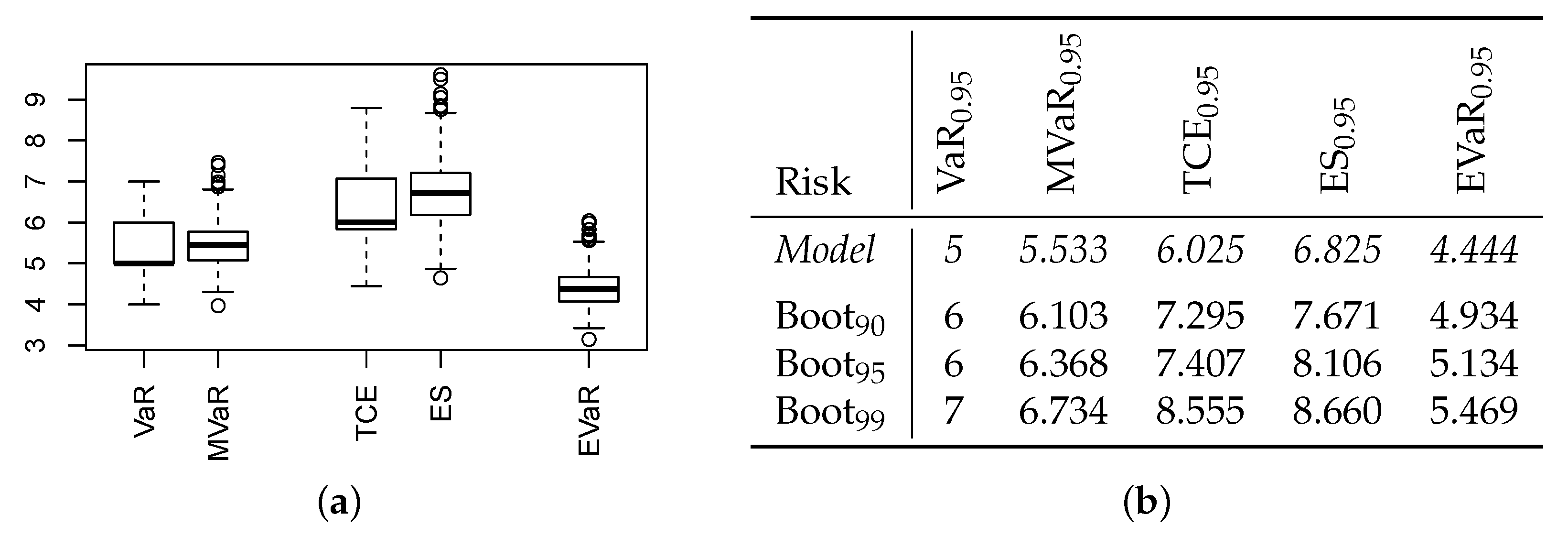
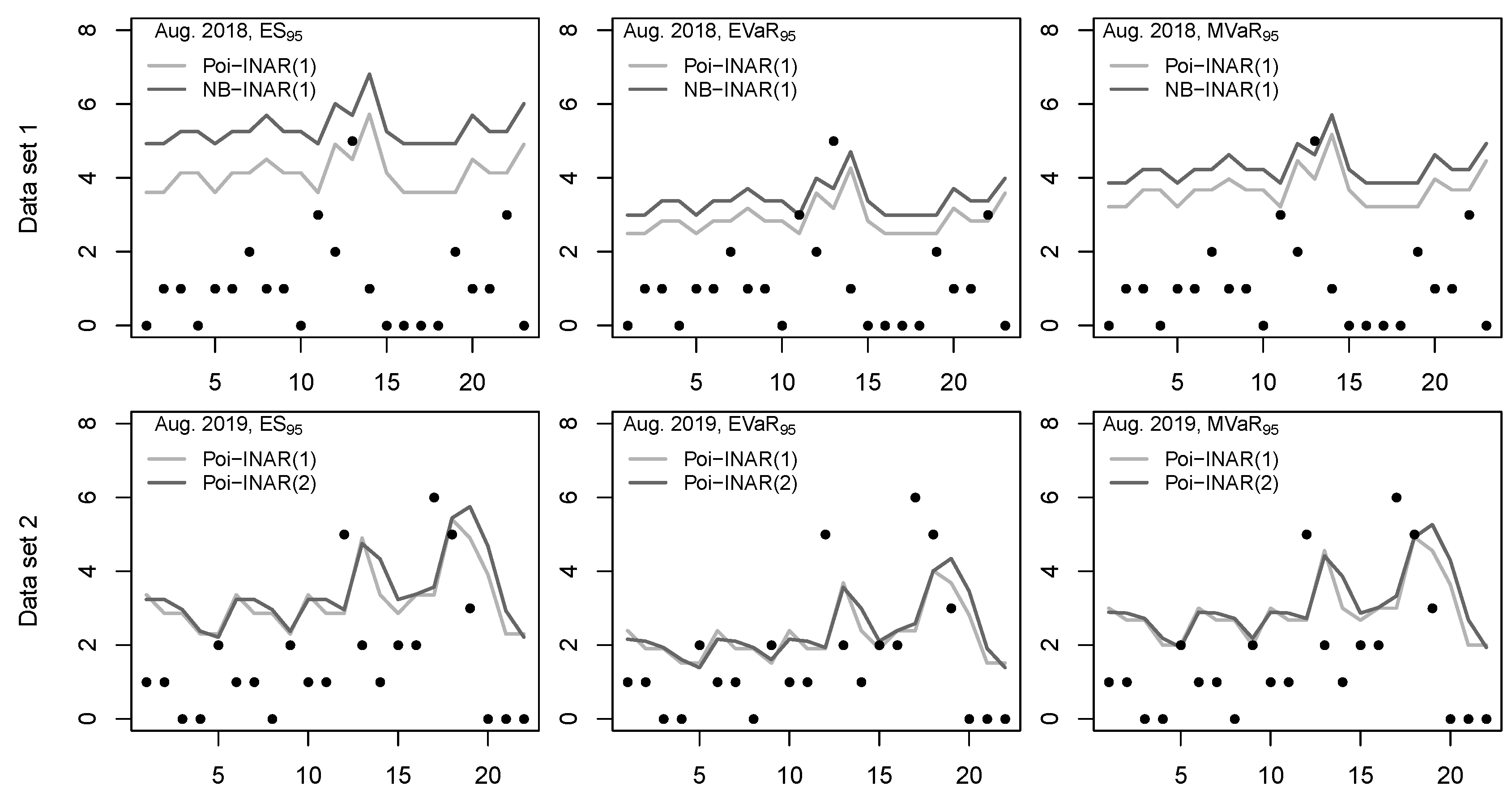
Since the potential for economic damages (loss) increases with an increasing number of storm surges, we focus our risk analysis on the upper tail of the storm surges’ distribution. For convenience, the risk level is again set at
. We start by computing the five risk measures for counts from
Section 2.1 for the fitted NB-model (coherent risk forecasts). Here, the
takes the value 5, i.e., in at most 5% of all seasons, we expect to observe more than five storm surges. The
can be understood as a refinement of the discrete
, leading to the value
. If having a season with ≥5 storm surges, then we actually expect
storm surges on average according to the NB-fit, whereas the
leads to the even larger value
. The
, in contrast, relying on the concept of expectiles, leads to a clearly lower risk value, namely ≈4.444. These risk assessments might be used for defining appropriate preparations and countermeasures in practice. But here, they shall serve as the starting point for further statistical analyses.
First, we check what would have happened if we would have used a fitted normal distribution for computing the risk measures, recall
Table 2. Then,
, i.e., these approximate risk forecasts would be lower than their coherent counterparts. The same happens for
as well as for
. So, using the Gaussian approximation, the risk is always judged lower than if using the coherent NB-model. For the considered application, such a risk underrating might lead to, e.g., insufficient capital reserves for dealing with the economic damages caused by the storm surges. Given these discrepancies, the question arises whether risk predictions based on a Gaussian approximation generally tend to underrate the risk, or whether we have found only sporadic evidence in this data example. To answer this question, we present results from a comprehensive simulation study later in
Section 4.
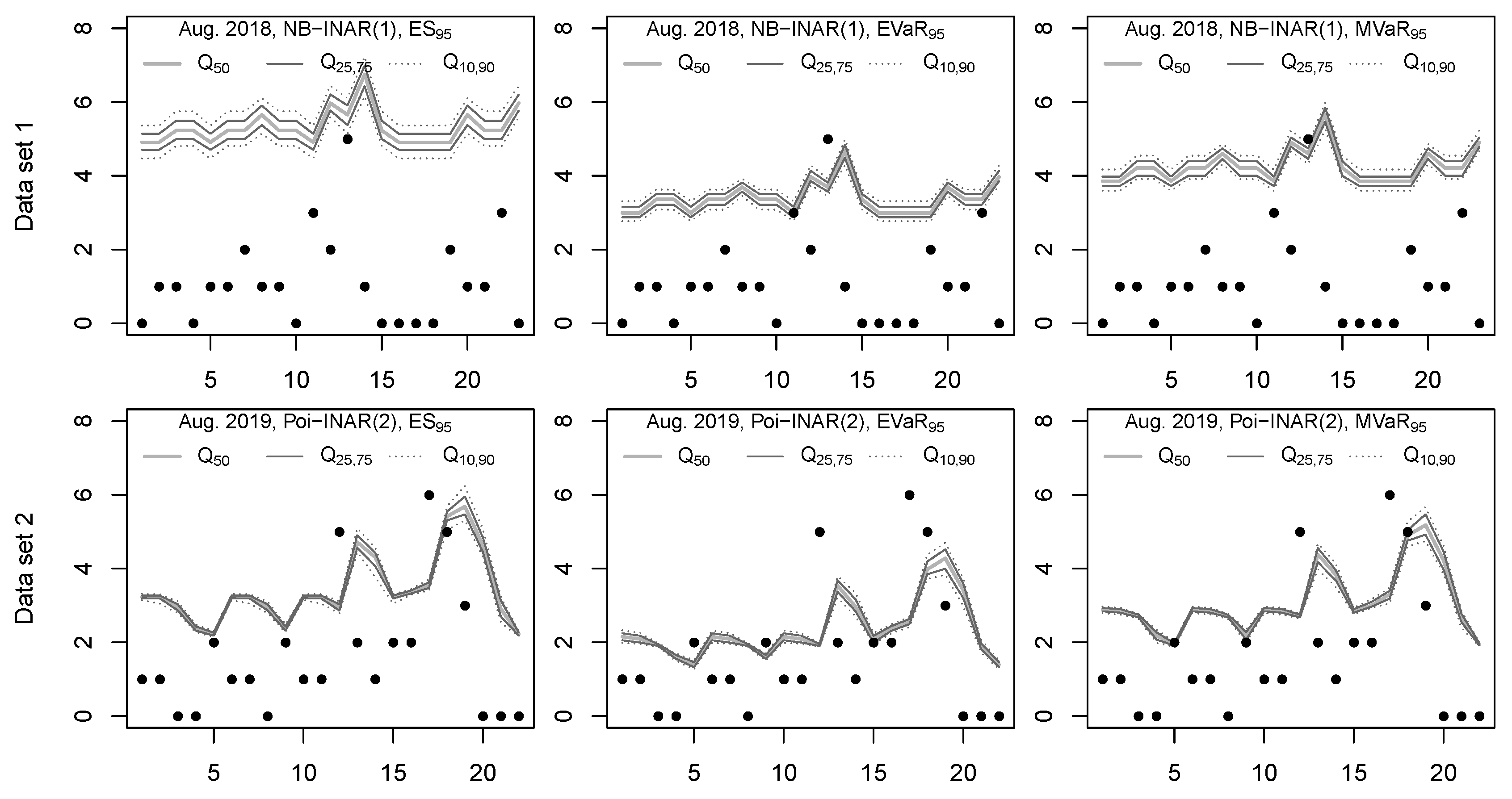
Second, even if using the more “conservative” coherent risk forecasts, one has to recall that these rely on a fitted model with
observations. The question arises to what extent the apparent estimation uncertainty affects the computed risk forecasts. Let us investigate this question with a bootstrap experiment. We generated 1000 i. i. d. samples from the
distribution (parametric bootstrap), fitted again a NB-model to each of the bootstrap samples, and computed the five risk measures based on these model fits. So for each risk measure, 1000 bootstrap replicates are available. Part (a) of
Figure 3 shows boxplots of the replicated risk forecasts, which exhibit a lot of dispersion. Note that the boxplots of VaR and (slightly weakened) of TCE look degenerate because of the discreteness pattern already discussed in
Section 2.2. So for practice, it appears to be advisable to account for the apparent estimation uncertainty before defining the countermeasures. Since the risk measures express some kind of “worst-case” scenario, a reasonable solution could be to compute an upper quantile from the bootstraped risk forecasts and to use this quantile for decision making. The table in
Figure 3b presents such quantiles for the levels
for illustration. The task of accounting for the effect of estimation uncertainty on the coherent risk forecasts is further investigated in
Section 5 below.





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}









