Herein we consider two different specifications of utility: (i) the standard model with separable and additive expected utility, and (ii) recursive utility of the Duffie–Epstein type with a Kreps–Porteus specification of the associated certainty equivalent, the latter being derived from expected utility.
It follows from optimal consumption and portfolio choice theory that the optimal consumption per time unit,
, and the optimal wealth at time
t,
, are connected. The starting point for this derivation is the following formula for the market value of current wealth
.
is the conditional expectation of any random variable
X given the information by time
t, where
is the information filtration,
and
is the state price deflator. Under the assumption of no arbitrage possibilities, it is given by
where
is the risk free rate of return at time
t,
is the market price of risk and
is a standard
d-dimensional Brownian motion, which generates the information set
for all
.
3.1. Optimal Consumption and Extraction with Expected Utility: A Deterministic Investment Opportunity Set
The agent’s optimal consumption and portfolio choice is determined next. First we give a representation of the optimal consumption
at any time
. By employing Kuhn–Tucker and the saddle point theorems, we find that the optimal consumption is given by
where
is the Lagrange multiplier, ultimately determined by equality in the budget constraint. This gives the following dynamics for the optimal consumption.
where,
and
Let
signify the investment opportunity set. We can write the optimal wealth in Equation (
3) of the agent in terms of the optimal consumption as follows.
where we have used the dynamics for the state price deflator in (
4) and for the optimal consumption in (
6).
In this expression the conditional expectation is in general a random variable (process), in which case the volatility of is not the same as the volatility of , and the instantaneous correlation coefficient between these two processes is not unity. We want to compute the conditional expectation, and consider two cases: (i) where the investment opportunity set is deterministic, and (ii) where the set is stochastic.
We start with (i). Clearly this assumption involves some loss of generality. We treat the situation (ii) later. In
Section 3.7 (for expected utility) and in the section about general recursive utility, aside from the obvious main result of the paper which is of an applied nature, the theoretical contributions of the paper can be found.
Now, by the Fubini theorem and the moment generating function of the normal distribution, we can write the above equation as follows.
The optimal consumption to wealth ratio is then
where
is an estimate of the optimal extraction rate at the present time
t, where
. The expression for
can be written as
where the
k is a constant for all
t by our above assumption (i), and is given by
Provided that
, the function
as
for any fixed value of
t.
1The result that
k is non-random and time invariant follows from our assumption about a deterministic investment opportunity set. For example, it has as the consequence that the volatility of
W is the same as the volatility of
c. If the investment opportunity set is stochastic, naturally this is no longer true. However, in order to focus on the essential questions raised in this paper, we make this simplification here. We analyze the situation with a stochastic investment opportunity set in
Section 3.7 below.
With a very long horizon
T, it is optimal for the agent to consume a fraction of the remaining wealth at any time
t. In reality, this fraction is a stochastic process. Here it is a deterministic function slowly increasing in
t, and when the horizon approaches, it increases sharply (see, e.g.,
Figure 1 below). If the horizon is unbounded at the outset, the fraction
k is consumed forever.
3.2. The Real Rate of Return versus the Optimal Extraction Rate
Recall the dynamics of the wealth portfolio
. It is given by the following stochastic differential equation.
We do not use control theory explicitly in our exposition. In the language of optimal control theory, in order for the wealth
W to remain nonnegative, any admissible control
has
and
for
t larger than the stopping time inf
. Thus, nonzero investment and spending are ruled out once there is no remaining wealth.
The problem (
1) of maximizing utility subject to the agent’s budget constraint results in both the optimal fractions in the various securities, and the associated optimal consumption, see
Mossin (
1968);
Samuelson (
1969) and
Merton (
1969,
1971) for the earliest treatments of this joint problem). With a deterministic investment opportunity set, the optimal portfolio weights at any time
t are given by
We want to compare the optimal extraction rate
k given Equation (
11) with the (conditional) expected real rate of return on the optimal wealth portfolio
, which is the solution to the stochastic differential equation (Equation (
12)) with
, the optimal consumption and the portfolio fractions given in Equation (
13). The (simple) return in the time interval
is
, where
With this interpretation, Equation (
14) is a standard expression for the real return with dividends.
Accordingly, from (
14), Equation (
12) and the optimal portfolio rule in Equation (
13), the
t-conditional expected real rate of return of the wealth portfolio is given by the following expression:
The optimal extraction rate
k may be rewritten as follows.
We then have the following result.
Proposition 1. Assuming a deterministic investment opportunity set, the optimal extraction rate k is a constant and depends on the return from the fund only via the certainty equivalent rate of return, and can be written as Proof. Starting with the risk premium,
where we have used (
13). From this result it follows that the quantity
can be recognized as relative certainty equivalent for “proportional risks”, since
is the volatility of the wealth portfolio (see Equation (
12)).
2 □
One basic comparison is between the expected real rate of return on the wealth portfolio given in (
15) and the optimal extraction rate
k. Assuming an infinite horizon for now, the inequality
holds if and only if
Since the second term on the right-hand side is negative, this inequality is true for reasonable values of the parameters of this problem.
3Alternatively, using the certainty equivalent and the representation for
k given in Equation (
16), the inequality (
19) is equivalent to
That is, when half the expected excess return on the fund over the risk-free rate is larger than the right-hand side of (
20), then the extraction rate is lower than the expected rate of return on the wealth portfolio.
Again, for reasonable values of the parameters of the problem, this can be seen to hold true. A very simple case occurs when
, in which case the inequality is obviously true, a fact which can be recognized from the inequality (
19) as well.
Typically, the real risk-free rate close to
is consistent with US-data (see
Table 1 below). Additionally, a reasonable value for the impatience rate is around
.
4 In this case the risk premium of the fund is certainly positive, about
for the data of
Table 1, so the inequality (
20) holds with a significant margin.
We conclude that for plausible values of the parameters, the optimal extraction rate is strictly smaller than the expected real rate of return on the wealth portfolio.
It can be seen that when the extraction rate k equals the expected rate of return on the fund W, then the expected value for any horizon t, and can be shown to be a martingale. Seen from time 0, the end wealth of the agent corresponds to the random variable , not the sure amount . Considered from the beginning of the period, a risk-averse agent would prefer the to the random wealth . A claim that the agent considers the random future value as equivalent to the plain expected value as of time zero thus rests on an implicit assumption that the agent is risk-neutral.
To use the expected return on the endowment fund as the extraction rate is, on the other hand, consistent with investing “everything” in the single risky asset, or group of assets, with the largest expected return(s) one can find, and completely ignoring risk.
5 Few responsible agents would recommend this “optimum portfolio selection strategy” for an endowment fund.
This is, however, what
Campbell (
2012) seems to claim, where the author recommends that
k is set equal to the real expected rate of return. In the author’s own words:
“The sustainable spending rate of an endowment, which is the amount spent as a fraction of the market value of the endowment, must equal the expected return in order to achieve immortality.”
This is called “vigorous immortality” by the author. As we have just demonstrated, this policy is a little bit too vigorous to be rational and consistent, and implies the above-mentioned contradiction. This policy will eventually deplete the fund with probability 1, to be shown in the
Section 3.5.
Can the policy advocated by
Dybvik and Qin (
2019), also considered in
Campbell and Sigalov (
2020), be consistent with the optimal spending rule outlined in the above? A little analysis shows that this requires
and
, but the latter is not allowed in our model. Accordingly, the criterion of the expected return subtracted by half the variance is not optimal for valid values of the preference parameters.
3.4. Examples Based on Expected Additive and Separable Utility
As an example, consider a wealth fund described by the three upper rows of
Table 1. The consumption data in
Table 1, the fourth row, has to do with society at large, which is not under consideration here.
Let us assume a relative risk aversion of
, and an impatience rate
. For the market structure of
Table 1, we obtain that the expected rate of return on the wealth portfolio is
and the certainty equivalent rate of return is
, corresponding to the optimal portfolio selection rule
. The optimal extraction rate under our assumptions is
, corresponding to
. The drawdown rate is seen to be significantly lower than the expected rate of return on the portfolio for these rather reasonable parameters of the preferences of the agent.
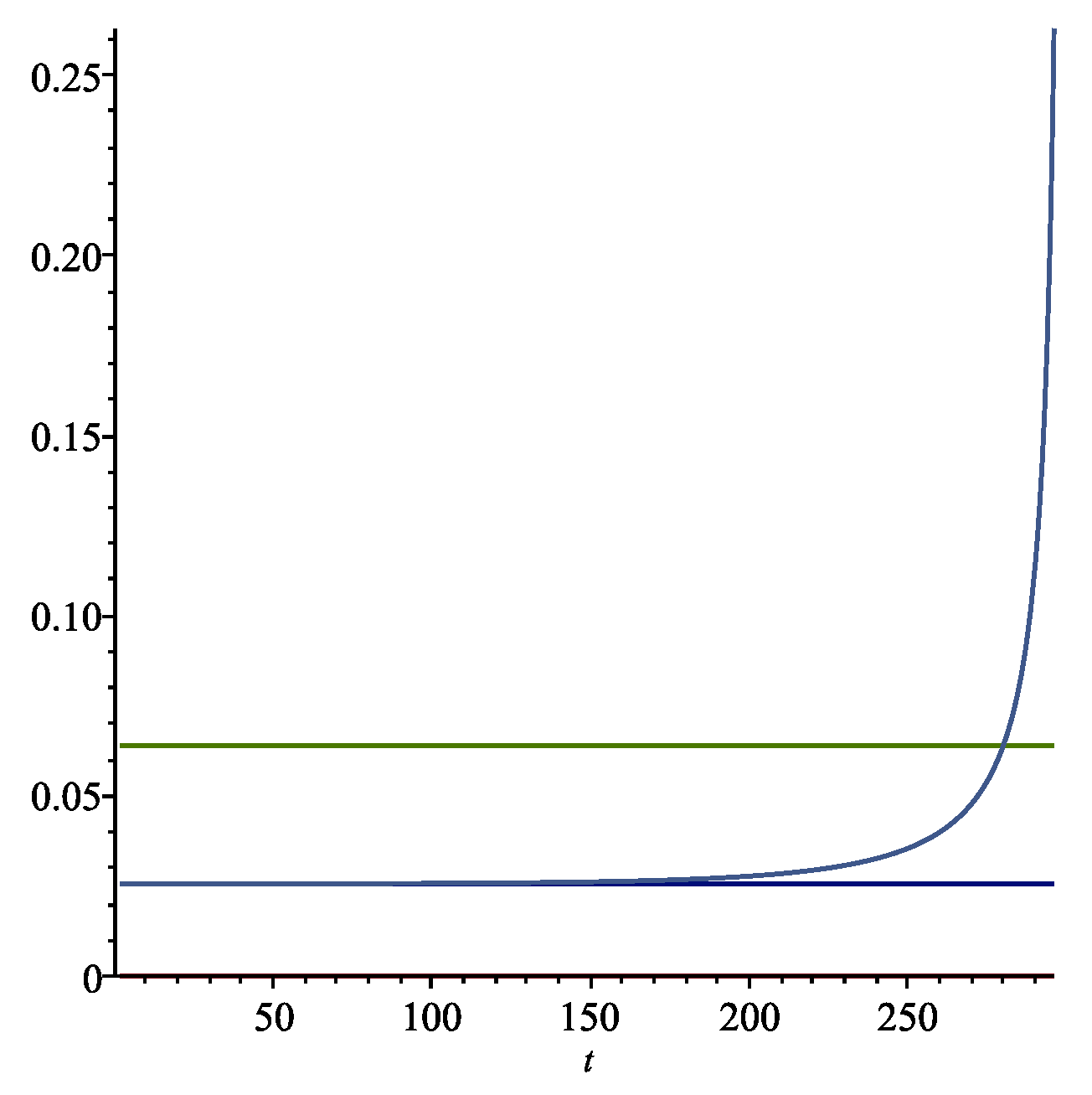
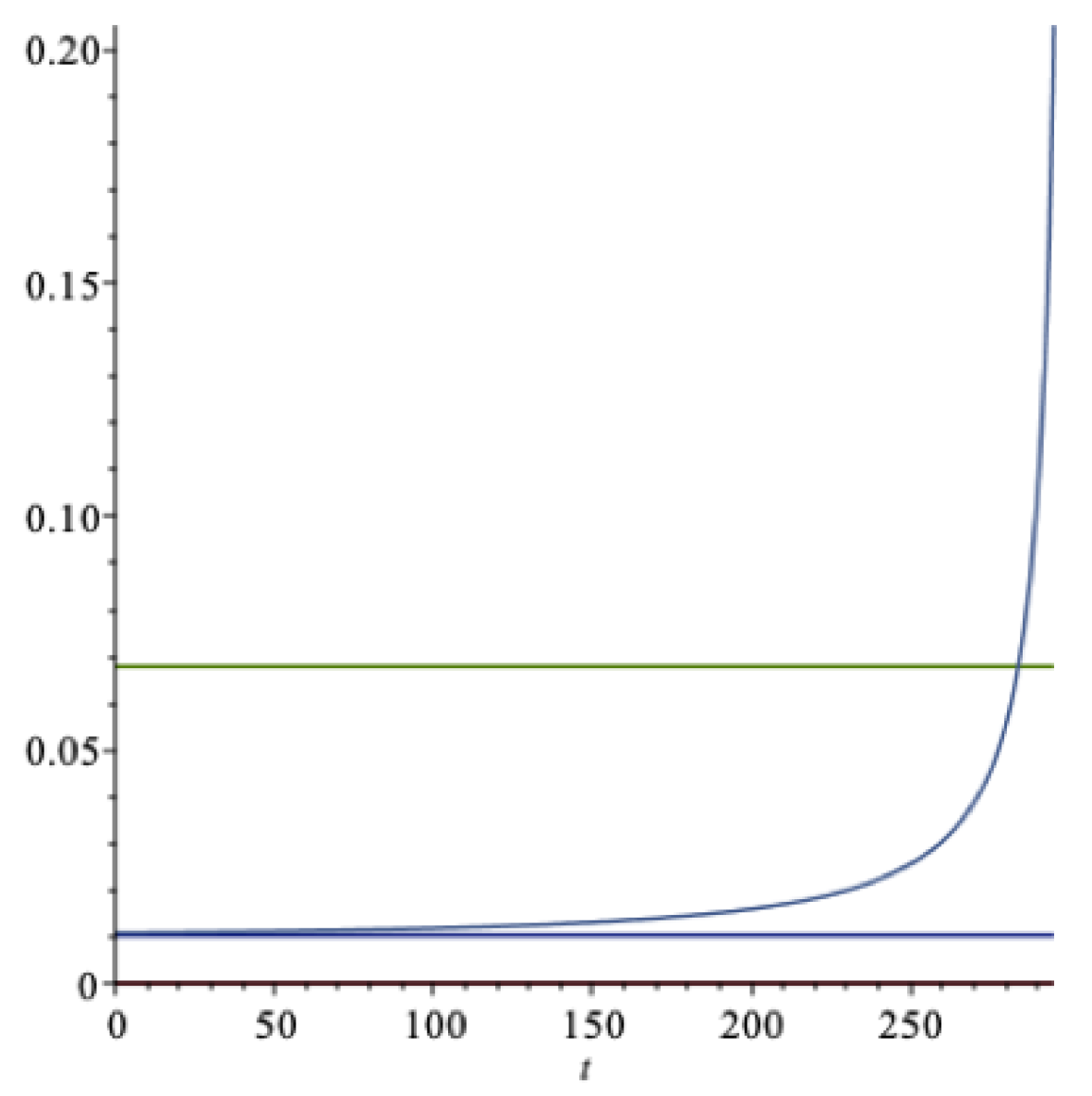
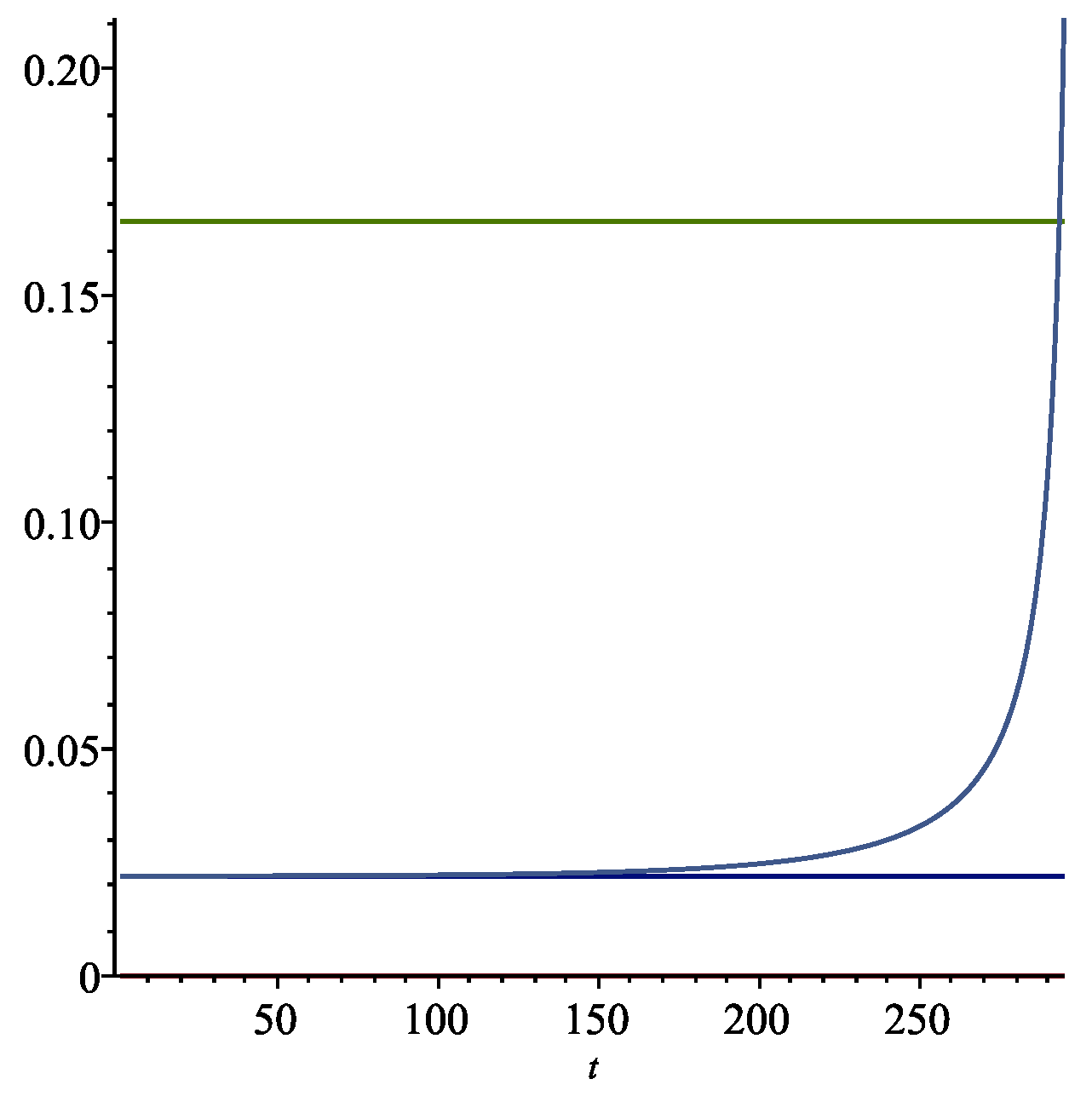
In
Figure 1 we present graphs with a finite time horizon of
years using the expected utility model explained above, with the parameters of this example. The optimal long run extraction rate
k is the lower horizontal (blue) line in
Figure 1. The expected return on the wealth portfolio is the upper horizontal (green) line in the figure. As the horizon approaches, there is a sharp increase in the rate of consumption. After about 200 years, the rate
, a modest increase from the steady state value of
.
The optimal consumption in this case has the expected growth rate given by the formula
As in the proof of Proposition 1, we can alternatively write this as
This term is estimated as
, and the estimate of the volatility
is
, which equals the estimate of
. According to our assumption about a deterministic investment opportunity set, this implies that these two volatilities must be equal—i.e.,
.
As noticed, the optimal extraction rate k can be written as an arithmetic mean of the impatience rate and the certainty equivalent return rate, with weight . We may calculate how large the impatience rate must be in order to have an extraction rate equal to the expected return. The answer is . This level is rather unrealistic as an impatience rate.
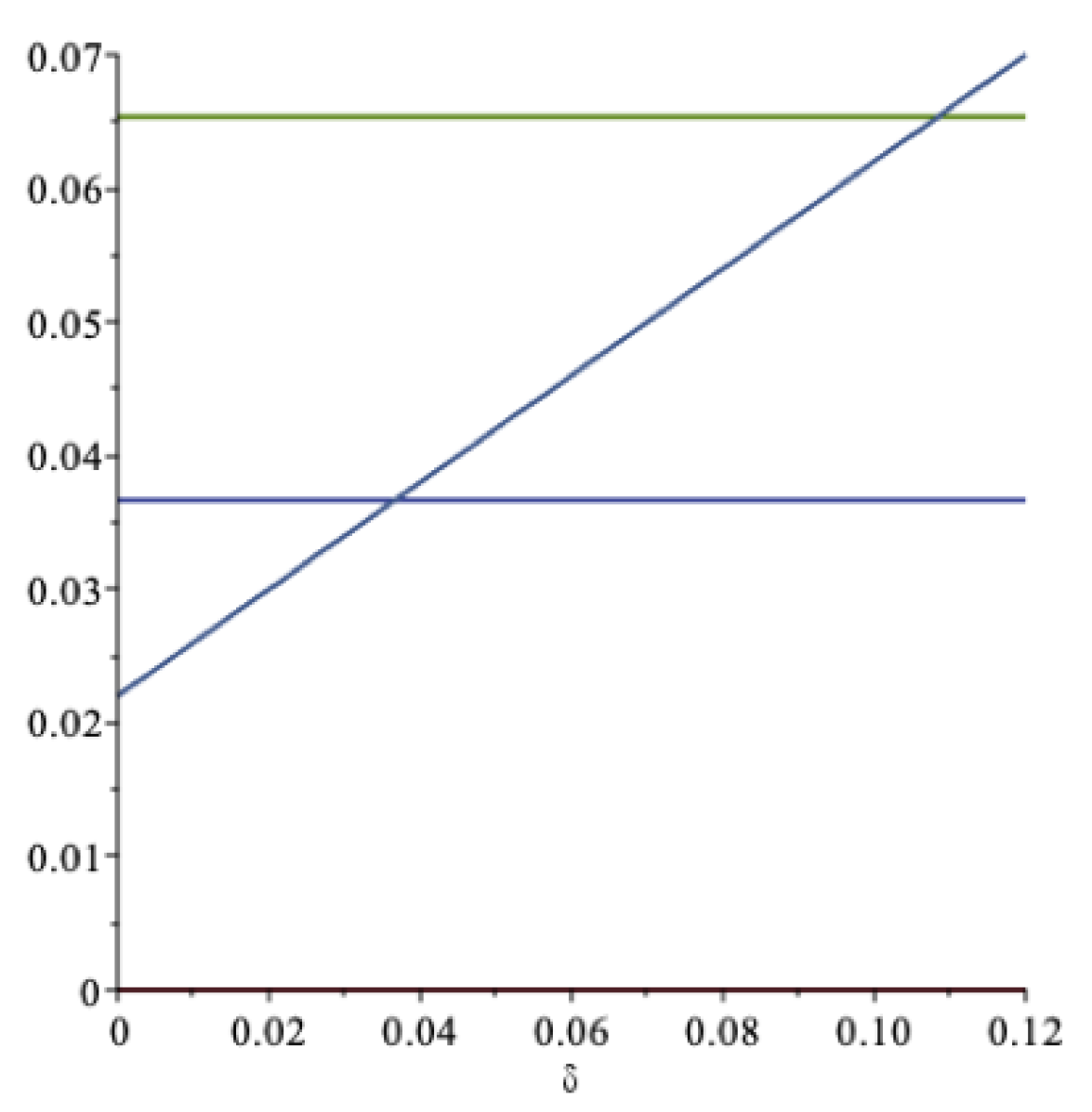
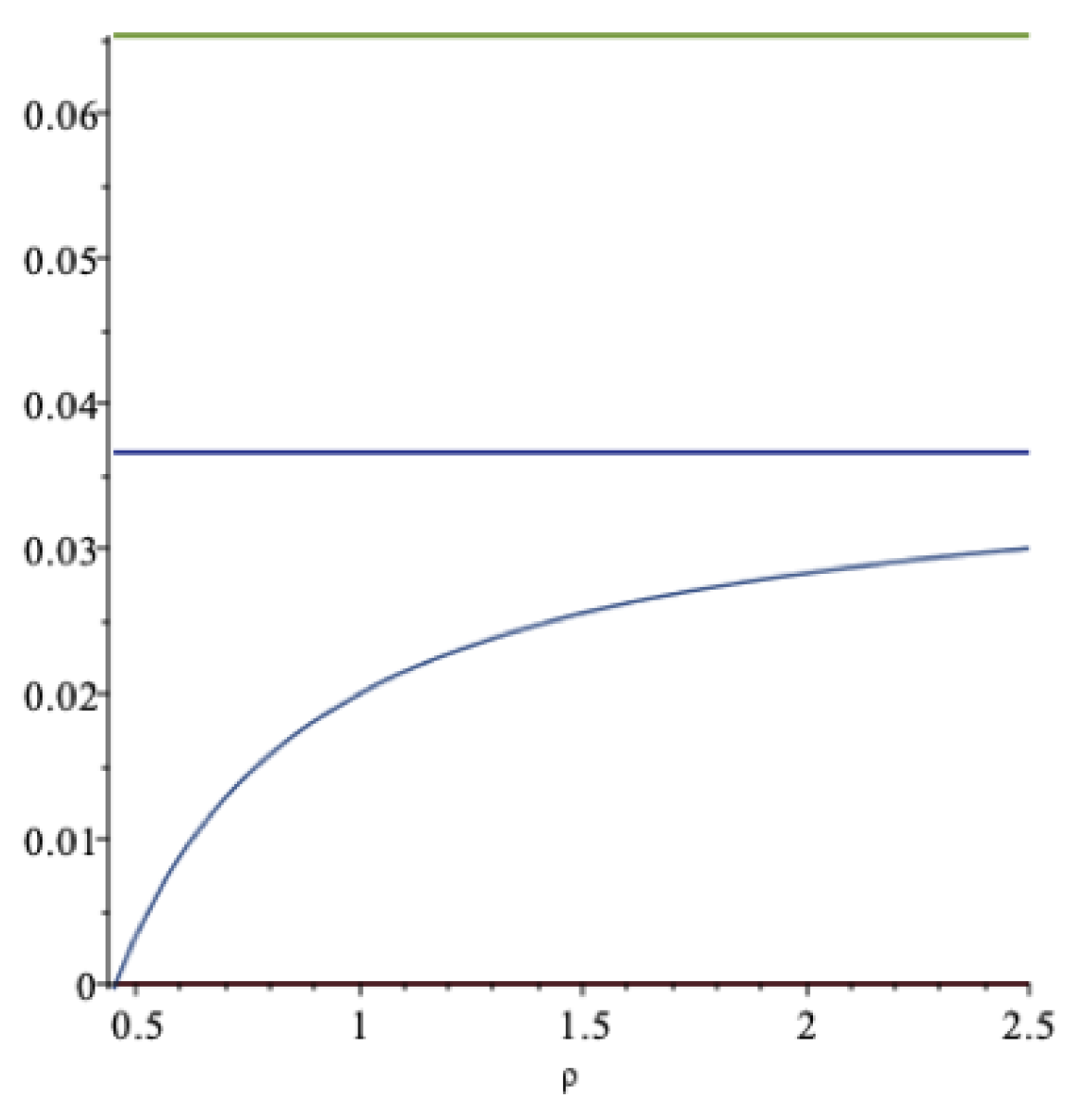
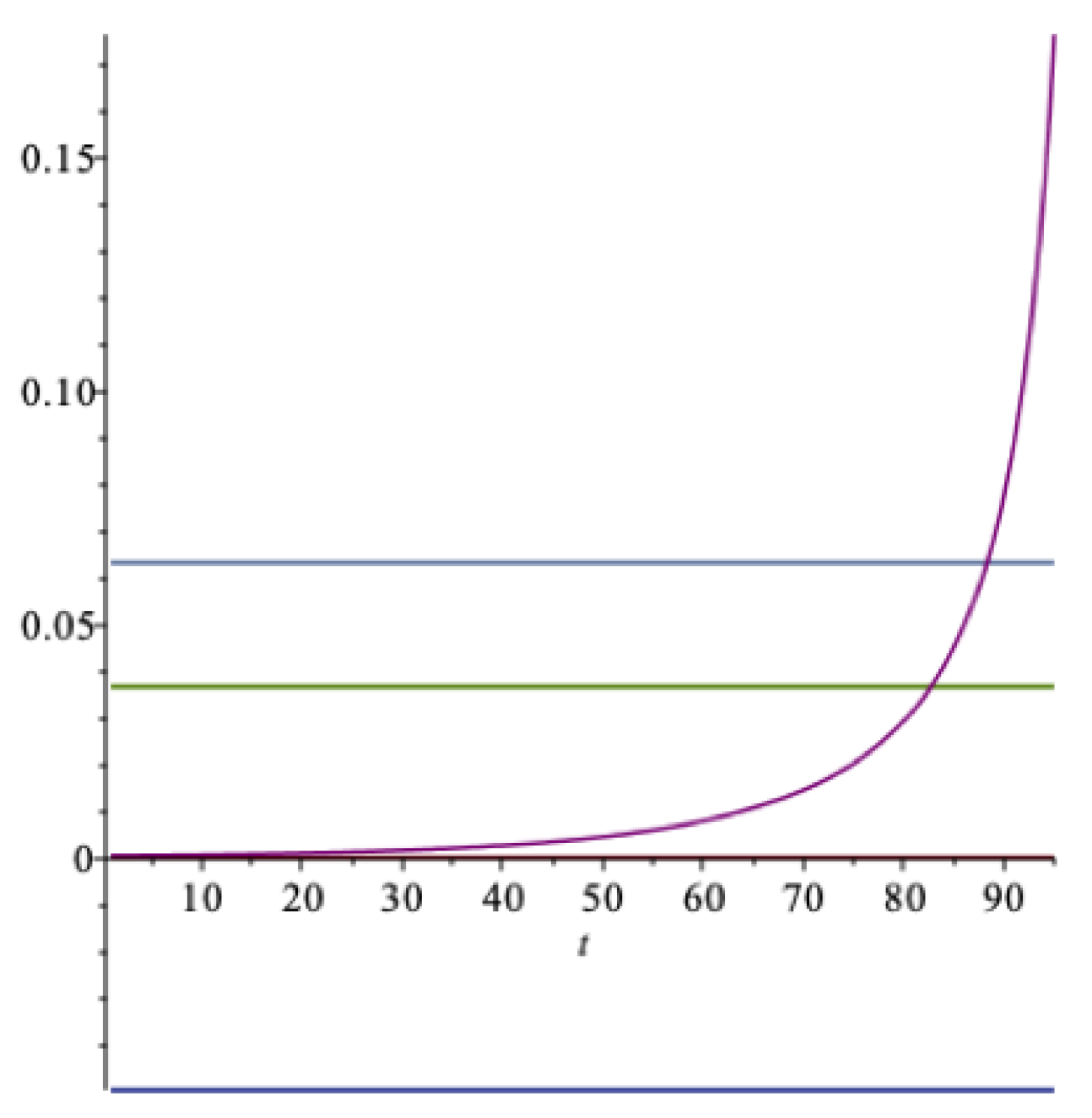
In
Figure 2 these aspects are illustrated. The increasing curve is the drawdown rate
; the lower horizontal line is the certainty equivalent,
, at
; and the upper horizontal line is the expected return,
, at
—all as functions of
. As we can see, the drawdown rate may exceed the expected return, but at a rather unrealistically high value of the impatience rate. For this data set, when the impatience rate is
, then
. An impatience rate above this level is hardly sustainable. At this level of spending, the optimal spending rate
should be compared to the expected rate of return
.
From the inequality (
19) we can notice that when the impatience rate
is large enough, the extraction rate may become larger than the expected rate of return. A high enough degree of impatience may then deplete the fund at a finite time in the future. This is usually not what politicians or owners of colleges and universities have in mind when deciding on an optimal drawdown rate from a fund or an endowment.
Failure to realize this may have
negative consequences for the beneficiaries of the fund. If
k is too large, equal to the expected rate of return from the fund, for example,
8 then the fund will not last “forever” (see
Section 3.5 below).
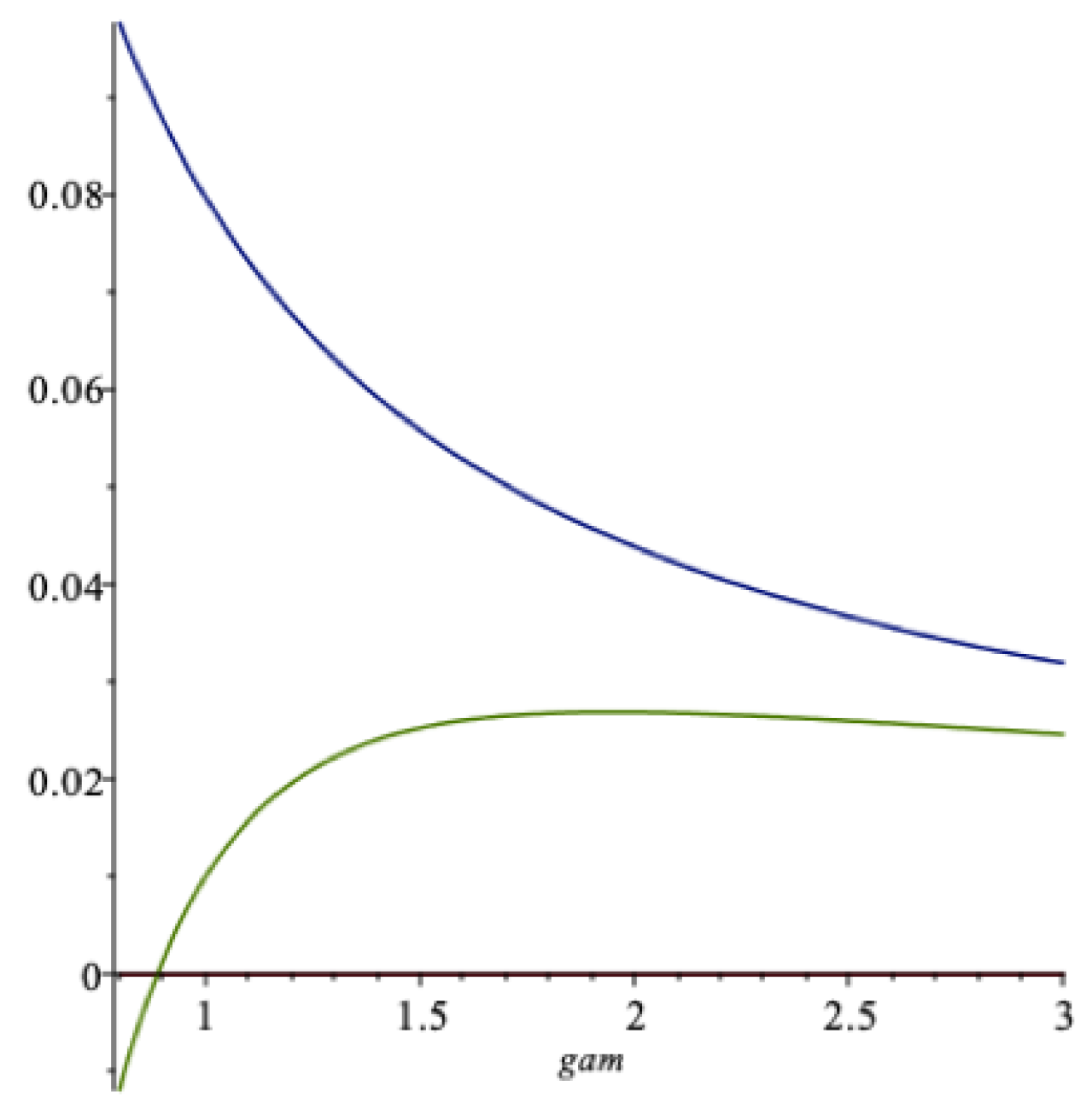
In
Figure 3 we show a graph of the fraction
of the risky asset as a function of
(the falling curve) for the data in
Table 1. In this situation the S&P-500 is a proxy for the risky asset, so here
with one risk-free asset, and
is one-dimensional. When
is larger than about
in this example, the agent does not borrow risk-free, since
is then smaller than 1.
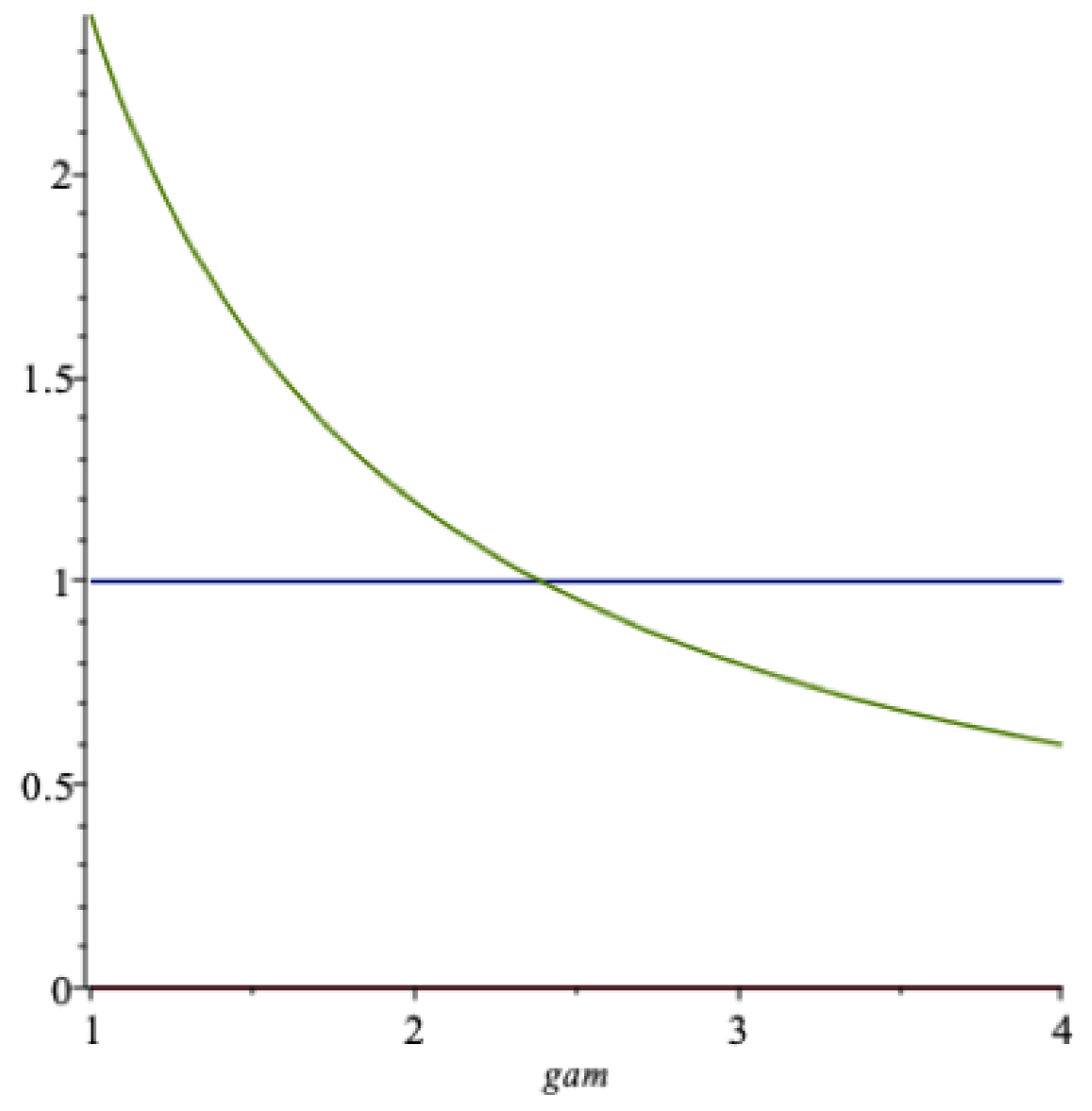
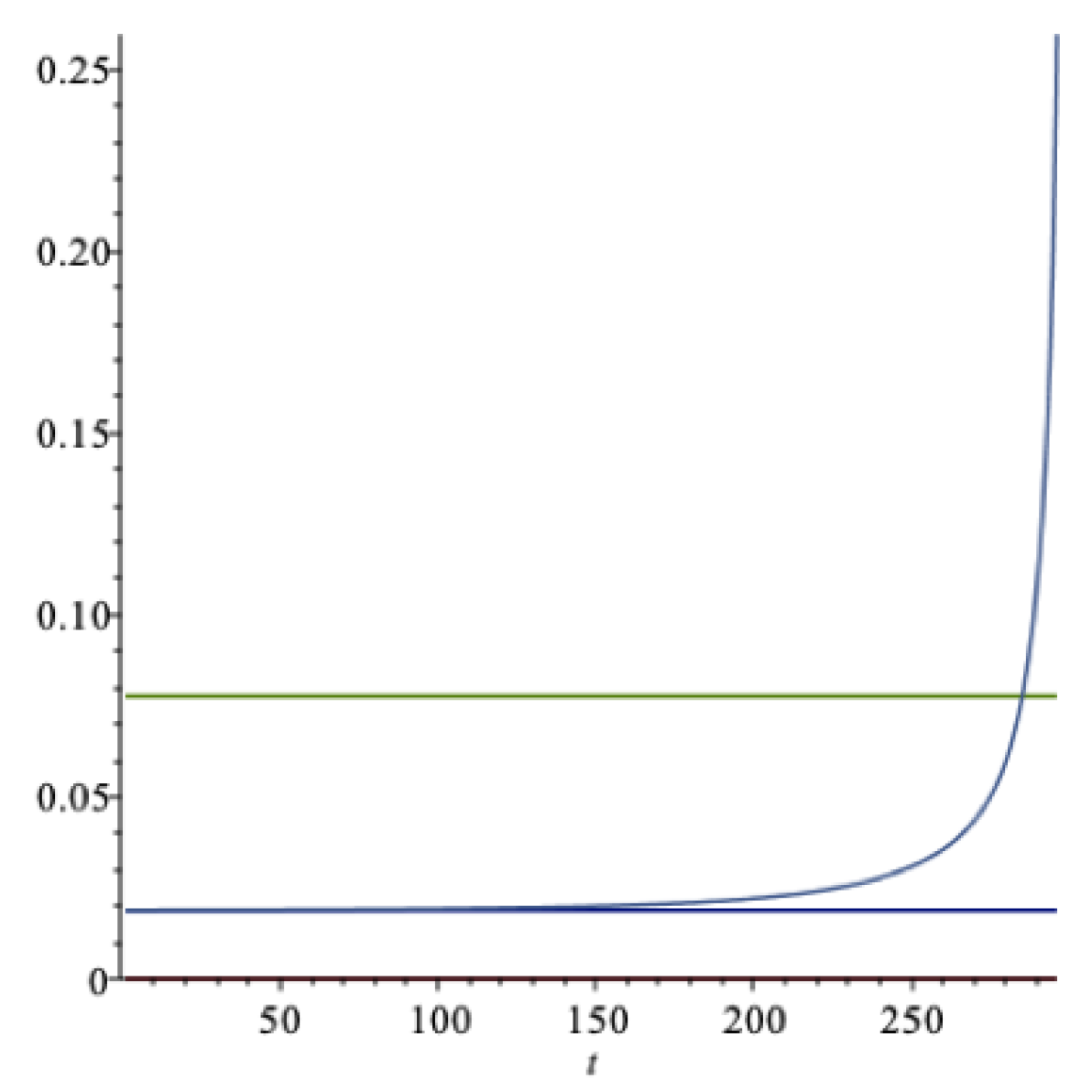
Figure 4 shows a graph of of the optimal extraction rate
as a function of
(the lowest curve) for the data of
Table 1. The upper curve is a graph of the certainty equivalent return
. We notice that
, where the latter quantity is the expected return, not shown in the figure.
The function is falling in when the risk aversion is larger than about in the figure. It may be surprising that it does not decrease over the whole range of -values, but this can be attributed to the two, sometimes conflicting, roles that this parameter plays. In this model the elasticity of intertemporal substitution () in consumption . Later we will separate these to properties of an individual using recursive utility, in which case we denote . The parameter , called the marginal utility flexibility parameter by R. Frisch, is a measure of the individual’s resistance against substituting consumption across time (in a deterministic world). When this parameter increases, the agent will be inclined to extract more from the fund. Since here, this explains the shape of the left part of the graph of k. We demonstrate later that with recursive utility, where the parameters and are separated, the function is strictly increasing in the parameter , under plausible conditions.
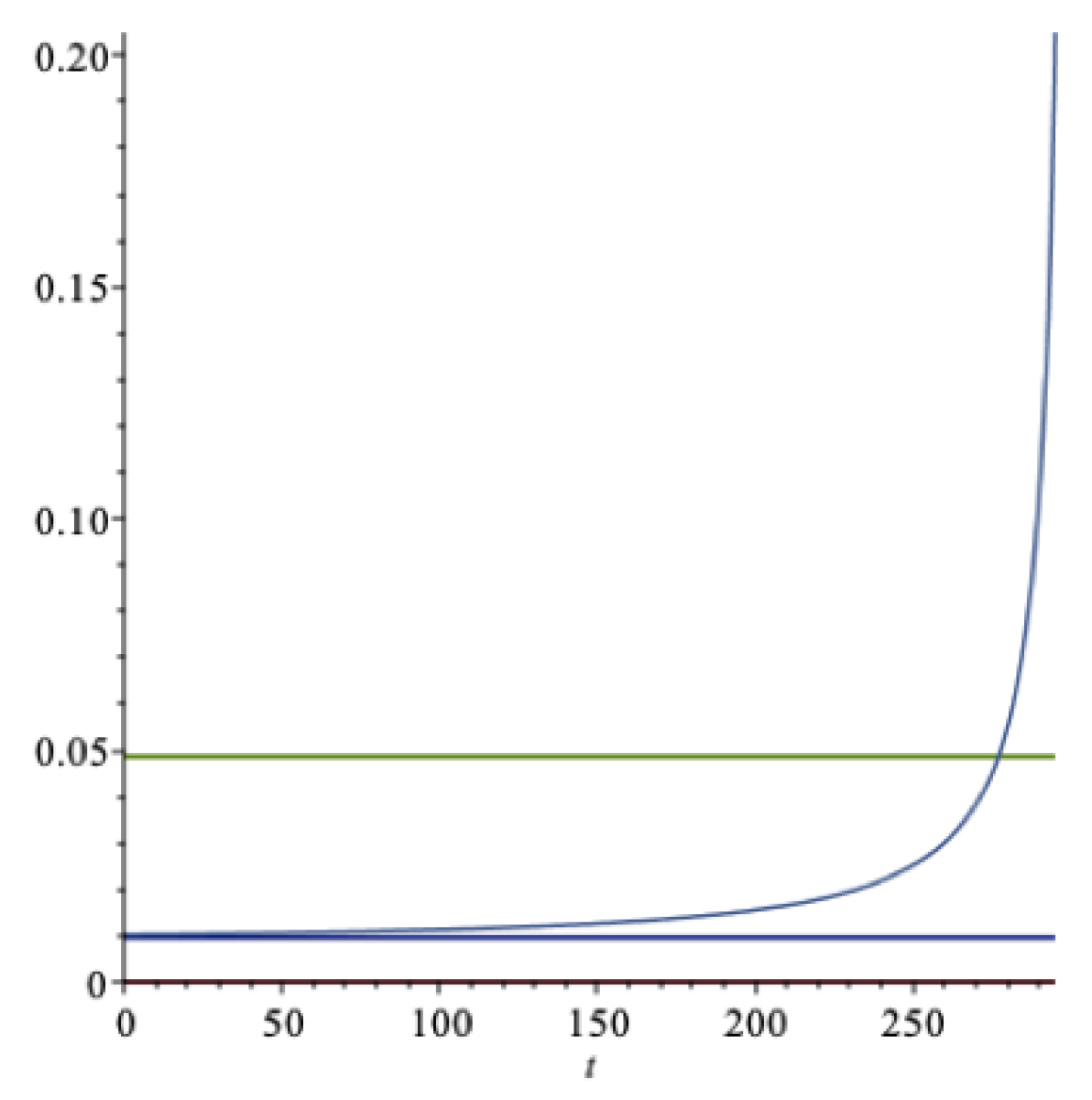
A few other scenarios will be discussed next. When and , then the optimal extraction rate is . Hence, the expected rate of return on the wealth portfolio is and the certainty equivalent rate of return is , corresponding to an optimal portfolio strategy of . Furthermore, , . Now the agent takes on more portfolio risk, since the risk aversion has decreased.
When and , then the optimal extraction rate is . Now the agent takes on about the same portfolio risk, but the extraction rate has increased because of increased impatience.
From the expression (
16) we notice that when
, the optimal extraction rate equals
, the impatience rate of the agent.
As a numerical example, when and , then . Thus, the expected rate of return on the wealth portfolio is and the certainty equivalent rate of return is , corresponding to an optimal portfolio strategy of . Furthermore, and .
In theory reported in textbooks, we often see examples where gamma is both (square root utility) and 1 (the Kelly Criterion), but it seems that such values are a bit too low in the present context, since they lead to positions that appear to be both risky, and sometimes rather odd.
Next we formulate our main findings related to the theme of the paper. Under our assumptions about the investment opportunity set , the following holds.
Proposition 2. When (i) the objective is to maximize utility and (ii) we consider a particular fund in isolation, the optimal spending rate will be significantly lower than the expected real rate of return on the fund, for any reasonable levels of the impatience rate and the relative risk aversion.
For an endowment fund with a well-defined owner, this analysis may be general enough to answer the question of optimal extraction from an endowment. The situation where consumption in society at large is considered as well is treated in the last section of the paper.
3.5. The Asymptotic Behavior of a Sovereign Wealth Fund
When the optimal spending rate
k is a constant, as in the above model, the wealth
is a geometric Brownian motion with dynamics
where
In other words, when the spending rate
k is equal to the expected rate of return, then
and
is a martingale. When
k is optimal, given in (
17), then either
is a submartingale or a supermartingale depending on the size of the impatience rate
. In general, when
, then
for all
t.
Note that the optimal portfolio rule
is the same in both lines in (
23). It can be shown that if
k is set to be equal to the expected real return, ex ante, and optimization is only in the variable
, the optimal portfolio rule remains the same as in the standard approach. This is most easily demonstrated by use of dynamic programming.
If , the process is a submartingale, in which case for all ; if , the process is a supermartingale, in which case for all . We have the former, , if , and the latter, , if .
Of some interest here is that we can also conclude about the asymptotic behavior of the wealth process from the sign of
. Since here
, by the law of the iterated logarithm for Brownian motion and Feller’s test for explosions, the following results hold (see, e.g.,
Karatzas and Shreve 1987;
Feller 1952,
1954):
Thus, when
—i.e., when spending equals the expected return, as advocated by, e.g.,
Campbell (
2012)—the martingale property gives that
for all
, but despite this, the wealth eventually converges to zero with probability 1, by the above result.
Moreover, using (
23) when
k is optimal and given in (
17), we see that (
24) is satisfied when
, and (
25) materializes when
. The right-hand side of this inequality is larger than or equal to the certainty equivalent rate of return when
. Thus, for example, when
is smaller than or equal to the certainty equivalent rate of return, then
converges to infinity as time
, provided
, and the wealth never hits zero with probability 1.
These results are is not so surprising as they may seem at first, since it is well known that neither convergence to , nor almost sure convergence, implies the other. When is not uniformly integrable, as here, this may typically be the case.
As we have argued above, it is reasonable that is smaller than, or at the most equal to, the certainty equivalent rate of return. It follows that the impatience rate will satisfy this requirement provided . Hence, the prospects for a long-term sustainable management of a sovereign wealth fund are promising using the optimal spending rate k as outlined above.
Finally, if
when
k is optimal, then
in which case
In this situation inf
, and sup
, a.s.
We summarize the most essential findings as follows
Theorem 1.
(i) With the optimal spending rate k, the fund value goes to infinity as as long as the impatience rate δ is smaller than or equal to the certainty equivalent rate of return on the fund, assuming .
(ii) If the spending rate is set equal to the expected rate of the return on the fund, then the fund value goes to 0 with probability 1 as time goes to infinity.
The transversality condition for the infinite horizon case turns out to be the following:
where
(see
Merton (
1971)). Notice that our condition in Theorem 1 (i) is that
for the optimal spending rate. Thus the transversality condition holds for our optimal spending rate
k. This means that the expected wealth grows at a slower rate than the impatience rate
as
.
We also have the following corollary:
Corollary 1. With the optimal spending rate k we have the following:
(i) almost surely as provided , in which case is also a submartingale.
(ii) almost surely as provided , in which case is also a supermartingale.
We can also say something about the expected time till the wealth process reaches a certain value; or more precisely, if the wealth process today satisfies , we can calculate the conditional expected time to the process W reaches a for the first time, say, given that a is reached before b. This is of course a topic of interest in the present model, and is what we consider next.
3.6. A Conditional First Exit Expectation Result
Consider a Feller process
on an interval
F in the real line, and let
, (see for example
Breiman (
1968)). Suppose
and let
, and
. Then the following result holds (
Aase (
1977)):
In the same paper we find the following application of this result to a geometric Brownian motion: For a diffusion where
, where
are two constants, and
. Let
, it follows that
A similar result holds for the boundary
a by use of
. Notice that here
.
Since we have a geometric Brownian motion process, where , these results are immediately applicable to our situation, which we explore below.
In the example related to
Figure 1 above, we calculate the conditional expected time to the fund leaves a given interval. Consider the interval
where
and
. In this scenario and with the
optimal spending rate, the parameters are
,
and the constant
. The first exit probabilities are
and
, so it is much more likely that the first exit takes place at the upper level
b than at the lower
a. We obtain that
years while
years.
In the situation where the spending rate is the expected rate of return, and while remains the same. The first exit probabilities have changed to and , so it is still more likely that the first exit takes place at the upper level b than at the lower level a, but much less likely than above. Here years and years. Yet we know that in this situation will eventually end up as zero, although it may take a long time, whereas in the former case with optimal extraction in place this does not ever happen with probability 1.
3.7. The Investment Opportunity Set Is Allowed to Be Stochastic
We now turn to the more general case with a stochastic investment opportunity set. As we now demonstrate, this can be made surprisingly simple. Starting with the optimal wealth given in Equation (
7), we condition on the vector stochastic process
and use the following iterated expectation result:
It is valid for
an adapted (vector) process satisfying standard conditions. This result follows since the stochastic integral
has an expectation of zero and variance
, and is conditional on the process
that the stochastic integral is normally distributed, so we can use the moment generating function for the normal distribution, which gives the last equality in the above.
Using this and the Fubini theorem, from Equation (
7) we obtain the following.
Let us define the integrand in exponent by
, that is,
where
as before. By Jensen’s inequality we then have
We now assume first-order
stationarity of the investment opportunity set. By Fubini’s theorem we then get
where
does not depend on
by our stationarity assumption. This gives that
where
It is still the case that the following convex representation holds:
However, we can no longer claim that the last term represents the certainty equivalent rate of return in the meaning of Proposition 1. The optimal portfolio weights
are not given by the simple formula (
13) with a stochastic investment opportunity set. It will contain an additional term that adjusts for the randomness in the market price of risk process
,
and the other quantities in
.
The comparison of interest is then between the optimal expected spending rate and the expected real rate of return on the wealth portfolio given by .
First we must find the relevant portfolio weights
when the investment opportunity set is stochastic. This problem has been discussed in great detail by, e.g.,
Karatzas and Shreve (
1998), but no explicit formula seems to exist. Here we choose another path and go back to Equation (
27) and write it as
where
When
we notice that
is deterministic, so no additional term arises. This corresponds to logarithmic utility, in which case the solution is known, and is quite generally given by the first term in (
32) below, where both
and
are allowed to be stochastic processes.
The function
is seen to be
-measurable by definition, and by Itô’s representation theorem there exists a process
with
such that
9
By the Clark–Ocone formula we know that
where
is the Malliavin derivative of
at
.
From the stochastic differential equation for the optimal wealth given in (
12) we then obtain by the product rule and diffusion invariance that
The expression for the optimal portfolio has two terms. The first is identical to the optimal portfolio for a constant investment opportunity set, except that here
and
are allowed to be stochastic. The second term adjusts for the time and state variations of the investment opportunities, referred to as the intertemporal hedging term, and is seen from (
31) and (
32) to be
forward-looking. The first term ignores these variations, is certainly not forward-looking and is called
myopic for that reason (see
Mossin (
1968)).
The random term
can be connected to the parameters of the problem via the Malliavin derivative of
. We have the following.
Therein we have used the “chain rule” and other rules of this calculus (see, e.g.,
Di Nunno et al. (
2008)). The Malliavin derivatives
and
can be further broken down by specifying the types of model for
r and
. For example, if the spot interest rate follows a diffusion process of the Ornstein–Uhlenbeck model, or Vasicek type of the form
where
and
are deterministic, and
, then
, for
a
d-vector of positive constants.
When the relative risk aversion
, we notice from (
33) and the subsequent discussion that the second term in (
32) typically is a vector of negative portfolio weights. This seems intuitive, since a risk-averse agent will invest less in the risky assets when confronted with a stochastic investment opportunity set. This term can be seen to hedge against the unanticipated changes in the variables in the investment opportunity set. The opposite conclusion follows if
, but as we have indicated before, this case is not very intuitive with expected utility because of the two different interpretations of the parameter.
With an infinite horizon, the extraction rate is smaller than the real rate of return when the inequality
holds, which is equivalent to
assuming that
is invertible. This inequality holds for all
t if and only if
We then have the following result:
Proposition 3. With a stochastic investment opportunity set, provided the inequality holds, the optimal extraction rate is strictly smaller than the real rate of return on the fund, unless the impatience rate δ is unreasonably large.
Proof. From the inequality (
35) we notice that the second and third terms on the right-hand side add up to something negative under the condition of the proposition. Thus, if
the inequality then holds, and the conclusion follows. □
How reasonable is the assumption of the proposition in practice? Unless the inequality holds, the investment policy more or less prescribes short-selling most of the risky assets in the portfolio, which is unheard of in real life portfolio choices of the type that we are studying here.
Further insights from the analysis involving a stochastic investment opportunity set can be gained from inspection of the expression in Equation (
33). For example, the optimal portfolios are seen to depend on the impatience rate
and the horizon
T, neither of which is present in the standard expression with a deterministic investment opportunity set.
In other words,
impatience has a direct impact on the optimal portfolio, and the dependence on
T has a potential to address the
horizon problem. There is, however, nothing in the model that indicates that the investments in the risky assets should decrease when
t approaches the horizon
T (see, e.g.,
Aase (
2017) for a treatment of this problem).
The application of the results of this section to the data in
Table 1 is by and large similar to the illustrations given in
Section 3.4, since the data, like the data in
Table 1, are based on estimates, assuming stationarity (or some kind of ergodicity), and are therefore estimates of the expected value
. However, the margin between the optimal extraction rate and the expected rate of return may have diminished, depending upon the stochastic structure of
and
.













{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}