1. Introduction
The Pearson correlation coefficient is a frequently used statistic in finance, most notably in the area of portfolio analysis, in which it facilitates understanding of the linear associations between various stock market returns. For example, among other applications, it is frequently used for calculating portfolio variance in the well-known mean-variance portfolio theory framework (
Cuthbertson and Nitzsche 2004, p. 121).
However, despite its popularity and ease of computation,
Kenett et al. (
2015) emphasize that the Pearson correlation coefficient is also characterized by an important limitation when used in the context of financial applications. A high correlation value for stock market returns does not necessarily imply a direct relationship between two stocks, but rather a common underlying influence by macroeconomic or psychological factors related to investors.
To properly understand the true direct correlation structure between stocks in such settings, it is important to first account for the common factors that influence stock movements and are most represented by the stock market index in the capital asset pricing model (CAPM) framework. The partial correlation coefficient enables such calculations by quantifying the correlation between two stock returns while conditioning for the effect of a third variable that influences both returns.
In this study, we propose a wavelet-based procedure for calculating the partial correlations between stocks using coefficients generated from maximal overlap discreet wavelet transforms (MODWT) of the stock market returns. Wavelets are classes of orthonormal basis functions (
Nason 2008) that enable the decomposition of time series into different frequency bands (time scales). This is a very useful property in finance (
In and Kim 2013) since it enables the examination of financial variables over different planning cycles. For example, take the case with investors who have different tolerances related to investment horizons (e.g., portfolio managers, brokers, traders, institutional investors). The need to estimate correlations between assets returns over different time scales was also noted by
Wątorek et al. (
2019), who proposed using the detrended cross-correlation coefficient (
Kwapień et al. 2015) for measuring the degree of cross-correlation between two time series over different time scales.
In the empirical applications of this study, the proposed method was used to estimate the partial correlations between the main S&P 500 sector indices in the US over different time scales while conditioning for movements in the returns of the general stock market index. The estimated partial correlation coefficients were subsequently used in a clustering procedure to better understand the similarities and differences between the different categories of stock market returns and therefore identify opportunities for portfolio diversification over different planning cycles.
Consequently, in the remaining sections the following research questions are addressed: (i) Can the partial correlation index be used to cluster stock market returns from different economic activity sectors and over different time scales? (ii) How do stock correlations between the different economic activity sectors vary over different time scales, once movements in the general stock market index have been accounted for? (iii) What are the implications for investors that differ in terms of their investment horizon orientation (short-term, medium-term, long-term)?
The rest of the article is organized as follows.
Section 2 reviews the relevant literature concerning the application of correlation, clustering, and wavelet methods in finance.
Section 3 introduces the data and the estimation procedure for the proposed wavelet-based partial correlation coefficient, which is subsequently used in the clustering applications of
Section 4.
Section 5 concludes and provides suggestions for further research.
2. Literature Review
The Pearson correlation coefficient is most commonly associated with two application areas in finance: portfolio diversification and financial contagion. In portfolio diversification applications, the principal consideration is the correct estimation of the correlation matrices between asset returns. However, in addition to the Pearson correlation coefficient, which is still frequently used in empirical studies (see, for example,
Geertsema and Lu 2020), several other correlation methods have been proposed in the literature, such as time-varying correlation (
Chiang et al. 2007), Fisher correlation (
Krishnan et al. 2009), partial correlation (
Kenett et al. 2015), dynamic conditional correlation (
Engle and Colacito 2006), detrended cross-correlation (
Wątorek et al. 2019), and partial distance correlation (
Creamer and Lee 2019).
Correlation coefficients have also been used in the financial contagion literature, where the principal aim is to measure cross-market linkages in financial markets following a shock to one or more countries. Two of the earlier studies in this field that used correlation coefficients include
King and Wadhwani (
1990) and
Lee and Kim (
1993). In a noteworthy study,
Forbes and Rigobon (
2002) showed that contagion tests based on the correlation coefficient are biased due to heteroskedasticity since cross-market correlations are conditional on market volatility. Under certain assumptions, the authors demonstrate the magnitude of this bias and explain the necessary adjustment to correct it.
More recently,
Alqaralleh and Canepa (
2021) proposed a wavelet-copula-GARCH procedure where changes in stock market correlations at higher frequencies are associated with contagion, and changes at lower frequencies are associated with normal interdependence. The authors found strong evidence of contagion between six major stock markets after the start of the COVID-19 pandemic, while before the pandemic the results support the long-run interdependence hypothesis.
Similarly, there is a considerable amount of literature concerning the application of cluster analysis methods in finance.
Bennett and Hugen (
2016) provide an informative introduction to the application of clustering methods for portfolio analysis with an emphasis on the k-means algorithm, which is also used in this study.
Tola et al. (
2008) used several clustering algorithms (such as the single and average linkage methods) to show that the reliability of portfolios in terms of the ratio between predicted and realized risk can be improved. In another interesting application,
Ahn et al. (
2009) used a correlation distance measure in the context of a minimum variance clustering algorithm to construct a set of basis assets that characterize an investor’s opportunity set and that are not susceptible to data-snooping biases.
Other notable applications of clustering methods in finance in recent years include the use of time-series hierarchical clustering for understating the correlation structure of an index and therefore building an optimal tracking portfolio (
Focardi and Fabozzi 2004); the application of techniques from network science and linkage algorithms to understand the clustering of exchange-rate time series (
Fenn et al. 2012); the incorporation of a distance measure based on variance ratio statistics in the complete-linkage algorithm for clustering international stock market returns (
Bastos and Caiado 2014); and the application of a Gaussian mixture model on the voting shares of mutual funds to identify distinctive groups (and philosophies) of corporate governance in the US (
Bubb and Catan 2021).
Due to their unique time scale decomposition properties, wavelets have been used in many economic and financial applications. Several studies concentrated on the estimation of the systematic risk and portfolio variance of assets across different time scales, such as the articles by
Gençay et al. (
2005),
Kim and In (
2010), and
Michis (
2014a,
2019). Another stream of research concentrated on the examination of macroeconomic relationships across different time scales, including money growth and inflation (
Rua 2012), wage inflation and unemployment (
Gallegati et al. 2011), productivity and unemployment (
Gallegati et al. 2016), the liquidity effect (
Michis 2015a), and the comovements exhibited by European economic sentiment indicators (
Michis 2021).
Rua and Nunes (
2009) analyzed international comovements between economic sector returns over different time scales. However, their analysis is based on simple correlations of monthly data in the frequency domain (wavelet coherency) that do not account for movements in the general stock market index, nor are any clustering applications involved. In contrast,
Kenett et al. (
2015) used partial correlation coefficients to estimate economic activity sector comovements in the US. Even though their authors use daily data, the analysis is not performed over different time scales, the economic activity sectors are not grouped into distinguishable clusters, and the long-run implications for investors are not considered.
Partial correlation coefficients and a cluster analysis were also used by
Jung and Chang (
2016), who analyzed data on the main stocks listed in the Korean stock exchange. Although interesting, their analysis is based on monthly data, the correlations are not evaluated over different time scales and there are no comparisons with the main US economic activity sectors. A time scale analysis of daily financial data was also suggested by
Nava et al. (
2018) using the empirical mode decomposition and Pearson’s correlation coefficient. However, no cluster analysis was involved, nor any considerations of the comovements between the main US economic activity sectors.
This study provides a synthesis of the research streams by incorporating a partial correlation coefficient distance measure in the k-means clustering algorithm to identify distinct groups of stock market returns by time scale. Time scale decomposition is achieved through the application of a wavelet transform to the actual stock market returns and is important for investors considering improvements in the diversification of their portfolios over different planning cycles, e.g., a long-term buy-and-hold passive strategy vs. a short-term active trading strategy.
3. Materials and Methods
3.1. Wavelet Transforms
In this section, we explain the estimation procedure for the wavelet-based partial correlation coefficient. First, we present the basic building blocks of wavelets, followed by the derivation of the MODWT coefficients, which are subsequently used for the estimation of the partial correlation coefficients between the different S&P 500 sector indices.
Wavelets constitute classes of orthonormal basis functions that enable simultaneous time-frequency decompositions of time series into different time scales. A two-dimensional family of wavelet functions can be generated by translating (a shift in the range) and dilating (an expansion in the range) the (real-valued) father and mother wavelets as follows:
Lower values of the index
capture the high frequency, oscillating features of a signal (high resolution), while higher values capture the low frequency (low resolution), smooth components (
In and Kim 2013, p. 11).
While the second condition implies movements of
away from zero, the first condition ensures that these movements cancel out (e.g., movements above zero are cancelled out by movements below zero), thus leading to the formation of small waves. In addition, the following admissibility condition enables the reconstruction of a function from its continuous wavelet transform, where
is the Fourier transform of the wavelet function:
A finite (
) wavelet series approximation of a dyadic length (
) time series
can be represented as follows:
with wavelet transform coefficients
and
or more compactly in terms of wavelet details (
) and smooths (
) as:
The scaling coefficients () corresponding to father wavelets capture the (low frequency) long-run trend in the series, while the detail coefficients () corresponding to mother wavelets capture the high frequency, oscillating characteristics of the series.
Consequently, the wavelet series approximation provides a decomposition of into time scale components (a multiresolution analysis). Adding progressively smaller time scale components () to the long-run trend () increases the finer detail characteristics of the signal until the original time series is reconstructed. For a weekly time series of length 512 (), the coefficients at time scale capture oscillations over cycles of 2–4 weeks. Accordingly, the coefficients at scales and capture oscillations over cycles of 4–8 and 8–16 weeks, respectively, and this is the case up to scale 9, which is associated with long-term cyclical variations in .
Two wavelet transforms frequently used for the analysis of time series with finite length are the discrete wavelet transform (DWT) and the MODWT. In this study, we will analyze stock market data using the MODWT, which is characterized by the following desirable properties (
In and Kim 2013, p. 25): it can be used with any sample size (not only dyadic length series), it is shift invariant (circularly shifting the series does not influence the multiresolution analysis), and its wavelet details and smooths are associated with zero-phase filtering (e.g., extreme values in the actual data can be aligned with corresponding values in the multiresolution analysis).
There are two additional characteristics of the MODWT that are particularly relevant for estimating partial correlation coefficients: (i) it provides an asymptotically more efficient variance estimator than the DWT, and (ii) by considering all integer translations of the series at each frequency resolution, it generates coefficient vectors that have the same length as the original time series, which facilitates computations. In applied work, the MODWT is computed using a pyramid algorithm with discrete high-pass and () low-pass filters ().
The first level of the algorithm filters the actual data with the rescaled filters
and
:
The second level proceeds by applying the same filtering procedure to the vector of scaling coefficients produced in level 1 (), which gives rise to the second level of wavelet () and scaling coefficient vectors (). Level 3 proceeds in the same way by applying the filtering procedure on the scaling vector . The same filtering procedure is repeated for levels, each time using as input the scaling vector of the previous level, which gives rise to the matrix of wavelet coefficient vectors that will be used for the calculation of the wavelet-based partial correlation coefficients in the next section.
3.2. Wavelet Based Partial Correlation Coefficients
To estimate the partial correlation coefficient between two time series
and
while conditioning on a third time series
, it is necessary to first estimate the variances and covariances associated with the three variables. An unbiased estimator of the wavelet variance for
at time scale
, using the MODWT coefficients, is given by:
where
and
refer to the length of the wavelet filter and the number of coefficients unaffected by the boundary, respectively (
Gençay et al. 2002, p. 241). Accordingly, the wavelet covariance between time series
and
can be expressed as:
It is then straightforward to obtain an expression for the wavelet correlation at scale
through normalization of the wavelet covariance with the individual variances:
The wavelet correlation coefficient bares the well-known property:
.
In and Kim (
2013, pp. 33–34) provided formulas for the computation of confidence intervals for both the wavelet covariance and wavelet correlation estimators presented above.
When working with stock market returns, a high correlation value is not always indicative of a direct association between two stocks.
Kenett et al. (
2015) emphasize that movements in both stocks can be associated with movements in a third variable that influences both stocks, as is, for example, the case with the general stock market index. In this case, it is necessary to use the partial correlation coefficient, which calculates the correlation between two variables (
and
), while controlling for the effect of a third variable (
).
In line with the partial correlation formula for continuous observations (
Chen and Popovich 2002, p. 73), the wavelet partial correlation coefficient can be calculated as follows, where
:
3.3. Data: S&P 500 Sectors
The wavelet partial correlation coefficient in Equation (1) was used to estimate the partial correlation matrices between the following S&P 500 sector returns on a scale-by-scale basis: telecom services (SPLRCL), consumer discretionary (SPLRCD), consumer staples (SPLRCS), energy (SPNY), financials (SPSY), health care (SPXHC), industrials (SPLRCI), information technology (SPLRCT), materials (SPLRCM), real estate (SPLRCREC), and utilities (SPLRCU).
The analysis was also augmented with the following precious metals and energy futures returns that likely exhibit distinct market movement characteristics and are therefore useful for portfolio diversification purposes: gold, silver, cooper, Brent oil, and natural gas. For all indices, the data were downloaded from the financial platform
www.investing.com (accessed on 9 September 2021) and concern weekly closing values for the period 1 August 2010–18 July 2021, in the US.
Table 1 includes summary statistics for all the indices, and
Figure 1 illustrates the time development of four indices that are representative of the cyclical variations inherent in the data.
For example, the information technology index exhibits a rising exponential trend, while the energy sector index has a slightly declining trend after 2014, a further drop in 2020, and a small rebound in 2021. In contrast, consumer staples are mostly associated with a slightly increasing trend and a small increase in volatility after 2018. Furthermore, even though all indices exhibit short-term fluctuations around their long-term trends, it can be observed that the gold futures index also exhibits several medium-term cycles, most notably during the periods August 2010–May 2013, December 2015–December 2016, and January 2020-February 2021.
Wavelets are particularly well suited for decomposing the cyclical characteristics of nonstationary time series (
Nason 2008, p. 60), such as those frequently encountered in stock market data. They are also very effective in handling time series with extreme values, such as spikes and shifts in trends (
Michis 2015b), which, in the case of
Figure 1, are most evident in the gold futures and energy sector values of 2 August 2020 and 15 March 2020, respectively.
For all pairs of stock and futures returns, the wavelet coefficients necessary for estimating the partial correlation coefficient in Equation (1) were generated using the MODWT with a Daubechies least asymmetric wavelet filter of length 8. This is a frequently used filter for financial time series (see, for example,
Michis 2014a and
Kim and In 2010), which also provided good resolutions of the financial returns analyzed in this study.
The partial correlation matrices for time scales 3, 6, and 8 are presented in
Appendix A. We concentrate on the results for these three time scales mainly because they are characteristic of the investment horizons typically encountered in financial markets (short-term, medium-term and long-term), and they are also representative of the correlation matrices estimated for the remaining time scales in the analysis. In several cases, the partial correlations between two financial returns are negative or close to zero, which is consistent with the findings of
Kenett et al. (
2015).
As is common for correlation estimates (
Obilor and Amadi 2018),
Appendix B includes
p-values for the estimated partial correlation coefficients of time scales 3, 6 and 8 that were generated using the testing procedure proposed by
Kim (
2015) based on the Student’s t distribution. Only 14% of the estimated coefficients were not found to be statistically significant at the 90% confidence level.
Jung and Chang (
2016) note that due to conditioning on general market index returns, partial correlation coefficients tend to be smaller than Pearson correlation coefficients of the same stock returns. In addition, not accounting for common factors that have an influence on stock returns can result in biased Pearson correlation estimates, which are not useful for investors seeking to diversify risk away from their portfolios. Furthermore, when the common factor in partial correlation estimates is chosen to be the general market index, the partial correlation coefficient resembles the CAPM.
4. Results: Clustering of Stock Market Returns
Jung and Chang (
2016) were among the first to propose the use of partial correlation coefficients for clustering stock returns using an agglomerative hierarchical clustering procedure. In this section, we extend these clustering applications by proposing the use of a wavelet-based partial correlation dissimilarity measure in the context of the k-means clustering algorithm to identify groups of stocks that exhibit distinct market movement characteristics.
In addition to being useful for portfolio diversification purposes (
Cuthbertson and Nitzsche 2004), such an analysis enables the exploration of differences between stocks on a time scale basis, such as variations over short-term, medium-term, and long-term cycles, and it is therefore particularly well suited for investors that differ in terms of their investment horizon orientations.
Can the partial correlation coefficient be used to cluster stock market returns from different economic activity sectors and over different time scales?
For the clustering applications of this section, we will use the following partial correlation dissimilarity measure between stocks
and
, which is based on the wavelet partial correlation coefficient formula presented in
Section 3:
This measure resembles the Pearson correlation dissimilarity measure that is frequently used for clustering continuous data observations (
Everitt et al. 2011, p. 50). However, it differs in two important aspects: (i) it is based on the partial correlation coefficient that measures the association between two stocks (
and
), while controlling for the effect of a third variable (the stock market index), and (ii) it can be calculated and used in clustering applications separately for each time scale.
Consequently, using the dissimilarity measure
, the k-means clustering algorithm can be applied separately for each time scale. To see this, first consider a
-dimensional dataset consisting of the level
wavelet coefficient vectors generated from the returns series of
separate stocks, as described in
Section 3.1. If there are
separate clusters inherent in the data, total dispersion is provided by the following matrix:
where
refers to the
th item in cluster
and
is the overall mean. Total dispersion can then be decomposed into within-cluster dispersion
and between-cluster dispersion
,
where
,
and
is the cluster
mean value.
The k-means algorithm used in this study proceeds to group items in a way that minimizes
and therefore most of the variation in the data are accounted for by between cluster variation
. Consequently, it attempts to minimize the following objective function:
where
is the cluster membership indicator (
when item
is assigned to cluster
) and
is the distance between item
and cluster
at time scale
. The classic k-means algorithm is based on Euclidean distances as used in the total dispersion decomposition above. However, when working with time series data, the Pearson correlation distance
is frequently preferred.
Berthold and Höppner (
2016) showed that for normalized series with zero mean and unit variance, the Euclidean distance is equal to
times the correlation distance:
.
In the empirical applications of this study, we will minimize the objective function (3) using the partial correlation dissimilarity measure presented in Equation (2), which is more suitable for analyzing stock returns. The k-means algorithm in this case proceeds in four steps:
Define an initial partition of the data into groups (randomly or using, e.g., a hierarchical method with a dendrogram).
For this initial partition, compute the score of .
Then, reallocate each item separately into other groups until a partition is found that reduces the criterion the most.
Repeat the procedure from step 2 until the score of cannot be reduced further.
Even though this procedure is successful at finding a local minimum, several repetitions with different initial partitions can lead to solutions that are equal or close to the global minimum (
Cox 2005, p. 93).
In applied work, a frequently used method for choosing the number of clusters suitable for partitioning a dataset first proceeds by calculating and plotting the within-group sum of squares generated by each separate k-means group solution. Increasing the number of clusters leads to a reduction in the sum of squares. Therefore, a noticeable “elbow” in the sum of squares plot provides an indication for the most suitable number of clusters to form (
Everitt and Hothorn 2011, p.180). Using the partial correlation matrices of time scales 3, 6, and 8 in
Appendix A,
Figure 2 plots the within-group sum of squares for seven different cluster numbers, generated using the dissimilarity measure (2) in the context of the k-means algorithm. The results suggest the following partitions: five clusters for time scale 3, four clusters for time scale 6, and three clusters for time scale 8.
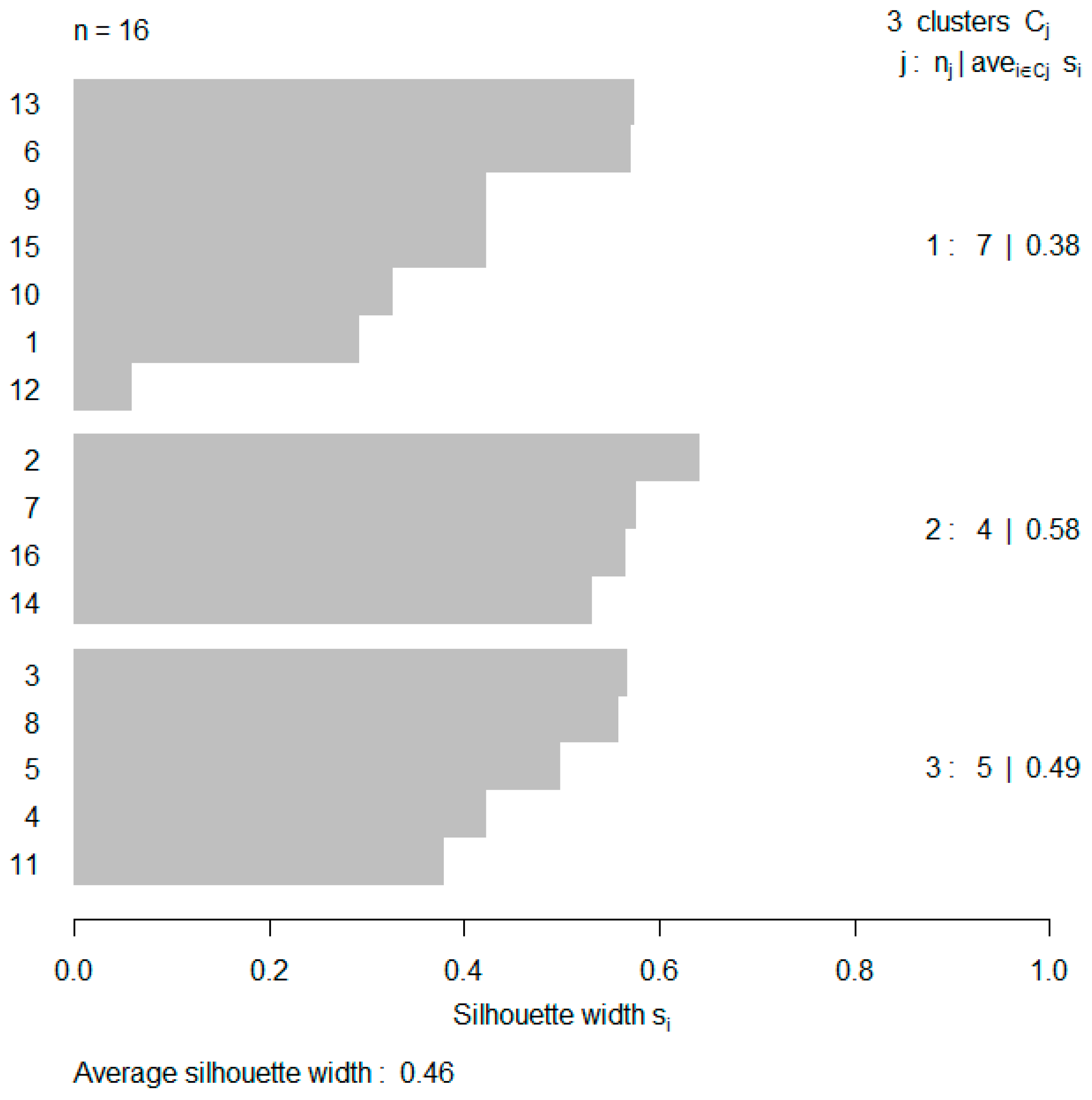
To evaluate the consistency of the resulting cluster formations for time scales 3, 6, and 8, we performed a silhouette analysis, which is a frequently used method for validating cluster formations. For each object, an index is defined that compares the object’s separation from its cluster against the heterogeneity of the cluster (
Everitt et al. 2011). Consequently, it provides an indication of how similar an observation is with the cluster to which it has been assigned relative to other clusters.
Values of the index close to 1 suggest that the object is well classified since the cluster’s heterogeneity is smaller than its separation, while values close to −1 suggest misclassification. Borderline cases where the object is not clearly assigned between two neighbouring clusters are indicated with values close to zero.
In silhouette plots, the values of the index for each cluster are displayed with horizontal bars, as shown in
Figure 3 for the three clusters of time scale 8.
Kaufman and Rousseeuw (
1990), who first proposed the silhouette method, consider silhouette width values higher than 0.5 to be indicative of a good cluster formation, as is the case with the results of time scale 8. However, more useful in applied work is the average silhouette width curve for different cluster sizes, since it enables identification of the optimal group sizes that maximize silhouette width.
Appendix C depicts the silhouette width curves for the clustering solutions of time scales 3, 6, and 8. In each case, the cluster formations were generated using a random starting point of two clusters, followed by a 100 iteration convergence limit. The maximum point of the average silhouette width curve for timescale 3 suggests that the optimal cluster size in this case is five. For time scales 6 and 8, the respective optimal cluster sizes are four and three respectively.
How do stock correlations between the different economic activity sectors vary over different time scales once movements in the general stock market index have been accounted for?
The results of the k-means clustering procedure using the abovementioned cluster partitions are presented in
Figure 4,
Figure 5 and
Figure 6. All data were analyzed using the wavelsim, cluster, factoextra, ppcor, and ggplot2 packages for R available from the CRAN archive. The horizontal and vertical axes correspond to the first two principal components that account for most of the variability in the partial correlation distance matrix, as represented by the respective percentage values. This dimension reduction method is commonly used in applied work for graphically illustrating clustering results in the space of the first two principal components (
Everitt and Hothorn 2011). For the purposes of this study, we used the visualisation procedure suggested by
Kassambara and Mundt (
2020).
It can also be observed that the precious metal (gold, silver, and copper) futures returns are always grouped together, while some indices are always grouped separately from precious metals, e.g., “Consumer discretionary” and “Consumer staples”. In contrast, the returns associated with the energy futures (Brent oil and natural gas) are grouped together only when considering movements over long-term cycles (time scale 8). The “Energy” and “Financial” indices are grouped together when considering medium-term (time scale 6) and long-term cycles, and the “Real estate” and “Utilities” indices are grouped separately only when considering long-term cycles.
Furthermore, the abovementioned cluster analysis results provide some interesting insights. First, the number of cluster formations necessary for grouping the indices is reduced as one moves progressively to higher time scales that represent longer duration cycles in the data. Consequently, in the long term, the cluster formations are larger, consist of more homogeneous stock returns, and are also more distinct, as represented by the distances between them in the configuration for time scale 8 in
Figure 6. In such environments, frequent trading and portfolio changes become less important.
What are the implications for investors that differ in terms of their investment horizon orientation (short-term, medium-term, long-term)?
Second, cluster participation varies by time scale. For example, “Information technology” and “Materials” belong to Cluster 1 at time scale 8, but to different clusters at time scales 3 and 6. In this case, a different portfolio selection strategy is required for investors adopting a short-term investment horizon strategy (since the two sectors can add diversification benefits in the short term, as shown by their negative partial correlation coefficient) compared to investors adopting a long-term investment horizon strategy.
Third, the partial correlation indices and the degree of homogeneity between the sector indices in each cluster also vary by time scale. This finding suggests that the traditional approach to determining the similarity of stocks based on their official industrial classification and irrespective of the investment horizon under consideration might not be the most appropriate way to consider adjustments in investment portfolios. Our results suggest that the similarities between sector indices differ by time scale. Therefore, a data-driven approach to identifying distinct market movements between sector indices (and stocks) on a scale-by scale basis could be more beneficial for diversifying risk away from a portfolio.
Wavelets can also be used for analyzing shorter time scales, using daily observations and concentrating on smaller periods of increased volatility in financial markets, as is the case with the recent COVID-19 pandemic. Consequently, for all the indices considered in our study, we collected daily observations (closing values) for the period 1 May 2019–8 July 2021 and performed the cluster analysis described in
Section 4.
Appendix D includes figures of the resulting cluster formations for time scales 3, 4, and 5 that cover cyclical movements of length 8–16, 16–32, and 32–64 days respectively.
The results for time scale 3 suggest that the precious metal (gold, silver, and cooper) and energy futures (oil and gas) returns form two distinct clusters, which are also closely located to each other. In the case of energy futures, a possible explanation concerns the unique market movements of energy fuels during the COVID-19 pandemic where an initial drop in prices was followed by sharp increases due to limitations on production and increased demand (
Camp et al. 2020). Precious metals on the other hand are usually considered as safe haven assets that many investors prefer during times of financial distress (
Michis 2019). In a recent study,
Sifat et al. (
2021) found evidence that speculations in the energy and precious metals futures markets have in fact increased during the COVID-19 pandemic, which could also be related with the distinct behavior of these indices in the cluster analysis results for time scale 3.
This conclusion (speculative behavior confined to the short-term cycles of time scale 3) is further supported by the clustering results for time scales 4 and 5 in
Appendix D that concern longer cycles. It can be observed that the precious metal and energy futures returns become less distinct and progressively move closer to some other sectors when evaluated over these longer time scales. In addition, the cluster formations in these time scales are more similar to the clustering results of
Figure 4 that were generated using weekly data. For example, the “Real estate”, “Consumer staples”, “Health care”, and “Utilities” sectors are grouped together in these time scales, as is the case for the “Materials”, “Industrials”, “Energy”, and “Financials” sectors. The same is also true for the “Information technology” and “Consumer discretionary” sectors.
It is also worth mentioning that, in the daily results for time scale 5, the “Gas futures” and “Telecom services” indices are grouped together, as is the case with the weekly data results for time scale 3 in
Figure 4. This unique behavior of the “Telecom services” sector may be explained by the high increase in demand for these services after the beginning of the COVID-19 pandemic, which is also reflected in the general trend of the index in
Figure 7. However, it is important to emphasize at this stage that a more in-depth analysis of the sectors that exhibit distinct market behavior during periods of increased volatility should be combined with an analysis of individual stock returns, since heterogeneity could exist within the aggregated sector movements. The analysis by
Jung and Chang (
2016) provides several useful suggestions in this direction.
5. Conclusions
This study proposed a data-driven procedure for analyzing associations between stock market returns using a wavelet-based estimator of the partial correlation coefficient. A key feature of this coefficient is the ability to estimate the associations between stock market returns over different time scales (short-term, medium-term, long-term), while conditioning for the general stock market movements that tend to inflate the Pearson correlation estimates.
The estimated partial correlation coefficients can also be used for constructing a dissimilarity measure between stock returns, which, when incorporated in the k-means clustering algorithm, generates separate cluster formations by time scale. This is an important distinction for investors differing in terms of their investment horizon orientations.
The results of an empirical study using all the major S&P 500 sector indices in the US, as well as precious metals and energy sector futures returns during the last decade, suggest that cluster formations (number of clusters, synthesis, and degree of homogeneity) do vary by time scale, which entails different implications for investors wishing to diversify risk away from their portfolios but differ in terms of their investment horizon orientation.
Similarly to
Kenett et al. (
2015), our findings also suggest that stocks can be correlated outside their primary sector classification and the correlation levels vary by time scale. These findings have implications for the stock selection strategies of investors relying on sectoral diversification in their efforts to diversify risk away from their portfolios. The degree of comovement between the different economic activity sectors is higher when considering long-term cycles. Therefore, diversification is less important in the long-run, a finding also reported by
Rua and Nunes (
2009). In contrast, more clusters were found to exist over short-term cycles, suggesting the existence of sectors with distinct market movements and therefore more opportunities for diversification.
Furthermore, accounting for movements in the general stock market index changes the correlation levels between the different economic activity sectors, which suggests that relying on simple Pearson correlation estimates might not be adequate for constructing well-diversified portfolios. Our proposed method can therefore be used as a supplementary tool that can reveal previously unobserved correlations between stocks, not dominated by movements in the general stock market index.
Our research can be extended in several directions that can improve some of the limitations associated with our proposed method. First, it would be useful to consider the incorporation of alternative wavelet-based dissimilarity measures in the clustering algorithm that can potentially improve the within-cluster dispersions when working with stock market returns. Moreover, the areas of application can be extended to include additional asset classes such as fixed-income securities. Second, it is worth considering the use of alternative wavelet transforms for calculating the partial correlations between stock market returns, such as the discreet wavelet transform and the maximal overlap discreet wavelet packet transform (
Percival and Walden 2000). Similarly, using alternative wavelet families can potentially improve the resolutions of stock market returns at higher frequencies. These are fruitful areas for further research, particularly with the aid of simulation studies that can evaluate the performance of the different methods with varying sample sizes.
Third, financial markets constitute complex environments influenced by the activities of multiple agents interacting over different cycles. In such environments, it is highly likely that correlations between stock market returns are influenced by many common factors and not just the general stock market index. Developing alternative methods for clustering stock returns over different time scales, while conditioning for multiple common factors in the analysis, is an interesting area for further research.
Finally, the partial correlation coefficient between stock returns, much like the Pearson correlation coefficient, is not static and could change periodically, particularly during times of extreme market volatility. Therefore, it is important to update the estimated coefficients frequently and in line with changes in the market conditions, especially when working with individual stock returns, which are more directly influenced by changes in the individual strategies of companies.















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}