
The Worst Case GARCH-Copula CVaR Approach for Portfolio Optimisation: Evidence from Financial Markets


Abstract
:1. Introduction
2. Research Methods
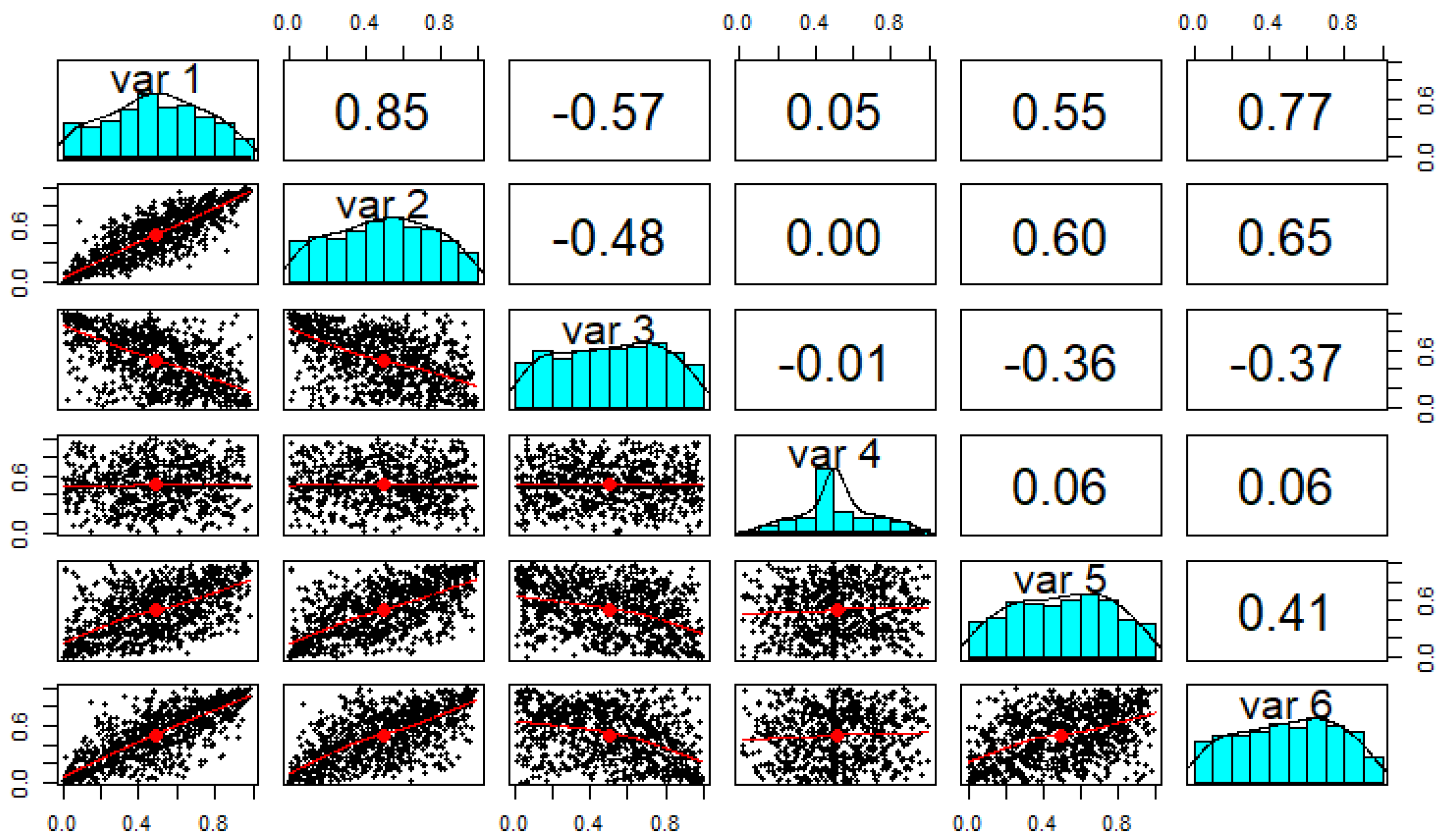
2.1. Copulas
2.1.1. Kendall’s Coefficient
2.1.2. Student’s t-Copula
2.1.3. Copula Inference with the Maximum Likelihood Method
2.1.4. Inference Functions for Margins (IFM)
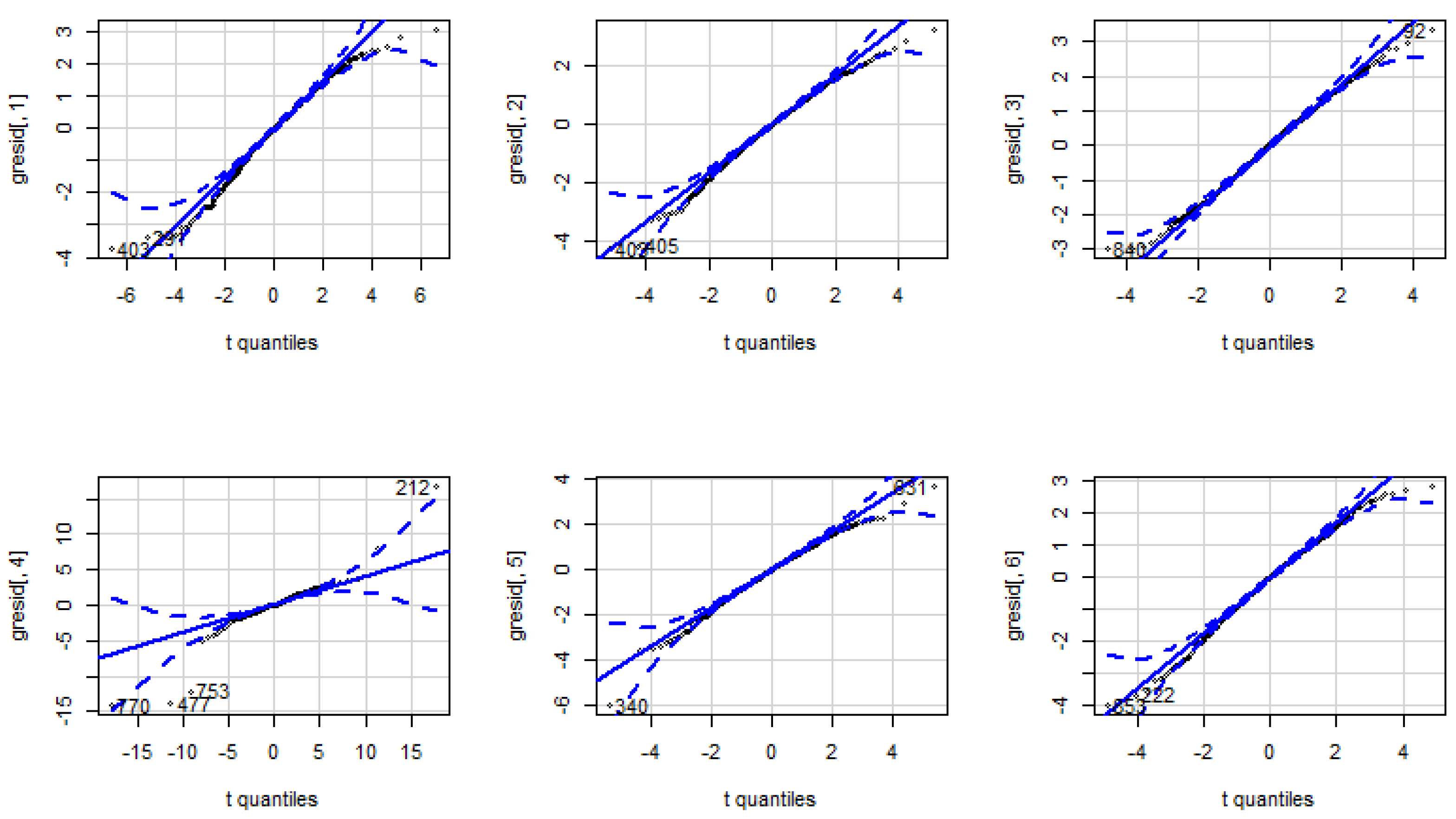
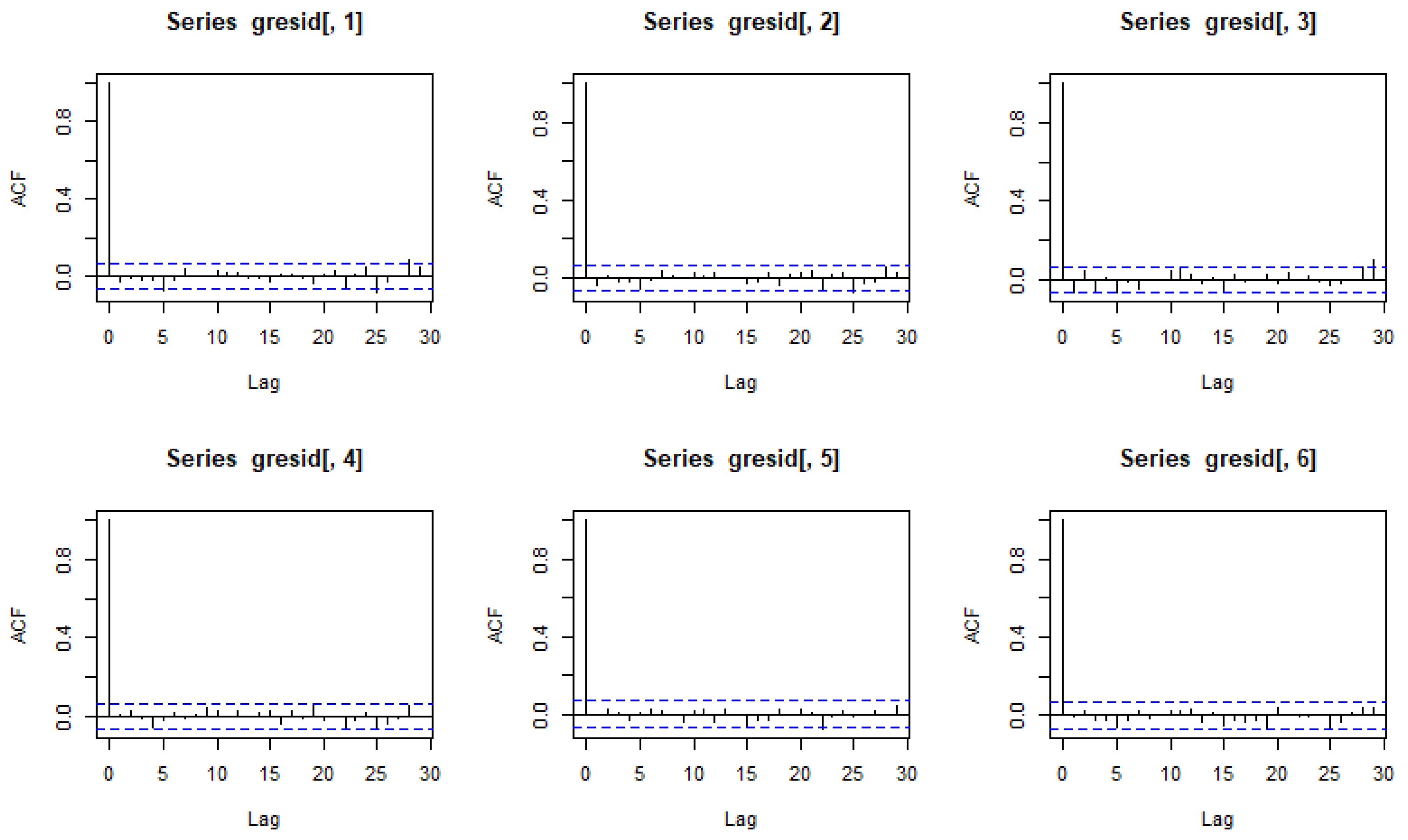
2.2. The GARCH Model
The GARCH (1,1) Case
2.3. The Copula-GARCH Model
2.4. The Worst Case Conditional Value at Risk
2.5. Worst Case GARCH-Copula CVaR Portfolio Optimisation
3. Application of the Worst Case GARCH-Copula CVaR to Financial Datasets
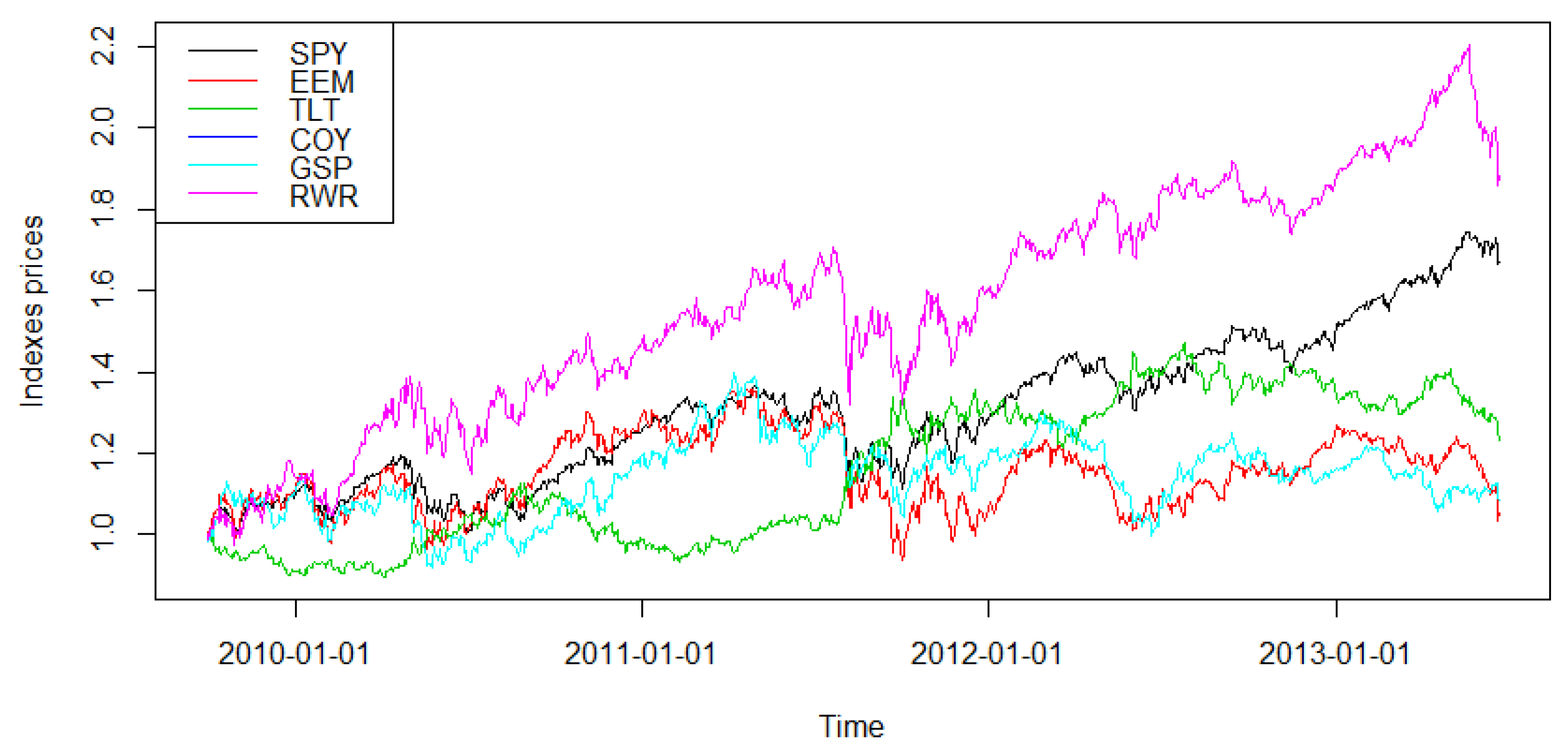
3.1. The Financial Market Indexes Dataset
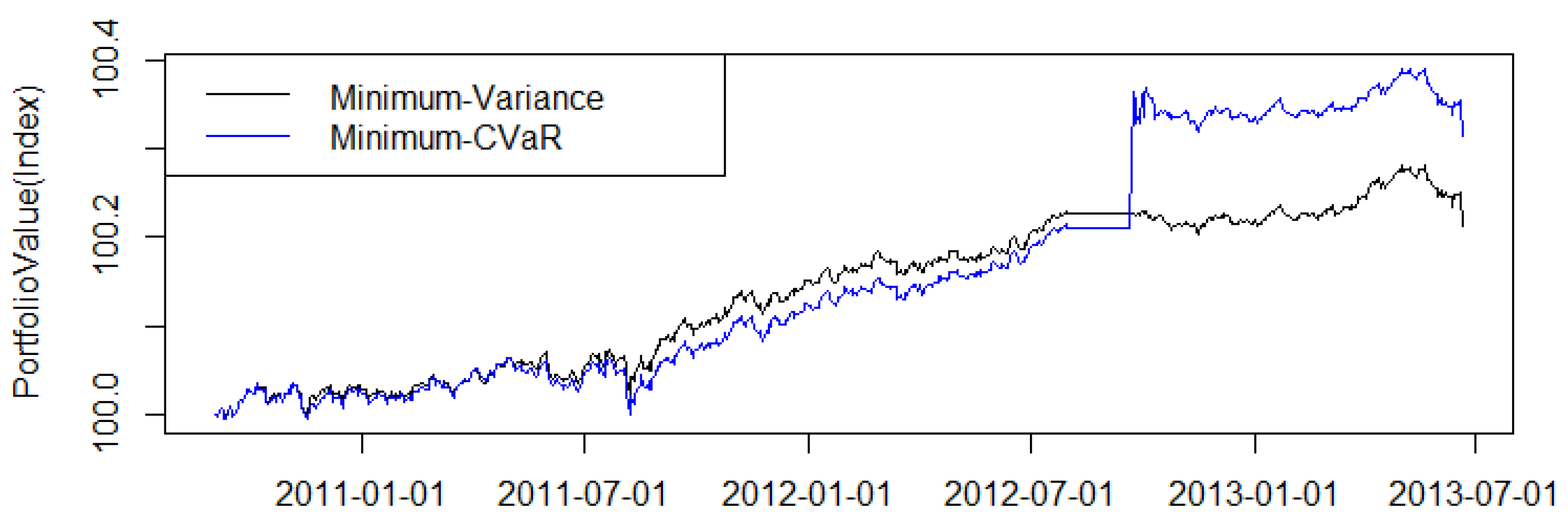
3.2. The Gulf Cooperation Council (GCC) Dataset
4. Conclusions and Future Work
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Alexander, Carol. 2001. Market Models: A Guide to Financial Data Analysis. New York: John Wiley. [Google Scholar]
- Alin, Aylin. 2010. Multicollinearity. Wiley Interdisciplinary Reviews: Computational Statistics 2: 370–74. [Google Scholar] [CrossRef]
- Aloui, Chaker, and Besma Hkiri. 2014. Co-movements of GCC emerging stock markets: New evidence from wavelet coherence analysis. Economic Modelling 36: 421–31. [Google Scholar] [CrossRef]
- Basu, Susanto. 1996. Procyclical productivity: Increasing returns or cyclical utilization? The Quarterly Journal of Economics 111: 719–51. [Google Scholar] [CrossRef] [Green Version]
- Ben Mabrouk, Anouar. 2020. Wavelet-based systematic risk estimation: Application on GCC stock markets: The Saudi Arabia case. Quantitative Finance and Economics 4: 542–95. [Google Scholar]
- Bertsimas, Dimitris, Geoffrey J. Lauprete, and Alexander Samarov. 2004. Shortfall as a risk measure: Properties, optimization and applications. Journal of Economic Dynamics and Control 28: 1353–81. [Google Scholar] [CrossRef]
- Bollerslev, Tim. 1986. Generalized autoregressive conditional heteroskedasticity. Journal of Econometrics 31: 307–27. [Google Scholar] [CrossRef] [Green Version]
- Bouyé, Eric, Valdo Durrleman, Ashkan Nikeghbali, Gaël Riboulet, and Thierry Roncalli. 2000. Copulas for Finance—A Reading Guide and Some Applications. Available online: https://ssrn.com/abstract=1032533 (accessed on 1 October 2021).
- Chan, Joshua C. C., and Dirk P. Kroese. 2010. Efficient estimation of large portfolio loss probabilities in t-copula models. European Journal of Operational Research 205: 361–67. [Google Scholar] [CrossRef] [Green Version]
- Cherubini, Umberto, and Elisa Luciano. 2001. Value-at-risk trade-off and capital allocation with copulas. Economic Notes 30: 235–56. [Google Scholar] [CrossRef]
- Cherubini, Umberto, Elisa Luciano, and Walter Vecchiato. 2004. Copula Methods in Finance. Hoboken: John Wiley & Sons. [Google Scholar]
- Chukwudum, Queensley. 2018. Extreme Value Theory and Copulas: Reinsurance in the Presence of Dependent Risks. Available online: https://hal.archives-ouvertes.fr/hal-01855971/file/EVT%20copulas%20and%20reinsurance.pdf (accessed on 1 September 2021).
- Coussement, Kristof, Dries F. Benoit, and Dirk Van den Poel. 2010. Improved marketing decision making in a customer churn prediction context using generalized additive models. Expert Systems with Applications 37: 2132–43. [Google Scholar] [CrossRef]
- Dalla Valle, Luciana, and Paolo Giudici. 2008. A bayesian approach to estimate the marginal loss distributions in operational risk management. Computational Statistics & Data Analysis 52: 3107–27. [Google Scholar]
- Dalla Valle, Luciana, Maria Elena De Giuli, Claudia Tarantola, and Claudio Manelli. 2016. Default probability estimation via pair copula constructions. European Journal of Operational Research 249: 298–311. [Google Scholar] [CrossRef] [Green Version]
- Dalla Valle, Luciana. 2009. Bayesian copulae distributions, with application to operational risk management. Methodology and Computing in Applied Probability 11: 95–115. [Google Scholar] [CrossRef]
- Dalla Valle, Luciana. 2017a. Copula and vine modeling for finance. In Wiley StatsRef: Statistics Reference Online. Hoboken: John Wiley & Sons, Ltd. [Google Scholar]
- Dalla Valle, Luciana. 2017b. Copulas and vines. In Wiley StatsRef: Statistics Reference Online. Hoboken: John Wiley & Sons, Ltd. [Google Scholar]
- Daníelsson, Jón. 2011. Financial Risk Forecasting: The Theory and Practice of Forecasting Market Risk with Implementation in R and Matlab. Hoboken: John Wiley & Sons. [Google Scholar]
- Demarta, Stefano, and Alexander J. McNeil. 2005. The t copula and related copulas. International Statistical Review 73: 111–29. [Google Scholar] [CrossRef]
- Di Clemente, Annalisa, and Claudio Romano. 2021. Calibrating and simulating copula functions in financial applications. Frontiers in Applied Mathematics and Statistics 7: 642210. [Google Scholar] [CrossRef]
- Embrechts, Paul, Rudiger Frey, and Alexander McNeil. 2005. Quantitative risk management. Princeton Series in Finance 10: 116–237. [Google Scholar]
- Engle, Robert F. 1982. Autoregressive conditional heteroscedasticity with estimates of the variance of United Kingdom inflation. Econometrica: Journal of the Econometric Society 50: 987–1007. [Google Scholar] [CrossRef]
- Fantazzini, Dean, Luciana Dalla Valle, and Paolo Giudici. 2008. Copulae and operational risks. International Journal of Risk Assessment and Management 9: 238–57. [Google Scholar] [CrossRef] [Green Version]
- Fortin, Ines, and Christoph Kuzmics. 2002. Tail-dependence in stock-return pairs. Intelligent Systems in Accounting, Finance & Management 11: 89–107. [Google Scholar]
- Ghahtarani, Alireza. 2021. A new portfolio selection problem in bubble condition under uncertainty: Application of z-number theory and fuzzy neural network. Expert Systems with Applications 177: 114944. [Google Scholar] [CrossRef]
- Graham, David I., and Matthew J. Craven. 2021. An exact algorithm for small-cardinality constrained portfolio optimisation. Journal of the Operational Research Society 72: 1415–31. [Google Scholar] [CrossRef]
- Hastie, Trevor, and Robert Tibshirani. 1990. Generalized Additive Models, Volume 43 of Monographs on Statistics and Applied Probability. Washington, DC: Chapman & Hall, CRC Press. [Google Scholar]
- Hoe, Lam Weng, Jaaman Saiful Hafizah, and Isa Zaidi. 2010. An empirical comparison of different risk measures in portfolio optimization. Business and Economic Horizons 1: 39–45. [Google Scholar]
- Hu, Ling. 2006. Dependence patterns across financial markets: A mixed copula approach. Applied Financial Economics 16: 717–29. [Google Scholar] [CrossRef]
- Huang, Jen-Jsung, Kuo-Jung Lee, Hueimei Liang, and Wei-Fu Lin. 2009. Estimating value at risk of portfolio by conditional copula-GARCH method. Insurance: Mathematics and Economics 45: 315–24. [Google Scholar] [CrossRef]
- Jin, Yan, Rong Qu, and Jason Atkin. 2016. Constrained portfolio optimisation: The state-of-the-art markowitz models. In Proceedings of the 5th International Conference on Operations Research and Enterprise Systems—Volume 1: ICORES, Rome, Italy, February 23–25. Cham: Springer, pp. 388–95. [Google Scholar]
- Joe, Harry, and James Jianmeng Xu. 1996. The Estimation Method of Inference Functions for Margins for Multivariate Models. Available online: https://open.library.ubc.ca/soa/cIRcle/collections/facultyresearchandpublications/52383/items/1.0225985 (accessed on 1 May 2021).
- Joe, Harry. 1997. Multivariate Models and Multivariate Dependence Concepts. Washington, DC: CRC Press. [Google Scholar]
- Jondeau, Eric, and Michael Rockinger. 2006. The copula-GARCH model of conditional dependencies: An international stock market application. Journal of International Money and Finance 25: 827–53. [Google Scholar] [CrossRef] [Green Version]
- Kakouris, Iakovos, and Berç Rustem. 2014. Robust portfolio optimization with copulas. European Journal of Operational Research 235: 28–37. [Google Scholar] [CrossRef]
- Konno, Hiroshi, and Hiroaki Yamazaki. 1991. Mean-absolute deviation portfolio optimization model and its applications to tokyo stock market. Management Science 37: 519–31. [Google Scholar] [CrossRef] [Green Version]
- Maghyereh, Aktham I., Basel Awartani, and Panagiotis Tziogkidis. 2017. Volatility spillovers and cross-hedging between gold, oil and equities: Evidence from the gulf cooperation council countries. Energy Economics 68: 440–53. [Google Scholar] [CrossRef] [Green Version]
- Mai, Jan-Frederik, and Matthias Scherer. 2017. Simulating Copulas: Stochastic Models, Sampling Algorithms, and Applications, Volume 6 of Series in Quantitative Finance. Singapore: World Scientific. [Google Scholar]
- Marimoutou, Velayoudoum, Bechir Raggad, and Abdelwahed Trabelsi. 2009. Extreme value theory and value at risk: Application to oil market. Energy Economics 31: 519–30. [Google Scholar] [CrossRef] [Green Version]
- Markowitz, Harry. 1952. Portfolio selection. The Journal of Finance 7: 77–91. [Google Scholar]
- Mensi, Walid, Atef Hamdi, and Seong-Min Yoon. 2018. Modelling multifractality and efficiency of gcc stock markets using the mf-dfa approach: A comparative analysis of global, regional and islamic markets. Physica A: Statistical Mechanics and Its Applications 503: 1107–16. [Google Scholar] [CrossRef]
- Messaoud, Samia Ben, and Chaker Aloui. 2015. Measuring risk of portfolio: GARCH-copula model. Journal of Economic Integration 30: 172–205. [Google Scholar] [CrossRef] [Green Version]
- Nelsen, Roger B. 2007. An Introduction to Copulas. New York: Springer Science & Business Media. [Google Scholar]
- Patton, Andrew J. 2004. On the out-of-sample importance of skewness and asymmetric dependence for asset allocation. Journal of Financial Econometrics 2: 130–68. [Google Scholar] [CrossRef] [Green Version]
- Pfaff, Bernhard. 2016. Financial Risk Modelling and Portfolio Optimization with R. New York: John Wiley & Sons. [Google Scholar]
- Quaranta, Anna Grazia, and Alberto Zaffaroni. 2008. Robust optimization of conditional value at risk and portfolio selection. Journal of Banking & Finance 32: 2046–56. [Google Scholar]
- Rockafellar, R. Tyrrell, and Stanislav Uryasev. 2000. Optimization of conditional value-at-risk. Journal of Risk 2: 21–42. [Google Scholar] [CrossRef] [Green Version]
- Rockafellar, R. Tyrrell, and Stanislav Uryasev. 2002. Conditional value-at-risk for general loss distributions. Journal of Banking & Finance 26: 1443–71. [Google Scholar]
- Sabino da Silva, Fernando B., and Flávio Ziegelman. 2017. Robust Portfolio Optimization with Multivariate Copulas: A Worst-Case CVaR Approach. Available online: https://papers.ssrn.com/sol3/papers.cfm?abstract_id=3076283 (accessed on 1 April 2021). [CrossRef]
- Salahi, Maziar, Farshid Mehrdoust, and Farzaneh Piri. 2013. CVaR robust mean-CVaR portfolio optimization. International Scholarly Research Notices 2013: 570950. [Google Scholar] [CrossRef] [Green Version]
- Smillie, Alan. 2008. New Copula Models in Quantitative Finance. Ph.D. thesis, Imperial College London, London, UK. [Google Scholar]
- Szegö, Giorgio. 2005. Measures of risk. European Journal of Operational Research 163: 5–19. [Google Scholar] [CrossRef]
- Welsh, William F. 1999. On the reliability of cross-correlation function lag determinations in active galactic nuclei. Publications of the Astronomical Society of the Pacific 111: 1347. [Google Scholar] [CrossRef] [Green Version]
- Yan, Jun. 2007. Enjoy the joy of copulas: With a package copula. Journal of Statistical Software 21: 1–21. [Google Scholar] [CrossRef] [Green Version]
- Young, Martin R. 1998. A minimax portfolio selection rule with linear programming solution. Management Science 44: 673–83. [Google Scholar] [CrossRef] [Green Version]
- Zhu, Shushang, and Masao Fukushima. 2009. Worst-case conditional value-at-risk with application to robust portfolio management. Operations Research 57: 1155–68. [Google Scholar] [CrossRef]







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| With Optimal Weights | With Random Weights | |||
|---|---|---|---|---|
| WCVaR | Multivariate Normal | WCVaR | Multivariate Normal | |
| VaR | 1.340576 | 1.087546 | 1.641517 | 1.619638 |
| CVaR | 1.675549 | 1.267103 | 2.122687 | 1.836164 |
| Class | Type of Asset | Number of Assets | VaR | WCVaR |
|---|---|---|---|---|
| 1 | Energy | 20 | 0.4749 | 0.6532 |
| 2 | Materials | 68 | 0.1702 | 0.2218 |
| 3 | Industrials | 52 | 0.3766 | 0.5712 |
| 6 | Healthcare | 9 | 1.1005 | 1.4873 |
| 8 | Information Technology | 5 | 1.0342 | 1.8063 |
| 9 | Communication Services | 13 | 1.3899 | 2.2619 |
| 10 | Utilities | 7 | 1.6091 | 2.1049 |
| 11 | Real Estate | 47 | 0.0128 | 0.0173 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Alotaibi, T.S.; Dalla Valle, L.; Craven, M.J. The Worst Case GARCH-Copula CVaR Approach for Portfolio Optimisation: Evidence from Financial Markets. J. Risk Financial Manag. 2022, 15, 482. https://doi.org/10.3390/jrfm15100482
Alotaibi TS, Dalla Valle L, Craven MJ. The Worst Case GARCH-Copula CVaR Approach for Portfolio Optimisation: Evidence from Financial Markets. Journal of Risk and Financial Management. 2022; 15(10):482. https://doi.org/10.3390/jrfm15100482
Chicago/Turabian StyleAlotaibi, Tahani S., Luciana Dalla Valle, and Matthew J. Craven. 2022. "The Worst Case GARCH-Copula CVaR Approach for Portfolio Optimisation: Evidence from Financial Markets" Journal of Risk and Financial Management 15, no. 10: 482. https://doi.org/10.3390/jrfm15100482
APA StyleAlotaibi, T. S., Dalla Valle, L., & Craven, M. J. (2022). The Worst Case GARCH-Copula CVaR Approach for Portfolio Optimisation: Evidence from Financial Markets. Journal of Risk and Financial Management, 15(10), 482. https://doi.org/10.3390/jrfm15100482