1. Introduction
We often cannot measure explanatory variables correctly in regression models because an observation may not be performed properly. The estimation result may be distorted when we estimate the model from data with measurement errors. We call models with measurement errors in an explanatory variable Error in Variable (EIV) models. In addition, actual phenomena often cannot be explained adequately by a simple linear structure, and the estimation of non-linear models, especially generalized linear models, from data with errors is a significant problem. Various studies have focused on non-linear EIV models (see, for example,
Box 1963;
Geary 1953). Classical error models assume that an explanatory variable is measured with independent stochastic errors (
Kukush and Schneeweiss 2000). Berkson error models assume that the explanatory variable is a controlled variable with an error and that only the controlled variable can be measured (
Burr 1988;
Huwang and Huang 2000). Approaches to EIV models vary according to the situation. In this paper, we consider the former EIV. The corrected score function in
Nakamura (
1990) has been used to estimate generalized linear models. In particular, the Poisson regression model is easy to handle analytically in generalized linear models as we see later. Thus, we focus on the Poisson regression model with measurement errors.
Approaches to a Poisson regression model with classical errors have been discussed by
Kukush et al. (
2004),
Shklyar and Schneeweiss (
2005),
Jiang and Ma (
2020),
Guo and Li (
2002), and so on.
Kukush et al. (
2004) described the statistical properties of the naive estimator, corrected score estimator, and structural quasi score estimator of a Poisson regression model with normally distributed explanatory variable and measurement errors.
Shklyar and Schneeweiss (
2005) assumed an explanatory variable and a measurement error with a multivariate normal distribution and compared the asymptotic covariance matrices of the corrected score estimator, simple structural estimator, and structural quasi score estimator of a Poisson regression model.
Jiang and Ma (
2020) assumed a high-dimensional explanatory variable with a multivariate normal error and proposed a new estimator for a Poisson regression model by combining Lasso regression and the corrected score function.
Guo and Li (
2002) assumed a Poisson regression model with classical errors and proposed an estimator that is a generalization of the corrected score function discussed in
Nakamura (
1990) for generally distributed errors; they derived the asymptotic normality of the proposed estimator.
In this study, we generalize the naive estimator discussed in
Kukush et al. (
2004). They reported the bias of the naive estimator, however, the explanatory variable is not always normally distributed as they assume. In practice, the assumption of a normal distribution is not realistic. Here, we assume that the explanatory variable and measurement error are not limited to normal distributions. However, the naive estimator does not always exist in every situation. Therefore, we clarify the requirements for the existence of the naive estimator and derive its asymptotic bias. The constant vector to which the naive estimator converges in probability does not coincide with the unknown parameter in the model. Therefore, we propose a consistent estimator of the unknown parameter using the naive estimator. It is obtained from a system of equations that represent the relationship between the unknown parameter and constant vector. As illustrative examples, we present explicit representations of the new estimator for a Gamma explanatory variable with a normal error or a Gamma error.
In
Section 2, we present the Poisson regression model with measurement errors and the definition of the naive estimator and show that the naive estimator has an asymptotic bias for the true parameter. In
Section 3, we consider the requirements for the existence of the naive estimator and derive its asymptotic bias and asymptotic mean squared error (MSE) assuming that the explanatory variable and measurement error are generally distributed. In addition, we introduce application examples of a Gamma explanatory variable with a normal error or a Gamma error. In
Section 4, we propose the corrected naive estimator as a consistent estimator of the true parameter under general distributions and give application examples for a Gamma explanatory variable with a normal error or a Gamma error. In
Section 5, we present simulation studies that compare the performance of the naive estimator and corrected naive estimator. In
Section 6, we apply the naive and corrected naive estimators to real data in two cases. Finally, discussions are presented in
Section 7.
4. Corrected Naive Estimator
In this section, we propose a corrected naive estimator as a consistent estimator of
under general distributions and give application examples for a Gamma explanatory variable with a normal error or a Gamma error. From (7), we have the following system of equations:
By solving this system of equations for
and replacing
with the naive estimator
, we obtain the consistent estimator of the true
. Here,
Therefore,
Thus,
is a consistent estimator of
. If
G has zero in
and satisfies
then, by the theorem of implicit functions, there exists a unique
-class function
h that satisfies
in the neighborhood of the zero of
G. We note that
h is the inverse function of
g in Theorem 1. We propose a corrected naive estimator that is the consistent estimator of the true
as follows.
Theorem 2. Let . Assume that and U is independent of . Assume the existence of . LetAssume G has zero in and satisfiesThen, the corrected naive estimator , which corrects the bias of the naive estimator , is given bywhere h is a -class function satisfying in the neighborhood of the zero of G. Furthermore, the corrected naive estimator is a consistent estimator of β. Example 1. We derive the corrected naive estimator assumingWe obtainG has zero in and satisfies . From , we obtain the implicit functionThus, by Theorem 2, the corrected naive estimator is given by Example 2. We derive the corrected naive estimator assumingWe obtainG has zero in and satisfies . From , we obtain the implicit functionThus, by Theorem 2, the corrected naive estimator is given by 6. Real Data Analysis
In this section, we apply the naive and corrected naive estimators to real data in two cases. First, we consider football data provided by
Understat (
2014). In this work, we focus on Goals and expected Goals (xG) in data on
N = 24,580 matches over 6 seasons between 2014–2015 and 2019–2020 from the Serie A, the Bundesliga, La Liga, the English Premier League, Ligue 1, and the Russian Premier League. Detail, such as the types and descriptions of the features, used in this section are provided in
Table 5.
We use goals as an objective variable Y and xG as an explanatory variable X and assume as the true model. Thus, this Poisson regression model refers to the extent to which expected goals (xG) explains (true) goals. We assume that the true parameter is obtained by the estimate from all N data.
As a diagnostic technique, we calculate a measure of goodness-of-fit to verify that the dataset follows a Poisson regression model.
Table 6 shows estimates of
and
(
McFadden 1974), where
is the ratio of the log-likelihood estimate to the initial log-likelihood.
is an overdispersion parameter. We may consider that overdispersion is not observed because
equates to the standard Poisson regression model. The estimated value of
is
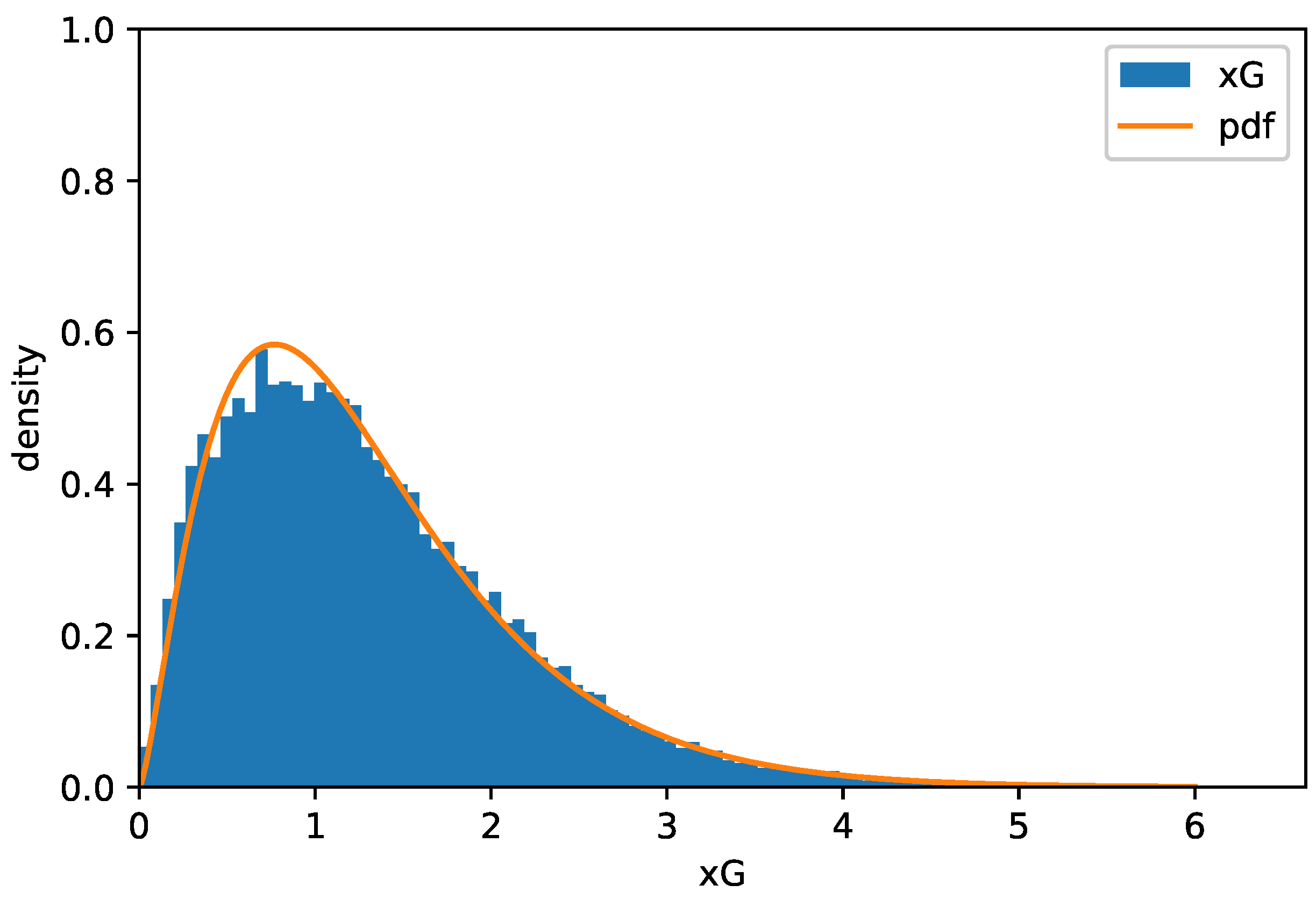
. Thus, we use this estimate as a true value. We assume
(xG)
and obtain estimates of
as
(see
Figure 1).
Expected goals (xG) is a performance metric used to represent the probability of a scoring opportunity that may result in a goal. xG is typically calculated from shot data. The measurer assigns a probability of scoring to a given shot and calculates the sum of the probabilities over a single game as xG. Observation error may occur in subjective evaluations. We can consider the situation that a high scorer happened to rate. Thus, we assume that
X includes a stochastic error
U given as
Because
W must be a positive value, we choose a positive error by
with
. We sample 1000 random samples from among all
N samples to obtain the values of the estimates of
s. We repeat the estimations
10,000 times to obtain the Monte Carlo mean of
s. The bias is calculated by the difference between the Monte Carlo mean and the true value.
Table 7 shows the estimated bias calculated by 10,000 simulations. The estimated bias of the corrected naive estimator is smaller than that of the naive estimator in all cases.
Next, we apply the naive and corrected naive estimators to financial data based on data collected in the FinAccess survey conducted in 2019, provided by
Kenya National Bureau of Statistics (
2019). In this study, we focus on the values labelled as finhealthscore and Normalized Household weights, with a sample size of
. Details of the features used in this section, such as their types and descriptions, are provided in
Table 8.
We use finhealthscore as an objective variable Y and normalized household weights as an explanatory variable X and assume as the true model. We further assume that the true parameter is obtained by the estimate from all N data.
As a diagnostic technique, we calculate a measure of goodness-of-fit to verify that the dataset follows a Poisson regression model.
Table 9 shows estimates of
and
(
McFadden 1974). Overdispersion tends to occur to some extent in this Poisson regression model because the estimate of
is greater than 1. The estimated value of
is
. As in the previous example, we regard the estimate as a true value. We assume
and obtain estimates of
as
(see
Figure 2).
According to
Kenya National Bureau of Statistics (
2019), the data from the FinAccess survey were weighted and adjusted for non-responses to obtain a representative dataset at the national and county level. Thus, we may consider the situation that
X exhibits a stochastic error
U as
We assume a positive error by
with
because the distribution of normalized household weights is positive. We sample random 1000 samples from among all
N samples to obtain the values of the estimates of
s. We repeat the estimations over
= 10,000 iterations to obtain the Monte Carlo mean of
s. The bias is calculated by the difference between the Monte Carlo mean and the true value.
Table 10 shows estimated bias calculated by 10,000 simulations. The estimated bias of the corrected naive estimator is smaller than that of the naive estimator in all cases.








{kind=link}
{kind=link}