
Revisiting the Determinants of Consumption: A Bayesian Model Averaging Approach


Abstract
:1. Introduction
2. Potential Determinants of Consumption
3. Data and the Model Specification
4. Econometric Framework
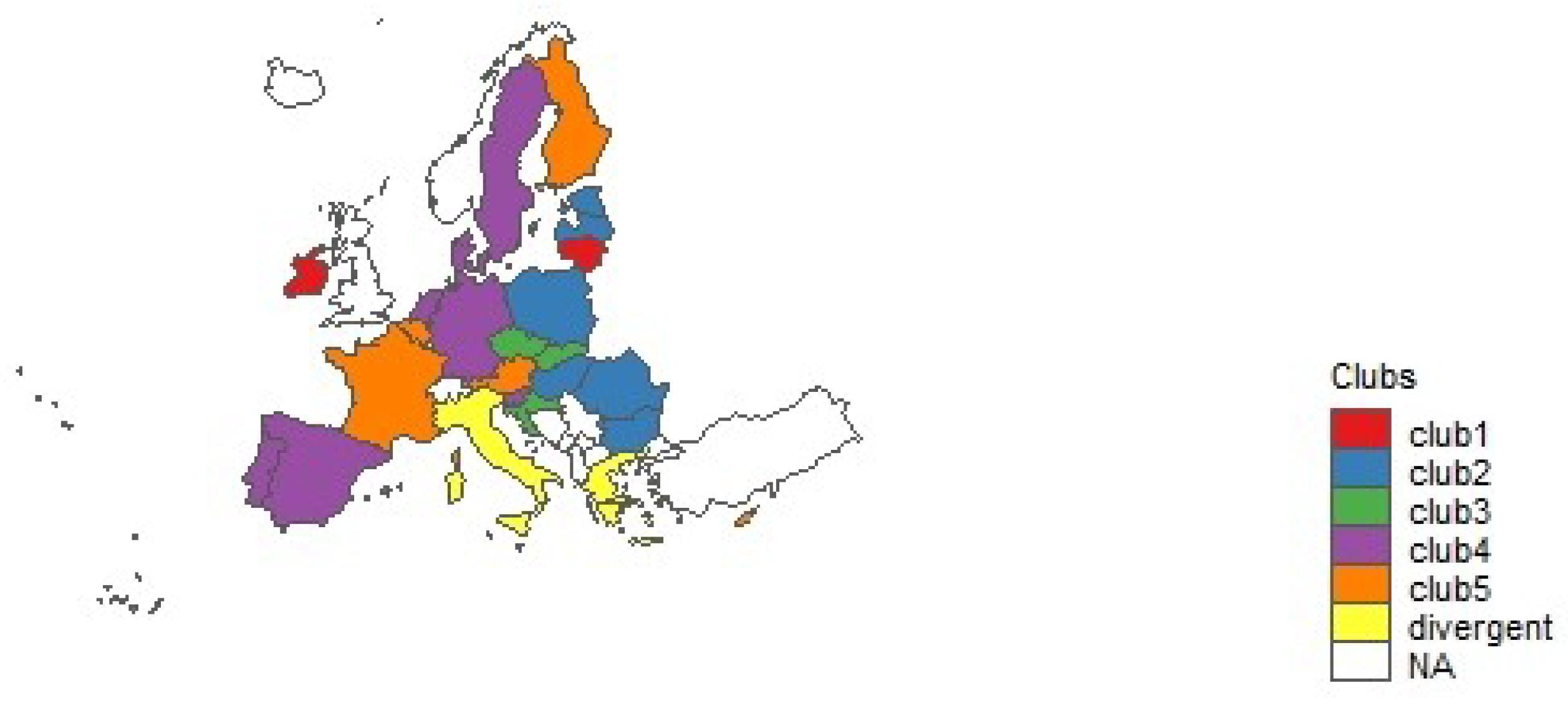
4.1. Convergence Club Analysis
4.2. Bayesian Model Averaging
5. Empirical Findings
6. Robustness Checks
7. Conclusions
Supplementary Materials
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
Appendix A. Relative Transition Paths for Convergence Clubs

Appendix B. Variable Definitions

{kind=link}
{kind=link}
{kind=link}
| Variable | Original Data | Original Frequency | Transformation from Original to Quarterly | Transformation from Original to Annual |
|---|---|---|---|---|
| cons | Final consumption expenditure: chain-linked volumes, Index 2010 = 100, per capita | Quarterly | seasonal adjustment and annual growth (%) | seasonal adjustment, annual growth (%) and annual averages |
| income | GDP at market prices: chain-linked volumes, Index 2010 = 100, per capita | Quarterly | seasonal adjustment and annual growth (%) | seasonal adjustment, annual growth (%) and annual averages |
| ipi | Volume index of production (manufacturing) seasonally adjusted data, 2015 = 100 | Monthly | annual growth (%) and quarterly averages | annual growth (%) and annual averages |
| wage | Real labor productivity per person, Index, 2015 = 100, seasonally adjusted | Quarterly | annual growth (%) | annual averages |
| ur | % of population in the labor force, seasonally adjusted | Monthly | annual change and quarterly averages | annual change and annual averages |
| car | Intention to buy a car within the next 12 months | Quarterly | level | annual averages |
| cci | Consumer confidence indicator (seasonally adjusted) | Monthly | quarterly averages | annual averages |
| house | Purchase or build a home within the next 12 months | Quarterly | level | annual averages |
| debt | Government consolidated gross debt (% of GDP) | Quarterly | annual difference | annual difference and annual averages |
| gasset | General government financial assets/liabilities % GDP | Quarterly | level | annual averages |
| hprice | Housing price index *, 2010 = 100 | Quarterly | annual growth (%) | annual growth (%) and annual averages |
| inf | HICP Index, 2015 = 100 | Monthly | annual growth and quarterly averages | annual growth and annual averages |
| int | EMU convergence criterion bond yield | Quarterly | levels | annual averages |
| trade | Trade balance for values (ratio for indices) Unit value index (2015 = 100) | Monthly | quarterly averages | annual averages |
| inequal | Income quintile share ratio S80/S20 for disposable income | Annual | - | level |
| hasset | Household total financial assets/liabilities (% of GDP) | Annual | - | differenced |
| environ | Total environmental taxes (% of GDP) | Annual | - | level |
| gprice | Natural gas prices for household consumers: Band D3-Gigajoule | Bi-annual | - | annual growth and annual averages |
| 1 | Pandemic period is excluded from the analysis. |
| 2 | can be , , . Phillips and Sul (2007) reflects that the prior function has the best test under Monte Carlo simulations. |
| 3 | Phillips and Sul (2007), r = 30% is recommended for small sample case, where T ≥ 50. |
| 4 | There can be divergent units not fitting into any club. |
| 5 | We use R-package “ConvergenceClubs” for convergence club analysis of described by Sichera and Pizzuto (2019). |
| 6 | Convergence club analysis is replicated for short-run approach using quarterly data. The country groups are observed to be similar with annual data. |
| 7 | We can add Croatia to the “new Europe” definition, joining by 2013. Additionally, Nowak and Kochkova (2011) excludes Cyprus and Malta from their analysis due to their different transition patterns. |
| 8 | Except for Slovenia, which is in club 4 and the divergent countries. |
| 9 | All regression models utilize pooled OLS since homogeneity of the panels is ensured using convergence club analysis. |
| 10 | We use R-package “BMS” for BMA analysis of described by Zeugner and Feldkircher (2015). |
| 11 | Instead of including government expenditure or taxation variables individually, we concentrate on net effect variables since the prior will provide insufficient inference in the availability of adverse shocks from expansionary and contractionary fiscal policies. |
| 12 | The robustness check using different model priors for subgroups of EU27 are available in the Supplementary File to this document. |
| 13 |
References
- Acemoglu, Daron, and Andrew Scott. 1994. Consumer confidence and rational expectations: Are agents’ beliefs consistent with the theory? The Economic Journal 104: 1–19. [Google Scholar] [CrossRef]
- Acuña, Guillermo, Cristián Echeverría, and Cristian Pinto-Gutiérrez. 2020. Consumer confidence and consumption: Empirical evidence from chile. International Review of Applied Economics 34: 75–93. [Google Scholar] [CrossRef]
- Ahmed, M. Iqbal, and Steven P. Cassou. 2016. Does consumer confidence affect durable goods spending during bad and good economic times equally? Journal of Macroeconomics 50: 86–97. [Google Scholar] [CrossRef]
- Alp, Esra, and Ünal Seven. 2019. The dynamics of household final consumption: The role of wealth channel. Central Bank Review 19: 21–32. [Google Scholar] [CrossRef]
- Attanasio, Orazio P., Laura Blow, Robert Hamilton, and Andrew Leicester. 2009. Booms and busts: Consumption, house prices and expectations. Economica 76: 20–50. [Google Scholar] [CrossRef] [Green Version]
- Blanchard, Olivier. 1993. Consumption and the recession of 1990–1991. The American Economic Review 83: 270–74. [Google Scholar]
- Boone, Laurence, and Nathalie Girouard. 2003. The stock market, the housing market and consumer behaviour. OECD Economic Studies 2002: 175–200. [Google Scholar] [CrossRef] [Green Version]
- Bootle, Roger. 1981. How important is it to defeat inflation-the evidence. Three Banks Review 132: 23–47. [Google Scholar]
- Calomiris, Charles, Stanley D. Longhofer, and William Miles. 2009. The (Mythical?) Housing Wealth Effect. Technical Report. Cambridge: National Bureau of Economic Research, Inc. [Google Scholar]
- Carroll, Christopher D., Jeffrey C. Fuhrer, and David W. Wilcox. 1994. Does consumer sentiment forecast household spending? if so, why? The American Economic Review 84: 1397–408. [Google Scholar]
- Cho, Dooyeon, and Dong-Eun Rhee. 2013. Nonlinear effects of government debt on private consumption: Evidence from oecd countries. Economics Letters 121: 504–7. [Google Scholar] [CrossRef]
- Dees, Stephane, and Pedro Soares Brinca. 2013. Consumer confidence as a predictor of consumption spending: Evidence for the united states and the euro area. International Economics 134: 1–14. [Google Scholar] [CrossRef] [Green Version]
- Dynan, Karen E., and Dean M. Maki. 2001. Does the stock market matter for consumption? Finance and Economics Discussion Working Paper 23: 1–44. [Google Scholar]
- Feldstein, Martin S. 2002. The Role for Discretionary Fiscal Policy in a Low Interest Rate Environment. Cambridge: National Bureau of Economic Research, Inc. [Google Scholar]
- Friedman, Milton. 1957. The Permanent Income Hypothesis. Princeton: Princeton University Press. [Google Scholar]
- Gholipour Fereidouni, Hassan, and Reza Tajaddini. 2017. Housing wealth, financial wealth and consumption expenditure: The role of consumer confidence. The Journal of Real Estate Finance and Economics 54: 216–36. [Google Scholar] [CrossRef]
- Gylfason, Thorvaldur. 1981. Interest rates, inflation, and the aggregate consumption function. The Review of Economics and Statistics 63: 233–45. [Google Scholar] [CrossRef]
- Hall, Robert E. 1978. Stochastic implications of the life cycle-permanent income hypothesis: Theory and evidence. Journal of Political Economy 86: 971–87. [Google Scholar] [CrossRef] [Green Version]
- Hall, Robert E. 2011. The long slump. American Economic Review 101: 431–69. [Google Scholar] [CrossRef] [Green Version]
- Jaramillo, Laura, and Alexandre Chailloux. 2015. It’s Not All Fiscal: Effects of Income, Fiscal Policy, and Wealth on Private Consumption. Washington, DC: International Monetary Fund. [Google Scholar]
- Juhro, Solikin M., and Bernard Njindan Iyke. 2020. Consumer confidence and consumption expenditure in indonesia. Economic Modelling 89: 367–77. [Google Scholar] [CrossRef]
- Katona, George. 1974. Psychology, and consumer economics. Journal of Consumer Research 1: 1–8. [Google Scholar] [CrossRef]
- Koop, Gary, Simon M. Potter, and Rodney W. Strachan. 2008. Re-examining the consumption–wealth relationship: The role of model uncertainty. Journal of Money, Credit and Banking 40: 341–67. [Google Scholar] [CrossRef] [Green Version]
- Kundan Kishor, N. 2007. Does consumption respond more to housing wealth than to financial market wealth? if so, why? Journal of Real Estate Finance & Economics 35: 427–448. [Google Scholar]
- Ludvigson, Sydney. 1996. The macroeconomic effects of government debt in a stochastic growth model. Journal of Monetary Economics 38: 25–45. [Google Scholar] [CrossRef]
- Mankiw, N. Gregory. 1981. The permanent income hypothesis and the real interest rate. Economics Letters 7: 307–11. [Google Scholar] [CrossRef]
- Modigliani, Franco, and Richard Brumberg. 1954. Utility analysis and the consumption function: An interpretation of cross-section data. Franco Modigliani 1: 388–436. [Google Scholar]
- Nowak, Jan, and Olena Kochkova. 2011. Income, culture, and household consumption expenditure patterns in the european union: Convergence or divergence? Journal of International Consumer Marketing 23: 260–75. [Google Scholar]
- Phillips, Peter C. B., and Donggyu Sul. 2007. Transition modeling and econometric convergence tests. Econometrica 75: 1771–855. [Google Scholar] [CrossRef] [Green Version]
- Phillips, Peter C. B., and Donggyu Sul. 2009. Economic transition and growth. Journal of Applied Econometrics 24: 1153–85. [Google Scholar] [CrossRef] [Green Version]
- Raftery, Adrian E. 1995. Bayesian model selection in social research. Sociological Methodology 25: 111–63. [Google Scholar] [CrossRef]
- Raut, Lakshmi K., and Arvind Virmani. 1989. Determinants of consumption and savings behavior in developing countries. The World Bank Economic Review 3: 379–93. [Google Scholar] [CrossRef] [Green Version]
- Sala-i Martin, Xavier, Gernot Doppelhofer, and Ronald I. Miller. 2004. Determinants of long-term growth: A bayesian averaging of classical estimates (bace) approach. American Economic Review 94: 813–35. [Google Scholar] [CrossRef] [Green Version]
- Sichera, Roberto, and Pietro Pizzuto. 2019. Convergenceclubs: A package for performing the phillips and sul’s club convergence clustering procedure. R Journal 11: 142. [Google Scholar] [CrossRef]
- Sierminska, Eva, and Yelena Takhtamanova. 2012. Financial and housing wealth and consumption spending: Cross-country and age group comparisons. Housing Studies 27: 685–719. [Google Scholar] [CrossRef]
- Weber, Warren E. 1970. The effect of interest rates on aggregate consumption. The American Economic Review 60: 591–600. [Google Scholar]
- Zellner, Arnold. 1986. On assessing prior distributions and bayesian regression analysis with g-prior distributions. Bayesian Inference and Decision Techniques 6: 223–43. [Google Scholar]
- Zeugner, Stefan, and Martin Feldkircher. 2015. Bayesian model averaging employing fixed and flexible priors: The bms package for r. Journal of Statistical Software 68: 1–37. [Google Scholar] [CrossRef] [Green Version]


| Tests | Countries | Beta | Standard Error |
|---|---|---|---|
| Convergence test | EU27 | −7.238 | 2.303 |
| Club Tests | |||
| club 1 | IE, LT | −3.307 | 3.140 |
| club 2 | RO, LV, PL, EE, MT, HU, BG | −3.331 | 2.109 |
| club 3 | SK, CZ, HR | −3.717 | 2.305 |
| club 4 | SI, DE, DK, SE, PT, ES, NL | −5.025 | 3.163 |
| club 5 | CY, BE, FR, AT, FI | −3.323 | 3.247 |
| EU27 | Club 1 | Club 2 | Club 3 | Club 4 | Club 5 | |||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| PIP | Post Mean | PIP | Post Mean | PIP | Post Mean | PIP | Post Mean | PIP | Post Mean | PIP | Post Mean | |
| (Intercept) | 1.000 | −2.810 | 1.000 | −4.039 | 1.000 | −0.894 | 1.000 | −1.707 | 1.000 | −4.115 | 1.000 | −2.878 |
| income | 1.000 | 0.779 | 0.996 | 0.885 | 1.000 | 0.714 | 0.999 | 0.591 | 1.000 | 1.060 | 1.000 | 1.260 |
| (0.036) | (0.226) | (0.057) | (0.118) | (0.078 | (0.147 | |||||||
| ipi | 1.000 | −0.169 | 0.171 | −0.010 | 0.059 | 0.001 | 0.883 | −0.194 | 1.000 | −0.450 | 0.994 | −0.271 |
| (0.022) | (0.036) | (0.011) | (0.099) | (0.049) | (0.070) | |||||||
| wage | 0.094 | −0.006 | 0.953 | −0.430 | 0.065 | 0.000 | 0.092 | 0.002 | 0.104 | −0.013 | 0.960 | −0.257 |
| (0.021) | (0.161) | (0.019) | (0.035) | (0.053) | (0.111) | |||||||
| ur | 1.000 | −0.160 | 0.204 | −0.030 | 0.206 | −0.022 | 0.215 | 0.023 | 0.948 | −0.169 | 0.359 | 0.047 |
| (0.025) | (0.091) | (0.052) | (0.057) | (0.054) | (0.074) | |||||||
| car | 0.195 | −0.008 | 0.334 | −0.071 | 0.222 | 0.018 | 0.979 | −0.265 | 0.061 | −0.001 | 0.082 | 0.000 |
| (0.018) | (0.132) | (0.040) | (0.080) | (0.010) | (0.014) | |||||||
| cci | 0.058 | 0.002 | 0.713 | 0.216 | 0.397 | −0.045 | 0.989 | 0.460 | 0.084 | 0.003 | 0.194 | 0.014 |
| (0.010) | (0.173) | (0.065) | (0.125) | (0.016) | (0.034) | |||||||
| house | 0.036 | 0.000 | 0.757 | −0.200 | 0.067 | 0.000 | 0.105 | 0.004 | 0.057 | −0.001 | 0.389 | 0.027 |
| (0.006) | (0.141) | (0.013) | (0.019) | (0.009) | (0.040) | |||||||
| debt | 0.045 | −0.001 | 0.236 | 0.029 | 0.070 | −0.002 | 0.931 | −0.248 | 0.064 | −0.002 | 0.074 | 0.001 |
| (0.006) | (0.071) | (0.016) | (0.110) | (0.014) | (0.016) | |||||||
| gasset | 0.998 | −0.073 | 0.358 | −0.032 | 0.145 | −0.008 | 0.145 | −0.008 | 0.946 | −0.095 | 0.884 | −0.090 |
| (0.017) | (0.052) | (0.023) | (0.027) | (0.036) | (0.045) | |||||||
| hprice | 0.998 | 0.094 | 0.693 | 0.250 | 0.893 | 0.152 | 0.084 | 0.001 | 0.196 | −0.012 | 0.099 | −0.004 |
| (0.021) | (0.206) | (0.072) | (0.020) | (0.028) | (0.017) | |||||||
| inf | 0.035 | 0.000 | 0.405 | 0.049 | 0.708 | −0.079 | 0.134 | −0.007 | 0.066 | −0.002 | 0.656 | 0.055 |
| (0.004) | (0.076) | (0.062) | (0.025) | (0.010) | (0.048) | |||||||
| int | 0.935 | 0.067 | 0.467 | 0.080 | 0.105 | 0.006 | 0.247 | 0.025 | 0.052 | 0.000 | 0.067 | 0.000 |
| (0.026) | (0.105) | (0.026) | (0.052) | (0.008) | (0.012) | |||||||
| trade | 1.000 | 0.115 | 0.166 | −0.010 | 0.656 | 0.065 | 0.092 | 0.003 | 0.983 | 0.104 | 0.992 | 0.130 |
| (0.015) | (0.035) | (0.056) | (0.018) | (0.031) | (0.036) | |||||||
| EU27 | Club 1 | Club 2 | Club 3 | Club 4 | Club 5 | |||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| PIP | Post Mean | PIP | Post Mean | PIP | Post Mean | PIP | Post Mean | PIP | Post Mean | PIP | Post Mean | |
| (Intercept) | 1.000 | −5.503 | 1.000 | −1.342 | 1.000 | −0.283 | 1.000 | −1.972 | 1.000 | −1.373 | 1.000 | −6.776 |
| income | 1.000 | 0.863 | 0.907 | 1.556 | 0.983 | 0.801 | 0.243 | 0.054 | 1.000 | 1.141 | 0.786 | 0.815 |
| (0.079) | (0.849) | (0.179) | (0.140) | (0.172) | (0.536) | |||||||
| ipi | 1.000 | −0.213 | 0.243 | 0.016 | 0.129 | −0.001 | 0.125 | 0.004 | 1.000 | −0.642 | 0.786 | −0.276 |
| (0.051) | (0.080) | (0.033) | (0.056) | (0.109) | (0.195) | |||||||
| wage | 0.070 | −0.008 | 0.864 | −0.897 | 0.175 | 0.028 | 0.178 | 0.008 | 0.240 | −0.043 | 0.431 | 0.282 |
| (0.041) | (0.536) | (0.101) | (0.078) | (0.120) | (0.416) | |||||||
| ur | 0.953 | −0.180 | 0.538 | 0.148 | 0.255 | −0.041 | 0.241 | 0.026 | 0.826 | −0.208 | 0.347 | −0.059 |
| (0.065) | (0.433) | (0.118) | (0.113) | (0.125) | (0.110) | |||||||
| car | 0.626 | −0.074 | 0.273 | 0.002 | 0.224 | −0.019 | 0.847 | −0.395 | 0.552 | −0.116 | 0.207 | 0.000 |
| (0.072) | (0.177) | (0.052) | (0.240) | (0.129) | (0.057) | |||||||
| cci | 0.090 | 0.002 | 0.143 | 0.005 | 0.148 | −0.006 | 0.752 | 0.516 | 0.138 | −0.006 | 0.365 | 0.037 |
| (0.019) | (0.094) | (0.043) | (0.406) | (0.039) | (0.071) | |||||||
| house | 0.166 | 0.014 | 0.237 | −0.014 | 0.148 | 0.002 | 0.322 | 0.068 | 0.249 | −0.027 | 0.250 | −0.017 |
| (0.041) | (0.172) | (0.032) | (0.135) | (0.083) | (0.064) | |||||||
| debt | 0.199 | −0.016 | 0.160 | −0.010 | 0.118 | 0.002 | 0.886 | −0.545 | 0.122 | −0.009 | 0.245 | 0.005 |
| (0.042) | (0.090) | (0.036) | (0.293) | (0.052) | (0.094) | |||||||
| gasset | 0.633 | −0.075 | 0.237 | −0.027 | 0.124 | 0.003 | 0.239 | −0.030 | 0.863 | −0.211 | 0.213 | −0.029 |
| (0.067) | (0.094) | (0.030) | (0.126) | (0.115) | (0.091) | |||||||
| hprice | 0.360 | 0.037 | 0.380 | 0.160 | 0.352 | 0.056 | 0.194 | 0.016 | 0.171 | −0.011 | 0.455 | −0.066 |
| (0.058) | (0.296) | (0.096) | (0.080) | (0.038) | (0.094) | |||||||
| inf | 0.089 | 0.000 | 0.383 | 0.054 | 0.609 | −0.089 | 0.278 | −0.022 | 0.156 | −0.001 | 0.194 | −0.009 |
| (0.013) | (0.108) | (0.089) | (0.073) | (0.025) | (0.042) | |||||||
| int | 0.325 | 0.033 | 0.383 | 0.098 | 0.238 | −0.018 | 0.539 | 0.153 | 0.118 | 0.005 | 0.221 | −0.008 |
| (0.056) | (0.182) | (0.066) | (0.175) | (0.032) | (0.050) | |||||||
| trade | 1.000 | 0.148 | 0.231 | 0.007 | 0.158 | 0.008 | 0.201 | 0.024 | 0.350 | 0.034 | 0.719 | 0.115 |
| (0.032) | (0.110) | (0.039) | (0.086) | (0.057) | (0.094) | |||||||
| inequal | 0.235 | 0.014 | 0.271 | 0.051 | 0.223 | 0.020 | 0.153 | 0.009 | 0.733 | −0.139 | 0.226 | 0.019 |
| (0.031) | (0.154) | (0.048) | (0.068) | (0.108) | (0.067) | |||||||
| hasset | 0.035 | 0.000 | 0.299 | 0.033 | 0.156 | 0.001 | 0.413 | −0.116 | 0.257 | −0.014 | 0.126 | 0.003 |
| (0.007) | (0.084) | (0.028) | (0.172) | (0.038) | (0.033) | |||||||
| environ | 0.068 | 0.002 | 0.285 | 0.038 | 0.233 | −0.011 | 0.181 | −0.001 | 0.226 | 0.013 | 0.241 | 0.017 |
| (0.011) | (0.123) | (0.037) | (0.070) | (0.051) | (0.064) | |||||||
| gprice | 0.504 | 0.042 | 0.246 | −0.003 | 0.349 | 0.039 | 0.402 | 0.061 | 0.191 | 0.013 | 0.616 | 0.097 |
| (0.050) | (0.084) | (0.070) | (0.104) | (0.037) | (0.101) | |||||||
| EU27 | Club 1 | Club 2 | Club 3 | Club 4 | Club 5 | |||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| PIP | Post Mean | PIP | Post Mean | PIP | Post Mean | PIP | Post Mean | PIP | Post Mean | PIP | Post Mean | |
| (Intercept) | 1.000 | −2.196 | 1.000 | −5.815 | 1.000 | 0.225 | 1.000 | −2.238 | 1.000 | −0.789 | 1.000 | −3.399 |
| lincome | 0.953 | 0.283 | 0.366 | −0.100 | 0.387 | 0.134 | 0.833 | 0.254 | 0.971 | 0.515 | 0.997 | 0.389 |
| (0.110) | (0.177) | (0.188) | (0.152) | (0.138) | (0.112) | |||||||
| lipi | 0.283 | −0.019 | 0.162 | −0.011 | 0.217 | 0.021 | 0.164 | −0.017 | 0.989 | −0.289 | 0.105 | −0.011 |
| (0.034) | (0.042) | (0.048) | (0.053) | (0.080) | (0.045) | |||||||
| lwage | 0.580 | 0.084 | 0.197 | 0.014 | 0.721 | 0.205 | 0.228 | 0.028 | 0.142 | 0.005 | 0.193 | −0.029 |
| (0.085) | (0.091) | (0.143) | (0.076) | (0.088) | (0.075) | |||||||
| lur | 1.000 | −0.191 | 0.615 | −0.152 | 0.679 | −0.153 | 0.185 | 0.019 | 0.833 | −0.160 | 0.081 | −0.004 |
| (0.050) | (0.153) | (0.121) | (0.054) | (0.099) | (0.025) | |||||||
| car | 0.334 | −0.027 | 0.141 | 0.010 | 0.184 | 0.016 | 0.999 | −0.354 | 0.093 | −0.002 | 0.070 | 0.002 |
| (0.042) | (0.070) | (0.041) | (0.078) | (0.029) | (0.018) | |||||||
| cci | 1.000 | 0.183 | 0.961 | 0.437 | 0.082 | 0.003 | 1.000 | 0.595 | 0.991 | 0.280 | 0.997 | 0.292 |
| (0.034) | (0.163) | (0.022) | (0.129) | (0.079) | (0.072) | |||||||
| house | 0.685 | −0.059 | 0.998 | −0.486 | 0.072 | −0.002 | 0.100 | 0.004 | 0.748 | −0.124 | 0.059 | 0.001 |
| (0.046) | (0.118) | (0.017) | (0.020) | (0.089) | (0.013) | |||||||
| debt | 0.361 | −0.027 | 0.136 | 0.006 | 0.464 | −0.076 | 0.858 | −0.284 | 0.317 | −0.050 | 0.314 | −0.050 |
| (0.040) | (0.045) | (0.096) | (0.160) | (0.085) | (0.086) | |||||||
| gasset | 1.000 | −0.171 | 0.491 | −0.055 | 0.827 | −0.112 | 0.626 | −0.083 | 0.998 | −0.218 | 1.000 | −0.258 |
| (0.022) | (0.068) | (0.065) | (0.077) | (0.049) | (0.048) | |||||||
| hprice | 1.000 | 0.210 | 1.000 | 0.678 | 1.000 | 0.316 | 0.114 | −0.007 | 0.098 | 0.006 | 0.234 | −0.022 |
| (0.028) | (0.147) | (0.072) | (0.031) | (0.025) | (0.046) | |||||||
| inf | 0.541 | −0.033 | 0.155 | −0.005 | 0.868 | −0.145 | 0.161 | −0.011 | 0.063 | 0.000 | 0.070 | −0.001 |
| (0.034) | (0.039) | (0.081) | (0.031) | (0.014) | (0.016) | |||||||
| int | 1.000 | 0.190 | 0.710 | 0.167 | 0.515 | 0.084 | 0.361 | 0.047 | 0.666 | 0.091 | 0.848 | 0.159 |
| (0.033) | (0.135) | (0.096) | (0.074) | (0.077) | (0.090) | |||||||
| trade | 0.933 | 0.065 | 0.673 | −0.114 | 0.112 | 0.007 | 0.077 | 0.000 | 0.054 | 0.001 | 0.879 | 0.151 |
| (0.026) | (0.099) | (0.025) | (0.015) | (0.011) | (0.077) | |||||||
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Deniz, P.; Stengos, T. Revisiting the Determinants of Consumption: A Bayesian Model Averaging Approach. J. Risk Financial Manag. 2023, 16, 190. https://doi.org/10.3390/jrfm16030190
Deniz P, Stengos T. Revisiting the Determinants of Consumption: A Bayesian Model Averaging Approach. Journal of Risk and Financial Management. 2023; 16(3):190. https://doi.org/10.3390/jrfm16030190
Chicago/Turabian StyleDeniz, Pinar, and Thanasis Stengos. 2023. "Revisiting the Determinants of Consumption: A Bayesian Model Averaging Approach" Journal of Risk and Financial Management 16, no. 3: 190. https://doi.org/10.3390/jrfm16030190
APA StyleDeniz, P., & Stengos, T. (2023). Revisiting the Determinants of Consumption: A Bayesian Model Averaging Approach. Journal of Risk and Financial Management, 16(3), 190. https://doi.org/10.3390/jrfm16030190