
Bayesian Statistics for Loan Default



Abstract
:1. Introduction
- The frequentist view places excessive reliance on historical data, which may lead to poor performance should the historical data be lacking or misleading;
- The frequentist view provides little-to-no incorporation of knowledge and experience to build sound judgement. In other words, proven prior knowledge and experience are not included;
- The frequentist view instils a false sense of security, which leads to a sense of complacency as it encourages a heavy reliance on actions that are supposedly based on scientific truth, however, in reality, many of the most critical and riskiest decisions do not sit within the narrow frequentist paradigm.
- We present a case study that Bayesian is important and can be an alternative to the frequentist approach in predicting loan default;
- We illustrate the repeatability and validity of deploying an analytics life cycle with the use of contemporary software packages. Data for the training are randomly obtained with no leakage or biasness;
- We first perform the comparisons of classical logistic regression and traditional machine learning methods to Bayesian;
- Finally, we extend the model performance and convergence comparisons to various distributions for non-informative priors.
- In Section 2, we briefly cover the background of the Bayesian technique and how Bayesian has slowly entered the mainstream of techniques used for classification, which includes loan default prediction.
- In Section 3, we conducted a case study to illustrate the use of Bayesian to estimate the mean of posterior for loan default.
- In Section 4, the analytics life-cycle methodology, with an emphasis on data pre-processing, is presented, which highlights the repeatability and validity of the methodology in conducting the research.
- In Section 5, various models are constructed and measured with various measurements, of which ROC-AUC is the chief measure.
- In Section 6, comparisons are drawn between Bayesian and traditional frequentist methods. Additionally, a comparison of model performance and ability for convergence for non-informative priors with various distributions (uniform, normal, and GLM) are highlighted.
2. Background
2.1. Bayesian in a Nutshell
- P(M|E) is the posterior distribution that indicates that the probability of the model is probable given the evidence;
- P(M) is the prior that indicates that the probability of the model is probable before the presence of any evidence;
- P(E|M) is the likelihood that indicates that the probability of observing the evidence given the model is probable;
- P(E) is the evidence that indicates the probability of observing the evidence.
2.2. Recent Techniques
3. A Case Study–Bayesian for Loan Default Application
Sample Data
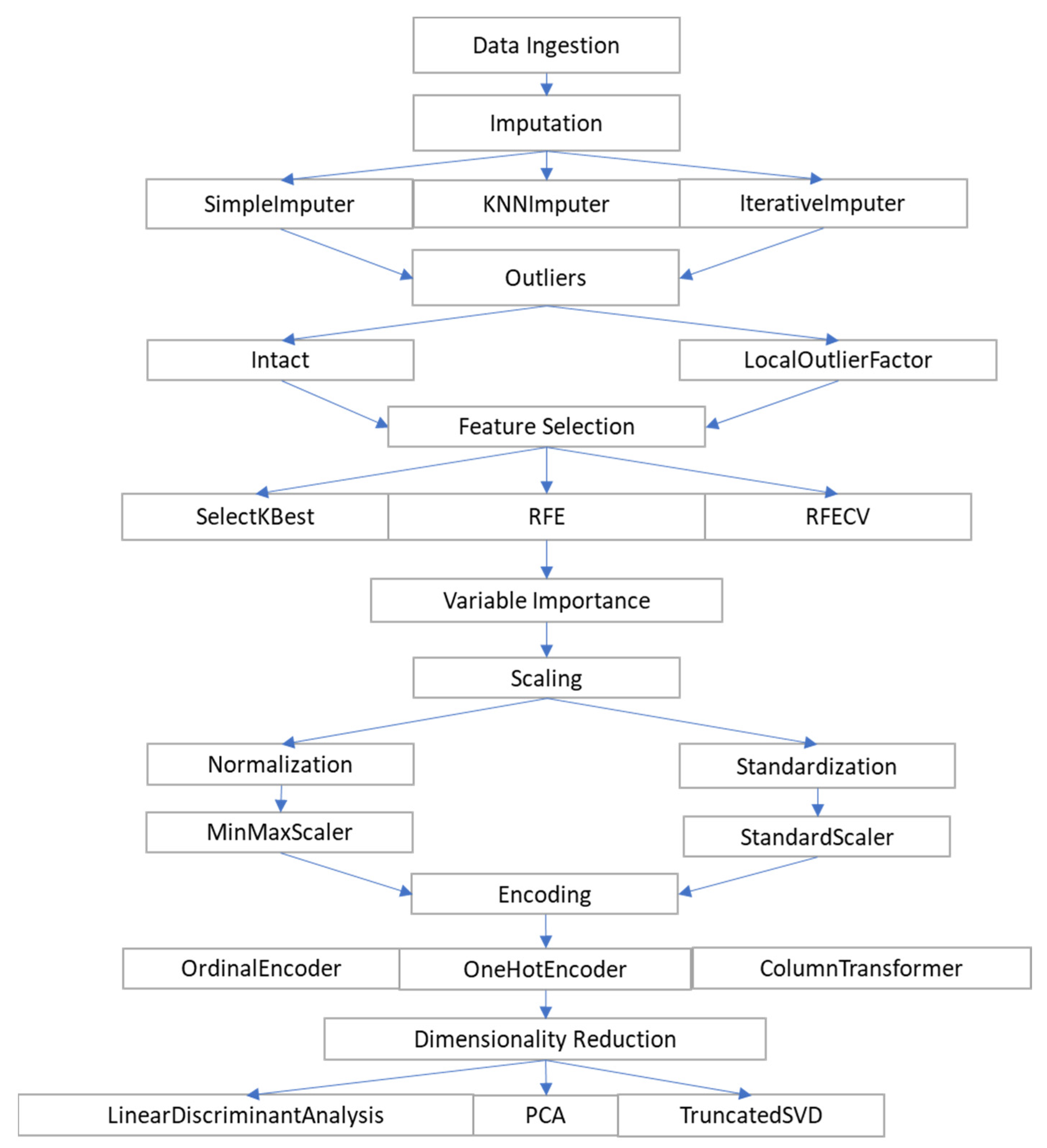
4. Analytics Life Cycle Methodology
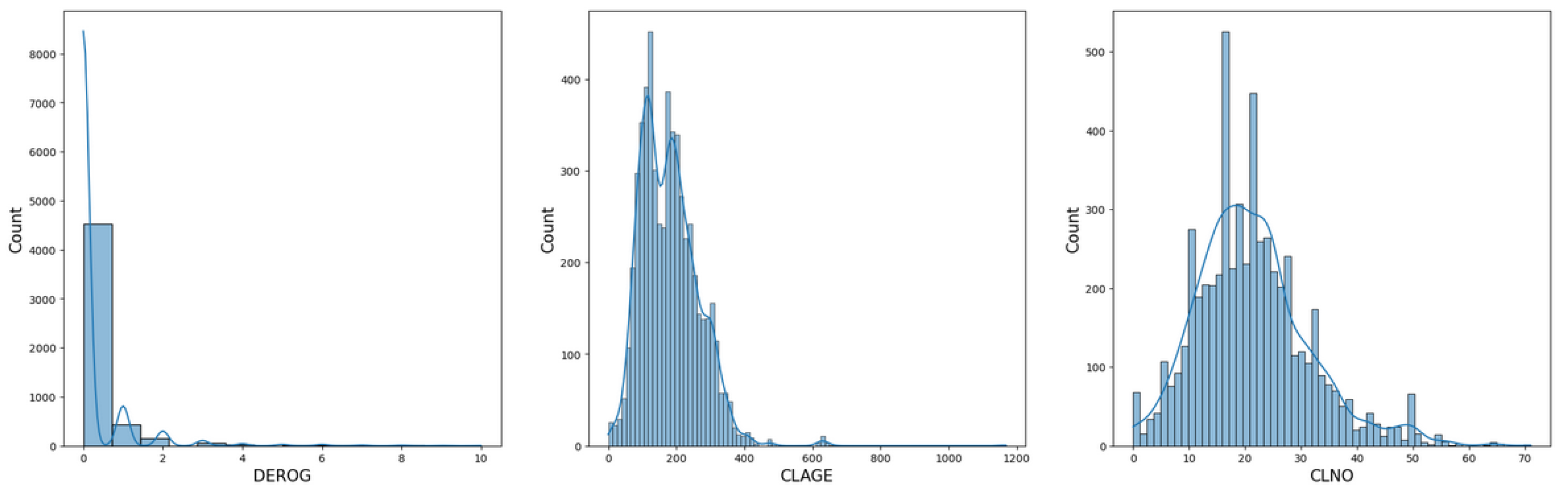
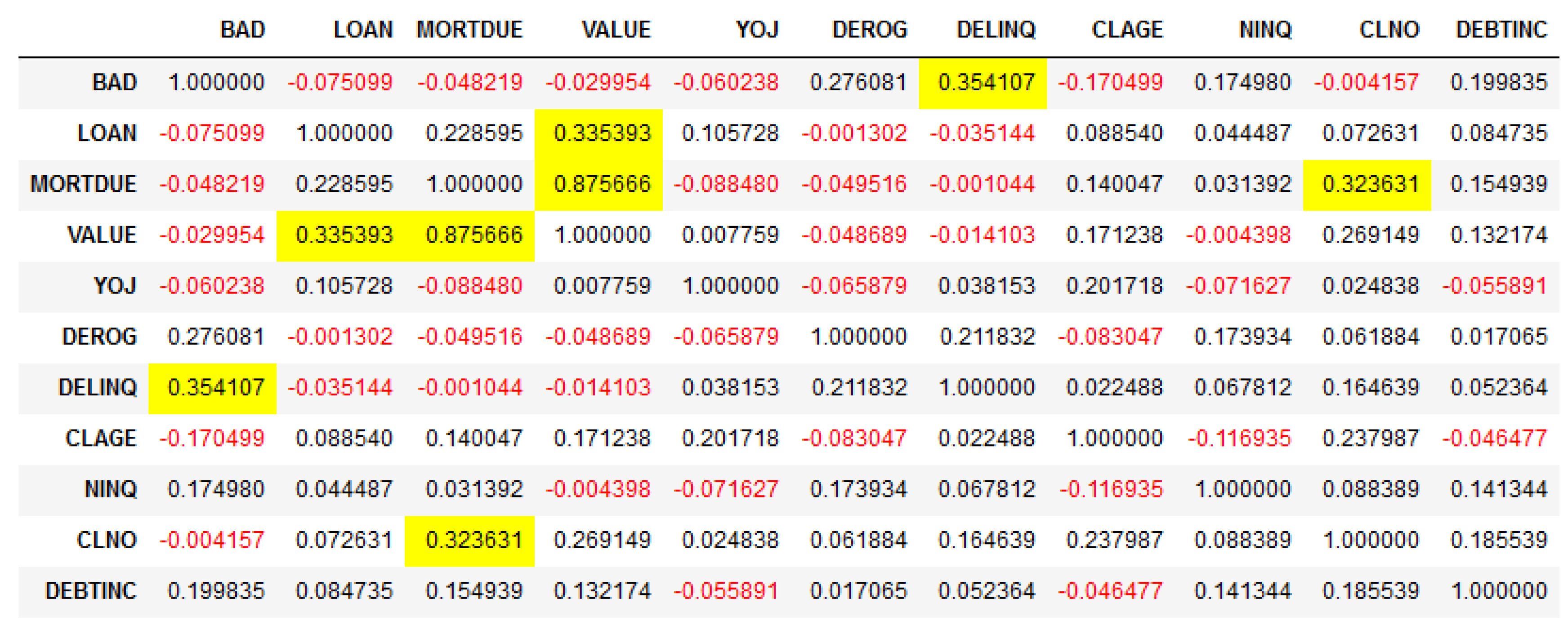
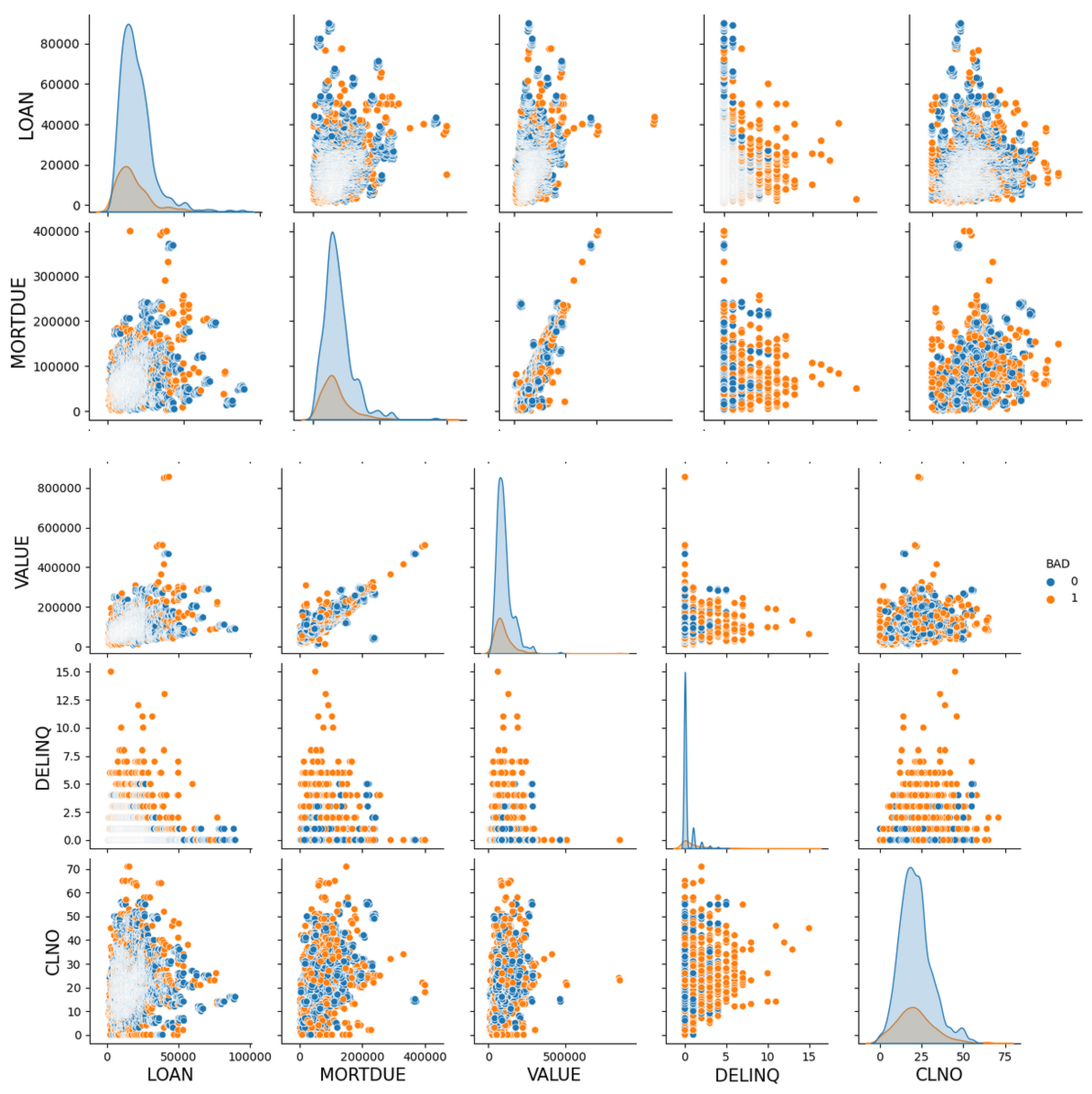
4.1. Exploratory Data Analysis (EDA)
4.2. Data Pre-Processing—Data Preparation
5. Modelling and Measurements
5.1. Modelling Classic Logistic Regression, Machine Learning Algorithms Versus Bayesian Inference
- Evaluate the algorithms:
- ○
- Make a validation dataset using 80:20 ratio for training and testing;
- ○
- Evaluate various algorithms to produce a baseline;
- ○
- Compare various algorithms using various evaluations such as accuracy, precision, recall, f1, and ROC-AUC.
- Improve model accuracy:
- ○
- Tune each model using hyperparameter settings and Scikit-Learn’s GridSearchCV;
- ○
- Include the use of ensemble methods and further turn ensemble methods.
- Select and finalise a model:
- ○
- Choose the best performing model for each algorithm out of the best hyperparameters already known.
5.2. Bayesian Logistic Regression Modelling
- Bayesian Logistic Regression Model 1—assumes a uniform distribution with large enough lower and upper bounds;
- Bayesian Logistic Regression Model 2—assumes a normal distribution;
- Bayesian Logistic Regression Model 3—assumes an automated built-in GLM model from PyMC3.
- TP (true positive)—actual is true and predicted true;
- TN (true negative)—actual is false and predicted false;
- FP (false positive)—actual is false but predicted true;
- FN (false negative)—actual is true but predicted false.
6. Results and Comparisons
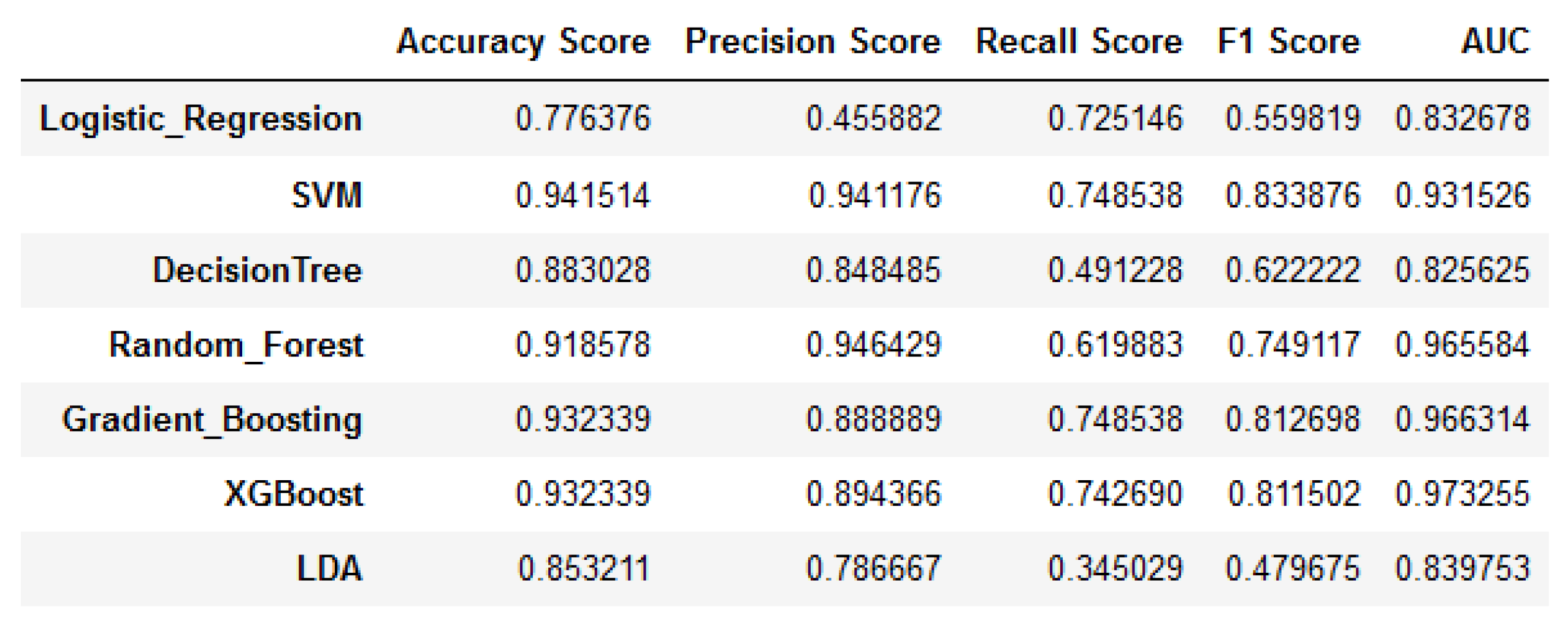
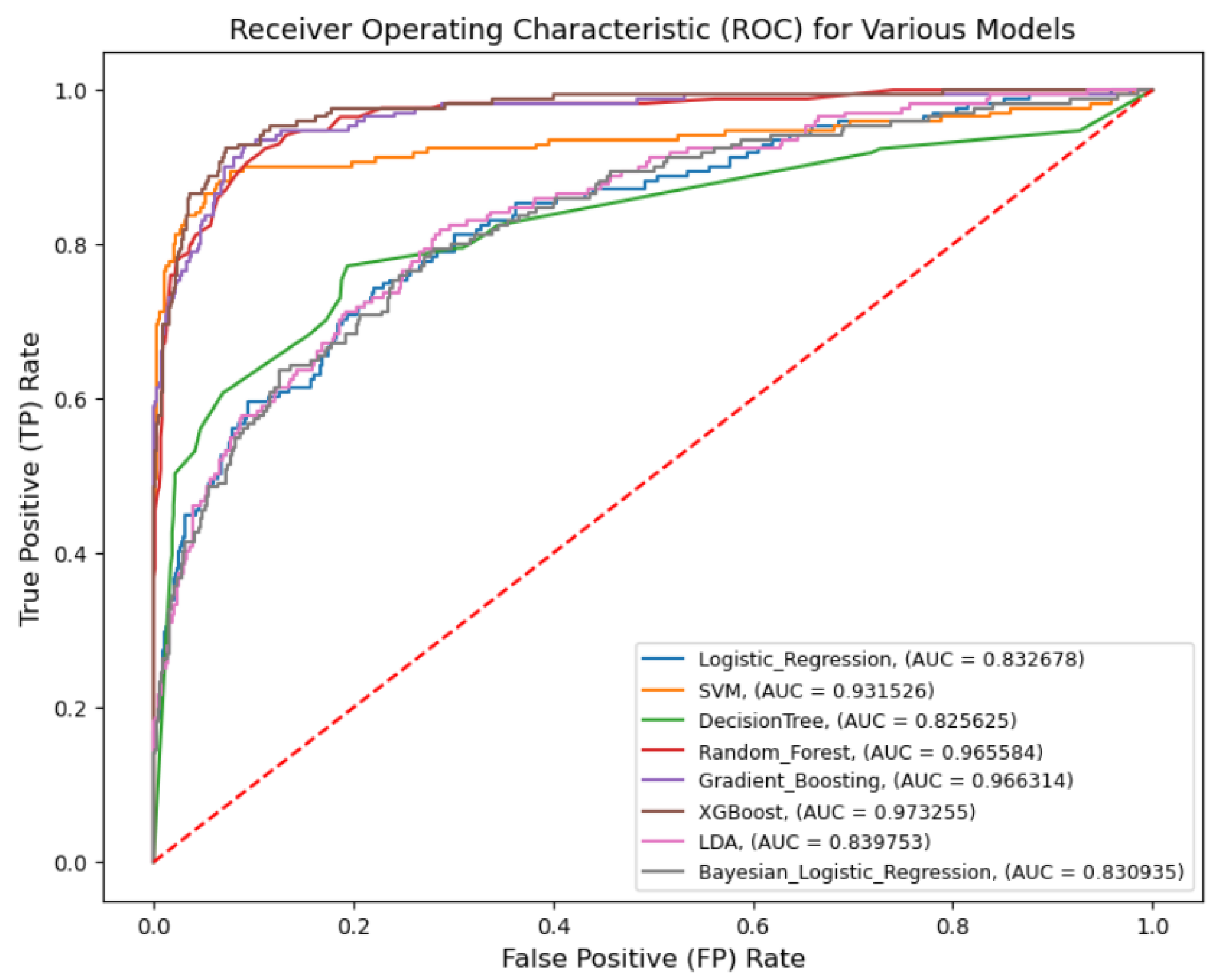
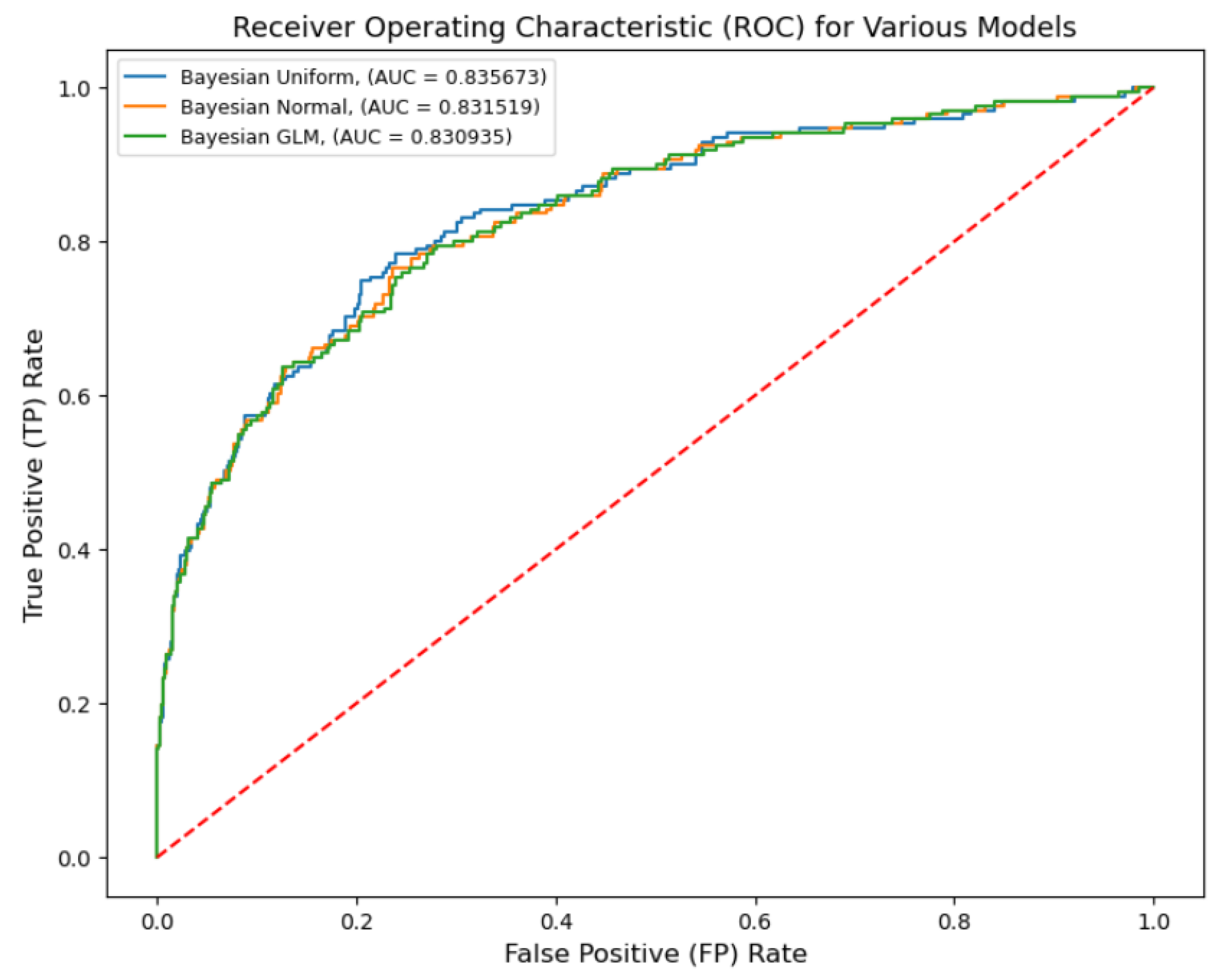
6.1. Classic Logistic Regression, Machine Learning Algorithms, and Bayesian Logistic Regression Model Results and Comparisons
- TP (true positive)—220 versus 221;
- TN (true negative)—2718 versus 2722;
- FP (false positive)—86 versus 82;
- FN (false negative)—463 versus 462.
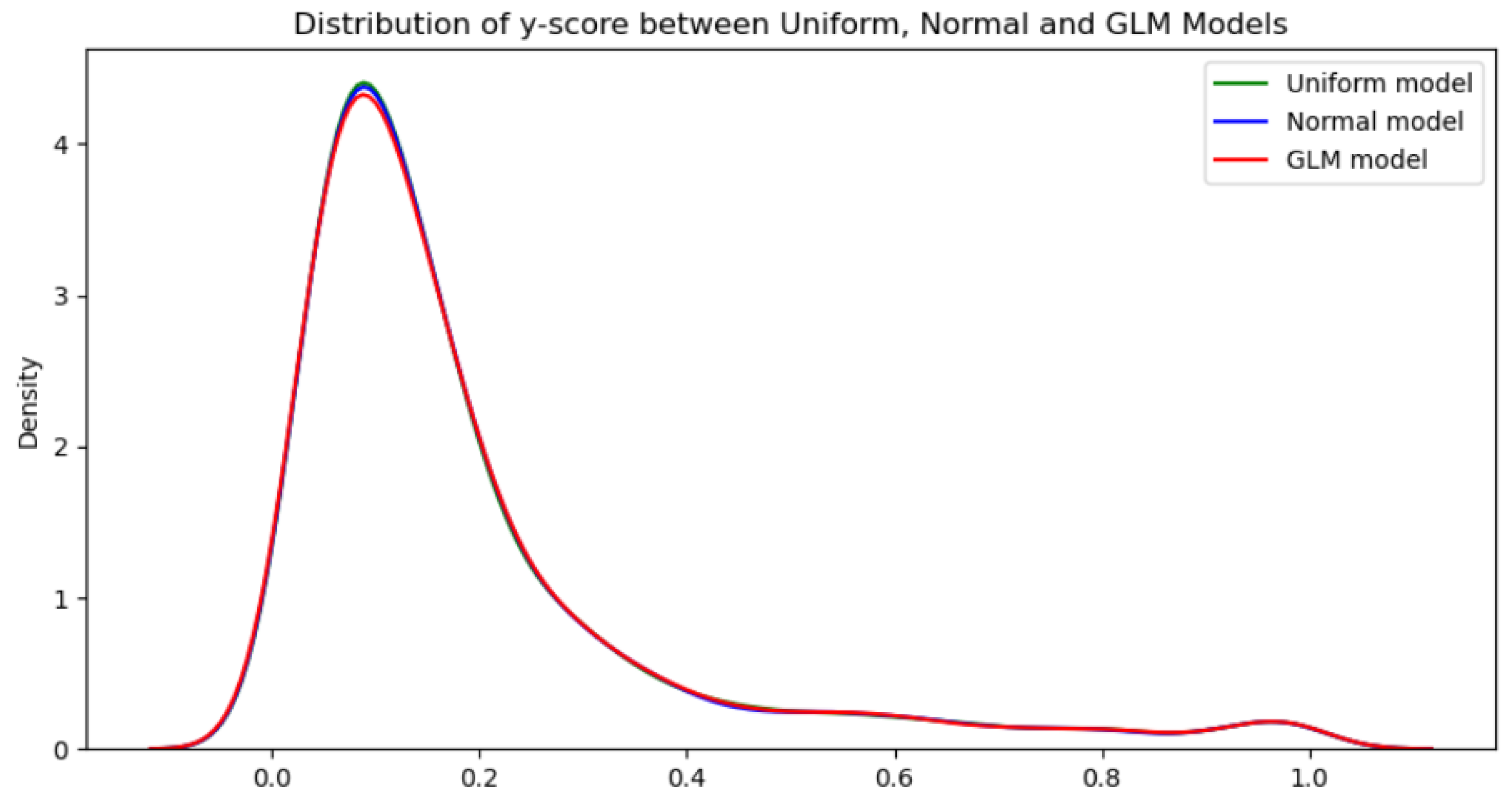
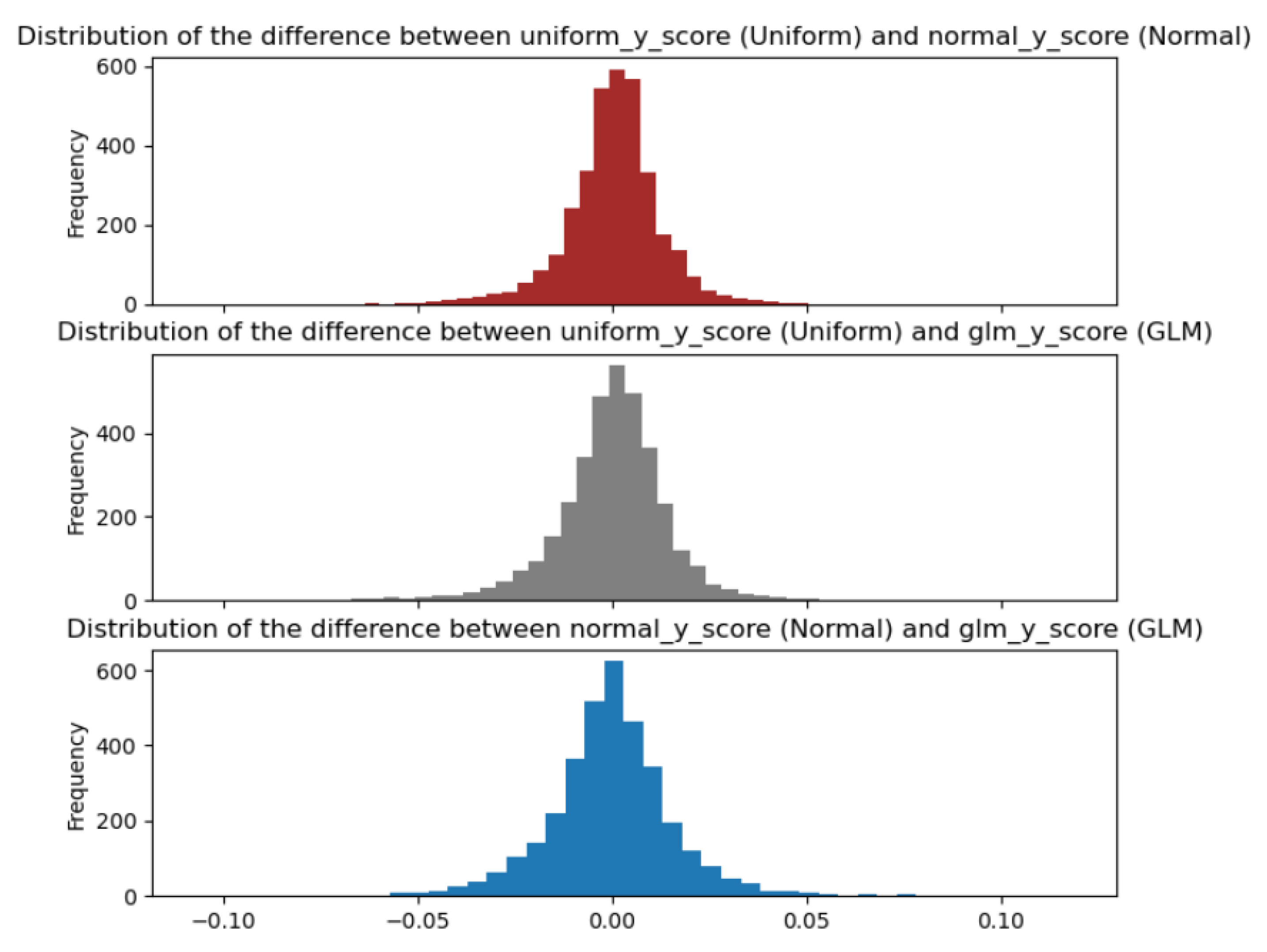
6.2. Bayesian Uniform, Normal, and Built-In GLM Model Results and Comparisons
7. Conclusions
- From the ROC-AUC measurement, classic logistic regression, various machine learning algorithms, and Bayesian logistic regression achieved a similar performance. Both classic and Bayesian logistic regression might not be the ‘best’ performing models, nonetheless, they are easier to interpret in that the logit can be constructed in both models. In the comparison, eXtreme gradient boosting (XGB) achieved the best score.
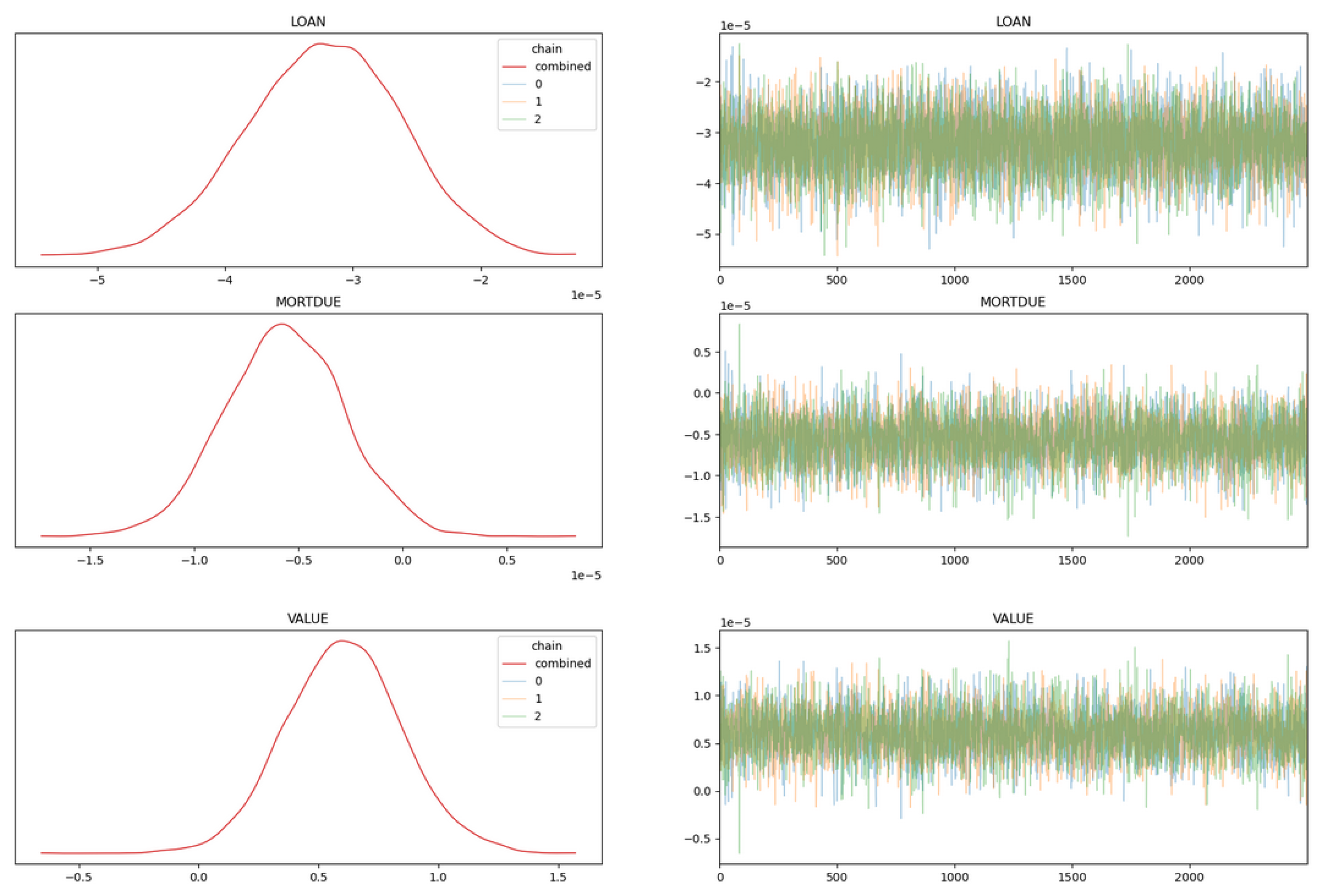
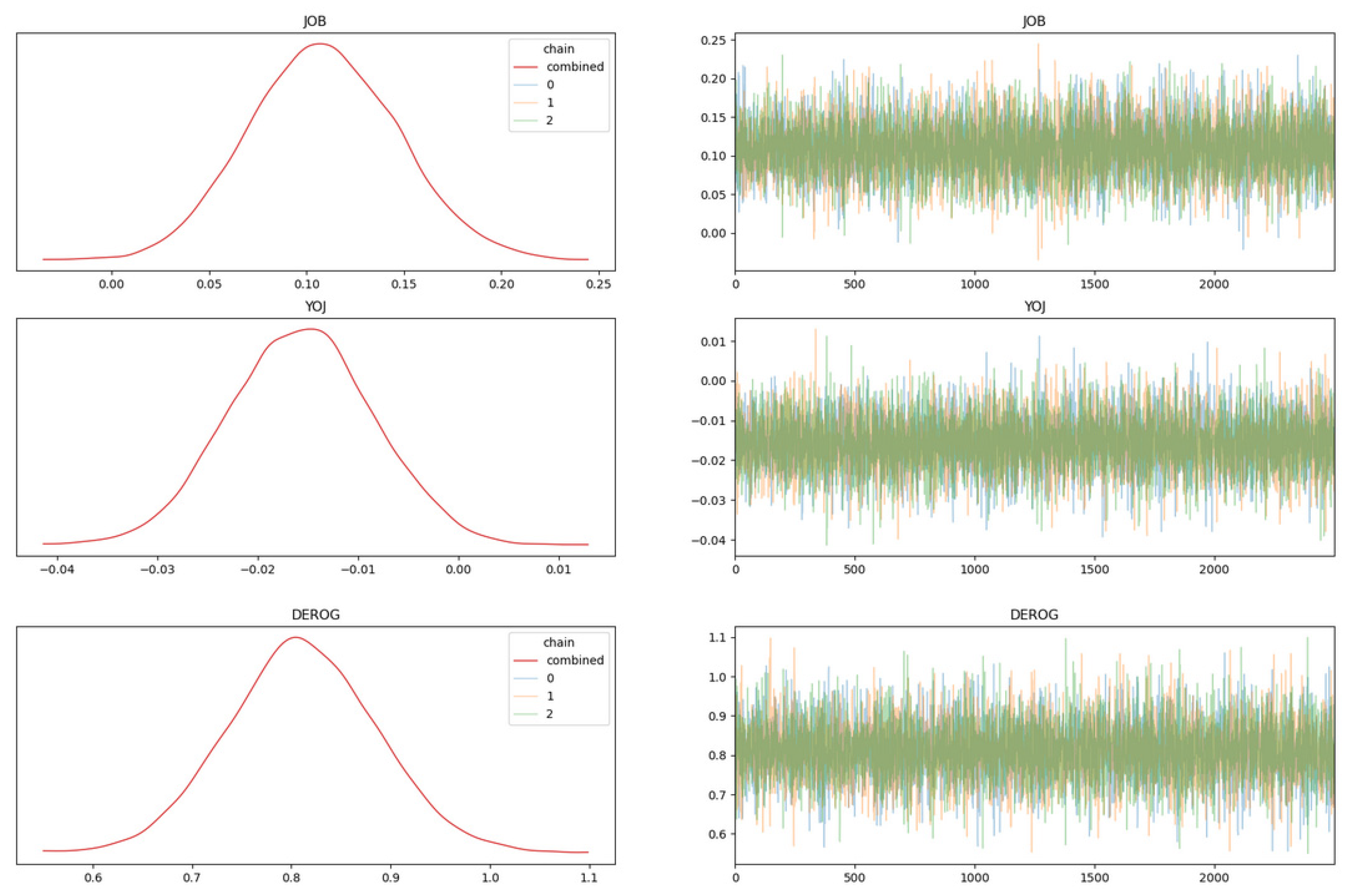
- Uncertainties for variables are clearly displayed and can be quantified for our estimates through various summarisation and graphs provided by Bayesian packages such as PyMC-Arviz. These packages implement the MCMC technique to make posterior distribution sampling tractable.
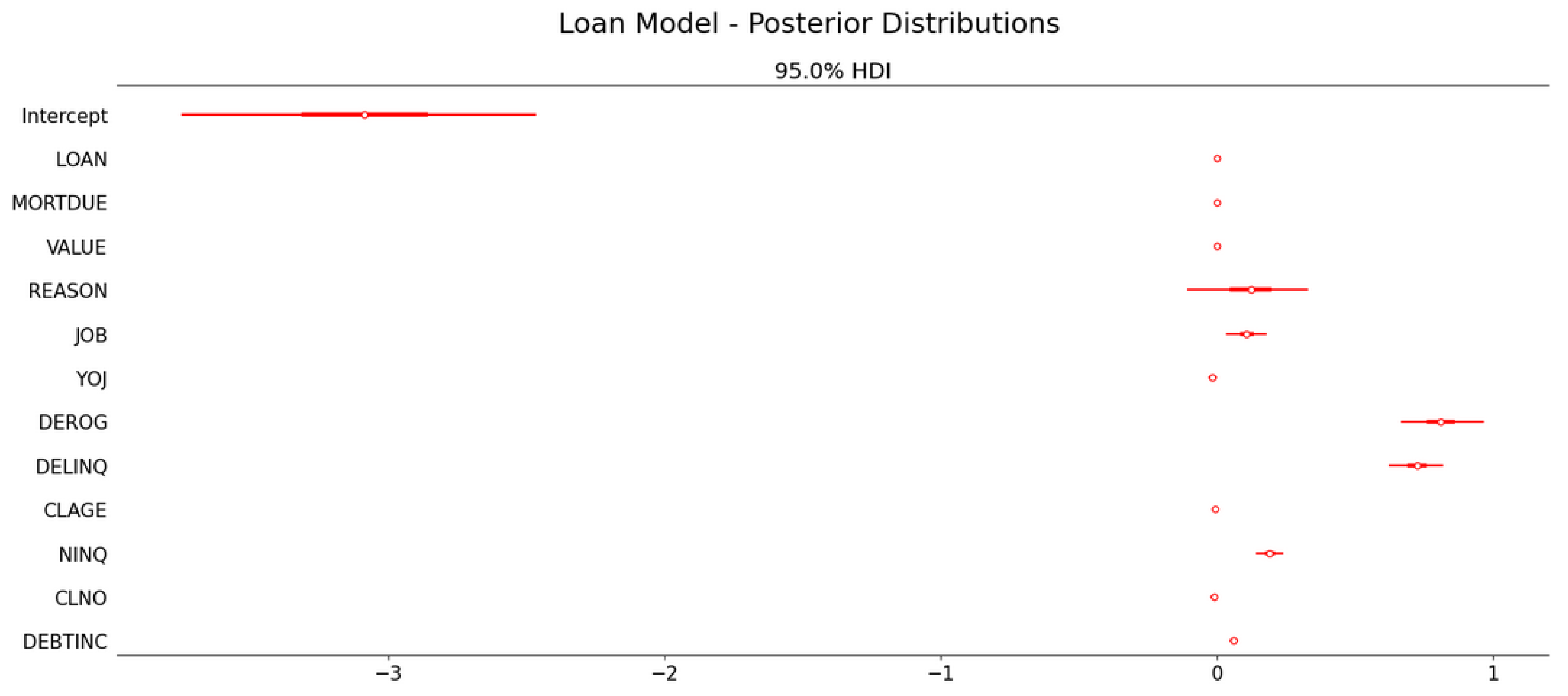
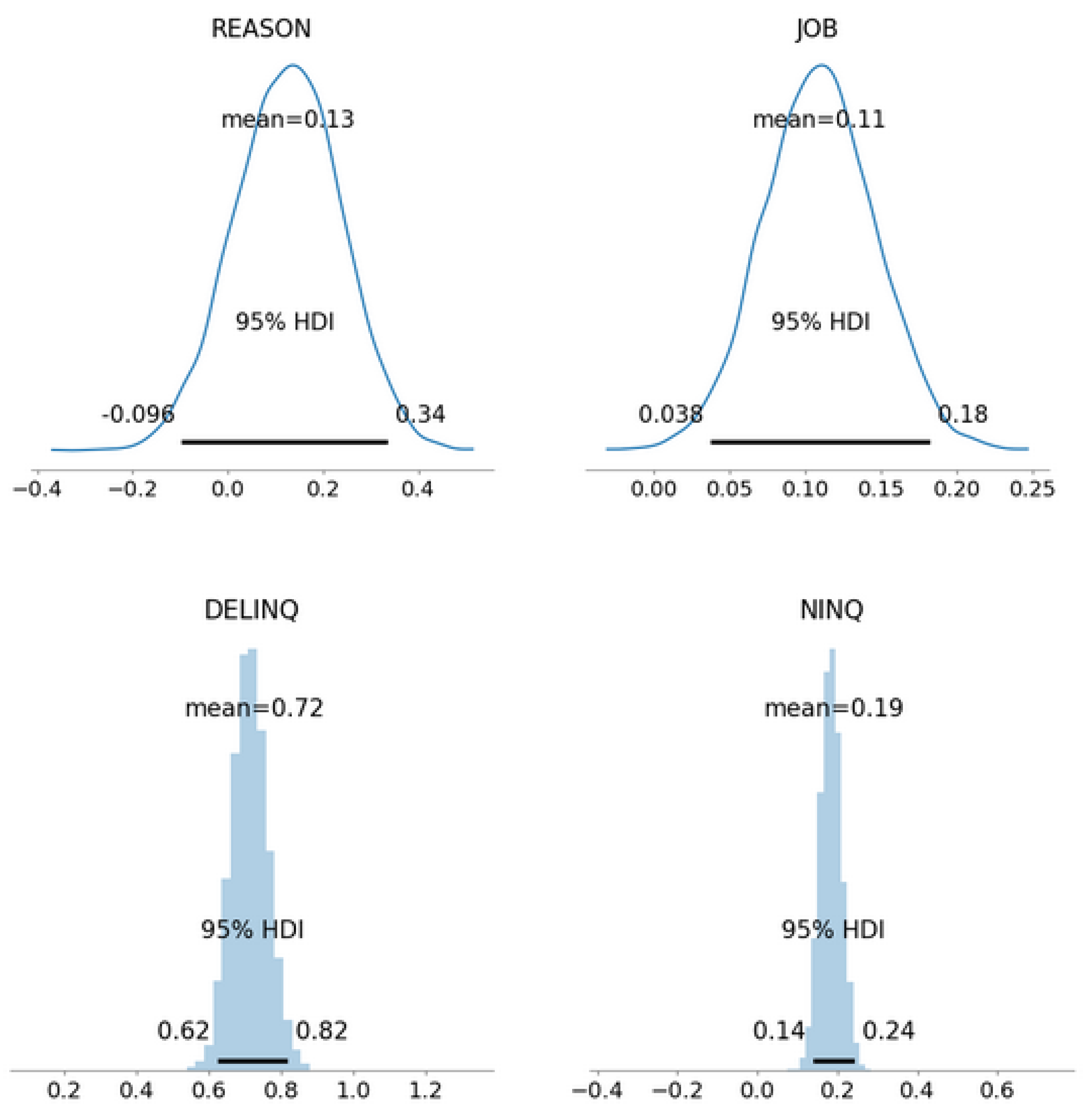
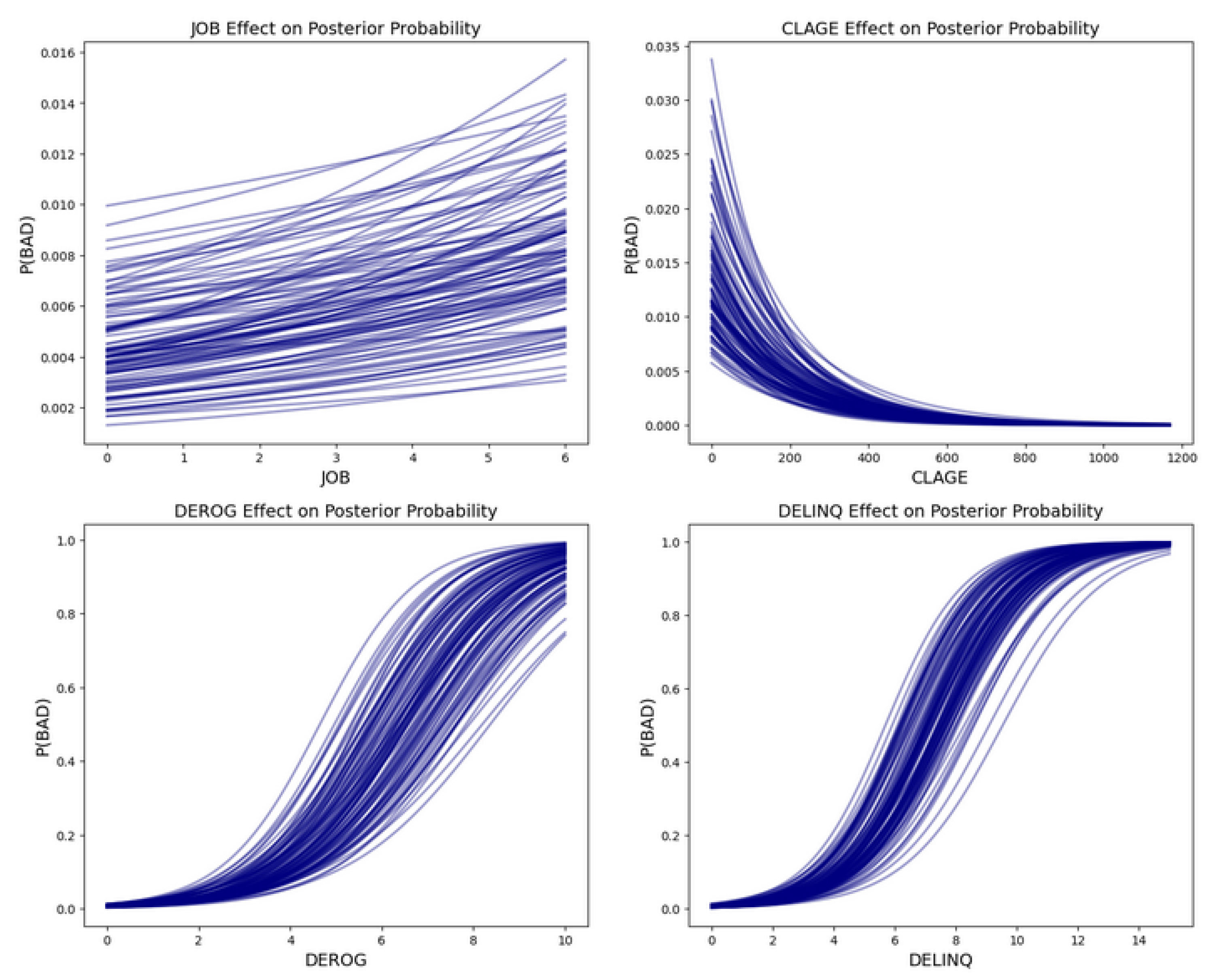
- Bayesian allows models to be interpreted easily and to help discover the relationship between variables and the target variable. For example, the coefficients and percentage effect can be used to assess the importance/influence of the variables toward the models. Additionally, an individual variable effect to the model with a relationship to the target variable can be obtained.
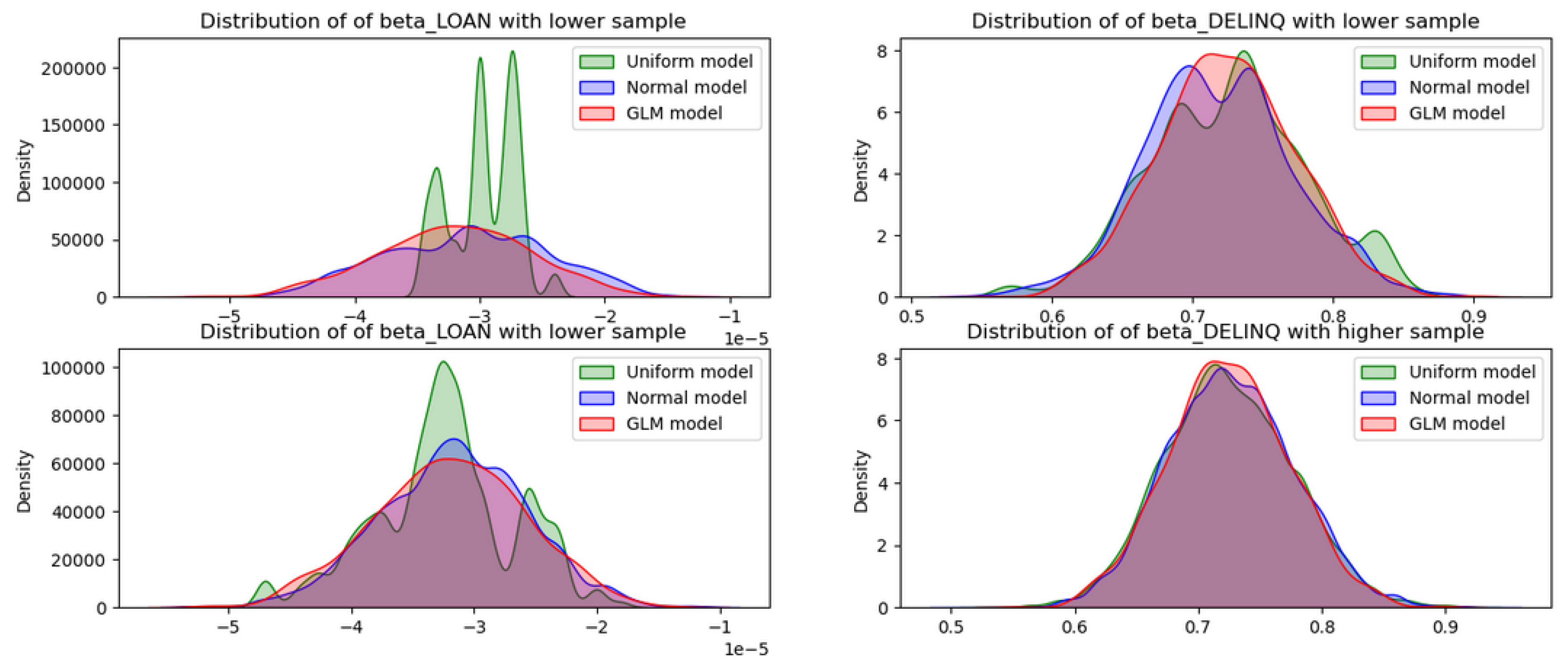
- Subsequently, a test using non-informative priors (uniform, normal, and the built-in GLM methods) for Bayesian created three separate models to prove that they converged relatively quickly. In other words, unless the data provided is highly irrelevant, the models eventually remove the differences in the posterior distribution.
- Informative priors for Bayesian logistic regression—this requires solid and proven knowledge to serve as priors;
- Hierarchical models for Bayesian inference—indeed, one huge advantage of using Bayesian is the ability to perform hierarchical modelling. This is an area that has garnered great interest and detailed research in this area will add to the body of knowledge for Bayesian and its modern implementation.
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Berg, Sigbjørn Atle, Finn R. Førsund, and Eilev S. Jansen. 1992. Malmquist indices of productivity growth during the deregulation of Norwegian banking, 1980–1989. The Scandinavian Journal of Economics 94: S211–28. [Google Scholar] [CrossRef]
- Berger, Allen N., and Robert DeYoung. 1997. Problem loans and cost efficiency in commercial banks. Journal of Banking & Finance 21: 849–70. [Google Scholar]
- Bernardo, José M., and Adrian F. M. Smith. 2009. Bayesian Theory. Chichester: John Wiley & Sons. [Google Scholar]
- Bijak, Katarzyna, and Lyn C. Thomas. 2015. Modelling LGD for unsecured retail loans using Bayesian methods. Journal of the Operational Research Society 66: 342–52. [Google Scholar] [CrossRef] [Green Version]
- Borison, Adam. 2010. How to manage risk (after risk management has failed). In MIT Sloan Management Review. Brighton: Harvard Business Review, vol. 1. [Google Scholar]
- Congdon, Peter. 2007. Bayesian Statistical Modelling, 2nd ed. Hoboken: John Wiley & Sons. [Google Scholar]
- Fornacon-Wood, Isabella, Hitesh Mistry, Corinne Johnson-Hart, Corinne Faivre-Finn, James P. B. O’Connor, and Gareth J. Price. 2022. Understanding the Differences Between Bayesian and Frequentist Statistics. International Journal of Radiation Oncology Biology Physics 112: 1076–82. [Google Scholar] [CrossRef] [PubMed]
- Gelman, Andrew. 2008. Objections to Bayesian statistics. Bayesian Analysis 3: 445–49. [Google Scholar] [CrossRef]
- Gelman, Andrew, Daniel Lee, and Jiqiang Guo. 2015. Stan: A probabilistic programming language for Bayesian inference and optimization. Journal of Educational and Behavioral Statistics 40: 530–43. [Google Scholar] [CrossRef] [Green Version]
- Geyer, Charles J. 2011. Introduction to Markov Chain Monte Carlo. In Steve Brooks. Handbook of Markov Chain Monte Carl. Edited by Andrew Gelman, Galin Jones and Xiao-Li Meng. Boca Raton: Chapman & Hall/CRC Press. [Google Scholar]
- Kéry, Marc, and Michael Schaub. 2011. Bayesian Population Analysis Using WinBUGS: A Hierarchical Perspective. New York: Academic Press. [Google Scholar]
- Koch, Karl-Rudolf, and Karl-Rudolf Koch. 1990. Bayes’ theorem. Bayesian Inference with Geodetic Applications, 4–8. [Google Scholar] [CrossRef]
- Kumar, Ravin, Colin Carroll, Ari Hartikainen, and Osvaldo Martin. 2019. ArviZ a unified library for exploratory analysis of Bayesian models in Python. Journal of Open Source Software 4: 1143. [Google Scholar] [CrossRef]
- Kobayashi, Genya, Yuta Yamauchi, Kazuhiko Kakamu, Yuki Kawakubo, and Shonosuke Sugasawa. 2022. Bayesian approach to Lorenz curve using time series grouped data. Journal of Business & Economic Statistics 40: 897–912. [Google Scholar]
- Kakamu, Kazuhiko, and Haruhisa Nishino. 2019. Bayesian estimation of beta-type distribution parameters based on grouped data. Computational Economics 53: 625–45. [Google Scholar] [CrossRef] [Green Version]
- Lee, Peter M. 2012. Bayesian Statistics: An Introduction. Hoboken: John Wiley & Sons. [Google Scholar]
- Lunn, David J., Andrew Thomas, Nicky Best, and David Spiegelhalter. 2000. WinBUGS-a Bayesian modelling framework: Concepts, structure, and extensibility. Statistics and Computing 10: 325–37. [Google Scholar] [CrossRef]
- Ma, Zhanyu, and Arne Leijon. 2011. Bayesian estimation of beta mixture models with variational inference. IEEE Transactions on Pattern Analysis and Machine Intelligence 33: 2160–73. [Google Scholar] [PubMed]
- Nelli, Fabio. 2018. Python Data Analytics, with Pandas, NumPy, and Matplotlib. Berkeley: Apress. [Google Scholar]
- O’Hagan, Anthony. 1998. Eliciting expert beliefs in substantial practical applications: [Read before The Royal Statistical Society at ameeting on’Elicitation ‘on Wednesday, April 16th, 1997, the President, Professor AFM Smithin the Chair]. Journal of the Royal Statistical Society: Series D (The Statistician) 47: 21–35. [Google Scholar]
- O’Hagan, Anthony, and Jonathan J. Forster. 2004. Kendall’s Advanced Theory of Statistics, Volume 2B: Bayesian Inference. London: Arnold. [Google Scholar]
- Ohtsuka, Yoshihiro, and Kazuhiko Kakamu. 2013. Space-time model versus VAR model: Forecasting electricity demand in Japan. Journal of Forecasting 32: 75–85. [Google Scholar] [CrossRef]
- Pereyra, Marcelo. 2017. Maximum-a-Posteriori Estimation with Bayesian Confidence Regions. SIAM Journal on Imaging Sciences 10: 285–302. [Google Scholar] [CrossRef] [Green Version]
- Smith, Andrew, and Charles Elkan. 2004. A Bayesian network framework for reject inference. In Paper presented at KDD ’04: Proceedings of the tenth ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, Seattle, WA, USA, August 22–25; pp. 286–95. [Google Scholar]
- Tharwat, Alaa. 2021. Classification assessment methods. Applied Computing and Informatics 17: 168–92. [Google Scholar] [CrossRef]
- Turkkan, Noyan, and T. Pham-Gia. 1993. Computation of the highest posterior density interval in Bayesian analysis. Journal of Statistical Computation and Simulation 44: 243–50. [Google Scholar] [CrossRef]
- Wang, Zheqi, Jonathan Crook, and Galina Andreeva. 2020. Reducing estimation risk using a Bayesian posterior distribution approach: Application to stress testing mortgage loan default. European Journal of Operational Research 287: 725–38. [Google Scholar] [CrossRef]
- Zago, Angelo, and Paola Dongili. 2006. Bad loans and efficiency in Italian banks. Dipartimento di Scienze Economiche-Università di Verona, 1–51. [Google Scholar]




















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Total Missing Values | HMEQ Features | ||
|---|---|---|---|
| Feature | Description | Nominal/ Categorical | |
| 0 | BAD | Loan Default: 1 = Client defaulted on loan, 0 = Loan repaid | Nominal |
| 0 | LOAN | Amount of the loan request | Nominal |
| 518 | MORTDUE | Amount due on existing mortgage | Nominal |
| 112 | VALUE | Value of current property | Nominal |
| 252 | REASON | DebtCon = Debt consolidation, HomeImp = Home improvement | Categorical |
| 279 | JOB | Job of the applicant: 6 occupational categories | Categorical |
| 515 | YOJ | Years at present job | Nominal |
| 708 | DEROG | Number of major derogatory reports | Nominal |
| 580 | DELINQ | Number of delinquent credit lines | Nominal |
| 308 | CLAGE | Age of oldest trade line in month | Nominal |
| 510 | NINQ | Number of recent credit lines | Nominal |
| 222 | CLNO | Number of credit lines | Nominal |
| 1267 | DEBTINC | Debt-to-income ratio | Nominal |
| Feature Pre-Processing | |
|---|---|
| Pre-Processing | Formula |
| Unprocessed | |
| Normalisation | |
| Standardisation | |
| Performance Metrics | |
|---|---|
| Accuracy Measurement | Formula |
| Accuracy (fraction of accurate prediction from the whole sample) | |
| Precision (measures correctness in true prediction) | |
| Recall/Sensitivity (measures actual observations that are predicted correctly) | |
| F1 (Harmonic mean for precision and recall) | |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Tham, A.W.; Kakamu, K.; Liu, S. Bayesian Statistics for Loan Default. J. Risk Financial Manag. 2023, 16, 203. https://doi.org/10.3390/jrfm16030203
Tham AW, Kakamu K, Liu S. Bayesian Statistics for Loan Default. Journal of Risk and Financial Management. 2023; 16(3):203. https://doi.org/10.3390/jrfm16030203
Chicago/Turabian StyleTham, Allan W., Kazuhiko Kakamu, and Shuangzhe Liu. 2023. "Bayesian Statistics for Loan Default" Journal of Risk and Financial Management 16, no. 3: 203. https://doi.org/10.3390/jrfm16030203
APA StyleTham, A. W., Kakamu, K., & Liu, S. (2023). Bayesian Statistics for Loan Default. Journal of Risk and Financial Management, 16(3), 203. https://doi.org/10.3390/jrfm16030203