
Enhancing Financial Market Analysis and Prediction with Emotion Corpora and News Co-Occurrence Network


Abstract
:1. Introduction
2. Related Work
3. Materials and Methods
3.1. Emotional Annotation Algorithm

- Logical Model 1—Improving the emotional algorithm.
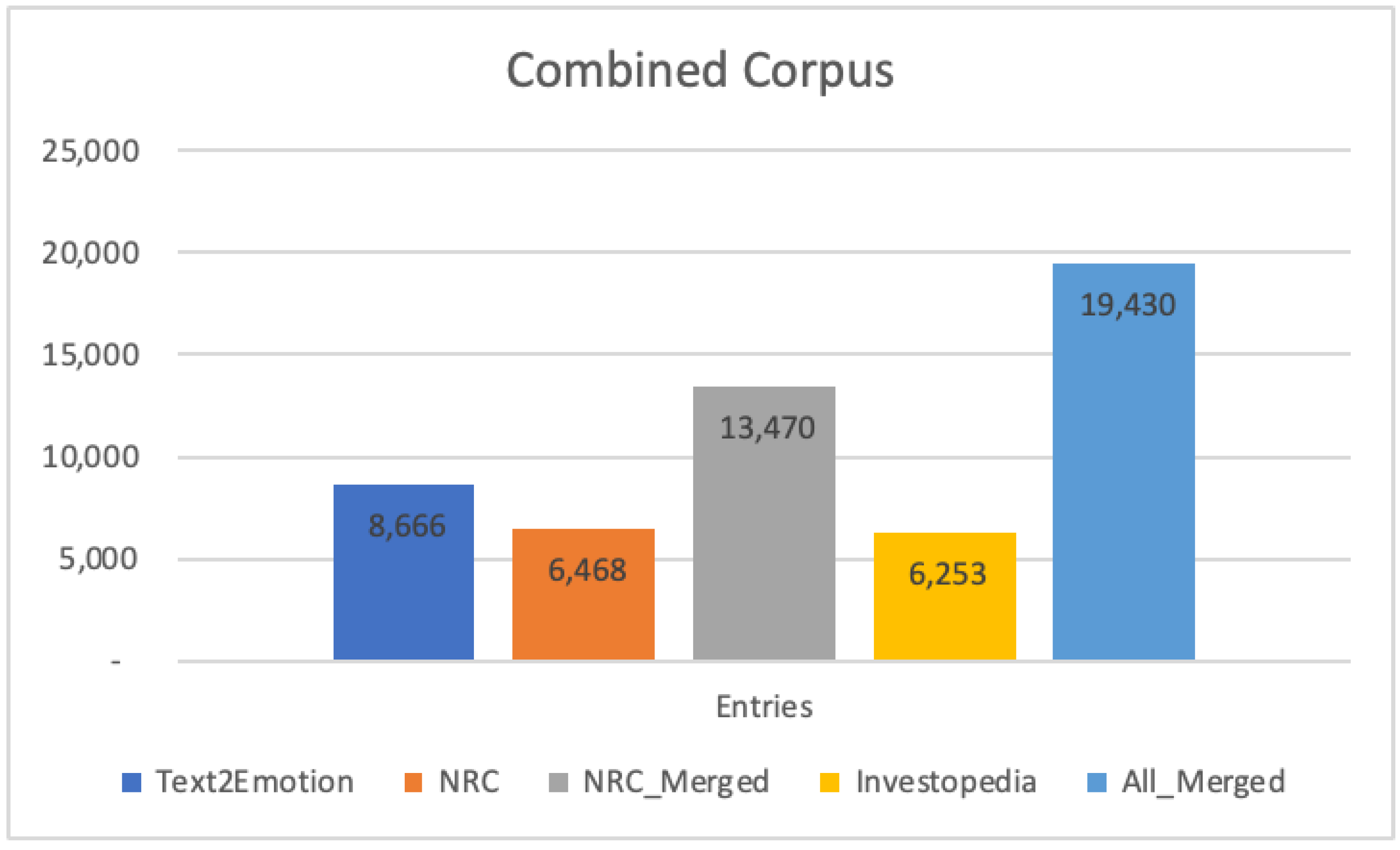
- Corpus Datasets
- NRC EmoLex: https://saifmohammad.com/WebPages/NRC-Emotion-Lexicon.htm (accessed on 24 April 2022)
- Text2Emotion: https://github.com/aman2656/text2emotion-library (accessed on 24 April 2022)
- We added sentiment checks leveraging the Natural Language Toolkit (NLTK) (Bird et al. 2009), which uses certain rules to incorporate the impact of surrounding text on perceived sentiment to slightly adjust those emotions that aligns to sentiment. The algorithm, called VADER (valence aware dictionary and sentiment reasoner) (Hutto and Gilbert 2014), is a lexicon-based sentiment analysis tool that uses a rule-based approach to determine the sentiment of a piece of text. It uses a combination of sentiment lexicons, grammatical rules, and syntactical patterns to assign a sentiment score to the text. The formula for calculating the sentiment score using VADER can be represented as:Sentiment score = (WPS ∗ Valence) + (SPS ∗ Intensity) + EmoticonScore
- As shown in the algorithm, additional data cleansing (Table 1) was also added to the Text2Emotion library to support better matching of terms, leveraging lemmatization over stemming a more modern approach and leveraging NLTKs updated stop words vocabulary all with the intent of achieving better term matching with the larger corpus.
- In analyzing articles, we found that using just the standard aggregate of individual words affect results in some articles being classified incorrectly. This led to the intuition of making just slight adjustments based on the overall article sentiment. If we find a positive sentiment and the emotion is positive (trust, surprise, joy, or anticipation) then the calculation of the word (how much that word contributes to the overall emotion) is slightly adjusted by an extra 0.5. The negative sentiment similarly adjusts the negative emotions (fear, anger, sadness, or disgust). This basically provides an emphasis on the emotion based on polarity of the overall article being analyzed. We tried larger values (adjusting by 1) and smaller values (adjusting by 0.25) that showed little difference before arriving at 0.5. This adjustment created stronger separation of emotions.
| Algorithm 1 Obtain the emotion vector for the news article |
| Algorithm: get_emotion |
| Input: News Article Output: Dictionary ‘emotions’ |
| 1. Calculate Sentiment score for the article 2. Clean input (remove stopwords, lemmatization, remove shortcuts, expand contradiction) 3. Create word to emotions lexicon of financial phrases and NRC EmoLex and Text2Emotion word to emotion mappings and store the data in the dictionary ‘data’ 4. Initialize an Emotion vector ‘emotions’ with keys “fear”, “anger”, “trust”, “surprise”, “sadness”, “disgust”, “joy”, and “anticipation”, all set to 0 5. For each word in the ‘Article’, do the following: a. Update Emotion vectors based on emotion in word to emotion lexicon. 6. Normalize emotion vector 7. Return ‘emotion vector’ |

- Logical Model 2—Improved Emotion algorithm with financial phrases
- Investopedia: https://www.investopedia.com/financial-term-dictionary-4769738 (accessed on 20 June 2022)
| Algorithm 2 Obtain the top emotion or mixed emotion from Plutchik emotion mixing |
| Algorithm: get_mixed_emotion Input: News Article Output: Top Emotion (or Mixed Emotion) |
| 1. Call get_emotion to get normalized vector of emotions for the article 2. Sort ‘emotions’ vector by descending value 3. If the sum of the top two values is greater than 0.5 and the difference between the values of the top two emotions is within 0.15, do the following: Return the emotion from Table 2 4. Otherwise, return the top emotion from the vector |
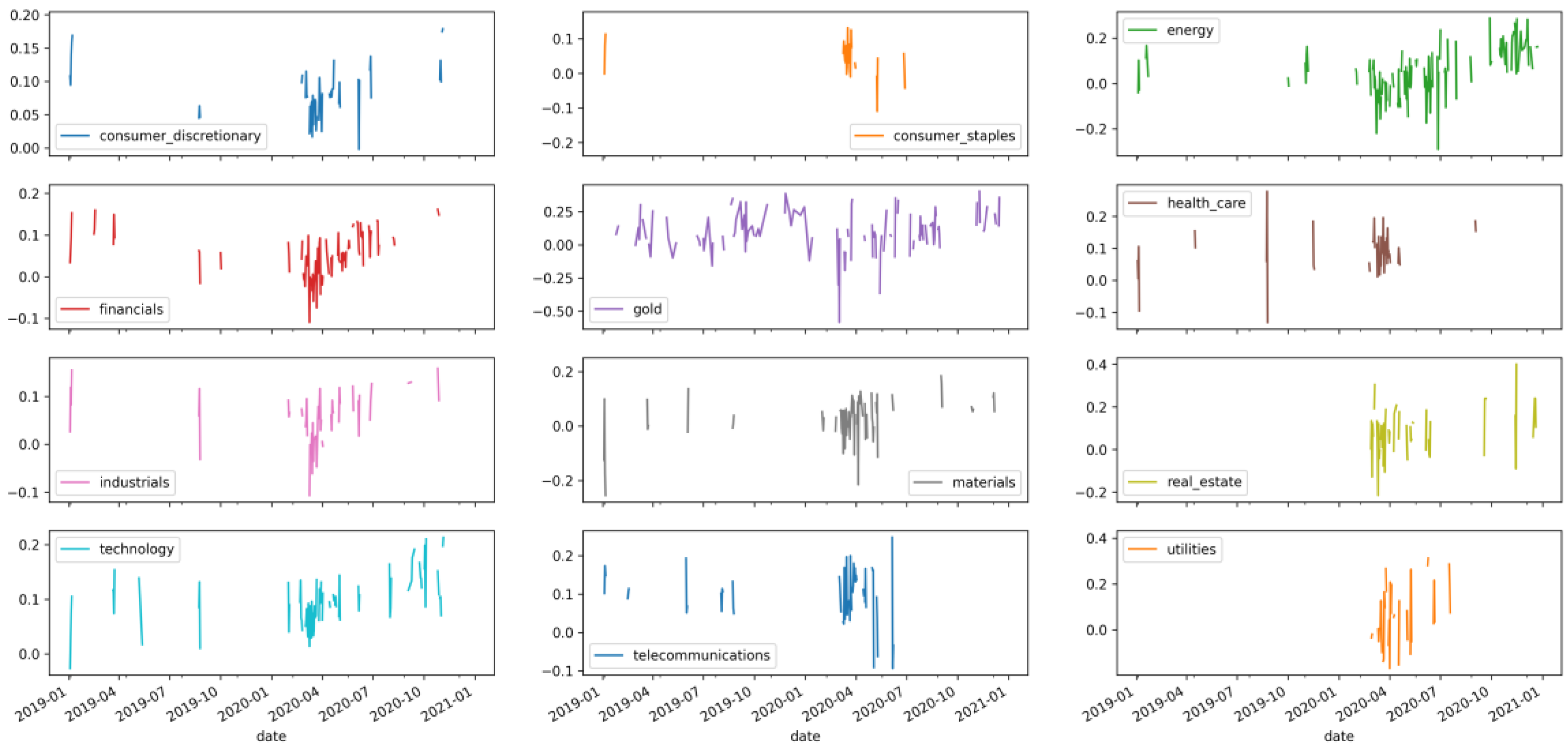
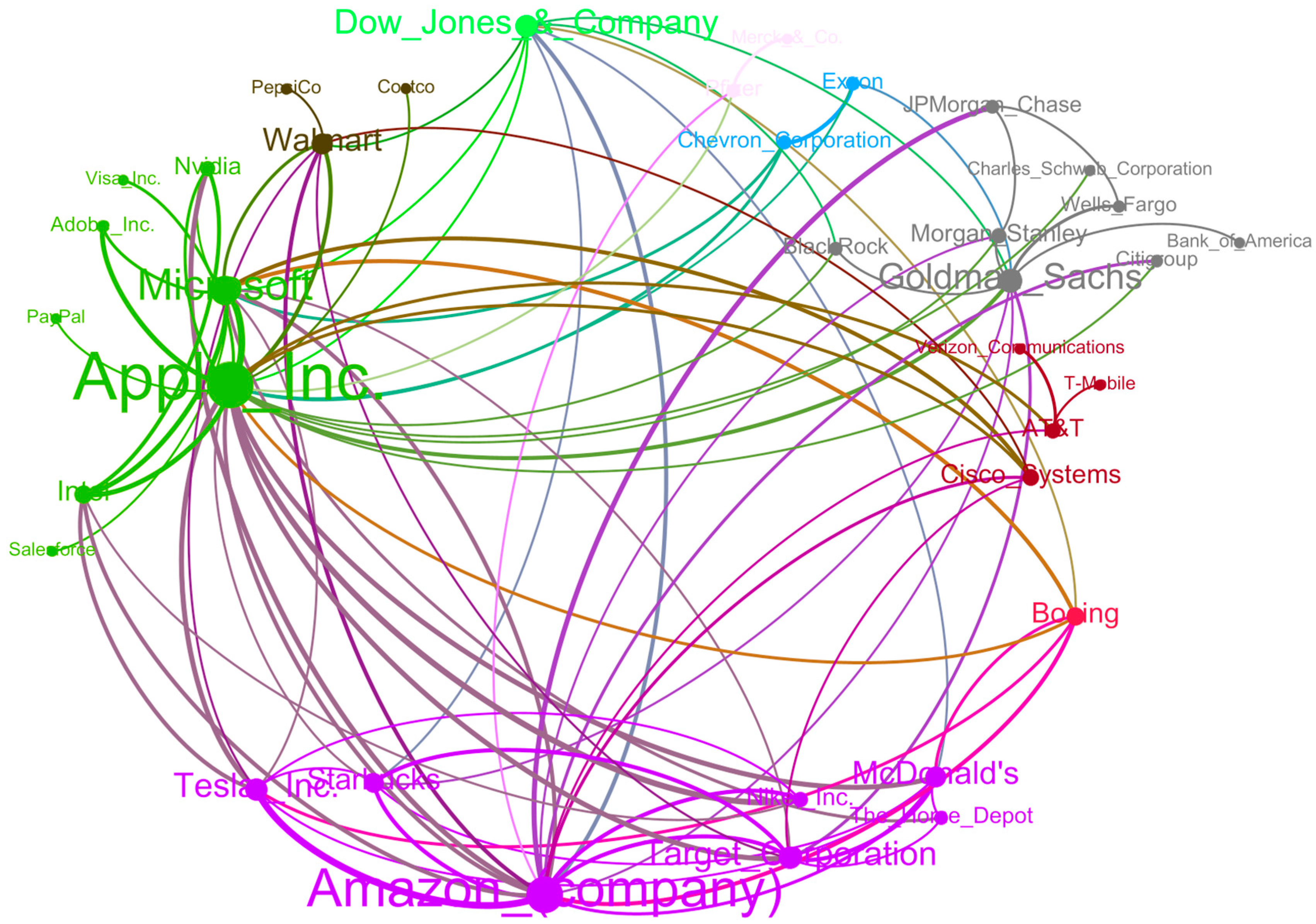
3.2. News Co-Occurrence Network

- Logical Model 3—Generating sentiment across all companies and sectors.

- Logical Model 4—Financial news co-occurrence graph
| Algorithm 3 Create the co-occurrence new network for company pairs |
| Algorithm: Co-occurrence Network Construction |
| Input: Dataset including date, company, and emotion for each news article for that day Output: Co-occurrence graph network constructed from the emotion data (pair of companies that share the same emotion on the same day) |
| 1. Generate Edges foreach emotion in emotions: group = from dataset get companies with the same emotion by date (group by date, emotion) for each row in group Set edges = Get all combination of companies with the same emotion Foreach edge in edges If edge not in hash set edge to empty {} edge_hash[edge][emo] = if first time emotion seen for edge, initialize to zero edge_hash[edge][emo] += 1 2. Generate Nodes with all Companies Names Graph.add_nodes_from(list of companies) 3. Keep edge weights greater than 5 Foreach key in edges If weight > 5 Graph.Add(key) |
4. Results and Discussion
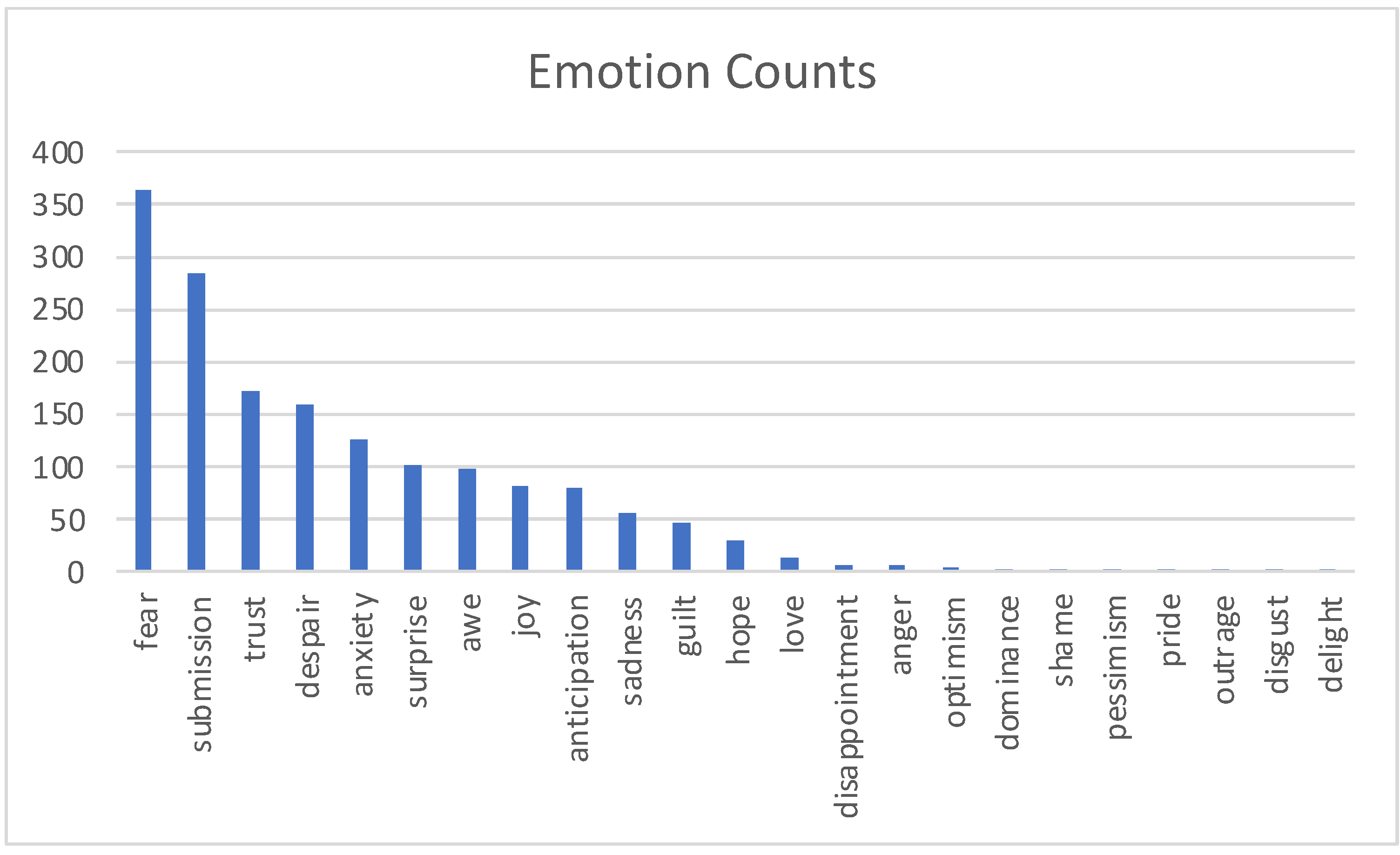
- Trust (vs. happy)—Twelve financial phrases differ (consumer goods, finance charge, Fortune 100, Fortune 500, free carrier, income elasticity of demand, inferior goods, legal tender, normal good, orange book, virtual good, Westpac consumer confidence index); from a reader’s perspective, the articles do not read happy, these read as the definition of financial terms.
- Surprise (vs. happy)—Three financial phrases differ (Giffen good, one-time charge, volatility smile); from a reader’s perspective, the articles do read more surprise (Giffen good being a condition that does not follow standard economic theory, one-time charges being a surprise to many, and volatility smile being a change in volatility as a surprise in economic movement)
- Sadness, fear (vs. happy) (representing mixed emotion despair)—One financial phrase differs (tax evasion); the reader would also concur that this does not represent happy and is more appropriately defined as despair.
- Anticipation (vs. happy)—Two financial phrases differ (public good, rival good); these articles do read more anticipation in positive outcomes (a public good being a commodity or service provided without profit).
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
Appendix A
Ethical Considerations
- The lexicons and corpus provide a mathematical representation of the aggregate emotional tone of a body of text; it should not then follow that the reader experiences the impact as noted; we draw correlation because articles hold the same language and tone and therefore are similar.
- The analysis and observation drawn in this paper are based on aggregate news articles across multiple sources in the US and Europe and we do not draw any conclusions based on individuals’ perception of a particular news source or any one individual’s emotional experience to a news article.
- In this body of work, although conveying information about the perceived emotional representation of an article, accurately determining the emotional state of the writer or even the reader would require additional information and as such should not be used to represent the true emotional state of the writer or reader.
- We do not recommend using this analysis to draw inferences about an individual or even an individual news source, unless 1. it is exercised with caution, 2. the news and individuals consent to the analysis, and 3. an expert in psychology or clinical study is included.
Appendix B

{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Sector | Company |
|---|---|
| Energy | Exxon, Chevron Corporation, Conoco, EOG Resources, Schlumberger, Marathon Petroleum, Pioneer Natural Resources, Phillips 66, Kinder Morgan, Williams Companies |
| Gold | Newmont Mining Corporation, Barrick Gold, Franco-Nevada, Wheaton Precious Metals Corporation, Newcrest Mining, Agnico Eagle Mines Limited, Kirkland Lake Gold, Northern Star Resources, Kinross Gold, Gold Fields |
| Materials | The Linde Group, Sherwin-Williams, Air Products & Chemicals, Freeport-McMoRan, Ecolab, Newmont, DuPont, Dow Jones & Company, PPG Industries, International Flavors & Fragrances |
| Industrials | UnitedHealth Group, Goldman Sachs, The Home Depot, Microsoft, Salesforce, McDonald’s, Honeywell, Visa Inc., Amgen, Boeing |
| Consumer discretionary | Amazon (company), Tesla, Inc., The Home Depot, Nike, Inc., McDonald’s, Lowe’s, Starbucks, Target Corporation, Booking Holdings, TJX Companies |
| Consumer staples | Procter & Gamble, The Coca-Cola Company, PepsiCo, Walmart, Costco, Philip Morris International, Mondelez International, Altria, Estée Lauder Companies, Colgate-Palmolive |
| Healthcare | Johnson & Johnson, UnitedHealth Group, Pfizer, Abbott Laboratories, AbbVie Inc., Thermo Fisher Scientific, Merck & Co., Eli Lilly and Company, Danaher Corporation, Medtronic |
| financials | Berkshire Hathaway, JPMorgan Chase, Bank of America, Wells Fargo, Citigroup, Morgan Stanley, Goldman Sachs, BlackRock, Charles Schwab Corporation, American Express |
| Technology | Apple Inc., Microsoft, Nvidia, Visa Inc., PayPal, Mastercard, Adobe Inc., Intel, Salesforce, Cisco Systems |
| Telecommunications | Cisco Systems, Verizon Communications, Garmin, Motorola Solutions, Arista Networks, AT&T, T-Mobile, Lumen Technologies, F5 Networks, Liberty Global |
| Utilities | NextEra Energy, Duke Energy, Southern Company, Dominion Energy, Exelon, American Electric Power, Sempra Energy, Xcel Energy, American Water Works, Public Service Enterprise Group |
| Real Estate | Realty Income Corporation, American Tower, Prologis, Crown Castle International Corp., Equinix, Public Storage, Digital Realty, Simon Property Group, SBA Communications, Welltower |
References
- Aslam, Naila, Furqan Rustam, Ernesto Lee, Patrick Bernard Washington, and Imran Ashraf. 2022. Sentiment analysis and emotion detection on cryptocurrency related tweets using ensemble LSTM-GRU model. IEEE Access 10: 39313–24. [Google Scholar] [CrossRef]
- Bird, Steven, Ewan Klein, and Edward Loper. 2009. Natural Language Processing with Python. Sebastopol: O’Reilly Media Inc. [Google Scholar]
- Dhar, Suparna, and Indranil Bose. 2020. Emotions in Twitter communication and stock prices of firms: The impact of Covid-19 pandemic. Decision 47: 385–99. [Google Scholar] [CrossRef]
- 2022. Volatility in Perspective [PDF Document]. Available online: https://www.crestmontresearch.com/docs/Stock-Volatility-Perspective.pdf (accessed on 11 October 2022).
- El-Qadi, Ayoub, Maria Trocan, Thomas Frossard, and Natalia Díaz-Rodríguez. 2022. Credit Risk Scoring Forecasting Using a Time Series Approach. Physical Sciences Forum 5: 16. [Google Scholar] [CrossRef]
- Gupta, Aman, Amey Band, Shivam Sharma, and Karan Bilakhiya. 2021. text2emotion-library [Computer Software]. Available online: https://github.com/aman2656/text2emotion-library (accessed on 24 April 2022).
- Horcher, Karen A. 2011. Essentials of Financial Risk Management. New York: John Wiley & Sons. [Google Scholar]
- Huang, Martin. 2016. Time Series Analysis for Risk Management in Finance: A Review. Available online: http://www.columbia.edu/~mh2078/QRM/TimeSeries_RiskManagement.pdf (accessed on 6 March 2023).
- Hutto, Clayton, and Eric Gilbert. 2014. VADER: A parsimonious rule-based model for sentiment analysis of social media text. Paper presented at the Eighth International Conference on Weblogs and Social Media (ICWSM-14), Ann Arbor, MI, USA, June 1–4. [Google Scholar]
- Ibbotson, Roger G., and Paul D. Kaplan. 2000. Does asset allocation policy explain 40, 90, or 100 percent of performance? Financial Analysts Journal 56: 26–33. [Google Scholar] [CrossRef] [Green Version]
- Lu, Shan, Chenhui Liu, and Zhensong Chen. 2021. Predicting stock market crisis via market indicators and mixed frequency investor sentiments. Expert Systems with Applications 186: 115844. [Google Scholar] [CrossRef]
- Mazzolli, R., L. Cusick, L. Marcolin, and J. Saperstein. 2023. Learn about Communication Compliance. Microsoft. Available online: https://learn.microsoft.com/en-us/microsoft-365/compliance/communication-compliance?view=o365-worldwide (accessed on 9 January 2023).
- Plutchik, Robert. 2001. The Nature of Emotions: Human emotions have deep evolutionary roots, a fact that may explain their complexity and provide tools for clinical practice. American Scientist 89: 344–50. [Google Scholar] [CrossRef]
- Ramírez-Sáyago, Ernesto. 2020. Sentiment Analysis from Twitter Data Regarding the COVID-19 Pandemic. Available online: https://www.researchgate.net/publication/346453096_Sentiment_Analysis_from_Twitter_Data_Regarding_the_COVID-19_Pandemic (accessed on 3 August 2022).
- Shapiro, Adam Hale, Moritz Sudhof, and Daniel Wilson. 2020. Measuring News Sentiment. Federal Reserve Bank of San Francisco, Working Paper Series, (01-49). Available online: https://www.frbsf.org/economic-research/publications/working-papers/2017/01/ (accessed on 12 October 2022).
- Tang, Yi, Yilu Zhou, and Marshall Hong. 2019. News Co-Occurrences, Stock Return Correlations, and Portfolio Construction Implications. Journal of Risk and Financial Management 12: 45. [Google Scholar] [CrossRef] [Green Version]
- Vishnubhotla, Krishnapriya, and Saif M. Mohammad. 2022. Tweet emotion dynamics: Emotion word usage in tweets from US and Canada. arXiv arXiv:2204.04862. Available online: https://arxiv.org/abs/2204.04862 (accessed on 3 August 2022).
- Wan, Xingchen, Jie Yang, Slavi Marinov, Jan-Peter Calliess, Stefan Zohren, and Xiaowen Dong. 2021. Sentiment correlation in financial news networks and associated market movements. Scientific Reports 11: 3062. [Google Scholar] [CrossRef] [PubMed]




| Data Cleansing | Action | Description |
|---|---|---|
| standardize_accented_chars | Added | Standardize accent characters |
| expand_contractions | Upgraded | Expand language contractions |
| removing_not | Kept | No changes |
| lemmatization | Upgraded | Changed from stemming to lemmatization |
| removing_stopwords | Upgraded | Upgraded to NLTK to remove stopwords |
| removing_shortcuts | Kept | Removed emojis and shortcuts |
| Mixed Emotion | Top 2 Emotions | Mixed Emotion | Top 2 Emotions |
|---|---|---|---|
| Love | Joy + trust | Remorse | Sadness + disgust |
| Guilt | Joy + fear | Envy | Sadness + anger |
| Delight | Joy + surprise | Pessimism | Sadness + anticipation |
| Submission | Trust + fear | Contempt | Disgust + anger |
| Curiosity | Trust + surprise | Cynicism | Disgust + anticipation |
| Sentimentality | Trust + sadness | Morbidity | Disgust + joy |
| Awe | Fear + surprise | Aggression | Anger + anticipation |
| Despair | Fear + sadness | Pride | Anger + joy |
| Shame | Fear + disgust | Dominance | Anger + trust |
| Disappointment | Surprise + sadness | Optimism | Anticipation + joy |
| Unbelief | Surprise + disgust | Hope | Anticipation + trust |
| Outrage | Surprise + anger | Anxiety | Anticipation + fear |
| ETF | Sector | Companies | Articles |
|---|---|---|---|
| XLE | Energy | Top 10 by holdings | 8671 |
| GDX | Gold miners | Top 10 by holdings | 1514 |
| XLB | Materials | Top 10 by holdings | 25,526 |
| DIA | Industrials | Top 10 by holdings | 78,215 |
| XLY | Consumer discretionary | Top 10 by holdings | 129,685 |
| XLP | Consumer staples | Top 10 by holdings | 36,753 |
| XLV | Health care | Top 10 by holdings | 28,607 |
| XLF | Financials | Top 10 by holdings | 71,310 |
| XLK | Technology | Top 10 by holdings | 109,429 |
| IYZ | Telecommunication | Top 10 by holdings | 22,499 |
| XLU | Utilities | Top 10 by holdings | 2874 |
| VNQ | Real estate | Top 10 by holdings | 1890 |
| 516,973 articles |
| Sector | Correlation | Correlation | Correlation | Correlation | Correlation |
|---|---|---|---|---|---|
| Cons. disc. | 1 | 0.55 | 0.61 | 0.58 | 0.56 |
| Cons. stap. | 0.55 | 1 | 0.5 | 0.38 | 0.44 |
| Financials | 0.61 | 0.5 | 1 | 0.63 | 0.56 |
| Industrials | 0.58 | 0.38 | 0.63 | 1 | 0.57 |
| Technology | 0.56 | 0.44 | 0.56 | 0.57 | 1 |
| Cons. disc. | Cons. stap. | Financials | Industrials | Technology |
| Company Pair 1 | Company Pair 2 |
|---|---|
| Target (consumer discretionary) | Apple (technology) |
| Tesla (consumer discretionary) | Apple (technology) |
| Amazon (consumer discretionary) | Nvidia (technology) |
| Amazon (consumer discretionary) | JP Morgan (financials) |
| Walmart (consumer staples) | Apple (technology) |
| McDonalds (consumer discretionary) | Apple (technology) |
| Goldman Sachs (financials) | Target (consumer discretionary) |
| Amazon (consumer discretionary) | Citigroup (financials) |
| Boeing (industrials) | Microsoft (technology) |
| Boeing (industrials) | Amazon (consumer discretionary) |
| Company Pair | Move Together | Time Series Correlation (Daily Price) |
|---|---|---|
| Target–Apple | 68% (194/284) | 0.95 |
| Tesla–Apple | 66% (190/284) | 0.94 |
| Amazon–Nvidia | 76% (218/284) | 0.97 |
| Amazon–JPMorgan | 60% (172/284) | −0.23 |
| Walmart–Apple | 62% (177/284) | 0.92 |
| McDonald’s–Apple | 61% (174/284) | 0.47 |
| Goldman Sachs–Apple | 68% (194/284) | 0.38 |
| Amazon–Citigroup | 62% (178/284) | −0.54 |
| Boeing–Microsoft | 63% (179/284) | −0.73 |
| Boeing–Amazon | 60% (172/284) | −0.67 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
McCarthy, S.; Alaghband, G. Enhancing Financial Market Analysis and Prediction with Emotion Corpora and News Co-Occurrence Network. J. Risk Financial Manag. 2023, 16, 226. https://doi.org/10.3390/jrfm16040226
McCarthy S, Alaghband G. Enhancing Financial Market Analysis and Prediction with Emotion Corpora and News Co-Occurrence Network. Journal of Risk and Financial Management. 2023; 16(4):226. https://doi.org/10.3390/jrfm16040226
Chicago/Turabian StyleMcCarthy, Shawn, and Gita Alaghband. 2023. "Enhancing Financial Market Analysis and Prediction with Emotion Corpora and News Co-Occurrence Network" Journal of Risk and Financial Management 16, no. 4: 226. https://doi.org/10.3390/jrfm16040226
APA StyleMcCarthy, S., & Alaghband, G. (2023). Enhancing Financial Market Analysis and Prediction with Emotion Corpora and News Co-Occurrence Network. Journal of Risk and Financial Management, 16(4), 226. https://doi.org/10.3390/jrfm16040226