1. Introduction
The international co-movement of stock market volatility has attracted much attention after the Asian financial crisis in the late 1990s. It is often argued that national financial instability is quickly transmitted internationally through accelerated capital flows, especially in emerging markets and then international financial crisis is more difficult to cope with.
One type of co-movement analysis is to estimate volatility spillover effects, which is essentially transmission mechanism of volatility in stock markets. This line of research uses extensively various variants of ARCH model first proposed by Engle [
1], such as the SWARCH model, which is the Markov switching model incorporated into the ARCH model. The existence of spillover effects has been recognized almost universally by empirical analyses.
Another type of co-movement analysis is to identify a volatility factor common to multiple series. This model is often used in explaining volatility contagion, namely increased correlation in high volatility period; correlation between two series increases when the volatility of their common factor is high in comparison with idiosyncratic volatilities. This phenomenon is also regarded as a stylized fact in financial markets.
In this paper we proposes the Lagrange multiplier (LM) test for a single common volatility factor model. The null hypothesis is an extreme case in that two markets have a single stochastic volatility process in common and have no idiosyncratic volatility factor. This situation is not unrealistic in that it expresses the situation where a single intermarket volatility factor overrides other minor volatility factors of two markets, for example, in the period that includes global financial crises. In such an “extreme" situation, other minor domestic volatility factors are negligible in size and markets looked as if they have a single common volatility process in common. The aim of our test is not to assert that there exists only one single volatility factor among markets, but that minor idiosyncratic volatility factors are overridden by a single intermarket volatility factors.
The use of the LM test is essential here. The Wald and Likelihood ratio test statistics cannot have
distribution asymptotically under the null hypothesis; the restricted parameter estimators, which is used by the Wald and Likelihood ratio test procedures, cannot have asymptotically standard distribution, since the null for our problem is on the boundary of the parameter space (General discussions of asymptotic tests in boundary situations have been provided by Chernoff [
2], Moran [
3], and Chant [
4].), namely variance should be positive and correlation should be less than one in absolute value. Only the LM test statistic has
distribution asymptotically under the null hypothesis of our problem, since the LM test procedure uses only restricted parameter estimators.
We here consider the linearized form of the bivariate Stochastic volatility (SV) model and assume that this linearized form has a Gaussian disturbance term. This unconventional assumption is a cost to derive the test statistic for the number of volatility factors, which is an unprecedented challenge in the literature. By this assumption, the model is free from numerical integration to be used in estimating the original SV model (The original formulation of the SV model was introduced by Taylor [
5], and has been applied successfully in financial analyses, for example, by Jacquier
et al. [
6] and Kim
et al. [
7]. For the recent development of the multivariate SV models, see Asai
et al. [
8].). A counterpart test in the ARCH framework was proposed by Engle and Susmel [
9]. We believed that our test would be also useful to find a single overriding factor in bivariate state-space model in level.
The rest of the paper is organized as follows.
Section 2 details the framework and notation of the model.
Section 3 proposes the formula of the test statistic for the linear state-space model.
Section 4 reports the results of our Monte Carlo experiments for the empirical size and power of the test. In
Section 5, the test is applied to the empirical analysis of the Asian stock market indexes.
Section 6 briefly concludes this study. The derivation of the score functions and the conditional moments of state variables are given in
Appendix.
2. Model
We here consider the following observation equations of the bivariate SV model:
for series
and time
. Note that
is the observed variable, which typically denotes the demeaned rate of return on assets,
is demeaned part of log volatility, where
,
is an idiosyncratic noise with constant variance, standardized at 1, and
is the mean of log volatility, and hence
is, roughly speaking, overall standard deviation of
.
We linearize the observation equation to the linear state-space model (The log transformation breaks down when
, since
. In practice, the use of
has been suggested in place of
for small constant
to avoid this problem. This transformation is useful in that
ϵ has no effect for large
x. See Breidt and Carriquiry [
10] for details.); taking log of squares of Equation (
1), we have
where
, and
.
The main difference of our model from the original multivariate SV model is that Gaussianity of
is assumed in our model, namely
where
γ is a correlation coefficient of
, and hence the distribution of
is no longer Gaussian. We are not asserting that the log squared returns follow a Gaussian distribution in reality (As suggested by an anonymous reviewer, the distribution of
under Gaussianity of
is, exactly speaking, inappropriate for market data. It can be easily shown that the marginal distribution of
is expressed as
noting that
follows a log-normal distribution. It is easy to see that this distribution has zero density function at the origin.).
Under the assumption of Gaussianity of
, the model (
1) would be a nonlinear non-Gaussian multivariate state space model; even conventional hypothesis testing for this model has been rarely calculated because of its heavy computational burden and complexity, and hence constructing a test for the number of factors, which is our aim, seems almost unfeasible under the original assumption.
It seems also algebraically unfeasible to derive a test statistics from Equation (
2) if Gaussianity of
is assumed. The properties of the linearized model under the Gaussianity assumption of (
) was extensively studied by Harvey
et al. [
11] and they reported that their analytical expression is extremely complicated; for example, the joint covariance of
and
is expressed as an infinite series; the mean and variance of
are expressed as
and
, respectively.
On the other hand, the linearized model (
2) is a linear state-space model under our assumption that the distribution of
is Gaussian and we can derive the score function and Fisher information, which are required to derive our test, though algebraically tedious, as shown in
Appendix A.
The non-Gaussianity of in our model is a serious drawback if we use this model for asset pricing, where Gaussianity of return is an essential assumption. However, in the context of spillover or contagion in international finance, Gaussianity is not always an essential element. We believe that our assumption of Gaussian is a cost to derive the test for a single volatility factor. The usefulness of our assumption can be tested by checking the usefulness of our test.
The observation equation density, namely the conditional density of
and
given
and
, are expressed as
We here assume that the log volatilities follow the bivariate first-order autoregressive (AR) process:
where the idiosyncratic noise
follows Gaussian distribution, namely
The transition Equation (
5), or the conditional densities of
and
given their past values, are expressed as
This formulation is not a general bivariate autoregressive process in that they are two univariate first-order AR processes with correlated innovations (Harvey
et al. [
11] set
to unity.). The general condition for the identity
is that the coefficient matrix of the multivariate first-order AR model has eigenvector
, in addition to the degeneracy of disturbances. However, we believe that our assumption is sufficient for practical use.
Then, the density function of
, or the likelihood function, from which our LM test statistic is derived, is expressed as follows:
by integrating out the state variables
, where
We have two notes for the integration in Equation (
8). First, our model defined by Equations (
2), (
3), (
5), and (
6) is linear and Gaussian, and hence the likelihood function can be evaluated and maximized, without numerical integration, whether by means of quadrature or Monte Carlo methods. Hence, we evaluate the likelihood by means of the Kalman filter method, which was suggested by Nelson [
12] and Harvey
et al. [
11]. Second, the transition density is degenerate under the null hypothesis and the integration can be performed by integration by parts, as shown in
Appendix A.
In the conventional multivariate SV model, which is different from ours, the observation equation disturbance term
follows Gaussian distribution:
Harvey
et al. [
11] showed that the maximum likelihood (ML) estimator of this transformed model, which is called the quasi-maximum likelihood estimator (QMLE), is consistent under the original assumption of the Gaussianity of
. The estimation of SV model in the original form (
9) can be carried out by various methods, for example, the generalized method of moments (GMM) used by Melino and Turnbull [
13], the efficient method of moments (EMM) applied by Gallant
et al. [
14], and Markov Chain Monte Carlo (MCMC) procedures used by Jacquier
et al. [
6] and Kim
et al. [
7]. The construction of tests for the original model (
9) based upon these methods is left for further research. However, little attention has been paid to hypothesis testing of this model.
3. Test Statistic
We propose the LM test for the hypothesis that the observation series
and
have the only stochastic volatility factor in common, and other idiosyncratic volatility factors are negligible, namely
for any
t in Equation (
5), against the alternative hypothesis that each series has different, possibly correlated, log volatility series
and
.
The null hypothesis that is a first order approximation to the international synchronization of asset price fluctuation, found, or believed to be found, in the period that includes financial crises. In normal periods actual volatilities of markets are expressed as mixtures of many factors. In the period that includes financial crises, however, only a single intermarket volatility factor may override other minor volatility factors in markets. In such an extreme situation, other minor domestic volatility factors are negligible in size and some markets look as if they have a single common volatility factor. The aim of our test is not to assert there exists only a single volatility factor among markets, but is to check whether minor volatility factors are negligible in comparison with a big intermarket volatility factor.
In our Equation (
7), the innovations are perfectly correlated if
, and mutually independent if
. Our test checks that the two series have the same autoregressive coefficient and innovation variance, namely
, as well as the degeneracy of the innovation, namely
. Therefore, in Equation (
5), the null hypothesis is formalized as
In our framework, in order to define the existence of a single overriding volatility factor in two markets, the volatility series of two markets should be exactly the same, which means , , , and hence , when the volatility series is stationary; the logic is as follows: If the volatility processes of two market are not identical but correlated by assuming , they have different volatility shocks and hence volatility series have different patterns especially when the absolute value of is large, then we have no choice than to define the number of volatility factors in the market is two when . Then the condition , or very small absolute value of , is a essential element in defining the single overriding volatility series. When , we need the condition , to define the single overriding volatility series, since implies different cyclicality or periodicity of volatility process.
It is arguable whether the condition is necessary. Under the assumption of , the condition expresses smaller variance of than that of around 0 and hence, intuitively, smaller variance of than that of around 1, namely variance of volatility of , disregarding proportionality constant . Then λ can be regarded as “volatility of volatility” parameter and hence should be 1 if two markets follow the same volatility factor. If the same volatility process implies identical volatility of volatility, we need the condition .
We need the initial value condition
additionally for the log volatilities to be exactly identical stochastic processes under the conditions of (
10). However, the log volatilities converge to zero quickly as long as they are stationary, even if their initial values are different, and the effect of
disappears in the vector moving average expression of
, as
t increases. Then, we only consider the conditions (
10) hereafter.
The Wald and Likelihood ratio principles are irrelevant to test for Equation (
10), because the maximum likelihood estimator of
can have a singular distribution under the null hypothesis; the parameter value
under the null is on the boundary of the parameter space
, so that their estimators cannot have an asymptotically normal distribution. The LM test is free from the boundary value problem, since it forgoes estimation of the constrained parameter
;
We now restate the null hypothesis (
10), by the parameter transformation
to
the original parameter vector
is transformed into the new parameter vector
. The vectors of the restricted and unrestricted parameters are denoted by
,
respectively, and the log likelihood function for
θ is denoted by
using the likelihood function defined in Equation (
8). Then, the LM test statistic for Equation (
11) is defined as
where the derivative of
with respect to
is denoted by
evaluated at
, namely the maximum likelihood estimator of
θ under the null hypothesis, and
is the upper-left three-by-three submatrix of the inverse of the Fisher information matrix evaluated at
. Then, the LM test statistic follows asymptotically
distribution with three degrees of freedom, which is the number of constraints.
The Fisher information can be calculated by
where
as shown by Hamilton [
15] from the identity
In practice,
is estimated by
where the unknown parameters
θ are estimated by the maximum likelihood method under the null hypothesis.
Hence, we have only to derive the score functions, or the derivatives of log of
in Equation (
8) with respect to
θ, to calculate the LM test statistics using Equations (
13) and (
14). Their derivation is straightforward, by means of integration by parts, but very lengthy so that we provide the detailed derivation in
Appendix A.
Denoting
as the expectation under the null hypothesis, their score functions evaluated under the null hypothesis are as follows:
Denoting
, the conditional moments of
given
under the null hypothesis can be expressed as
from Equations (
2) and (
5). See
Appendix B for their derivation.
4. Monte Carlo Experiments
To examine the performance of our proposed test, we conduct Monte Carlo experiments using the GAUSS programming language. We use the following data generating process:
Generate
from multivariate log-normal random number generator from GAUSS library (The joint probability density function of
and
is expressed as
for
. Note that the library name of multivariate log-normal random number generator in GAUSS is
.). In addition, generate
from Gaussian random number generator.
Generate
from
. The processes of
and
are obtained from the following model;
for
.
Calculate from and generate from , respectively.
From the above data generating process, we can define the following linear Gaussian state-space model:
Structure of innovation distribution
We here report the simulation at
and its neighborhood (Note that the parameters
are fixed at
throughout this experiment. Then,
is expressed simply as
.). In this experiments, the number of replications is 1000, the sample sizes are
, and the initial value of
are fixed at
respectively. The initial value of parameters for ML estimation are
. Finally, we generate
periods of data and use the last
T periods by discarding the first 100 periods to reduce the effect of initial values. The procedure (See Durbin and Koopman [
16] for a detailed discussion and review of the algorithm of the Kalman filter and smoother.) works as follows.
Table 1 gives the empirical size of the test, namely the rejection rate of the null hypothesis, under the null for some values of the correlation coefficient
γ in Equation (
4), the autocorrelation coefficient and variance of the transition equation, namely
and
in Equation (
7).
Table 2 reports the empirical power of the test, when the two series have different log volatility series, with different autocorrelation coefficients
and
, or nondegenerate innovations with nonzero value of
in Equation (
7). Each table reports the percentage rate of rejection of the relevant null hypothesis at the asymptotic 5% and 1% significance level. Note that the rejection region of the tests are in the upper tail areas. Our main findings are summarized as follows.
Size of the test: For , the actual size of the test deviates from the nominal sizes of 5 and 1 percent at most by 3.1 and 1.9 percent, respectively. In particular, when the estimated volatility series are strongly correlated and can be characterized as near unit root processes, the size distortion are increasing. As the sample size increases, namely when , the actual rejection rate is closer to the nominal level, as is expected.
Power under the alternative: For , the rejects rate of the null ranges from 12.9 percent to 58.9 percent for the nominal 5 percent significance level. As the sample size increases, the actual rejection rate is increasing. This results indicate that the absolute value of the difference between the null and the alternative is 0.2 or more, the test statistics can discriminate the hypothesis.
Table 1.
Empirical size of the LM test by Monte Carlo experiments.
Table 1.
Empirical size of the LM test by Monte Carlo experiments.
| γ | | | | |
|---|
| 5% | 1% | 5% | 1% |
|---|
| 0.1 | 0.7 | 0.1 | 6.1 | 1.2 | 5.5 | 0.9 |
| 0 | 0.7 | 0.1 | 5.8 | 1.9 | 5.3 | 1.2 |
| −0.1 | 0.7 | 0.1 | 4.6 | 0.8 | 5.1 | 1.1 |
| 0.1 | 0.9 | 0.1 | 7.2 | 1.8 | 5.7 | 1.4 |
| 0.1 | 0.95 | 0.1 | 8.1 | 2.9 | 6.5 | 1.8 |
| 0.1 | 0.7 | 0.2 | 7.1 | 1.6 | 5.4 | 1.1 |
| 0.1 | 0.7 | 0.3 | 5.1 | 0.7 | 4.9 | 1.2 |
Table 2.
Empirical power of the LM test by Monte Carlo experiments.
Table 2.
Empirical power of the LM test by Monte Carlo experiments.
| λ | | | |
|---|
| 5% | 1% | 5% | 1% |
|---|
| 0.5 | 1 | 0 | 25.5 | 10.7 | 36.9 | 17.7 |
| 0.9 | 1 | 0 | 39.0 | 18.4 | 52.3 | 24.6 |
| 0.7 | 0.8 | 0 | 12.9 | 1.3 | 15.1 | 5.1 |
| 0.7 | 0.6 | 0 | 31.5 | 14.1 | 44.4 | 20.9 |
| 0.7 | 1 | 0.2 | 17.9 | 5.5 | 24.9 | 9.0 |
| 0.7 | 1 | 0.4 | 58.9 | 32.3 | 79.1 | 52.3 |
An important practical conclusion of our simulation is that a rather large sample size, such as more than , is necessary to distinguish the null and the alternative. However, datasets with a sample size of 500 or more are easily available in financial analyses.
Summarizing, Monte Carlo results showed that the tests are reliable in terms of both size and power performance.


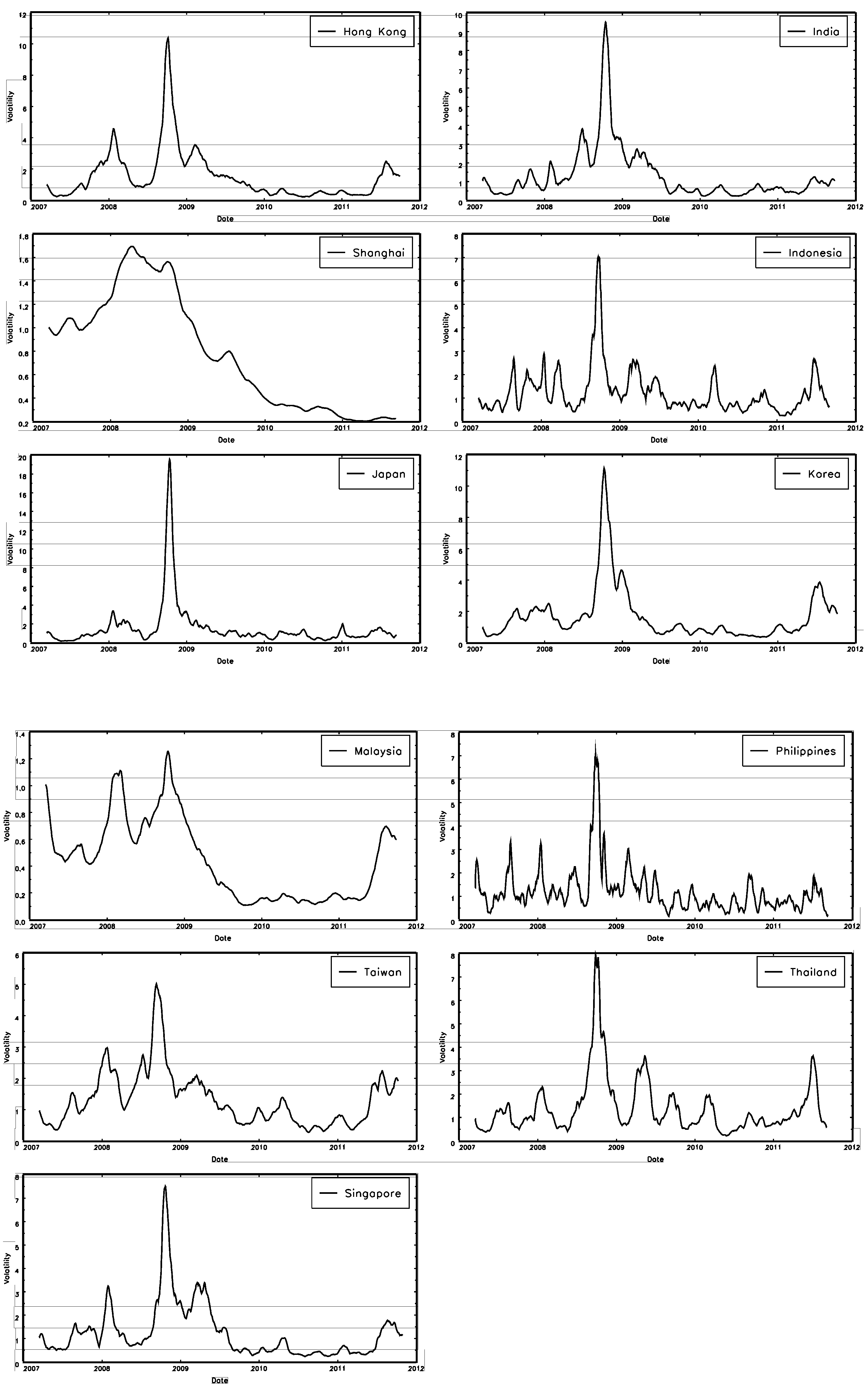{kind=link}
