2. Dynamic Bayesian Network Model
Bayesian networks are graphical models consisting of nodes representing stochastic variables and directed links between the nodes, representing causal relationships. For a discrete model, each node has a discrete number of states, corresponding to the possible outcomes of the stochastic variable. If the stochastic variable is in fact continuous, it can be discretized such that each state represents an interval of values. To define the Bayesian network, the conditional probability distribution must be specified for each node conditioned on parent nodes (the nodes pointing towards a node). For a node with no parents, the marginal distribution is specified. The network can then be used for calculating the probability of each state for each of the nodes, and these probabilities can be updated, when any of the nodes are observed.
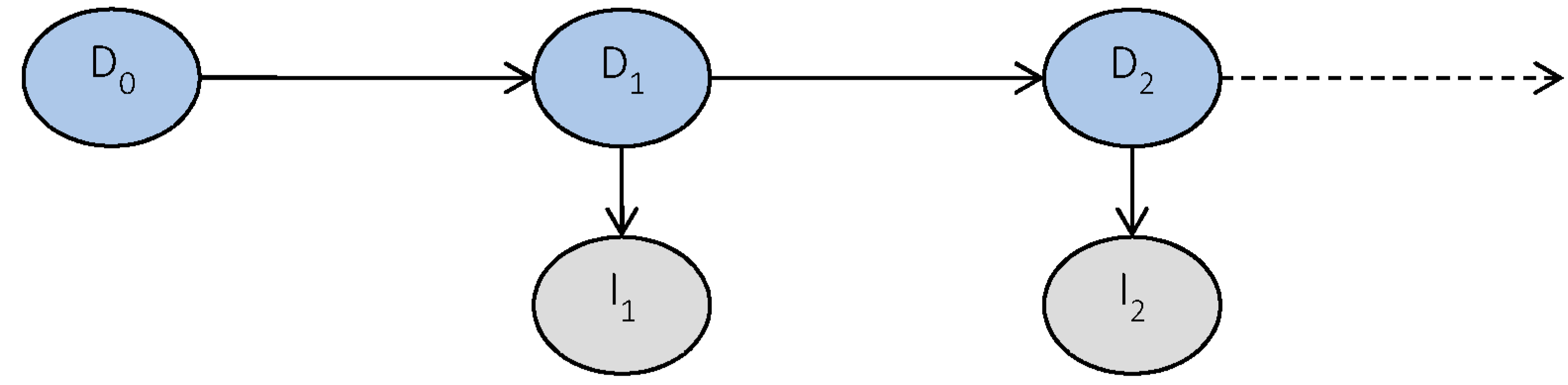
Dynamic Bayesian networks are especially appropriate for problems evolving with time like deterioration, as they consist of a sequence of time slices, each connected only to the previous and following time slice. Dynamic Bayesian networks can be applied for modelling of a Markov chain. For a Markov chain, the future is independent on the past, given the present, and it is modelled as a chain of nodes, each node pointing to the next. For RUL estimation, the nodes in the Markov chain can represent the deterioration state, e.g., damage size. When a Markov model is used, the RUL estimate only depends on the current deterioration state. For wind turbine blades, inspections are associated with uncertainty, and the current deterioration state is not directly observable. Therefore, a hidden Markov model is applied, as illustrated in
Figure 1. The time slices generally contain two nodes: a node for the true deterioration state (
) with
states, and a node for the observation of the deterioration state (
) with
states.
For this model, time is discretized into a finite number of time steps, and the probabilities of transferring from each state to the following state within a time step are specified. In a Markov process where time is continuous, the time spent in each state follows an exponential distribution. When time is discretized, this becomes a geometric distribution. This assumption can be relaxed by using a semi-Markov model, where the time in each state does not have to be exponential distributed. To model this using a Bayesian network, each ‘physical’ state is divided into several virtual states, to obtain another sojourn time distribution for the physical state, and the time spent in each virtual state is still exponentially distributed [
21]. Dynamic Bayesian networks can also be applied for deterioration modelling based on physical models as shown in Equation (1) [
22].
The network in
Figure 1 is specified in terms of three probability distributions:
: prior probability distribution for the initial deterioration state ( vector).
: conditional probability distribution for the deterioration state in time step given the deterioration state in time step ( matrix).
: conditional probability distribution for the observation of the deterioration state in time step given the deterioration state in time step ( matrix).
When these three probability distributions are specified, the Bayesian network model can be used for computing the marginal distribution of
and
for each time step. When no observations have been made, this can be done using forward computing. Sequentially, starting at
, the marginal distribution for
is found by elementwise multiplication of
and
to obtain the joint distribution
, and then marginalizing out
by summation:
When the probability distributions are given as matrices and vectors, this operation corresponds to matrix multiplication. In the same way, the marginal distribution for
can be obtained:
When any of the nodes are observed, this affects how the computations are performed. The marginal distribution
can be updated, when
is observed by applying Bayes rule. The marginal distribution for
given the observation
is:
where “∝” means “proportional to”. After elementwise multiplication, the distribution is scaled to sum to one.
The task of computing the distribution for time steps , when observations are received for nodes up to , is so-called filtering. It is performed by applying Equations (2) and (4) sequentially. The task of computing the distribution for time steps , when observations are received for nodes up to , is so-called prediction. This is simply performed by applying Equation (2) sequentially.
2.1. Model Specification
To obtain the probability distributions
,
, and
, inspection data in the Guide2defect database is considered for illustration. The database contains an entry for each defect detected during an inspection. For inspections of blades without the detection of any defects, an entry for “no detected defects” is made. The defects are classified based on the type, and categorized based on the severity of the defect. Categorizations similar to the one applied in the database are commonly used in the wind turbine inspection industry [
23]. For cracks in the laminate, the categorization is performed based on the size of the crack. For each crack present in the blade, there are seven possible outcomes for an inspection, as shown in
Table 1, as these are the categories used in the database. These seven possible outcomes are the states for the node
, if the variable
represents the size of a specific crack.
If we are interested in a model for the overall health of the blade for the estimation of the RUL, it is not enough to consider each crack separately. Instead, a model is made where the variable represents the overall health of the blade. We assume that the largest crack dominates the repair costs and the probability of failure, and let the variable represent the size of the largest crack in the blade. If the deterioration model calibration is performed based on observations of the largest crack in the blade, the model considers both the possibility that the largest detected crack grows, and the possibility that a smaller crack grows to become the largest. We hereby consider all cracks as belonging to the same population.
The states for the node for the true damage size () must be related to the states of the node for the observed damage size () through the inspection model. It is natural to choose the same states for as for , except for the first state, which should be “no crack initiated” instead of “no detection”.
Adding more sub-states within each observed state can make it possible to model a non-exponential sojourn time. If a physical model was available or each blade was inspected many times, it would be relevant to study the effect of adding more states. However, in the available data, each blade is only inspected one or a few times, and a more accurate estimate of the sojourn time distribution cannot be made. We, therefore, use the same number of states for the deterioration model as for the inspection model, and assume that it is not possible for a crack to grow more than one state during each time step. Then, the conditional probability distribution
is defined in terms of six transition probabilities
to
:
If we assume that no cracks are present in the first time step, the distribution for the initial crack size is:
The inspection model should reflect the reliability of the inspection method being used. For the current version of the database, the inspection method is not specified. We assume that all inspections are visual inspections performed using rope access, that detected cracks are classified correctly, and that no false detections occur. Then, the inspection model is defined based on the probability of detection for each crack size,
to
:
The
values can be estimated using engineering judgement, and the values used for this paper are inspired by [
18], and are shown in
Table 2.
2.2. Calibration of Markov Deterioration Model Using Inspection Data
Several methods exist for the assessment of probability distributions in a Bayesian network model [
7,
19]. Here, we apply the maximum likelihood method for estimation of the transition probabilities. In the maximum likelihood method, the transition probabilities are found such that the probability of getting the observed dataset is maximized. To avoid numerical underflow, the logarithm of the product of the probabilities is taken instead, yielding the objective function:
where
is the probability of data point
for a given set of transition probabilities
. Each data point contains information on maximum observed crack size (
), age at the time step of inspection (
), and blade identification number (
). The age (
) should be given as the number of whole time steps, e.g., months. The dataset is assumed to contain information from one or more inspections for several identical wind turbine blades.
For blades only inspected once, the probability is obtained by applying Equation (2) sequentially for , and then applying Equation (3) for , to get the marginal distribution . The probability of data point is then .
For blades inspected several times, the observations are not independent, and the joint probability of all data points is found using Bayes rules to obtain conditional probabilities. For example, for two observations
and
of the same blade, the joint probability can be found by multiplication of the probability of the first data point and the probability of the second data point given the first data point:
The probability of the first data point is obtained in the same way, as for blades only inspected once. Then, to obtain the conditional probability of the second data point given the first, Equation (4) is applied for the first data point for . Then Equation (2) is applied sequentially for and, finally, Equation (3) is applied for such that the probability can be retrieved.
The most likely set of transition probabilities is found by solving the maximization problem using a built-in solver for non-linear constrained optimization in MATLAB [
24]. The objective function was given in Equation (8), and the constraints for the transition probabilities are the general bounds for probabilities; zero and one.
3. Example
In this example, preliminary data from the database Guide2defect [
17] is used for demonstration of the method. Due to confidentiality, the raw data used in the example is not publicly available. To ensure homogeneity in the data, one specific wind turbine model is selected, and all data for this model is extracted. For each blade inspection, the following information is identified: the category of the largest detected crack (or the information that no cracks have been detected), the age of the blade at the time of inspection, and the identification number of the blade. The division of the observations on crack category is shown in
Table 3.
In several cases, the same blade has been inspected several times. The method presented in
Section 2.2 assumes that the blade has not been repaired between inspections, but in reality, blades will often be repaired after detection of cracks, especially larger cracks. The present version of the database does not contain information of repairs and, therefore, assumptions must be made concerning repairs. If the same blade is inspected several times, and the size of the largest detected crack declines between inspections, it is most likely, that a repair has been made. If the size of the largest crack stays the same or increases, it could be the same crack, if it has not been repaired, or a new crack both if it has or has not been repaired. To identify whether previously detected cracks are still present, the following information on the type and location of the detected cracks is considered:
Reference number (contains blade ID);
Defect code (type of defect);
Section (approximate location on blade in longitudinal direction);
Outside profile position (location on blade in transverse direction);
Profile side (suction side, pressure side, leading edge, trailing edge); and
Defect “radius” (distance from blade root to defect).
The defect radius is a measurement and is, therefore, somewhat uncertain. Two observations are assumed to be observations of the same crack, if the difference in defect radius is less than one meter, and if all other information on location and type is equal. With this information, each crack can be assigned a crack ID number and can be tracked. If the largest crack detected at an inspection is not found in a later inspection, it is assumed to be repaired, and the data from after the repair is discarded. The damage categories for the remaining observations are shown in
Table 4.
Based on the dataset summarized in
Table 4 and the method outlined in
Section 2, the estimates of the transition probabilities in the Markov model are found and are shown together with the mean sojourn time
in each state in
Table 5. The time step used in the model is one month.
3.1. Estimation of RUL—Remaining Useful Life
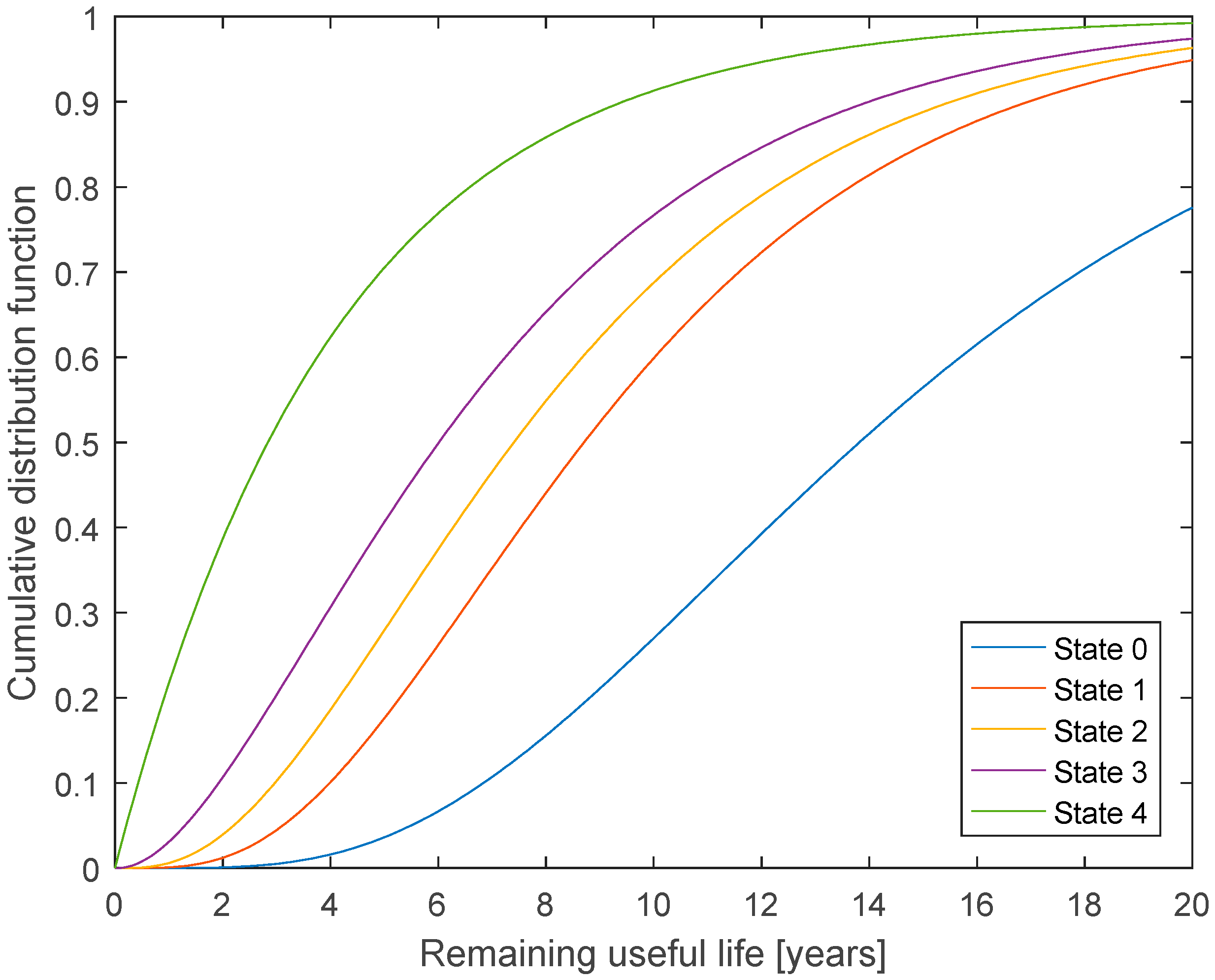
Defects of both category 5 and 6 are classified as critical, and we assume that a blade exchange is necessary for both types of defects. Therefore, the remaining useful life is assumed to end when the blade enters state 5, even though it is still able to operate, but at a high risk of catastrophic failure.
If the current state is known, the mean RUL can be found directly by addition of the mean sojourn times from the current state. For a blade in state 0, the mean RUL is 183.1 months (15.3 years). If the useful life was assumed to end when the blade enters state 6, mean RUL is 222.9 months (18.6 years).
As there is large uncertainty on the RUL, the distribution for RUL is of interest. The Bayesian network model can be used for estimation of the probability distribution for RUL. If the current state is known (or the current distribution for the deterioration state is known), this information can be used as initial deterioration state
, and Equation (2) can be used to find the distribution for future deterioration states. For each time step, the value of the cumulative distribution function can be found as the sum of the probability for state 5 and 6.
Figure 2 shows the resulting cumulative distribution function for RUL, when the current state is known.
3.2. Updating Using Inspections
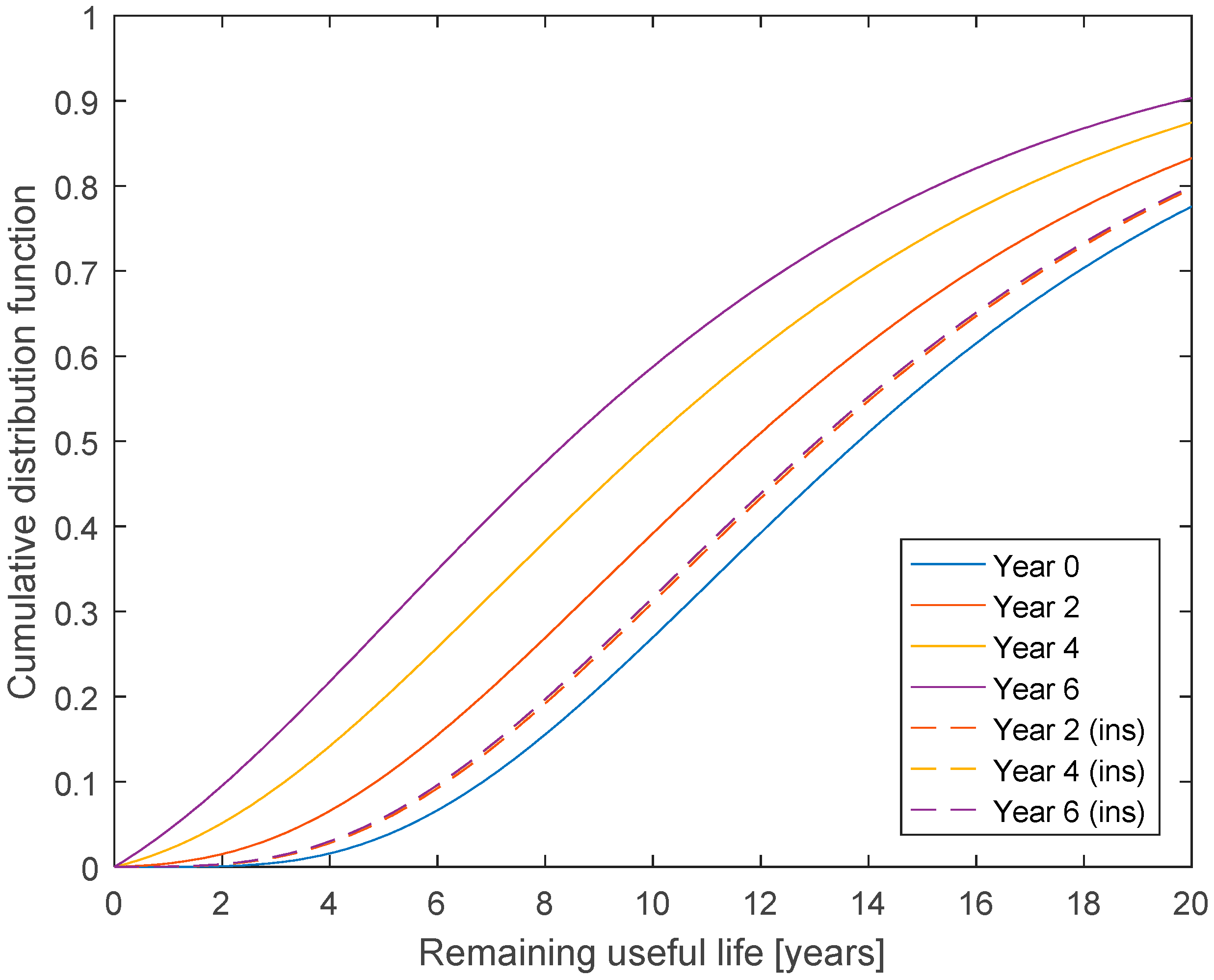
The Bayesian network model can also be used for estimation of RUL, when the current state is not known for certain. When inspection data is available, Bayesian updating can be performed using Equation (4) for time steps with inspections. A similar updating can be performed, if it is known that the useful life has not yet ended.
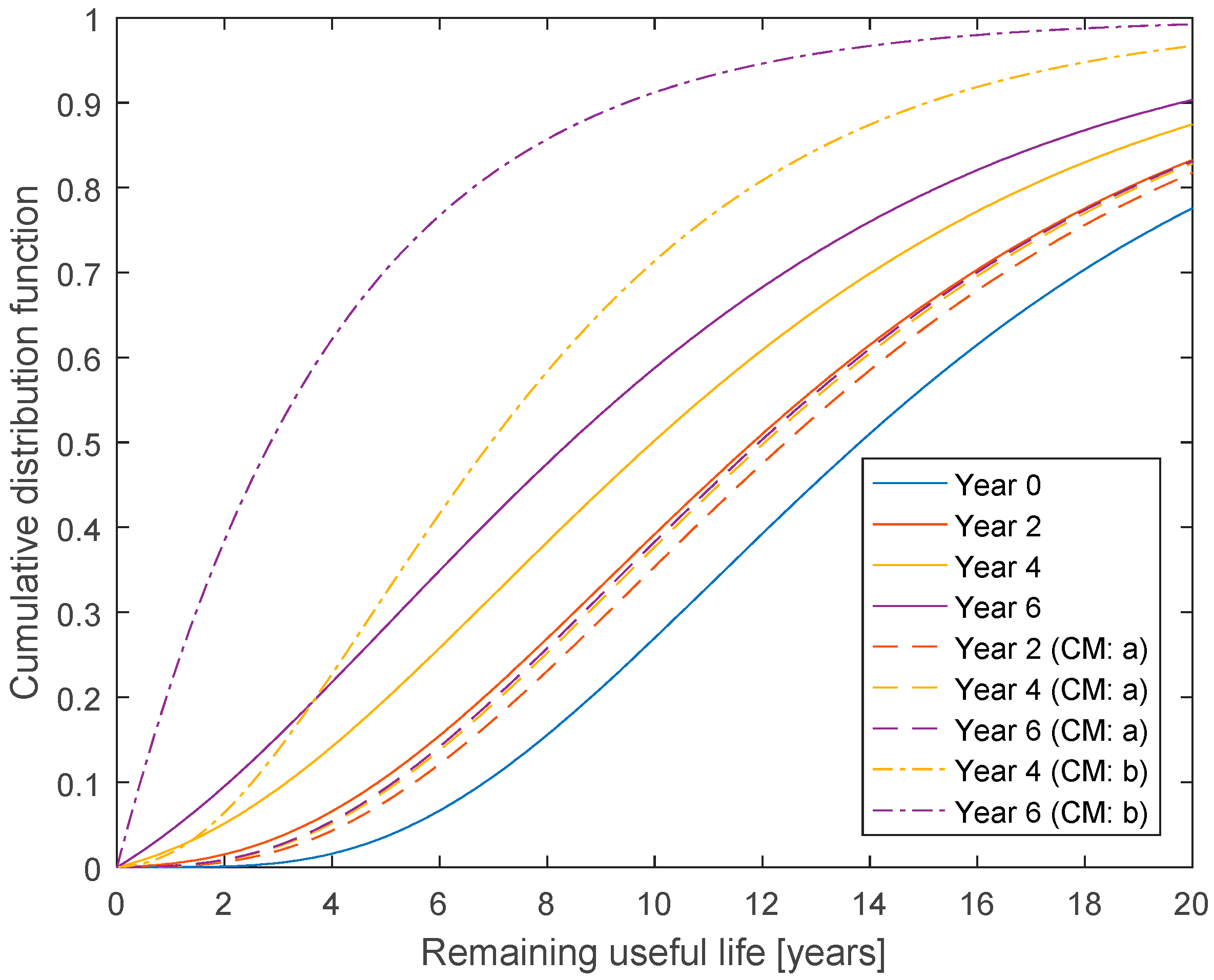
Figure 3 shows the distribution for RUL at year 0, and at year 2, 4, and 6 if it is known that the lifetime has not yet ended, and if annual inspections are made, and no cracks are detected during the inspections.
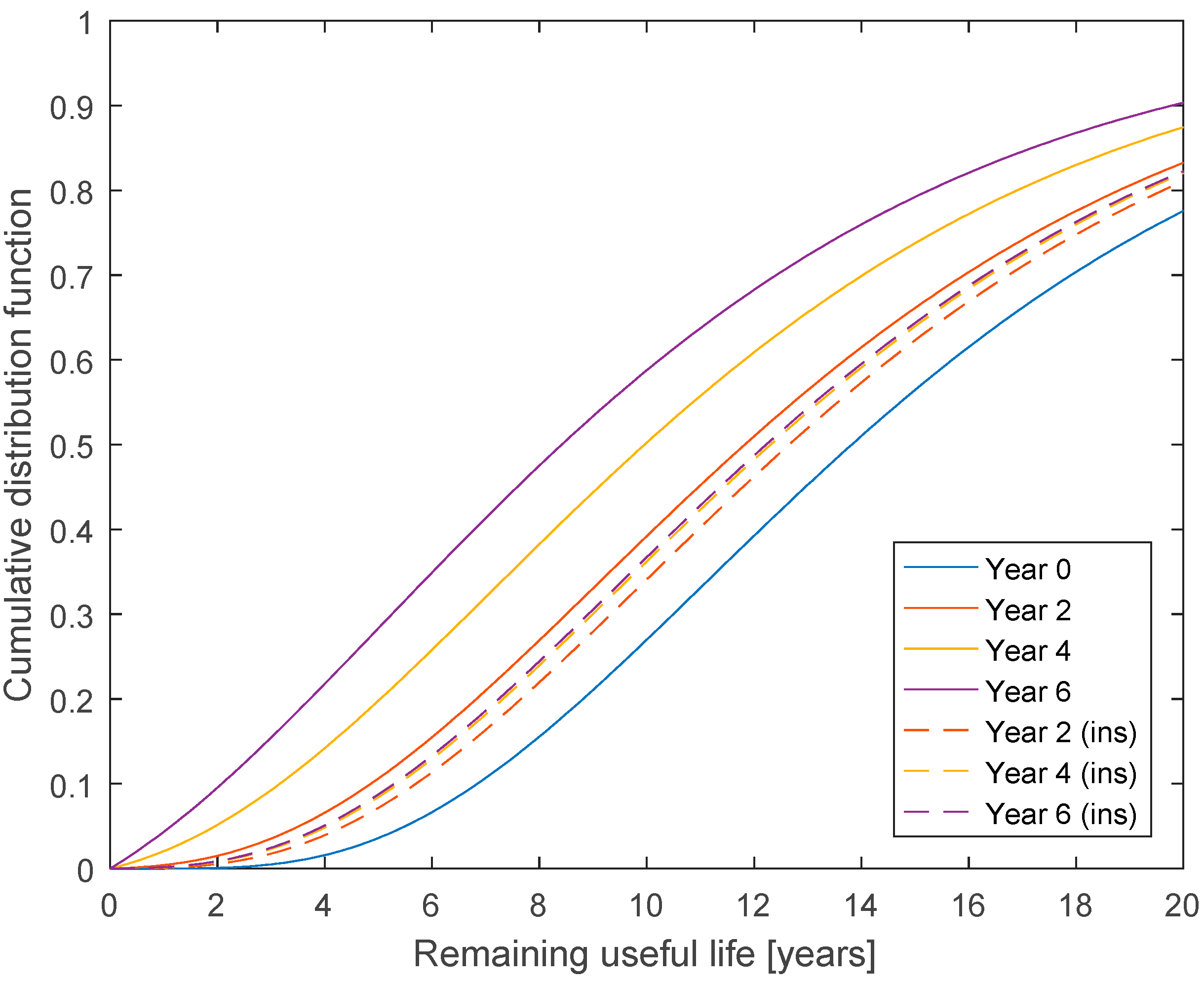
The updating of the curves depends on the probability of detection for each deterioration state. If a less reliable inspection technique was used, the probability of detection would be reduced. If the values for states 1 to 5 was reduced to 20%, 40%, 80%, 90%, and 95%, respectively, and annual inspections were still made, the estimated RUL would be reduced, as shown in
Figure 4.
3.3. Updating Using Condition Monitoring
Compared to inspections, CM has the advantage that information is continuously received without need to access the turbines. If a CM system is installed for health monitoring of the blades, the information from it can be used for updating of the RUL in the same way as inspection information under the following conditions: (1) the model is updated once every time step using a statistical value of the processed signal, e.g., mean or maximum value; (2) the observations used for updating are independent given the damage size. A model for the reliability of the CM method is needed, and should be derived based on information of the actual CM system and the statistics used for updating.
An example of a model with four possible states is shown in
Table 6. The values are fictive, but represent a system, where the probability of detection per time step is lower than for a visual inspection, and where two alarm levels have been set. The system is assumed always to detect failures, defined as cracks larger than 3 meters (category 6). Cracks less than 50 mm (category 1) are never detected, and for cracks between 50 mm and 3 m, the probability of detection increases with size, and the probability of high alarm compared to low alarm increases with size.
Figure 5 shows two examples of how the RUL estimate is updated using information from CM, together with the case, where RUL is just updated using the information that the useful life has not yet ended. In the first example (CM: a in
Figure 5), the CM system is assumed to have the outcome “no detection” in all time steps, until the RUL estimate is made. In the second example (CM: b in
Figure 5), the CM signal is assumed to change to “low alarm” after four years. With a CM system with “no detection”, the curve almost stops to move after four years. However, when the first “low alarm” is received after four years, the curve moves to a much lower estimate of RUL, and when “low alarm” is continuously received from the fourth to the sixth year, the curve has moved further. The RUL estimates updated using CM can be used as basis for decisions on inspections using a risk-based approach [
1]. Decision rules for inspections can for example be based on the probability of failure within a reference period or the mean (or median) remaining useful life, and the optimal decision rule can be determined as the one resulting in the lowest expected lifetime costs.
4. Conclusions and Discussion
In this paper, a dynamic Bayesian network approach was applied for the estimation of the remaining useful life for wind turbine blades. The maximum likelihood method was applied successfully for the estimation of transition probabilities for a hidden Markov model. Generally, the maximum likelihood method is suitable for estimation of conditional probability distributions for complete dataset, and may not succeed in finding a solution for incomplete data. However, for this application it was assumed, that no states could be skipped, and the conditional probability distribution was specified only in terms of six transition probabilities. For less constrained models, other approaches can be applied for the estimation of probabilities, e.g., the expectation maximization (EM) algorithm [
19]. This could be relevant for other wind turbine components, where CM is already implemented, and where CM data is available for the development of deterioration models.
The found transition probabilities were largest for transition from states 1 and 2. The reason for this can be seen in the inspection data, where only few cracks in categories 1 and 2 was found compared to states 3 and 4. Therefore, on average, each crack can only have this size for a short time, otherwise more cracks of these sizes would have been found. However, the transition probabilities also depend on the assumed inspection model. If the probability of detection values were decreased for states 1 and 2, which could also explain the lack of observations, and the resulting transition probabilities for states 1 and 2 would be smaller. However, the other transition probabilities would also be adjusted, such that the effect on the mean RUL for state 0 would be limited.
After the transition probabilities are found, the Bayesian network model can be used for the estimation of RUL, and can be updated using observations from inspections or CM. If no observations were made, the RUL gradually decreased with time. However, when inspections were made, and nothing was detected, the RUL estimate stagnated. It stagnated at a lower RUL, if a less reliable inspection technique was used. Condition monitoring also provided efficient stagnation of the RUL estimate, when nothing was detected, even though the reliability of CM was assumed to be lower than inspections. On the other hand, CM outcomes were achieved in all time steps, not only annually as was assumed for inspections. It should be noted that the observations were assumed to be independent, given the model. In reality, it would be fairer to account for some dependence between CM outcomes in different time steps, as the location and type of crack would affect the probability of detection. Ignoring a correlation, which is, in fact, present could lead to RUL estimates that are too optimistic. The correlation between observations can be included by adding a joint parent node for the nodes for CM outcomes and is an important topic for future research.









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}