4.1. Qualitative Scatter Analysis
The characteristics of the computed statistics were visualised using scatter plots. Four scatter relations are considered:
σ2s vs.
Vs,
σ2t vs.
Vt,
ε vs.
Vt, and
η vs.
Vt. For each relation, eleven separate plots were made to describe the scatter at each of the eleven pressure levels considered. Four of these are representatively shown in
Figure 2,
Figure 3,
Figure 4 and
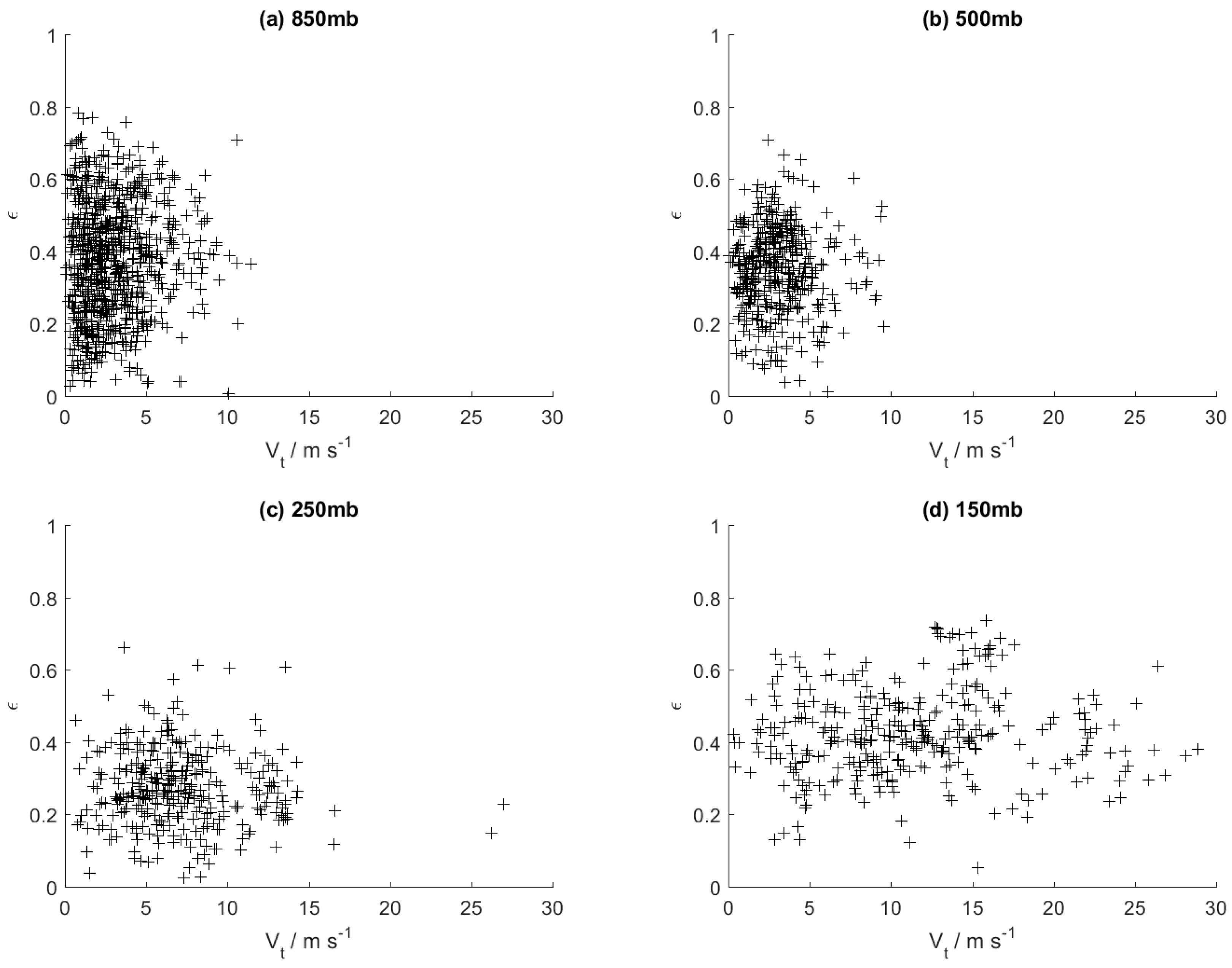
Figure 5: 850 mb (lower troposphere), 500 mb and 250 mb (middle troposphere), and 150 mb (upper troposphere). Each scatter point in these plots represents the statistics obtained for a single set of the observation data as described in the previous section. The sets can be of different seasons or launch times but all points on a single plot are from sets of the same pressure level.
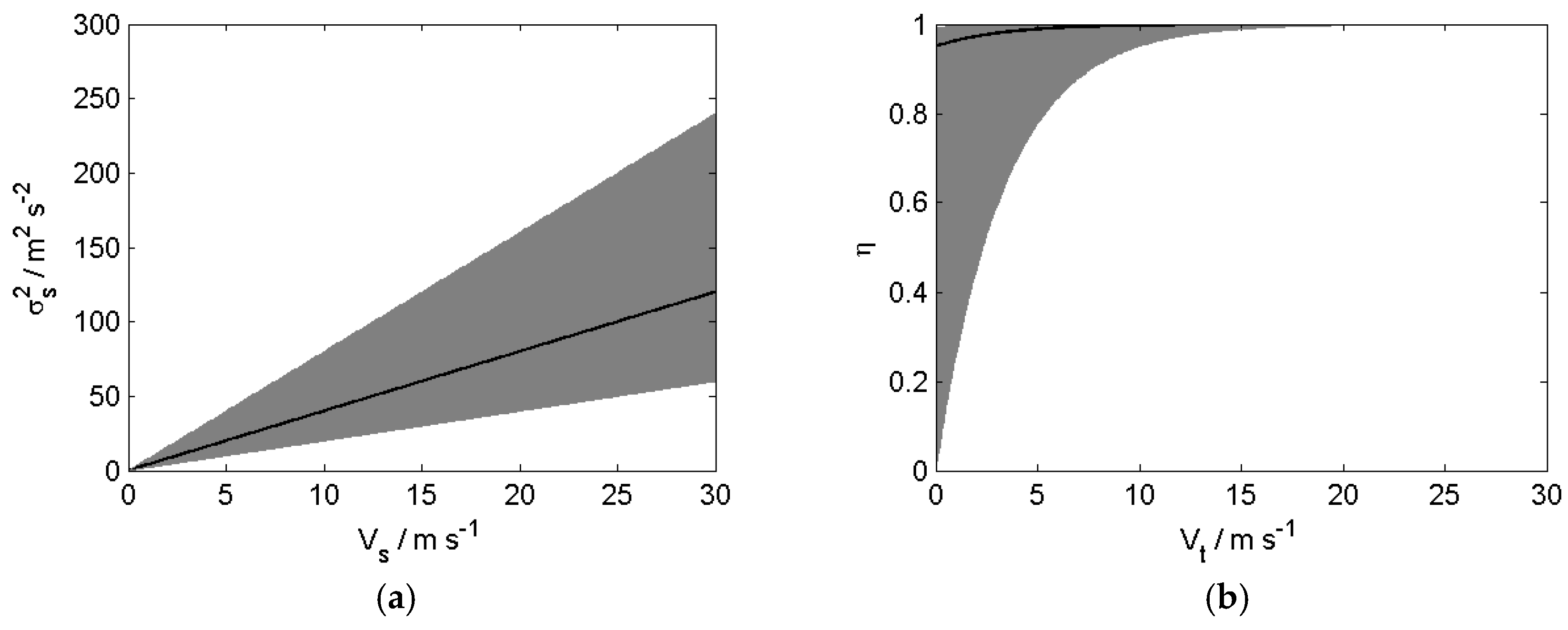
A quick inspection of the scatter plots reveals some salient features. The plots of
σ2s vs.
Vs in
Figure 2 show a trend of increasing
σ2s with increasing
Vs. This implies that the scalar variance tends to get larger with higher mean wind speed. Also, the spread of scatter points increases with increasing
Vs, giving the impression that the scatter points are fanning out from the origin. This implies a greater variability of the scalar variance at higher mean wind speeds.
As for the plots of
σ2t vs.
Vt (
Figure 3), which are the vector equivalent of
σ2s vs.
Vs, neither
σ2t nor its spread seems to be related to
Vt. However, the spread of
σ2t exhibits a peculiar skewness with high density of scatter points coalescing towards a pseudo lower bound and the density gradually tapering off towards higher values of
σ2t. It is noted that this pseudo lower bound appears to move upwards with a higher pressure level. This implies that the trace of the variance tensor tends to become larger with increasing height.
For the plots of
ε vs.
Vt in
Figure 4, the spread of
ε reduces and appears to tend towards a particular median value of
ε as
Vt increases. This implies that the degree of anisotropy in the variance tends towards a certain value at higher magnitudes of the mean wind velocity whereas at lower magnitudes, a greater variability of the anisotropy can be expected. It is also noted that the median
ε value and the spread are different in each of the plots, suggesting that these characteristics are related to the pressure level. Finally, for the plots of
η vs.
Vt in
Figure 5, the spread of
η reduces and
η tends sharply towards 1 with increasing
Vt. Furthermore, even at low
Vt, the spread of
η is also highly skewed towards
η = 1. This implies that the direction of the mean wind velocity tends to align with the axis of the maximal variance and especially so at higher magnitudes of mean wind velocity.
4.2. Regression Fitting of Percentile Lines
In furthering the analysis, percentile lines were used to quantify the observed scatter patterns. These percentile lines describe how the location and spread of the scatter points change with Vs or Vt, similar to how a standard regression line describe that for the scatter mean. Five percentiles were considered: 10th, 25th (1st quartile), 50th (median), 75th (3rd quartile), and 90th percentile. The percentile lines were obtained using a two-step process. The first involved binning of scatter points in each scatter plot into bins in the horizontal Vs or Vt-axis. For each of the five percentiles considered, a regression point was computed for each bin. The vertical coordinate of this point is the percentile calculated for only the scatter in the particular bin and the horizontal coordinate is the bin centre. In order to ensure statistical significance, regression points calculated from bins with less than five scatter points were discarded. The second step was to obtain the percentile line by fitting a regression line through the regression points from all the bins. For this, a weighted linear least-squares regression analysis was used with the regression points weighted by the number of scatter points in the respective bins. Two binning schemes were tested in the analysis. A coarser scheme has, for all pressure levels except 150 mb, a bin width of 2 m·s−1 for Vs or Vt between 0 and 20 m·s−1 followed by a single bin from 20 to 30 m·s−1. For the 150 mb pressure level, the scheme has a bin width of 2 m·s−1 between 0 and 24 m·s−1 followed by a single bin from 24 to 30 m·s−1. An inspection of the scatter points showed none of them falling beyond 30 m·s−1. The finer bin scheme contains smaller bin widths and twice the number of total bins. It has, for all pressure levels other than 150 mb, a bin width of 1 m·s−1 for Vs or Vt between 0 and 20 m·s−1 followed by two larger bins from 20 to 25 m·s−1 and 25 to 30 m·s−1. For the 150 mb pressure level, this scheme has a bin width of 1 m·s−1 between 0 and 25 m·s−1 followed by a single bin from 25 to 30 m·s−1. It was found that the use of either binning scheme did not alter the conclusions of the study. The results presented hereafter in this paper are that obtained for the finer scheme.
For the scatters of
σ2s vs.
Vs,
σ2t vs.
Vt, and
ε vs.
Vt, linear relations were assumed between percentiles of
σ2s,
σ2t,
ε and
Vs/
Vt. The equations of the percentile lines fitted take the form:
In these equations, C, D, E, L, M, and N are fitting coefficients which characterise the percentile lines and that in turn characterise the scatters. Since five percentile lines were fitted for each scatter and eleven scatters, one for each pressure level, were made for each scatter relation, the fitting coefficients obtained can be functions of both the pressure level and the percentile. This is denoted by the subscript %|h: for example, L25%|500 would denote the L coefficient for the 25th percentile line of the 500 mb scatter. The same notation is also used to uniquely identify equations of individual percentile lines as shown by the left-hand-side terms of Equations (11)–(13). In the linear Equations (11)–(13), L, M, and N are coefficients of gradient and they give the correlation between the percentile and Vs/Vt. C, D, and E, on the other hand, are axis-intercept coefficients and they give the value of σ2s, σ2t, ε at each percentile when Vs/Vt approaches 0 m·s−1.
For the scatter relation
η vs.
Vt, however, the percentile lines that would describe the scatters are clearly not linear. An exponential relation, as given by the form:
is proposed instead. Linear fitting of the lines were performed in the logarithmic space using the linearised form of Equation (14) as shown by:
Here, B is the gradient coefficient which indicates how sharply the percentile line tends towards η = 1 whereas A is the intercept coefficient with 1 − A being the value of η at each percentile as Vt approaches 0 m·s−1. If A = 1 (ln A = 0), the percentile line passes through the origin.
4.3. Vertical Profiles of Fitting Coefficients
The results for the fitting coefficients
L,
M,
N,
C,
D,
E,
A, and
B are plotted in
Figure 6,
Figure 7,
Figure 8,
Figure 9,
Figure 10,
Figure 11,
Figure 12 and
Figure 13. As separate scatters were created for each individual pressure level, vertical profiles of the fitting coefficients could be obtained and plotted for each of the percentiles considered. In the plots, the pressure level is plotted on the horizontal axis from a lower level to a higher level while the value of the respective fitting coefficient is plotted on the vertical axis. The results obtained for the different percentiles are represented by markers of different colours. On top of the point-estimated values obtained from the regression analysis, the 98% confidence intervals for each estimate are also given as denoted by the co-located error bars.
In
Figure 6, the point estimates for the coefficient
L are positive at all pressure levels except 1000 mb and 925 mb. Even at these two levels, the confidence intervals obtained do not exclude the possibility of
L being positive. Two further features were observed based on an impressionistic observation of the plot that also takes into account the error bars. First, the value of
L at each pressure level appears to increase with higher percentiles.
This implies that the gradient of the percentile lines in the σ2s vs. Vs scatters increase with the percentile and this is consistent with the earlier qualitative observation that the scatter points appear to fan out from the origin. Next, it was also observed that the value of L for each percentile could be the same regardless of the pressure level. This possibly suggests a constant vertical profile.
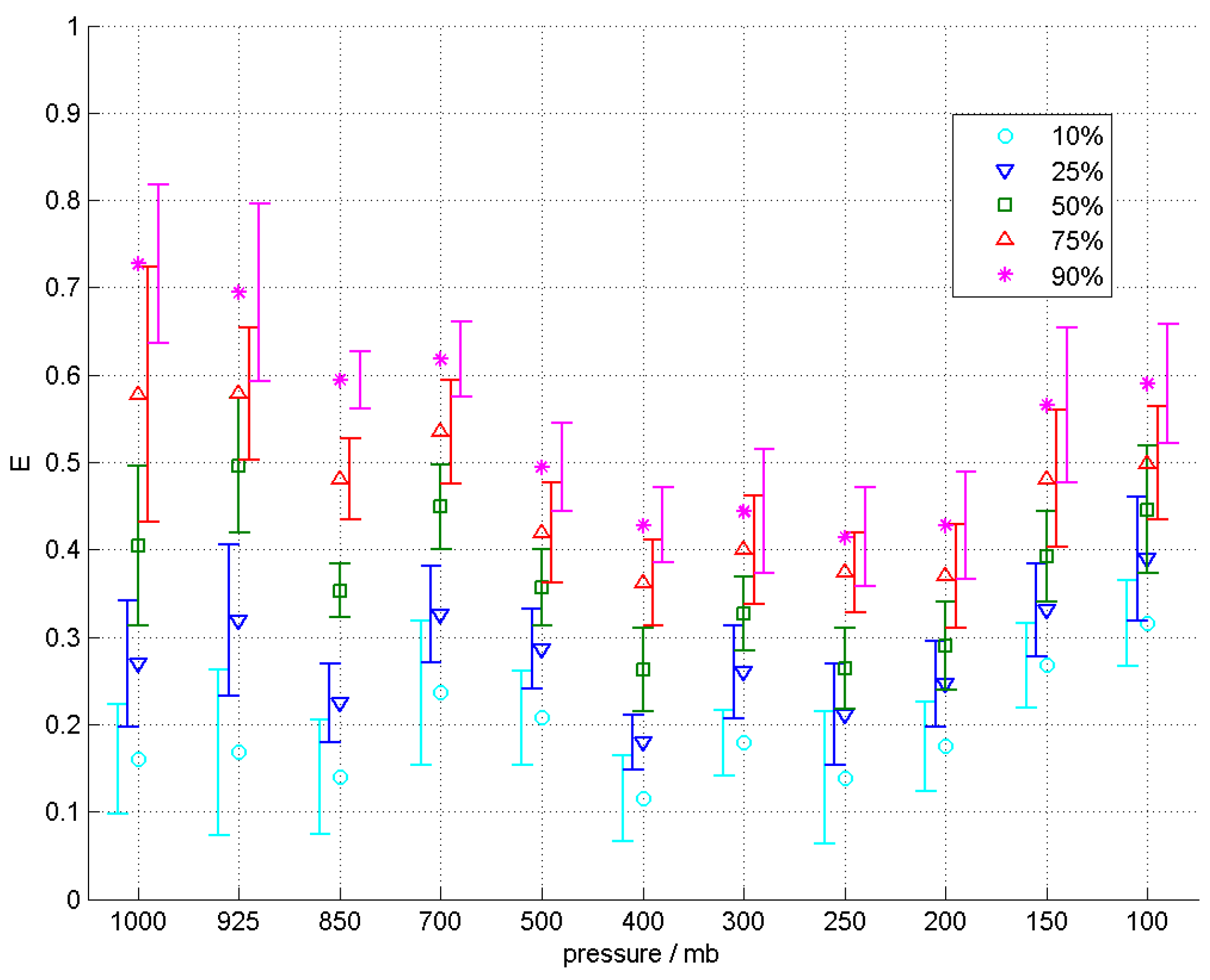
In
Figure 7, the point estimates for coefficient
C are scattered about the
C = 0 line. A similar impressionistic observation of the plot suggests that the value of
C could be zero as many of the error bars do contain the zero line. This implies that the percentile lines in the
σ2s vs.
Vs scatters pass through the origin and this is again in line with the earlier qualitative observation.
For the gradient coefficients
M and
N in
Figure 8 and
Figure 10, respectively, the plots are similar to
C in that the point estimates also scatter about zero and that many of the error bars contain the zero line. This implies that the scatters of
σ2t and
ε do not correlate significantly with
Vt. Also, it was observed specifically in
Figure 10 that the point estimates for
N at the 1000 mb and 925 mb pressure levels are more negative as compared to the other pressure levels.
In
Figure 9 and
Figure 11, the plots of coefficients
D and
E show non-trivial vertical profiles with salient features. This is notable as unlike the other coefficients, the error bars here are generally smaller compared to the overall trends exhibited by the point estimates and this excludes the possibility of a constant vertical profile. The coefficient
D in
Figure 9 shows an increasing trend towards higher pressure levels while the coefficient
E in
Figure 11 shows a gradual decreasing trend up to about the 200 mb pressure level followed by a sharper increasing trend above it.
For the scatter relation
η vs.
Vt, it was observed in
Figure 12 that the point-estimated values for ln
A (and thus also for
A) at each pressure level decrease with higher percentiles. This means that the
η-axis intercept of the percentile lines, given by 1 −
A, increase with the percentile. The observation is expected and in fact necessary for the percentile lines to stack in their proper order as
Vt approaches 0 m·s
−1.
One other feature, noted based on an impressionistic observation of
Figure 12, is that the value of ln
A for each percentile appears to be the same regardless of the pressure level. This implies that the
η-axis intercept of each percentile is the same for all pressure levels. Finally, in
Figure 13, an impressionistic observation of the plot suggests that coefficient
B could be a non-zero constant with a same value regardless of the percentile or pressure level. This, together with the observations made of
A, would imply that the scatters of
η vs.
Vt are characteristically similar for all the pressure levels.
4.4. Simplifying Relations for L, M, N, C, A, and B.
Using the impressionistic observations described above, the following simplifying relations for the fitting coefficients
L,
M,
N,
C,
A, and
B are hypothesised. No such hypothesis was made for the coefficients
D and
E. In the Equations (16) and (20) below, the dropping of
h in the subscript of the right-hand-side terms is to denote that the coefficient is hypothesised to not depend on the pressure level but is still dependent on the percentile.
To examine the validity of the hypothesised relations, the following test was carried out. Consider a single result of a fitting coefficient. Assuming the hypothesised value to be true, the probability of the 100
p% confidence interval (
p = 0.98 in the plots shown above) not including the hypothesised value is 1 −
p. Now, further consider the 55 instances of results, corresponding to the five considered percentiles and the eleven pressure levels, for each fitting coefficient. The probability that
k or more of them do not include the hypothesised value can be modelled by the binomial distribution and is given by:
where
K is the random variable denoting the number of confidence intervals not including the hypothesised value and
n is the total number of instances of results (
n = 55 in this case). Using this logic, if the value of
k observed from the results is such that the probability
p(
K ≥
k) is less than the significance value 1 −
p, it can be concluded that there is sufficient evidence that the hypothesised value is not correct. Otherwise, even though rigourous statistical theory would say no conclusions can be made, for the purpose of this work it is taken that the hypothesised value is sound. Note that the hypothesised values for coefficients
L,
A, and
B are not explicit. For these cases,
k was obtained by selecting a hypothesised value for the coefficient that minimises
k.
Table 2 shows the results for
k for the six fitting coefficients with hypothesised relations. Also given is the value of
kcrit, the critical value of
k such that the hypothesised relation is rejected if
k ≥
kcrit. The results show that the hypothesised relations for coefficients
L,
M,
C, and
B are not supported. On closer investigation, however, it was realised that most instances with non-conforming confidence intervals are for either the higher levels at or above 150 mb, levels near the tropopause, or the lower levels at or below 850 mb, levels within the surface boundary layer or affected by topography. Removing these levels,
Table 3 shows the results for
k considering only the mid-tropospheric levels of 700 mb to 200 mb (with consequent reduction of
n from 55 to 30). These new results show that the hypothesised relations for all the coefficients are sound when considering only the middle troposphere.
4.5. Implications and Discussion
Assuming the proposed relations given in Equations (16)–(21) are correct, some inferences can be made regarding the characteristics of
σ2s with respect to
Vs and
σ2t,
ε, and
η with respect to
Vt. Equations (23)–(26) in the following paragraphs show Equations (11)–(14) rewritten to reflect the simplified relations.
For
σ2s, the coefficient
L says that the percentile lines at each percentile have positive gradients and are the same for all pressure levels. Furthermore, the coefficient
C suggests that all these lines pass through the origin. This implies two things. First, the scalar variance can be expected to increase with the mean wind speed and notably, for the inference to make physical sense, zero variance is expected for a no wind condition (i.e., zero mean wind speed, noting that wind speed is always positive or zero). Second, the scatters of
σ2s vs.
Vs are characteristically similar for all pressure levels. This implies that the scalar variance, while dependent on the wind speed, does not depend on the pressure level.
The characteristics of
σ2t is, in contrast, quite the opposite. The coefficient
M taking zero value implies that the trace of the variance does not depend on the magnitude of the mean wind. Also, the coefficient
D shows a clear vertical profile in
Figure 9 that indicates dependence on the pressure level. Since
M = 0,
D, rather than only being an intercept value, can be regarded as indicative of the value of
σ2t at each percentile regardless of
Vt. The vertical profile of
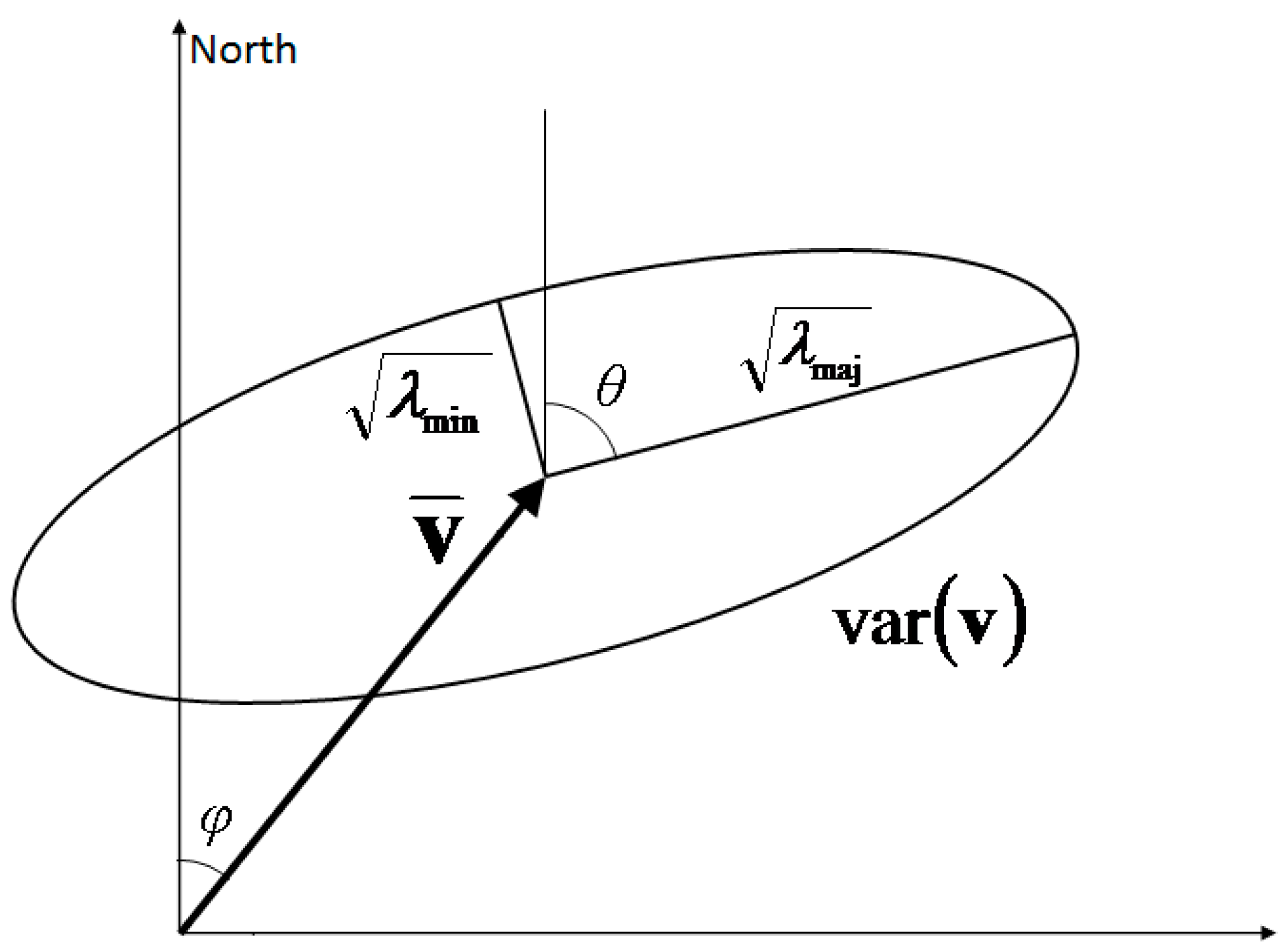
D observed is such that it implies the standard deviation (the size of the ellipse in
Figure 1) grows larger with height until near the tropopause level. This trend could easily be mistaken for an increasing trend with the wind magnitude as the magnitude of the mean wind velocity too increases with height. However, the scatter analysis showed that the dependency is on the pressure level and not the wind velocity.
ε shows similar characteristics to
σ2t in that it does not depend on the magnitude of the mean wind but is dependent on the pressure level. The vertical profile of
E in
Figure 11 shows that the spread of the eccentricity reduces with height as the higher percentile lines approach the lower percentile lines which remain around the same value up to about the 200 mb pressure level. In this sense, the wind variance gets more isotropic with height. But upon nearing the tropopause (at pressures lower than 200 mb), the eccentricity seems to rise while keeping the same spread, denoting increasing anisotropy in the wind variance.
For η, Equations (20) and (21) for coefficients A and B further the description of η by saying that the scatters of η vs. Vt are characteristically identical for all pressure levels. Moreover, the constant value of B across percentile lines lends fundamental support that the spread of η tightens as the mean wind gets stronger and implies a growing tendency for the largest variance to occur in the direction of the mean wind as the mean wind strengthens. This last point is not a logical necessity but seems to be an interesting result of fundamental wind dynamics.
Table 4 and
Figure 14 summarise the characteristics of
σ2s,
σ2t,
ε, and
η on their dependencies on
Vs,
Vt, and pressure level.
The increase of the scalar variance with mean wind speed can be explained by the other three results in
Table 4.
Appendix A proves the following identity:
which implies, using the result in
Table 4 that
σ2t is independent of
Vt:
Thus,
σ2s increases with
Vs (
d(
σ2s)/
d(
V2s) > 0) if and only if
V2s increases more slowly than
V2t (
d(
V2s)/
d(
V2t) < 1) as the mean wind strengthens (
Vt increases).
Appendix B proves that this is indeed so for the case of small variations compared to the mean wind. Here, we offer a consistent, heuristic explanation for the general case. As the mean wind gets stronger, the size and anisotropy of the wind variations (
σ2t and
ε) remain constant but there is greater alignment of the direction of wind variations with the direction of the mean wind, as
Table 4 says. Such alignment leads to more effective variation in the magnitude of the wind vector and so
σ2s increases. With the constraint set by the identity in equation (27),
V2s must increase more slowly than
V2t, or otherwise, decrease. The latter case of decreasing
V2s occurs when there are frequent, large enough variations compared to the mean wind speed: from Equation (28), negative
d(
V2s)/
d(
V2t) implies that
d(
σ2s)/
d(
V2s) = (
σs/
Vs)
dσs/
dVs < −1 and so
σs/
Vs > |
dVs/
dσs|. However, our result in
Table 4 that
σ2s increases with
Vs and hence
V2s is explained by the former case, where the wind variations are sufficiently small most of the time, i.e., qualitatively more like the case proven in
Appendix B.
Some caveats are to be noted when considering the trends inferred above. Firstly, the proposed simplifying relations were shown to be valid only for the mid-troposphere between the 700 mb and 200 mb pressure levels. This means that the trends described are strictly valid only within this same part of the atmosphere. While no specific physical mechanisms will be proposed in this paper to explain the discrepancy at the lower and the higher levels, these excluded levels represent two unique parts of the troposphere. The lower levels at 850 mb and below is within the planetary boundary layer and are affected by the mountainous terrain found in parts of the monsoonal tropics (e.g., Sumatra, Borneo, East Africa). The obstructions caused by topography as well as friction against the planetary surface can cause distortions to wind flow. Similarly, at the higher levels of 150 mb and 100 mb pressure, distortions to the flow dynamics may also happen due to outflow from deep convection near the tropopause. The second caveat is that the results are applicable only within the specified near-equatorial monsoon region for which the radiosonde data for this study have been obtained. As scatter plots were used to derive the trends and implications, the inferred trends can only be considered as an aggregate for the entire geographic region being studied and that the trends observed at specific individual locations may be considerably different.



















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}