1. Introduction
Photovoltaic (PV) solar systems have become very popular due to the fact that they have seen a surge in efficiency and a decrease in price. Energy demand is increasing rapidly due to rapid population growth and industrialization. Conventional sources of energy such as fossil fuels cause environmental problems such as
emission and other environmental issues. This has been subject to international agreements such as the Conference of Parties 21 (COP21) aiming to invest in renewable energy technologies and reduce the emission of greenhouse gases [
1].
However, connecting the energy produced by PV arrays to the power grid is challenging because of high variation in solar irradiance levels. Solar irradiance data is an essential factor to design a solar energy system [
2], and a shortage of irradiance data has led to a downturn in the use of solar energy [
3]. Another issue that should be highlighted is the need for accurate forecasting models to decrease the uncertainty in power generation levels, balance energy generation and consumption, and make solar energy a more reliable source.
In order to tackle these issues, Chiteka and Enweremadu [
4] used a feed-forward neural network with a back-propagation training algorithm. Meteorological data of humidity, pressure, clearness index, and average temperature as well as geographical data of latitude and longitude were used to forecast the global horizontal irradiance (GHI) in Zimbabwe. Data were collected from different locations. A trial and error approach was utilized to determine the inputs, hidden layer size, and transfer function. The results indicated that temperature, humidity, and clearness index had a more significant effect on the forecasting results and a root mean square error (RMSE) of 0.223
and a mean absolute error (MAE) of 0.17
were the results of the proposed model.
Khosravi et al. [
5] forecasted hourly solar radiation in Abu Musa Island, Iran by using two different approaches. The first approach used local time, temperature, pressure, wind speed, and relative humidity as input variables, and the second approach realized forecasting by time series prediction, utilizing previous values of the solar radiance. After comparing different machine learning algorithms, support vector regression (SVR) and multi-layer feed-forward neural network (MLFFNN) were found to generate better results for the first approach and adaptive neuro-fuzzy interface system (ANFIS), SVR, and MLFFNN for the second one in terms of the correlation coefficient (R). However, the study does not discuss the possibility of the utilizing all meteorological and previous values of solar radiance as input variables of the machine learning techniques.
In another study, a radial basis function (RBF) and multi-layer perceptron (MLP) were proposed by Hejase et al. [
6] for the prediction of the GHI in the United Arab Emirates. Different network architectures and different input sets were tested in order to find the best combination of inputs and the best network tuning. The best results were obtained using maximum temperature, mean daily wind speed, sunshine hours, and main daily relative humidity as inputs, and the MLP model demonstrated a better performance in comparison with the RBF model. The research reached a mean bias error (MBE) value of −0.0003
using the MLP model.
In another study conducted by Renno et al. [
7], the power generated by a residential building’s PV system was predicted. An artificial neural network model for prediction of the direct normal irradiance (DNI) and global radiation (GR) was developed using meteorological data of longitude, mean temperature, sunshine duration, total precipitation, daylight hours, and declination angle. Various input combinations as well as different hidden layer sizes and numbers of hidden layers were tested to find the best topology for the network. The study resulted in an RMSE value of 160.3
for the GI and 17.7
for the DNI.
Gutierrez-Corea et al. [
8] investigated the effect of using meteorological data from neighboring stations for forecasting short-term solar irradiance. The study used different network architectures and input parameters to obtain the inputs and tune the network. The results indicated that using data from neighboring meteorological stations up to 55 km as a reference radius increases forecasting accuracy in terms of forecasting until 3 h ahead.
Mellit and Pavan [
9] used artificial neural networks for forecasting of the GHI up to 24 h ahead, where the mean daily solar irradiance and air temperatures were the considered inputs. Different numbers of neurons in the hidden layer were tested with several distributions of data for training and testing data sets. The data were collected from Trieste, Italy.
An artificial neural network (ANN) model was proposed by Amrouche and Pivert [
10] for forecasting of the daily GHI. The data set was provided by the US National Oceanic and Atmospheric Administration (NOAA) for two locations, namely Le Bourget du Lac (45°38′44″ N, 05°51′33″ E) and Cadarache (43°42′28″ N, 05°46′31″ E). The article addresses the problem of choosing a suitable MLP architecture and activation function. The data base was divided to sunny and cloudy days and the results demonstrated higher correlation coefficient for sunny days than cloudy days. The results of the mentioned articles have proved the efficiency of ANNs in forecasting applications.
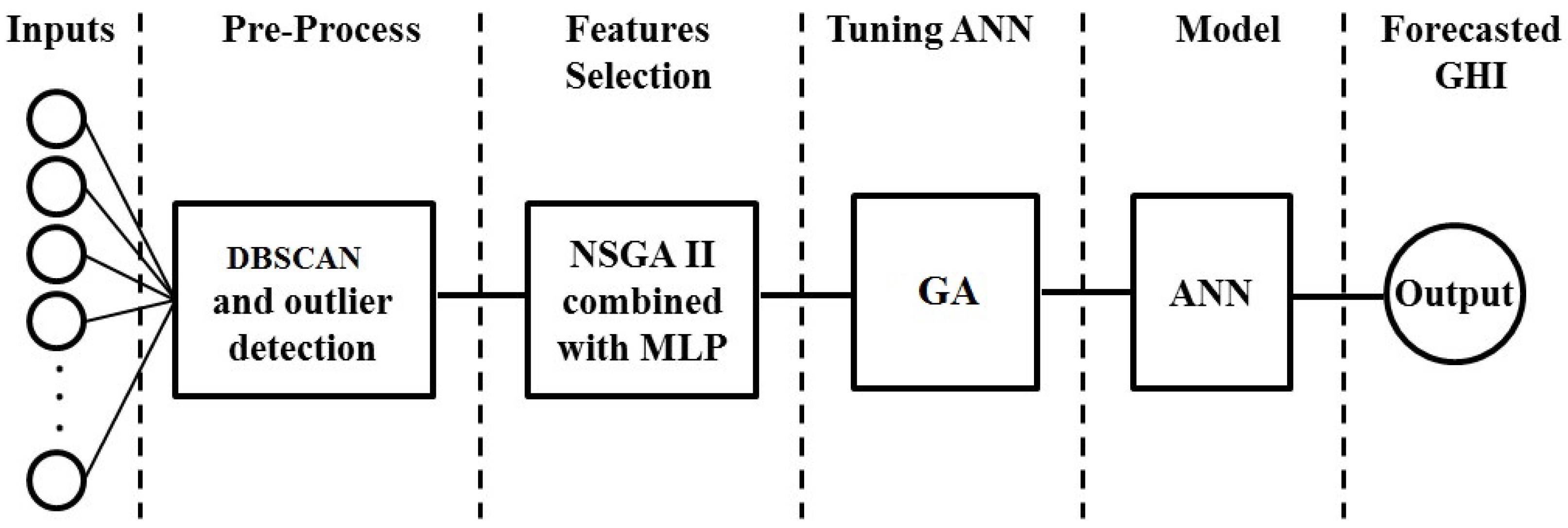
None of the articles mentioned above present a robust method for tuning the ANN and selecting the input parameters. Despite utilizing different machine learning algorithms in previous studies, there is no clear strategy for developing an algorithm which does not need an operator in all steps of the process. The aim of the present study was to develop an algorithm that takes the raw data and generates the results. While in previous studies, different hidden layer sizes, transfer functions, and numerous combinations of input parameters must be tested, in current research the whole process is automatic and has no need of human interference. This research used an MLP as the main algorithm and the parameters to be used as the inputs of the MLP were selected by the non-dominant sorted genetic algorithm II (NSGA II). Meanwhile, the MLP was tuned by a genetic algorithm (GA).
The rest of the paper is organized as follows:
Section 2 describes the methodology, including the location from which data were collected and a brief explanation of the whole process.
Section 3 describes the employed machine learning algorithms. The results are presented and discussed in
Section 4. Finally,
Section 5 summarizes the conclusions of the present study.
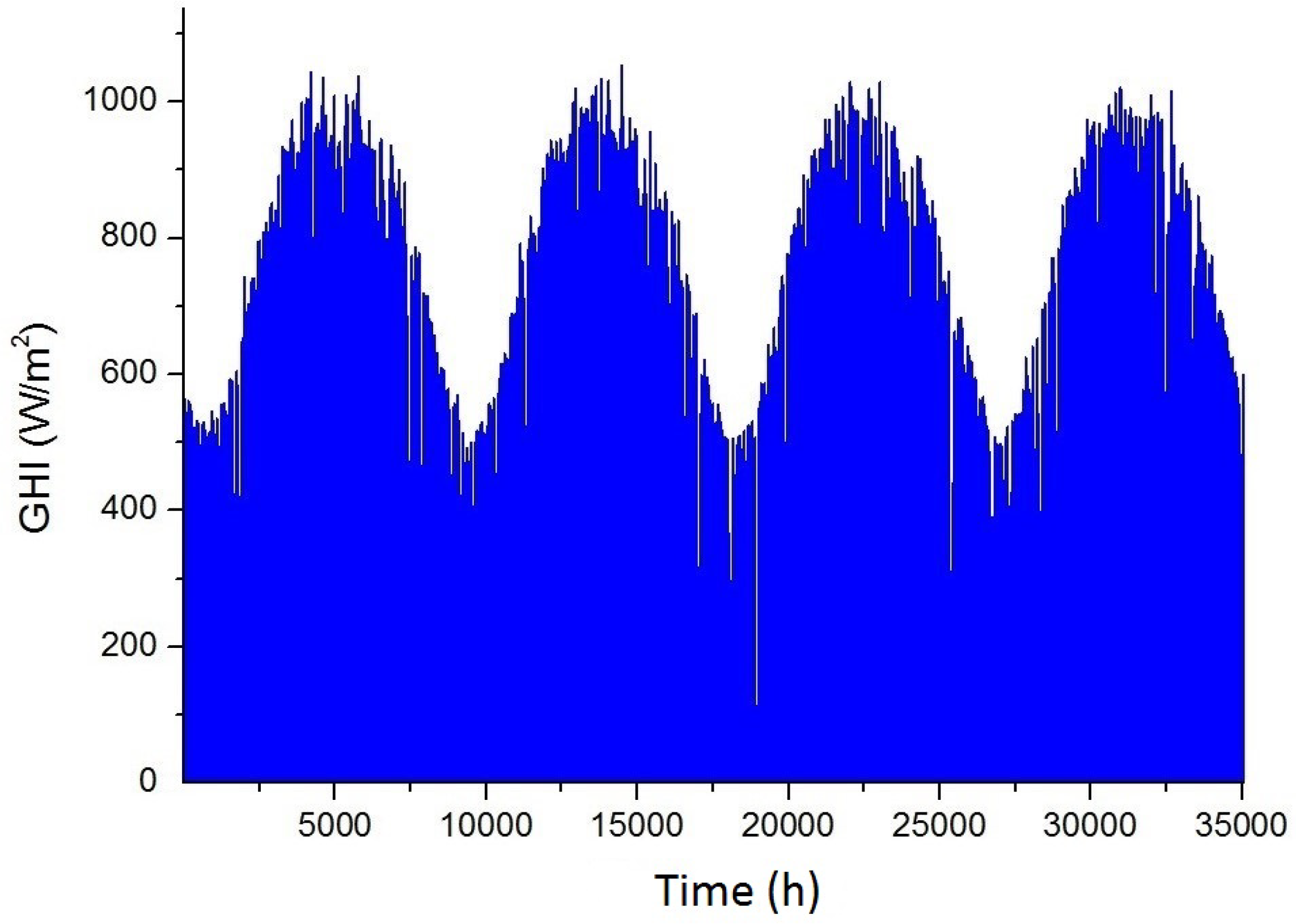
3. Data Pre-Processing
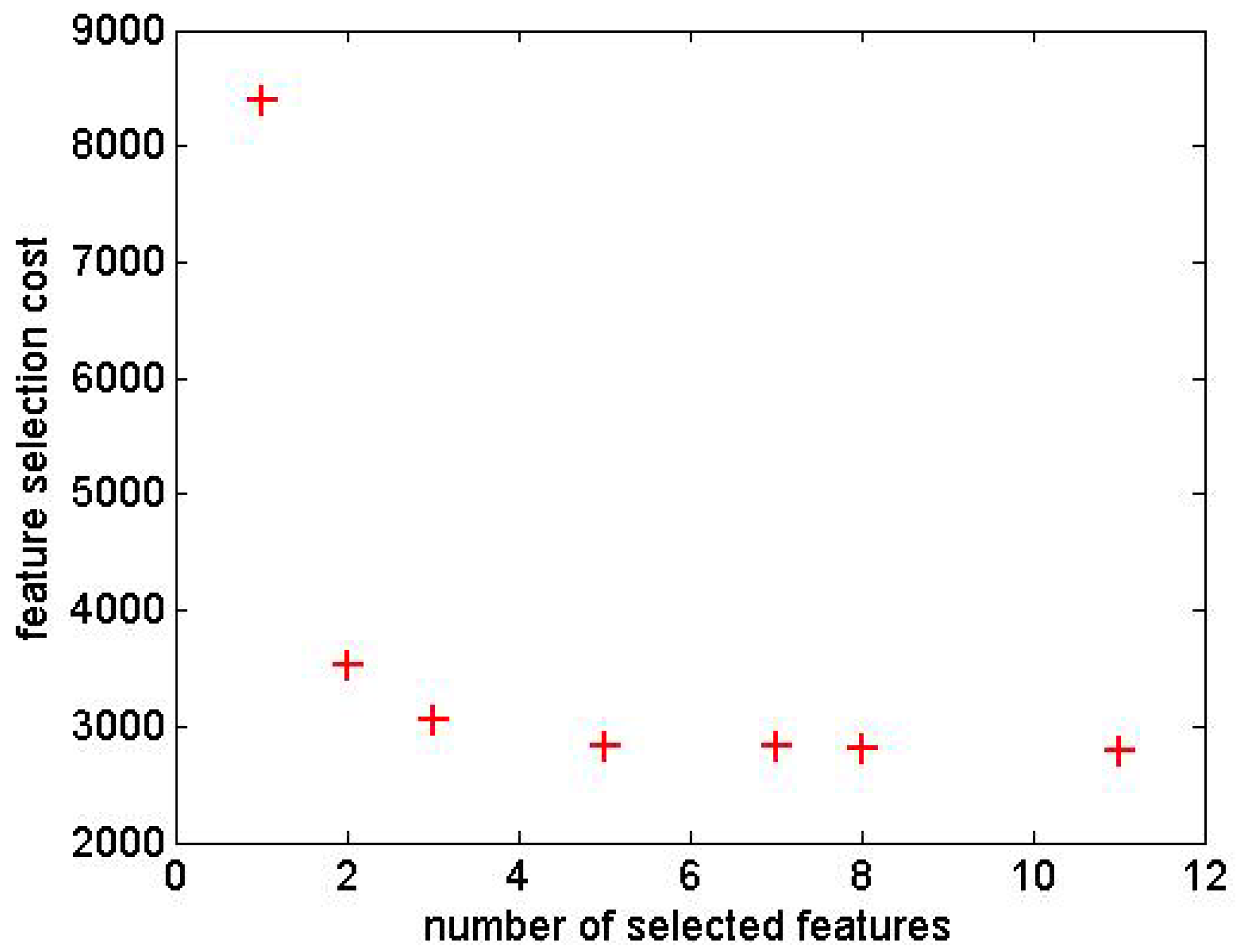
Collected raw data must be pre-processed and prepared to be used as the input of the MLPNN. The first step is anomaly detection. Some of the raw data might be of no use due to extraordinary climate changes or failure of the measuring equipment, and these data need to be eliminated. The employed anomaly detection technique for this study was DBSCAN. Following the detection and elimination of the anomalies (outliers), feature selection is considered to be the next step. Having used all the measured parameters as the inputs of the network, one may still not be successful in terms of accurate forecasting, and some of the parameters might not be useful. Furthermore, in the presence of computational restrictions, the suitable parameters must be selected to guarantee the accuracy of the forecasting. Therefore, the nature of the problem is a multi-objective optimization in which the primary objectives are higher accuracy and fewer input parameters. To help resolve this issue, one approach is the use of meta-heuristic algorithms such as particle swarm optimization (PSO), genetic algorithm (GA), ant colony optimization (ACO), etc. For each number of the parameters, the aforementioned algorithms randomly select the parameters by associating 0 or 1 to each one of them, then the process is repeated to the point of a stopping criterion. Another faster and more accurate approach is the use of multi-objective optimization algorithms. Considering that we are facing a multiple-criteria decision making problem, this study employed an NSGA II algorithm, which is recognized as one of the most widespread multi-objective optimization algorithms.
3.1. DBSCAN
Clustering is the practice of classifying similar objects together based on their similarities. The similarity might be limited to distance. Lloyd’s algorithm, mostly known as k-means, is a good example of this approach, where k is the number of clusters. Lloyd’s algorithm assumes that the best clusters are found by minimizing intra-cluster variance and maximizing the inter-cluster variance [
14]. However, using distance-based algorithms does not necessarily guarantee the success of the clustering, particularly for high-dimensional data, where density-based clustering methods lead to better results. DBSCAN was introduced by Ester et al. [
15], and is one the most effective density-based clustering algorithms. It is able to discover any number of clusters with different sizes and arbitrary shapes. DBSCAN assigns the points to the same cluster if they are density-reachable from one another. This algorithm has three inputs: set of points, neighborhood value (N), and minimum number of points in neighborhood (density).
DBSCAN starts by labeling the points as core, border, or noise points. The point with minimum points in its neighborhood is called a core point. The non-core point with at least one core point in its neighborhood is a border point, and all other points are noise points (outliers) and lie alone in low-density regions. The next step is assigning core and border points to clusters until all points are assigned to a cluster. It is important to note that DBSCAN is sensitive to neighborhood parameters. Choosing a small neighborhood value results in many points labeled as noise, and choosing a high value merges the dense clusters. Examples for core, border, and noise points are shown in
Figure 4.
In the present research, the codes of the DBSCAN were developed in Matlab so as to detect and remove the data with noise from the data set. A previous study for anomaly detection based on DBSCAN can be found in [
16], and more details and codes of the algorithm are given in [
15].
3.2. NSGA II
The NSGA II algorithm was introduced by Deb et al. in 2002 [
17] as an improved version of the NSGA [
18]. It was utilized to solve various multi-objective optimization problems, including input selection [
19]. NSGA II is a population-based algorithm and initializes with a random population. Then, population is sorted based on the value of the cost function in non-dominant order in each front, where individuals in the first front (
) are non-dominant by other individuals, and the second front (
) contains dominated individuals in the population in each iteration.
The GA operators of selection, crossover, and mutation are the next steps of the algorithm. The selection is a binary tournament selection, and is based on the crowding distance and cost value. Higher crowding distance demonstrates higher population diversity. Offspring is created by crossover and mutation operators, and the best N individuals of the offspring population are selected and sorted in non-dominant order. NSGA II depends on parameters like population size, number of iterations, crossover probability, and mutation probability. Some indications to set these parameters are given in [
20].
The algorithm for the non-dominated sort is given in Algorithm 1, where p, P, and Q are the individuals, parent vector, and the offspring vector, respectively. contains the individuals dominated by p, is the number of individuals that dominate p, and i is the number of the ith front.
The procedure for calculating the crowding distance is shown in Algorithm 2. As seen in Algorithm 2, the boundaries have infinite distance and
m is the number of the
mth objective function of the
ith individual in
I. The selection is based on the calculated crowding distance, and after applying crossover and mutation operators, the final step is recombination and selection. To ensure the elitism, the next generation is the combination of the best individuals from the parent vector and offspring vector. The process subsequently repeats to generate the individuals of the next generations, and stops when the stopping criteria is satisfied.
| Algorithm 1 Non-dominated sort |
for each P do for each q P do if < q then ∪ else(q < ) end if if = 0 then = 1 ∪ end if end for end for i = 1 while do Q = for each do for each q do if = 0 then i+1 Q = Q end if end for end for i = i + 1 = Q end while
|
| Algorithm 2 Crowding distance |
H for each i, set = 0 do for each objective m do I = Sort ∞ for i = 2 to (l-1) do end for end for end for
|
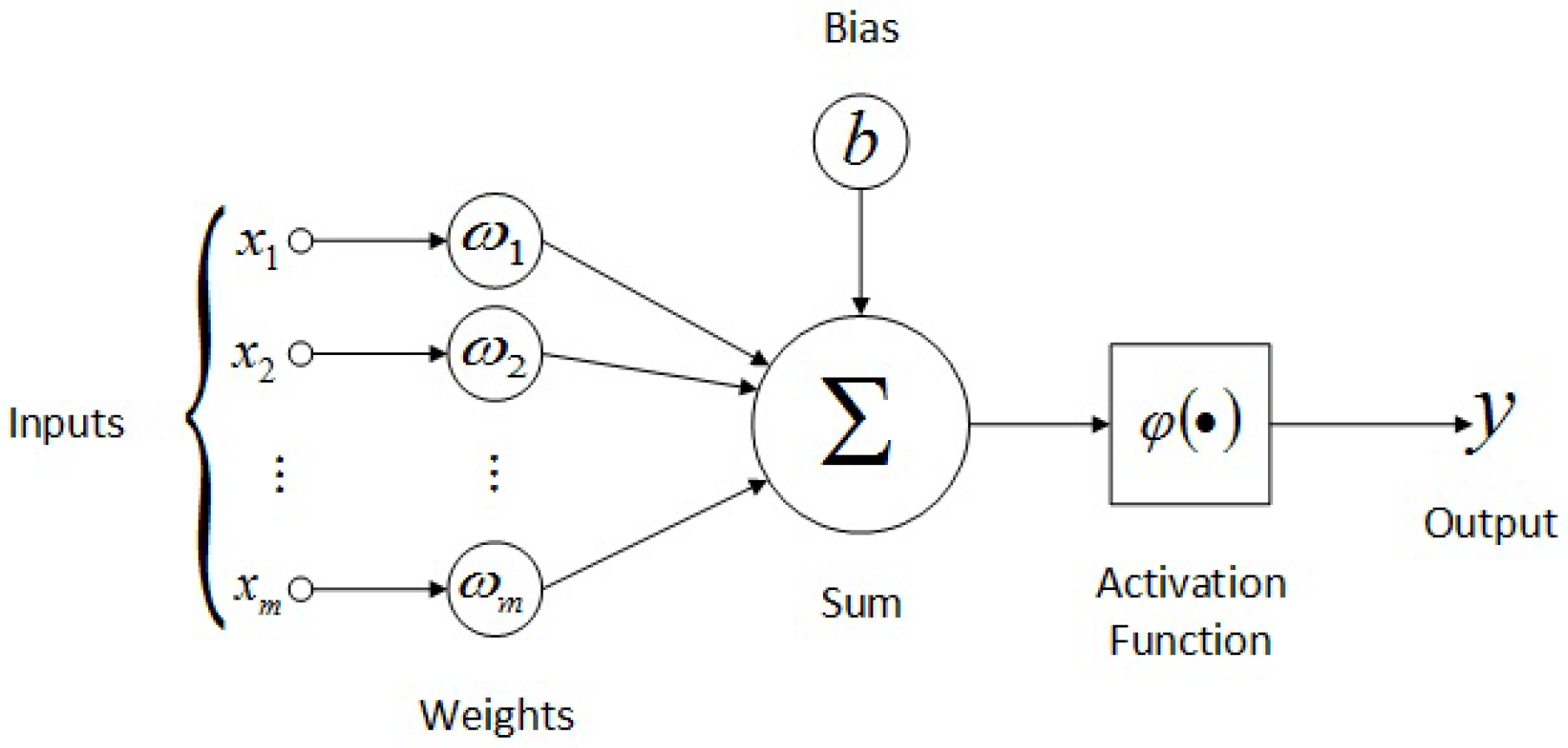
4. MLPNN
As mentioned above, this work employed multi-layer perceptron neural network (MLPNN) to forecast the GHI. An MLP consists of an input layer, at least one hidden layer, and an output layer. Each layer contains processing units (neurons) that perform operations on their input data and send it to the following layers. The number of neurons in input layer is equal to the number of the input variables. In this work, the output layer has one neuron because of the only one desired output (i.e., forecasted GHI). The major challenge lies in choosing the proper number of the neurons in the hidden layer. Furthermore, it must be considered that each input is first multiplied by the corresponding weight parameter and the resulting product is added to a bias to produce a weighted sum [
21]. The resulted weighted sum of each neuron passes through a neuron activation function (i.e., transfer function) to produce the final output of the neuron. The most common activation functions are provided in
Table 1, and the structure of an artificial neuron is shown in
Figure 5.
The process of the adaptation of the weights is known as the training stage. There are several training algorithms, each applied to different neural network models, and the main difference among them is how the weights are adjusted. The present study utilized supervised learning with the back-propagation training algorithm, which iteratively reduces the difference between the obtained and desired output using a minimum error as reference. In this method, the weights are adjusted between the layers by means of the back-propagation of the error found in each iteration.
The tuning discussed in this work, which is realized by the GA and PSO algorithm, consists of choosing the proper hidden layer size and the proper activation function.
4.1. PSO
PSO was developed by James Kennedy and Russell Eberhart in 1995 [
22] and was inspired by the flocking and schooling patterns of birds. It is recognized as a powerful population-based algorithm for optimization. The algorithm is initialized by random particles, and the initial population creates the swarm as presented in Equation (
2):
Unlike algorithms such as GA, PSO does not use selection, and all particles can share information about the search space. Each particle moves in an D-dimensional space and contains a position and a velocity. The position of each particle is described in Equation (
3):
Velocity controls the exploration, and cannot exceed the maximum allowed speed (
). Maximum velocity controls the exploration. Low values result in local exploration, whereas higher values of the maximum velocity cause global exploration. Velocity is adjusted using Equation (
4):
Equations (5) and (6) are used to determine the minimum and maximum velocity to the solution:
and
are the minimum and maximum positions of the particle in the
jth dimension, and
is a constant between 0 and 1.
The particles keep a record of the position of its best performance. Meanwhile, the best value obtained by all particles is stored as the global best. All particles can share information about the search space, and each particle calculates its velocity based on its best performance and the global best. By using this velocity, the particles update their position at each iteration, which is calculated by Equation (
7):
where
w is the inertial weight,
is the personal best, and
g is the global best.
t and
t + 1 indicate two successive iterations of the algorithm, and
is the vector of velocity components of the
ith particle.
and
are constant values. Some approaches to set
w,
, and
are discussed in [
23].
The trajectory of particles towards the optimal solution is defined as Equation (
8):
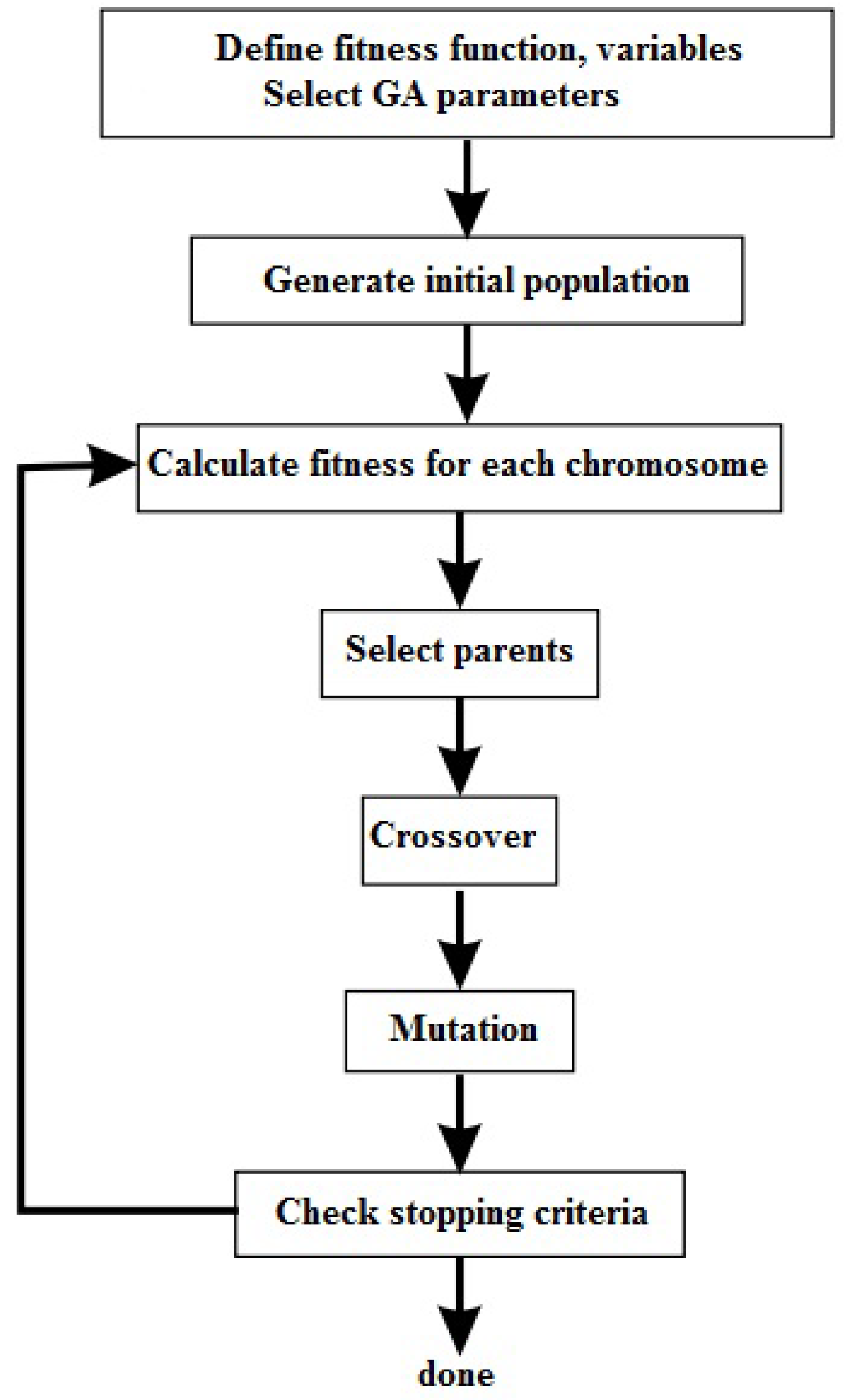
4.2. GA
GA is a meta-heuristic algorithm inspired by evolution of chromosomes and natural selection. It was introduced by John Holland in 1960 [
24], and has been found to demonstrate good performance in solving non-linear optimization problems. GA is originally a binary coded algorithm, and it can be used for solving continuous space problems by applying some modifications to its operators [
25]. The GA used in this research is a continuous GA. It starts with an initial population, and after assigning a fitness value for each chromosome, new chromosomes (offspring) are created from the previous chromosomes (parents), which have better fitness values. Selection of the parents can be done by many techniques, such as roulette-wheel selection, tournament selection, and elitist selection. In the next step, genetic operations of mutation and crossover are applied to the selected chromosomes to generate the offspring. Crossover is the process of dividing two randomly selected chromosomes with the best fitness value and exchanging them to produce new offspring. Various crossover approaches for continuous GA are given in [
26,
27]. Mutation is randomly changing a part of a selected chromosome based on the defined mutation rate, which causes a random change in exploring the solution space. Without mutation, GA converges rapidly and this causes a tendency to converge to a local optimum.
Finally, the generated new population (chromosomes) passes through evaluation and calculation of the fitness value. These steps repeat in each iteration until a termination criterion is satisfied. A flowchart of the continuous GA is shown in
Figure 6.
6. Conclusions
Switching to renewable energy is unavoidable due to various problems caused by generating energy with fossil fuels and nuclear power plants. Among renewable sources, solar energy makes it possible to generate energy with different methods. PV solar energy is one of the methods which is currently of great importance due to its clean and environmentally friendly characteristics as well as decreasing PV cell prices. However, there is still much ongoing research aiming to overcome the challenges caused by PV systems. The current study is dedicated to developing a methodology to make the forecasting of the GHI more reliable. By using the developed methodology, there is no need to adapt new data sets to the currently existing algorithms or to tune the neural network by a trial and error approach. Since the the developed methodology employs an input selection algorithm, it generates results with any given data set containing different variables. Once the inputs are selected and the neural network is trained and tuned, the algorithm is ready to use without any computational complexities.
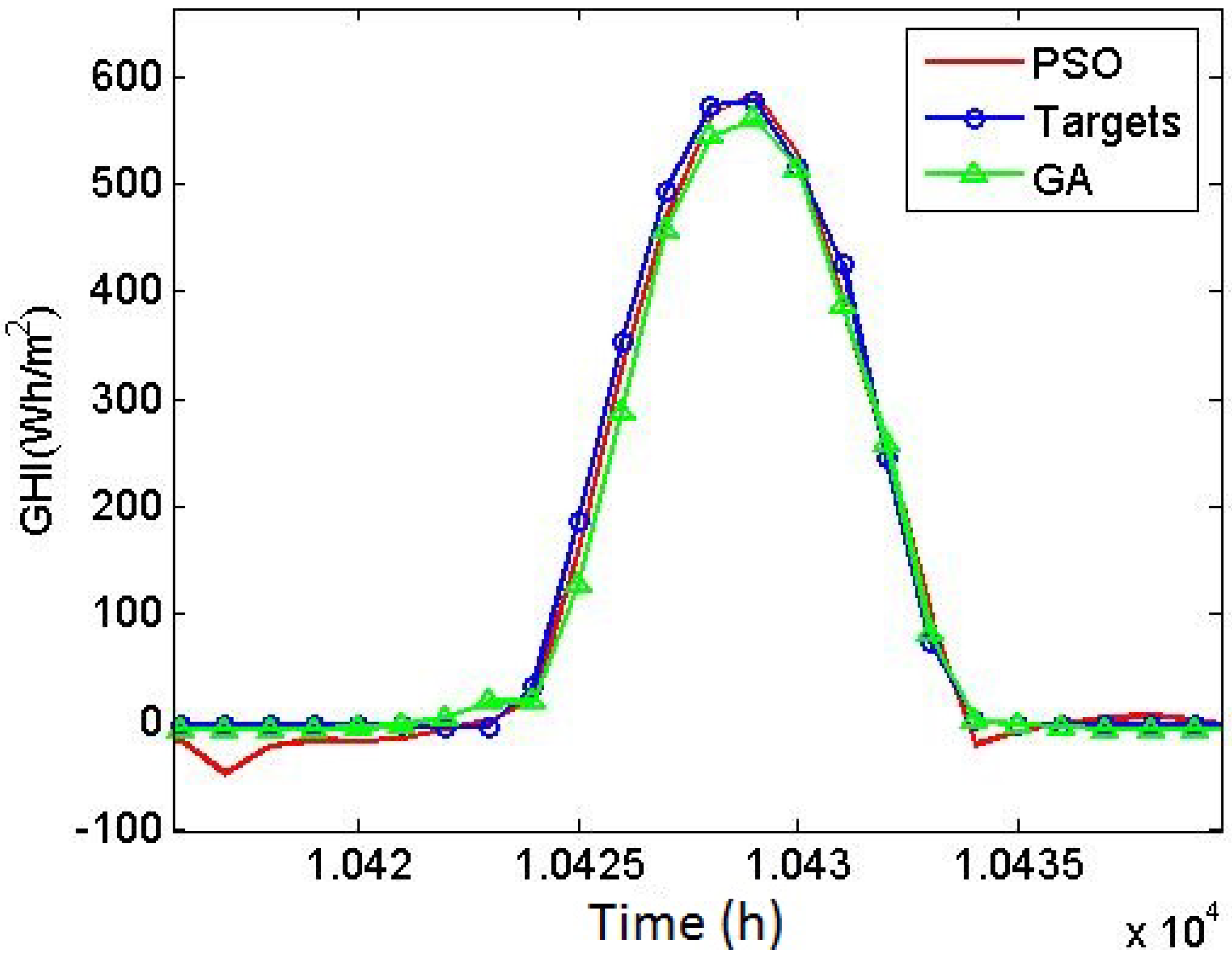
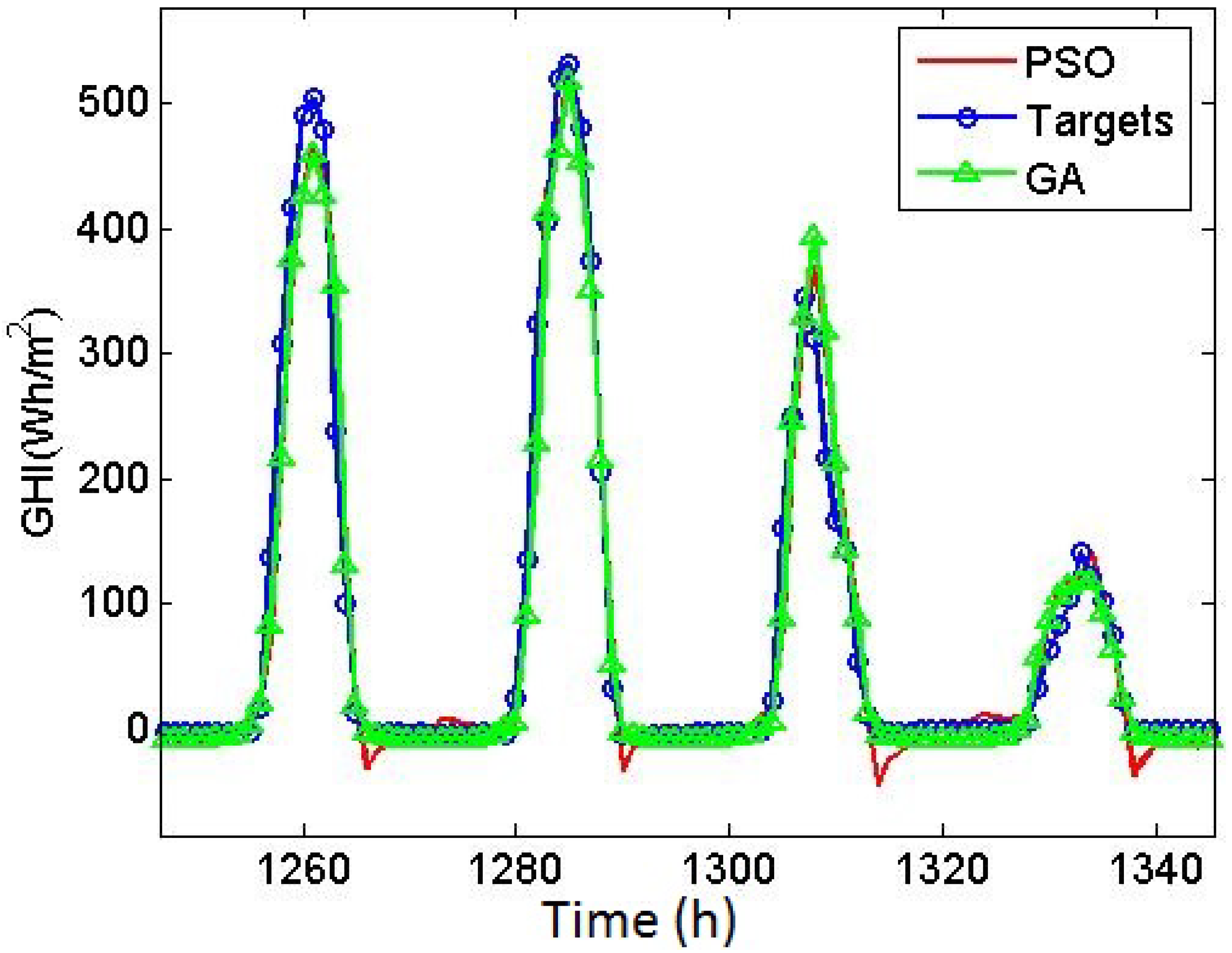
In this paper, a combination of different machine learning techniques were used to forecast the GHI. Anomalies were detected and removed by DBSCAN, and features were selected by NSGA II. A multi-layer perceptron neural network was employed to forecast the hourly GHI, and the tuning of the network was realized by GA, which demonstrated good performance in generating solutions in the explored solution space. This study proves the better performance of the GA over PSO algorithm in terms of the tuning of neural networks.
The uniqueness of this approach lies in employing NSGA II for selecting the inputs of the MLPNN and adapting GA for tuning of the neural network. In previous studies that employed artificial neural networks, there are no specific approaches for addressing these issues.
The validity of the developed model was tested using the data set for Elizabeth City, North Carolina, USA, and the error rates constantly reduced in each stage of applying the methodology. Using this specific data set, the study achieved an nRMSE value of 0.0458, an nMAE value of 0.0238, and a correlation coefficient of 0.9884.














{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}