1. Introduction
Electric Vehicles (EVs) are increasingly important nowadays for environmental reasons. However, their sustainable deployment requires new technology and infrastructures as, for example, specialized charging stations to accommodate large fleets of EVs. There have been considerable research effort on different aspects related to EV charging as, for example, the location of EV charging stations [
1,
2,
3,
4] or electricity price forecasting [
5], among others. Charging scheduling is particularly interesting due to the large charging times often required by batteries and also to the power and physical constraints of the charging stations. Only with the use of smart scheduling algorithms is it possible to make the best use of the available resources and to satisfy the user requirements at the same time [
6,
7].
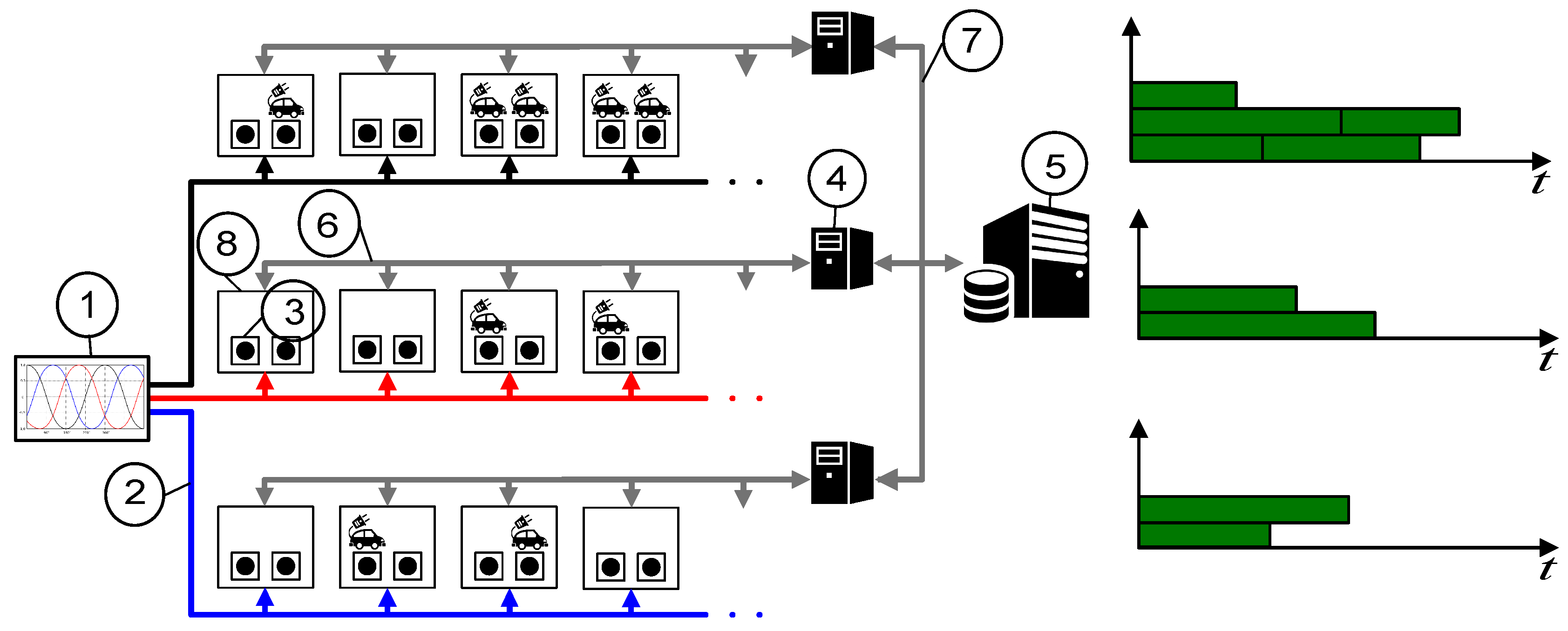
In this paper, we tackle the problem raised in [
8], which is motivated by a charging station designed to be exploited in a residential parking where each vehicle must be parked in its owner’s space. This physical constraint, together with others derived from the electric characteristics of the charging station, makes the problem of scheduling the EV’s charging times over periods of large demand difficult. For this reason, a number of metaheuristics were proposed to solve the problem, in particular dispatching rules [
8], memetic algorithm [
9] and artificial bee colony (ABC) algorithm [
10].
In this paper, we build on the work presented in [
10] and include a number of new contributions, in addition to a thorough updating of the literature review: (1) We introduce several new strategies for both employed and onlooker bee phases, which contribute to improving the performance of the ABC algorithm so that it is able to reach much better solutions; (2) We hybridize the algorithm with an additional local search step, which allows the algorithm to further improve the final solution; (3) We performed a much more comprehensive experimental study using a larger set of instances than that used in previous studies, in which we compare our proposals and show that the new hybrid algorithm was able to improve the quality of the results reported in [
8,
9,
10].
The remainder of this paper is organized as follows: in
Section 2, we review the literature on EV charging scheduling. In
Section 3, we present the characteristics of the charging station considered herein.
Section 4 defines the scheduling problem. In
Section 5, we describe the artificial bee colony algorithm and the proposed enhancements. The results of the experimental study are reported and analyzed in
Section 6. Finally,
Section 7 summarizes the main contributions of this paper and proposes some ideas for further work.
2. Literature Review
EV charging raises challenging scheduling problems. Indeed, the research community has proposed a number of EV charging scheduling models in the last years. Some comprehensive reviews of such problems and solving techniques are given in [
6,
7,
11].
There are two main strategies for scheduling EV charging. The first one is distributed or decentralized strategy [
12,
13,
14], which offers great flexibility to EV owners, allowing them to decide about when and how to charge their EVs. This may give rise to some security problems and overload in the power grid. Some of these inconveniences may be avoided to some extent by imposing some price incentives that stimulate EV owners to charge their EVs in off-peak hours (see, for example, [
15,
16]). However, it is generally difficult to achieve an optimal charging strategy [
17].
The second strategy is centralized charging, in which an aggregator makes all the scheduling decisions as starting time and charging rate of the EVs. In order to build a schedule, the aggregator receives the status of all EVs along with their desired departure times (provided by EV owners) and tries to optimize both the customers satisfaction and the use of the available power [
18]. Most papers in the literature recommend this strategy over the decentralized one. Indeed, some studies demonstrate that a coordinated charging scheme with some valley-filling strategy significantly outperforms uncoordinated charging by suppressing elevated peak load demands on the power grid [
19].
Regarding the objectives pursued, there are a number of strategies. Some papers perform single objective optimization of total cost [
20,
21], total tardiness [
22] or the use of renewable energy sources [
23]. It is also usual to minimize peak demands or grid congestion [
17,
24]. Other approaches consider three-phase power flows and try to minimize the imbalance between phases [
8,
25]. Clearly, in these types of problems, there may be many relevant objectives, and therefore multi-objective optimization is often considered. For example, in [
26], the optimization of the total load variance and EV owners’ preferences is considered. Another interesting example can be found in [
27], where the objectives are the minimization of the costs incurred from being parked, maximization of the revenues offering secondary regulation and the maximization of the vehicle fleet charging station efficiency.
It is important to mention that each environment and EV charging station present particular characteristics, so each of them gives rise to a different model and poses its own scheduling problem. For example, some systems consider varying the charging rate of the EVs [
24], varying power of the charging station [
28], or varying electricity prices [
29,
30]. Other models consider uncertainty and stochastic parameters [
31,
32]. Another issue is whether [
33] or not [
8] the scheduler can decide to which dock each EV is assigned. Some models even consider charging/discharging strategies to optimize the overall process [
34].
Due to the complexity of these problems, many existing optimization techniques have been applied to solve them—for example, linear programming [
35], ant-based swarm algorithm [
12], genetic algorithm [
27], particle swarm optimization [
21,
36], multi-agent based system [
37], estimation of distribution algorithm [
30], moving window optimization [
29], tabu search and GRASP [
38], among others.
As mentioned, the model considered in this work is that proposed in [
8]. This model corresponds to the charging station described in [
39], which is designed to be installed in community parking. In this station, a parking lot has a charging point connected to one of the lines of a three-phase feeder. This, together with the fact that each user must use his own parking lot, gives rise to the main constraint of the model: the load imbalance on the three lines must be limited. The solution proposed in [
8] relies on the use of dispatching rules to meet online scheduling requirements. For this reason, the quality of the solutions is moderate and may be improved as demonstrated in further studies [
22] by means of offline algorithms. Hence, two new approaches were proposed in order to obtain better solutions, memetic algorithm [
9] and artificial bee colony algorithm [
10]. We argue that the results of the later could still be improved with some intensification step. To this end, we propose incorporating problem domain knowledge by local search and some other improvements in different phases of the artificial bee colony algorithm.
5. Artificial Bee Colony Algorithm
The Artificial Bee Colony algorithm (ABC) is a swarm population-based metaheuristic introduced in [
42], which is inspired by the intelligent foraging behavior of honey bees. The method mimics the search for food of three types of foraging bees: employed, onlooker and scout. ABC is often used to solve scheduling problems because of its effectiveness and its good balance between diversification and intensification. A review of its fundamentals and some applications can be found in [
43]. The ABC algorithm was proposed for numerical optimization and so, in principle, the food sources should be encoded by vectors of real numbers in a given interval. However, unlike other similar metaheuristics as Particle Swarm Optimization (PSO), whose variation operators strongly rely on accurate distance metrics between solutions, ABC is easy to adapt to discrete; i.e., combinatorial, optimization. This was done, for example, in [
44] where the authors tackled a variant of the Flow Shop Scheduling problem and encode food sources by permutations of jobs. We use similar coding schema for the EV charging scheduling problem herein.
As shown in Algorithm 1, the proposed ABC algorithm starts creating a number of initial solutions or food sources. Then, it iterates over a number of cycles. In each cycle, several steps are performed: employed bee phase, onlooker bee phase and scout bee phase. The termination criterion is satisfied when the best solution is not improved for a consecutive number of cycles, or if a solution with zero tardiness is reached. Finally, local search is applied to the best solution found so far. The main features and steps of this algorithm are described below.
| Algorithm 1 The Artificial Bee Colony algorithm |
Input An EV charging scheduling problem instance PGenerate the initial population; while Termination criterion is not satisfied do end while Apply local search to the best solution; return The schedule from the best solution reached;
|
5.1. Food Source Representation and Evaluation
We encode solutions; i.e., food sources, as permutations of EVs. In the static problem, all EVs of the problem are considered as the algorithm is applied only once to solve the problem. However, in the dynamic problem, the algorithm is applied to solve each instance and so the permutation contains only the EVs at that do not start to charge. Each solution has an associated value, , which is the number of times it was tried to improve without success.
To evaluate a food source, a schedule
S is built from the permutation by sequentially scheduling the EVs at the earliest possible starting time such that all the constraints defined in
Section 4 are met with respect to the EVs previously scheduled. The amount of nectar (the measure of quality of a solution) is the value
, where
is the tardiness of the solution calculated by Equation (
5). Abusing the language, in the following, we will use the symbol
S to denote both the schedule and the permutation of EVs corresponding to a given solution.
5.2. Initial Population
We propose combining two dispatching rules with some random food sources to create an initial population. The goal is to achieve good balance among quality and diversity. The first dispatching rule is the Due Date Rule (DDR), which sorts all vehicles in increasing order of their due dates
. The second is the Latest Starting Time (LST) rule, which sorts all vehicles in increasing order of their latest starting times, defined as
. Both rules are deterministic, so we follow the approach proposed in [
22] to create diverse food sources. To add the next vehicle to the permutation
V, we sort the vehicles not yet added to
V using the corresponding dispatching rule and then we perform a tournament selection: a number
of vehicles is selected uniformly and the best of them according to the ordering given by the dispatching rule is added to
V. As we will see, the parameter
is actually relevant: too large values generate too similar food sources, whereas too small values generate almost random ones. To build up the initial population, one third of the individuals are generated by each dispatching rule and the other third at random.
5.3. Employed Bee Phase
Employed bees are in charge of searching for new and hopefully better food sources. To this end, in the original ABC algorithm, each employed bee generates one new candidate solution in the neighborhood of the solution in one food source. The new candidate replaces the old solution if it is better. In our algorithm, we propose exploiting crossover operators borrowed from genetic algorithms following two different approaches.
In the first one (denoted ), the best solution found so far is selected, unless it was already selected in previous cycles. In that case, we choose the food source with the largest such that it was never chosen for this role. This requires maintaining the list “common parents” containing the solutions that were already chosen. Then, the food source in each employed bee is combined with the selected food source, generating two new offspring. The best of them replaces the food source in the memory of the employed bee if it is better; in that case, is set to zero for this food source; otherwise, the original food source remains in the population with increased in one unit. The rationale of this method is that it may produce good solutions as a solution that was not improved after many trials may be a good solution. At the same time, it may produce reasonable diversity, as new solutions are always created from different outstanding food sources in successive cycles of the algorithm.
In the second approach (denoted ), we randomly shuffle the food sources of the population and organize them in pairs to be combined. Thus, all food sources in the population are combined. In this way, the diversity is expected to be larger than in the first method at the cost of lower quality.
We consider different crossover operators to combine solutions. The first one, which is specially designed for this problem, is the Starting-time Based Crossover (SBX), initially proposed in [
22]. It randomly selects a time
(where
is the minimum starting time of all vehicles in both parents and
is the maximum starting time), and builds the first offspring
with all the EVs in the first parent
that are scheduled before
, in the order they appear in
, followed by the remaining EVs in the same order as they appear in
. The second offspring
is created similarly by exchanging the roles of
and
. The second operator is the classic Partially-Mapped Crossover (PMX) proposed in [
45], which is commonly used in permutations encoding. In addition, we consider a third option that consists of choosing SBX or PMX at random each time. In [
10], it was proven that this method obtains better results than using each operator separately. In
Section 6, we report results from some experiments carried out to compare all these options.
5.4. Onlooker Bee Phase
Employed bees share their information with onlooker bees waiting in the hive. Then, onlooker bees probabilistically choose their food sources to go. Once there, they try to find a better neighboring source. In particular, the probability to choose a food source
k in this phase is
Notice that, in this case, divisions by zero will not be produced as the algorithm ends as soon as a solution with zero tardiness is reached.
We propose different ways to apply the onlooker bee phase, which are adapted to the EV charging scheduling problem. The rationale is trying to schedule a vehicle with tardiness earlier or to delay a vehicle without tardiness.
The first one, termed
, is a generalization of the procedure proposed in [
10], which selects at random up to the
of the EVs in the permutation
. For each selected EV,
, its tardiness is checked. If it is zero,
could possibly be delayed; therefore we try to swap
with all the EVs from its position onwards, until an improving solution is found. However, if the tardiness is positive
is swapped with the previous ones instead. In any case, as soon as an improving solution is reached, it replaces the original one and
is set to zero. Otherwise, the original solution remains and
is increased in one unit.
In this paper, we enhance this procedure by using two parameters:
and
. As soon as we find a swap that leads to a better solution, we set
, and we repeat the process from this new solution, unless we have reached the maximum of
improvements. On the other hand,
is used so that not all swaps are tried, but only a swap for every
vehicles. This new proposal may be better than that in [
10] because the parameter
allows for increasing the intensification (of course at the cost of increasing the computational time), whereas the parameter
allows the algorithm to reduce the computational time, as it avoids testing all candidate swaps. The enhanced procedure is denoted
and it is showed in Algorithm 2. The proposal described in [
10] would be a particular case taking
and
.
| Algorithm 2 First type improvement for the onlooker bee phase |
| Input A solution S and parameters and |
| ; |
| ; |
| while and do |
| Select one vehicle randomly; |
| ; |
| if tardiness of then |
| ; |
| else |
| ; |
| end if |
| while and and do |
| Swap and in S to obtain ; |
| if is better than S then |
| ; |
| ; |
| end if |
| if tardiness of then |
| ; |
| else |
| ; |
| end if |
| end while |
| ; |
| end while |
| return The current solution S; |
The second way to apply the onlooker bee phase (denoted ) chooses EVs to move earlier or to delay depending on the structure of the schedule. Firstly, it considers whether to schedule tardy EVs earlier or to delay EVs without tardiness. This selection is done with probability proportional to the number of tardy EVs. For example, if 20% of EVs have zero tardiness, then we have 80% probability of trying to delay non tardy EVs and only 20% of trying to schedule tardy EVs earlier. The rationale behind this strategy is that when there are many tardy EVs, delaying some non tardy EV gives the chance for a large number of tardy EVs get scheduled earlier—while in situations with a small portion of tardy EVs, it is better trying to schedule earlier one of them each time. Furthermore, an additional control parameter determines the maximum number of swaps that we try for each single EV, so that it helps with further reducing the computational time. The detailed procedure can be seen in Algorithm 3.
5.5. Scout Bee Phase
When a solution cannot be improved after trials, its food source is abandoned and a scout bee is in charge of looking for a new source. To implement the scout phase, we replace all solutions having by random ones, and set for each of them.
| Algorithm 3 Second type improvement for the onlooker bee phase |
| Input A solution S and parameters , and |
| ; |
| random number in [0..1]; |
| ; |
| ; |
| while and do |
| if then |
| Select uniformly one non tardy EV ; |
| ; |
| else |
| Select uniformly one tardy EV ; |
| ; |
| end if |
| ; |
| ; |
| while and and and do |
| Swap and in S to obtain ; |
| ; |
| if is better than S then |
| ; |
| ; |
| ; |
| end if |
| if then |
| ; |
| else |
| ; |
| end if |
| end while |
| ; |
| end while |
| return The current solution S; |
5.6. Local Search
It is well known that hybridization with local search usually improves the results of an evolutionary metaheuristic, providing extra intensification [
46,
47,
48]. Here, we propose applying a hill climbing procedure to the final solution reached by a ABC algorithm in the following way: we iterate over the EVs in the order they are scheduled and if the EV in position
i (
) is tardy, we try to schedule it earlier, just before each one of the
previous EVs in the schedule, where
is a parameter. If an improving solution is reached, it substitutes the previous one and the iterative process is started again. The local search finishes when no improving solution is reached in a whole iterative process. The parameter
is given a small value for the sake of efficiency and to introduce reasonably small changes in the neighboring solutions. Notice that the number of EVs for which
is swapped depending on the position
i; the rationale is that the chances of a EV being scheduled earlier in an improving schedule is in direct ratio with the position in the schedule. Algorithm 4 shows the detailed steps. In
Section 6, we will see that this additional local search improves the results of the algorithm, and the extra computational time taken is small due to the fact that it is only applied to the best solution returned by the ABC algorithm.
| Algorithm 4 The local search |
| Input A solution S and the parameter |
| improvement ← True; |
| while improvement do |
| improvement ← False; |
| ; |
| while do |
| if tardiness of then |
| ; |
| ; |
| local_improvement ← False; |
| while local_improvement do |
| Swap and in S to obtain ; |
| if is better than S then |
| ; |
| improvement ← True; |
| local_improvement ← True; |
| end if |
| ; |
| end while |
| end if |
| ; |
| end while |
| end while |
| return The current solution S; |
6. Results
We have considered the benchmark proposed in [
8] (publicly available in [
49]), which consists of 2160 instances organized in 72 sets of 30 instances each. This benchmark is inspired in a prototype charging station with 180 spaces. The profiles of arrival times, demands and due dates correspond to the expected behavior of real users under different circumstances. The time horizon is one day and three different scenarios were considered: scenario 1 represents a normal week day, where vehicles arrive throughout the day, with two arrival peaks. Scenarios 2 and 3 represent more complex situations where the arrival time of most of the vehicles is at almost the same time. Scenario 3 having tighter due dates than scenario 2. Each set is characterized by the tuple
;
has two possible values 1 and 2, in type 1 instances, one third of the vehicles arrive to each line, whereas in instances of type 2 the loads are unbalanced so that 60% of the vehicles arrive to line 1, 30% to line 2 and 10% to line 3. This unbalance among the lines makes type 2 instances harder to solve due to the difficulty in maintaining the constraint of maximum imbalance. Three values are considered for
n, 20, 30 and 40, and four values for
, 0.2, 0.4, 0.6 and 0.8.
The proposed algorithm is implemented in C++ programming language using a single thread, and the target machine is Xeon E5520 running Scientific Linux 6.0. Due to the stochastic nature of the ABC algorithm, 30 independent executions were done for each instance to obtain statistically significant results.
For the purpose of comparison, the main reference is the EVS algorithm proposed in [
8]. After EVS, some new approaches were proposed, namely a Memetic Algorithm (MA) [
9] and an Artificial Bee Colony (ABC) [
10], which were able to improve the quality of the solutions from EVS at the cost of taking more execution time. Here, it is important to remark that there are prototype implementations of the charging station, but there are no actual implementations in a real parking yet, and so all previous experimental results considered were obtained by simulations.
To set up the best values of the parameters of the algorithm, we have conducted some experiments using a set of 24 instances, namely the first instance of each group of scenario 1. For all experiments, the stopping condition was adjusted so that the computational time of the different configurations was similar and comparable to that of other state-of-the-art algorithms.
Table 1 summarizes the values tested for each parameter and the best values of the parameters for the static and dynamic versions of the problem.
Using the proposed parameter setting, which is shown in the columns “best static” and “best dynamic” of
Table 1, and considering 25 consecutive iterations without improving the best solution obtained so far as stopping condition, we see that the convergence pattern is appropriate. As an example,
Figure 2 shows the evolution of the total tardiness in a run of one scenario 1, type 1 instance with
and
, considering the static version of the problem.
From the results in
Table 1, we may draw some interesting conclusions. For example, the second improvement proposed for the employed bee phase (
) performed better than the method
proposed in [
10]. Perhaps this is due to a larger diversity on the generated offspring. In addition, the best configuration for the onlooker bee phase (
with
and
higher than one) performs better than that proposed in [
10] (which uses
and
). It is also worth to mentioning that the final local search step is able to improve the final results of the ABC algorithm when using similar computational times in the comparison.
Using the best configuration reported in
Table 1, we have performed experiments across the full benchmark with 2160 instances.
Table 2,
Table 3 and
Table 4 report the results in scenarios 1, 2 and 3, respectively. For scenario 1, we report the results obtained by MA [
9], ABC [
10] and hABC. For the EVS algorithm [
8], we only report tardiness values obtained for the dynamic problem, as that paper does not tackle the static one. For scenarios 2 and 3, we only show tardiness values from hABC along with those reported for EVS [
8] and MA [
9] on the dynamic problem. As in [
10], there are no results reported from ABC on these scenarios. Each value in the Tables represents the sum of the tardiness (in hours) of the 30 instances of each group. The numbers in bold indicate that the best value for each version of the problem.
As it can be expected, the results reported in
Table 2,
Table 3 and
Table 4 show that the tardiness values strongly depend on the problem characteristics
,
,
n,
. Instances with lower
n and
values present larger tardiness, which seems reasonable as these instances are much more constrained. Type 2 instances have larger tardiness than those of type 1 because of the bottleneck caused by the unequal distribution of EVs in the three lines. In addition, instances of scenario 1 have the lowest tardiness due to the EVs’ arrival being evenly distributed along the day, which allows for scheduling many EVs without tardiness. In addition, the tardiness obtained in static problems are generally much lower than those obtained in dynamic ones, which suggests that knowing in advance all the information allows the algorithms to obtain better schedules and that there may still be room to improve the solutions of the dynamic problem.
From
Table 2,
Table 3 and
Table 4, it is also clear that ABC outperforms ABC [
10] and EVS [
8] in all groups of 30 instances with the same values of parameters
n and
, in both the static and dynamic versions of the problem. hABC also outperforms MA [
9] in most cases, although the differences in the static problem considering scenario 1 are small. In order to assess that the improvement is statistically significant, following [
50], we have performed non-parametric statistical tests for cases where we have multiple-problem analysis. First of all, a Shapiro–Wilk test confirmed the non-normality of the data. Then, we used paired Wilcoxon signed rank tests to compare the average results in all instances. In both the static and dynamic versions of the problem, we have obtained
p-values lower than 2.2 × 10
−16 against the other three state-of-the-art approaches. These tiny
p-values confirm that the improvements in these instances are statistically significant, and so we can tell that hABC performs better than the other methods. If we perform a more detailed analysis, we find that specifically in type 2 instances from scenario 1 in the static version, the difference in the results obtained by hABC and MA is not statistically significant (the
p-value when assessing if hABC is better than MA is 0.5735, and it is 0.8531 the other way around). In all other cases, hABC is always significantly better.
In order to visualize the structure of the schedules and to appreciate how the difficulty of the problems strongly depend on the different loads of the three lines, we show two complete schedules (types 1 and 2 respectively,
and
in both cases) for the dynamic problem in
Figure 3 and
Figure 4 (more schedulesare included in the complementary material of the paper). The schedule in
Figure 3 shows a normal situation where the load is balanced in the three lines so that all EVs are scheduled almost without tardiness and at the same time the maximum imbalance (
) is only reached over small periods of time. However, the schedule in
Figure 4 represents an extreme situation (which probably will not happen in the real environment) where EVs are unevenly distributed on the lines. As a consequence, the imbalance is at a maximum over almost the entire scheduling horizon and the tardiness in line 1 is very high due to the low load in lines 2 and 3. For this reason, the charge of EVs in line 1 is delayed up to one day more than in the schedule of
Figure 3.
The EVs charging scheduling algorithm must be run in a real-time setting, and so it is quite relevant to consider its computational cost. Thus, we should check if hABC requires much lower time than 120 s to solve any instance of the dynamic problem, as this is the time lapse between consecutive instances (see
Section 4.2). We have seen that the instances requiring the most computational time are those of type 2,
and
(see
Table 5). The average time required by hABC to solve an instance having those parameters was 1.88 s, being 12.34 s in the worst case. Clearly, these times are much lower than two minutes and hence we can conclude that hABC can be used in the real setting. The other metaheuristic methods require similar computational times: MA [
9] took an average of 1.23 s per instance and 10.26 s in the worst case, and ABC [
10] required 1.97 s in average and 15.03 s in the worst case. On the other hand, EVS [
8] is the fastest algorithm, taking less than 0.012 s in all runs, although it also obtained the worst results; this is reasonable due to using simple dispatching rules.
Regarding the static version of the problem, the computational time required by hABC is also comparable to that of the other metaheuristic approaches. In
Table 5, we report the average running times for scenario 1 instances, depending on the instance type and the parameters
n and
, in both the static and dynamic versions of the problem. We have to remark that the values of the dynamic problem represent the total execution time for solving all instances (up to 720 in the 24-h period) each one with the EVs in the station that have not started to charge at the scheduling point, whereas in the static problem there is only one large instance with all EVs over the whole time horizon. It is also worth to noting that, in the dynamic problem, all EVs that have not yet started to charge have to be rescheduled, and so the same vehicle may appear in several consecutive instances, which also justifies larger values than those of the static version, particularly in type 2 instances. For all the above, the comparison of the times required to solve the static and dynamic problems lacks real significance. What is really relevant is the gap between their tardiness, which provides some hints about how much the solution of the dynamic problem could be further improved with powerful algorithms or just by having some knowledge on EV arrival.







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}