1. Introduction
With the increasing population, the introduction of new electrical and electronic gadgets in daily lives has increased the demand for electricity. Global warming and the emission of carbon dioxide are challenges for power production. Unfortunately, more than 65% of electricity is wasted during production, transmission, and distribution [
1]. The power wastage is controlled by bidirectional communication between the supply or production side and consumer or demand side. The Smart Grid (SG) is a modernized electric grid that uses advanced Information and Communication Technologies (ICTs) on demand and supply sides. The consumers are educated to optimize their energy demands according to electricity tariff. Moreover, the load demand is reduced on the supply side by introducing Micro-Grids (MGs) with cheap electricity production and storage. Many new concepts which include Electric Vehicle (EV) charging and discharging, Advanced Metering Infrastructure (AMI), elastic load management and smart appliances [
2] have been proposed by the researchers for efficient use of electricity. The home with smart appliances is called Smart Home (SH).
Variety of load optimization techniques are used on the demand side to minimize energy-consumption cost. Electricity prices are high during peak hours due to high production cost. The load of appliances is shifted from peak to off-peak hours to shave the peak load on the supply side and reduce the cost on the demand side. However, load-shifting compromises consumer satisfaction. Cheap, uninterrupted, and self-sufficient power-producing MGs are introduced on the demand side to resolve the user-satisfaction issue. However, MGs with Renewable Energy Sources (RESs) have an intermittent nature and are complex to maintain. Energy storage companies have been developing scenario-based flexible, reliable, and cheap energy demand solutions [
3].
When a SH is connected with the utility then it has to optimize its load demand according to utility tariff. Demand response is a program in which the consumer changes the behavior of power consumption according to the utility tariff [
4]. These programs play an important role in maintaining the sustainability of the SG. The consumers are also informed when and how to use electricity. For efficient and on-time energy management on the demand side, the utility provides predicted electricity market pricing [
5]. Similarly, varying the demand of electricity causes fluctuation in pricing. Therefore, behavioral- and time-varying electricity prices are calculated and informed to consumers [
6]. A huge number of requests from the demand side is received on supply side. The development of the Internet of Things (IoT) technology has enabled consumers to share information of energy consumption with the supply side autonomously. Similarly, the supply side also shares the tariff details with the demand side. The home energy-management program optimizes the load of appliances to reduce the load on supply side. The huge requests from the demand side need to be processed, which requires a huge computing system. The huge requests from the demand side are processed on a cloud-based system [
7]. The energy supply and consumption is optimized with IoT-based devices and cloud-based energy management.
Autonomous and intelligent energy management, with distributed energy sources for the demand side to mitigate the load on the supply side, is the requirement of modern SG. The reliable and efficient communication network with computing infrastructure for efficient and robust power management in SG is necessary. A huge number of requests from the demand side is generated every day and computing needs for these requests can be met with cloud computing [
8]. However, cloud computing suffers from delay, load request congestion, huge data computation and communication cost. The physical distance of the cloud platform from the end devices is the main cause of latency.
Fog computing extends the computing services on the edge to mitigate cloud load. The challenges of cloud computing are resolved with fog computing. Fogs are placed near the end devices which provide near-real-time response. Fog computing has characteristics of low latency, locality, geographic distribution, the mobility of end devices, high processing, wired and wireless connectivity, and heterogeneity [
9]. The SG requests from the demand side are executed and responded back on the fog in near real time. However, in this paper, the cloud-fog-based system model is proposed for distributed clusters of residential buildings in different regions to process their requests. The performances of the fogs are enhanced with a proposed New Service Broker Policy (NSBP) and a load request balancer. MGs are placed near each fog, which controls maintenance or recurring cost. The sum of Virtual Machines (VMs) cost, Data Transfer (DT) cost and recurring cost of MG comprise the system cost, which is added in the consumer bill.
1.1. Motivation
The MGs with RESs and storage systems on the demand side provide cheap and uninterrupted power supply. Multiple small MGs are joined, or a large-size MG is developed to meet the multiple SHs and communal energy demands. The cost of energy consumption is also optimized to use the cheap energy of MGs during peak hours [
10,
11,
12,
13]. In the proposed system model, RES and energy storage-based MGs are placed for each cluster of residential buildings. Similarly, the huge requests generated from residential buildings need to be processed. The cloud provides ideal computing resources for such a huge number of requests. However, network latency, data computation, and communication cost is challenging [
8]. Fog computing provides cost-efficient and near-real-time services. It offloads the cloud computing services; however, it does not replace the cloud. Fog computing has limited resources as compared to cloud computing [
14]. This is suitable for real-time applications with low traffic congestion, minimum bandwidth, and low energy consumption. The characteristics of cloud and fog encourage the proposed cloud-fog-based system model. Moreover, efficient resource use enhances computational performance. The load of requests on the VMs is balanced with Particle Swarm Optimization (PSO) in [
15] for efficient resource use to enhance the performance of the fog. In PSO, in local solution, the particles are not fully connected; rather, each particle is connected to their neighboring particles. In a global solution, the particles are fully connected, and the swarm is controlled by the best particle. This makes the PSO inefficient for a global solution; however, local search time is reduced by increasing the inertia weight [
16]. On the other hand, Simulated Annealing (SA) is inspired from the natural process of annealing in metallurgy in which after a long cooling period the system always converges to global optima [
17]. Hence, PSO suffers from the instability of particles during global convergence and SA jumps to the convergence of global optima. The challenge is to join the local optima of PSO and global optima of SA for efficient load balancing on VMs of fog data centers.
1.2. Problem Statement
In SG, Demand-Side Management (DSM) reduces the consumption cost on the demand side and reduces production loads on the supply side. Researchers have proposed many DSM models, infrastructures, and platforms to optimize power demands. In distributed demand response, the supply side broadcasts the information e.g., current load, tariff. Individual consumers optimize energy consumption [
18]. However, error messages on the communication network and locally solving the optimization are challenges for efficient power management. The authors of [
19] propose a cloud-based centralized DSM. To overcome the delay issues of the cloud, the authors introduced a two-tier cloud-based model: edge cloud, near the end users, and centralized cloud, for all edge clouds. Inefficient resource use of cloud computing exacerbates the delay issue. The authors in [
20] propose he efficient resource allocation algorithms to enhance the performance of cloud computing for DSM. Load traffic on cloud-based DSM and network delay are the challenge for DSM in SG [
19,
21,
22]. To overcome the delay issues, the authors of [
23] propose a fog-based architecture for DSM. The fog has limited resources compared to the cloud; however, the fog is close to the end devices. A bottleneck is created for fog computing due to a huge load of requests that compromise the performance of fog computing. Routing of the demand-side request traffic at the appropriate data center and allocation of requests on fog-computing resources for enhanced performance are challenging.
1.3. Contributions
In this paper, cloud-fog-based SG is proposed for enhancing services. Six regions with six clusters of residential buildings are considered. The clusters share the requests with the fogs to process and respond back in near real time. The fogs are connected to the cloud to permanently store their data. The cloud is connected to the utility and it also broadcasts the utility tariff to the fogs. The MGs are placed near the fogs to provide cheap and undisrupted power supply to the buildings. The MGs have fixed capital and maintenance or recurring cost [
24]. The cost depends on the size and types of energy sources. In this paper, RESs and energy storage system-based MGs are proposed. The sizes of MGs are defined according to demands from the clusters. The maintenance cost of an MG is also called a recurring cost, which is proportional to the size of it. This paper is an extension of [
25] and the contributions of this research are as follows:
A three-layered model—core or cloud, fog or middle-ware, and end-user layers—is proposed.
Hybrid of PSO and SA: PSO-SA is proposed for efficient load request allocation to VMs in the fog data center.
A service broker policy, hybrid of Optimized Response Time (ORT) and Service Proximity (SP) is proposed for the selection of potential data center. The requests traffic is routed on the selected data center.
Fog layer is introduced between cloud and end users for near-real-time processing and respond back to the end user.
The recurring cost of MGs and computational cost on fog form the system cost. The system cost is a recurring cost which is added to the consumer bill.
The proposed PSO-SA and the new service broker policy outperforms the state-of-the-art service broker policies and load-balancing algorithms.
1.4. Organization
The rest of this paper is organized as follows:
Section 2 presents the literature review. In
Section 3, the proposed system model, load-balancing algorithms, and NSBP are presented.
Section 4 demonstrates the simulation results, and in
Section 5 the conclusion is discussed.
2. Literature Review
The end users in SG are educated to optimize their load consumption; however, for the last few years, insightful researchers have proposed autonomous DSM programs [
26]. The purpose of the DSM is to autonomously optimize the load consumption on the demand side. In [
27], authors propose a cloud-based EV charging and discharging system for SG. A priority assignment algorithm optimizes and reduces the waiting time for EVs on public supply stations. The proposed system manages SG operations and maintains the communication between the cloud and the SG. The simulation results validate the usefulness of the proposed approach for the charging of EV even during peak hours, which improves the SG stability.
Moghaddam et al. [
28] propose the stochastic model for consumers to schedule the energy load of appliances using the cloud-based DSM for SG. The model creates small energy hubs for users and shifts the load from peak to off-peak hours using the Monte Carlo method. The proposed model reduces the peak to average ratio and the cost. However, authors of [
19] analyze the Distributed Demand Response (DDR) and Cloud-based Demand Response (CDR). The comparative analysis of simulation results shows that CDR performs better than DDR with scalability, reliability of power and a stable communication network. Unlike CDR, the DDR has unreliable channels which are prone to lose messages. Hence, CDR has improved performance with cost efficiency. The simulation results show that proposed CDR reduces more cost and PAR compare to DDR.
Home appliances are categorized to form subsystems by connecting with the controllers. The controllers and remaining appliances are connected to the Smart Meter (SM). The SM communicates with the fog for controlling and scheduling the load of appliances. The authors of [
23] propose hardware and software architectures for fog computing. The fog provides services for energy management for SHs. The fog-based energy-management service reduces the cost, RT and PT compared to the cloud. Similarly, in [
29], cloud-based Cyber-Physical System (CPS) for energy efficiency in smartphones is proposed. An energy-aware dynamic task scheduling algorithm is proposed to aggressively reduce the energy consumption in smart phones. However, latency issues of the cloud compromise the performance, which is difficult to resolve.
A cloud-based cost-oriented model for Direct Current (DC) nano-grid for next-generation smart cities is proposed in [
30]. Low-voltage smart appliances are controlled for energy and cost efficiency using cloud-based energy management. The model is proposed with the uninterrupted power supply to reduce maximum cost. For experimental analysis, a group of buildings from the smart city is taken, which are controlled by generating alerts from the data centers on high power consumption. These data centers are connected with a centralized cloud infrastructure to control the energy consumption of smart city buildings. The simulation results show that the proposed scheme has high satisfaction ratio, cured delay and reduced demand supply gap.
Energy management on the fog for SHs is a novel approach to optimize energy consumption with direct or indirect autonomous control. In [
31], energy management as a service over a fog-computing platform is proposed. Home appliances are categorized into subgroups. Software and hardware architecture for SH energy control and fog-computing resources are proposed. Fog computing provides flexibility, data privacy, interoperability, and real-time energy management. Two prototypes are implemented to validate the reduction of implementation cost and time to market.
The authors in [
20] propose the analysis for new trends in next-generation cloud computing. The cloud infrastructure is modified into multi-tier architecture and applications are also modified accordingly. Multiple infrastructure providers and distributed computing have resulted in new cloud infrastructure. The authors analyze that emerging cloud architecture will improve the connection between people and devices. It will provide a self-learned cloud-based system.
The authors in [
32], propose a model of bi-level optimization to schedule power consumption of local appliances and amount of power production. Adequate constraints on optimization vectors reduce the cost of power generation in the local grid. Using cloud computing, it is possible to design and implement an optimized DSM program for utilities and consumers. In [
33], authors propose an efficient energy-management scheme for SG based on CPS. Smart devices are located on the physical plane and the controller on the cyber plane. The Nash equilibrium approach is used to analyze the performance of the proposed coalition. The proposed scheme provides cost-efficient energy management solutions during peak hours.
The authors in [
34] propose energy-aware fog-based load balancing on equipment in a smart factory. An improved PSO algorithm is proposed for an efficient energy-consumption model. The distributed scheduling of manufacturing clusters is resolved with a proposed multi-agent system. Similarly, to improve the performance of cloud and fog computing, a variety of heuristic and meta-heuristic techniques are implemented and have been proposed. In [
35,
36,
37], heuristic-based load-balancing schemes are proposed for fog-computing resources. Fogs are preferred for real-time applications and their efficient performances are important to consider. Hence, maximum use of resources improves the performance as well as reduces the computing cost.
The aforementioned literature advocates the importance and benefits of cloud- and fog-based SG. However, issues such as latency of the cloud-based system are incurable. However, fog computing offers a wide horizon to ensure scalability, security, and low latency in energy-management strategies. In this paper, three scenarios for efficient fog computing with proposed PSO-SA for load balancing of requests on VMs and hybrid service broker policy are implemented.
3. System Model
In this paper, a three-layer system model is proposed as shown in
Figure 1. The clusters of residential buildings exist at the end-user layer. The cluster generates several requests for their energy consumption. Each cluster is attached with a fog in the middle-ware layer. The fog receives the requests from the cluster for processing. MG with RESs and storage system is placed near each fog. The service broker policy routes the traffic of requests in the potential fog server or data center. The load-balancing algorithm efficiently allocates the requests on VMs in the data center. The recurring cost of MGs and computational cost of the fogs form the system cost and is added in consumer energy-consumption bills. The fogs are connected with the core or cloud layer, where necessary data from the fogs are sent for permanent storage. The cloud also broadcasts the utility tariff to the fogs.
In the system model, each region has a N number of clusters of residential buildings. Each cluster has n buildings, } and each building has m SHs, . It is assumed that the production and current status of MGs are shared with the fog. The fogs have utility tariff and information of MGs to process energy demand requests. In this paper, Photovoltaic (PV), Wind Turbine (WT) and Fuel Cell (FC) are assumed for energy-producing sources and battery storage systems are used to store the energy in MGs. It is assumed that fog servers or data centers are placed near end users to reduce the end-to-end latency. Moreover, when huge request congestion is created on fogs then the requests are routed on the cloud for processing. The communication between end devices and the fogs take place using wireless communication media such as Wi-Fi, Z-Wave or ZigBee.
The end devices (for instance SMs) generate requests and send to the fogs for processing. Each request contains information of previous load consumption, current load demand, the source of energy (utility or MG), cost and time (for request generation which is sent to the fog and receive back). The request can have other information such as number of appliances, power ratings of appliances, the current cost for consumed energy, etc. depending on the consumer services and facilities from the fogs. Every cluster generates a huge number of requests and sends to the fog for processing. Optimization of resource use is performed on the fog. Two necessary and effective steps are: (i) selection of efficient server or data center where traffic of requests is routed for processing; and (ii) balanced load request allocation of routed requests on the VMs in the server. The necessary information of these requests is sent to the cloud and for usage in permanent storage for future statistics and projects. The fogs also contain the information of MGs (production, capacity, the rate of energy flow out, etc.). When a MG has insufficient power to fulfill the demand then fog requests the cloud to facilitate energy consumer.
In the end user layer, the SMs of SHs in residential buildings have information of smart appliances. The set of smart appliances, in a SH are connected with the SM. The SMs share the request with the fog and the request carries the information of and ownership of SH. Hence, information of each appliance and biodata of the consumer are sensitive and called private data of the SH. However, it is assumed that the total power consumption of a SH is shareable and called public data. The SMs categorize the energy data of each SH into private and public.
Private data is usually never shared; however, the companies use this information for their statistics and analysis for future or for upgrading the existing system. Such sensitive data can be compromised in the cloud-based system. In the fog-based system, the information is local, and it is less likely to be compromised.
Public data refers to total energy consumption from a building, power generation of each MG and utility tariff. This information does not contain sensitive data and there is no harm in sharing.
The fog in the fog layer receives requests for energy demand from the cluster of residential buildings and the current status of the MG. On the basis of this information, the fog decides whether energy is supplied from the MG or the utility. The cluster does not directly communicate with the MG and utility. Similarly, in the case of utility, the fog requests the cloud which facilitates the energy demand request from the utility.
3.1. Problem Formulation
Effective task scheduling can be done in such a way that the upcoming requests from end users get minimum execution time. Let ‘x’ be the number of requests received by task handler with task length . The set of independent tasks is represented by . Every independent task is assigned to a VM with processor speed , bandwidth , memory and the number of CPU . Let, is the set of y VMs in the fog. The VMs execute the x tasks in parallel. Each VM runs on its own resources and processes the tasks independently.
The maximum completion time required for a task is the makespan of the task. The objective of load requests balancing is to mitigate the makespan and RT. The makespan of
r task on
is denoted by
. The makespan for
r on
is elaborated using the following Equation (
1):
where
and
. Mapping of the task
to
y VMs affects performance parameters. Now, the total tasks assigned to each VM are dependent on the set of end user requests and in the performance of the load-balancing algorithm. The PT and RT of tasks are formulated using linear programming. The PT of the allocated task
to
s VM is
and status of the task is
. Total
of
x tasks allocate to
y VMs and statuses
:
The objective is to minimize PT,
where,
Now, RT is the total time taken from sender to data center, PT on data center (by VMs) and time to receive back from data center. It is computed with the help of an Equation (
5),
where
is used to represent the total RT of the VMs in the system and
is the completion time of the tasks.
VM is installed on a physical machine in a data center, acquiring resources to process the tasks. There are two costs, fixed and recurring cost. The cost of the physical machine, maintenance, and installation is fixed cost. Recurring cost is associated with the use of resources of physical machine to meet user requirements. Optimized use of resources reduces the recurring cost. The concept of VM is madde to use physical resources with optimization. The fixed cost of a VM can be calculated with Equation (
6) when
y number of VMs are installed on a physical machine,
where
and
are physical machine cost and maintenance cost. The recurring cost in this paper is calculated on the basis of number of requests arriving at the VM and the number of instruction executions per second by the VM. Length of a task
elaborates the number of instructions
,
Cost of a VM is calculated by the number of instructions executed in a given time. Cost for a VM is defined by execution of a Million of Instructions Per Second (MIPS). Cost of VM for given task of length
is,
where,
is a cost
c of VM for a task
T of length
L,
is the cost of MIPS. The total cost of VM for all
x tasks,
MG available next to fog in middle layer having power generations; from WT,
, from PV,
and from FC,
with the costs of
,
and
, respectively. Price
per unit energy is defined according to all power generations and their respective costs. WT and PV are dependent upon the weather hence their power production is used with predictive nature of production. FC is used for backup to keep MG alive. The capacity of power generation of MG
is,
Total cost of energy produced by MG is,
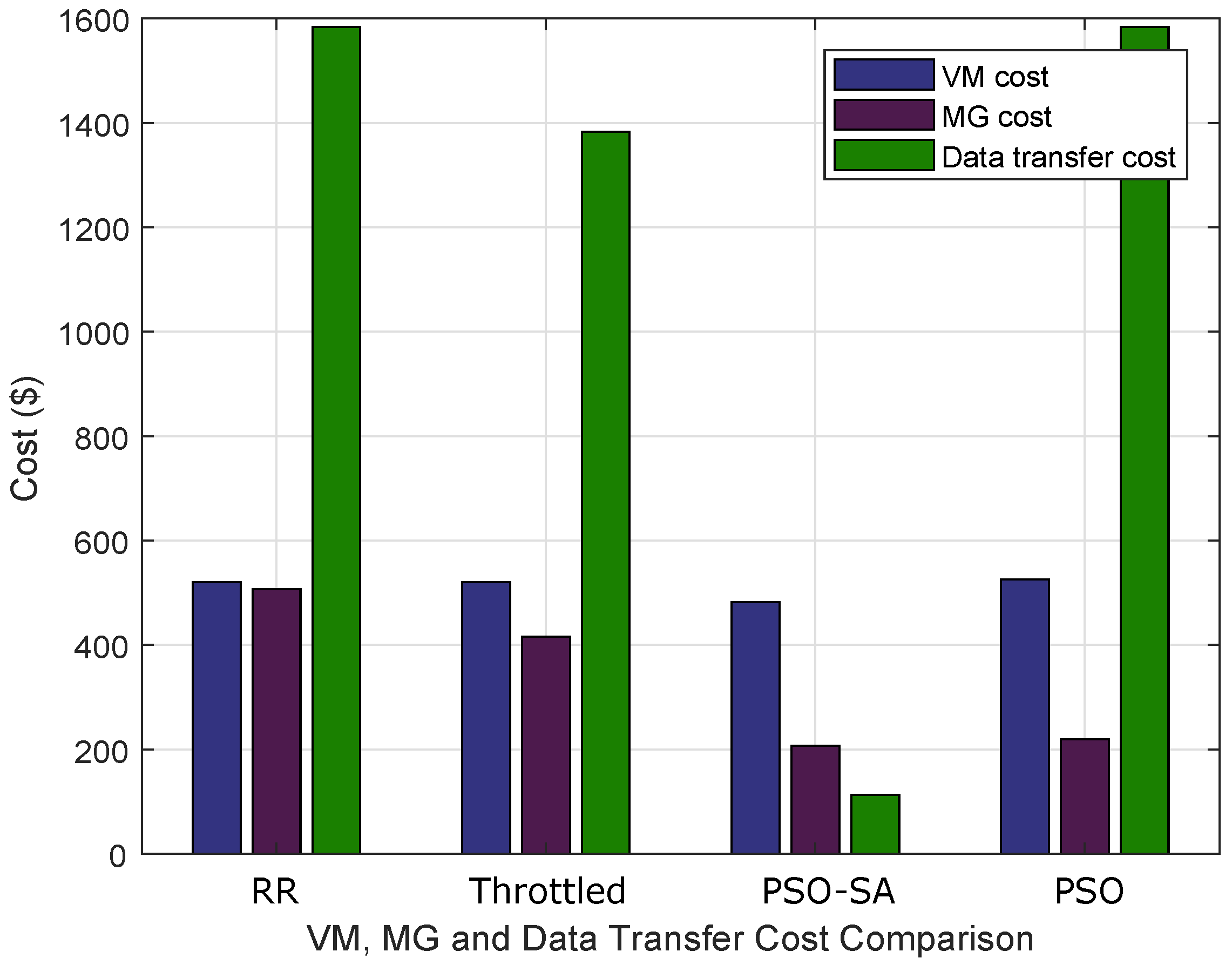
Cost of DT is the composite of interconnection and transit costs. Interconnection is a fixed cost used for connectivity with Internet Service Provider (ISP) cross-linking. Transit cost is a variable depending upon bits per second or bytes per second sent. Cost of DT is computed by transit rates or bandwidth.
The total cost of the system is calculated by accumulating VM cost, MG cost and DT cost. Therefore, the total cost of the system is given by Equation (
12):
where
,
,
and
represents the total system cost, VM cost, MG cost and DT cost. The objective is to minimize
,
and
.
3.2. Load-Balancing Algorithms
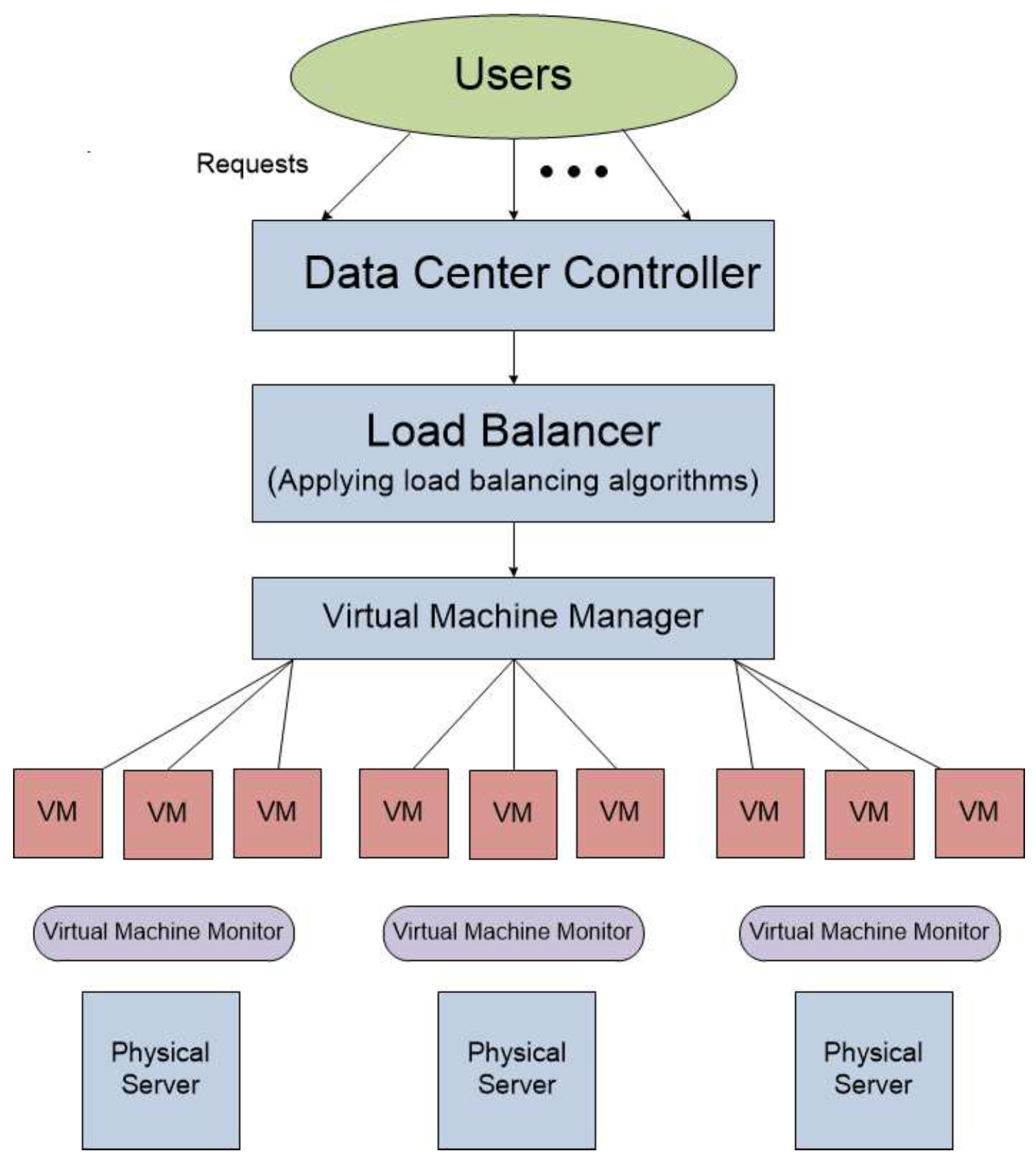
Efficient resource use enhances the performance of computing resource. The cloud and fog have huge resources to execute a huge number of requests. The resources are shared to enhance the performance. In this paper, resources of fog are shared by creating VMs. The requests are executed according to the performance of VMs; however, execution of the overall load of requests is optimized by the efficient allocation of the requests to the VMs. The performance of a data center is compromised when some VMs have overloaded requests and some have very few or sitting idle. To resolve this issue, load-balancing algorithms are used to allocate balanced load of requests on the VMs. The mechanism of load balancing is illustrated in
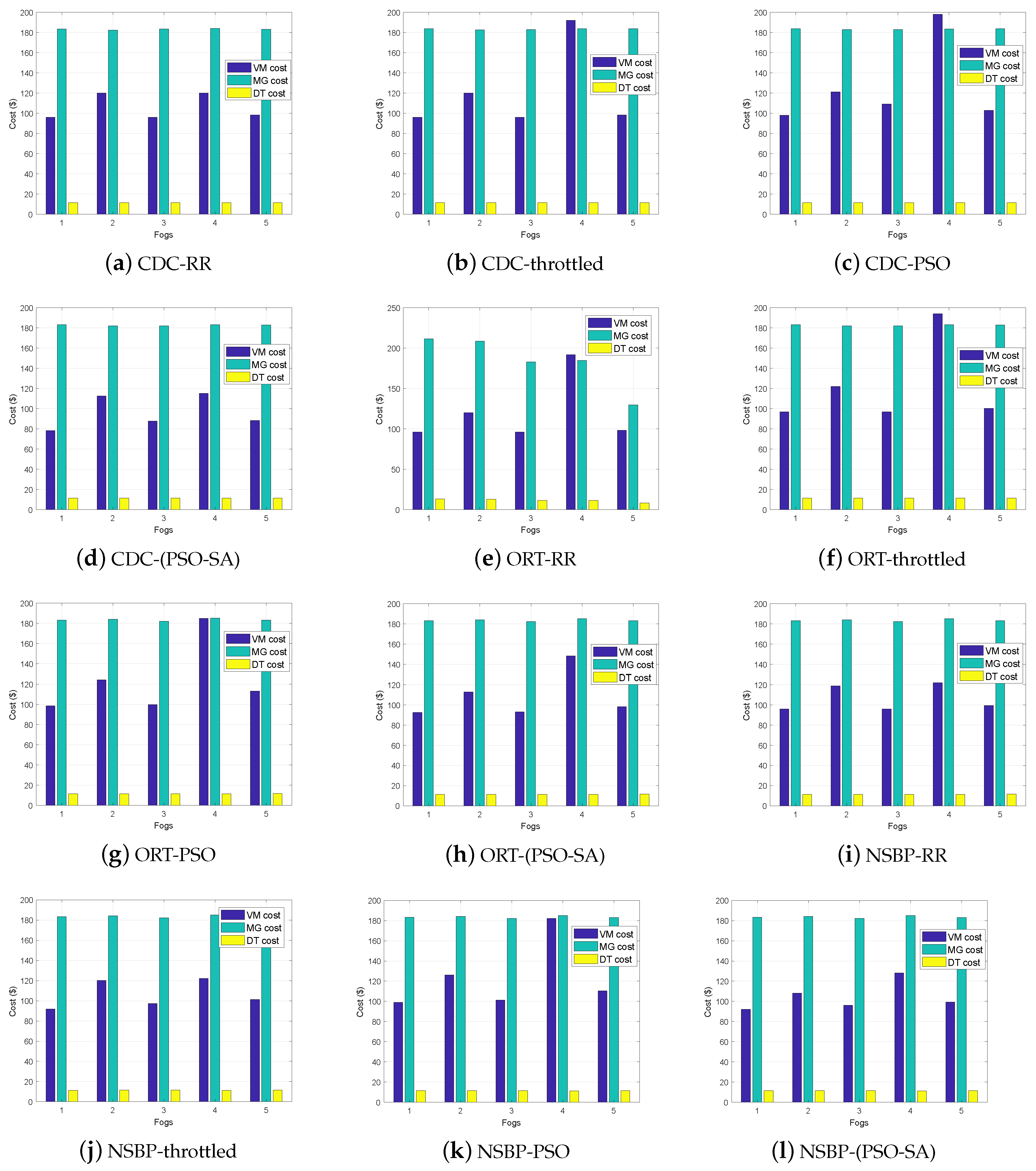
Figure 2. From top to bottom, the end users generate requests which are sent to the fog data centers. The data center controller routes the requests on the potential server where the load balancer (load-balancing algorithm) efficiently allocates the load of requests on VMs. The VM manager furnishes the VMs for the load of requests to execute. The VMs are created on physical resources which are maintained by the VM monitor. However, collective performance of these VMs depends on the load of requests assigned to them. The PT, RT and the execution cost with proposed load-balancing algorithm PSO-SA are analyzed by comparing them to Round Robin (RR), throttled and PSO algorithms.
3.2.1. RR Algorithm
RR algorithm is based on equal time slicing. In this paper, the RR algorithm is used to allocate resources to each host by equal time slicing for utilization of resources. This algorithm is used to balance the load of requests on the VMs by assigning equal time slice. The basic steps are described in Algorithm 1.
| Algorithm 1 RR-based resource allocation. |
- 1:
Input: List of tasks, List of the VMs - 2:
Output: VmId where tasks will be assigned - 3:
Initialize VmId=1, maxIter=maxValue - 4:
forvm=1; vm ≤ length (VmList); vm++ do - 5:
Find allocated to vm - 6:
if VmId=1 then - 7:
=0; - 8:
else - 9:
=vm.getCurAssign() - 10:
end if - 11:
find (cur_VmState) - 12:
State=VmState - 13:
if ( ≤ MaxCount && - 14:
State.equals (available)) then - 15:
MaxCount=; - 16:
VmId=vm; - 17:
end if - 18:
end for - 19:
Return VmId
|
3.2.2. Throttled Algorithm
In the throttled algorithm, “throttledVMLoad” balancer maintains the table by indexing the all VMs which are available at the beginning and the load of requests. Data center controller receives new requests from end users. The requests query the controller where to be assigned. The algorithm assigns the requests to the VMs by identifying the tags assigned by the data center controller. If identical tags are found, then requests are considered for the next allocation after amending the tag information. The table is also updated according to the amendments. If there is no next request then balancing function returns “”. The basic steps of the Algorithm are explained in Algorithm 2.
| Algorithm 2 Throttled-based resource allocation. |
- 1:
Input: List of tasks, List of the VMs - 2:
Output: VmId where tasks will be assigned - 3:
Throttled Load Balancer initialize an index - 4:
VmList checking (); - 5:
VmState (); - 6:
DC controller receives request - 7:
NextAllocation (); - 8:
CheckAvailability (); - 9:
if (VmId=1) then - 10:
Return VmId; - 11:
waitforNextAllocation (); - 12:
ModifyIndex (); - 13:
else - 14:
Return VmId=−1; - 15:
end if - 16:
if (more requests are in queue) then - 17:
Repeat step 8 to 15 - 18:
end if - 19:
Return VM with load
|
3.2.3. PSO Algorithm
PSO is inspired from the motion behavior of birds or fish to improve the candidate solution. The individual particle (animal) is not intelligent enough to solve a complex problem. The swarm intelligence (all the animals in search space) provides the efficient solution. Each particle is influenced by its neighbors and each particle updates itself with respect to its neighbor which make the whole swarm update. This leads the whole swarm to the best solution. The PSO algorithm uses the following steps to find the best solution.
The particles (swarm) move in the search space according to some calculations or formulae.
The movement is made with two constraints: locally best position and best position in whole swarm.
Any update in a position will update the whole particle swarm, which makes the PSO inefficient for its global search.
The basic steps of the algorithm are given in Algorithm 3.
| Algorithm 3 PSO-based resource allocation. |
- 1:
Input: List of tasks/requests, List of Population VMs - 2:
Output: - 3:
=0 - 4:
for c=1 to do - 5:
Particle velocity = - 6:
Particle position = - 7:
= - 8:
if Cost() <= then - 9:
= - 10:
end if - 11:
Stopping-condition - 12:
for ( do d=1 to ) - 13:
= Update(, , ) - 14:
= Update(, ) - 15:
if Cost(Cost() <= Cost() then - 16:
= - 17:
if Cost(Cost()) <= Cost() then - 18:
= - 19:
end if - 20:
end if - 21:
end for - 22:
end for - 23:
Return VM
|
3.2.4. PSO-SA Algorithm
In the proposed algorithm, PSO is used to find local best position () and global best position () is found with SA. In PSO, the best solution is found by a sequential flow of information. The best solution sends information to nearby particles. In local search, partials are compared to their neighbors and provide efficient solution. However, in global search, all particles are compared with a single best solution which compromises the performance of PSO. On the other hand, the SA algorithm is inspired by the natural process of metallurgy. SA converges to global best search after a long cooling process. Hence, during heating and a long cooling process, the performance of suffers. The hybridization of of PSO and of SA provides efficient solutions. The basic steps of the proposed hybrid PSO-SA are illustrated in Algorithm 4.
3.3. Proposed Service Broker Policy
The service broker policy selects the data center where requests are routed for processing. The requests from the end-user layer are sent to the fog where service broker policy selects efficient data center (according to the policy algorithm) [
38]. The requests query the service broker for the destination. In this paper, a hybrid of ORT and SP is proposed for selection of an efficient data center. In both service broker policies index tables are maintained for available data centers. In the table of SP, the table is indexed according to the nearest data centers. The regions are ordered in the list by the sender region and region queried. The remaining are order in lowest latency first. The earliest data center (lowest latency) is picked from the list. If there are more than one data centers, then a random data center is selected. However, the table of ORT is indexed according to RT from the data centers using the Internet characteristics. The requests query the closest destination (according to latency) and at selected using the service broker algorithm. The best RT is found by iterating through each data center due to:
Last performed task using Internet characteristics.
If time is recorded before the threshold time, then PT is appended . It defines the idle state of the data center.
If closest data center does not have estimated smallest RT then on 50:50 chance either of them is selected.
In proposed hybrid service broker policy, following points followed:
A table is maintained with index of all available data centers.
The requests query the data center controller about the destination.
The sender region and queries for the regions are enlisted using SP broker.
The network delay from the regions are enlisted from the Internet characteristics and by querying the last recorded PT (using ORT step).
The network delay for other regions from the given region also enlisted (using SP step).
The CDC with minimum RT is selected; otherwise, data center with least RT is selected (using ORT and SP steps).
| Algorithm 4 PSO-SA-based resource allocation. |
- 1:
Input: Load of requests, list of VMs - 2:
Initialize Population (all VMs) - 3:
Initialize the Best known VM for the requests - 4:
for Number of all VMs do - 5:
Input Load of Requests - 6:
if (Number of ==0 && ) > 1 then - 7:
Select random VM - 8:
end if - 9:
if < VM (capacity) then - 10:
Update the the population according to - 11:
end if - 12:
for x=1 to Population do - 13:
T=x/ - 14:
=Pick random neighbor of - 15:
if Acceptance-Probability P(,Current VM)), T) >= rand(0,1) then - 16:
= - 17:
end if - 18:
end for - 19:
end for Return best VM
|
5. Conclusions
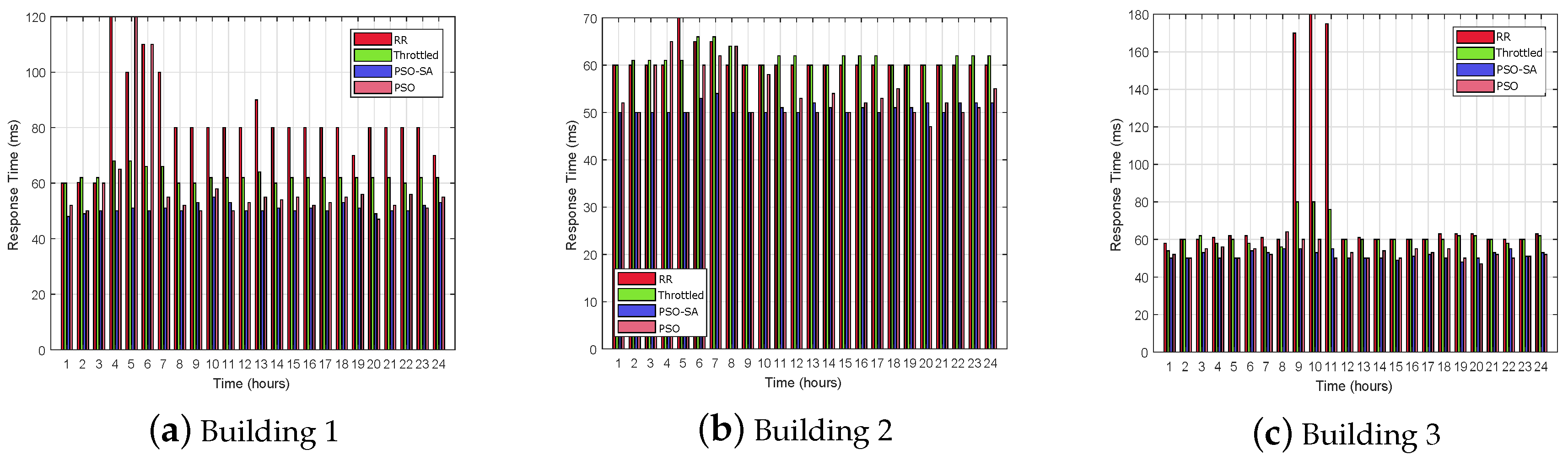
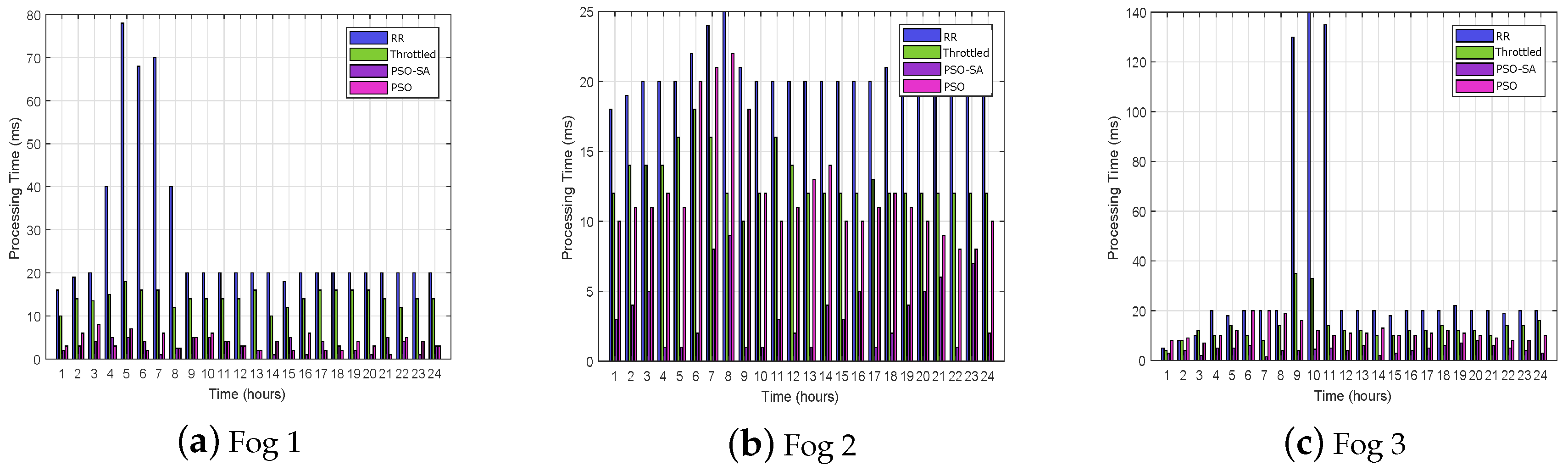
In this paper, a cloud-fog-based system model is proposed. Residential buildings form the clusters and each cluster has a fog to compute the energy requests generated from the buildings. MGs are placed with each fog for uninterrupted and cheap power supply to the clusters. MGs have RESs with storage systems. A MG has maintenance or recurring cost which depends on the size, types of sources and number of demand requests from the clusters. When a MG has insufficient energy to meet the demand then it requests the cloud to entertain the demand by requesting the utility. In this paper, requests from the clusters are sent to the fogs for processing. The RT and PT are optimized by SBP and request load balancing. A hybrid of SP and ORT SBP is proposed for selection of potential data center in the fog. A hybrid of PSO and SA is proposed for balancing load requests on VMs in the data center. Two scenarios are implemented to evaluate the performance of NSBP and the load-balancing algorithm. In
-1 the requests from three residential buildings from three regions are sent to the respective fogs to evaluate the performance of PSO-SA. ORT is used to route the request traffic on the potential data center. The simulation results show that the PSO-SA has 26.68%, 19.45% and 5.21% more efficient RT than RR, throttled and PSO, respectively. The PT using PSO-SA is enhanced by 51.9%, 54.32% and 60.9% as compared to RR, throttled and PSO, respectively. The VMs cost also optimized by 7.38%, 5.91% and 4.95% as compared to RR, throttled and PSO, respectively. The simulation results of
-2, for PT and RT of five fogs and respective clusters of residential buildings are given in
Table 3 and
Table 4. The results validate the performance of PSO-SA and proposed NSBP. The
Figure 6, validate the VM cost efficiency with PSO-SA using CDC, ORT and NSBP as well as using NSBP with RR, throttled, PSO and PSO-SA. The simulations show the trade-off between VM cost and performance with respect to hardware specifications. In the future, a multi-objective tasks-based resource allocation mechanism shall be proposed. The implementation of the realistic environment is important to validate the feasibility of proposed model in consideration of optimized power consumption and computation cost. However, this will be the scope of our future work.

 ,
, 






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}