Mixed Kernel Function Support Vector Regression with Genetic Algorithm for Forecasting Dissolved Gas Content in Power Transformers


Abstract
:1. Introduction
2. Methodology
2.1. Support Vector Regression
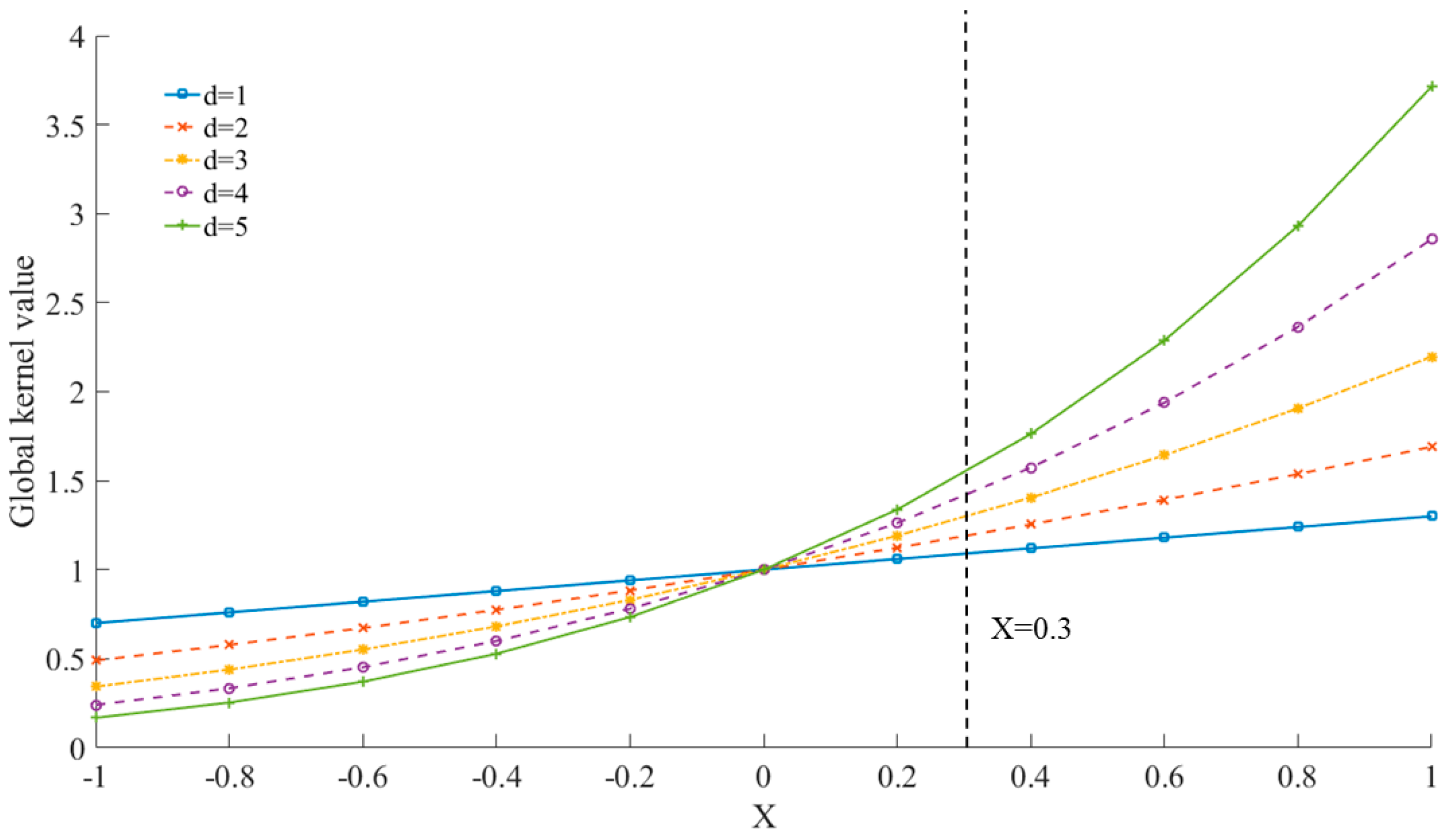
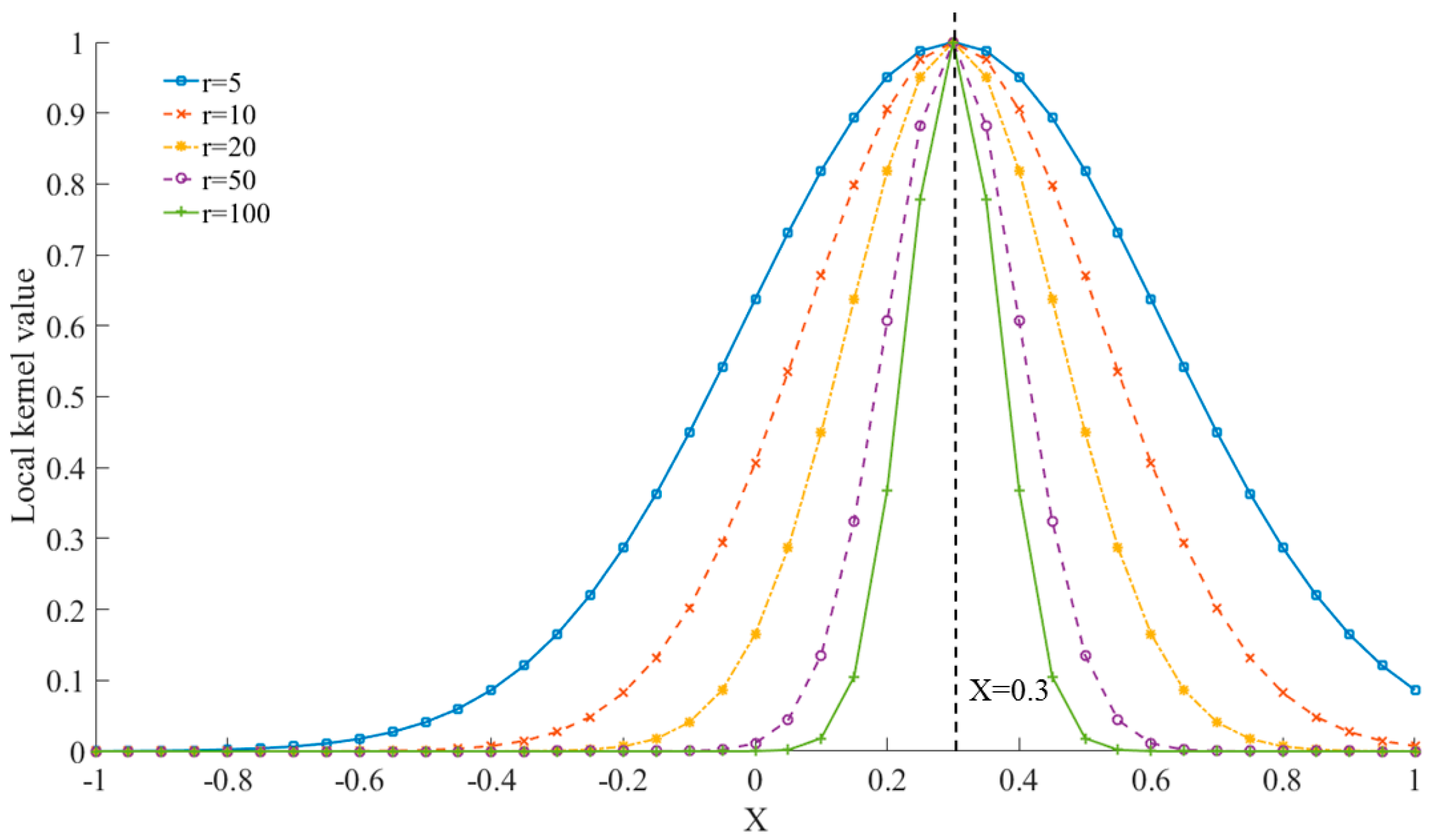
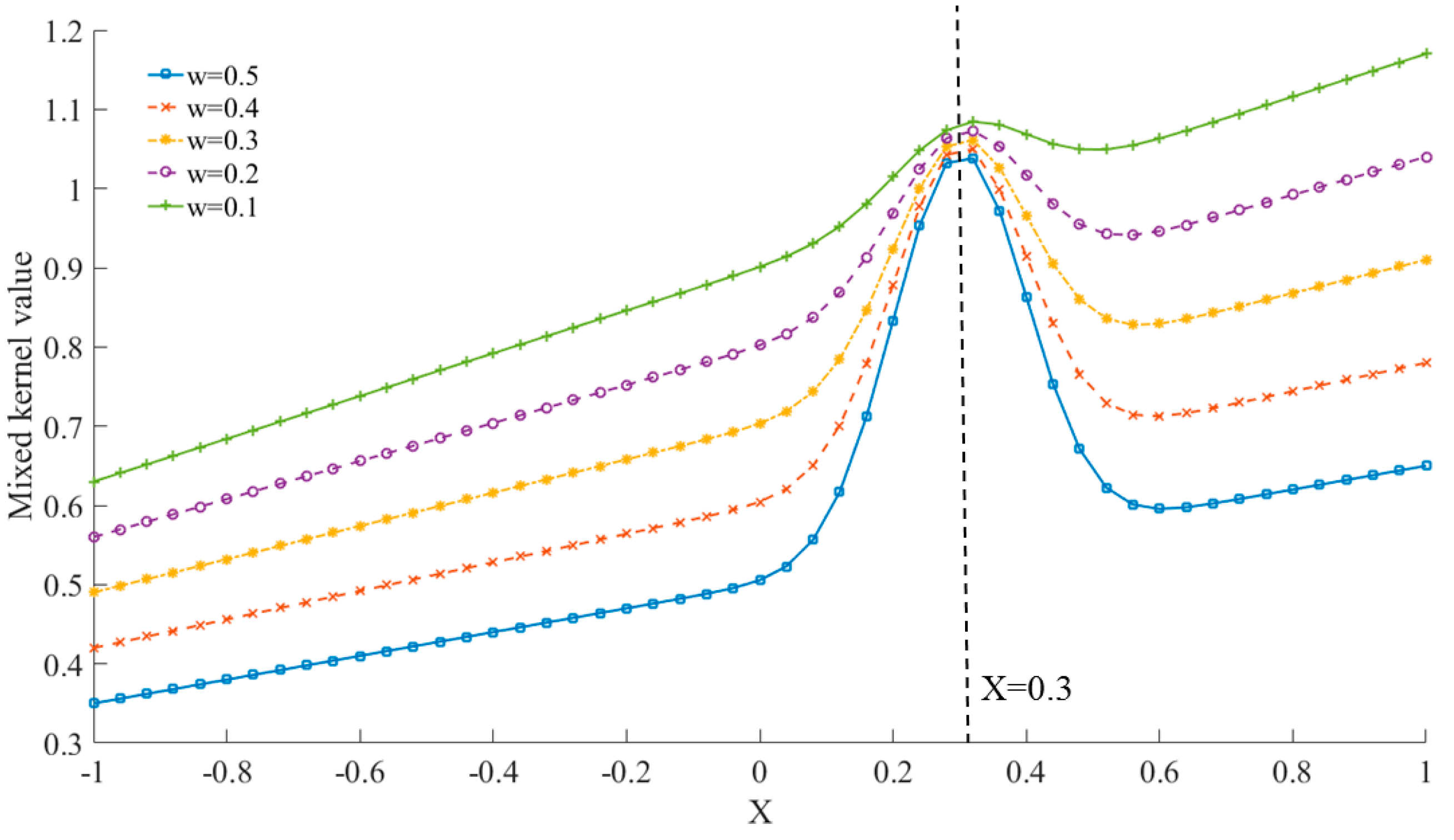
2.2. Multi-Kernel Funciton
- (1)
- Linear kernel function:
- (2)
- Polynomial kernel function:
- (3)
- Gaussian kernel function (or RBF):
- (4)
- Sigmoid kernel function:
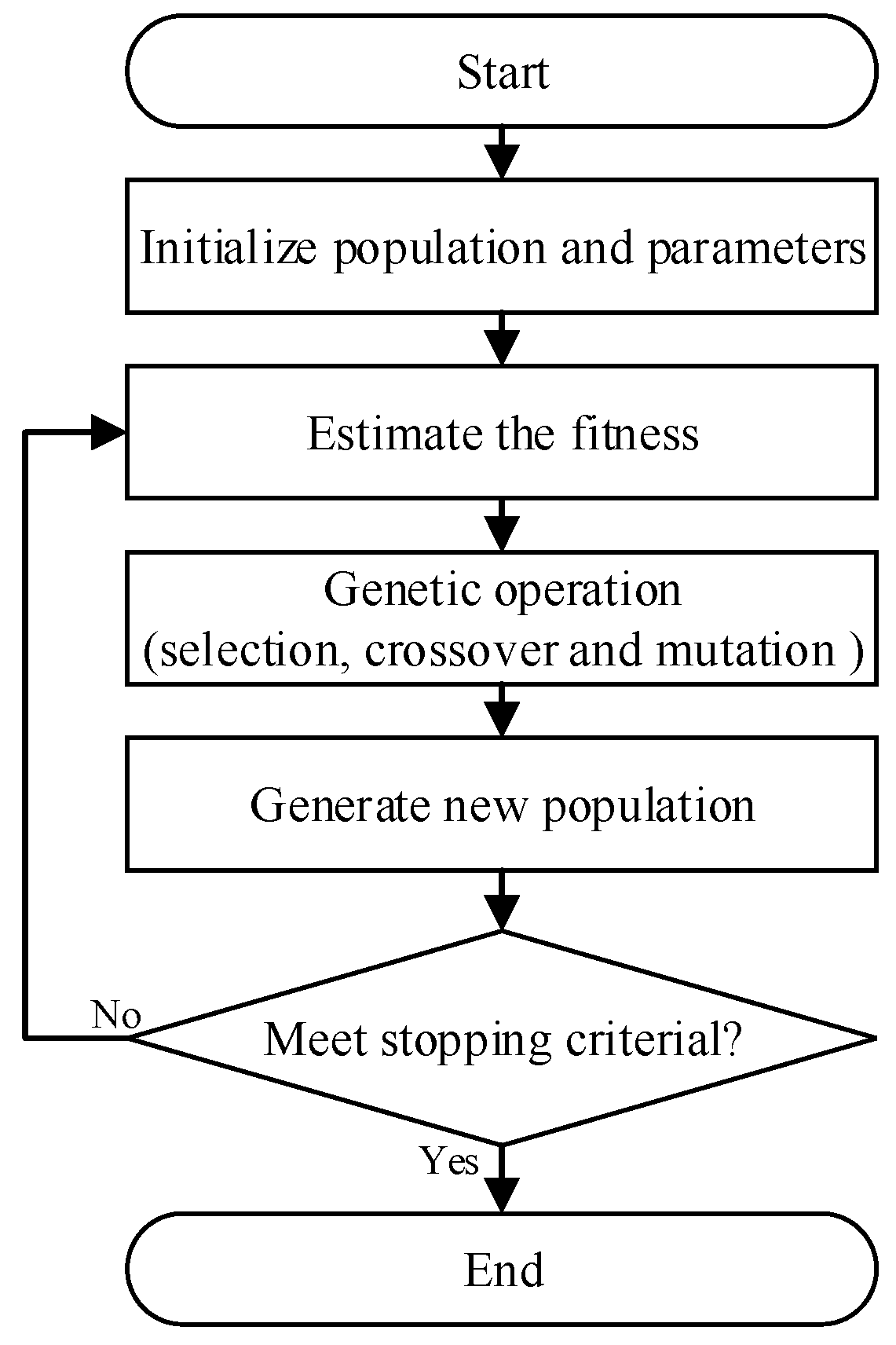
2.3. Genetic Algorithm
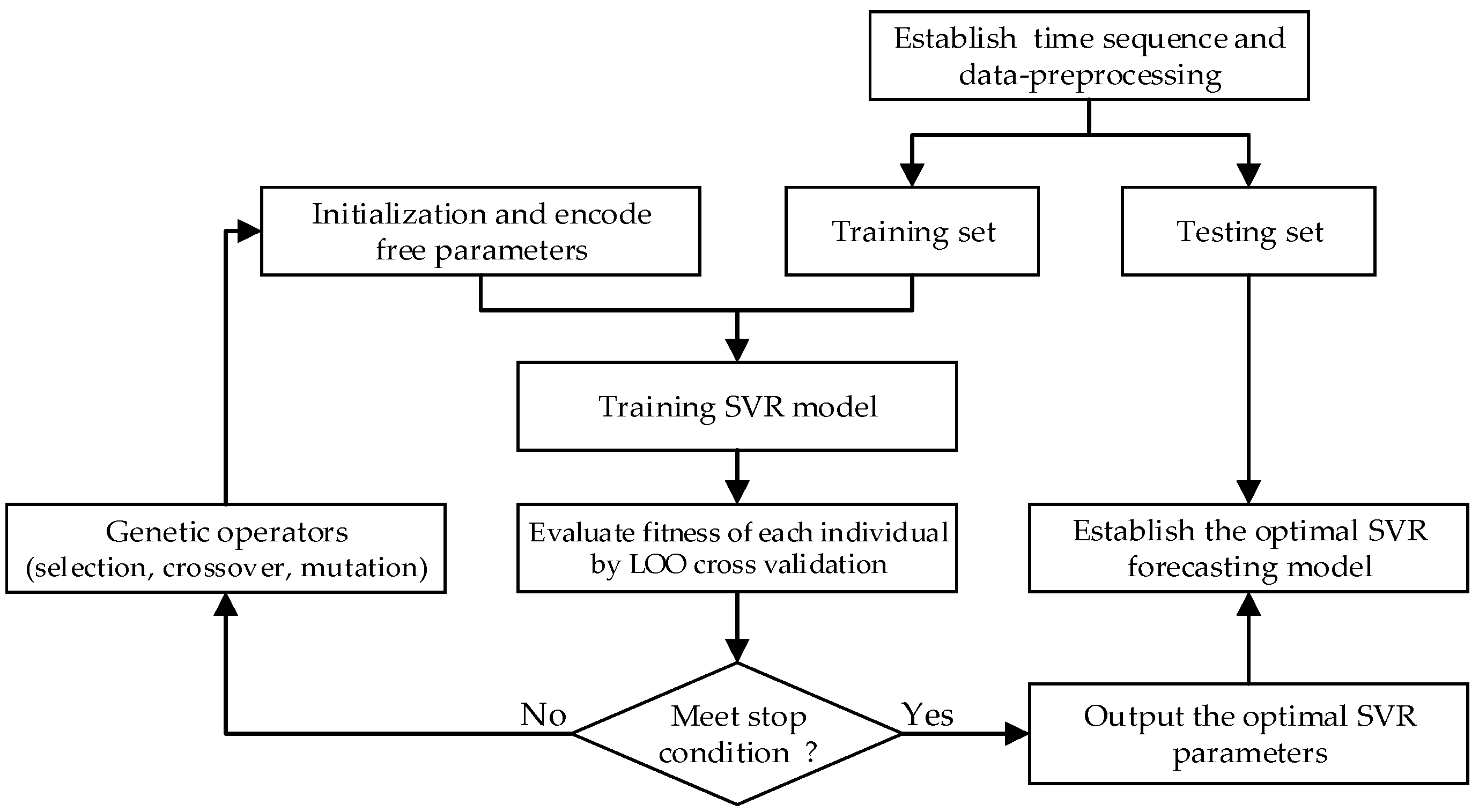
3. Procedure for Forecasting Using Proposed Regression
3.1. Data Preprocess
3.2. Training and Testing of The Forecasting Model
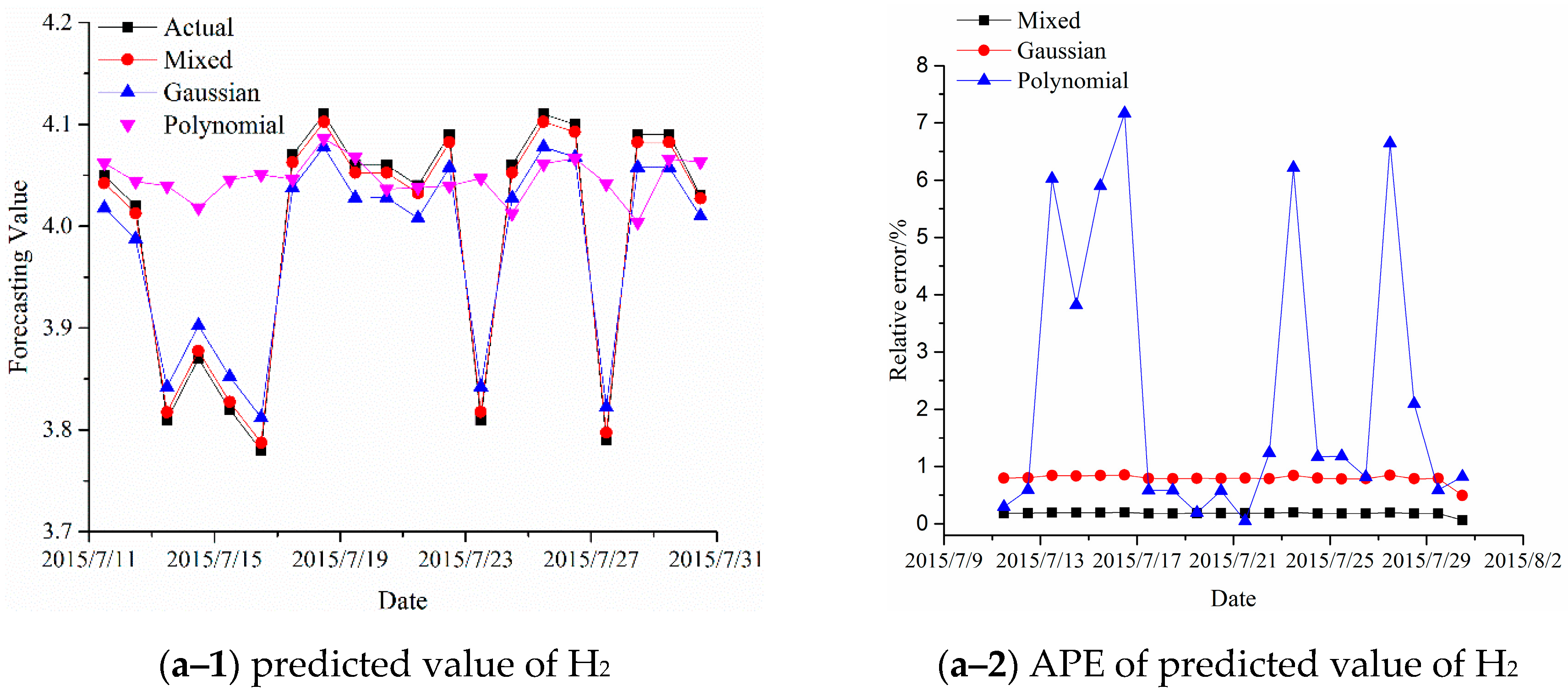
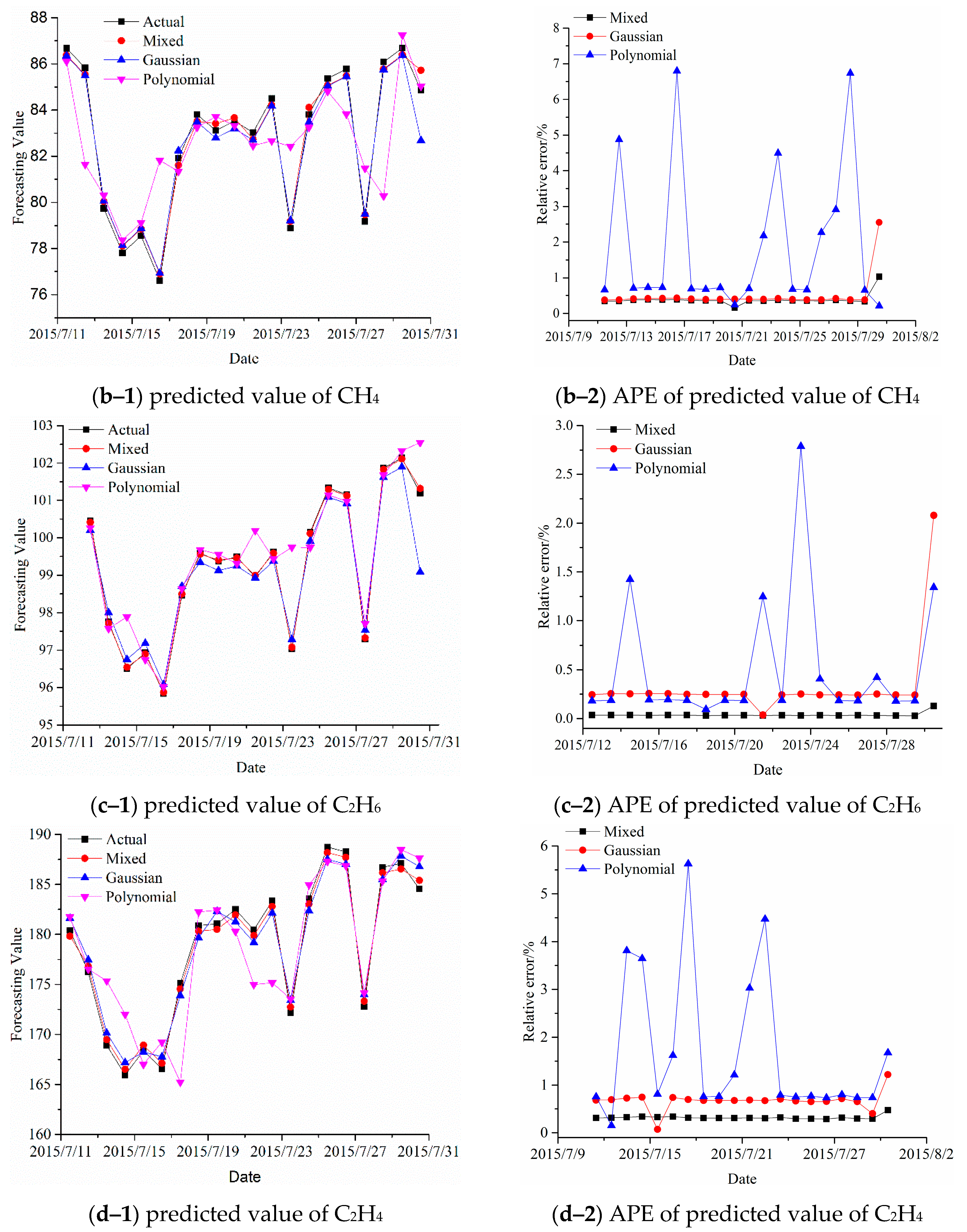
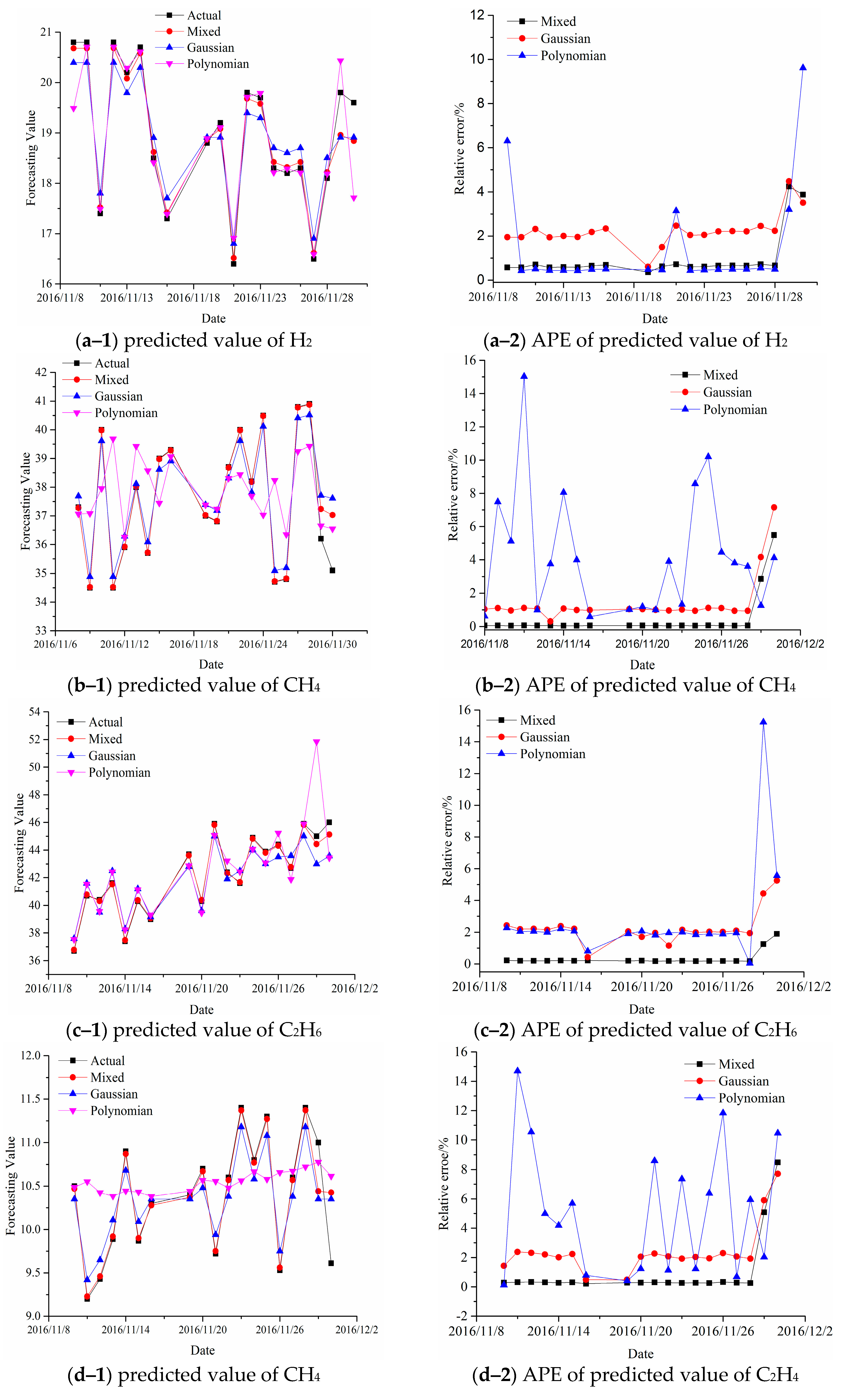
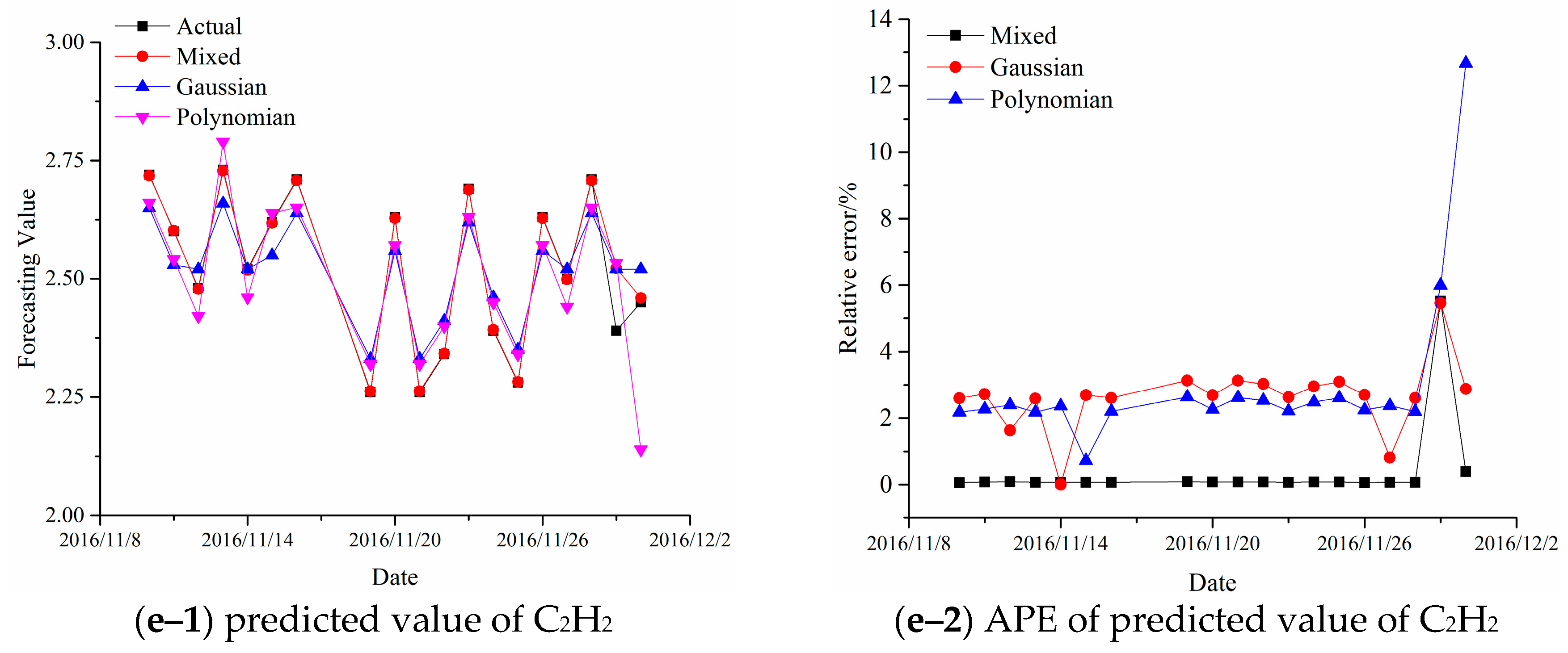
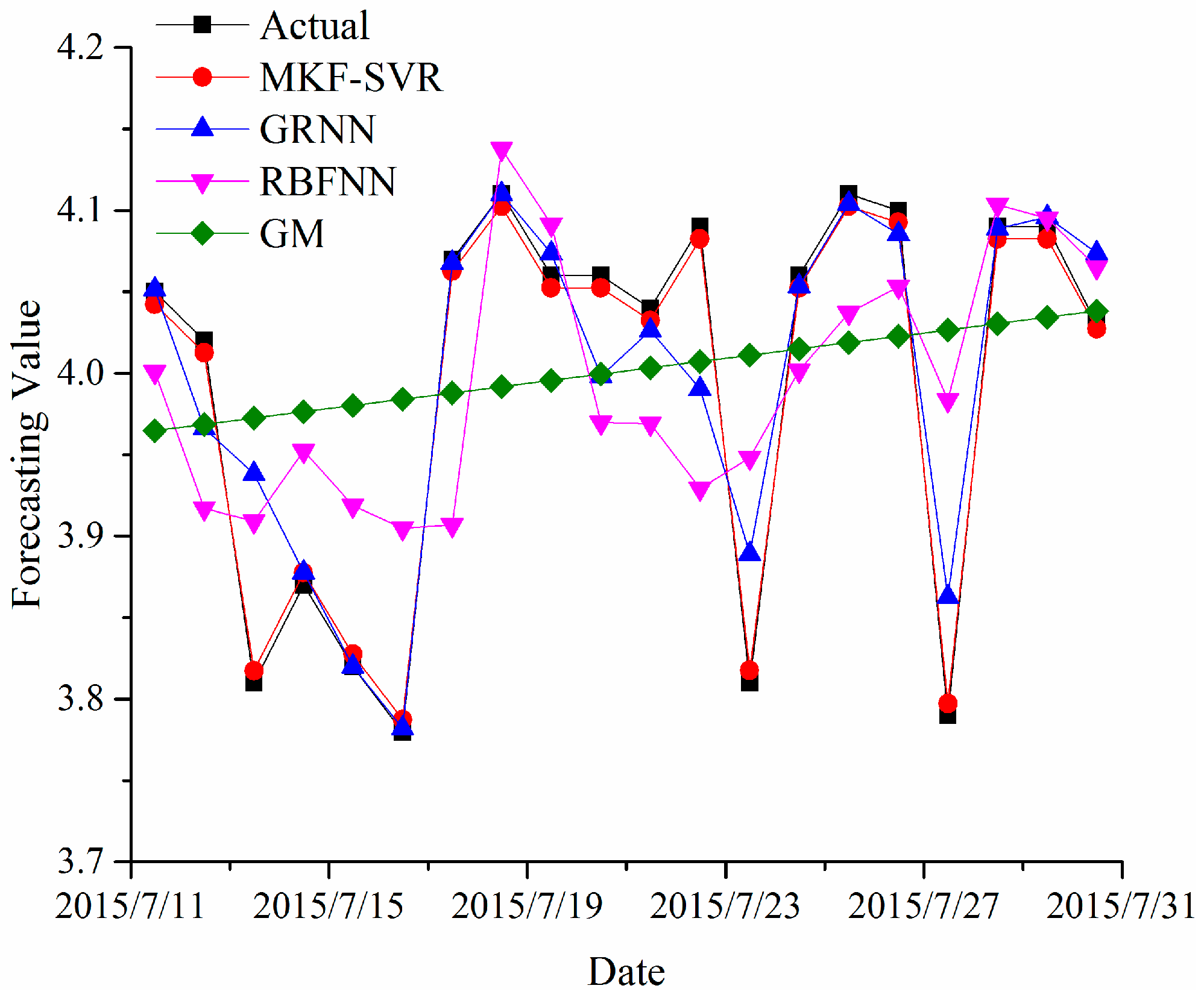
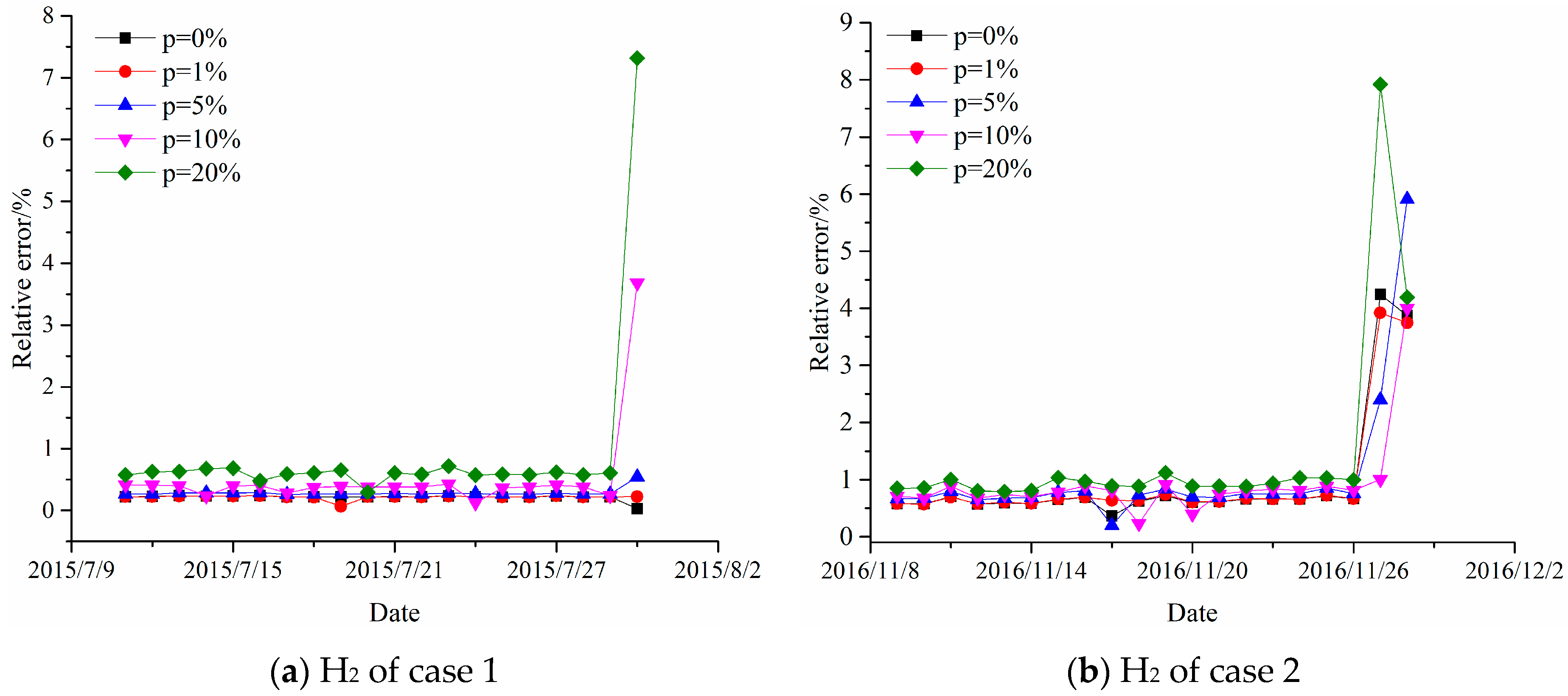
4. Experimental Results for Forecasting Dissolved Gas Content in Power Transformer Oil
5. Conclusions
Author Contributions
Acknowledgments
Conflicts of Interest
Nomenclature
| DGA | dissolved gas analysis |
| MKF | mixed-kernel function |
| SVR | support vector regression |
| GA | genetic algorithm |
| MAPE | mean absolute percentage error |
| r2 | squared coefficient correlation |
| AI | artificial intelligence |
| RBFNN | radial basis function neural network |
| BPNN | back propagation neural network |
| GRNN | generalized regression neural network |
| GM | grey model |
| LSSVM | least squares support vector machine |
| H2 | hydrogen |
| CH4 | methane |
| C2H6 | ethane |
| C2H4 | ethylene |
| C2H2 | acetylene |
| CV | cross validation |
| LOO | leave-one-out |
| ARE | absolute percentage error |
References
- Kari, T.; Wen, S.; Zhao, D. An Integrated Method of ANFIS and Dempster-Shafer Theory for Fault Diagnosis of Power Transformer. IEEE Trans. Dielectr. Electr. Insul. 2018, 25, 360–371. [Google Scholar] [CrossRef]
- Faiz, J.; Soleimani, M. Dissolved gas analysis evaluation in electrical power transformer using conventional methods: A review. IEEE Trans. Dielectr. Electr. Insul. 2017, 24, 1239–1248. [Google Scholar] [CrossRef]
- Cheng, L.; Yu, T. Dissolved Gas Analysis Principle-Based Intelligent Approaches to Fault Diagnosis and Decision Making for Large Oil-Immersed Power Transformers: A Survey. Energies 2018, 11, 913. [Google Scholar] [CrossRef]
- Duval, M. Dissolved Gas Analysis: It Can Save Your Transformer. IEEE Electr. Insul. Mag. 1989, 5, 22–27. [Google Scholar] [CrossRef]
- Rogers, R. IEEE and IEC Codes to Interpret Incipient Faults in Transformers Using Gas in Oil Analysis. IEEE Trans. Electr. Insul. 1978, 13, 349–354. [Google Scholar] [CrossRef]
- Ghoneim, S.; Taha, I.; Elkalashy, N. Integrated ANN-Based Proactive Fault Diagnostic Scheme for Power Transformer Using Dissolved Gas Analysis. IEEE Trans. Dielectr. Electr. Insul. 2016, 23, 1838–1845. [Google Scholar] [CrossRef]
- Khatib, E.; Barco, R.; Andrades, A. Diagnosis Based on Genetic Fuzzy Algorithms for LTE Self-Healing. IEEE Trans. Veh. Technol. 2016, 65, 1639–1651. [Google Scholar] [CrossRef]
- Mansour, D. Development of a New Graphical Technique for Dissolved Gas Analysis in Power Transformers Based on the Five Combustible Gases. IEEE Trans. Dielectr. Electr. Insul. 2015, 22, 2507–2512. [Google Scholar] [CrossRef]
- Piotr, M.; Yann, L. Statistical machine learning and dissolve gas analysis: A Review. IEEE Trans. Power Deliv. 2012, 27, 1791–1799. [Google Scholar]
- Wang, M. Grey-Extension Method for Incipient Fault Forecasting of Oil-Immersed Power Transformer. Electr. Power Compon. Syst. 2010, 32, 959–975. [Google Scholar] [CrossRef]
- Pereira, F.; Bezerra, F.; Junior, S. Nonlinear Autoregressive Neural Network Models for Prediction of Transformer Oil-Dissolved Gas Concentrations. Energies 2018, 11, 1694. [Google Scholar] [CrossRef]
- Lin, J.; Sheng, G.; Yan, Y. Prediction of Dissolved Gas Concentrations in Transformer Oil Based on the KPCA-FFOA-GRNN Model. Energies 2018, 11, 225. [Google Scholar] [CrossRef]
- Shaban, K.B.; EI-Hag, A.H.; Benhmed, K. Prediction of Transformer Furan Levels. IEEE Trans. Power Deliv. 2016, 31, 1778–1779. [Google Scholar] [CrossRef]
- Weron, R. Electricity price forecasting: A review of the state-of-the-art with a look into the future. Int. J. Forecast. 2014, 30, 1030–1081. [Google Scholar] [CrossRef]
- Cinotti, S.; Gallo, G.; Ponta, L. Modeling and forecasting of electricity spot-prices: computational intelligence VS classical econometrics. AI Commun. 2014, 27, 301–314. [Google Scholar]
- Liao, R.; Zheng, H.; Grzybowski, S. Particle swarm optimization-least square support vector regression based forecasting model on dissolved gas in oil-filled power transformer. Electr. Power Syst. Res. 2011, 81, 2074–2080. [Google Scholar] [CrossRef]
- Liao, R.; Bian, J.; Yang, L. Forecasting dissolved gas content in power transformer oil based on weakening buffer operator and least square support vector machine–Markov. IET Gener. Transm. Dis. 2011, 6, 142–151. [Google Scholar] [CrossRef]
- Zheng, H.; Zhang, Y.; Liu, J. A novel model based on wavelet LS-SVM integrated improved POS algorithm for forecasting of dissolved gas contents in power transformer. Electr. Power Syst. Res. 2018, 155, 196–205. [Google Scholar] [CrossRef]
- Zhang, Y.; Wei, H.; Yang, Y. Forecasting of Dissolved gas in Oil-immersed Transformers Based upon Wavelet LS-SVM Regression and PSO with Mutation. Energy Procedia 2016, 104, 38–43. [Google Scholar] [CrossRef]
- Fei, S.; Liu, C.; Miao, Y. Support vector machine with genetic algorithm for forecasting of key-gas ratios in oil-immersed transformer. Expert Syst. Appl. 2009, 36, 6326–6331. [Google Scholar] [CrossRef]
- Fei, S.; Sun, Y. Forecasting dissolved gas content in power transformer oil based on support vector machine with genetic algorithm. Electr. Power Syst. Res. 2008, 78, 507–514. [Google Scholar] [CrossRef]
- Fei, S.; Wang, M.; Miao, Y. Particle swarm optimization-based support vector machine for forecasting dissolved gas content in power transformer oil. Energy Convers. Manag. 2009, 50, 1604–1609. [Google Scholar] [CrossRef]
- Cheng, K.; Lu, Z.; Wei, Y. Mixed kernel function support vector regression for global sensitivity analysis. Mech. Syst. Signal. Appl. 2017, 96, 201–214. [Google Scholar] [CrossRef]
- Zhu, X.; Huang, Z.; Shen, H. Dimensionality reduction by Mixed Kernel Canonical Correlation Analysis. Pattern Recognit. 2012, 45, 3003–3016. [Google Scholar] [CrossRef]
- Li, S.; Fang, H.; Liu, X. Parameter optimization of support vector regression based on sine cosine algorithm. Expert Syst. Appl. 2018, 91, 63–71. [Google Scholar] [CrossRef]
- Wu, L.; Cao, G. Seasonal SVR with FOA algorithm for single-step and multi-step ahead forecasting in monthly inbound tourist flow. Knowl.-Based Syst. 2016, 110, 157–166. [Google Scholar]
- Li, W.; Xuan, Y.; Li, H. Hybrid Forecasting Approach Based on GRNN Neural Network and SVR Machine for Electricity Demand Forecasting. Energies 2017, 10, 44. [Google Scholar] [CrossRef]
- Peng, L.; Fan, G.; Huang, M. Hybridizing DEMD and Quantum PSO with SVR in Electric Load Forecasting. Energies 2016, 9, 221. [Google Scholar] [CrossRef]
- Huang, M. Hybridization of Chaotic Quantum Particle Swarm Optimization with SVR in Electric Demand Forecasting. Energies 2016, 9, 426. [Google Scholar] [CrossRef]
- Zhong, Z.; Carr, T. Application of mixed kernels function (MKF) based support vector regression model (SVR) for CO2—Reservoir oil minimum miscibility pressure prediction. Fuel 2016, 184, 590–603. [Google Scholar] [CrossRef]
- Wu, D.; Wang, Z.; Chen, Y. Mixed-kernel based weighted extreme learning machine for inertial sensor based human activity recognition with imbalanced dataset. Neurocompuing 2016, 190, 35–49. [Google Scholar] [CrossRef]
- Zhang, Y.; Wang, Y.; Zhou, G. Multi-kernel extreme learning machine for EEG classification in brain-computer interfaces. Expert Syst. Appl. 2018, 96, 302–310. [Google Scholar] [CrossRef]
- Liu, Y.; Wang, R. Study on network traffic forecast model of SVR optimized by GAFSA. Chaos Solitons Fractals 2016, 89, 153–159. [Google Scholar] [CrossRef]
- Wang, S.; Hae, H.; Kim, J. Development of Easily Accessible Electricity Consumption Model Using Open Data and GA-SVR. Energies 2018, 11, 373. [Google Scholar] [CrossRef]
- Gholamalizadeh, E.; Kim, M. Multi-Objective Optimization of a Solar Chimney Power Plant with Inclined Collector Roof Using Genetic Algorithm. Energies 2016, 9, 971. [Google Scholar] [CrossRef]
- Li, C.; Zhai, R.; Yang, Y. Optimization of a Heliostat Field Layout on Annual Basis Using a Hybrid Algorithm Combining Particle Swarm Optimization Algorithm and Genetic Algorithm. Energies 2017, 10, 1924. [Google Scholar] [Green Version]
- Wang, B.; Yang, Z.; Lin, F. An Improved Genetic Algorithm for Optimal Stationary Energy Storage System Locating and Sizing. Energies 2014, 7, 6434–6458. [Google Scholar] [CrossRef] [Green Version]
- Haghrah, A.; Mohammadi, B.; Seyedmonir, S. Real coded genetic algorithm approach with random transfer vectors-based mutation for short-term hydrothermal scheduling. IET Gener. Transm. Distrib. 2013, 9, 75–89. [Google Scholar] [CrossRef]
- Herrera, F.; Lozano, M.; Verdegay, J. Tackling Real-Coded Genetic Algorithms: Operators and Tools for Behavioural Analysis. Artif. Intell. Rev. 1998, 12, 265–319. [Google Scholar] [CrossRef]
- Chang, C.; Lin, C. A library for support vector machines. ACM T. Intell. Syst. Technol. 2011, 2, 27:1–27:27. [Google Scholar]












{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Algorithms | Parameter | Value |
|---|---|---|
| SVR | Mixing coefficient ω | [0,1] |
| Penalty factor C | [0.001,100] | |
| RBF bandwidth σ | [0.001,100] | |
| Epsilon ε | [0.0001,0.1] | |
| Polynomial degree d | [1,5] | |
| GA | Population size | 50 |
| Iterations | 100 | |
| Crossover probability | 0.8 | |
| Mutation probability | 0.02 |
| Case Number | Date | H2 | CH4 | C2H6 | C2H4 | C2H2 | Data Type |
|---|---|---|---|---|---|---|---|
| 1 | 2015/7/8 | 3.79 | 80.57 | 97.44 | 167.51 | 0 | Training |
| 2015/7/9 | 4.04 | 88.02 | 101.8 | 178.63 | 0 | Training | |
| 2015/7/10 | 4.04 | 86.55 | 101.4 | 179.98 | 0 | Training | |
| 2015/7/11 | 4.05 | 86.68 | 100.98 | 180.39 | 0 | Training | |
| 2015/7/12 | 4.02 | 85.83 | 100.45 | 176.25 | 0 | Training | |
| 2015/7/13 | 3.81 | 79.74 | 97.75 | 168.92 | 0 | Training | |
| 2015/7/14 | 3.87 | 77.81 | 96.51 | 165.95 | 0 | Training | |
| 2015/7/15 | 3.82 | 78.55 | 96.93 | 168.37 | 0 | Training | |
| 2015/7/16 | 3.78 | 76.61 | 95.84 | 166.54 | 0 | Training | |
| 2015/7/17 | 4.07 | 81.91 | 98.46 | 175.09 | 0 | Training | |
| 2015/7/18 | 4.11 | 83.81 | 99.59 | 180.88 | 0 | Training | |
| 2015/7/19 | 4.06 | 83.12 | 99.37 | 181.06 | 0 | Training | |
| 2015/7/20 | 4.06 | 83.53 | 99.49 | 182.5 | 0 | Training | |
| 2015/7/21 | 4.04 | 83.03 | 98.96 | 180.45 | 0 | Training | |
| 2015/7/22 | 4.09 | 84.51 | 99.62 | 183.36 | 0 | Training | |
| 2015/7/23 | 3.81 | 78.88 | 97.04 | 172.18 | 0 | Training | |
| 2015/7/24 | 4.06 | 83.81 | 100.15 | 183.58 | 0 | Training | |
| 2015/7/25 | 4.11 | 85.37 | 101.33 | 188.73 | 0 | Training | |
| 2015/7/26 | 4.1 | 85.78 | 101.16 | 188.25 | 0 | Training | |
| 2015/7/27 | 3.79 | 79.17 | 97.29 | 172.77 | 0 | Training | |
| 2015/7/28 | 4.09 | 86.08 | 101.86 | 186.71 | 0 | Training | |
| 2015/7/29 | 4.09 | 86.69 | 102.14 | 187.1 | 0 | Training | |
| 2015/7/30 | 4.03 | 84.85 | 101.19 | 184.53 | 0 | Testing | |
| 2 | 2016/11/5 | 17.40 | 37.30 | 40.80 | 10.70 | 2.89 | Training |
| 2016/11/6 | 17.20 | 40.10 | 38.90 | 10.00 | 2.63 | Training | |
| 2016/11/7 | 18.60 | 39.90 | 39.50 | 10.80 | 2.59 | Training | |
| 2016/11/8 | 18.20 | 37.30 | 37.20 | 9.84 | 2.97 | Training | |
| 2016/11/9 | 20.80 | 34.50 | 40.10 | 9.73 | 2.55 | Training | |
| 2016/11/10 | 20.80 | 40.00 | 36.70 | 10.50 | 2.72 | Training | |
| 2016/11/11 | 17.40 | 34.50 | 40.70 | 9.20 | 2.60 | Training | |
| 2016/11/12 | 20.80 | 35.90 | 40.40 | 9.43 | 2.48 | Training | |
| 2016/11/13 | 20.20 | 38.00 | 41.60 | 9.89 | 2.73 | Training | |
| 2016/11/14 | 20.70 | 35.70 | 37.40 | 10.90 | 2.52 | Training | |
| 2016/11/15 | 18.50 | 39.00 | 40.30 | 9.87 | 2.62 | Training | |
| 2016/11/16 | 17.30 | 39.30 | 39.00 | 10.30 | 2.71 | Training | |
| 2016/11/17 | 18.80 | 37.00 | 43.70 | 10.40 | 2.26 | Training | |
| 2016/11/18 | 19.20 | 36.80 | 40.30 | 10.70 | 2.63 | Training | |
| 2016/11/19 | 16.40 | 38.70 | 45.90 | 9.72 | 2.26 | Training | |
| 2016/11/20 | 19.80 | 40.00 | 42.40 | 10.60 | 2.34 | Training | |
| 2016/11/21 | 19.70 | 38.20 | 41.60 | 11.40 | 2.69 | Training | |
| 2016/11/22 | 18.30 | 40.50 | 44.90 | 10.80 | 2.39 | Training | |
| 2016/11/23 | 18.20 | 34.70 | 43.90 | 11.30 | 2.28 | Training | |
| 2016/11/24 | 18.30 | 34.80 | 44.40 | 9.53 | 2.63 | Training | |
| 2016/11/25 | 16.50 | 40.80 | 42.70 | 10.60 | 2.50 | Training | |
| 2016/11/26 | 18.10 | 40.90 | 45.90 | 11.40 | 2.71 | Training | |
| 2016/11/27 | 19.80 | 36.20 | 45.00 | 11.00 | 2.39 | Testing | |
| 2016/11/28 | 19.60 | 35.10 | 46.00 | 9.61 | 2.45 | Testing | |
| 3 | 2015/7/15 | 8.58 | 7.58 | 6.39 | 1.65 | 0 | Training |
| 2015/7/22 | 7.67 | 7.11 | 5.54 | 1.58 | 0 | Training | |
| 2015/7/29 | 8.25 | 7.33 | 6.59 | 1.85 | 0 | Training | |
| 2015/8/5 | 8.62 | 7 | 5.88 | 1.66 | 0 | Training | |
| 2015/8/12 | 7.92 | 7.64 | 6.56 | 1.62 | 0 | Training | |
| 2015/8/19 | 7.57 | 7.3 | 6.4 | 1.87 | 0 | Training | |
| 2015/8/26 | 8.52 | 7.68 | 5.67 | 1.59 | 0 | Training | |
| 2015/9/2 | 7.51 | 7.48 | 6.53 | 1.74 | 0 | Training | |
| 2015/9/9 | 8.14 | 7.67 | 5.64 | 1.6 | 0 | Training | |
| 2015/9/16 | 8.3 | 9.51 | 6.91 | 2.11 | 0 | Training | |
| 2015/9/23 | 7.84 | 9.89 | 7.14 | 2.11 | 0 | Training | |
| 2015/9/30 | 7.57 | 9.76 | 7.58 | 2.2 | 0 | Training | |
| 2015/10/7 | 8.68 | 9.52 | 6.95 | 2.11 | 0 | Training | |
| 2015/10/14 | 7.94 | 8.97 | 6.64 | 1.97 | 0 | Testing | |
| 2015/10/21 | 7.79 | 8.11 | 6.59 | 2.19 | 0 | Testing |
| Dissolved Gas | Kernel Type | MAPE/% | Average r2 | ||
|---|---|---|---|---|---|
| Max | Min | Average | |||
| H2 | Linear | 0.9132 | 0.5176 | 0.8227 ± 0.1018 | 0.0403 ± 0.0064 |
| Sigmoid | 0.6392 | 0.4035 | 0.5484 ± 0.0801 | 0.0649 ± 0.0188 | |
| Gaussian | 0.6917 | 0.4961 | 0.6077 ± 0.0484 | 0.9958 ± 0.0018 | |
| Polynomial | 1.4718 | 0.8222 | 1.1495 ± 0.1422 | 0.2311 ± 0.0834 | |
| Mixed | 0.7411 | 0.0653 | 0.4144 ± 0.1764 | 0.9881 ± 0.0272 | |
| CH4 | Linear | 1.7395 | 0.4885 | 1.1726 ± 0.3569 | 0.1582 ± 0.0178 |
| Sigmoid | 2.6103 | 0.3090 | 1.9075 ± 0.3687 | 0.0049 ± 0.0217 | |
| Gaussian | 2.7872 | 2.5508 | 2.7202 ± 0.0631 | 0.9838 ± 0.0067 | |
| Polynomial | 2.5717 | 0.2112 | 1.5787 ± 0.6075 | 0.7397 ± 0.2489 | |
| Mixed | 2.3868 | 0.0176 | 1.1702 ± 0.6838 | 0.9035 ± 0.1975 | |
| C2H6 | Linear | 2.5265 | 1.1519 | 1.4769 ± 0.3788 | 0.1445 ± 0.0059 |
| Sigmoid | 3.7174 | 3.6412 | 3.6703 ± 0.0201 | 0.0007 ± 0.0001 | |
| Gaussian | 2.1104 | 2.0794 | 2.1027 ± 0.0006 | 0.9854 ± 0.0042 | |
| Polynomial | 14.6658 | 0.1851 | 7.9456 ± 6.3304 | 0.6667 ± 0.3152 | |
| Mixed | 1.1391 | 0.0105 | 0.4101 ± 0.2536 | 0.9713 ± 0.0394 | |
| C2H4 | Linear | 1.1385 | 0.0957 | 0.4457 ± 0.3161 | 0.2592 ± 0.0135 |
| Sigmoid | 9.4499 | 0.2294 | 3.3252 ± 1.9865 | 0.1056 ± 0.0514 | |
| Gaussian | 2.2305 | 1.2168 | 2.0206 ± 0.2003 | 0.9917 ± 0.0052 | |
| Polynomial | 1.7409 | 0.5681 | 1.5511 ± 0.3239 | 0.6648 ± 0.1375 | |
| Mixed | 2.8552 | 0.4731 | 1.4342 ± 0.4458 | 0.9590 ± 0.0180 | |
| Dissolved Gas | Kernel Type | MAPE/% | Average r2 | ||
|---|---|---|---|---|---|
| Max | Min | Average | |||
| H2 | Linear | 3.8211 | 2.2219 | 3.2477 ± 0.3734 | 0.0474 ± 0.0055 |
| Sigmoid | 3.9352 | 3.8265 | 3.8321 ± 0.0192 | 0.0252 ± 0.0392 | |
| Gaussian | 4.5223 | 3.9864 | 4.1491 ± 0.1088 | 0.9723 ± 0.0021 | |
| Polynomial | 11.6459 | 6.4116 | 10.7708 ± 0.773 | 0.9598 ± 0.0197 | |
| Mixed | 4.1166 | 3.9798 | 4.0138 ± 0.0311 | 0.9855 ± 0.0184 | |
| CH4 | Linear | 5.6681 | 0.9128 | 1.9240 ± 1.6286 | 0.1198 ± 0.0064 |
| Sigmoid | 35.2251 | 3.8304 | 19.7238 ± 4.9772 | 0.0037 ± 0.0041 | |
| Gaussian | 5.7169 | 5.6574 | 5.6986 ± 0.0139 | 0.9921 ± 0.0007 | |
| Polynomial | 38.4981 | 2.885 | 34.8767 ± 7.934 | 0.9059 ± 0.1747 | |
| Mixed | 5.4689 | 3.7155 | 4.9363 ± 0.4794 | 0.9877 ± 0.0309 | |
| C2H4 | Linear | 2.4426 | 0.1028 | 1.5430 ± 0.6544 | 0.5348 ± 0.0086 |
| Sigmoid | 8.3909 | 0.1954 | 8.0604 ± 1.5451 | 0.0560 ± 0.0891 | |
| Gaussian | 5.5427 | 4.8443 | 5.2869 ± 0.1656 | 0.9694 ± 0.0239 | |
| Polynomial | 13.3713 | 9.7006 | 12.1296 ± 0.997 | 0.9009 ± 0.0084 | |
| Mixed | 3.18 | 1.5021 | 2.6799 ± 0.4240 | 0.9797 ± 0.0797 | |
| C2H6 | Linear | 10.2447 | 8.0635 | 9.2906 ± 0.6432 | 0.1107 ± 0.0112 |
| Sigmoid | 11.3452 | 7.4219 | 10.1950 ± 1.2591 | 0.0051 ± 0.0074 | |
| Gaussian | 6.9159 | 6.7734 | 6.8489 ± 0.0324 | 0.9752 ± 0.0032 | |
| Polynomial | 20.9745 | 6.2449 | 19.6727 ± 2.644 | 0.8881 ± 0.0164 | |
| Mixed | 6.8225 | 6.8054 | 6.8085 ± 0.0035 | 0.9891 ± 0.0081 | |
| C2H2 | Linear | 2.5655 | 0.1149 | 1.6961 ± 0.6905 | 0.3469 ± 0.0059 |
| Sigmoid | 5.2049 | 5.0081 | 5.1173 ± 0.0466 | 0.0006 ± 0.0005 | |
| Gaussian | 4.2828 | 4.1690 | 4.2138 ± 0.0299 | 0.9695 ± 0.0022 | |
| Polynomial | 10.714 | 4.92 | 9.6174 ± 1.3411 | 0.8397 ± 0.0134 | |
| Mixed | 3.1884 | 2.6363 | 2.9458 ± 0.1212 | 0.9934 ± 0.0079 | |
| Case No. | Dissolved Gas | Parameters | MAPE/% | ||||||
|---|---|---|---|---|---|---|---|---|---|
| m | C | σ | ξ | d | ω | Training | Testing | ||
| 1 | H2 | 3 | 45.2410 | 66.4078 | 0.0228 | 1.8197 | 0.9991 | 0.1884 | 0.0645 |
| CH4 | 3 | 64.0668 | 24.8862 | 0.0261 | 1.5696 | 0.3923 | 0.3509 | 1.0295 | |
| C2H6 | 4 | 72.7747 | 68.2022 | 0.0051 | 2.8875 | 0.1179 | 0.0332 | 0.1292 | |
| C2H4 | 3 | 51.1808 | 77.3654 | 0.0538 | 3.7792 | 0.2934 | 0.6412 | 0.4713 | |
| 2 | H2 | 4 | 66.6143 | 59.5728 | 0.0273 | 1.1563 | 0.7490 | 0.6221 | 4.0578 |
| CH4 | 3 | 62.6013 | 53.9830 | 0.0033 | 2.0307 | 0.9092 | 0.0576 | 4.1765 | |
| C2H6 | 5 | 44.8368 | 19.0071 | 0.0087 | 2.6108 | 09281 | 0.1917 | 1.5704 | |
| C2H4 | 5 | 43.9790 | 68.0588 | 0.0134 | 1.0770 | 0.8621 | 0.2843 | 6.7836 | |
| C2H2 | 5 | 63.0017 | 47.3237 | 0.0026 | 2.6083 | 0.7759 | 0.0754 | 2.9589 | |
| 3 | H2 | 1 | 2.2736 | 91.1686 | 0.0639 | 1.0834 | 0.7572 | 1.0224 | 0.8085 |
| CH4 | 1 | 0.1742 | 55.3330 | 0.0577 | 3.0111 | 0.0381 | 4.9175 | 3.6875 | |
| C2H6 | 5 | 6.3558 | 88.1067 | 0.0012 | 2.6507 | 0.9225 | 0.0430 | 6.3674 | |
| C2H4 | 4 | 70.8075 | 95.6627 | 0.0269 | 1.7927 | 0.9516 | 0.8165 | 0.0185 | |
| Case | Kernel Type | H2 | CH4 | C2H6 | C2H4 | C2H2 |
|---|---|---|---|---|---|---|
| 1 | Actual/Mixed RBF/Polynomial | 4.0300/4.0274/ 4.0101/4.0631 | 84.8500/85.7235/ 82.6856/85.0292 | 101.1900/101.3207/ 99.0858/102.5478/ | 184.5300/185.4030/ 186.7754/187.6218 | -- |
| MAPE(%) (2015/7/30) | 0.0645/0.4938 /0.8213 | 1.0295/2.5509 /0.2112 | 0.1292/2.0794/ /1.3418 | 0.4731/1.2168/ /1.6755 | -- | |
| 2 | Actual-1/Mixed RBF/Polynomial | 19.8000/18.9596/ 18.913/20.434 | 36.2/37.2366/ 37.707/36.548 | 45.0000/44.4396/ 43.0012/51.855 | 11.0000/10.4411/ 10.3502/7.7145 | 2.3900/2.5220/ 2.5206/2.5333 |
| Actual-2/Mixed RBF/Polynomial | 19.6000/18.8412/ 18.9117/17.7143 | 35.1000/37.0268/ 37.6111/36.5464 | 46.0000/45.1275/ 43.5865/43.442 | 9.6100/10.4255/ 10.3503/9.017 | 2.4500/2.4596/ 2.5258/2.1396 | |
| MAPE1(%) (2016/11/27) | 4.2444/4.4848 /10.5353 | 2.8635/4.1630 /0.9613 | 1.2447/4.4418 /15.2333 | 5.0809/5.9063 /29.8636 | 5.5230/5.4644 /5.9832 | |
| MAPE2(%) (2016/11/28) | 3.8714/3.5102 /9.6224 | 5.4894/7.1538 /4.1197 | 1.896/5.2467 /5.5608 | 8.4860/7.7034 /6.1707 | 0.3918/3.0938 /12.6938 | |
| 3 | Actual-1/Mixed RBF/Polynomial | 7.9400/7.9315/ 7.9160/7.5543 | 8.9700/9.4120/ 9.3905/9.2016 | 1.9700/2.0758/ 1.9234/1.4785 | 6.6400/6.6377/ 6.5933/5.0692 | -- |
| Actual-2/Mixed RBF/Polynomial | 7.7900/7.6724/ 7.7044/7.8758 | 8.1100/8.5526/ 8.8907/8.4542 | 2.1900/2.0287/ 1.9234/1.1178 | 6.5900/6.5902/ 6.5933/4.0049 | -- | |
| MAPE-1(%) (2015/10/14) | 0.1068/0.3025 /4.8574 | 1.9171/4.6881 /2.5814 | 5.3716/2.3650 /24.9491 | 0.0340/0.7033 /23.6561 | -- | |
| MAPE-2(%) (2015/10/21) | 1.5102/1.0988 /1.1014 | 5.4580/9.6268 /4.2437 | 7.3631/12.1731 /48.9590 | 0.0031/0.0501 /39.2284 | -- |
| Methods | Training Set | Testing Set | |
|---|---|---|---|
| MAPE | r2 | MAPE | |
| MKF-SVR | 0.4144 | 0.9881 | 0.0645 |
| GRNN | 0.7625 | 0.8566 | 1.0893 |
| RBFNN | 2.1712 | 0.3478 | 0.8734 |
| GM | 2.6542 | 0.0911 | 0.2062 |
© 2018 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Kari, T.; Gao, W.; Tuluhong, A.; Yaermaimaiti, Y.; Zhang, Z. Mixed Kernel Function Support Vector Regression with Genetic Algorithm for Forecasting Dissolved Gas Content in Power Transformers. Energies 2018, 11, 2437. https://doi.org/10.3390/en11092437
Kari T, Gao W, Tuluhong A, Yaermaimaiti Y, Zhang Z. Mixed Kernel Function Support Vector Regression with Genetic Algorithm for Forecasting Dissolved Gas Content in Power Transformers. Energies. 2018; 11(9):2437. https://doi.org/10.3390/en11092437
Chicago/Turabian StyleKari, Tusongjiang, Wensheng Gao, Ayiguzhali Tuluhong, Yilihamu Yaermaimaiti, and Ziwei Zhang. 2018. "Mixed Kernel Function Support Vector Regression with Genetic Algorithm for Forecasting Dissolved Gas Content in Power Transformers" Energies 11, no. 9: 2437. https://doi.org/10.3390/en11092437
APA StyleKari, T., Gao, W., Tuluhong, A., Yaermaimaiti, Y., & Zhang, Z. (2018). Mixed Kernel Function Support Vector Regression with Genetic Algorithm for Forecasting Dissolved Gas Content in Power Transformers. Energies, 11(9), 2437. https://doi.org/10.3390/en11092437