A Cluster-Based Baseline Load Calculation Approach for Individual Industrial and Commercial Customer


Abstract
:1. Introduction
2. The General Framework of Calculating CBL
3. Baseline Estimation Methods for Individual Customer
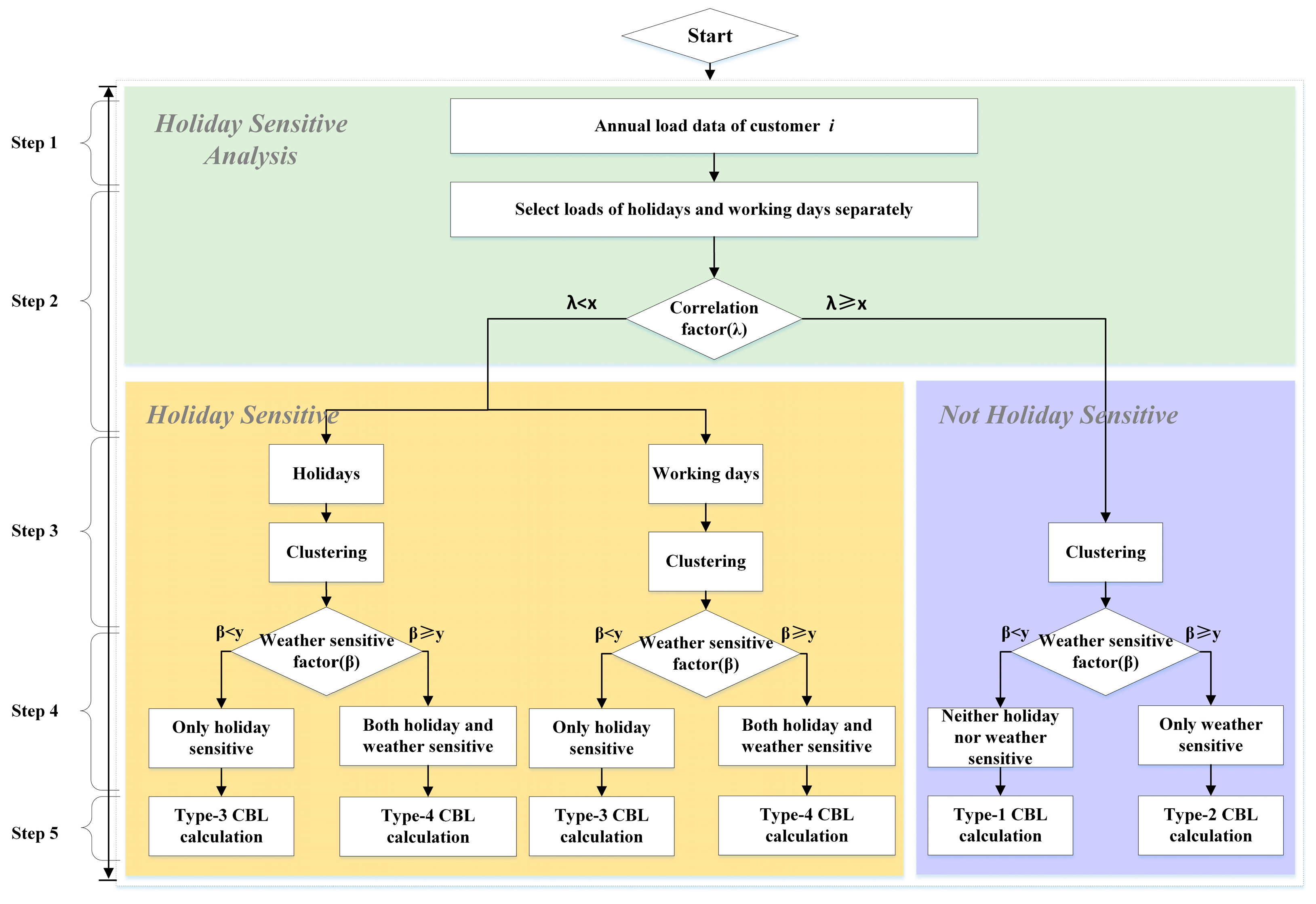
3.1. Data-Mining Approach Based on Clustering Analysis
3.2. CBL Calculation Methods
3.2.1. Simple Average Model-High X of Y
3.2.2. Simple Average Model-Middle X of Y
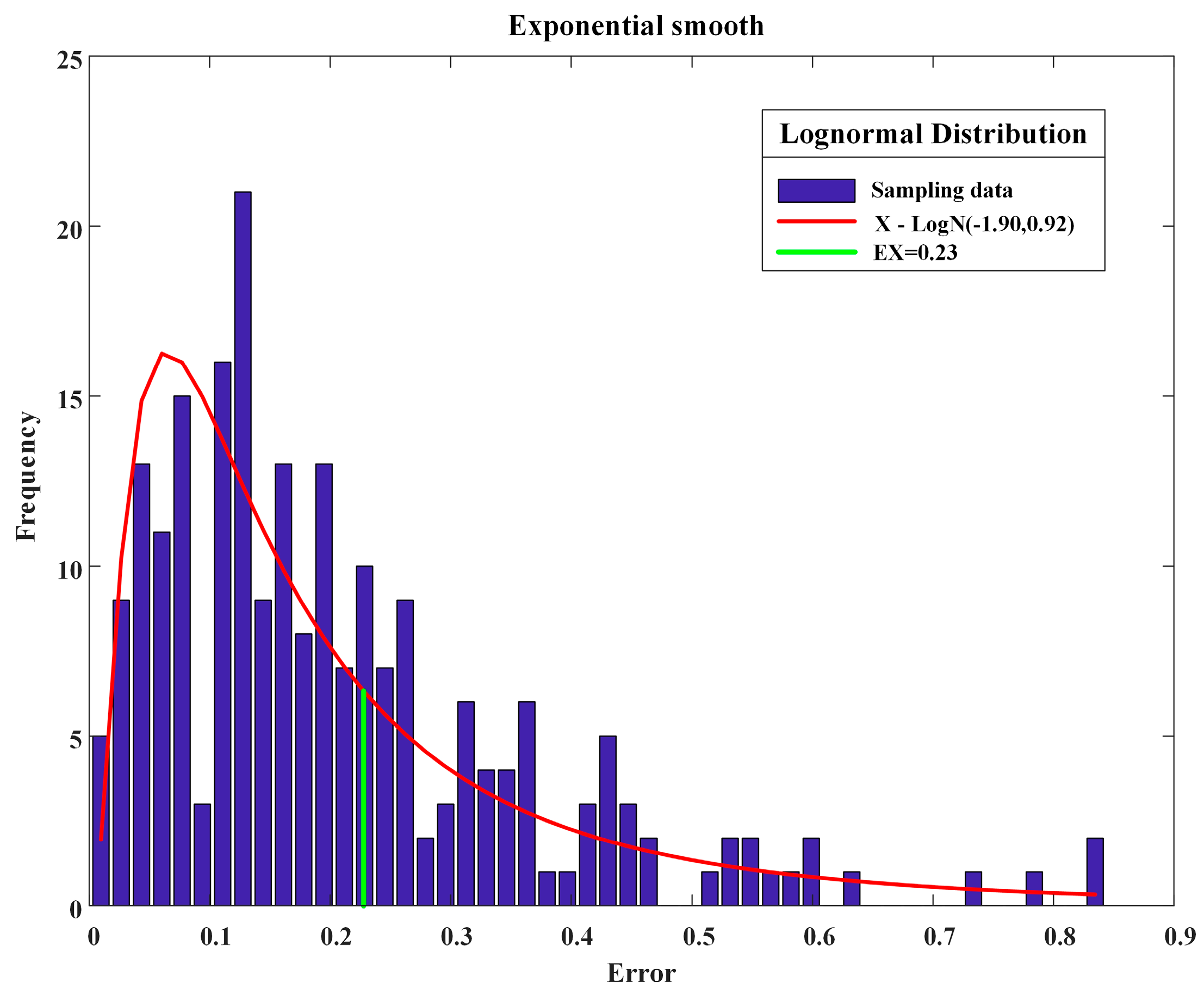
3.2.3. Exponential Smoothing Model
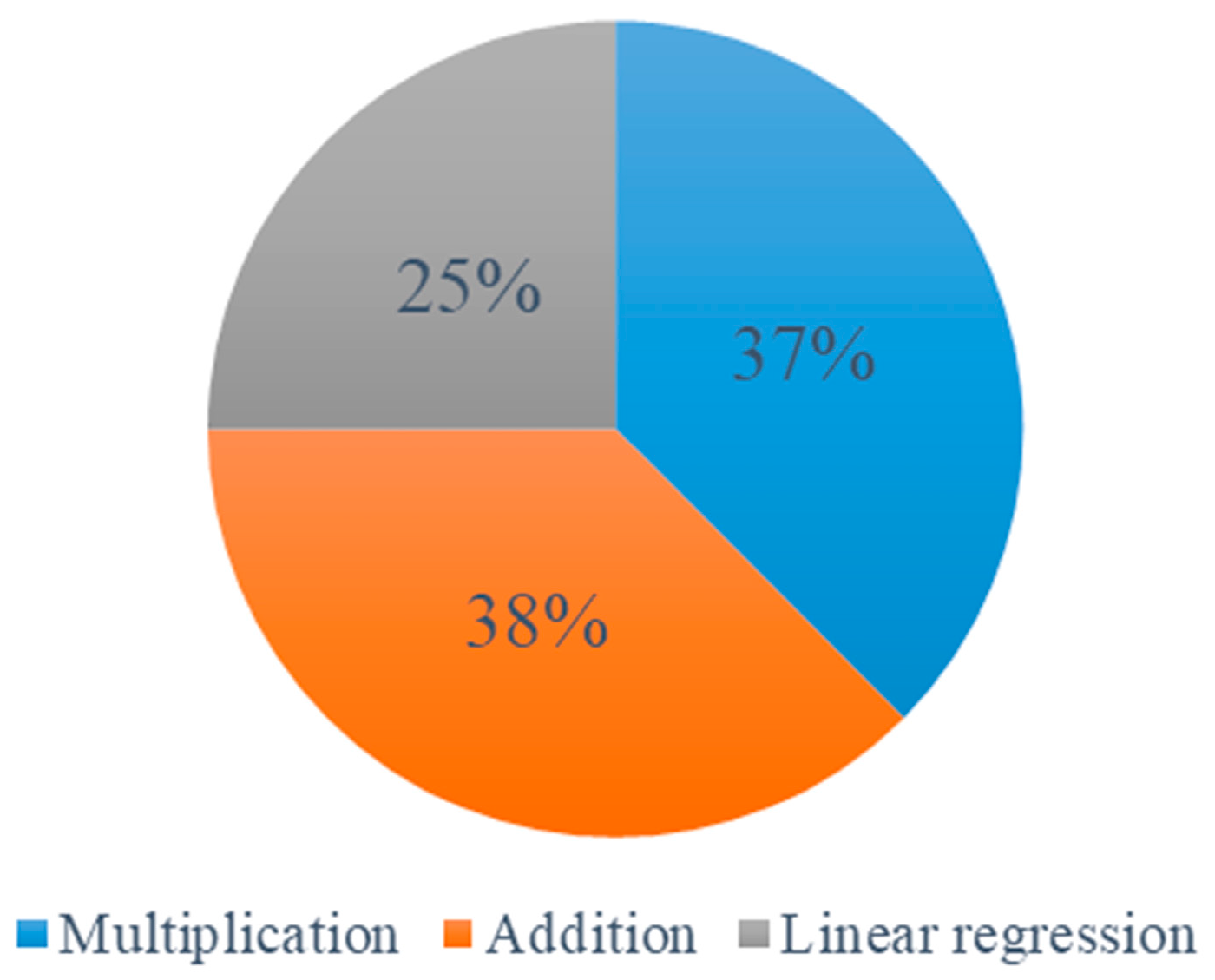
3.3. CBL Adjustment Method
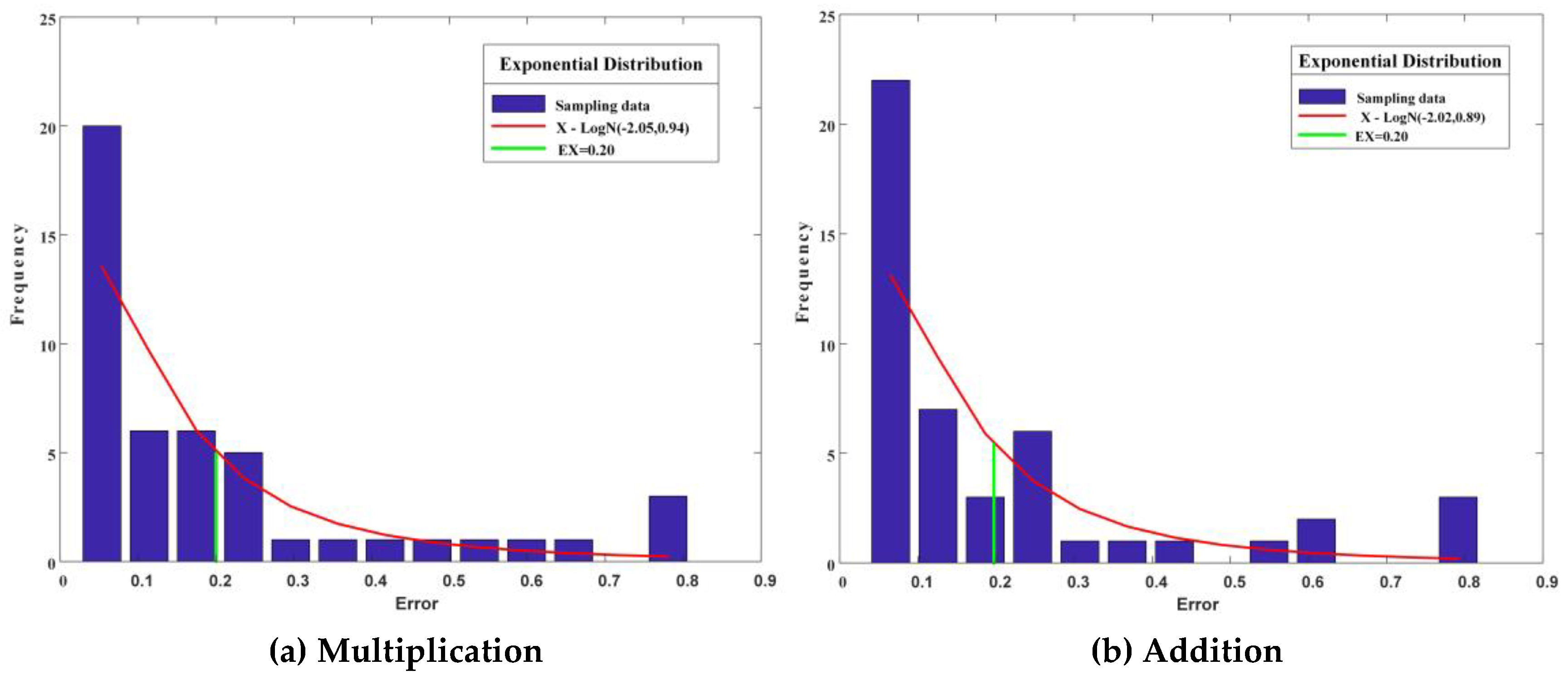
3.3.1. Multiplication Adjustment
3.3.2. Addition Adjustment
3.3.3. Linear Regression Adjustment
4. Empirical Tests
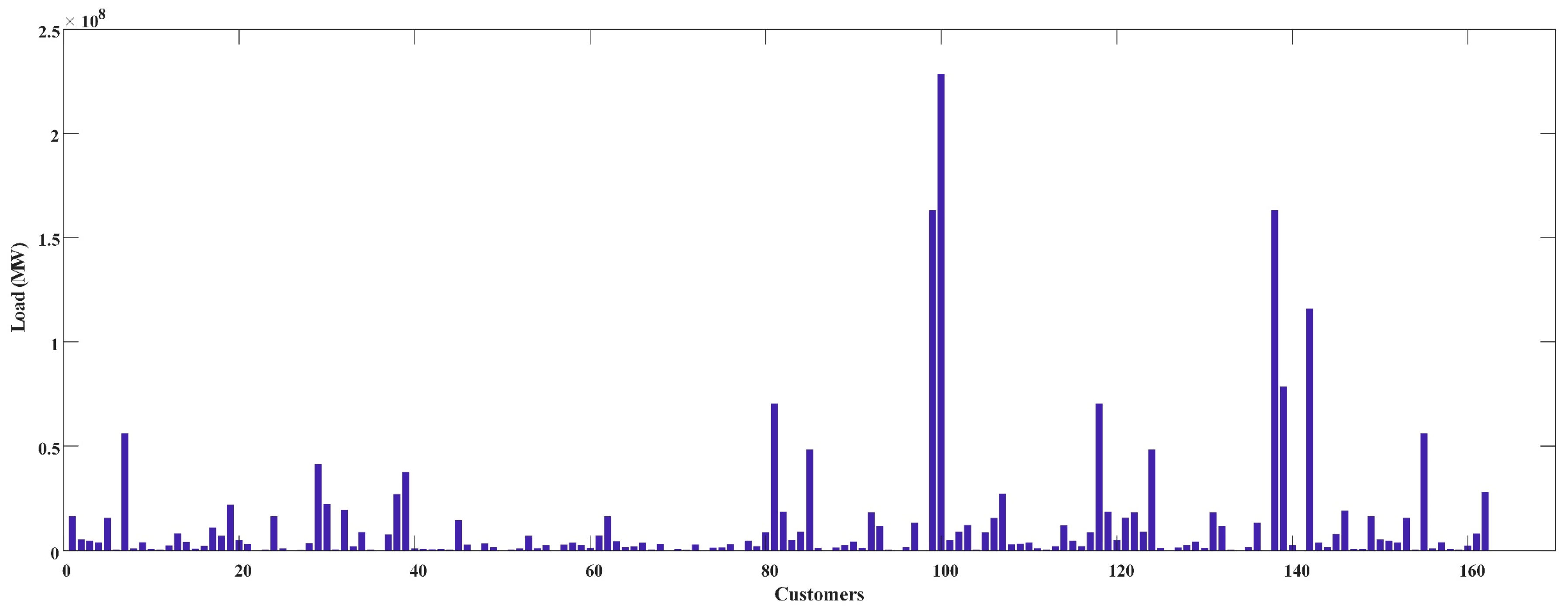
4.1. Data Overview
4.2. CBL Performance Metrics
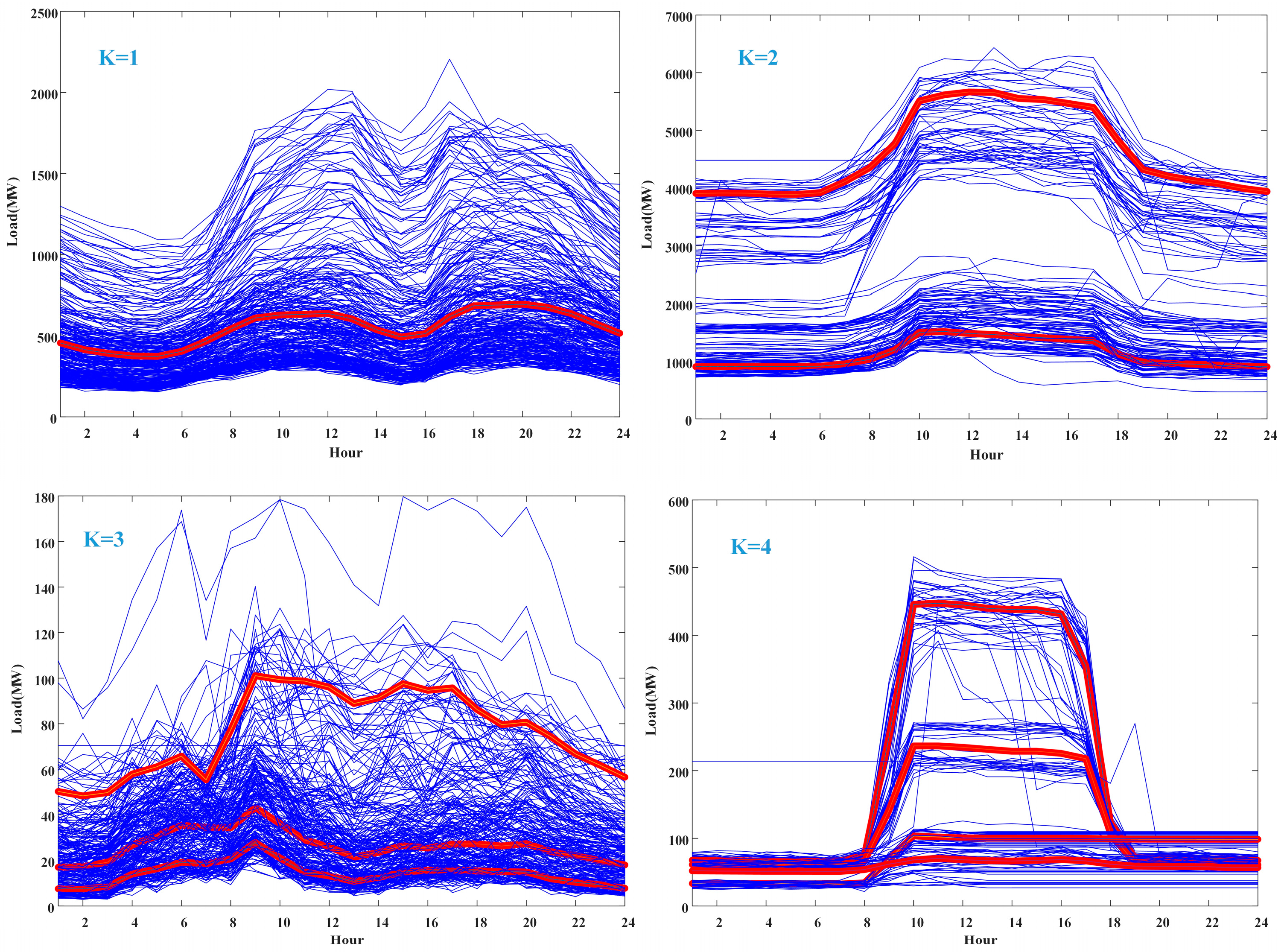
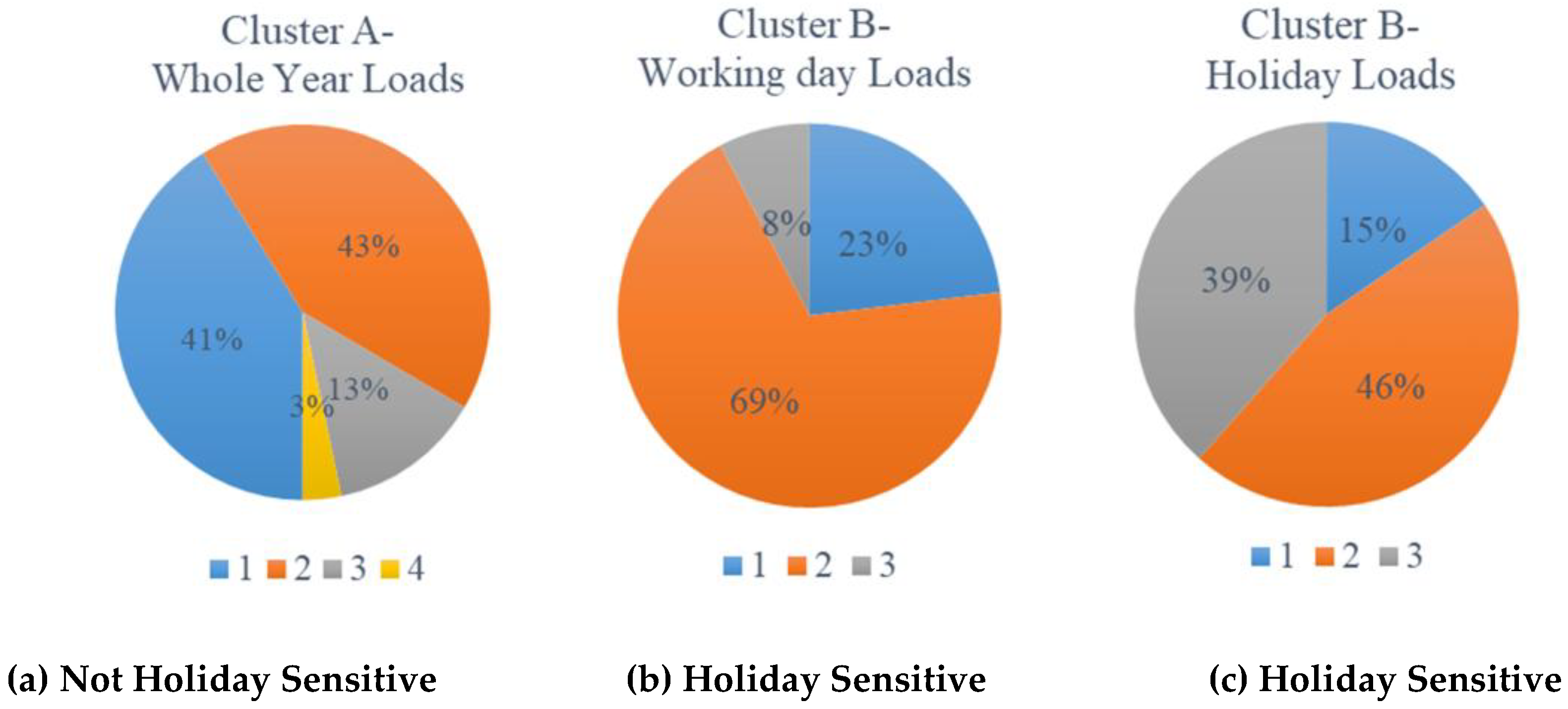
4.3. Clusters
4.4. Experimental Settings
4.4.1. Scenarios
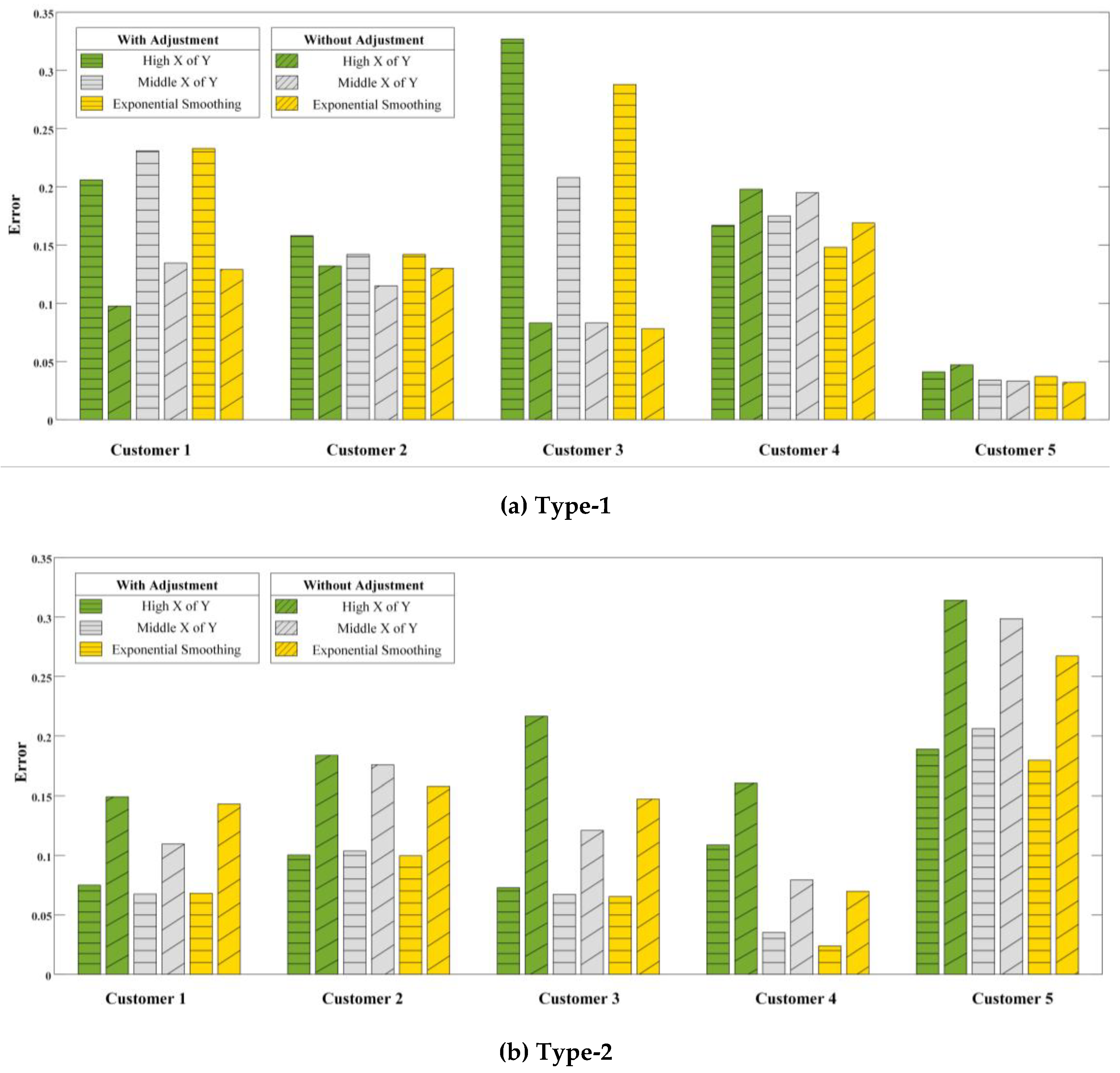
- Type-1: Neither holiday nor weather sensitive.
- Type-2: Only weather sensitive.
- Type-3: Only holiday sensitive.
- Type-4: Both weather and holiday sensitive.
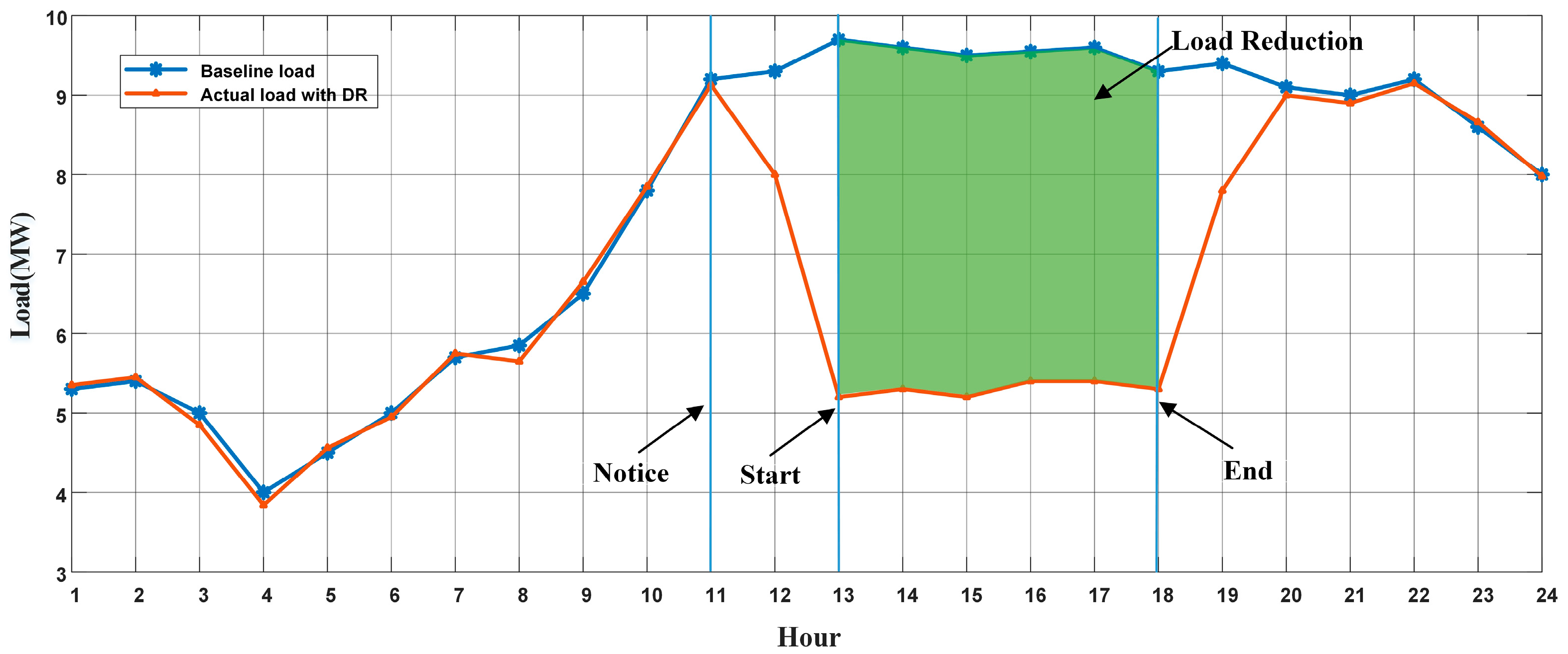
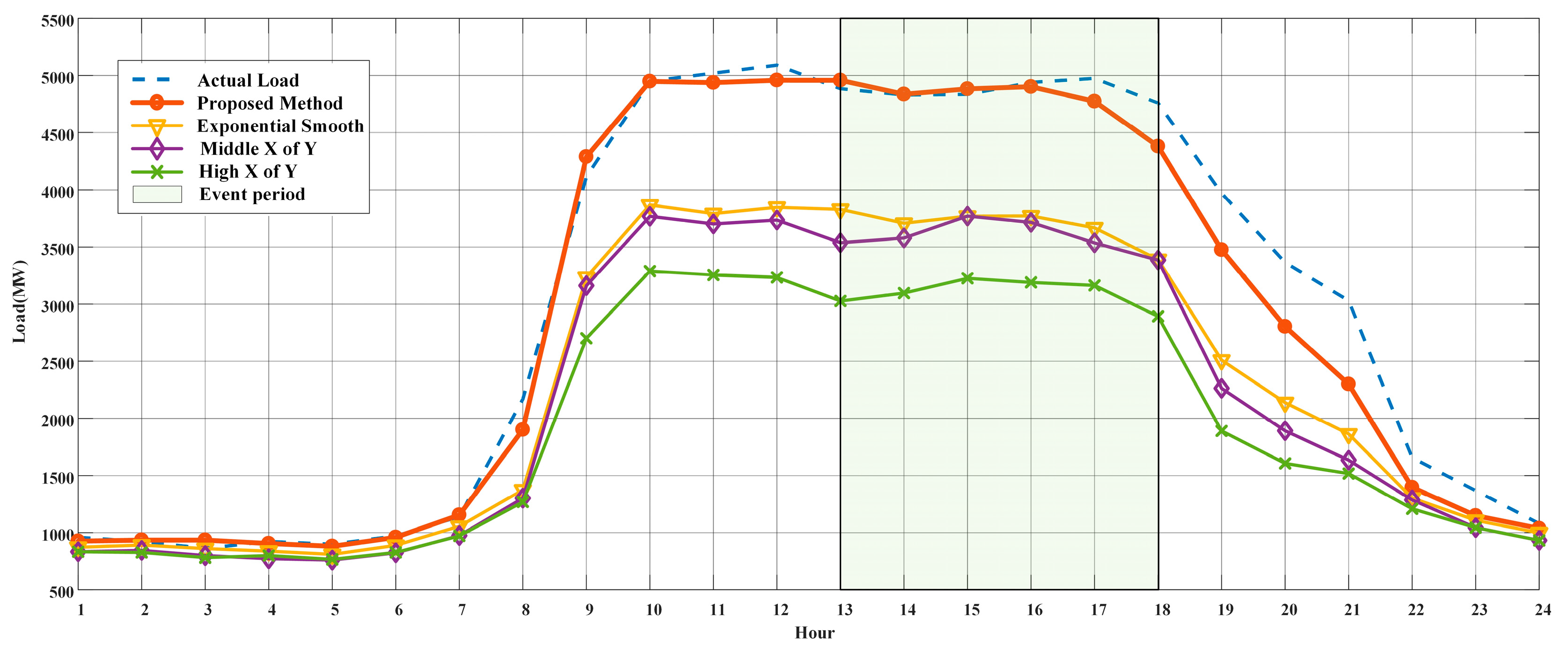
4.4.2. Type of DR Event Day
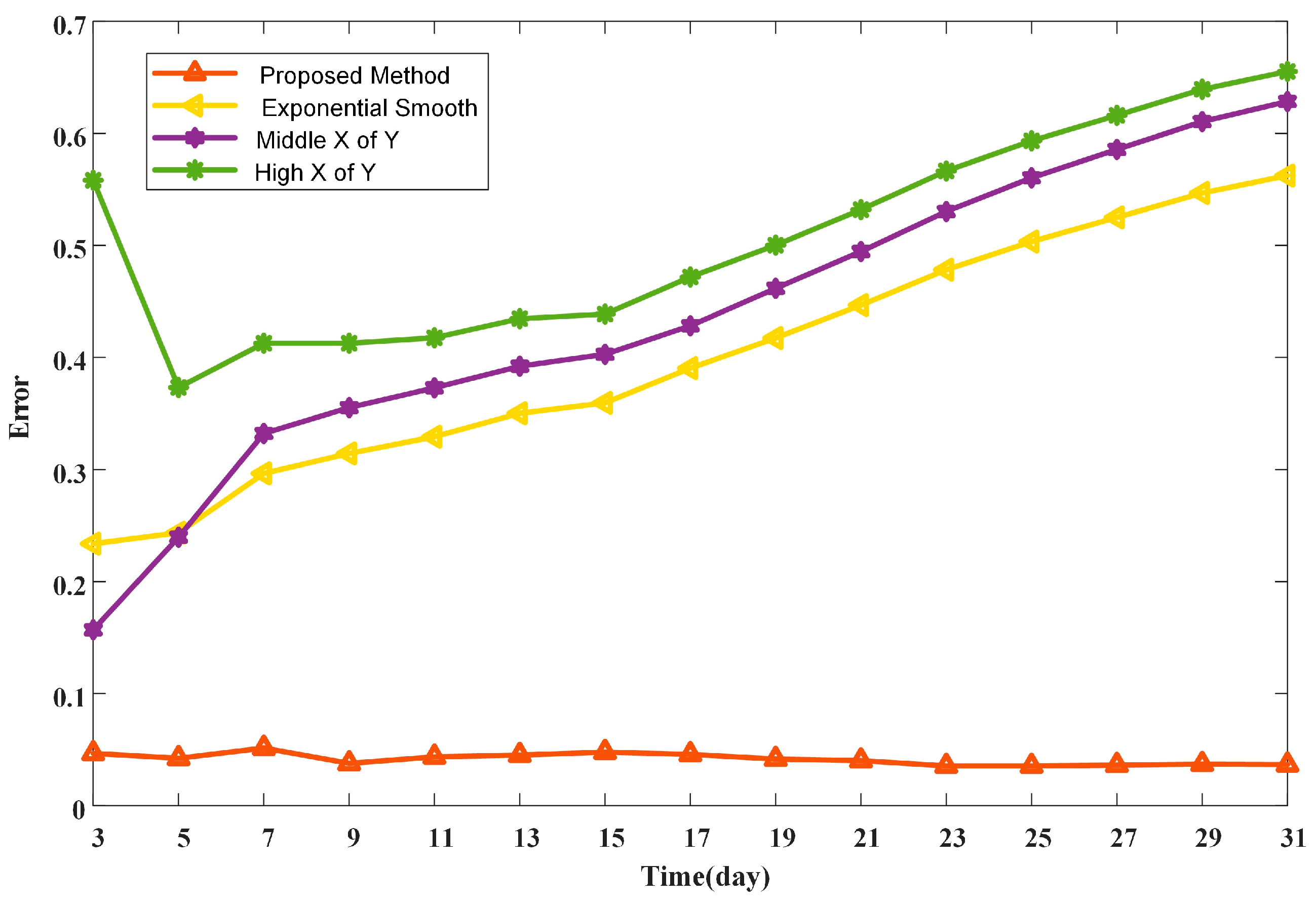
4.5. Baseline Estimation Results
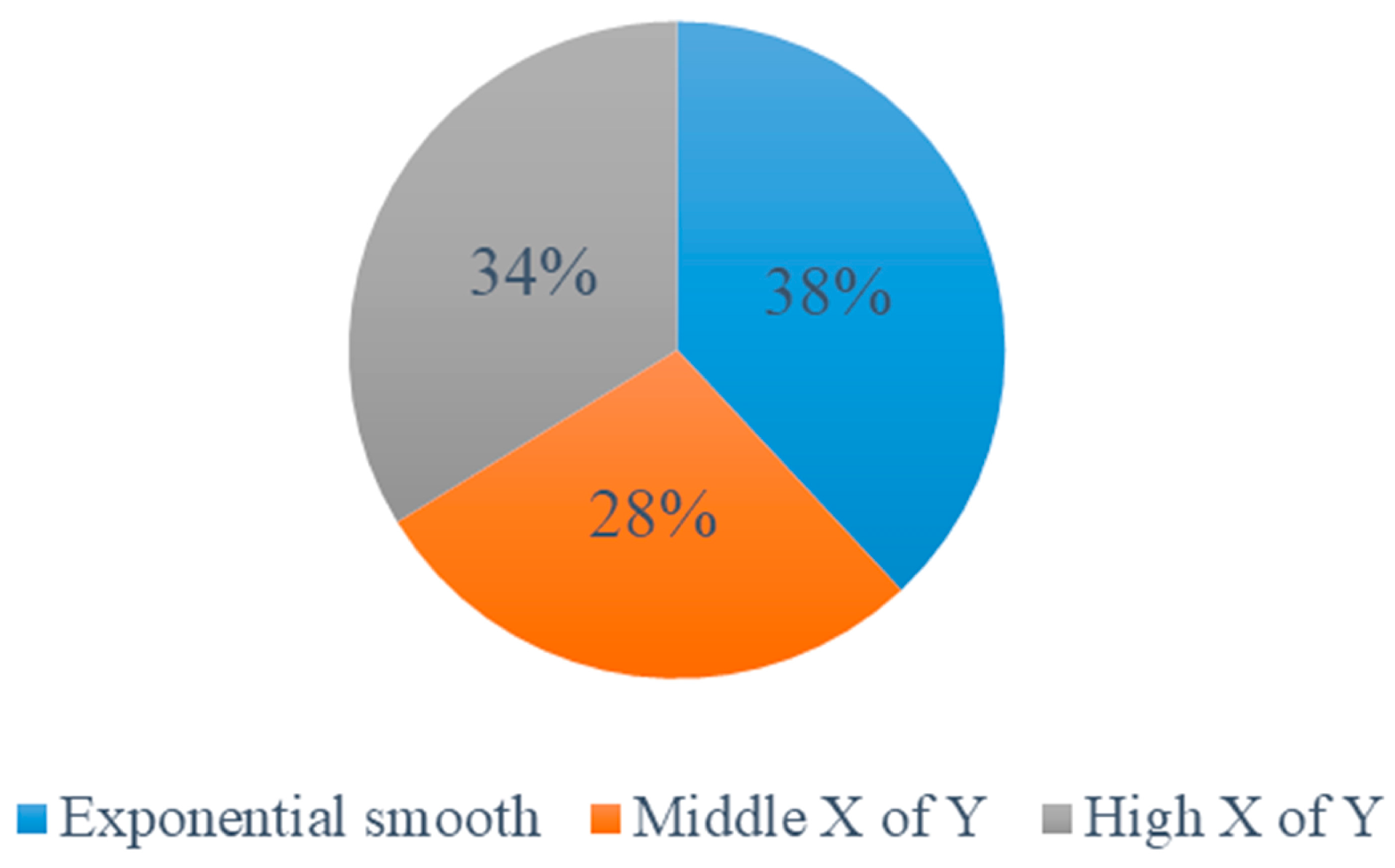
4.5.1. The Method for Each Type
4.5.2. Comparative Analysis
5. Conclusions
- Extending the method to residential customers to determine the applicability of the proposed methods.
- Applying the methods to data datasets from other regions in the presence of a real DR program.
- More clustering algorithms can be applied to our method to test whether the performance of CBL can be improved from our quadratic clustering method.
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
References
- Lee, M.; Aslam, O.; Foster, B.; Kathan, D.; Kwok, J.; Medearis, L.; Palmer, R.; Sporborg, P.; Tita, M. Assessment of Demand Response and Advanced Metering; Federal Energy Regulatory Commission: Washington, DC, USA, 2013.
- Su, C.-L.; Kirschen, D. Quantifying the effect of demand response on electricity markets. IEEE Trans. Power Syst. 2009, 24, 1199–1207. [Google Scholar]
- Ahmad, S.; Ahmad, A.; Naeem, M.; Ejaz, W.; Kim, H. A Compendium of Performance Metrics, Pricing Schemes, Optimization Objectives, and Solution Methodologies of Demand Side Management for the Smart Grid. Energies 2018, 11, 2801. [Google Scholar] [CrossRef]
- Chao, H.-P. Demand response in wholesale electricity markets: The choice of customer baseline. J. Regul. Econ. 2011, 39, 68–88. [Google Scholar] [CrossRef]
- Conejo, A.J.; Morales, J.M.; Baringo, L. Real-time demand response model. IEEE Trans. Smart Grid 2010, 1, 236–242. [Google Scholar] [CrossRef]
- Chen, W.; Wang, X.; Petersen, J.; Tyagi, R.; Black, J. Optimal scheduling of demand response events for electric utilities. IEEE Trans. Smart Grid 2013, 4, 2309–2319. [Google Scholar] [CrossRef]
- Zhang, Y.; Chen, W.; Xu, R.; Black, J. A cluster-based method for calculating baselines for residential loads. IEEE Trans. Smart Grid 2016, 7, 2368–2377. [Google Scholar] [CrossRef]
- Park, S.; Ryu, S.; Choi, Y.; Kim, J.; Kim, H. Data-Driven Baseline Estimation of Residential Buildings for Demand Response. Energies 2015, 8, 10239–10259. [Google Scholar] [CrossRef] [Green Version]
- PJM Empirical Analysis of Demand Response Baseline Methods. PJM Load Manage. Task Force; KEMA Inc.: Clark Lake, MI, USA, 2011.
- Day-Ahead and Real-time Market Operations. PJM Manual 11: Energy & Ancillary Service Market Operations. 2017. Available online: https://www.pjm.com/~/media/documents/manuals/m11.ashx (accessed on 1 November 2017).
- Qu, D.; Wu, W.; Jiang, D.; Chen, G. Calculation method of radial basis function neural network based on user demand side response baseline load. Electron. Test 2014, 2, 26–30. (In Chinese) [Google Scholar]
- Liu, G.; Gao, Y.; Wang, L. Baseline load calculation with considering customer different electrical characteristics. Power Demand Side Manag. 2016, 33, 17–22. [Google Scholar]
- Baylis, P.; Cappers, P.; Jin, L.; Spurlock, A.; Todd, A. Go for the Silver? Evidence from field studies quantifying the difference in evaluation results between “gold standard” randomized controlled trial methods versus quasi-experimental methods. In Proceedings of the ACEEE Summer Study on Energy Efficiency in Buildings, Asilomar, CA, USA, 21–26 August 2016. [Google Scholar]
- Mohajeryami, S.; Doostan, M.; Asadinejad, A.; Schwarz, P. Error analysis of customer baseline load (CBL) calculation methods for residential customers. IEEE Trans. Ind. Appl. 2017, 53, 5–14. [Google Scholar] [CrossRef]
- Wijaya, T.K.; Vasirani, M.; Aberer, K. When bias matters: An economic assessment of demand response baselines for residential customers. IEEE Trans. Smart Grid 2014, 5, 1755–1763. [Google Scholar] [CrossRef]
- Fallah, S.N.; Deo, R.C.; Shojafar, M.; Conti, M.; Shamshirband, S. Computational Intelligence Approaches for Energy Load Forecasting in Smart Energy Management Grids: State of the Art, Future Challenges, and Research Directions. Energies 2018, 11, 596. [Google Scholar] [CrossRef]
- Wang, Y.; Chen, Q.; Sun, M.; Kang, C.; Xia, Q. An ensemble forecasting method for the aggregated load with sub profiles. IEEE Trans. Smart Grid 2018, 9, 3906–3908. [Google Scholar] [CrossRef]
- Huang, J.; Li, Y.; Liu, Y. Summer daily peak load forecasting considering accumulation effect and abrupt change of temperature. In Proceedings of the Power and Energy Society General Meeting (PES), San Diego, CA, USA, 22–26 July 2012; Volume 6, pp. 1–4. [Google Scholar]
- Gao, C.; Li, Q.; Su, W.; Li, Y. Temperature correction model research considering temperature cumulative effect in short-term load forecasting. Trans. China Electrotech. Soc. 2015, 4, 242–248. (In Chinese) [Google Scholar]
- Grimm, C.; Energy, D.T.E. Evaluating baselines for demand response programs. In Proceedings of the AEIC Load Research Workshop, San Antonio, TX, USA, 25–27 February 2008. [Google Scholar]
- Faria, P.; Vale, Z.; Antunes, P. Determining the adjustment baseline parameters to define an accurate customer baseline load. In Proceedings of the Power and Energy Society General Meeting (PES), Vancouver, BC, Canada, 21–25 July 2013; pp. 1–5. [Google Scholar]
- Yamaguchi, N.; Han, J.; Ghatikar, G.; Kiliccote, S.; Piette, M.A.; Asano, H. Regression models for demand reduction based on cluster analysis of load profiles. In Proceedings of the Sustainable Alternative Energy (SAE), Valencia, Spain, 28–30 September 2009; pp. 1–7. [Google Scholar]
- Hatton, L.; Charpentier, P.; Matzner-Løber, E. Statistical estimation of the residential baseline. IEEE Trans. Power Syst. 2016, 31, 1752–1759. [Google Scholar] [CrossRef]
- Li, C.; Li, X.; Zhao, R.; Li, J.; Liu, X. A novel algorithm of selecting similar days for short-term power load forecasting. Autom. Electr. Power Syst. 2008, 9, 18. (In Chinese) [Google Scholar]
- Sun, X.; Luh, P.B.; Cheung, K.W.; Guan, W.; Michel, L.D.; Venkata, S.; Miller, M.T. An efficient approach to short-term load forecasting at the distribution level. IEEE Trans. Power Syst. 2016, 31, 2526–2537. [Google Scholar] [CrossRef]














{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Type | Type-1 | Type-2 | Type-3 | Type-4 |
|---|---|---|---|---|
| Numbers | 215 | 37 | 34 | 14 |
| Methods | Proposed Method | High X of Y | Middle X of Y | Exponential Smooth |
|---|---|---|---|---|
| Error (OPI) | 0.064 | 0.393 | 0.292 | 0.238 |
© 2018 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Song, T.; Li, Y.; Zhang, X.-P.; Li, J.; Wu, C.; Wu, Q.; Wang, B. A Cluster-Based Baseline Load Calculation Approach for Individual Industrial and Commercial Customer. Energies 2019, 12, 64. https://doi.org/10.3390/en12010064
Song T, Li Y, Zhang X-P, Li J, Wu C, Wu Q, Wang B. A Cluster-Based Baseline Load Calculation Approach for Individual Industrial and Commercial Customer. Energies. 2019; 12(1):64. https://doi.org/10.3390/en12010064
Chicago/Turabian StyleSong, Tianli, Yang Li, Xiao-Ping Zhang, Jianing Li, Cong Wu, Qike Wu, and Beibei Wang. 2019. "A Cluster-Based Baseline Load Calculation Approach for Individual Industrial and Commercial Customer" Energies 12, no. 1: 64. https://doi.org/10.3390/en12010064
APA StyleSong, T., Li, Y., Zhang, X. -P., Li, J., Wu, C., Wu, Q., & Wang, B. (2019). A Cluster-Based Baseline Load Calculation Approach for Individual Industrial and Commercial Customer. Energies, 12(1), 64. https://doi.org/10.3390/en12010064