Estimation of the Daily Variability of Aggregate Wind Power Generation in Alberta, Canada



Abstract
:1. Introduction
1.1. Other Modeling Methodologies
1.2. Applications
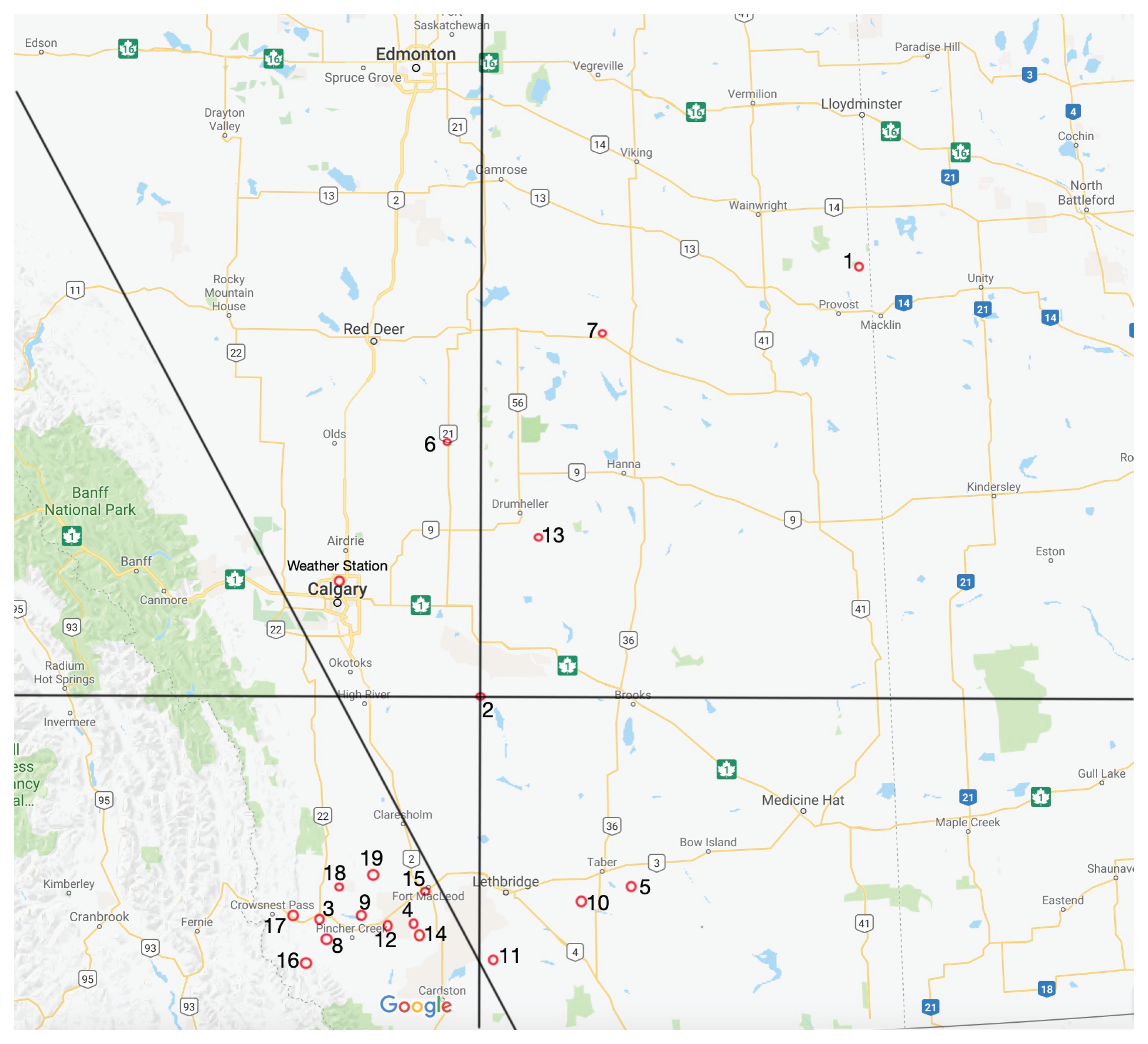
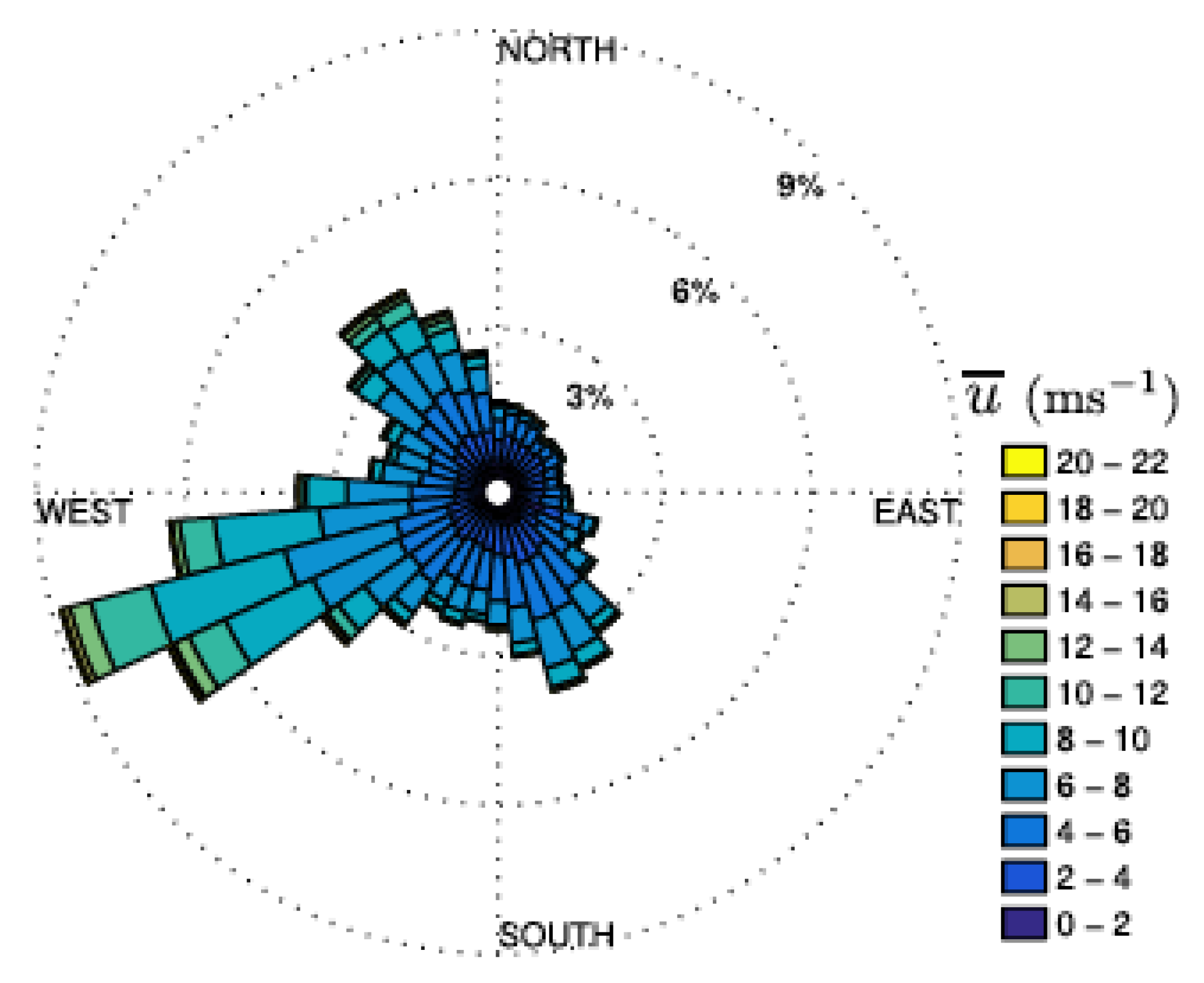
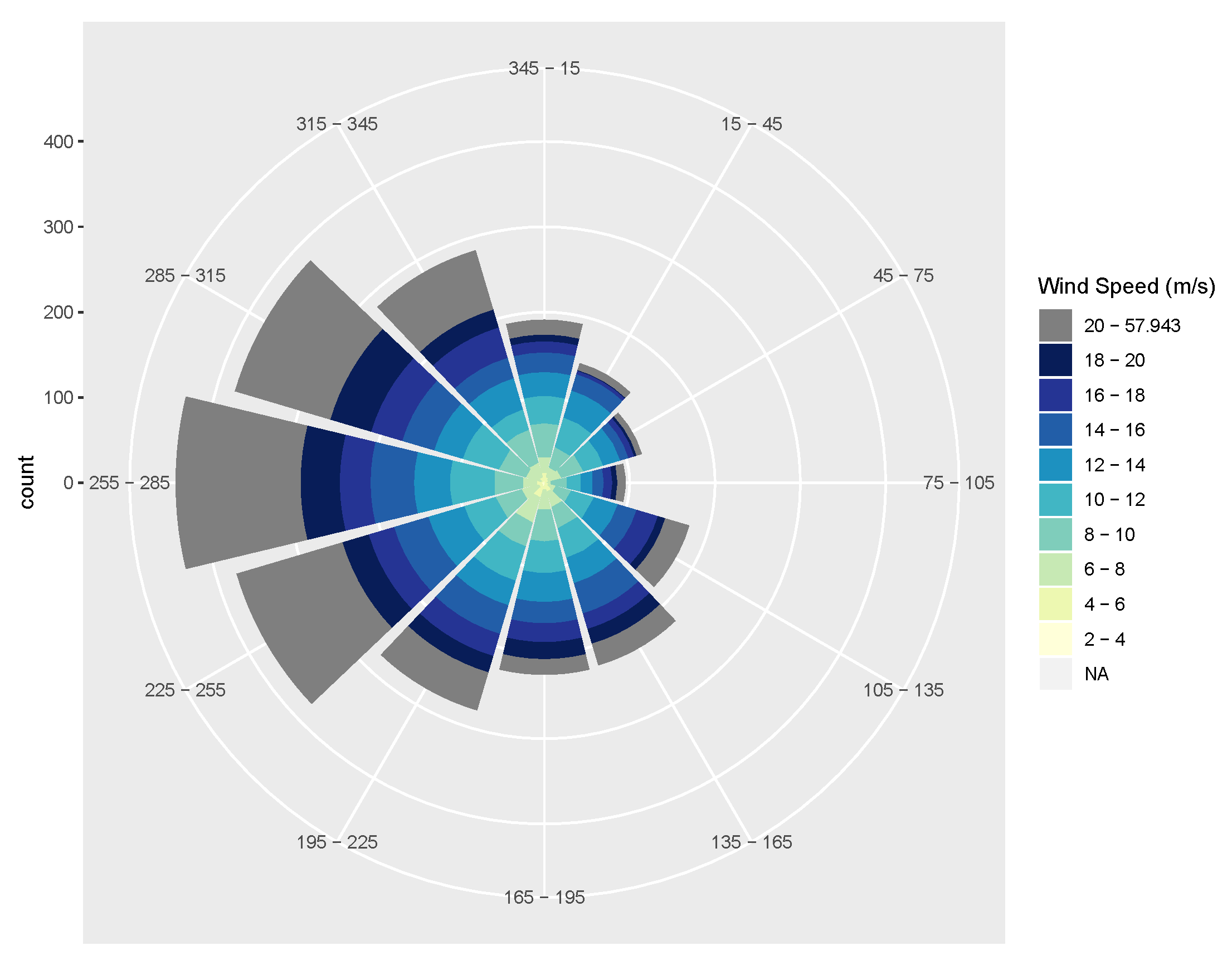
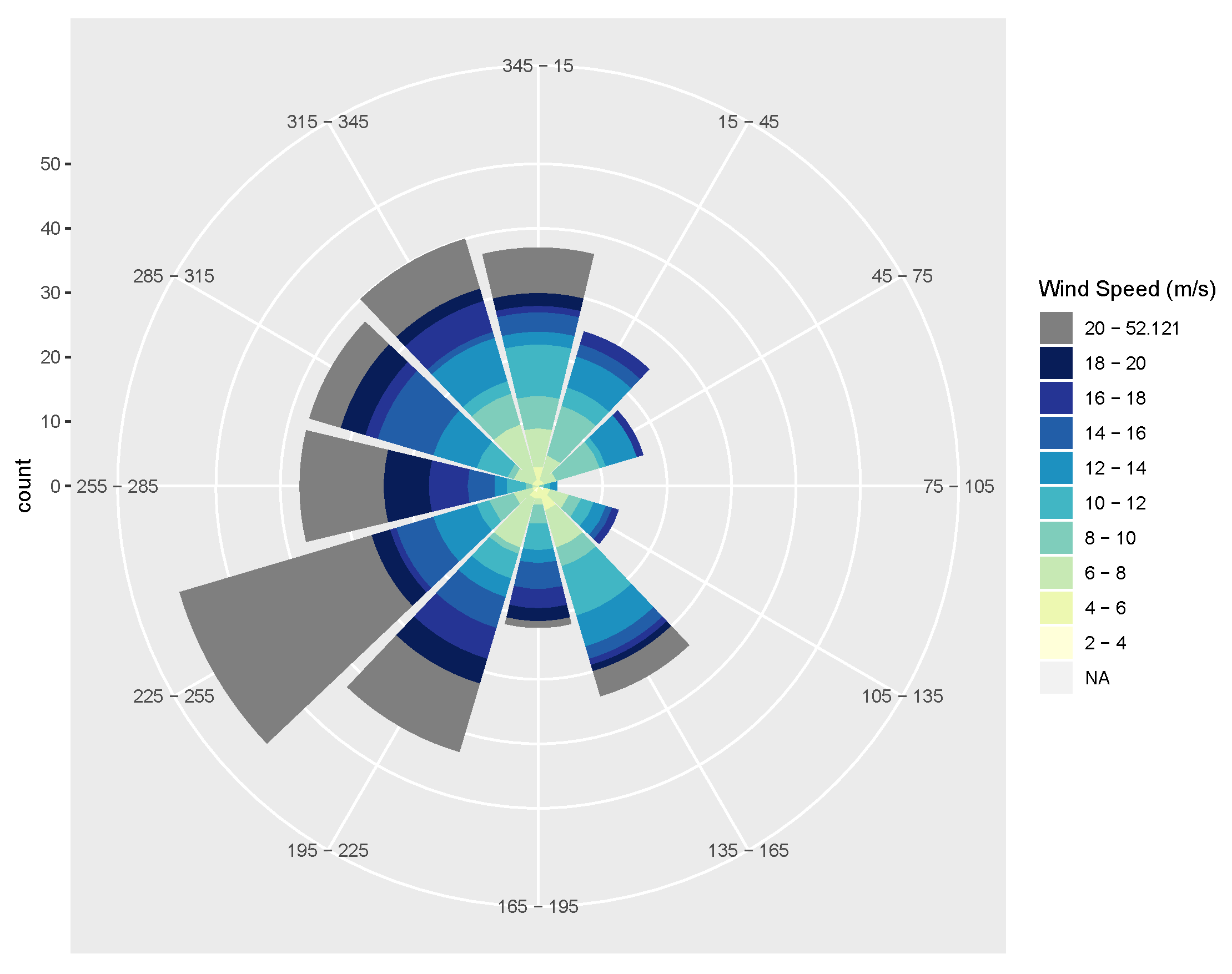
2. Wind Energy Generation Data
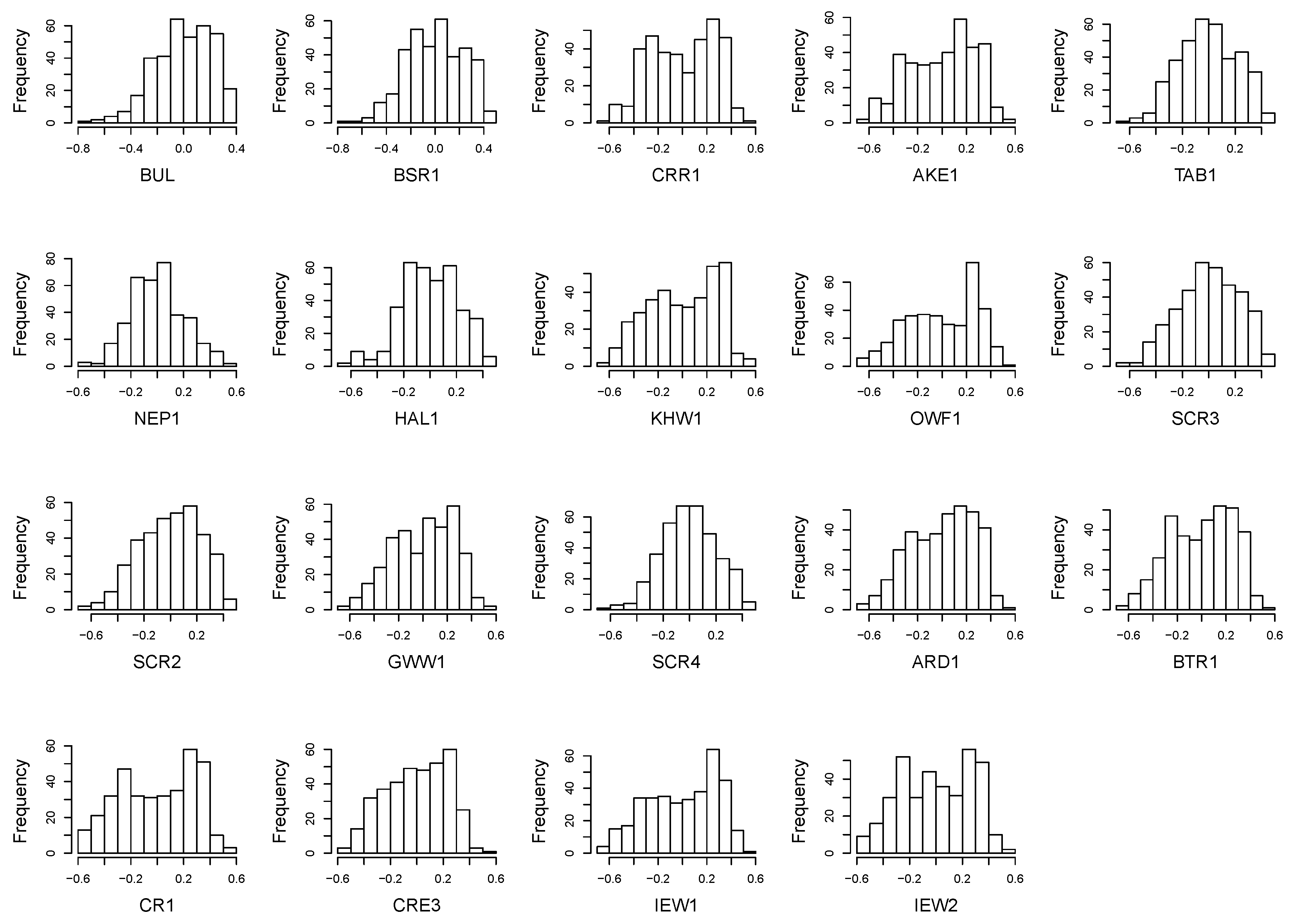
Data Preprocessing
3. Modeling
3.1. Separable Model
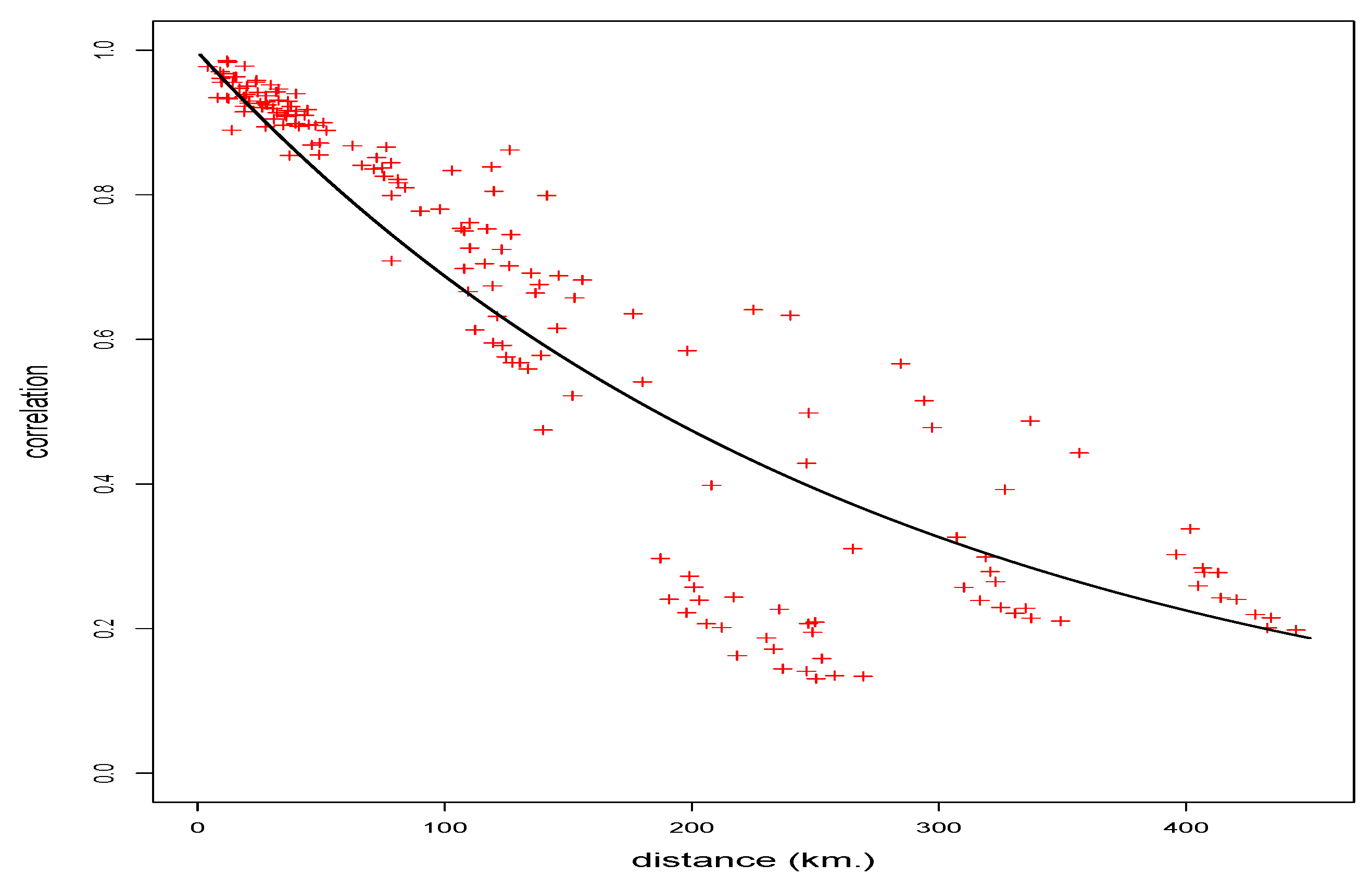
3.1.1. Pure Spatial Correlation Function
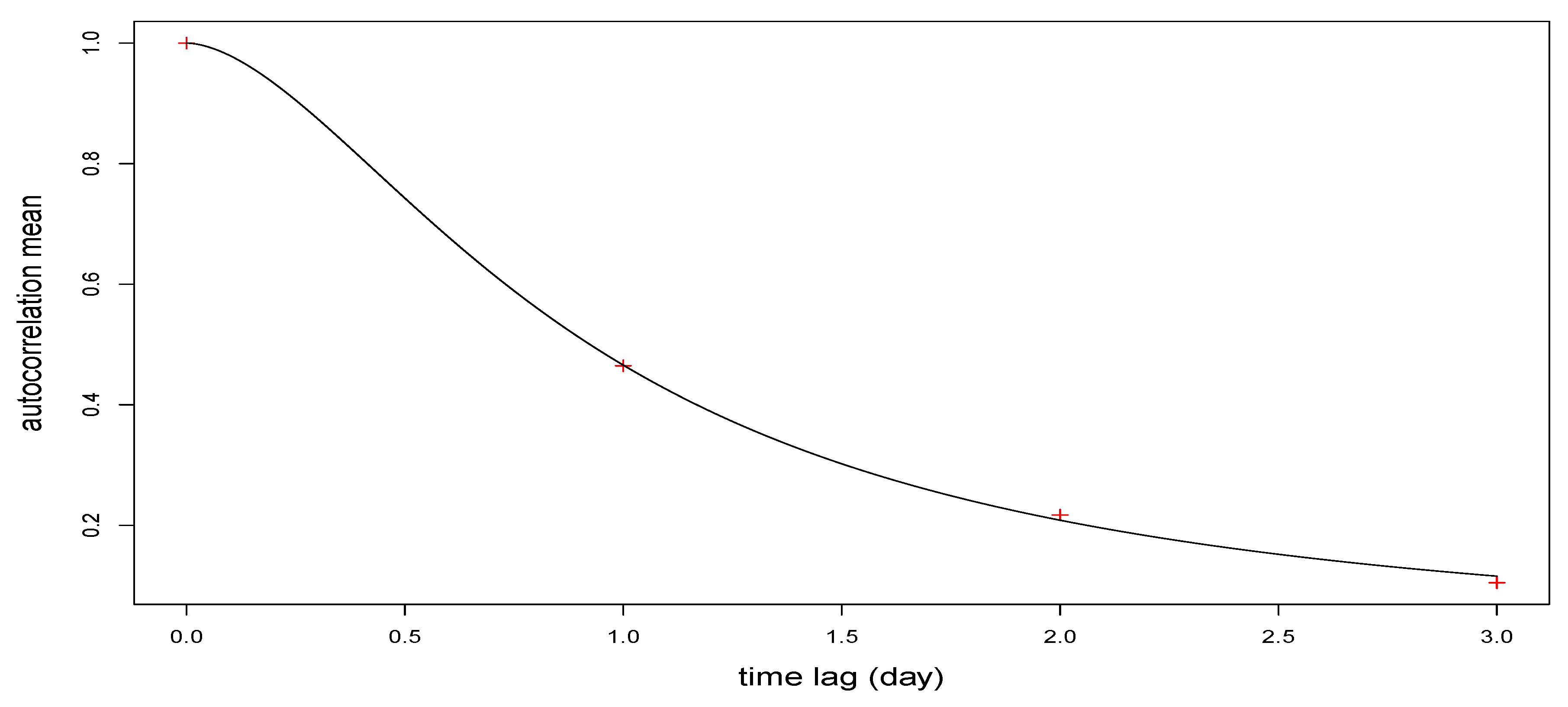
3.1.2. Pure Temporal Correlation Function
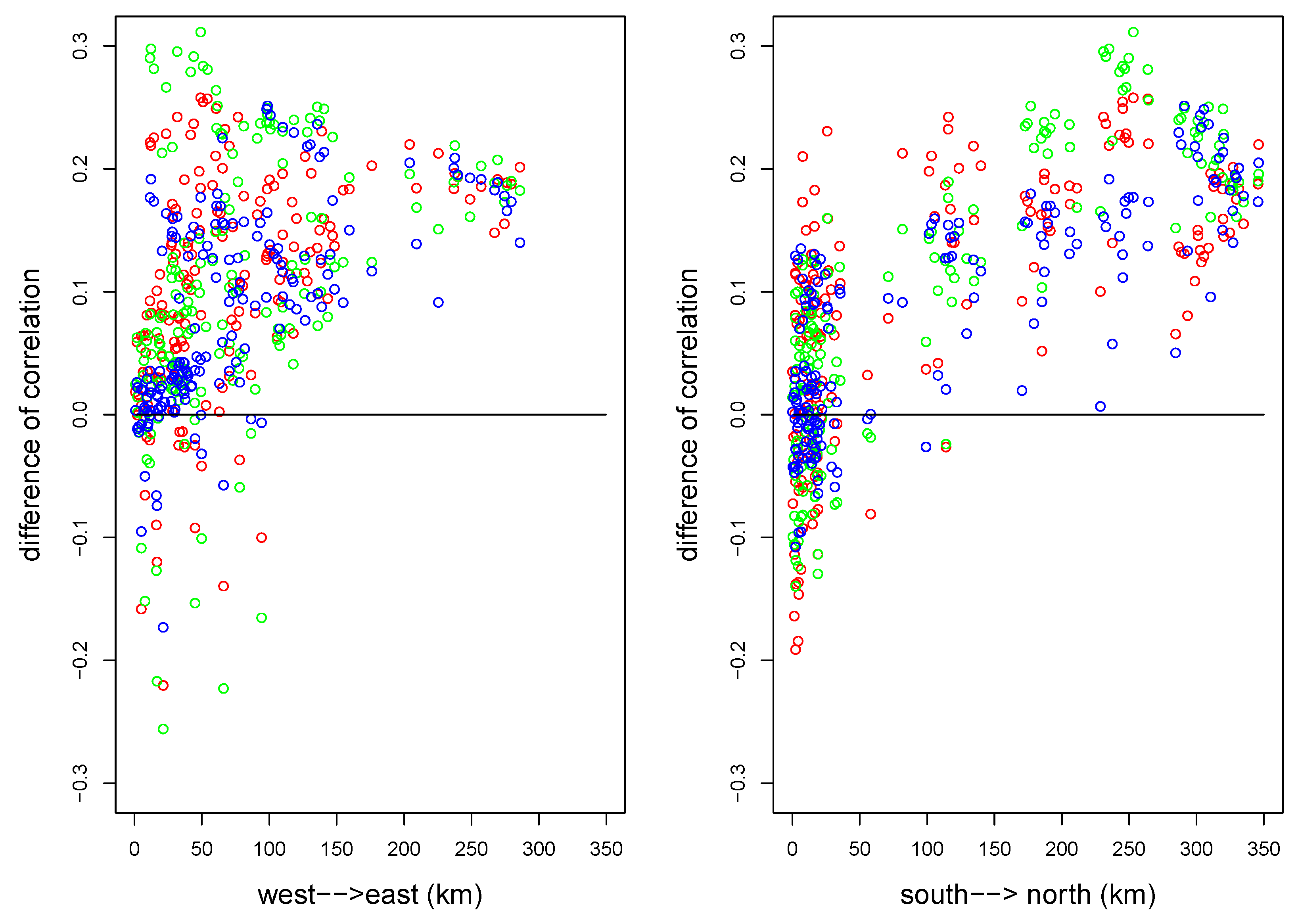
3.2. Fully Symmetric Model
3.3. General Stationary Model
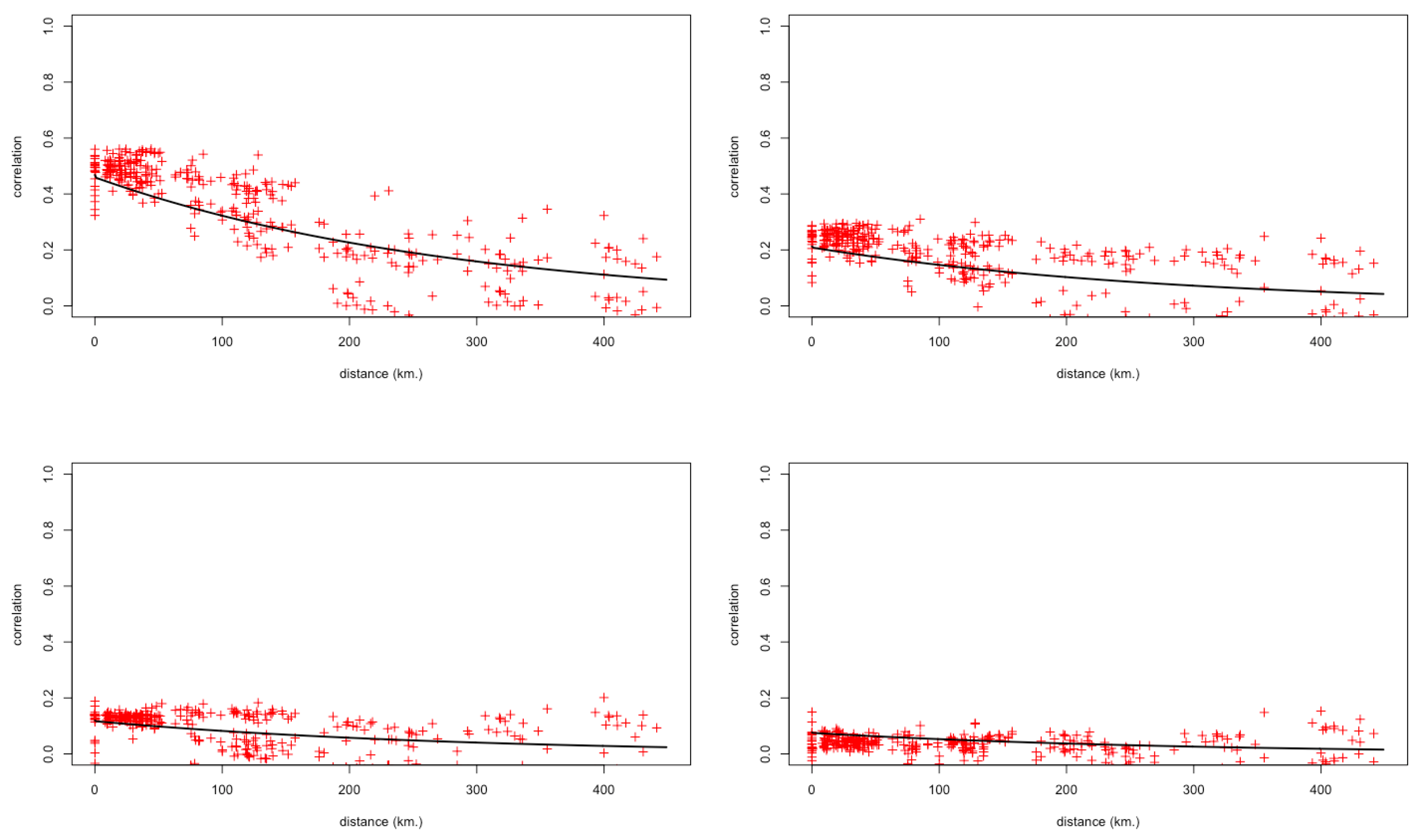
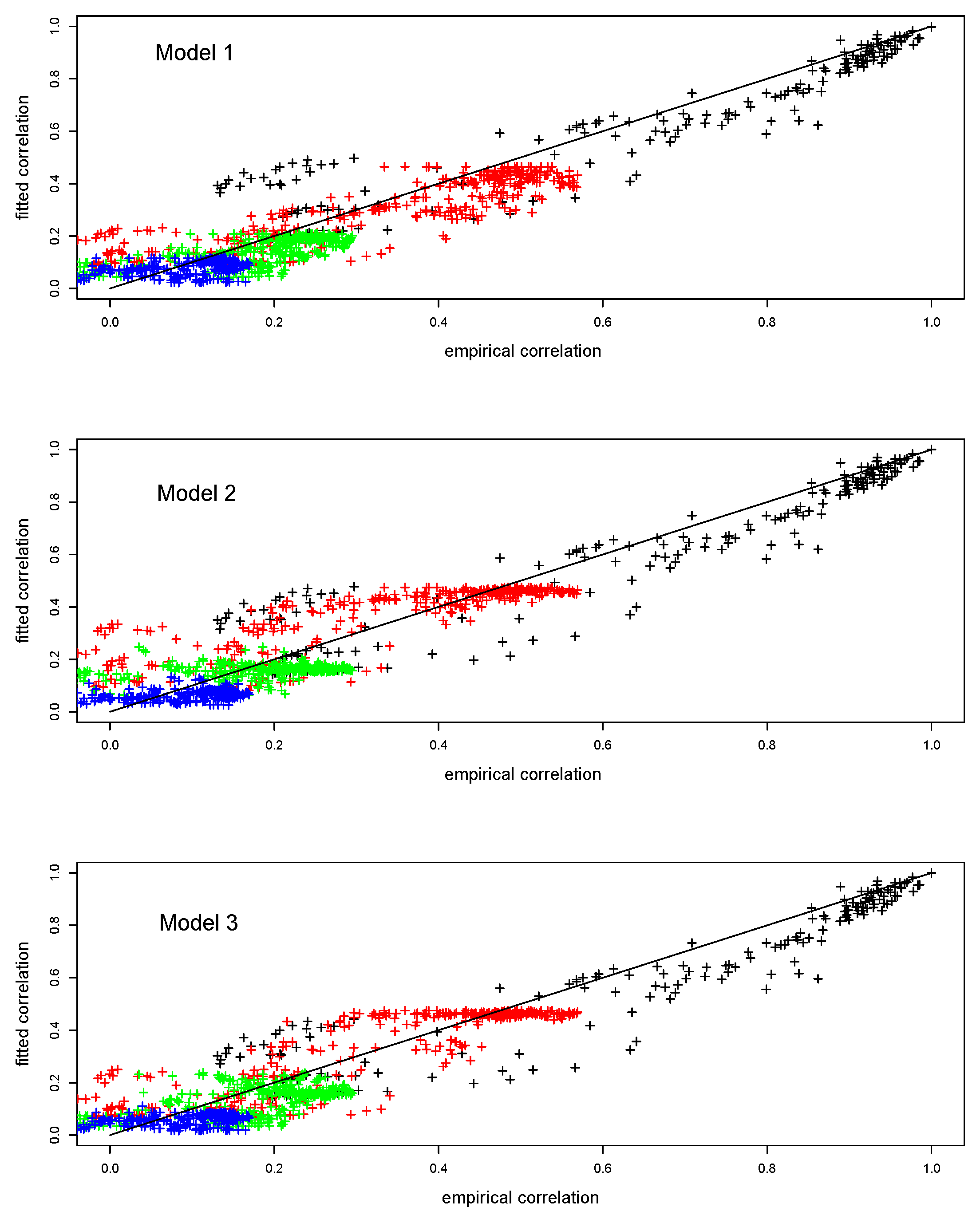
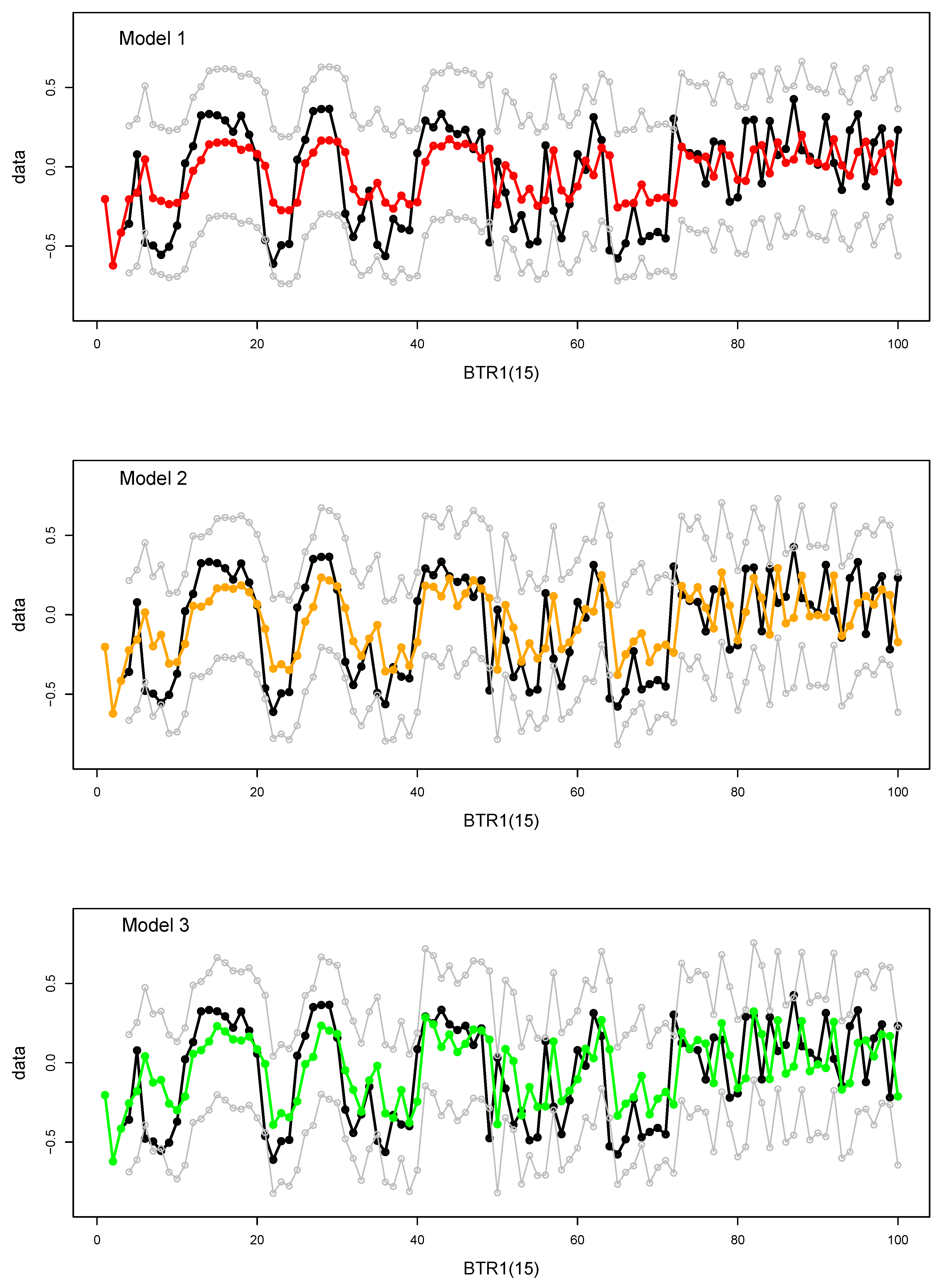
4. Comparison of the Models
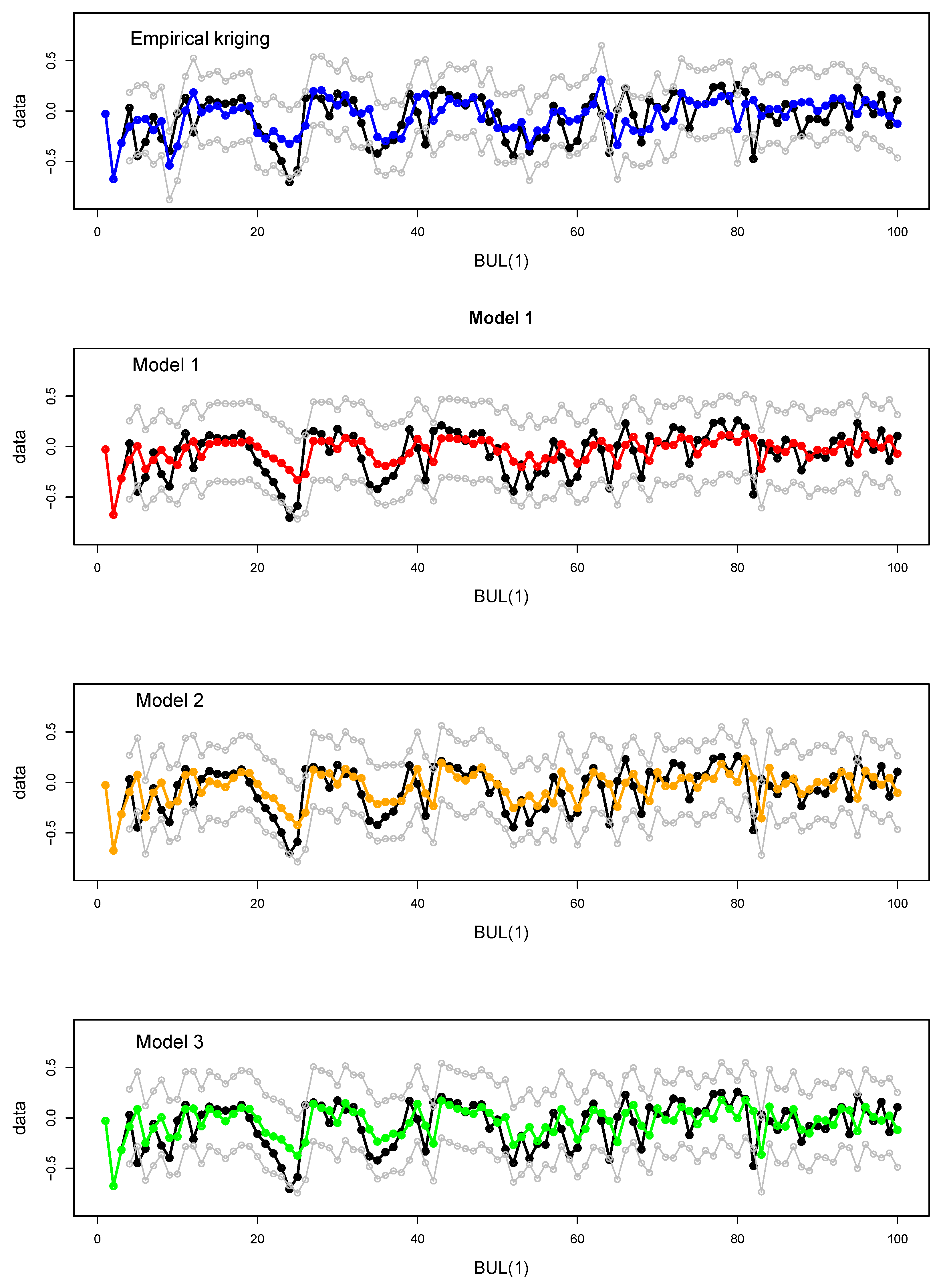
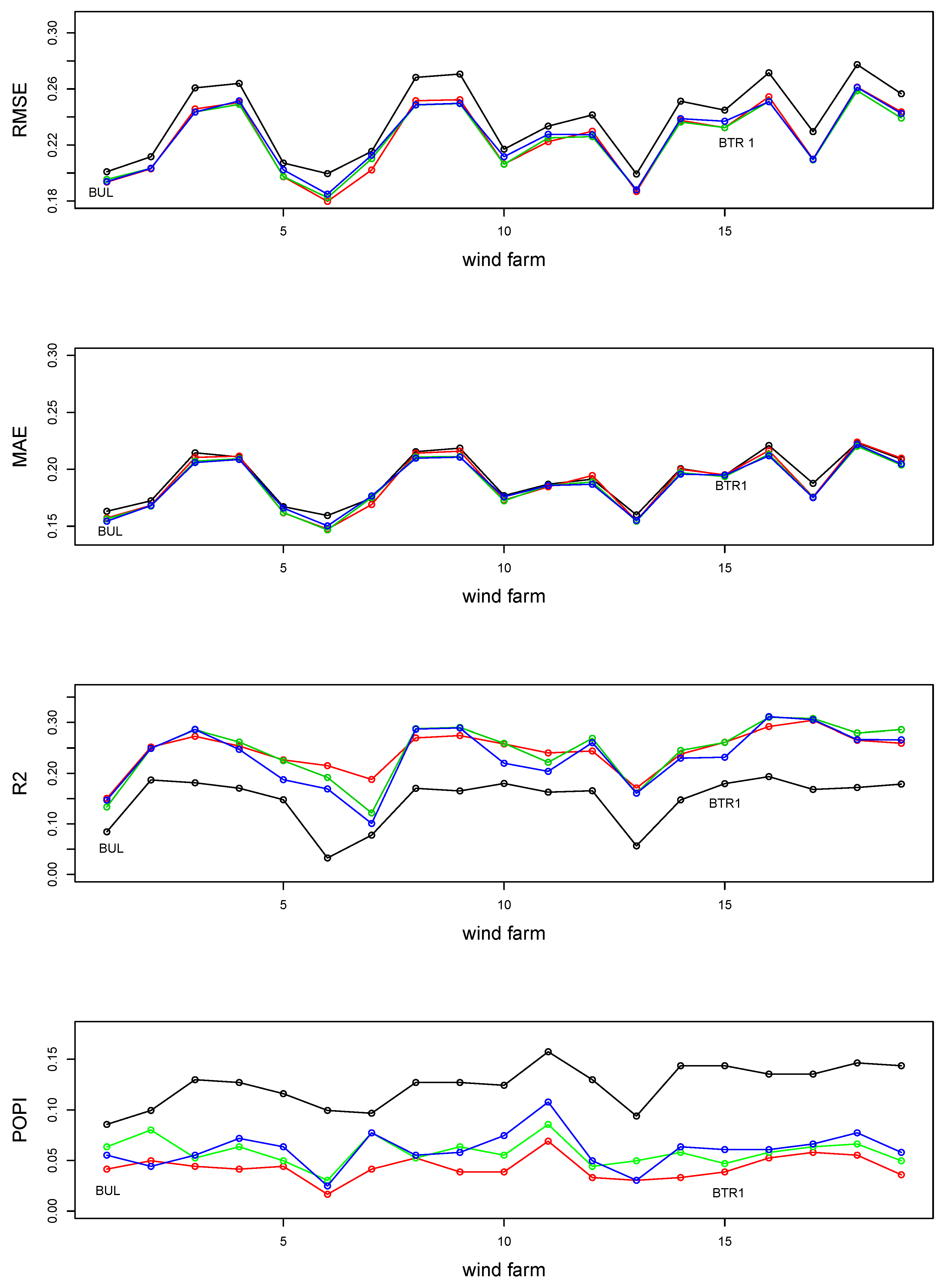
- Model 1with
- Model 2withand km/day and as in Model 1;
- Model 3withand km/day and as in Model 1.
4.1. Goodness of Fit
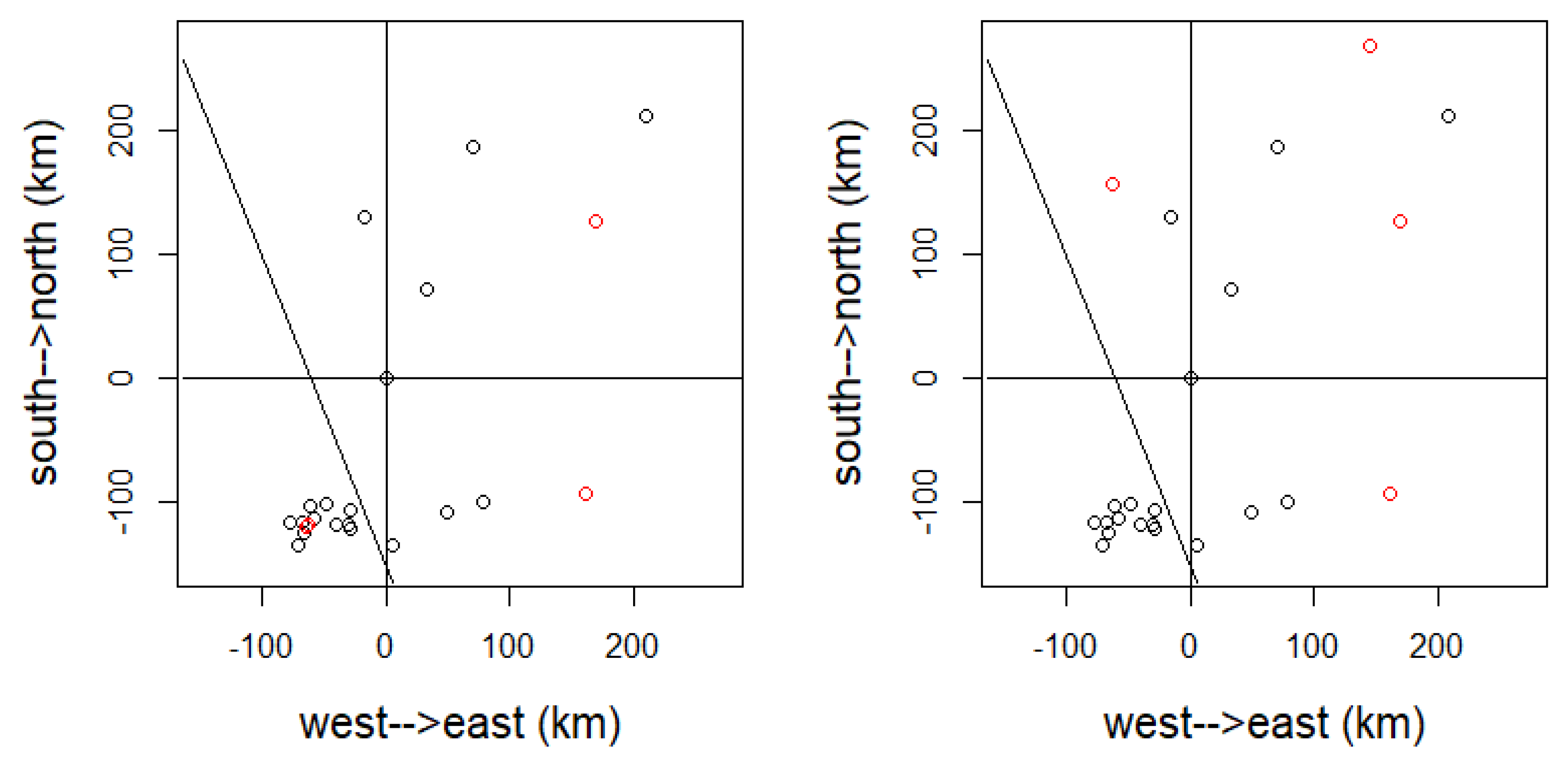
4.2. Kriging Predictions
4.3. Scenario 1: Prediction for an Existing Wind Farm
4.4. Prediction for a New Wind Farm
5. The Aggregate Wind Power Generation and the Effect of New Farms
Variance of the Aggregate Wind Power Generation
6. Conclusions and Future Work
Author Contributions
Funding
Conflicts of Interest
Abbreviations
| AESO | Alberta Electric System Operator |
| Cov(X,Y) | Covariance of the random variables X and Y |
| Cor(X,Y) | Correlation of the random variables X and Y |
| Expectation of the random variable X | |
| LOWESS | Locally Weighted Scatterplot Smoothing |
| MAE | Mean Absolute Error |
| MSE | Mean Square Error |
| k-dimensional normal distribution with mean vector and covariance matrix | |
| PI | Prediction Interval |
| POPI | Percent of Observations out of Prediction Intervals |
| RMSE | Root mean Square Error |
| Coefficient of Determination | |
| Var(X) | Variance of the random variable X |
| WLS | Weighted least Squares |
Appendix A. The Prediction Interval
Appendix B. Mean and Variance of the Aggregate Wind Power
References
- Canadian Wind Energy Association. Wind Energy in Alberta. 2018. Available online: http://xxx.lanl.gov/abs/https://canwea.ca/wind-energy/alberta/ (accessed on 1 January 2019).
- Jurasz, J.; Beluco, A.; Canales, F.A. The impact of complementarity on power supply reliability of small scale hybrid energy systems. Energy 2018, 161, 737–743. [Google Scholar] [CrossRef]
- de Oliveira Costa Souza Rosa, C.; Costa, K.A.; da Silva Christo, E.; Bertahone, P.B. Complementarity of Hydro, Photovoltaic, and Wind Power in Rio de Janeiro State. Sustainability 2017, 9, 1130. [Google Scholar] [CrossRef]
- Pinson, P. Wind Energy: Forecasting Challenges for Its Operational Management. Stat. Sci. 2013, 28, 564–585. [Google Scholar] [CrossRef] [Green Version]
- Gneiting, T.; Genton, M.; Guttorp, P. Geostatistical Space-Time Models, Stationarity, Separability and Full Symmetry; Technical Report; Department of Statistics, University of Washington: Seattle, WA, USA, 2006. [Google Scholar]
- Chen, N.; Qian, Z.; Nabney, I.; Meng, X. Wind Power Forecasts Using Gaussian Processes and Numerical Weather Prediction. IEEE Trans. Power Syst. 2014, 29, 656–665. [Google Scholar] [CrossRef]
- Ma, X.; Sun, Y.; Fang, H. Scenario Generation of Wind Power Based on Statistical Uncertainty and Variability. IEEE Trans. Sustain. Energy 2013, 4, 894–904. [Google Scholar] [CrossRef]
- Yang, M.; Lin, Y.; Zhu, S.; Han, X.; Wang, H. Multi-dimensional scenario forecast for generation of multiple wind farms. J. Mod. Power Syst. Clean Energy 2015, 3, 361–370. [Google Scholar] [CrossRef] [Green Version]
- Li, P.; Guan, X.; Wu, J.; Zhou, X. Modeling Dynamic Spatial Correlations of Geographically Distributed Wind Farms and Constructing Ellipsoidal Uncertainty Sets for Optimization-Based Generation Scheduling. IEEE Trans. Sustain. Energy 2015, 6, 1594–1605. [Google Scholar] [CrossRef]
- Gneiting, T.; Larson, K.; Westrick, K.; Genton, M.G.; Aldrich, E. Calibrated Probabilistic Forecasting at the Stateline Wind Energy Center. J. Am. Stat. Assoc. 2006, 101, 968–979. [Google Scholar] [CrossRef]
- Hering, A.S.; Genton, M.G. Powering up with Space-Time Wind Forecasting. J. Am. Stat. Assoc. 2010, 105, 92–104. [Google Scholar] [CrossRef]
- Cavalcante, L.; Bessa, R.; Reis, M.; Browell, J. LASSO vector autoregression structures for very short-term wind power forecasting. Wind Energy 2017, 20, 657–675. [Google Scholar] [CrossRef]
- Browell, J.; Drew, D.R.; Philippopoulos, K. Improved very short-term spatio-temporal wind forecasting using atmospheric regimes. Wind Energy 2018, 21, 968–979. [Google Scholar] [CrossRef]
- Damousis, I.; Alexiadis, M.C.; Theocharis, J.; Dokopoulos, P. A Fuzzy Model for Wind Speed Prediction and Power Generation in Wind Parks Using Spatial Correlation. IEEE Trans. Energy Convers. 2004, 19, 352–361. [Google Scholar] [CrossRef]
- Morales, J.; Minguez, R.; Conejo, A. A methodology to generate statistically dependent wind speed scenarios. Appl. Energy 2010, 87, 843–855. [Google Scholar] [CrossRef]
- Malvaldi, A.; Weiss, S.; Infield, D.; Browell, J.; Leahy, P.; Foley, A.M. A spatial and temporal correlation analysis of aggregate wind power in an ideally interconnected Europe. Wind Energy 2017, 20, 1315–1329. [Google Scholar] [CrossRef] [Green Version]
- Gneiting, T. Nonseparable, Stationary Covariance Functions for Space-Time Data. J. Am. Stat. Assoc. 2002, 97, 590–600. [Google Scholar] [CrossRef]
- Ezzat, A.; Jun, M.; Ding, Y. Spatio-temporal asymmetry of local wind fields and its impact on short-term wind forecasting. IEEE Trans. Sustain. Energy 2018, 9, 1437–1447. [Google Scholar] [CrossRef] [PubMed]
- Reichenberg, L.; Wojciechowski, A.; Hedenus, F.; Johnsson, F. Geographic aggregation of wind power—An optimization methodology for avoiding low outputs. Wind Energy 2017, 20, 19–32. [Google Scholar] [CrossRef]
- Tejeda, C.; Gallardo, C.; Domínguez, M.; Gaertner, M.; Gutierrez, C.; Castro, M. Using wind velocity estimated from a reanalysis to minimize the variability of aggregated wind farm production over Europe. Wind Energy 2018, 21, 174–183. [Google Scholar] [CrossRef]
- MacCormack, J.; Westwick, D.; Zareipour, H.; Rosehart, W. Stochastic modeling of future wind generation scenarios. In Proceedings of the 2008 40th North American Power Symposium, Calgary, AB, Canada, 28–30 September 2008; pp. 1–7. [Google Scholar] [CrossRef]
- Miettinen, J.; Holttinen, H. Characteristics of day-ahead wind power forecast errors in Nordic countries and benefits of aggregation. Wind Energy 2016, 20, 959–972. [Google Scholar] [CrossRef]
- Baxevani, A.; Lennartsson, J. A spatiotemporal precipitation generator based on a censored latent Gaussian field. Water Resour. Res. 2015, 51, 4338–4358. [Google Scholar] [CrossRef] [Green Version]
- Glasbey, C.; Nevison, I.; Hunter, A. Parameter Estimators for Gaussian Models with Censored Time Series and Spatio-temporal Data. In COMPSTAT98: Proceedings in Computational Statistics; Payne, R., Green, P., Eds.; Physica-Verlag: Heidelberg, Germany, 1998; pp. 323–328. [Google Scholar]
- Allcroft, D.J.; Glasbey, C.A. A latent Gaussian Markov random-field model for spatiotemporal rainfall disaggregation. J. R. Stat. Soc. Ser. C Appl. Stat. 2003, 52, 487–498. [Google Scholar] [CrossRef]
- Cleveland, W.S. Robust Locally Weighted Regression and Smoothing Scatterplots. J. Am. Stat. Assoc. 1979, 74, 829–836. [Google Scholar] [CrossRef]
- Sherry, M.; Rival, D. Meteorological phenomena associated with wind-power ramps downwind of mountainous terrain. J. Renew. Sustain. Energy 2015, 7. [Google Scholar] [CrossRef]
- Alberta Agriculture and Forestry. Current and Historical Alberta Weather Station Data Viewer. Available online: https://agriculture.alberta.ca/acis/alberta-weather-data-viewer.jsp (accessed on 4 January 2019).
- Gaeton, C.; Guyon, X. Spatial Statistics and Modeling; Springer Science+Business Media, LLC: Berlin/Heidelberg, Germany, 2010. [Google Scholar]
- Banerjee, S.; Carlin, B.; Gelfand, A. Hierarchical Modeling and Analysis of Spatial Data; CRC Press: Boca Raton, FL, USA, 2015; Chapter 5; pp. 129–175. [Google Scholar]




















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| BUL | BSR1 | CRR1 | AKE1 | TAB1 | NEP1 | HAL1 | KHW1 | OWF1 | SCR3 |
| 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 |
| 29 | 300 | 77 | 73 | 81 | 82 | 150 | 63 | 46 | 30 |
| 0.046 | 0.055 | 0.072 | 0.074 | 0.048 | 0.041 | 0.048 | 0.079 | 0.084 | 0.053 |
| SCR2 | GWW1 | SCR4 | ARD1 | BTR1 | CR1 | CRE3 | IEW1 | IEW2 | |
| 11 | 12 | 13 | 14 | 15 | 16 | 17 | 18 | 19 | |
| 30 | 71 | 88 | 68 | 66 | 39 | 20 | 66 | 66 | |
| 0.053 | 0.064 | 0.042 | 0.067 | 0.066 | 0.08 | 0.055 | 0.082 | 0.072 |
| Model | ||||
|---|---|---|---|---|
| Empirical | 0.2379 | 0.1920 | 0.1484 | 0.1234 |
| Model 1 | 0.2242 | 0.1886 | 0.2440 | 0.0429 |
| Model 2 | 0.2238 | 0.1869 | 0.2446 | 0.0584 |
| Model 3 | 0.2255 | 0.1873 | 0.2326 | 0.0608 |
| Model | ||||
|---|---|---|---|---|
| Model 1 | 0.2245 | 0.1892 | 0.2432 | 0.0366 |
| Model 2 | 0.2246 | 0.1878 | 0.2397 | 0.0538 |
| Model 3 | 0.2260 | 0.1880 | 0.2306 | 0.0621 |
| Sites | Capacity (MW) | Coordinates |
|---|---|---|
| Sharp Hills, Oyen | 248.4 | |
| Riverview, Pincher Creek | 115 | |
| CRR2 Pincher Creek | 30.6 | |
| Whitla Wind, Medicine Hat | 201.6 |
| Farms | Total Capacity (MW) | Mean Production (MW) | Standard Deviation (MW) |
|---|---|---|---|
| Current (Farms 1–19) | 1445 | 737.23 | 381.34 |
| Future (Farms 1–23) | 2040.6 | 1037.93 | 502.34 |
© 2019 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Luo, Y.; Sezer, D.; Wood, D.; Wu, M.; Zareipour, H. Estimation of the Daily Variability of Aggregate Wind Power Generation in Alberta, Canada. Energies 2019, 12, 1998. https://doi.org/10.3390/en12101998
Luo Y, Sezer D, Wood D, Wu M, Zareipour H. Estimation of the Daily Variability of Aggregate Wind Power Generation in Alberta, Canada. Energies. 2019; 12(10):1998. https://doi.org/10.3390/en12101998
Chicago/Turabian StyleLuo, Yilan, Deniz Sezer, David Wood, Mingkuan Wu, and Hamid Zareipour. 2019. "Estimation of the Daily Variability of Aggregate Wind Power Generation in Alberta, Canada" Energies 12, no. 10: 1998. https://doi.org/10.3390/en12101998
APA StyleLuo, Y., Sezer, D., Wood, D., Wu, M., & Zareipour, H. (2019). Estimation of the Daily Variability of Aggregate Wind Power Generation in Alberta, Canada. Energies, 12(10), 1998. https://doi.org/10.3390/en12101998