Fuzzy-Enhanced Modeling of Lignocellulosic Biomass Enzymatic Saccharification


Abstract
:1. Introduction
2. Materials and Methods
2.1. Enzyme and Substrates
2.2. Hydrolysis Assays
2.3. Carbohydrates Determination
2.4. Mathematical Modeling
2.4.1. Process Modeling
- Reaction 1: Cellulose → γCl-Cb Cellobiose
- Reaction 2: Cellulose → γCl-Gl Glucose
- Reaction 3: Cellobiose → γCb-Gl Glucose
- Reaction 4: Hemicellulose → γHe-Xy Xylose
- Reaction 5: Lignin → Lignin
- Reaction 6: Enzyme → Inactive Enzyme
2.4.2. Standalone Reaction Rate Models
2.4.3. Fuzzy Kinetic Model
2.4.4. Fitting Algorithm and Statistics
3. Results and Discussion
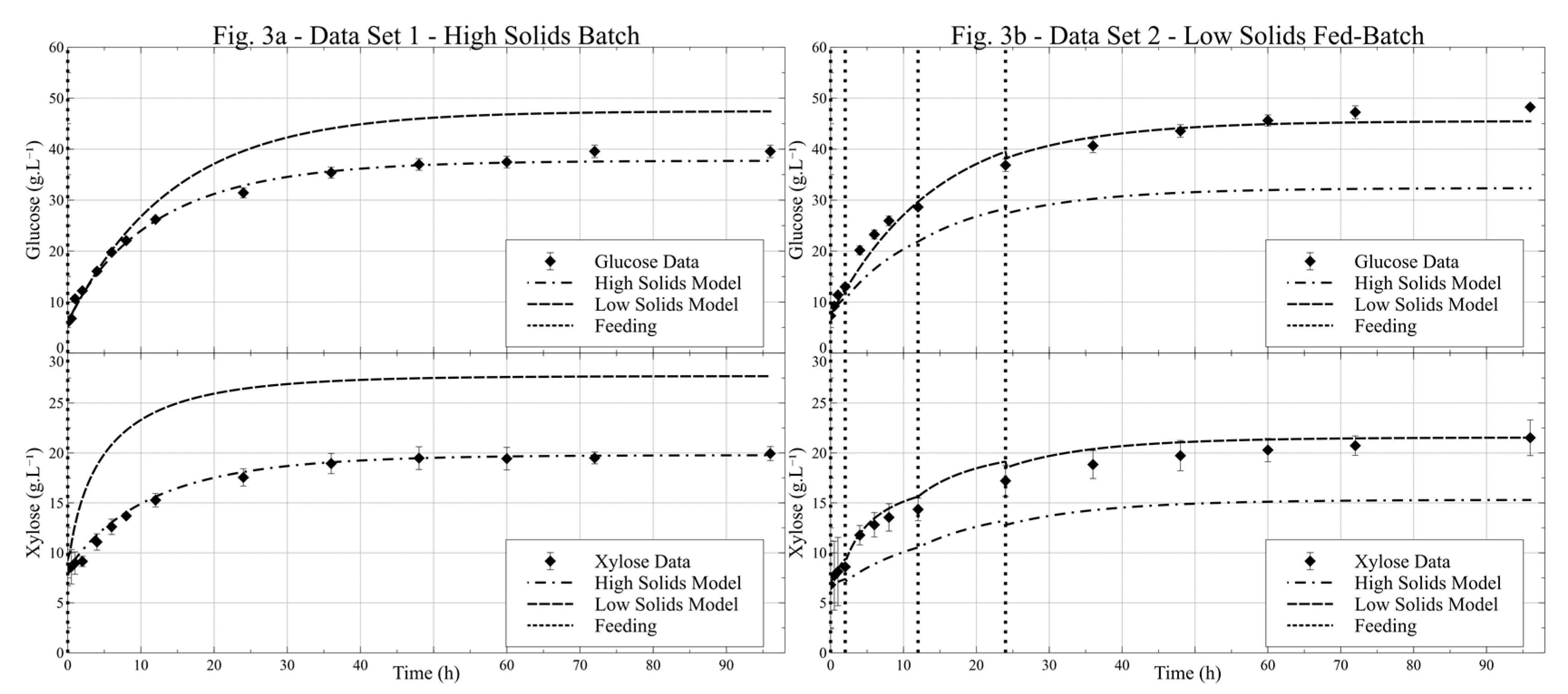
3.1. Standalone Models Fitting
3.2. Fuzzy Kinetic Model Fitting
4. Conclusions
Supplementary Materials
Author Contributions
Funding
Conflicts of Interest
Nomenclature
| Variables | |
| Cl0 | Initial cellulose concentration (g·kg−1) |
| Cov(θ) | Parameters Covariance Matrix |
| Emi | Maximum adsorbed enzyme constant (gProtein/gSubstrate) |
| F | Objective Function Optimum Value |
| HMSFLb | High Model Membership Function Lower Bound |
| HMSFUb | High Model Membership Function Upper Bound |
| ki | Kinetic constants (min−1) |
| Kadi | Dissociation constants for enzyme (gProtein/gSubstrate) |
| kei | First order inactivation constant (min−1) |
| KiCb | Cellobiose Inhibition constant (g·kg−1) |
| KiGl | Glucose Inhibition constant (g·kg−1) |
| KiXl | Xylose Inhibition constant (g·kg−1) |
| Kmi | Michaelis-Menten constant (g·L−1) |
| Kpi | Products competitive inhibition constant (g·L−1) |
| m | Number of Parameters |
| MDHSM | Membership Degree of the High Solids Model |
| MDLSM | Membership Degree of the Low Solids Model |
| n | Number of Data Points |
| Q | Cost Function Weights Matrix |
| Rs | Substrate reactivity parameter |
| X | Regressors Matrix |
| [Cb] | Cellobiose Concentration (g·L−1) |
| [Cl] | Cellulose Concentration (g·L−1) |
| [Ef] | Free enzyme concentration (g·kg−1) |
| [En] | Enzyme Concentration (g·L−1) |
| [Et] | Total Enzyme concentration (g·kg−1) |
| [Gl] | Glucose Concentration (g·L−1) |
| [He] | Hemicellulose Concentration (g·L−1) |
| [Lg] | Lignin Concentration (g·L−1) |
| [Pi] | Product concentration (g·L−1) |
| [Si] | Substrate Concentration (g·L−1) |
| [Xy] | Xylose Concentration (g·L−1) |
| Greek Letters | |
| αFUZZY | Fuzzy Model reaction rate (g·L−1.·min−1) |
| αHSM | High Solids Model reaction rate (g·L−1.·min−1) |
| αi | Reaction rate for “i” reaction, where “i” are reactions 1 through 6 (g·L−1.·min−1) |
| αLSM | Low Solids Model reaction rate (g·L−1.·min−1) |
| αr | Reactivity Constant |
| γCl-Cb | Pseudo-stoichiometric mass relation between cellulose and cellobiose (gCellobiose.gCellulose−1) |
| γCl-Gl | Pseudo-stoichiometric mass relation between cellulose and glucose (gGlucose.gCellulose−1) |
| γCb-Gl | Pseudo-stoichiometric mass relation between cellobiose and glucose (gGlucose.gCellobiose−1) |
| γHe-Xy | Pseudo-stoichiometric mass relation between Hemicellulose and Xylose gXylose.gHemicellulose−1 |
| Abbreviations | |
| FM | Fuzzy Model |
| FRR | Fuzzy Reaction Rate |
| HSB | High Solids Batch |
| HSM | High Solids Model |
| LK | Langmuir Kinetics |
| LSF | Low Solids Fed-batch |
| LSM | Low Solids Model |
| MD | Membership Degree |
| MSE | Mean Squared Error |
| MMK | Michaelis-Menten kinetics |
| MPF | Mixed Profile Fed-batch |
References
- Rastogi, M.; Shrivastava, S. Recent advances in second generation bioethanol production: An insight to pretreatment, saccharification and fermentation processes. Renew. Sustain. Energy Rev. 2017, 80, 330–340. [Google Scholar] [CrossRef]
- Łukajtis, R.; Rybarczyk, P.; Kucharska, K.; Konopacka-Łyskawa, D.; Słupek, E.; Wychodnik, K.; Kamiński, M. Optimization of saccharification conditions of lignocellulosic biomass under alkaline pre-treatment and enzymatic hydrolysis. Energies 2018, 11, 886. [Google Scholar] [CrossRef]
- Dantas, G.A.; Legey, L.F.L.; Mazzone, A. Energy from sugarcane bagasse in Brazil: An assessment of the productivity and cost of different technological routes. Renew. Sustain. Energy Rev. 2013, 21, 356–364. [Google Scholar] [CrossRef]
- Liguori, R.; Soccol, C.R.; de Souza Vandenberghe, L.P.; Woiciechowski, A.L.; Faraco, V. Second generation ethanol production from brewers’ spent grain. Energies 2015, 8, 2575–2586. [Google Scholar] [CrossRef]
- Balat, M.; Balat, H.; Öz, C. Progress in bioethanol processing. Prog. Energy Combust. Sci. 2008, 34, 551–573. [Google Scholar] [CrossRef]
- Gandla, M.L.; Martín, C.; Jönsson, L.J. Analytical Enzymatic Saccharification of Lignocellulosic Biomass for Conversion to Biofuels and Bio-Based Chemicals. Energies 2018, 11, 2936. [Google Scholar] [CrossRef]
- Hodge, D.B.; Karim, M.N.; Schell, D.J.; Mcmillan, J.D. Soluble and insoluble solids contributions to high-solids enzymatic hydrolysis of lignocellulose. Bioresour. Technol. 2008, 99, 8940–8948. [Google Scholar] [CrossRef] [PubMed]
- Hodge, D.B.; Karim, M.N.; Schell, D.J.; Mcmillan, J.D. Model-Based Fed-Batch for High-Solids Enzymatic Cellulose Hydrolysis. Appl. Biochem. Biotechnol. 2009, 152, 88–107. [Google Scholar] [CrossRef]
- Malgas, S.; Thoresen, M.; Van Dyk, J.S.; Pletschke, B.I. Enzyme and Microbial Technology Time dependence of enzyme synergism during the degradation of model and natural lignocellulosic substrates. Enzyme Microb. Technol. 2017, 103, 1–11. [Google Scholar] [CrossRef] [PubMed]
- Yao, M.; Wang, Z.; Wu, Z.; Qi, H. Evaluating Kinetics of Enzymatic Saccharification of Lignocellulose by Fractal Kinetic Analysis. Biotechnol. Bioprocess Eng. 2011, 16, 1240–1247. [Google Scholar] [CrossRef]
- Berlin, A.; Gilkes, N.; Kurabi, A.; Bura, R.; Tu, M.; Kilburn, D.; Saddler, J. Weak Lignin-Binding Enzymes. Appl. Biochem. Biotechnol. 2005, 121–124, 163–170. [Google Scholar] [CrossRef]
- Bansal, P.; Hall, M.; Realff, M.J.; Lee, J.H.; Bommarius, A.S. Modeling cellulase kinetics on lignocellulosic substrates. Biotechnol. Adv. 2009, 27, 833–848. [Google Scholar] [CrossRef]
- Suarez, C.A.G.; Cavalcanti-montaño, I.D.; da Costa Marques, R.G.; Furlan, F.F.; e Aquino, P.L.M.; de Campos Giordano, R.; Souza, R., Jr. Modeling the Kinetics of Complex Systems: Enzymatic Hydrolysis of Lignocellulosic Substrates. Appl. Biochem. Biotechnol. 2014, 173, 1083–1096. [Google Scholar] [CrossRef] [PubMed]
- Carvalho, M.L.; Souza, R., Jr.; Suarez, C.A.G. Kinetic study of the enzymatic hydrolysis of sugarcane bagasse. Braz. J. Chem. Eng. 2013, 30, 437–447. [Google Scholar] [CrossRef] [Green Version]
- Souza, R., Jr.; Carvalho, M.L.; Giordano, R.L.C.; Giordano, R.C. Recent trends in the modeling of cellulose hydrolysis. Braz. J. Chem. Eng. 2011, 28, 545–564. [Google Scholar] [Green Version]
- Bezerra, R.M.F.; Dias, A.A. Discrimination among eight modified Michaelis-Menten kinetics models of cellulose hydrolysis with a large range of substrate/enzyme ratios: Inhibition by cellobiose. Appl. Biochem. Biotechnol. 2004, 112, 173–184. [Google Scholar] [CrossRef]
- Ghose, K.T.; Bisaria, V.S. Studies on the mechanism of enzymatic hydrolysis of cellulosic substances. Biotechnol. Bioeng. 1979, 21, 131–146. [Google Scholar] [CrossRef] [PubMed]
- Kadam, K.L.; Rydholm, E.C.; Mcmillan, J.D. Development and Validation of a Kinetic Model for Enzymatic Saccharification of Lignocellulosic Biomass. Biotechnol. Prog. 2004, 20, 698–705. [Google Scholar] [CrossRef] [PubMed]
- Karimi, K.; Taherzadeh, M.J. A critical review of analytical methods in pretreatment of lignocelluloses: Composition, imaging, and crystallinity. Bioresour. Technol. 2016, 203, 348–356. [Google Scholar] [CrossRef]
- Samaniuk, J.R.; Scott, C.T.; Root, T.W.; Klingenberg, D.J. The effect of high intensity mixing on the enzymatic hydrolysis of concentrated cellulose fiber suspensions. Bioresour. Technol. 2011, 102, 4489–4494. [Google Scholar] [CrossRef]
- Liu, K.; Zhang, J.; Bao, J. Two stage hydrolysis of corn stover at high solids content for mixing power saving and scale-up applications. Bioresour. Technol. 2015, 196, 716–720. [Google Scholar] [CrossRef] [PubMed]
- Al-hadithi, B.M.; Jiménez, A.; Matía, F. A new approach to fuzzy estimation of Takagi—Sugeno model and its applications to optimal control for nonlinear systems. Appl. Soft Comput. J. 2012, 12, 280–290. [Google Scholar] [CrossRef]
- Gouveia, E.R.; Nascimento, R.T.; Souto-Maior, A.M.; Rocha, G.J.M. Validacao De Metodologia Para a Caracterizacao De Bagaco De Cana De Acucar. Quim. Nova 2009, 32, 1500–1503. [Google Scholar] [CrossRef]
- Sluiter, A.; Hames, B.; Ruiz, R.; Scarlata, C.; Sluiter, J.; Templeton, D.; Crocker, D. Determination of Sugars, Byproducts, and Degradation Products in Liquid Fraction Process Samples; Technical Report NREL/TP-510-42623; National Renewable Energy Laboratory: Golden, CO, USA, 2008.
- Yao, S.; Nie, S.; Yuan, Y.; Wang, S.; Qin, C. Efficient extraction of bagasse hemicelluloses and characterization of solid remainder. Bioresour. Technol. 2015, 185, 21–27. [Google Scholar] [CrossRef]
- Ye, Z.; Berson, R.E. Kinetic modeling of cellulose hydrolysis with first order inactivation of adsorbed cellulase. Bioresour. Technol. 2011, 102, 11194–11199. [Google Scholar] [CrossRef] [PubMed]
- Kellock, M.; Rahikainen, J.; Marjamaa, K.; Kruus, K. Lignin-derived inhibition of monocomponent cellulases and a xylanase in the hydrolysis of lignocellulosics. Bioresour. Technol. 2017, 232, 183–191. [Google Scholar] [CrossRef]
- Qi, B.; Chen, X.; Su, Y.; Wan, Y. Enzyme adsorption and recycling during hydrolysis of wheat straw lignocellulose. Bioresour. Technol. 2011, 102, 2881–2889. [Google Scholar] [CrossRef] [PubMed]
- Rahikainen, J.L.; Martin-Sampedro, R.; Heikkinen, H.; Rovio, S.; Marjamaa, K.; Tamminen, T.; Rojas, O.J.; Kruus, K. Inhibitory effect of lignin during cellulose bioconversion: The effect of lignin chemistry on non-productive enzyme adsorption. Bioresour. Technol. 2013, 133, 270–278. [Google Scholar] [CrossRef]
- Bastin, G.; Dochain, D. On-line Estimation and Adaptive Control of Bioreactors, 1st ed.; Elsevier: Amsterdam, The Neatherlands, 1990; pp. 1–381. [Google Scholar]
- Angarita, J.D.; Souza, R.B.A.; Cruz, A.J.G.; Biscaia, E.C., Jr.; Secchi, A.R. Kinetic modeling for enzymatic hydrolysis of pretreated sugarcane straw. Biochem. Eng. J. 2015, 104, 10–19. [Google Scholar] [CrossRef]
- Takagi, T.; Sugeno, M. Fuzzy identification of systems and its applications to modeling and control. IEEE Trans. Syst. Man. Cybern. 1985, SMC-15, 116–132. [Google Scholar] [CrossRef]
- Nelles, O. Fuzzy and Neuro-Fuzzy Models. In Nonlinear System Identification, 1st ed.; Springer-Verlag: Berlin, Germany, 2001; pp. 1–785. [Google Scholar]
- Himmelblau, D.M. Nonlinear Models. In Process Analysis by Statistical Methods, 1st ed.; John Wiley and Sons Ltd.: New York, NY, USA, 1970; pp. 1–496. [Google Scholar]
- Battista, F.; Bolzonella, D. Some Critical Aspects of the Enzymatic Hydrolysis at High Dry-matter Content: A Review. Biofuel. Bioprod. Biorefin. 2018, 12, 711–723. [Google Scholar] [CrossRef]







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Fitting Data Sets | Validation Data Sets | |||||||
|---|---|---|---|---|---|---|---|---|
| Data Set 1—High Solids Batch | Data Set 2—Low Solids Fed-Batch | Data Set 3—Mixed Profile Fed-Batch | ||||||
| Feeding Time (h) | Solids Feeding (g) | Enzyme Feeding (gProtein) | Feeding Time (h) | Solids Feeding (g) | Enzyme Feeding (gProtein) | Feeding Time (h) | Solids Feeding (g) | Enzyme Feeding (g) |
| 0.0 | 600.0 | 2.22 | 0.0 | 150.0 | 2.22 | 0.0 | 150.0 | 2.22 |
| - | - | - | 2.0 | 150.0 | - | 0.5 | 150.0 | - |
| - | - | - | 12.0 | 150.0 | - | 1.0 | 150.0 | - |
| - | - | - | 24.0 | 150.0 | - | 2.0 | 150.0 | - |
| Reaction | Solids Model | Parameters | |||
|---|---|---|---|---|---|
| k (min−1) | Km (g·L−1) | Kp (g·L−1) | ke (min−1) | ||
| 1 | High | (3.03 ± 0.00) × 10−3 | (5.31 ± 0.01) × 10−2 | (7.65± 0.01) × 10−4 | - |
| Low | (2.67 ± 0.38) × 10−3 | (9.75 ± 0.25) × 10−3 | (1.11 ± 0.03) × 10−3 | - | |
| 3 | High | (9.13 ± 0.00) × 10−2 | (3.82 ± 0.01) × 10−4 | (1.83 ± 0.00) × 10−1 | - |
| Low | (6.41 ± 0.07) × 10−4 | (4.49 ± 0.10) × 10−6 | (2.50 ± 0.00) × 10−1 | - | |
| 4 | High | (1.28 ± 0.00) × 10−3 | (2.02 ± 0.00) × 10−2 | (3.46 ± 0.00) × 10−1 | - |
| Low | (1.13 ± 0.02) × 10−1 | (7.80 ± 0.15) × 10−4 | (3.73 ± 0.35) × 10−3 | - | |
| 6 | High | - | - | - | (1.16 ± 0.00) × 10−3 |
| Low | - | - | - | (1.15 ± 0.35) × 10−3 | |
| Model | High Solids Batch | Low Solids Fed-Batch | Mixed Profile Fed-Batch | Total Training MSE | Total Validation MSE | |
|---|---|---|---|---|---|---|
| Langmuir-Type Kinetics | Data Usage | Training | Training | No Prediction | 27.77 g2.·L−2 | No Prediction |
| MSE | 13.72 g2.·L−2 | 42.82 g2.·L−2 | ||||
| Michaelis-Menten Kinetics | Data Usage | Training | Training | No Prediction | 8.90 g2.·L−2 | No Prediction |
| MSE | 7.12 g2.·L−2 | 10.69 g2.·L−2 | ||||
| High Solids Model | Data Usage | Training | Validation | Validation | 0.64 g2.·L−2 | 37.86 g2.·L−2 |
| MSE | 0.64 g2.·L−2 | 50.26 g2.·L−2 | 25.45 g2.·L−2 | |||
| Low Solids Model | Data Usage | Validation | Training | Validation | 2.15 g2.·L−2 | 28.12 g2.·L−2 |
| MSE | 42.40 g2.·L−2 | 2.15 g2.·L−2 | 13.84 g2.·L−2 | |||
| Fuzzy Model | Data Usage | Training | Training | Validation | 1.29 g2.·L−2 | 14.48 g2.·L−2 |
| MSE | 0.45 g2.·L−2 | 2.14 g2.·L−2 | 14.48 g2.·L−2 | |||
© 2019 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Furlong, V.B.; Corrêa, L.J.; Giordano, R.C.; Ribeiro, M.P.A. Fuzzy-Enhanced Modeling of Lignocellulosic Biomass Enzymatic Saccharification. Energies 2019, 12, 2110. https://doi.org/10.3390/en12112110
Furlong VB, Corrêa LJ, Giordano RC, Ribeiro MPA. Fuzzy-Enhanced Modeling of Lignocellulosic Biomass Enzymatic Saccharification. Energies. 2019; 12(11):2110. https://doi.org/10.3390/en12112110
Chicago/Turabian StyleFurlong, Vitor B., Luciano J. Corrêa, Roberto C. Giordano, and Marcelo P. A. Ribeiro. 2019. "Fuzzy-Enhanced Modeling of Lignocellulosic Biomass Enzymatic Saccharification" Energies 12, no. 11: 2110. https://doi.org/10.3390/en12112110
APA StyleFurlong, V. B., Corrêa, L. J., Giordano, R. C., & Ribeiro, M. P. A. (2019). Fuzzy-Enhanced Modeling of Lignocellulosic Biomass Enzymatic Saccharification. Energies, 12(11), 2110. https://doi.org/10.3390/en12112110