Research on Predicting Line Loss Rate in Low Voltage Distribution Network Based on Gradient Boosting Decision Tree

Abstract
:1. Introduction
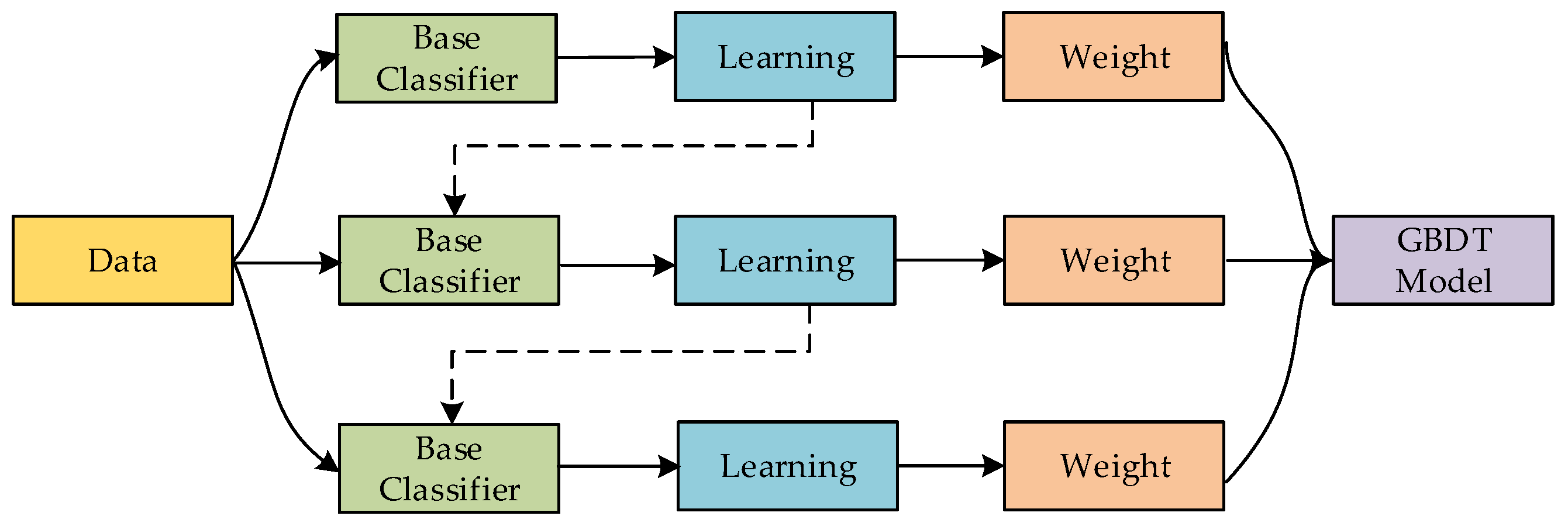
2. Gradient Boosting Decision Tree
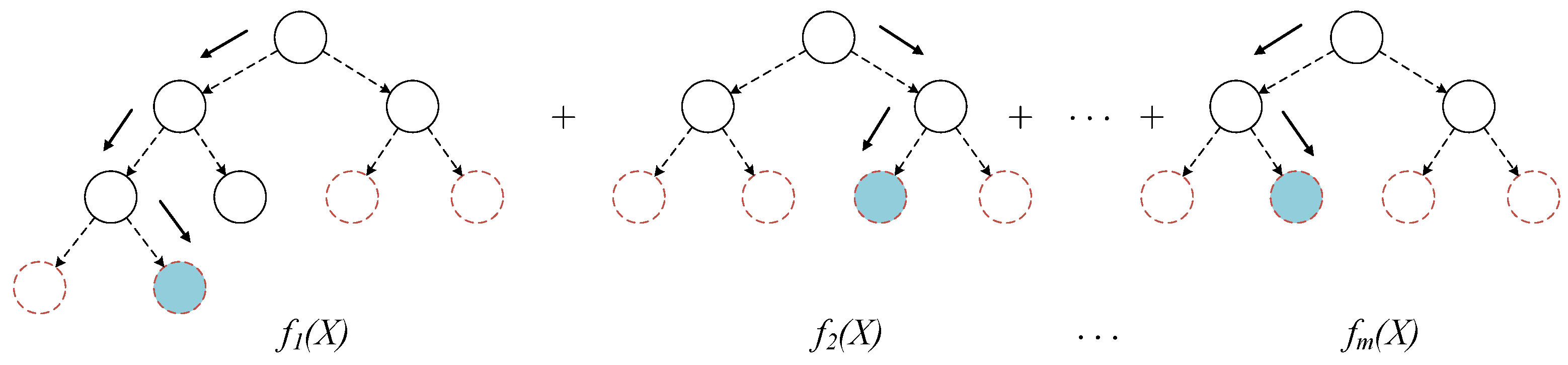
2.1. Gradient Boosting
2.2. Classification and Regression Tree
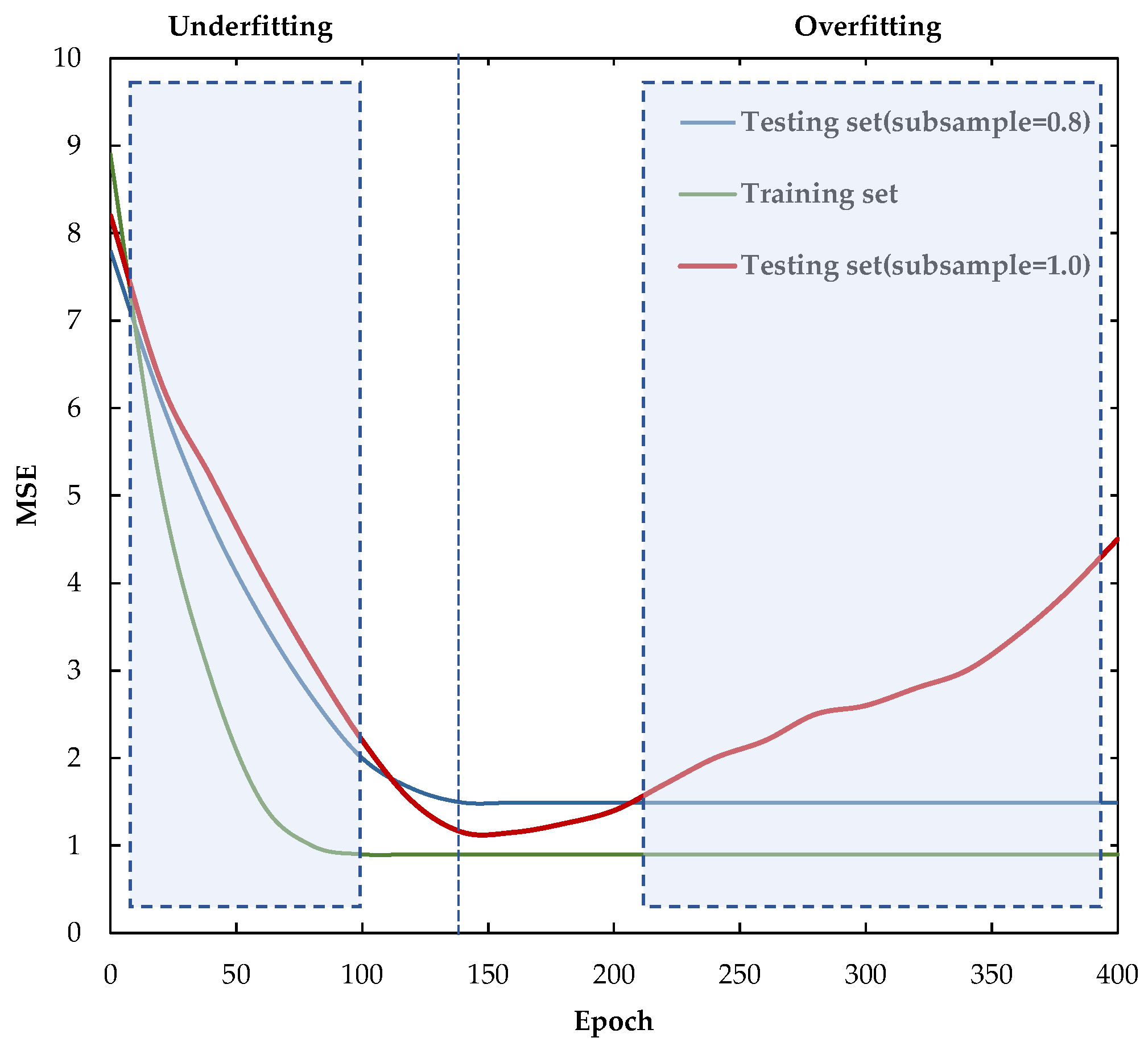
2.3. Gradient Boosting Decision Tree
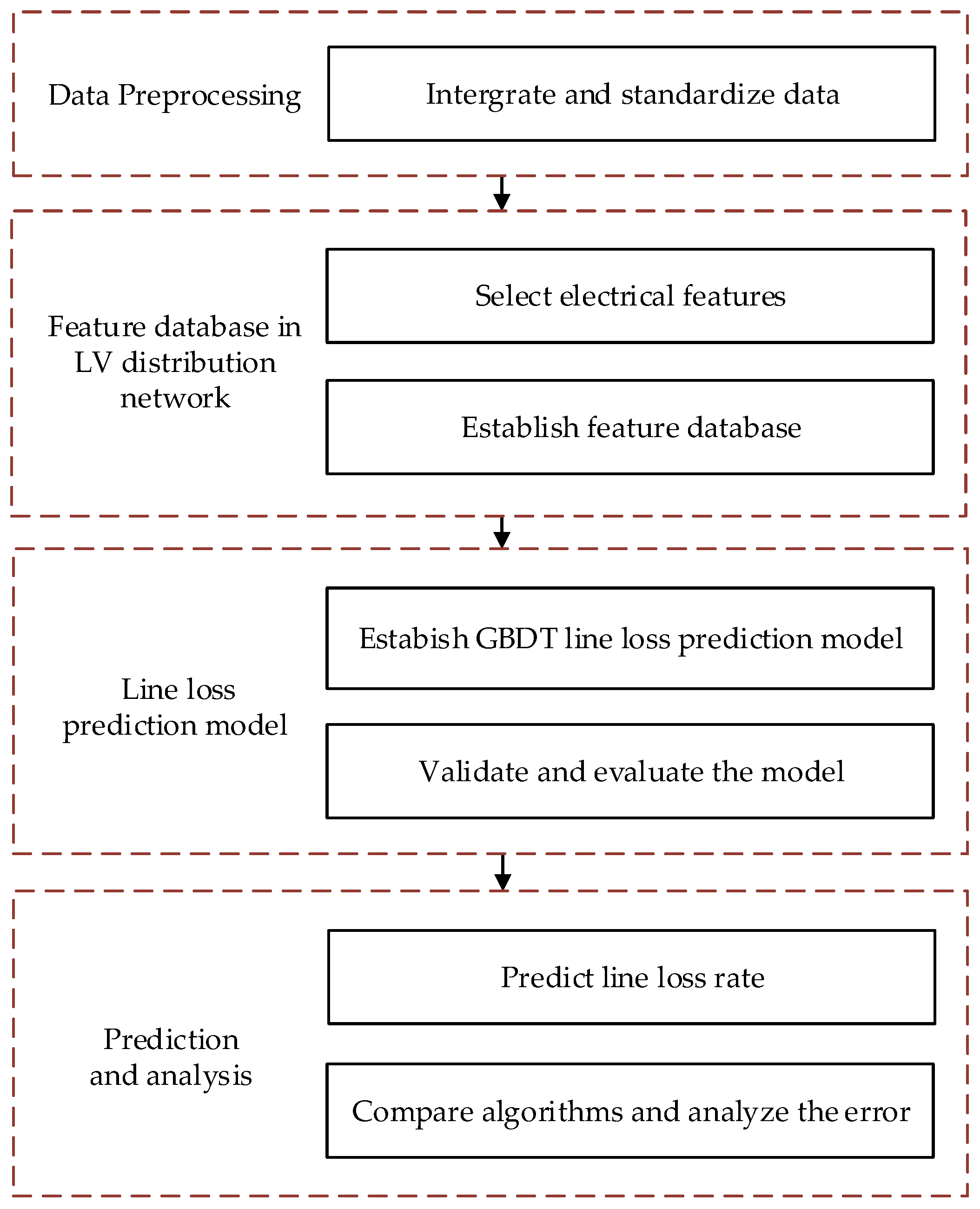
3. Approach to Calculating Line Loss Rate in the LV Distribution Network Based on GBDT
3.1. Establish Feature Database
3.2. LV Distribution Network Classification Based on DBSCAN
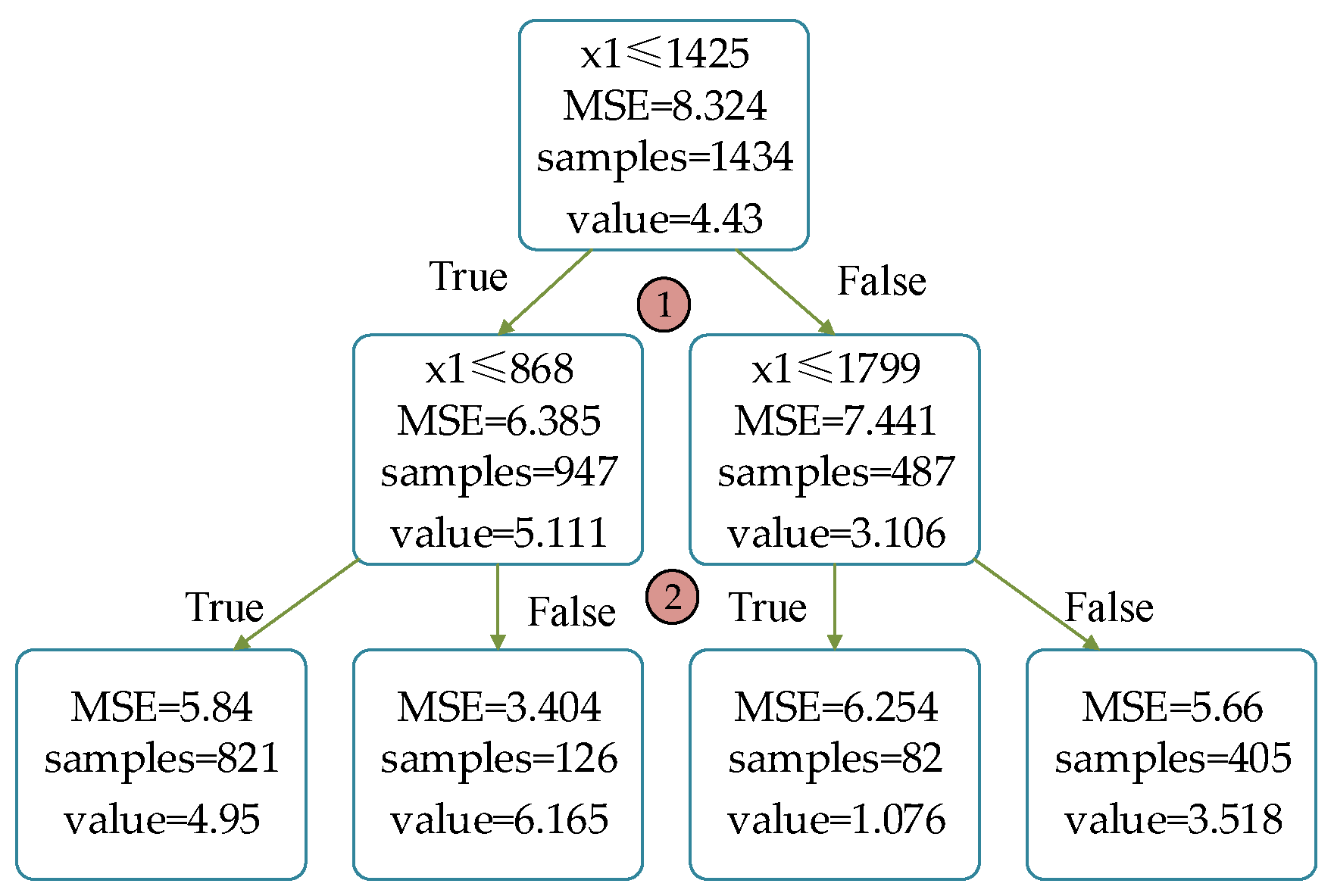
3.3. Line Loss Prediction of LV Distribution Network Based on GBDT
4. Experiments
4.1. Data Preprocessing
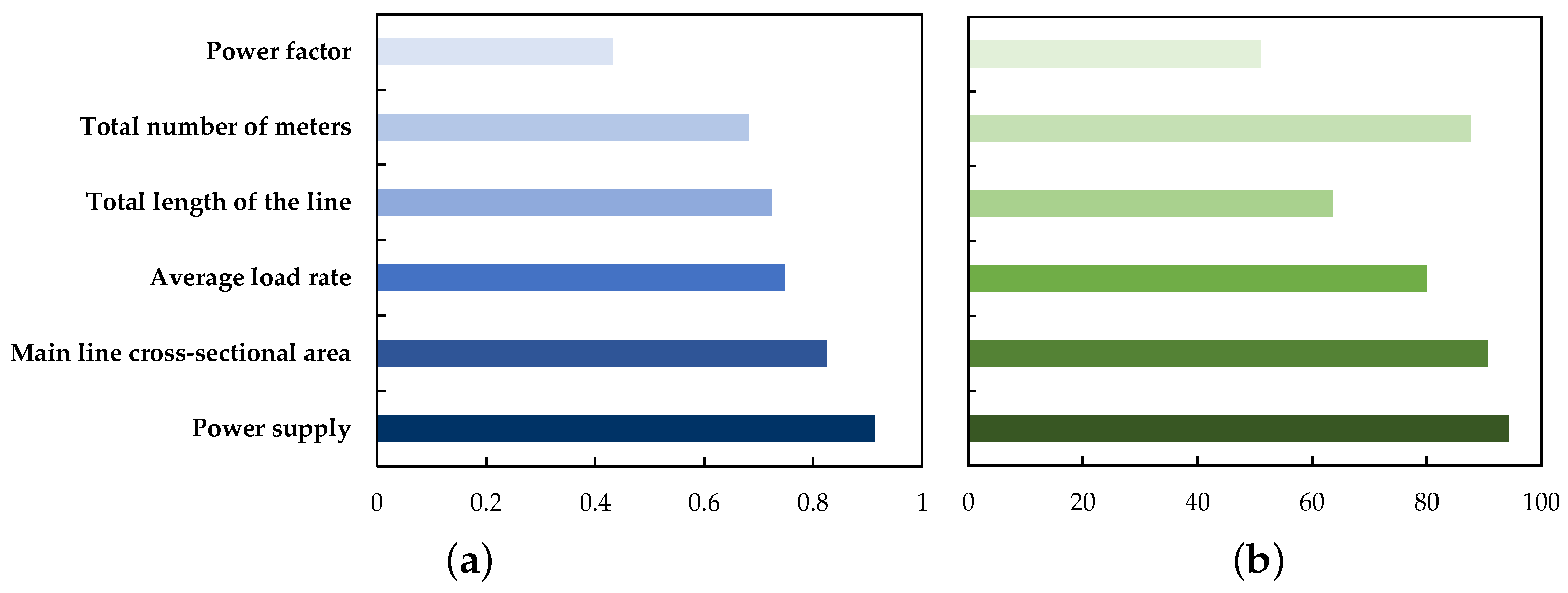
4.2. Establish Feature Database
4.3. Classifying the LV Distribution Network
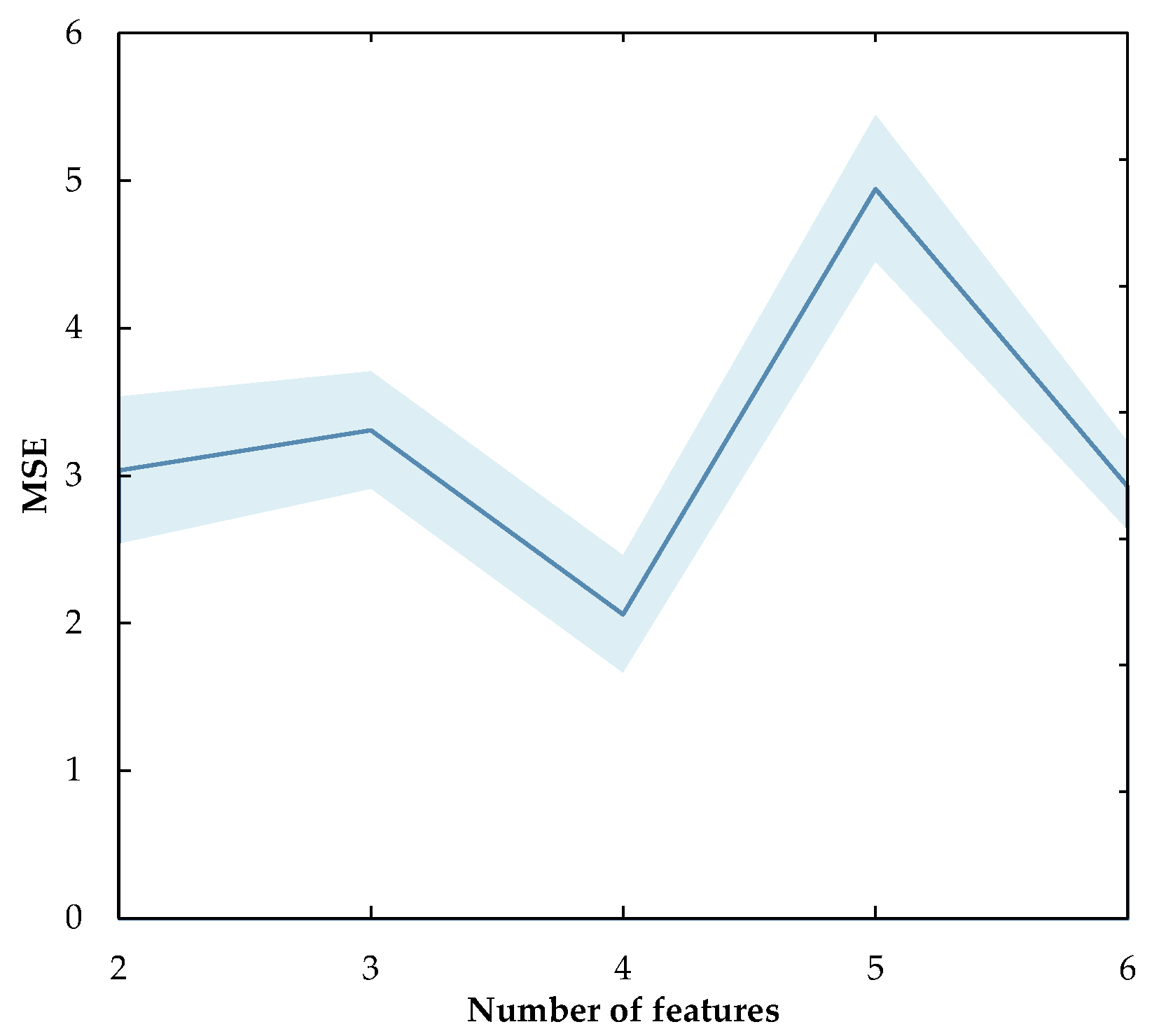
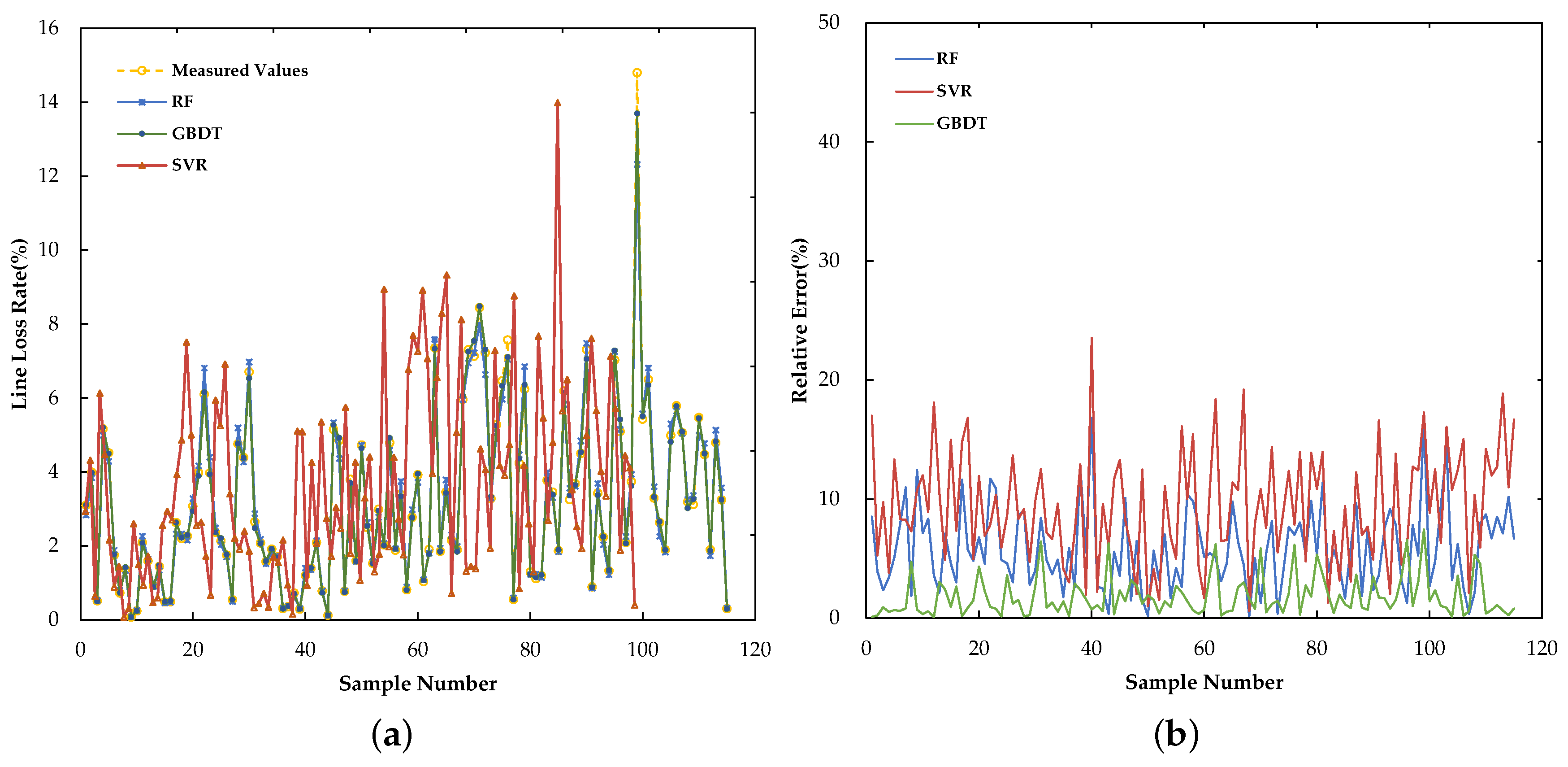
4.4. Results
5. Conclusions
Author Contributions
Funding
Conflicts of Interest
Abbreviations
| LV | Low voltage |
| GBDT | Gradient boosting decision tree |
| DBSCAN | Density-based spatial clustering of applications with noise |
| AMR | Automatic meter reading |
| ANN | Artificial neural network |
| BPNN | Back propagation neural network |
| SVR | Support vector regression |
| RF | Random forest |
| CART | Classification and regression trees |
| MART | Multiple additive regression tree |
| MSE | Mean squared error |
| SGBT | Stochastic gradient boosting tree |
References
- Sun, D.I.H.; Abe, S.; Shoults, R.R.; Chen, M.S.; Eichenberger, P.; Farris, D. Calculation of Energy Losses in a Distribution System. IEEE Trans. Power Appar. Syst. 1980, PAS-99, 1347–1356. [Google Scholar] [CrossRef]
- Chen, L.I.; Ding, X.Q.; Liu, X.B.; Zhou, Z.H. Line loss comprehensive analytical method based on real-time system data and its application. Electr. Power Autom. Equip. 2005, 25, 47–50. [Google Scholar]
- Li, Z.Y.; Ren, Z.; Chen, Y.J. Loss study of HVDC system. Dianli Zidonghua Shebei/Electr. Power Autom. Equip. 2007, 27, 9–12. [Google Scholar]
- Chen, D.; Guo, Z. Distribution system theoretical line loss calculation based on load obtaining and matching power flow. Power Syst. Technol. 2005, 29, 80–84. [Google Scholar]
- Zhang, K.; Yang, X.; Bu, C.; Ru, W.; Liu, C.; Yang, Y.; Chen, Y. Theoretical analysis on distribution network loss based on load measurement and countermeasures to reduce the loss. Proc. Chin. Soc. Electr. Eng. 2013, 33, 92–97. [Google Scholar]
- Liu, T.; Wang, S.; Zhang, Z.; Zhu, J. Newton-Raphson method for theoretical line loss calculation of low-voltage distribution transformer district by using the load electrical energy. Power Syst. Prot. Control 2015, 43, 143–148. [Google Scholar]
- Xin, K.Y.; Yang, Y.H.; Chen, F. Advanced algorithm based on combination of GA with BP to energy loss of distribution system. Proc. Chin. Soc. Electr. Eng. 2002, 22, 79–82. [Google Scholar]
- Li, X.Q.; Wang, H.; Xu, C.W.; Xu, F.; Zhao, L.N.; Meng, Q.R.; Liu, D.W. Calculation of line losses in distribution systems using artificial neural network aided by immune genetic algorithm. Proc. CSU-EPSA 2009, 37, 36–39. [Google Scholar]
- Jiang, H.L.; An, M.; Liu, X.J.; Zhao, X.; Zhang, J.H. Calculation of energy losses in distribution systems based on RBF network with dynamic clustering algorithm. Proc. Chin. Soc. Electr. Eng. 2005, 25, 35–39. [Google Scholar]
- Kim, H.; Ko, Y.; Jung, K.H. Artificial neural-network based feeder reconfiguration for loss reduction in distribution systems. IEEE Trans. Power Deliv. 1993, 8, 1356–1366. [Google Scholar] [CrossRef]
- Li, Y.; Liu, L.; Li, B.; Yi, J.; Wang, Z.; Tian, S. Calculation of line loss rate in transformer district based on improved k-means clustering algorithm and BP neural network. Proc. CSEE 2016, 36, 4543–4551. [Google Scholar]
- Ahmadizar, F.; Soltanian, K.; Akhlaghiantab, F.; Tsoulos, I. Artificial neural network development by means of a novel combination of grammatical evolution and genetic algorithm. Eng. Appl. Artif. Intell. 2015, 39, 1–13. [Google Scholar] [CrossRef]
- Zou, Y.F.; Mei, F.; Yue, L.I.; Cheng, Y.; Wang, T.U.; Mei, J. Prediction model research of reasonable line loss for transformer district based on data mining technology. Power Demand Side Manag. 2015, 4, 25–29. [Google Scholar] [CrossRef]
- Chen, C.S.; Hwang, J.C.; Cho, M.Y.; Chen, Y.W. Development of simplified loss models for distribution system analysis. IEEE Trans. Power Deliv. 2002, 9, 1545–1551. [Google Scholar] [CrossRef]
- Huang, D.X.; Gong, R.X.; Gong, S. Prediction of Wind Power by Chaos and BP Artificial Neural Networks Approach Based on Genetic Algorithm. J. Electr. Eng. Technol. 2015, 10, 41–46. [Google Scholar] [CrossRef] [Green Version]
- Fushuan, W.; Zhenxiang, H. The Calculation of Energy Losses in Distribution Systems Based upon a Clustering Algorithm and an Artificial Neural Network Model. Proc. CSEE 1993, 3, 41–51. [Google Scholar]
- Wang, S.; Zhou, K.; Yun, S.U. Line loss rate estimation method of transformer district based on random forest algorithm. Electr. Power Autom. Equip. 2017. [Google Scholar] [CrossRef]
- Peng, Y.; Liu, K. A distribution network theoretical line loss calculation method based on improved core vector machine. Proc. Chin. Soc. Electr. Eng. 2011, 31, 120–126. [Google Scholar]
- Xu, R.; Wang, Y. Theoretical line loss calculation based on SVR and PSO for distribution system. Electr. Power Autom. Equip. 2012, 32, 86–89+93. [Google Scholar]
- Breiman, L. Arcing The Edge. Ann. Stat. 1998, 26, 801–824. [Google Scholar]
- Breiman, L.; Friedman, J.; Stone, C.J.; Olshen, R.A. Encyclopedia of Ecology. In Classification and Regression Trees; Routledge: London, UK, 1984. [Google Scholar]
- Seera, M.; Lim, C.P. Online Motor Fault Detection and Diagnosis Using a Hybrid FMM-CART Model. IEEE Trans. Neural Netw. Learn. Syst. 2014, 25, 806–812. [Google Scholar] [CrossRef] [PubMed]
- Gey, S.; Nedelec, E. Model selection for CART regression trees. IEEE Trans. Inf. Theory 2005, 51, 658–670. [Google Scholar] [CrossRef]
- Wang, T.; Pal, A.; Thorp, J.S.; Wang, Z.; Liu, J.; Yang, Y. Multi-Polytope-Based Adaptive Robust Damping Control in Power Systems Using CART. IEEE Trans. Power Syst. 2015, 30, 2063–2072. [Google Scholar] [CrossRef]
- Loh, W.Y. Classification and regression trees. Wiley Interdiscip. Rev. Data Min. Knowl. Discov. 2011, 1, 14–23. [Google Scholar] [CrossRef]
- Zhang, X.; Wang, X.; Chen, W.; Tao, J.; Huang, W.; Wang, T. A Taxi Gap Prediction Method via Double Ensemble Gradient Boosting Decision Tree. Processdings of the 2017 IEEE 3rd International Conference on Big Data Security on Cloud (Bigdatasecurity), Beijing, China, 26–28 May 2017; pp. 255–260. [Google Scholar] [CrossRef]
- Friedman, J.H. Greedy function approximation: A gradient boosting machine. Ann. Stat. 2001, 29, 1189–1232. [Google Scholar] [CrossRef]
- Ma, X.; Ding, C.; Luan, S.; Wang, Y.; Wang, Y. Prioritizing Influential Factors for Freeway Incident Clearance Time Prediction Using the Gradient Boosting Decision Trees Method. IEEE Trans. Intell. Transp. Syst. 2017, 18, 2303–2310. [Google Scholar] [CrossRef]
- Shouxiang W, T.L. Gradient Boosting Decision Tree Method for Residential Load Classification Considering Typical Power Consumption Modes. Proc. CSU-EPSA 2017, 29, 27–33. [Google Scholar] [CrossRef]
- Wang, L.; Zhou, D.; Zhang, H.; Zhang, W.; Chen, J. Application of Relative Entropy and Gradient Boosting Decision Tree to Fault Prognosis in Electronic Circuits. Symmetry 2018, 10, 495. [Google Scholar] [CrossRef]
- Lucas, A.; Barranco, R.; Refa, N. EV Idle Time Estimation on Charging Infrastructure, Comparing Supervised Machine Learning Regressions. Energies 2019, 12, 269. [Google Scholar] [CrossRef]
- Naz, A.; Javed, M.U.; Javaid, N.; Saba, T.; Alhussein, M.; Aurangzeb, K. Short-Term Electric Load and Price Forecasting Using Enhanced Extreme Learning Machine Optimization in Smart Grids. Energies 2019, 12, 866. [Google Scholar] [CrossRef]
- Wang, J.; Li, P.; Ran, R.; Che, Y.; Zhou, Y. A Short-Term Photovoltaic Power Prediction Model Based on the Gradient Boost Decision Tree. Appl. Sci. 2018, 8, 689. [Google Scholar] [CrossRef]
- Cai, L.; Gu, J.; Ma, J.; Jin, Z. Probabilistic Wind Power Forecasting Approach via Instance-Based Transfer Learning Embedded Gradient Boosting Decision Trees. Energies 2019, 12, 159. [Google Scholar] [CrossRef]
- Zheng, H.; Yuan, J.; Chen, L. Short-Term Load Forecasting Using EMD-LSTM Neural Networks with a Xgboost Algorithm for Feature Importance Evaluation. Energies 2017, 10, 1168. [Google Scholar] [CrossRef]
- Ouyang, S.; Chen, X. Reactive power optimal configuration strategy in transformer areas based on normal state-differential characteristics. Power Syst. Technol. 2015, 39, 3513–3519. [Google Scholar] [CrossRef]
- Ouyang, S.; Feng, T.; An, X. Line-loss rate calculation model considering feeder clustering features for medium-voltage distribution network. Electr. Power Autom. Equip. 2016, 36, 33–39. [Google Scholar] [CrossRef]
- Xu, T.; Chiang, H.; Liu, G.; Tan, C. Hierarchical K-means Method for Clustering Large-Scale Advanced Metering Infrastructure Data. IEEE Trans. Power Deliv. 2017, 32, 609–616. [Google Scholar] [CrossRef]
- Mat Isa, N.A.; Salamah, S.A.; Ngah, U.K. Adaptive fuzzy moving K-means clustering algorithm for image segmentation. IEEE Trans. Consum. Electr. 2009, 55, 2145–2153. [Google Scholar] [CrossRef]
- Ghaemi, Z.; Farnaghi, M. A Varied Density-based Clustering Approach for Event Detection from Heterogeneous Twitter Data. ISPRS Int. J. Geo-Inf. 2019, 8, 82. [Google Scholar] [CrossRef]
- Lee, G.; Kim, D.I.; Kim, S.H.; Shin, Y.J. Multiscale PMU Data Compression via Density-Based WAMS Clustering Analysis. Energies 2019, 12, 617. [Google Scholar] [CrossRef]
- Jadidi, A.; Menezes, R.; De Souza, N.; De Castro Lima, A.C. A Hybrid GA–MLPNN Model for One-Hour-Ahead Forecasting of the Global Horizontal Irradiance in Elizabeth City, North Carolina. Energies 2018, 11, 2614. [Google Scholar] [CrossRef]
- Gowanlock, M.; Blair, D.M.; Pankratius, V. Optimizing Parallel Clustering Throughput in Shared Memory. IEEE Trans. Parallel Distrib. Syst. 2017, 28, 2595–2607. [Google Scholar] [CrossRef]
- Shen, J.; Hao, X.; Liang, Z.; Liu, Y.; Wang, W.; Shao, L. Real-Time Superpixel Segmentation by DBSCAN Clustering Algorithm. IEEE Trans. Image Process. 2016, 25, 5933–5942. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Ester, M.; Kriegel, H.P.; Sander, J.; Xu, X. A Density-Based Algorithm for Discovering Clusters in Large Spatial Databases with Noise. In Proceedings of the KDD’96 Proceedings of the Second International Conference on Knowledge Discovery and Data Mining, Portland, OR, USA, 2–4 August 1996. [Google Scholar]
- Friedman, J.H. Stochastic Gradient Boosting. Comput. Stat. Data Anal. 2002, 38, 367–378. [Google Scholar] [CrossRef]
- Ouyang, S.; Yang, J.; Geng, H.; Wu, Y.; Chen, X. Comprehensive evaluation method of transformer area state oriented to transformer area management and its application. Dianli Xitong Zidonghua/Autom. Electr. Power Syst. 2015, 39, 187–192. [Google Scholar] [CrossRef]
- James, G.; Witten, D.; Hastie, T.; Tibshirani, R. An Introduction to Statistical Learning; Springer: Berlin, Germany, 2013. [Google Scholar]










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Cluster Number | Features | |||
|---|---|---|---|---|
| Main Line Cross-Sectional Area (mm) | Total Length of The Line (m) | Average Load Rate (%) | Power Supply (MW·h) | |
| A | 120 | 6210.42 | 54 | 1690.56 |
| B | 86.402 | 1610.56 | 43 | 920.02 |
| C | 69.862 | 1706.35 | 37 | 443.39 |
| D | 48.691 | 568.67 | 33 | 81.65 |
| Models | Hyperparameters |
|---|---|
| Support vector regression (SVR) | {’C’: 4 , ’epsilon’: 0} |
| Random forest (RF) | {‘n_estimators’: 200, ‘min_samples_split’: 8, ‘min_samples_leaf’: 5, ’max_features’: 2, ‘max_depth’: 80, ‘bootstrap’: True} |
| GBDT | {‘n_estimators’: 120, ‘min_samples_split’: 4, ‘min_samples_leaf’: 3, ‘max_depth’: 60, ‘learning_rate’: 0.1, ‘subsample’: 0.8} |
| MSE | Maximum Relative Error (%) | Mean Relative Error (%) | ||||||
|---|---|---|---|---|---|---|---|---|
| SVR | RF | GBDT | SVR | RF | GBDT | SVR | RF | GBDT |
| 4.99 | 3.61 | 2.75 | 23.53 | 16.84 | 7.43 | 9.41 | 5.81 | 1.81 |
| Number | Measured Value (%) | Prediction Value (%) | Relative Error (%) | Assessment |
|---|---|---|---|---|
| 7 | 4.52 | 4.49 | 0.66 | |
| 142 | 2.09 | 2.14 | 2.39 | |
| 359 | 7.76 | 8.02 | 3.35 | Qualified |
| 376 | 6.19 | 6.37 | 2.91 | |
| 791 | 3.92 | 3.76 | 4.14 | |
| 528 | 12.31 | 12.82 | 4.08 | Heavy loss |
| 1025 | 15.79 | 15.23 | 3.55 | |
| 38 | −2.9 | 3.804 | - | |
| 242 | ? | 6.203 | - | Abnormal |
| 586 | 63.84 | 12.76 | - |
© 2019 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Yao, M.; Zhu, Y.; Li, J.; Wei, H.; He, P. Research on Predicting Line Loss Rate in Low Voltage Distribution Network Based on Gradient Boosting Decision Tree. Energies 2019, 12, 2522. https://doi.org/10.3390/en12132522
Yao M, Zhu Y, Li J, Wei H, He P. Research on Predicting Line Loss Rate in Low Voltage Distribution Network Based on Gradient Boosting Decision Tree. Energies. 2019; 12(13):2522. https://doi.org/10.3390/en12132522
Chicago/Turabian StyleYao, Mengting, Yun Zhu, Junjie Li, Hua Wei, and Penghui He. 2019. "Research on Predicting Line Loss Rate in Low Voltage Distribution Network Based on Gradient Boosting Decision Tree" Energies 12, no. 13: 2522. https://doi.org/10.3390/en12132522
APA StyleYao, M., Zhu, Y., Li, J., Wei, H., & He, P. (2019). Research on Predicting Line Loss Rate in Low Voltage Distribution Network Based on Gradient Boosting Decision Tree. Energies, 12(13), 2522. https://doi.org/10.3390/en12132522