Solving Scheduling Problem in a Distributed Manufacturing System Using a Discrete Fruit Fly Optimization Algorithm




Abstract
:
1. Introduction
- (1)
- An initialization strategy based on problem-specific characteristics is proposed to generate an initial population with good quality and diversity.
- (2)
- In the smell-based search phase of DFOA, a novel neighborhood strategy is designed with the view of extending the exploration.
- (3)
- To enhance the exploitation of DFOA, an adaptive VND-based local search strategy is highlighted.
- (4)
- In the vision-based search phase, an effective elite-based update criterion is proposed, which helps DFOA converge faster.
2. Related Work
2.1. Blocking Flowshop Scheduling Problem (BFSP)
2.2. Distributed Flowshop Scheduling Problem (DFSP)
- (1)
- Assign job j to the factory with the lowest current makespan Cmax (not including job j).
- (2)
- Assign job j to the factory that completes it at the earliest time, i.e., the factory resulting in the lowest makespan Cmax (after assigning job j).
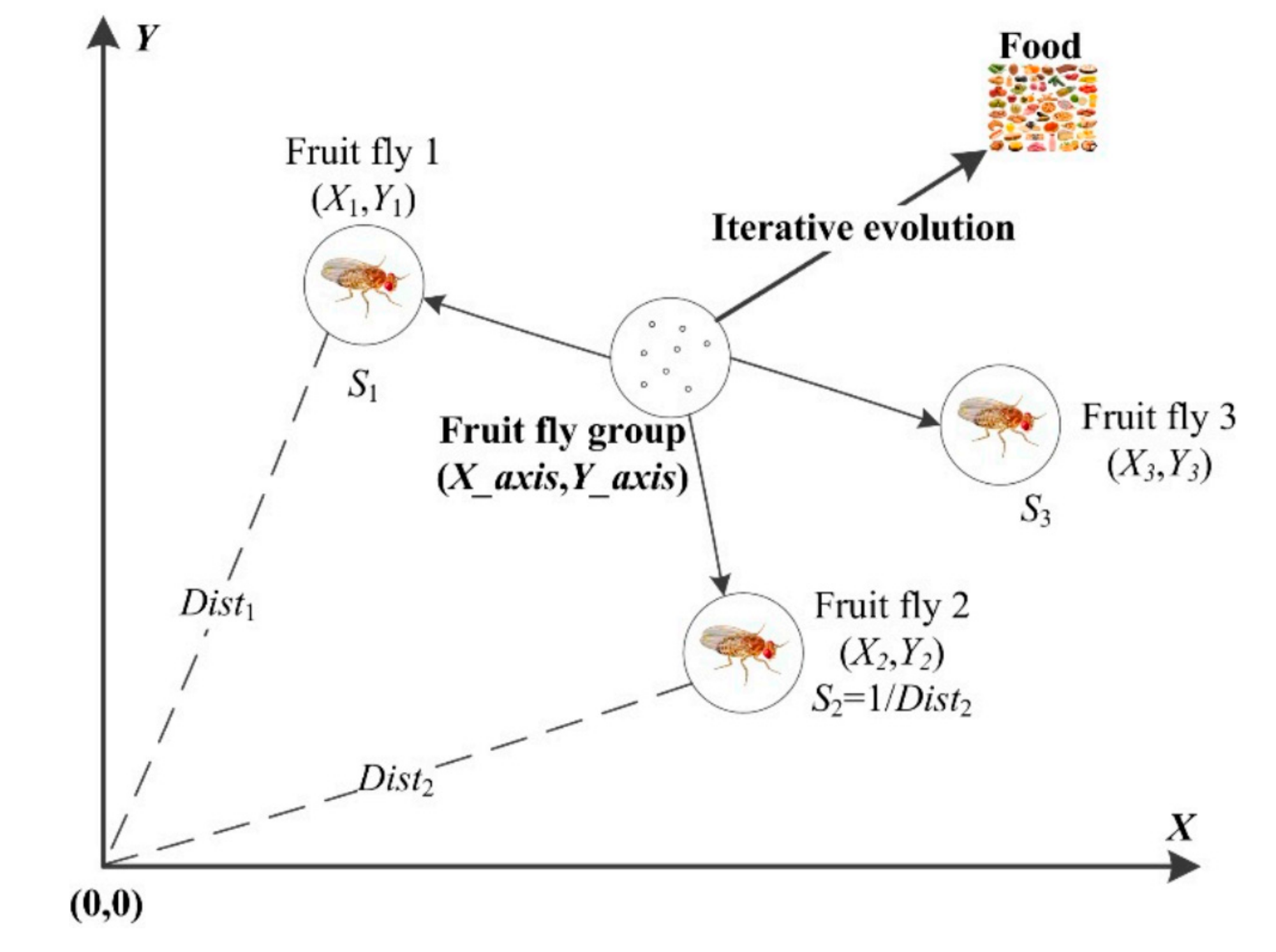
2.3. Fruit Fly Algorithm (FOA)
- Step 1.
- Initialization of parameters: Set the population size and the number of generations.
- Step 2.
- Initialization of the fruit fly population with location.
- Step 3.
- Smell-based search phase: The fruit fly exploits N locations (i.e., food sources) randomly. Evaluate the N locations with the smell concentration values as fitness values.
- Step 4.
- Vision-based search phase: Replace the current best population location when a better location is found. The population flies towards the new best location.
- Step 5.
- Termination criterion: End the procedure if the maximum generation number is reached; otherwise, back to Step 3. The detailed search procedure of FOA refers to Reference [36].
2.4. Discussion
3. Problem Statement
3.1. Problem Description of BFSP and DBFSP
- (1)
- The orders where all jobs to be processed is the same on each machine.
- (2)
- If is occupied, the job needs to be blocked on the current machine until is available.
- (3)
- The job cannot be interrupted once it starts operation.
- (4)
- Each machine can only handle one job at a time.
- (5)
- All jobs and machines are available at time zero.
- (6)
- The setup time of jobs is included in the processing time.
3.2. Mathematical Model of DBFSP
4. Proposed Algorithm for Solving DBFSP
4.1. Solution Representation
4.2. Population Initialization
| Algorithm 1 ECF rule |
| Procedure ECF rule |
| Input Parameter (solution , factory number F) |
| Fork = 1 to F |
| End For |
| Fork = F + 1 to n |
| Find the factory f that can process job with the earliest completion time |
| End For |
| Output |
4.3. Smell-Based Search Phase
| Algorithm 2 Neighborhood search strategy |
| Procedure Neighborhood search strategy |
| Input: Parameter (initialized solution , critical factory fc) Output: Solution |
| Begin // neighborhood operation |
| :← Forward insertion operator within the critical factory :← Backward insertion operator within the critical factory :← Insertion operator between the critical factory and other factories :← Swap operator between the critical factory and other factories evaluate , , , // makespan evaluation Output End |
4.4. VND-Based Local Search
- Step 1:
- Calculate the departure time, , of the jobs that are already assigned in the factory with Equations (1)–(5).
- Step 2:
- Calculate the tails, , of jobs that are already assigned in the factory with Equations (9)–(13), shown as follows:
- Step 3:
- Calculate the departure times, , of jo J to be inserted in the position q of the selected factory in the current solution.
- Step 4:
- Compare the makespan of the selected factory after inserting job J in the position by
- Step 5:
- Choose the best insertion position and return the best makespan. The pseudocode of the LS_Insert process is illustrated in Algorithm 3.
| Algorithm 3 Local search insert |
| Procedure Local search insert |
| Input: Parameter (solution , factory number F) |
| Output: Solution |
| Begin |
| While stop criterion is not satisfied |
| For j = 1 to // traverse all jobs in the critical factory |
| Select job j from the critical factory fc without repetition |
| Select a factory f randomly without repetition (with sequence ) |
| Insert j in the best position of f and obtaining |
| If then |
| : update by substituting with , remove job j from the critical factory |
| Calculate the using the speed-up method and detect the new critical factory |
| Else |
| End If |
| End For |
| End While |
| End |
| Algorithm 4 Local search swap |
| Procedure Local search swap |
| Input: Parameter (solution , factory number F) |
| Output: Solution |
| Begin |
| While the stop criterion is not satisfied |
| For j = 1 to // job number in the critical number |
| Select j from the critical factory fc without repetition |
| For f = 1 to F // select a non-critical factory |
| If f ≠ fc then |
| For i = 1 to // the job number in the select factory |
| remove job j from fc and insert i in the best position of fc obtaining , calculate using the speed-up method |
| remove job i from f and insert j in the best position of f obtaining , calculate using the speed-up method |
| If and then |
| : modify with and |
| Else , return job j and job i to their original positions |
| End If |
| End For |
| End If |
| End For |
| End For |
| Output |
| End |
| Algorithm 5 VND-based local search |
| Procedure VND-based local search |
| Input: Parameter (Solution ) |
| Output: Solution |
| Begin |
| Nl = {LS_Insert, LS_Swap} |
| For i = 1 to Size(Nl) |
| If then |
| Else i = i + 1 End If |
| If i > Size(Nl) |
| Break End If End For |
| End |
4.5. Vision-Based Search Phase
| Algorithm 6 DFOA for DBFSP |
| Procedure DFOA for DBFSP |
| Input: Parameter (population size Ps, termination time Tmax) |
| Output: best solution |
| Begin |
| // Initialize population (Section 4.2) |
| ← problem-specific heuristic (DNPM) |
| ← problem-specific heuristic (NEH2) |
| ← problem-specific heuristic (DNRM) |
| Repeat |
| Fori = 1 to Ps // smell-based search phase (Section 4.3) |
| ← Neighborhood search strategy |
| ← VND-based local search // (Section 4.4) |
| If then |
| If then |
| End If |
| End If |
| End For |
| // vision-based search phase (Section 4.5) |
| Find out the worst solution in the whole population |
| = Update criterion () |
| Until the termination time Tmax is met |
| End |
5. Computational Experiment
5.1. Experiment Setting
- (1)
- Average relative percentage deviation (ARPD) is considered as a response variable that evaluates the mean quality of solutions, as follows:
- (2)
- Standard deviation (SD) that evaluates the quality of initial solutions and the robustness of the algorithm, as follows:
- (1)
- Sensitivity analysis of parameter Ps;
- (2)
- Comparison of the heuristics initialization methods;
- (3)
- Comparison of the local search methods;
- (4)
- Comparison with heuristics on small-scale instances;
- (5)
- Comparison with metaheuristics from other literature on large-scale instances.
5.2. Sensitivity Analysis
5.3. Comparison of the Heuristic Initialization Methods
5.4. Comparison of the Local Search Methods
5.5. Comparison with Heuristics on Small-Scale Instances
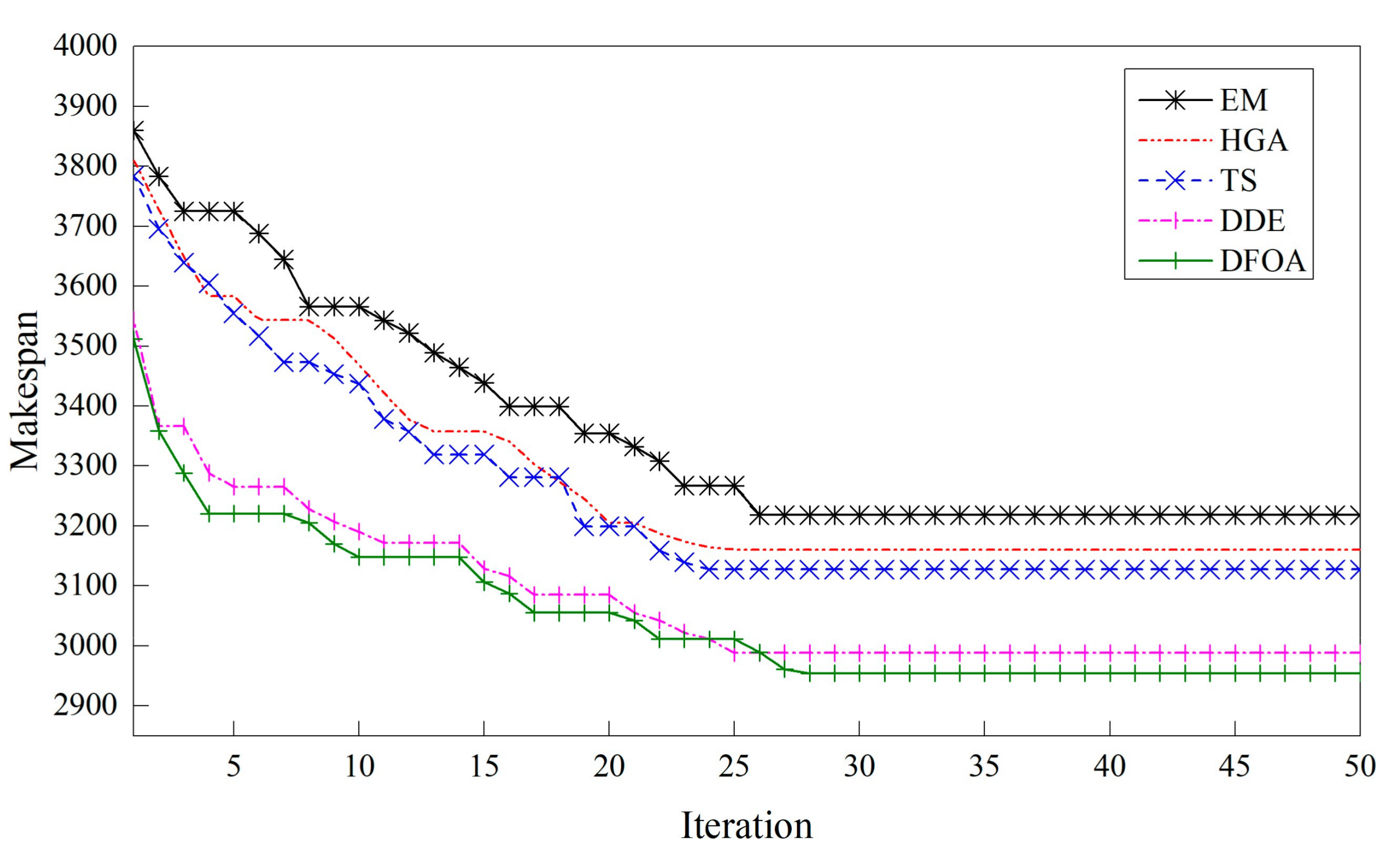
5.6. Comparison to Other Metaheuristics on Large-Scale Instances
6. Conclusion and Future Works
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
References
- Zhao, F.; Xue, F.; Zhang, Y.; Ma, W.; Zhang, C.; Song, H. A discrete gravitational search algorithm for the blocking flow shop problem with total flow time minimization. Appl. Intell. 2019, 49, 3362–3382. [Google Scholar] [CrossRef]
- Leisten, R. Flowshop sequencing problems with limited buffer storage. Int. J. Prod. Res. 1990, 28, 2085–2100. [Google Scholar] [CrossRef]
- Graham, R.L.; Lawler, E.L.; Lenstra, J.K.; Kan, A.R. Optimization and approximation in deterministic sequencing and scheduling: A survey. Ann. Discret. Math. 1979, 5, 287–326. [Google Scholar] [CrossRef]
- Riahi, V.; Newton, M.H.; Su, K.; Sattar, A. Constraint guided accelerated search for mixed blocking permutation flowshop scheduling. Comput. Oper. Res. 2019, 102, 102–120. [Google Scholar] [CrossRef]
- Nagano, M.S.; Komesu, A.S.; Miyata, H.H. An evolutionary clustering search for the total tardiness blocking flow shop problem. J. Intell. Manuf. 2019, 30, 1843–1857. [Google Scholar] [CrossRef]
- Leiras, A.; Hamacher, S.; Elkamel, A. Petroleum refinery operational planning using robust optimization. Eng. Optim. 2010, 42, 1119–1131. [Google Scholar] [CrossRef]
- Zhu, Q.; Wu, N.; Yan, Q.; Zhou, M. Optimal scheduling of complex multi-cluster tools based on timed resource-oriented petri nets. IEEE Access 2017, 4, 2096–2109. [Google Scholar] [CrossRef]
- Pan, D.; Yang, Y. Localized independent packet scheduling for buffered crossbar switches. IEEE Trans. Comput. 2009, 58, 260–274. [Google Scholar] [CrossRef]
- Fernandez-Viagas, V.; Leisten, R.; Framinan, J.M. A computational evaluation of constructive and improvement heuristics for the blocking flow shop to minimise total flowtime. Expert Syst. Appl. 2016, 61, 290–301. [Google Scholar] [CrossRef]
- Zhang, Y.; Gong, D.W.; Sun, J.Y.; Qu, B.Y. A decomposition-based archiving approach for multi-objective evolutionary optimization. Inf. Sci. 2018, 430, 397–413. [Google Scholar] [CrossRef]
- Caraffa, V.; Ianes, S.; Bagchi, T.P.; Sriskandarajah, C. Minimizing Makespan in a Blocking Flowshop using Genetic Algorithms. Int. J. Prod. Econ. 2001, 70, 101–115. [Google Scholar] [CrossRef]
- Grabowski, J.; Pempera, J. The permutation flow shop problem with blocking. A tabu search approach. Omega 2007, 35, 302–311. [Google Scholar] [CrossRef]
- Wang, L.; Pan, Q.K.; Suganthan, P.N.; Wang, W.H.; Wang, Y.M. A novel hybrid discrete differential evolution algorithm for blocking flowshop scheduling problems. Comput. Oper. Res. 2010, 37, 509–520. [Google Scholar] [CrossRef]
- Ribas, I.; Companys, R.; Tort-Martorell, X. An iterated greedy algorithm for the flowshop scheduling problem with blocking. Omega 2011, 39, 293–301. [Google Scholar] [CrossRef]
- Nawaz, M.; Enscore, E.E., Jr.; Ham, I. A heuristic algorithm for the m-machine, n-job flow-shop sequencing problem. Omega 1983, 11, 91–95. [Google Scholar] [CrossRef]
- Wang, X.; Tang, L. A discrete particle swarm optimization algorithm with self-adaptive diversity control for the permutation flowshop problem with blocking. Appl. Soft Comput. 2012, 12, 652–662. [Google Scholar] [CrossRef]
- Han, Y.Y.; Pan, Q.K.; Li, J.Q.; Sang, H.Y. An improved artificial bee colony algorithm for the blocking flowshop scheduling problem. Int. J. Adv. Manuf. Technol. 2012, 60, 1149–1159. [Google Scholar] [CrossRef]
- Han, Y.Y.; Gong, D.W.; Sun, X.Y.; Pan, Q.K. An improved NSGA-II algorithm for multi-objective lot-streaming flow shop scheduling problem. Int. J. Prod. Res. 2014, 52, 2211–2231. [Google Scholar] [CrossRef]
- Han, Y.Y.; Gong, D.W.; Li, J.Q.; Zhang, Y. Solving the blocking flowshop scheduling problem with makespan using a modified fruit fly optimisation algorithm. Int. J. Prod. Res. 2016, 54, 6782–6797. [Google Scholar] [CrossRef]
- Taillard, E. Benchmarks for basic scheduling problems. Eur. J. Oper. Res. 1993, 64, 278–285. [Google Scholar] [CrossRef]
- Shao, Z.; Pi, D.; Shao, W.; Yuan, P. An efficient discrete invasive weed optimization for blocking flow-shop scheduling problem. Eng. Appl. Artif. Intell. 2019, 78, 124–141. [Google Scholar] [CrossRef]
- Naderi, B.; Ruiz, R. The distributed permutation flowshop scheduling problem. Comput. Oper. Res. 2010, 37, 754–768. [Google Scholar] [CrossRef]
- Peng, K.; Pan, Q.K.; Gao, L.; Li, X.; Das, S.; Zhang, B. A multi-start variable neighbourhood descent algorithm for hybrid flowshop rescheduling. Swarm Evolut. Comput. 2019, 45, 92–112. [Google Scholar] [CrossRef]
- Liu, H.; Gao, L. A discrete electromagnetism-like mechanism algorithm for solving distributed permutation flowshop scheduling problem. In Proceedings of the International Conference on Manufacturing Automation, Hong Kong, China, 13–15 December 2010; pp. 156–163. [Google Scholar]
- Gao, J.; Chen, R. A hybrid genetic algorithm for the distributed permutation flowshop scheduling problem. Int. J. Comput. Int. Syst. 2011, 4, 497–508. [Google Scholar] [CrossRef]
- Gao, J.; Chen, R.; Deng, W. An efficient tabu search algorithm for the distributed permutation flowshop scheduling problem. Int. J. Prod. Res. 2013, 51, 641–651. [Google Scholar] [CrossRef]
- Wang, S.Y.; Wang, L.; Liu, M.; Xu, Y. An effective estimation of distribution algorithm for solving the distributed permutation flow-shop scheduling problem. Int. J. Prod. Econ. 2013, 145, 387–396. [Google Scholar] [CrossRef]
- Naderi, B.; Ruiz, R. A scatter search algorithm for the distributed permutation flowshop scheduling problem. Eur. J. Oper. Res. 2014, 239, 323–334. [Google Scholar] [CrossRef]
- Xu, Y.; Wang, L.; Wang, S.; Liu, M. An effective hybrid immune algorithm for solving the distributed permutation flow-shop scheduling problem. Eng. Optim. 2013, 46, 1269–1283. [Google Scholar] [CrossRef]
- Bargaoui, H.; Driss, O.B.; Ghedira, K. A novel chemical reaction optimization for the distributed permutation flowshop scheduling problem with makespan criterion. Comput. Ind. Eng. 2017, 111, 239–250. [Google Scholar] [CrossRef]
- Pan, Q.K.; Gao, L.; Wang, L.; Liang, J.; Li, X.Y. Effective heuristics and metaheuristics to minimize total flowtime for the distributed permutation flowshop problem. Expert Syst. Appl. 2019, 124, 309–324. [Google Scholar] [CrossRef]
- Ruiz, R.; Pan, Q.K.; Naderi, B. Iterated Greedy methods for the distributed permutation flowshop scheduling problem. Omega 2019, 83, 213–222. [Google Scholar] [CrossRef]
- Fernandez-Viagas, V.; Framinan, J.M. A bounded-search iterated greedy algorithm for the distributed permutation flowshop scheduling problem. Int. J. Prod. Res. 2015, 53, 1111–1123. [Google Scholar] [CrossRef]
- Zhang, G.; Xing, K.; Cao, F. Discrete differential evolution algorithm for distributed blocking flowshop scheduling with makespan criterion. Eng. Appl. Artif. Intell. 2018, 76, 96–107. [Google Scholar] [CrossRef]
- Shao, W.; Pi, D.; Shao, Z. Optimization of makespan for the distributed no-wait flow shop scheduling problem with iterated greedy algorithms. Knowl. Based Syst. 2017, 137, 163–181. [Google Scholar] [CrossRef]
- Pan, W.T. A new fruit fly optimization algorithm: Taking the financial distress model as an example. Knowl. Based Syst. 2012, 26, 69–74. [Google Scholar] [CrossRef]
- Darvish, A.; Ebrahimzadeh, A. Improved fruit-fly optimization algorithm and its applications in antenna arrays synthesis. IEEE Trans. Antennas Propag. 2018, 66, 1756–1766. [Google Scholar] [CrossRef]
- Cong, Y.; Wang, J.; Li, X. Traffic flow forecasting by a least squares support vector machine with a fruit fly optimization algorithm. Procedia Eng. 2016, 137, 59–68. [Google Scholar] [CrossRef]
- Lin, S.M. Analysis of service satisfaction in web auction logistics service using a combination of fruit fly optimization algorithm and general regression neural network. Neural Comput. Appl. 2013, 22, 783–791. [Google Scholar] [CrossRef]
- Meng, T.; Pan, Q.K. An improved fruit fly optimization algorithm for solving the multidimensional knapsack problem. Appl. Soft Comput. 2017, 50, 79–93. [Google Scholar] [CrossRef]
- Zheng, X.L.; Wang, L.; Wang, S.Y. A novel fruit fly optimization algorithm for the semiconductor final testing scheduling problem. Knowl. Based Syst. 2014, 57, 95–103. [Google Scholar] [CrossRef]
- Zheng, X.; Wang, L. A knowledge-guided fruit fly optimization algorithm for dual resource constrained flexible job-shop scheduling problem. Int. J. Prod. Res. 2018, 54, 1–13. [Google Scholar] [CrossRef]
- Li, J.Q.; Pan, Q.K.; Mao, K. A hybrid fruit fly optimization algorithm for the realistic hybrid flowshop rescheduling problem in steelmaking systems. IEEE Trans. Autom. Sci. Eng. 2016, 13, 932–949. [Google Scholar] [CrossRef]
- Deng, G.L.; Yu, H.Y.; Zheng, S.M. An enhanced discrete artificial bee colony algorithm to minimize the total flow time in permutation flowshop scheduling with limited buffers. Math. Probl. Eng. 2016, 2016, 1–11. [Google Scholar] [CrossRef]
- Holm, S. A simple sequentially rejective multiple test procedure. Scand. J. Stat. 1979, 6, 65–70. [Google Scholar] [CrossRef]












{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| F | ARPD | Running Time | ||||
|---|---|---|---|---|---|---|
| DNRM | NEH2 | DNPM | DNRM | NEH2 | DNPM | |
| 2 | 20.85 | 14.38 | 12.05 | 0.003 | 0.003 | 0.003 |
| 3 | 21.47 | 15.9 | 13.59 | 0.004 | 0.004 | 0.004 |
| 4 | 22.93 | 16.19 | 14.25 | 0.006 | 0.006 | 0.006 |
| 5 | 23.49 | 17.67 | 15.2 | 0.009 | 0.009 | 0.009 |
| 6 | 22.5 | 16.32 | 14.47 | 0.010 | 0.010 | 0.010 |
| 7 | 23.24 | 15.81 | 13.728 | 0.011 | 0.011 | 0.011 |
| Ave. | 22.41 | 15.87 | 13.86 | 0.0072 | 0.0072 | 0.0072 |
| F | LS_ins | LS_sw | NLS | LS_V | ||||
|---|---|---|---|---|---|---|---|---|
| ARPD | SD | ARPD | SD | ARPD | SD | ARPD | SD | |
| 2 | 1.612 | 1.352 | 1.454 | 1.034 | 2.241 | 1.827 | 0.939 | 0.684 |
| 3 | 1.538 | 1.348 | 1.292 | 1.168 | 2.238 | 1.758 | 0.823 | 0.732 |
| 4 | 1.529 | 1.361 | 1.258 | 1.138 | 2.097 | 1.732 | 0.786 | 0.743 |
| 5 | 1.464 | 1.308 | 1.281 | 1.102 | 2.116 | 1.962 | 0.807 | 0.618 |
| 6 | 1.492 | 1.292 | 1.349 | 1.106 | 2.182 | 1.814 | 0.881 | 0.757 |
| 7 | 1.473 | 1.315 | 1.178 | 1.048 | 2.052 | 2.095 | 0.844 | 0.704 |
| Ave. | 1.518 | 1.329 | 1.302 | 1.136 | 2.154 | 1.865 | 0.847 | 0.706 |
| Instance (F × n) | LPT2 | SPT2 | Johnson2 | NEH2 | VND(a) | DFOA |
|---|---|---|---|---|---|---|
| 2 × 4 | 8.326 | 3.919 | 5.368 | 0.586 | 0.000 | 0.000 |
| 2 × 6 | 15.831 | 4.424 | 10.172 | 1.923 | 1.53 | 0.000 |
| 2 × 8 | 20.485 | 7.342 | 12.279 | 3.761 | 2.764 | 0.000 |
| 2 × 10 | 23.855 | 12.279 | 16.024 | 5.681 | 3.573 | 0.000 |
| 2 × 12 | 28.747 | 15.486 | 14.325 | 5.508 | 3.112 | 0.000 |
| 2 × 14 | 31.639 | 20.367 | 19.895 | 6.544 | 3.433 | 0.000 |
| 2 × 16 | 32.095 | 18.997 | 17.351 | 6.225 | 3.771 | 0.000 |
| 3 × 4 | 6.472 | 4.786 | 5.288 | 0.353 | 0.000 | 0.000 |
| 3 × 6 | 20.533 | 9.528 | 10.648 | 2.371 | 1.269 | 0.000 |
| 3 × 8 | 21.684 | 12.235 | 15.247 | 3.813 | 2.673 | 0.000 |
| 3 × 10 | 28.729 | 15.687 | 17.542 | 5.279 | 4.082 | 0.000 |
| 3 × 12 | 29.754 | 19.376 | 19.556 | 6.852 | 4.565 | 0.000 |
| 3 × 14 | 28.652 | 18.453 | 21.455 | 6.034 | 5.263 | 0.000 |
| 3 × 16 | 30.213 | 18.674 | 20.859 | 5.511 | 4.736 | 0.000 |
| 4 × 4 | 0.000 | 0.000 | 0.000 | 0.000 | 0.000 | 0.000 |
| 4 × 6 | 10.538 | 11.789 | 12.523 | 0.418 | 0.000 | 0.000 |
| 4 × 8 | 13.277 | 13.894 | 14.267 | 1.278 | 0.879 | 0.000 |
| 4 × 10 | 15.541 | 16.452 | 17.385 | 3.923 | 2.598 | 0.000 |
| 4 × 12 | 20.067 | 20.155 | 21.716 | 5.536 | 4.677 | 0.000 |
| 4 × 14 | 25.244 | 23.483 | 25.006 | 6.893 | 5.343 | 0.000 |
| 4 × 16 | 29.875 | 25.276 | 27.233 | 7.282 | 5.816 | 0.000 |
| Ave. | 21.027 | 13.933 | 15.435 | 4.084 | 2.8611 | 0.000 |
| F | LPT2 | SPT2 | Johnson2 | NEH2 | VND(a) | DFOA |
|---|---|---|---|---|---|---|
| 2 | 0.00151 | 0.00151 | 0.00151 | 0.00151 | 0.0174 | 53.14 |
| 3 | 0.00149 | 0.00149 | 0.00149 | 0.00149 | 0.0126 | 52.08 |
| 4 | 0.00148 | 0.00148 | 0.00148 | 0.00148 | 0.0085 | 49.59 |
| Ave. | 0.00149 | 0.00149 | 0.00149 | 0.00149 | 0.0128 | 51.6 |
| Algorithms | Year | Parameter Setting |
|---|---|---|
| EM [24] | 2010 | |
| HGA [25] | 2011 | |
| TS [26] | 2013 | |
| DDE [34] | 2018 |
| Instance | EM | HGA | TS | DDE | DFOA | |
|---|---|---|---|---|---|---|
| 2 | 4.682 | 3.272 | 2.701 | 1.688 | 1.024 | |
| 3 | 5.047 | 3.443 | 2.889 | 1.852 | 1.084 | |
| 4 | 5.231 | 3.361 | 3.146 | 1.578 | 0.865 | |
| F | 5 | 5.378 | 3.434 | 3.048 | 1.543 | 1.011 |
| 6 | 4.864. | 3.002 | 2.997 | 1.433 | 0.848 | |
| 7 | 4.597 | 2.703 | 2.356 | 1.271 | 0.595 | |
| 20 | 4.365 | 2.783 | 2.384 | 1.355 | 0.798 | |
| 50 | 4.702 | 2.908 | 2.722 | 1.524 | 0.806 | |
| n | 100 | 4.808 | 3.172 | 2.968 | 1.539 | 0.857 |
| 200 | 5.146 | 3.429 | 3.095 | 1.618 | 1.087 | |
| 500 | 5.698 | 3.812 | 3.371 | 1.642 | 1.031 | |
| 5 | 5.472 | 3.557 | 3.335 | 1.829 | 1.114 | |
| m | 10 | 4.966 | 3.038 | 2.899 | 1.447 | 0.896 |
| 20 | 4.708 | 2.917 | 2.578 | 1.366 | 0.707 | |
| Ave. | 4.985 | 3.202 | 2.901 | 1.548 | 0.91 |
| H0 | p-Value | Hi | |
|---|---|---|---|
| DFOA = EM | 0 | 0.0095 | Reject |
| DFOA = HGA | 0 | 0.0184 | Reject |
| DFOA = TS | 0 | 0.0236 | Reject |
| DFOA = DDE | 0 | 0.3971 | Reject |
© 2019 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zhang, X.; Liu, X.; Tang, S.; Królczyk, G.; Li, Z. Solving Scheduling Problem in a Distributed Manufacturing System Using a Discrete Fruit Fly Optimization Algorithm. Energies 2019, 12, 3260. https://doi.org/10.3390/en12173260
Zhang X, Liu X, Tang S, Królczyk G, Li Z. Solving Scheduling Problem in a Distributed Manufacturing System Using a Discrete Fruit Fly Optimization Algorithm. Energies. 2019; 12(17):3260. https://doi.org/10.3390/en12173260
Chicago/Turabian StyleZhang, Xiaohui, Xinhua Liu, Shufeng Tang, Grzegorz Królczyk, and Zhixiong Li. 2019. "Solving Scheduling Problem in a Distributed Manufacturing System Using a Discrete Fruit Fly Optimization Algorithm" Energies 12, no. 17: 3260. https://doi.org/10.3390/en12173260
APA StyleZhang, X., Liu, X., Tang, S., Królczyk, G., & Li, Z. (2019). Solving Scheduling Problem in a Distributed Manufacturing System Using a Discrete Fruit Fly Optimization Algorithm. Energies, 12(17), 3260. https://doi.org/10.3390/en12173260