Flexibility-Based Energy and Demand Management in Data Centers: A Case Study for Cloud Computing


Abstract
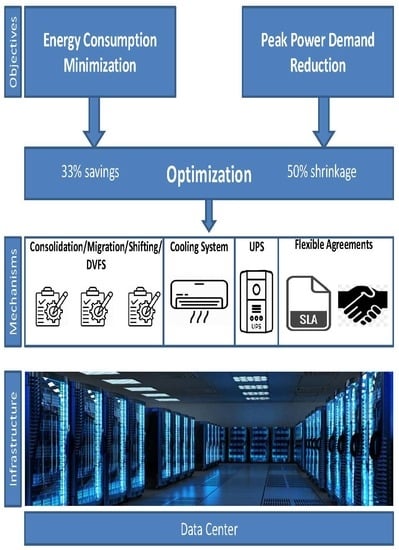
:
1. Introduction
- With flexibility being the key enabler of demand and energy management, which mechanisms provide flexibilities in a data center and how those can be exploited?
- What are the required fundamental changes needed to realize such types of management?
- Which architectural building blocks are necessary for the implementation of intelligent demand and energy management systems?
- Identify the most relevant flexibility providing mechanisms in a data center and specify each ones’ reaction time as well as the required IoT infrastructure.
- Describe the architectural building blocks for two different management systems: minimization of overall energy consumption (energy-efficiency) and reduction/increase of power demand (demand-response and demand-side management). The adopted modular description makes it easier to understand the complex processes that are involved.
- Demonstrate the need for flexible service level (SLA) together with supply-demand agreements (SDA) to achieve demand-side management. The proposed agreements not only take into account power reduction but also the case for demand increase (e.g., excess of power from renewables). The presented case of federating several data centers showed additional optimization possibilities.
- The experiments that are carried out show that the underlying concepts can be realized in real-life configurations in such a way that the findings provide “best practices” and insights to data center operators who are willing to achieve energy optimization and demand-side management.
2. Flexibility Mechanisms in Data Centers
2.1. Workload
2.1.1. Consolidation
2.1.2. Shifting
2.1.3. Migration
2.1.4. Frequency Scaling
2.2. Cooling System
2.3. Uninterrupted Power Supply
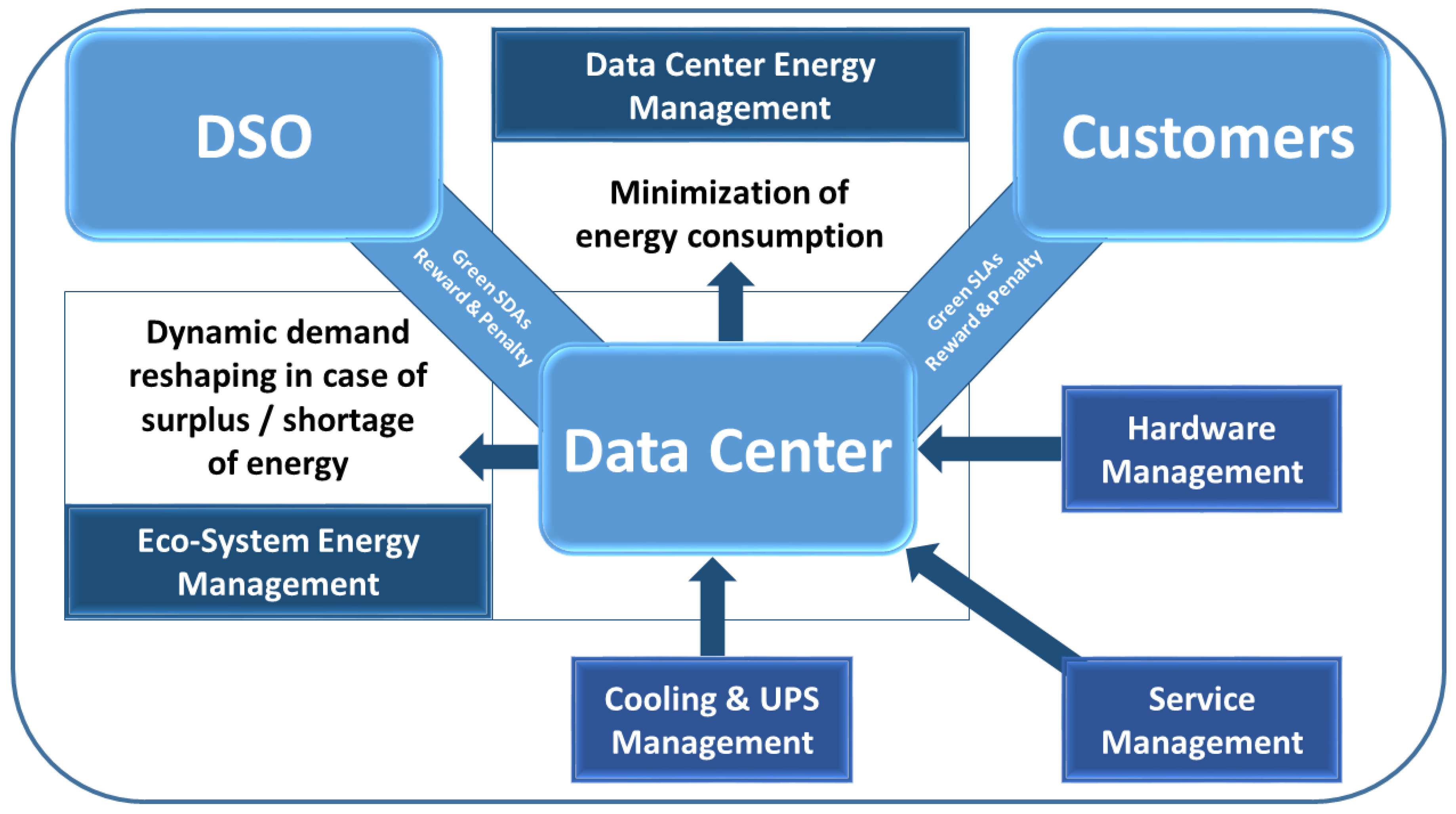
3. Flexible Contracts
3.1. Green Service Level Agreement
3.2. Green Supply-Demand Agreement
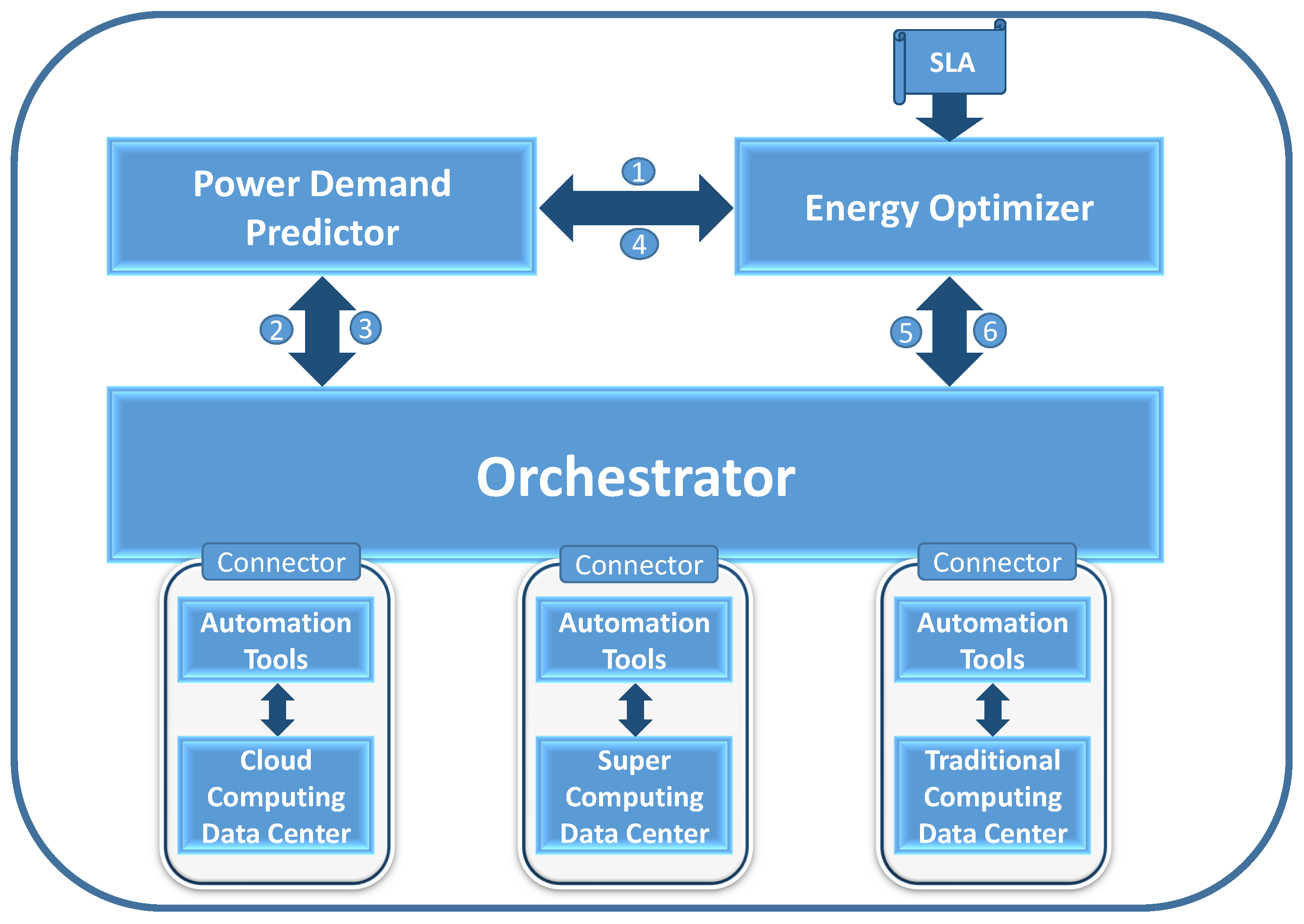
4. Energy and Demand Management in Data Centers
- Minimization of the overall energy consumption of data centers,
- Reduction of peak power demand necessary for the participation in demand-response schemes, thus achieving demand-side management.
4.1. Energy Consumption Minimization
4.1.1. Problem Statement
4.1.2. Methodology
- Given a set of ICT equipment (e.g., servers) each having its properties in terms of energy-efficiency,
- Given a set of services (e.g., applications) running on different ICT resources where each such service has its own quality related requirements determined by SLAs.
- Consolidate as many services as possible onto minimal number of resources so that no SLA is breached. Also, in choosing those resources, the priority is given to most energy-efficient ones.
- Shutdown unused or idle resources to save energy consumption.
4.1.3. Metrics
4.2. Peak Power Demand Reduction
4.2.1. Problem Statement
4.2.2. Methodology
4.2.3. Metrics
5. Evaluation
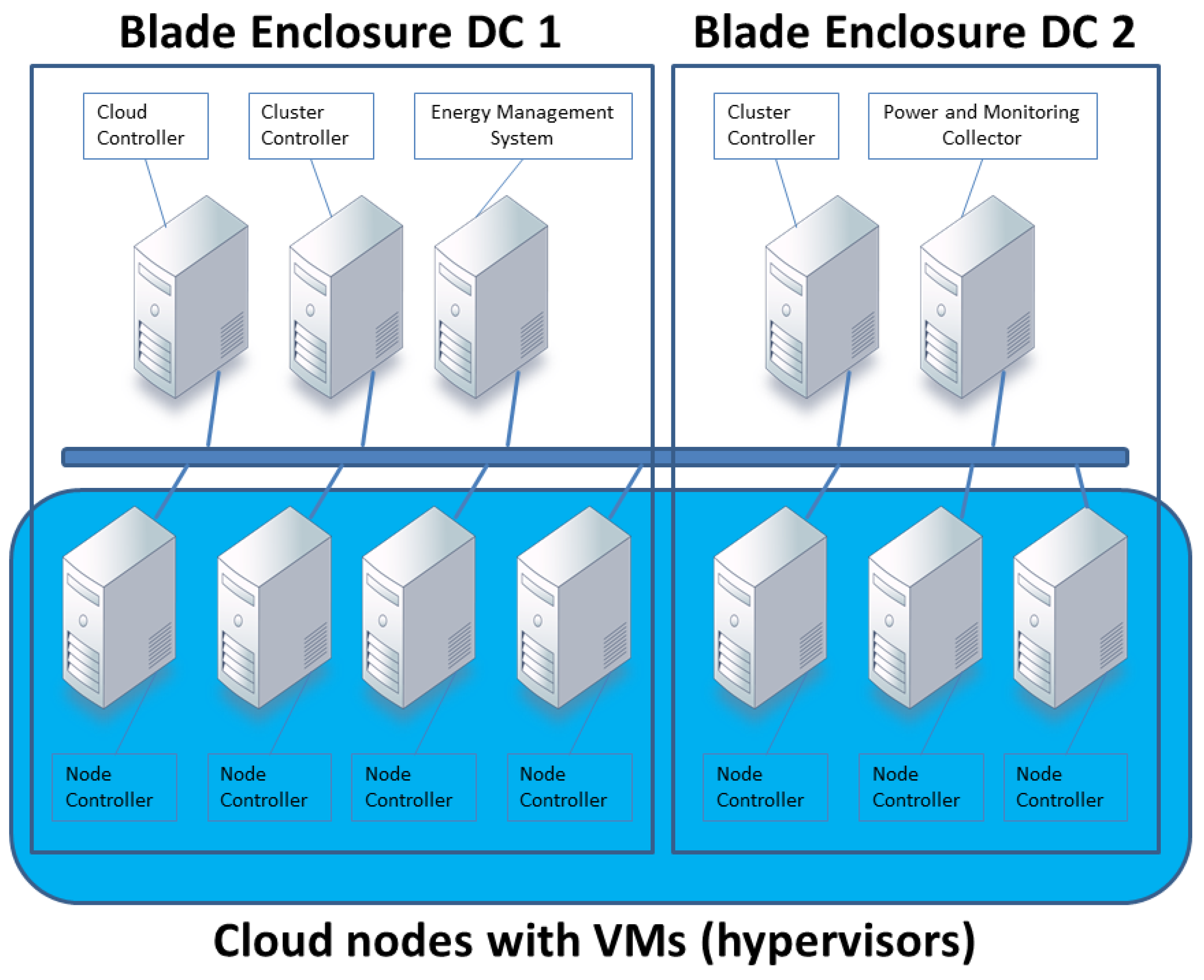
5.1. Setup Environment and Configuration
5.1.1. Hardware Configuration
5.1.2. Software Configuration
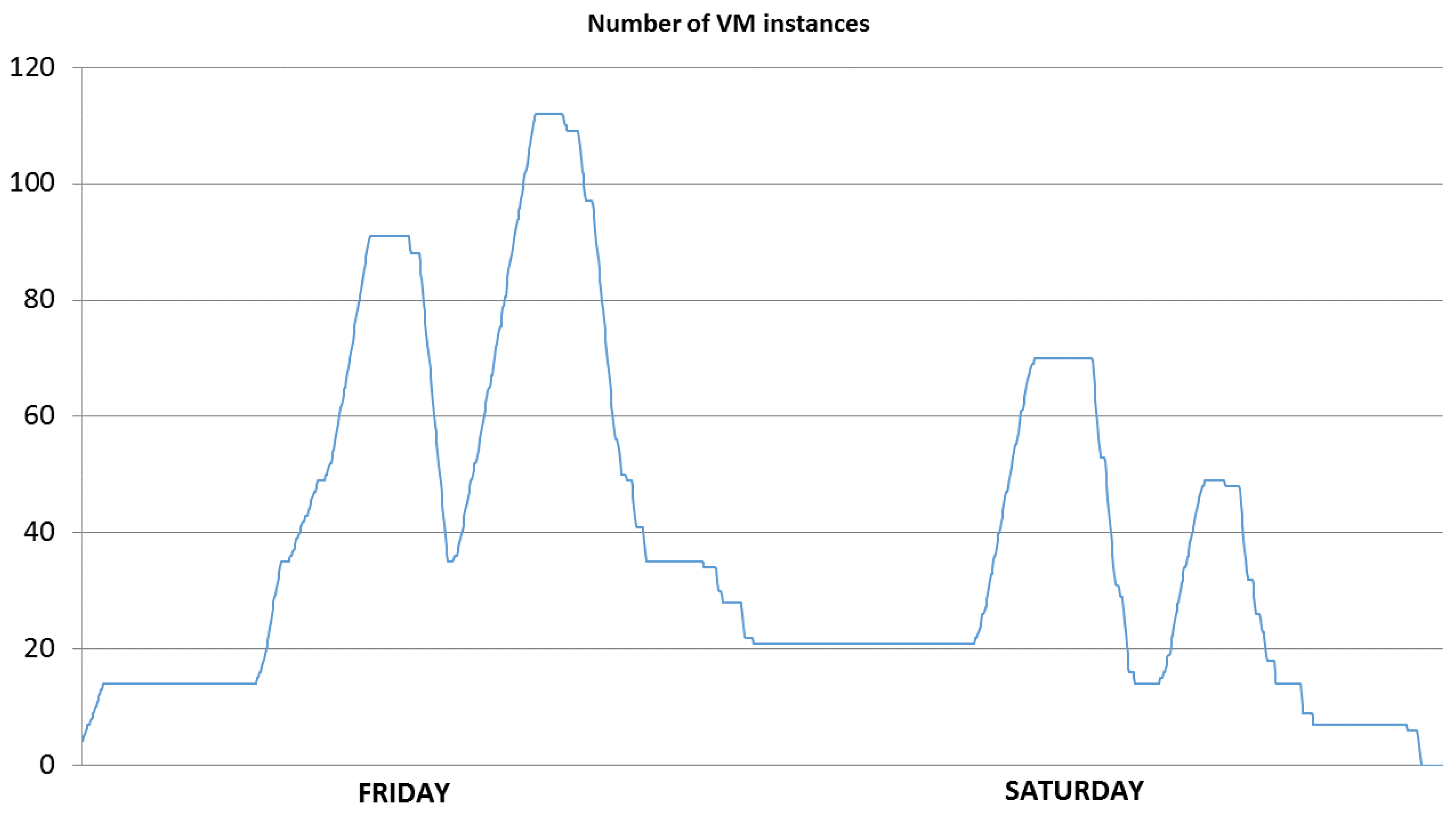
5.2. Workload Description
5.3. Results
5.3.1. Energy Consumption Minimization
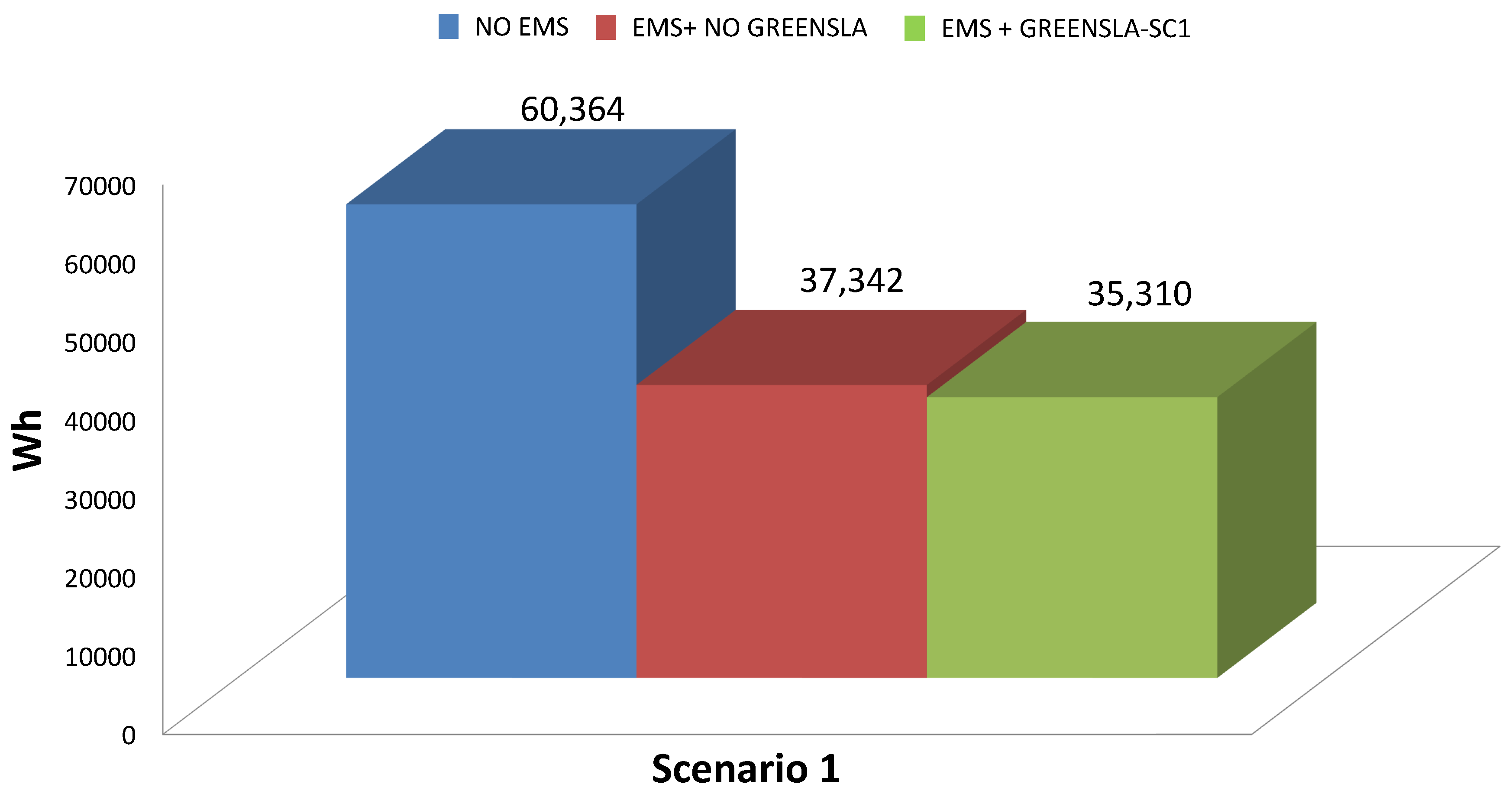
Single Site Use Case
- No energy management.
- EMS is enabled where nodes can be turned on/off together with internode migration of virtual machines.
Federated Site Use Case
- No energy management.
- EMS is enabled where optimization takes into account turning on/off nodes, internode migration of virtual machines as well as migration of virtual machines to the most energy-efficient data center using its PUE.
5.3.2. Peak Power Demand Reduction
- The temperature set-point ranges were kept within those of ASHRAE recommendation for ICT equipment.
- The considered workload of Section 5.2 was executed according to its Green SLA. SLA manager was used to validate the correctness of the implemented SLAs. This manager reported no SLA breaching, thus guaranteeing customers’ comfort and satisfaction.
- High: 100% guaranteed performance during weekdays between 9:00 AM and 8:00 PM. Note that performance is measured as percentage of ECU (Amazon WS EC2 Compute Unit) where 1 ECU is the equivalent CPU capacity of a 1.0–1.2 GHz 2007 Opteron or 2007 Xeon processor.
- Medium: 80% of performance during weekdays between 12:00 AM and 9:00 AM and 8:00 PM and 12:00 AM.
- During weekends, the performance is Medium.
Baseline Scenario
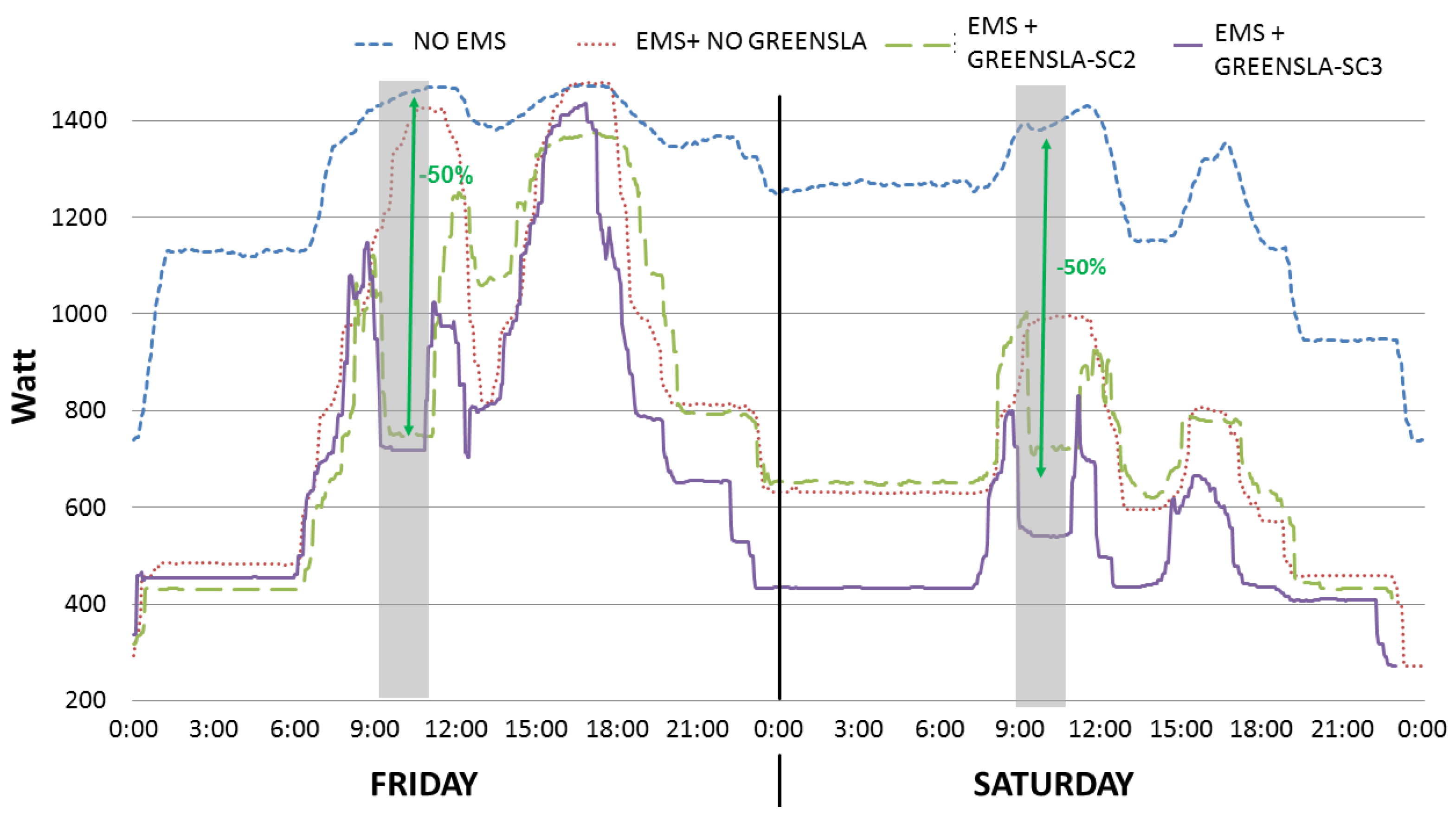
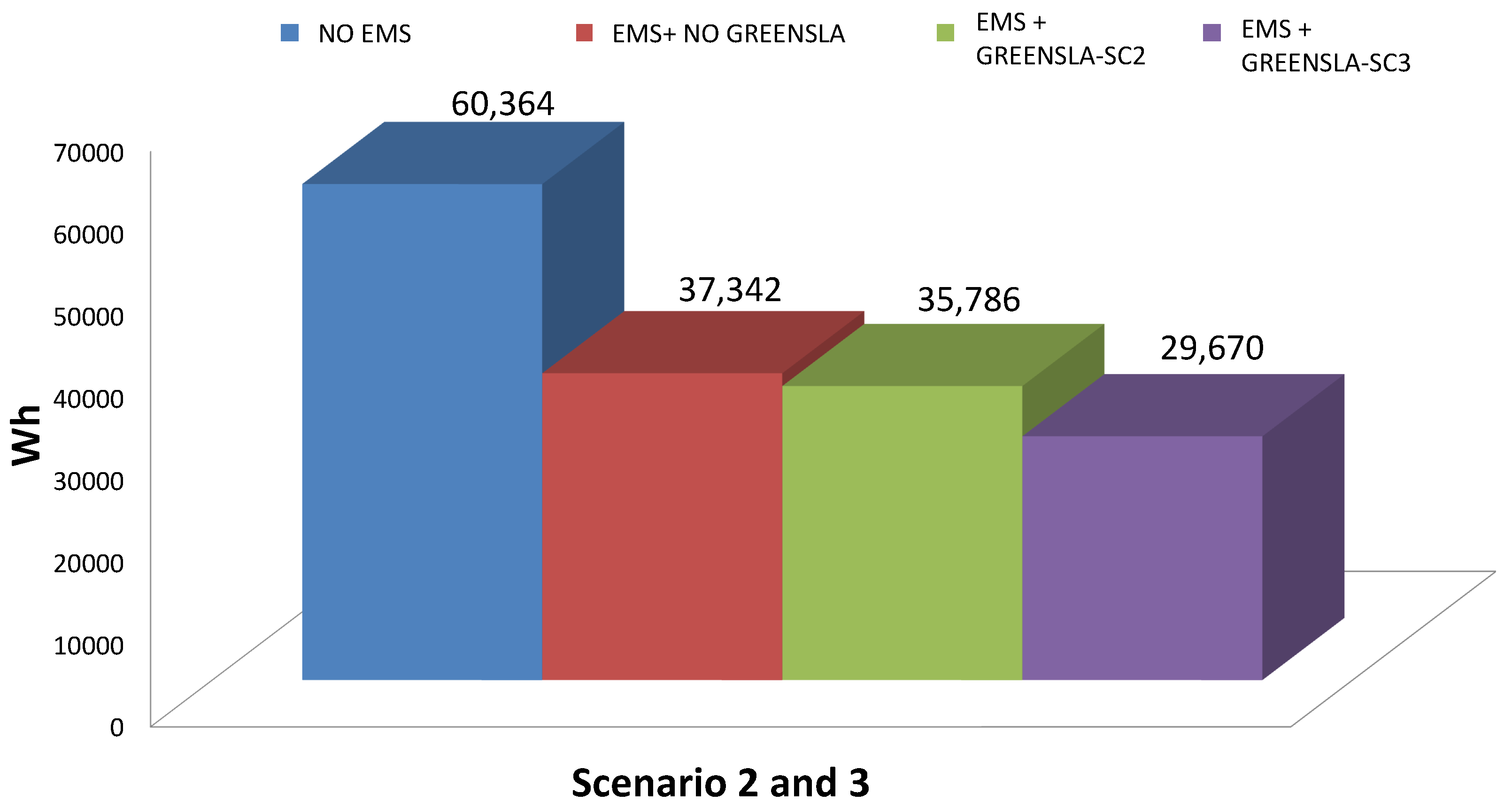
Demand-Response with and without Federation Scenarios
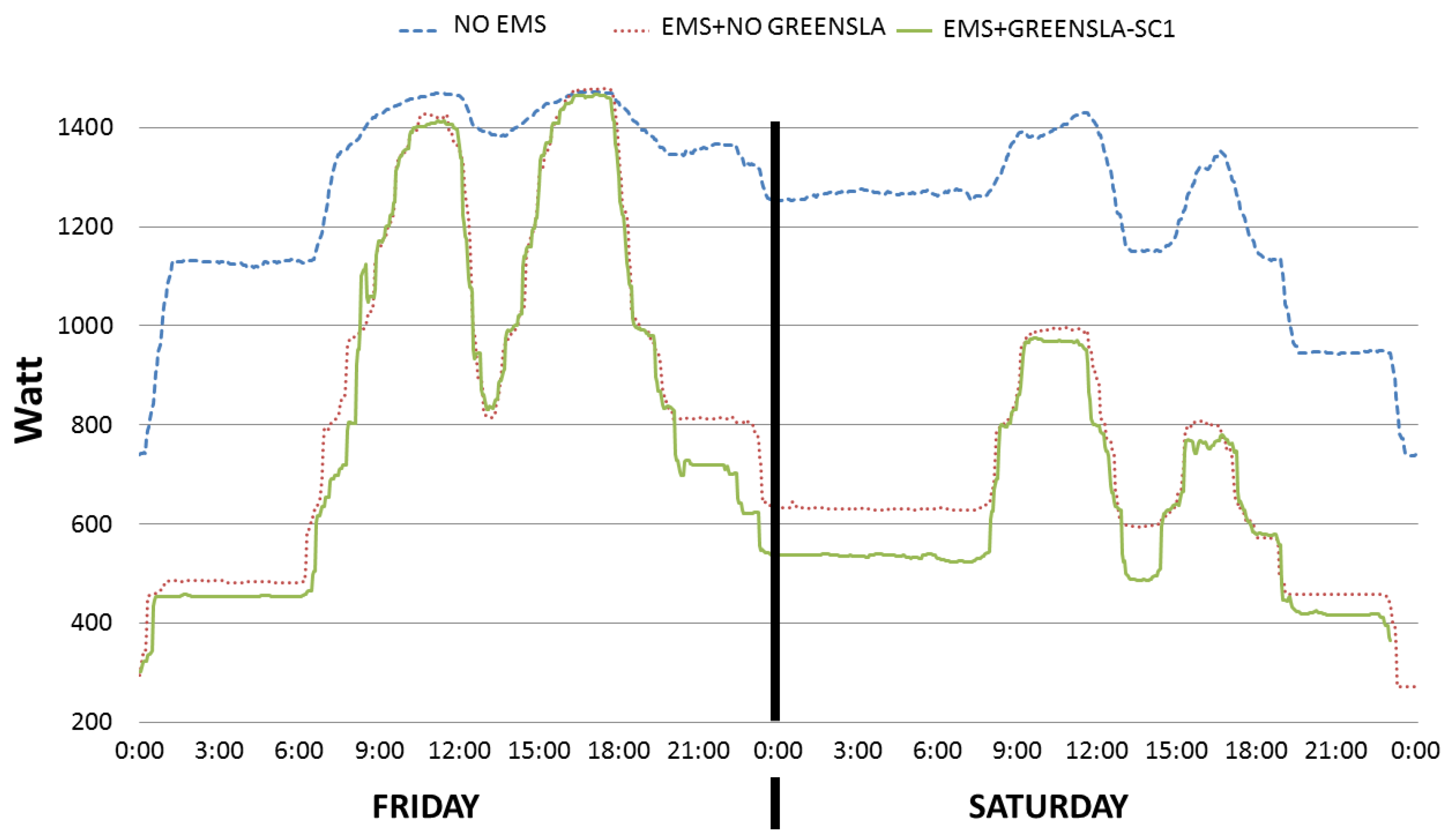
- Because of flexible Green SLAs, there was a reduction of 50% in power demand (see the green arrow line) during the demand-response period (e.g., between 9:30 AM and 11:30 AM on Friday and Saturday), compared to the rigid SLAs.
- In the nonfederated configuration (green long dashed line EMS+GREENSLA-SC2), due to the launching of delayed virtual machines together with the ordinary workload, there was a noticeable peak power demand after the end (e.g., at ~12 PM on Friday and Saturday) of the demand-response period.
- In the federated configuration (purple line EMS+GREENSLA-SC3), no peak demand is occurring after the end (e.g., around 12 PM on Friday and Saturday) of the demand-response period, as was the case for the nonfederated configuration, simply because the virtual machines were allocated to a different (federated) data center.
- On Friday between 4 PM and 6 PM, the peak demand of 1450 Watt was not reduced when EMS was considered (e.g., red, green, and purple lines). This is due to the fact that during that period the data center exhibited the highest workload in terms of instances of VMs (see Figure 4). Consequently, no consolidation and turning off idle machines were possible, which hindered any further optimization with respect to the case when no EMS (e.g., blue line) was considered. Note however that the peak demands for the last two cases (green long dashed line EMS+GREENSLA-SC2 and purple line EMS+GREENSLA-SC3) during the aforementioned period are lower than the ones of first two cases (NO EMS and EMS+NO GREENSLA) due to the shifting of workload happened after the end of the demand-response period (e.g., between 12 PM and 2 PM on Friday and Saturday).
6. Conclusions
Funding
Acknowledgments
Conflicts of Interest
Abbreviations
| ASHRAE | American Society for Heating and Air Conditioning Engineers |
| CPU | Central Processing Unit |
| DC | Data Center |
| DCiE | Data Center infrastructure Efficiency |
| DVFS | Dynamic Voltage and Frequency Scaling |
| DSO | Distribution System Operator |
| EMS | Energy Management System |
| GEC | Green Energy Coefficient |
| Green SLA | Green Service Level Agreement |
| Green SDA | Green Supply-Demand Agreement |
| GPUE | Green PUE |
| HPE | Hewlett Packard Enterprise |
| ICT | Information and Communication Technologies |
| IoT | Internet of Things |
| Opex | Operational expenditure |
| OpenADR | Open Automated Demand Response |
| OS | Operating System |
| PUE | Power Usage Effectiveness |
| SLA | Service Level Agreement |
| TCO | Total Cost of Ownership |
| UPS | Uninterrupted Power Supply |
References
- Katz, R.H. Tech titans building boom. IEEE Spectr. 2009, 46, 40–54. [Google Scholar] [CrossRef]
- Jones, N. How to stop data centres from gobbling up the world’s electricity. Nature 2018, 561, 163. [Google Scholar] [CrossRef] [PubMed]
- GeSI. SMART 2020: Enabling the Low Carbon Economy in the Low Carbon Economy in the Information Age; Technical Report; The Climate Group: London, UK, 2008. [Google Scholar]
- Andrae, A.S.G.; Edler, T. On global electricity usage of communication technology: Trends to 2030. Challenges 2015, 6, 117–157. [Google Scholar] [CrossRef]
- ATAG. Air Transport Action Group (ATAG): Facts and Figures, 2018; ATAG: Dunfermline, UK, 2018. [Google Scholar]
- Lima, J.M. Data Centres Of The World Will Consume 1/5 Of Earth’s Power By 2025; Technical report, online article for Data Economy; Euromoney Institutional Investor PLC.: London, UK, 2017. [Google Scholar]
- Bittner, J. Data Center Location Considerations (Principles and Resources); Technical report; Exit Technologies: Naples, FL, USA, 2018. [Google Scholar]
- Hansen, K.; Mathiesen, B.V.; Skov, I.R. Full energy system transition towards 100% renewable energy in Germany in 2050. Renew. Sustain. Energy Rev. 2019, 102, 1–13. [Google Scholar] [CrossRef]
- Gellings, C.; Chamberlin, J.H. Demand-Side Management: Concepts and Methods; PennWell Books: Tulsa, OK, USA, 1987. [Google Scholar]
- OpenADR Alliance. OpenADR 2.0 Profile Specification B Profile; Technical report; OpenADR Alliance: San Ramon, CA, USA, 2013. [Google Scholar]
- Federal Energy Regulatory Commission. Assessment of Demand Response and Advanced Metering; Technical report; Federal Energy Regulatory Commission: Washington, DC, USA, 2013. [Google Scholar]
- Ghatikar, G.; Ganti, V.; Matson, N.; Piette, M.A. Demand Response Opportunities and Enabling Technologies for Data Centers: Findings from Field Studies; Technical report; Lawrence Berkeley National Laboratory: Berkeley, CA, USA, 2012. [Google Scholar]
- Ghatikar, G.; Piette, M.A.; Fujita, S.; McKane, A.; Dudley, J.H.; Radspieler, A. Demand Response and Open Automated Demand Response Opportunities for Data Centers; Technical report; Lawrence Berkeley National Laboratory: Berkeley, CA, USA, 2010. [Google Scholar]
- Basmadjian, R.; Botero, J.F.; Giuliani, G.; Hesselbach, X.; Klingert, S.; de Meer, H. Making Data Centres Fit for Demand Response: Introducing GreenSDA and GreenSLA Contracts. IEEE Trans. Smart Grid 2018, 9, 3453–3464. [Google Scholar] [CrossRef]
- Barroso, L.A.; Clidaras, J.; Hoelzle, U. The Datacenter as a Computer: An Introduction to the Design of Warehouse-Scale Machines; Morgan & Claypool: San Rafael, CA, USA, 2013; Chapter 6; p. 96. [Google Scholar]
- Alboaneen, D.A.; Pranggono, B.; Tianfield, H. Energy-aware virtual machine consolidation for cloud data centers. In Proceedings of the 2014 IEEE/ACM 7th International Conference on Utility and Cloud Computing; IEEE Computer Society: Washington, DC, USA, 2014; pp. 1010–1015. [Google Scholar] [CrossRef]
- Khani, H.; Latifi, A.; Yazdani, N.; Mohammadi, S. Distributed consolidation of virtual machines for power efficiency in heterogeneous cloud data centers. Comput. Electr. Eng. 2015, 47, 173–185. [Google Scholar] [CrossRef]
- Basmadjian, R.; Niedermeier, F.; de Meer, H. Modelling and analysing the power consumption of idle servers. In Proceedings of the 2012 Sustainable Internet and ICT for Sustainability (SustainIT), Pisa, Italy, 4–5 October 2012. [Google Scholar]
- Habib, I. Virtualization with KVM. Linux J. 2008, 2008, 8. [Google Scholar]
- Barham, P.; Dragovic, B.; Fraser, K.; Hand, S.; Harris, T.; Ho, A.; Neugebauer, R.; Pratt, I.; Warfield, A. Xen and the art of virtualization. SIGOPS Oper. Syst. Rev. 2003, 37, 164–177. [Google Scholar] [CrossRef]
- Clark, C.; Fraser, K.; Hand, S.; Hansen, J.G.; Jul, E.; Limpach, C.; Pratt, I.; Warfield, A. Live migration of virtual machines. In Proceedings of the 2nd Conference on Symposium on Networked Systems Design & Implementation—Volume 2; USENIX Association: Berkeley, CA, USA, 2005; pp. 273–286. [Google Scholar]
- Snowdon, D.; Ruocco, S.; Heiser, G. Power management and dynamic voltage scaling: Myths and facts. In Proceedings of the 2005 Workshop on Power Aware Real-Time Computing, Jersey, NJ, USA, 18–22 September 2005. [Google Scholar]
- Basmadjian, R.; Niedermeier, F.; de Meer, H. Modelling performance and power consumption of utilisation-based DVFS using M/M/1 queues. In Proceedings of the ACM Seventh International Conference on Future Energy Systems of e-Energy, Waterloo, ON, Canada, 21–24 June 2016; pp. 14:1–14:11. [Google Scholar]
- Basmadjian, R.; de Meer, H. Modelling and analysing conservative governor of DVFS-enabled processors. In Proceedings of the Ninth International Conference on Future Energy Systems; ACM: New York, NY, USA, 2018; pp. 519–525. [Google Scholar] [CrossRef]
- Meijer, G. Cooling energy-hungry data centers. Science 2010, 328, 318–319. [Google Scholar] [CrossRef] [PubMed]
- Evans, T. The Different Types of Air Conditioning Equipment for IT Environments; American Power Conversion: South Kingstown, RI, USA, 2004. [Google Scholar]
- Pore, M.; Abbas, Z.; Gupta, S.K.S.; Varsamopoulos, G. Techniques to achieve energy proportionality in data centers: A survey. In Handbook on Data Centers; Springer: Berlin, Germany, 2015; pp. 109–162. [Google Scholar]
- Patterson, M.K.; Fenwick, D. The State of Data Center Cooling: A Review of Current Air and Liquid Cooling Solutions; Intel Corporation: Santa Clara, CA, USA, 2008. [Google Scholar]
- Li, L.; Zheng, W.; Wang, X.; Wan, X. Coordinating liquid and free air cooling with workload allocation for data center power minimization. In Proceedings of the 11th International Conference on Autonomic Computing, Philadelphia, PA, USA, 18–20 June 2014. [Google Scholar]
- Kuusisto, O. Thermal Guidelines for data Processing Environments—Expanded Datacenter Classes and Usage Guidance; ASHRAE: Atlanta, GA, USA, 2011. [Google Scholar]
- Basmadjian, R.; Ghiassi-Farrokhfal, Y.; Vishwanath, A. Hidden storage in data centers: Gaining flexibility through cooling systems. In International Conference on Measurement, Modelling and Evaluation of Computing Systems; Springer: Berlin, Germany, 2018; pp. 68–82. [Google Scholar]
- Rincón, D.; Agustí-Torra, A.; Botero, J.F.; Raspall, F.; Remondo, D.; Hesselbach, X.; Beck, M.T.; de Meer, H.; Niedermeier, F.; Giovanni, G. A novel collaboration paradigm for reducing energy consumption and carbon dioxide emissions in data centres. Comput. J. 2013, 56, 1518–1536. [Google Scholar] [CrossRef]
- Basmadjian, R.; Niedermeier, F.; Lovasz, G.; Meer, H.D.; Klingert, S. GreenSDAs leveraging power adaption collaboration between energy provider and data centres. In Proceedings of the 3rd IFIP Conference on Sustainable Internet and ICT for Sustainability (SustainIT 2013), Palermo, Italy, 30–31 October 2013. [Google Scholar]
- Dupont, C.; Hermenier, F.; Schulze, T.; Basmadjian, R.; Somov, A.; Giuliani, G. Plug4Green: A flexible energy-aware VM manager to fit data centre particularities. Ad Hoc Netw. 2015, 25, 505–519. [Google Scholar] [CrossRef]
- Basmadjian, R.; Ali, N.; Niedermeier, F.; de Meer, H.; Giuliani, G. A methodology to predict the power consumption of servers in data centres. In Proceedings of the 2nd International Conference on Energy-Efficient Computing and Networking; ACM: New York, NY, USA, 2011; pp. 1–10. [Google Scholar] [CrossRef]
- Janacek, S.; Nebel, W. Expansion of data centers’ energetic cegrees of freedom to employ green energy sources. In Advances and New Trends in Environmental and Energy Informatics; Springer: Berlin, Germany, 2016; pp. 21–38. [Google Scholar]
- Basmadjian, R.; de Meer, H.; Lent, R.; Giuliani, G. Cloud computing and its interest in saving energy: The use case of a private cloud. J. Cloud Comput. Adv. Syst. Appl. 2012, 1, 5. [Google Scholar] [CrossRef]
- Belady, C.; Amd, A.R.; Dell, J.P.; Spraycool, T.C. The Green Grid Data Center Power Efficiency Metrics: Pue and DCiE; Technical report; The Green Grid: Beaverton, OR, USA, 2008. [Google Scholar]
- Piette, M.A.; Girish, G.; Sila, K.; Koch, E.; Hennage, D.; Palensky, P.; McParland, C. Open Automated Demand Response Communications Specification (Version 1.0); Technical report; LBNL: Berkeley, CA, USA, 2009. [Google Scholar]
- Basmadjian, R.; Mueller, L.; de Meer, H. Data centres’ power profile selecting policies for demand response: Insights of green supply-demand agreement. Ad Hoc Netw. Spec. Issue Energy-Aware Data Cent. Archit. Infrastruct. Commun. 2015, 25, 581–594. [Google Scholar] [CrossRef]
- Chowdhury, C.R.; Chatterjee, A.; Sardar, A.; Agarwal, S.; Nath, A. A comprehensive study on cloud green computing: To reduce carbon footprints using clouds. Int. J. Adv. Comput. Res. 2013, 3, 78–84. [Google Scholar]
- Varela, M.; Skorin-Kapov, L.; Ebrahimi, T. Quality of service versus quality of experience. In Quality of Experience: Advanced Concepts, Applications and Methods; Springer: Berlin, Germany, 2014; pp. 85–96. [Google Scholar]
- Kies, A.; Schyska, B.U.; Von Bremen, L. The demand side management potential to balance a highly renewable european power system. Energies 2016, 9, 955. [Google Scholar] [CrossRef]









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Component | Configuration |
|---|---|
| Processor | Quad-core Intel Xeon E5520, 2.26 GHz |
| Memory | 24 GB (6 × 4 GB DIMMs) DDR3 |
| Hard Disk | Two hot plug hard drives 2 × 300 GB |
| Network | Dual-port 10 gigabit Ethernet adapter NC532m |
| Power Rating | 120 W (idle) and 235 W (full load) |
| No EMS | EMS Enabled | |
|---|---|---|
| Measured ICT energy | 11.3 kWh | 8.474 kWh |
| % savings | reference | 25% |
| No EMS | EMS Enabled | |
|---|---|---|
| Measured ICT energy | 21.720 kWh | 14.483 kWh |
| % savings | reference | 33.31% |
| EMS (1.2) | EMS (1.5) | EMS (2.0) | EMS (2.5) | |
|---|---|---|---|---|
| Measured ICT energy | 7.914 kWh | 6.879 kWh | 5.123 kWh | 4.125 kWh |
| % savings | reference | 13.07% | 35.25% | 47.87 % |
© 2019 by the author. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Basmadjian, R. Flexibility-Based Energy and Demand Management in Data Centers: A Case Study for Cloud Computing. Energies 2019, 12, 3301. https://doi.org/10.3390/en12173301
Basmadjian R. Flexibility-Based Energy and Demand Management in Data Centers: A Case Study for Cloud Computing. Energies. 2019; 12(17):3301. https://doi.org/10.3390/en12173301
Chicago/Turabian StyleBasmadjian, Robert. 2019. "Flexibility-Based Energy and Demand Management in Data Centers: A Case Study for Cloud Computing" Energies 12, no. 17: 3301. https://doi.org/10.3390/en12173301
APA StyleBasmadjian, R. (2019). Flexibility-Based Energy and Demand Management in Data Centers: A Case Study for Cloud Computing. Energies, 12(17), 3301. https://doi.org/10.3390/en12173301