Machine Learning-Based Soft Sensors for the Estimation of Laundry Moisture Content in Household Dryer Appliances

 , ,
, ,  , ,
, ,  ,
,  and
and 
Abstract
:
1. Introduction
2. Related Works
- End-of-the-Cycle (EoC)—exploiting the moisture estimation to be more accurate in the automatic determination of the cycle end, i.e., the instant in which the drying should be ideally stopped, as the laundry is perfectly dried (when a predefined laundry moisture target is reached).
- Time-to-End (TTE)—using the SS to estimate precisely how much time is needed for the drying process to reach the moisture target; it is particularly important to estimate the TTE in the first part of the drying cycle to provide an indication of such TTE to the user through the appliance interface.
- The experimental apparatus: Here, we are dealing with domestic tumble dryers, whereas in [22], the study was conducted on industrial continuous dryers. The latter includes more advanced energy-saving features and in general more sophisticated physical sensors. In both cases, the applications are focused on textile fabric drying.
- The general objective: The authors of [22] present a study of the adequate general mathematical model to follow the drying phenomenon. In this work, the focus is also on the procedure adopted for the online estimation of the parameters of the best model selected from data. In both cases, the mathematical expression for the drying phenomenon is the same.
3. Modeling
3.1. Moisture Transfer Modeling by Diffusion
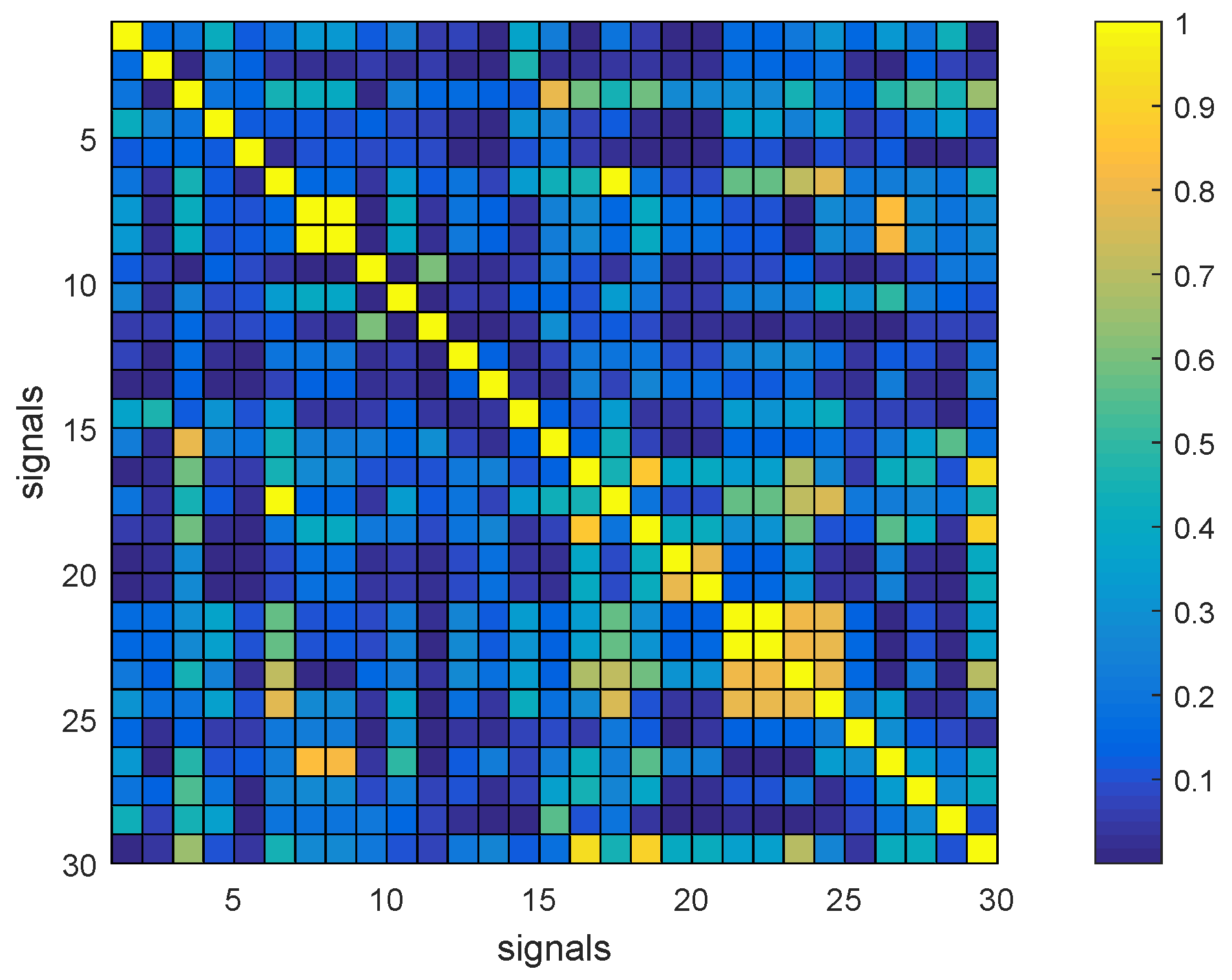
3.2. Data-Driven Methods
- Regularized Linear Regression (Method 1): has been exploited to evaluate the estimation performance using simple linear dependencies between input signals (available online) and output (laundry moisture time series).
- Genetic Programming for Symbolic Regression (Method 2): with the same inputs and output of the previous method, this procedure has been adopted to explore different nonlinear dependencies together with estimation performances.
- Polynomial model for drying cycle prediction (Method 3): the available signals are processed here to obtain features. These features are then used as inputs to estimate the parameters of a model (selected offline), which uses the elapsed time as additional input to determine the laundry moisture. Unlike previous methods, it provides a smooth curve that is more suitable for the two objectives (EoC and TTE) introduced in Section 2.
3.2.1. Method 1: Regularized Linear Regression
3.2.2. Method 2: Genetic Programming for Symbolic Regression
- Crossover: A child program is created from two selected parent programs by combining chosen parts randomly.
- Mutation: A new child program is generated altering a randomly chosen part of a selected parent program.
3.2.3. Method 3: Polynomial Model for Drying Cycle Prediction
4. Experimental Setting
5. Results
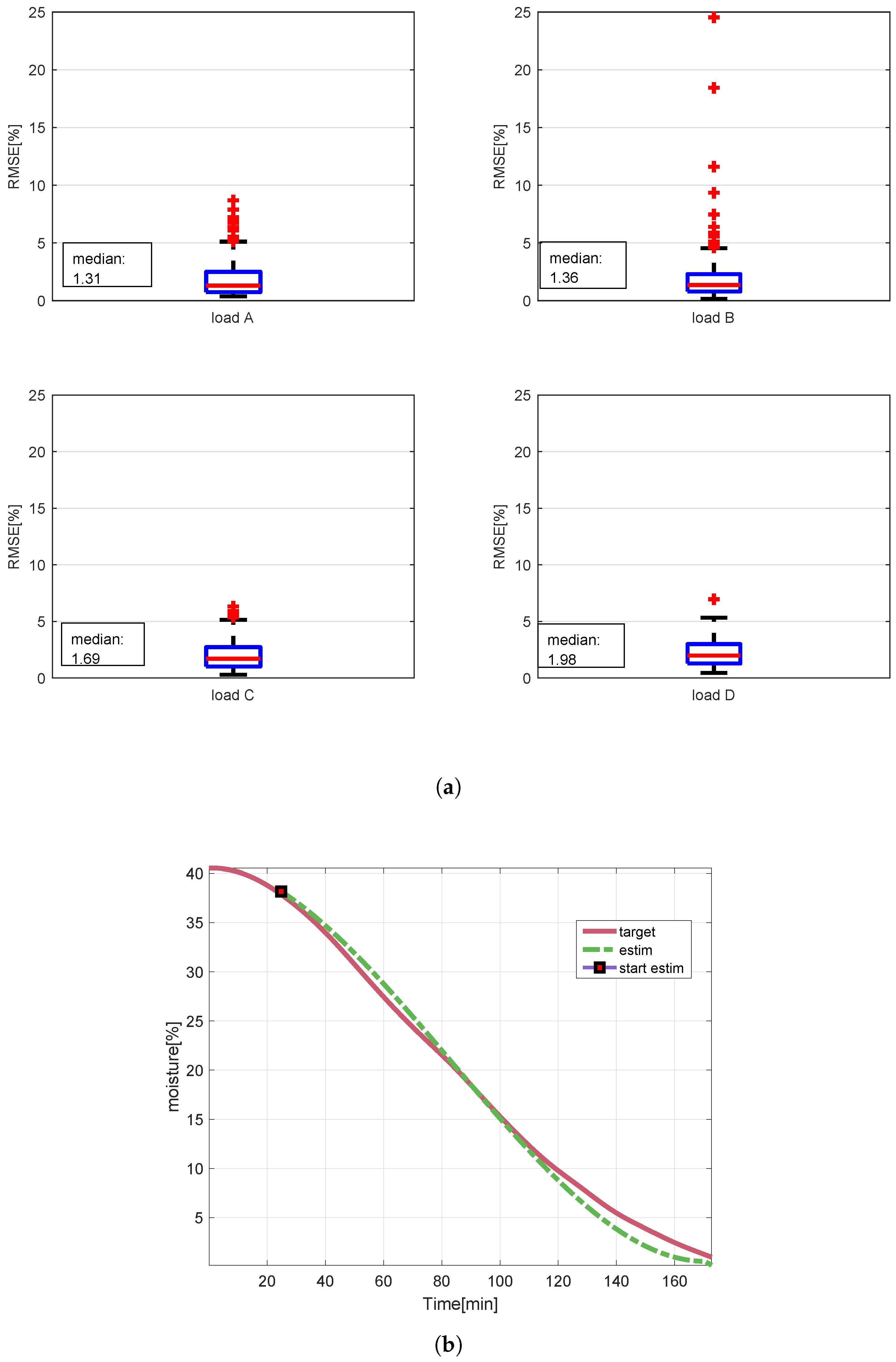
5.1. Method 1: Regularized Linear Regression
- The solution is simple and does not require particular effort for implementation: the use of a linear models makes the solution very easy because the signals used as inputs are already available online on WD HP machines and the information required is restricted to the values of coefficients obtained with offline simulations.
- With a small set of input signals, it is possible to achieve results with a RMSE between and of laundry moisture content, which is not sufficient to satisfy the target required by the industrial partner, but it is interesting result considering the simplicity of the method.
- Using a bigger set of input signals leads to an improvement in terms of performance and it seems to be not possible to obtain moisture estimations with a RMSE under for the EoC using this kind of approach and the set of signals available.
5.2. Method 2: Genetic Programming for Symbolic Regression
5.3. Method 3: Polynomial Model for Drying Cycle Prediction
6. Conclusions
- the use of different approaches to obtain the estimation of laundry moisture content during drying cycles in the domestic washer–dryers, and
- the determination of the best model to provide the estimation of laundry moisture content as a time series obtaining a smooth curve to predict the end-of-the-cycle automatically.
- The best nonlinear models selected by symbolic regression (Method 2) always involve main signals of temperatures and motor torque (or signals that are an elaboration of those), which confirm the result obtained using sparse regularization and linear regression (Method 1), where the structure of the model is fixed and always linear. These types of signals are, therefore, the most useful for the purpose. The models provided by methods 1 an 2 use available signals as predictors, which affect the estimation with their noise.
- The best model for the description of laundry moisture content as a time series is the 3rd-degree polynomial model (7) (Method 3), and it comes from a comparison between several models from Table 1; this is the best model to describe laundry moisture content during the drying cycles based on available real data.
7. Patents
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
Abbreviations
| CV | Cross-Validation |
| DL | Deep Learning |
| DOE | Design of Experiments |
| EoC | End-of-the-Cycle |
| GP | Genetic Programming |
| LASSO | Least Absolute Shrinkage and Selection Operator |
| RMSE | Root-Mean-Square Error |
| RR | Ridge Regression |
| RSS | Residual Sum of Squares |
| SS | Soft-Sensors |
| TTE | Time-to-End |
| WD-HP | Washer Dryer–Heat Pump (technology) |
References
- Shang, C.; Yang, F.; Huang, D.; Lyu, W. Data-driven soft sensor development based on deep learning technique. J. Process Control 2014, 24, 223–233. [Google Scholar] [CrossRef]
- Susto, G.A.; Johnston, A.B.; O’Hara, P.G.; McLoone, S. Virtual metrology enabled early stage prediction for enhanced control of multi-stage fabrication processes. In Proceedings of the IEEE International Conference on Automation Science and Engineering (CASE), Madison, WI, USA, 17–20 August 2013; pp. 201–206. [Google Scholar]
- Trevor, H.; Robert, T.; JH, F. The Elements of Statistical Learning: Data Mining, Inference, and Prediction; Springer: Berlin/Heidelberg, Germany, 2009. [Google Scholar]
- Kadlec, P.; Gabrys, B.; Strandt, S. Data-driven soft sensors in the process industry. Comput. Chem. Eng. 2009, 33, 795–814. [Google Scholar] [CrossRef]
- Soares, S.G. Ensemble Learning Methodologies for Soft Sensor Development in Industrial Processes. Ph.D. Thesis, Coimbra, Portugal, 2015. [Google Scholar]
- Susto, G.A.; Zambonin, G.; Altinier, F.; Pesavento, E.; Beghi, A. A soft sensing approach for clothes load estimation in consumer washing machines. In Proceedings of the IEEE Conference on Control Technology and Applications (CCTA), Copenhagen, Denmark, 21–24 August 2018; pp. 1252–1257. [Google Scholar]
- Susto, G.A.; Maggipinto, M.; Zannon, G.; Altinier, F.; Pesavento, E.; Beghi, A. Machine Learning-based laundry weight estimation for vertical axis washing machines. In Proceedings of the IEEE European Control Conference (ECC), Limassol, Cyprus, 12–15 June 2018; pp. 3179–3184. [Google Scholar]
- Zambonin, G.; Altinier, F.; Corso, L.; Sessolo, M.; Beghi, A.; Susto, G.A. Soft sensors for estimating laundry weight in household heat pump tumble dryers. In Proceedings of the IEEE 14th International Conference on Automation Science and Engineering (CASE), Munich, Germany, 20–24 August 2018; pp. 774–779. [Google Scholar]
- Susto, G.A.; Vettore, L.; Zambonin, G.; Altinier, F.; Beninato, D.; Girotto, T.; Rampazzo, M.; Beghi, A. A machine learning-based soft sensor for laundry load fabric typology estimation in household washer–dryers. In Proceedings of the IFAC Conference on Intelligent Control and Automation Science (ICONS), Belfast, Northern Ireland, 21–23 August 2019. [Google Scholar]
- Schölkopf, B.; Smola, A.J. Learning with Kernels: Support Vector Machines, Regularization, Optimization, and Beyond; MIT Press: Cambridge, MA, USA, 2002. [Google Scholar]
- Scheidegger, A.E. The physics of flow through porous media. Soil Sci. 1958, 86, 355. [Google Scholar] [CrossRef]
- Luikov, A.V. Heat and mass transfer in capillary-porous bodies. In Advances in Heat Transfer; Elsevier: Amsterdam, The Netherlands, 1964; Volume 1, pp. 123–184. [Google Scholar]
- Doymaz, İ. Effect of dipping treatment on air drying of plums. J. Food Eng. 2004, 64, 465–470. [Google Scholar] [CrossRef]
- Kucuk, H.; Midilli, A.; Kilic, A.; Dincer, I. A review on thin-layer drying-curve equations. Dry. Technol. 2014, 32, 757–773. [Google Scholar] [CrossRef]
- Younis, M.; Abdelkarim, D.; El-Abdein, A.Z. Kinetics and mathematical modeling of infrared thin-layer drying of garlic slices. Saudi J. Biol. Sci. 2018, 25, 332–338. [Google Scholar] [CrossRef] [PubMed]
- Dincer, I. Energy and environmental impacts: Present and future perspectives. Energy Sources 1998, 20, 427–453. [Google Scholar] [CrossRef]
- Ketelaars, A.; Pel, L.; Coumans, W.; Kerkhof, P. Drying kinetics: A comparison of diffusion coefficients from moisture concentration profiles and drying curves. Chem. Eng. Sci. 1995, 50, 1187–1191. [Google Scholar] [CrossRef] [Green Version]
- Sahin, A.; Dincer, I.; Yilbas, B.; Hussain, M. Determination of drying times for regular multi-dimensional objects. Int. J. Heat Mass Transf. 2002, 45, 1757–1766. [Google Scholar] [CrossRef]
- Prasertsan, S.; Saen-Saby, P. Heat pump drying of agricultural materials. Dry. Technol. 1998, 16, 235–250. [Google Scholar] [CrossRef]
- Haghi, A.; Ghanadzadeh, H. A study of thermal drying process. Indian J. Chem. Technol. 2005, 12, 654–663. [Google Scholar]
- Sander, A.; Kardum, J.P. Experimental validation of thin-layer drying models. Chem. Eng. Technol. Ind. Chem.-Plant Equip.-Process Eng.-Biotechnol. 2009, 32, 590–599. [Google Scholar] [CrossRef]
- Hamdaoui, M.; Baffoun, A.; Chaaben, K.B.; Hamdaoui, F. Experimental study and mathematical model to follow the drying phenomenon of knitted textile fabric. J. Eng. Fibers Fabr. 2013, 8. [Google Scholar] [CrossRef]
- Crank, J. The Mathematics of Diffusion; Oxford University Press: Oxford, UK, 1979. [Google Scholar]
- Dincer, I.; Zamfirescu, C. Drying Phenomena: Theory and Applications; John Wiley & Sons: Hoboken, NJ, USA, 2016. [Google Scholar]
- Pan, N.; Gibson, P. Thermal and Moisture Transport in Fibrous Materials; Woodhead Publishing: Sawston, UK, 2006. [Google Scholar]
- Van Oudenaarden, A. Cell Systems Biology Lecture; Course: Systems Biology, Modeling Biological Networks; Technical Report; MIT: Cambridge, MA, USA, 2009. [Google Scholar]
- Luikov, A.V. Analytical Heat Diffusion Theory; Elsevier: Amsterdam, The Netherlands, 2012. [Google Scholar]
- Berger, J.; Gasparin, S.; Dutykh, D.; Mendes, N. Accurate numerical simulation of moisture front in porous material. Build. Environ. 2017, 118, 211–224. [Google Scholar] [CrossRef] [Green Version]
- Gasparin, S.; Berger, J.; Dutykh, D.; Mendes, N. Advanced reduced-order models for moisture diffusion in porous media. Transp. Porous Media 2018, 124, 965–994. [Google Scholar] [CrossRef]
- Azeem, M.; Boughattas, A.; Wiener, J.; Havelka, A. Mechanism of liquid water transport in fabrics; a review. Fibres Text. Vlákna Text. 2017, 4, 58–62. [Google Scholar]
- Sharma, S.; Tambe, S.S. Soft-sensor development for biochemical systems using genetic programming. Biochem. Eng. J. 2014, 85, 89–100. [Google Scholar] [CrossRef]
- Orzechowski, P.; La Cava, W.; Moore, J.H. Where are we now? A large benchmark study of recent symbolic regression methods. In Proceedings of the Genetic and Evolutionary Computation Conference, Kyoto, Japan, 15–19 July 2018; ACM: New York, NY, USA, 2018; pp. 1183–1190. [Google Scholar]
- Searson, D.P. GPTIPS 2: An open-source software platform for symbolic data mining. In Handbook of Genetic Programming Applications; Springer: Berlin/Heidelberg, Germany, 2015; pp. 551–573. [Google Scholar]
- Goodfellow, I.; Bengio, Y.; Courville, A. Deep Learning; The MIT Press: Cambridge, MA, USA, 2016. [Google Scholar]











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Model | Expression | RMSE [%] | Index | #Params |
|---|---|---|---|---|
| Lewis | 9.069 | 0.781 | 2 | |
| Henderson & Pabis | 1.147 | 0.996 | 3 | |
| quadratic | 1.051 | 0.997 | 3 | |
| poly3 | 0.399 | 0.999 | 4 | |
| rational | 6.564 | 0.897 | 4 | |
| gaussian | 0.417 | 0.999 | 4 | |
| sigmoid | 0.496 | 0.999 | 3 | |
| two exp | 0.746 | 0.998 | 5 | |
| mixed | 0.453 | 0.999 | 5 |
| Methods | EoC Feasibility | TTE Feasibility | Performance Target * | Low Error Variance | Algorithm Calibration | Implementation Facility |
|---|---|---|---|---|---|---|
| Method 1 | ✔ | ✔ | ✔ | ✔ | ||
| Method 2 | ✔ | ✔ | ✔ | |||
| Method 3 | ✔ | ✔ | ✔ | ✔ | ✔ | |
| Current algorithm | ✔ | ✔ | ✔ | ✔ | ✔ |
© 2019 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zambonin, G.; Altinier, F.; Beghi, A.; Coelho, L.d.S.; Fiorella, N.; Girotto, T.; Rampazzo, M.; Reynoso-Meza, G.; Susto, G.A. Machine Learning-Based Soft Sensors for the Estimation of Laundry Moisture Content in Household Dryer Appliances. Energies 2019, 12, 3843. https://doi.org/10.3390/en12203843
Zambonin G, Altinier F, Beghi A, Coelho LdS, Fiorella N, Girotto T, Rampazzo M, Reynoso-Meza G, Susto GA. Machine Learning-Based Soft Sensors for the Estimation of Laundry Moisture Content in Household Dryer Appliances. Energies. 2019; 12(20):3843. https://doi.org/10.3390/en12203843
Chicago/Turabian StyleZambonin, Giuliano, Fabio Altinier, Alessandro Beghi, Leandro dos Santos Coelho, Nicola Fiorella, Terenzio Girotto, Mirco Rampazzo, Gilberto Reynoso-Meza, and Gian Antonio Susto. 2019. "Machine Learning-Based Soft Sensors for the Estimation of Laundry Moisture Content in Household Dryer Appliances" Energies 12, no. 20: 3843. https://doi.org/10.3390/en12203843
APA StyleZambonin, G., Altinier, F., Beghi, A., Coelho, L. d. S., Fiorella, N., Girotto, T., Rampazzo, M., Reynoso-Meza, G., & Susto, G. A. (2019). Machine Learning-Based Soft Sensors for the Estimation of Laundry Moisture Content in Household Dryer Appliances. Energies, 12(20), 3843. https://doi.org/10.3390/en12203843