1. Introduction
Within the field of soft computing, intelligent optimization modelling techniques include various major techniques in artificial intelligence [
1] pretending to generate new business data knowledge transforming sets of "raw data" into business value. In the Merriam-Webster dictionary data mining is defined as “the practice of searching through large amounts of computerized data to find useful patterns or trends”, so we can then say that intelligent optimization modelling techniques are data mining techniques.
Nowadays, connections among industrial assets and integrating information systems, processes and operative technicians [
2] are the core of the next-generation of industrial management. Based on the industrial Internet of Things (IoT), companies have to seek intelligent optimization modelling techniques (advanced analytics) [
3] in order to optimize decision-making, business and social value. These techniques are preferred to fall inside the soft computing category, with the idea of solving real complex problems with inductive reasoning like humans, searching for probable patterns, being less precise, but adaptable to reasonable changes and easily applicable and obtainable [
4].
To be able to implement these advanced techniques requires a comprehensive process sometimes named “intelligent data analysis” (IDA) [
5], which is a more extensive and non-trivial process to identify understandable patterns from data. Within this process, the main difficulty is to identify valid and correct data for the analysis [
3] from the different sources in the company. Second, efforts must be developed to create analytic models that provide value by improving performance. Third, a cultural change has to be embraced for companies to facilitate the implementation of the analytical results. In addition to this, since accumulation of data is too large and complex to be processed by traditional database management tools (the definition of “big data” in the Merriam-Webster dictionary), new tools to manage big data must be taking into consideration [
6].
Under these considerations IDA can be applied to renewable energy production, as one of the most promising fields of application of these techniques [
7]. The stochastic nature of these energy sources, and the lack of a consolidated technical background in most of these technologies, make this sector very susceptible for the application of intelligent optimization modelling techniques. The referred stochastic nature is determined by circumstances in the generation sources, but also by the existing operational conditions. That is, the natural resources have variations according to weather with a certain stationarity but with difficulties in forecasting behaviours. In addition, depending on the operational and environmental stresses in the activities, they will be more likely to fail. Consequently, the analysis of renewable energy production must consider adaptability to dynamic changes that can yield results [
8].
The identification and prediction of potential failures can be improved using advanced analytics as a way to search proactively and reduce risk in order to improve efficiency in energy generation. Algorithms, such as machine learning, are now quite extended in renewable energy control systems. These kinds of facilities are characterized by the presence of a great number of sensors feeding the SCADA systems (supervisory control and data acquisition systems), usually very sophisticated systems including a control interface and a client interface (the plant’s owner, distribution electric network administrator, etc.). Power and energy production measures are two of the most important variables managed by the SCADA. As principal system performance outputs, they can be exploited through data mining techniques to control system failures, since most of the systems failures directly affect the output power and the energy production efficiency [
7].
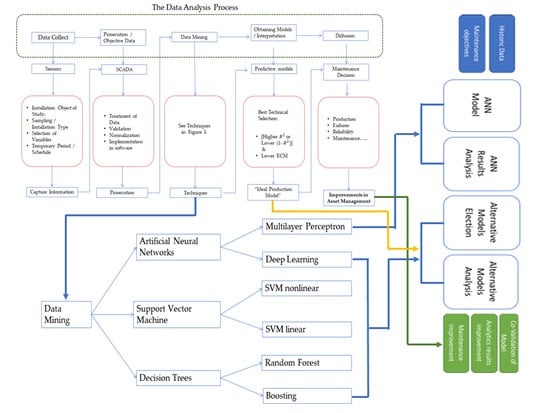
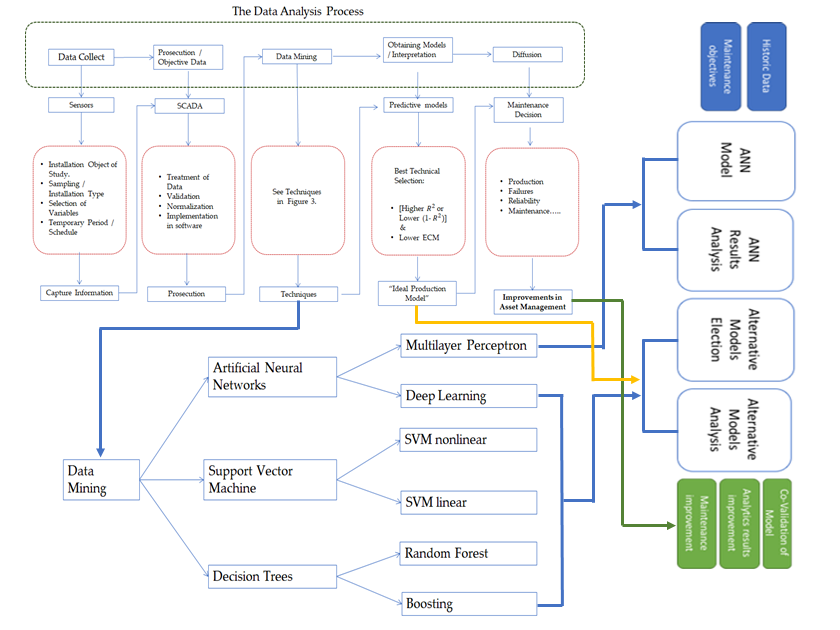
A sample process for a comprehensive IDA, applied to the improvement of assets management in renewable energy, is presented in
Figure 1.
In
Figure 1 the green box describes the generic IDA process phases, phases which need to be managed inside an asset management condition-based maintenance (CBM) framework, in order to make sustainable and well-structured decisions, to obtain developments and to keep and improve solutions over time. In order to take rapid and optimal decisions, the challenge is to structure the information from different sources, synchronizing it properly in time, in a sustainable and easily assimilable way, reducing the errors (avoiding dependencies among variables, noise, and interferences) and valuing real risks. A clear conceptual framework allows the permanent development of current and new algorithms, corresponding to distinct data behaviour-anomalies with physical degradation patterns of assets according to their operation and operation environment conditions and their effects on the whole plant [
11].
Each one of these IDA phases are interpreted, in the red boxes, for a PV energy production data system [
9,
10] showing a flow-chart for practical implementation. In this paper we will focus on the central phase in
Figure 1, the analysis of different techniques of data mining (DM). Different techniques can be applied. We will concentrate in the selection of advanced DM techniques, comparing their results when applied to a similar case study. This issue is often not addressed when applying certain complex intelligent optimization modelling techniques, and no discussion emerges concerning this issue. This is because, often, the computational effort to apply a certain method is very important in order to be able to benchmark the results of several methods [
12]. In the future, assuming more mature IDA application scenarios, the selection of DM techniques will likely be crucial to generating well-informed decisions.
Accepting this challenge, a review of the literature, the selection of techniques and a benchmark of their results are presented in this paper. According to the previous literature, most representative techniques of data mining [
13,
14] are presented and applied to a case study in a photovoltaic plant (see other examples where these techniques were applied in
Table 1).
Artificial neural networks (ANN) have been largely developed in recent years. Some authors [
15,
16,
17,
18,
19,
20] have focused on obtaining PV production predictions through a behavioural pattern that is modelled by selected predictor variables. A very interesting topic is how these results can be applied in predictive maintenance solutions. In [
7] these models are used to predict PV system’s faults before they occur, improving the efficiency of PV installations, allowing programming in advance of suitable maintenance tasks. Following a similar approach, the rest of DM techniques are implemented to validate, or even improve, the good results obtained with the ANN in terms of asset maintenance and management.
In general terms, the results obtained using DM or machine learning to follow and predict PV critical variables, like solar radiation [
21], are good enough to use as inputs in decision-making processes, like maintenance decisions [
7]. However, not all of the techniques have the same maturity level as ANNs. SVM, Random Forest and Boosting, as techniques to predict the yield of a PV plant, should be studied in greater depth in the coming years [
22].
5. Employed DM Techniques
The employed DM techniques, for failure prediction, are presented below, using for comparison the mean square error to measure the quality of the results:
- -
ANN Models:
- ○
Multilayer Perceptron
- ○
Deep Learning
- -
Support Vector Machines:
- ○
SVM non-linear
- ○
SVM Lineal (Lib Linear)
- -
Random Forest
- -
Boosting
The practical implementation for each one of these techniques will now be introduced, describing the employed libraries, functions and transformation variables.
It is important to mention that unless learning is applied we cannot say that any DM model is intelligent. Therefore, for those situations when new data arrives after significant changes in an asset’s location or operation, a learning period for the algorithms is required.
The error predicted by the model can also offer a good clue regarding potential scenario modifications and can be used to trigger and lead to a new phase of model actualization, or learning period. This will reduce reasonable worries about model validation and will give more confidence to support asset managers’ decision-making regarding prediction and time estimation for the next failures. These ideas can also be programmed and automatically put into operation in the SCADA.
5.1. ANN Models: Multilayer Perceptron
For the case study, first, a three-layer perceptron is employed with the following activation functions: logistic and identity in the hidden layer (
g(
u) =
eu/(
eu + 1)) and in the output layer, respectively. If we denote
wh synaptic weights between the hidden layer and the output layer {
wh,
h = 0, 1, 2, ...,
H},
H as the size of the hidden layer, and
vih synaptic weights of connections between the input layer (
p size) and the hidden layer {
vih,
i = 0, 1, 2, …,
p,
h = 1, 2, …,
H}, thus, with a vector of inputs (
x1, …,
xp), the output of the neural network could be represented by the following function (1):
We have used the R library nnet [
56], where multilayer perceptrons with one hidden layer are implemented. The nnet function needs, as parameters, the decay parameter (
λ) to prevent overfitting in the optimization problem, and the size of the hidden layer (
H). Therefore, providing the vector of all
M coefficients of the neural net
W = (
W1, …, WM), and specified
n targets
y1, …, yn, the following optimization problem (Equation (2)) is (L2 regularization):
A quasi-Newton method, namely the BFGS (Broyden-Fletcher-Goldfarb-Shanno) training algorithm [
44], is employed by nnet, in R with e1071 library using the tune function [
57], determining the decay parameter (
λ) as {1, 2, …, 15} × {0, 0.05, 0.1} by a ten-fold cross-validation search.
The λ parameter obtained for the two transformations presented below has been zero in all the models built, the logical value considering the sample size and the reduced number of predictor variables, which carries little risk of overfitting.
Through prior normalization of the input variables, the performance could be enhanced in the model. For that, we have considered two normalization procedures, a first transformation that subtracts each variable predictor
X from its mean, and the centred variable is divided by the standard deviation of
X. In this way we manage to normalize with a 0 mean and a standard deviation equal to 1. The second lineal normalization transforms the range of
X values into the range (0, 1). We design, respectively, the values of the standards
Z1 and
Z2, which are calculated as follow:
These transformations have used the mean, standard deviation, maximums and minimums calculated in the network training dataset, and these same values have been used for the test set, thus avoiding the intervention of the test set in the training of the neural network.
Since the range of values provided by the logistic function is in the range (0, 1) and the dependent variable Y takes values in the range (0, 99). We transform this with the Y/100 calculation. However, after obtaining the predictions, the output values obtained in the original range were transformed back to the original range of values by multiplying by 100 to bring it back to the interval (0, 99).
5.2. ANN Models: Deep Learning
We have used the R package h2o [
58] to prevent overfitting with several regularization terms, building a neural network with four layers, and with two hidden layers formed by 200 nodes each.
First, L1 and L2 regression terms are both included in the objective function to be minimized in the parameter estimation process (Equation (4)):
Another regularization type to prevent overfitting is dropout, which averages a high number of models as a set with the same global parameters. In this type, during the training, in the forward propagation the activation of each neuron is supressed less than 0.2 in the input layer and up to 0.5 in the hidden layers, and provoking that weights of the network will be scaled towards 0.
The two normalization procedures used with nnet have also been used with h2o.
5.3. Alternative Models (SVM): Support Vector Machines (Non-Linear SVM)
Now, we have used the svm function of the R system library e1071 [
57] for the development of the SVM models and, concretely, the
ε-classification with the radial basis Gaussian kernel function (5); by
n training compound vectors {
xi,
yi},
i = 1, 2, …,
n as the dataset, where
xi incorporates the predictor features and
yi ∈ {−1, 1} are the results of each vector:
Therefore, it is solved by quadratic programming optimization (Equation (6)):
With the parameter
C > 0 to delimit the tolerated deviations from the desired
ε accuracy. The additional slack variables
allows the existence of points outside the
ε-tube. The dual problem is given by Equation (7):
with
K(xi,
xj) =
φ(xi)tφ(xj) being the kernel function, a positive semi-definite matrix
Q is employed by
Qij =
K(xi,
xj),
i,
j = 1, 2, …,
n,. The prediction for a vector
x (Equation (8)) is computed by:
depending on the margins
.
A cross-validation grid search for C and γ over the set {1, 5, 50, 100, 150, …, 1000} × {0.1, 0.2, 0.3, 0.4} was conducted by the R e1071 tune function, while the parameter ε was maintained at its default value, 0.1.
We have built this SVM model with the original input variables, and with the two normalization procedures previously described in the multilayer perceptron description.
5.4. Alternative Models (SVM): LibLineaR (Linear SVM)
A library for linear support vector machines is LIBLINEAR [
59] for the case of large-scale linear prediction. We have used the version used in [
60], with fast searching estimation (in comparison with other libraries) through the heuristicC function for
C and based on the default values for
ε, and employing L2-regularized support vector regression (with L1- and L2-loss).
5.5. Alternative Models (DT): Random Forests
The Random Forests (RF) algorithm [
61] combines different predictor trees, each one fitted on a bootstrap sample of the training dataset. Each tree is grown by binary recursive partitioning, where each split is determined by a search procedure aimed to find the variable of a partition rule which provides the maximum reduction in the sum of the squared error. This process is repeated until the terminal nodes are too small to be partitioned. In each terminal node, the average of response variable is the prediction. RF is similar to bagging [
39], with an important difference: the search for each split is limited to a random selection of variables, improving the computational cost. We have used the R package Random Forest [
62]. By default, p/3 variables (p being the predictor’s number) are randomly selected in each split, and 500 trees are grown.
5.6. Alternative Models (DT): Boosting
From the different boosting models depending on the used loss functions, base models, and optimization schemes, we have employed one based on Friedman´s gradient boosting machine of the R gbm package [
63] where the target is to boost the performance of a single tree with the following parameters:
- -
The squared error as a loss function ψ (distribution),
- -
T (n.trees) as the number of iterations,
- -
The depth of each tree, K (interaction.depth),
- -
The learning rate parameter, λ (shrinkage), and
- -
The subsampling rate, p (bag.fraction).
The function is initialized to be a constant. For t in 1, 2, …, T do the following:
Following the suggestions of Ridgeway in his R package, our work considered the following values:
shrinkage = 0.001; bag.fraction = 0.5; interaction.depth = 4; n.trees = 5000, but cv.folds 10 performed a cross-validation search for the effective number of trees.
7. Conclusions
In this paper a methodology to introduce the use of different data mining techniques for energy forecasting and condition-based maintenance was followed. These techniques compete for the best possible replica of the production behaviour patterns.
A relevant set of DM techniques have been applied (ANN, SVM, DT), and after their introduction to the readers, they were compared when applied to a renewable energy (PV installation) case study.
In this paper a very large sample of data has been considered. This data spans from 1 June 2011 to 30 September 2015.
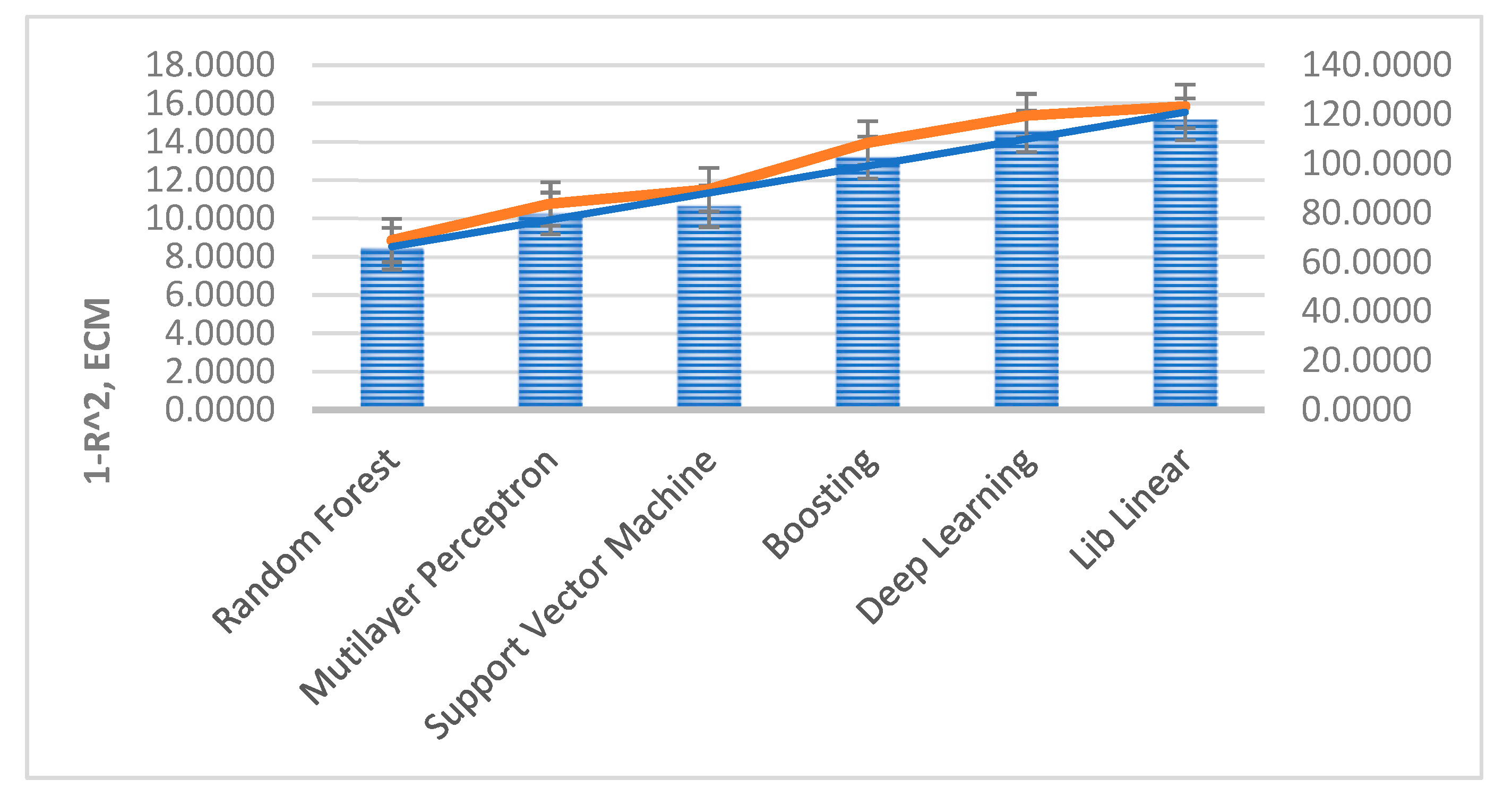
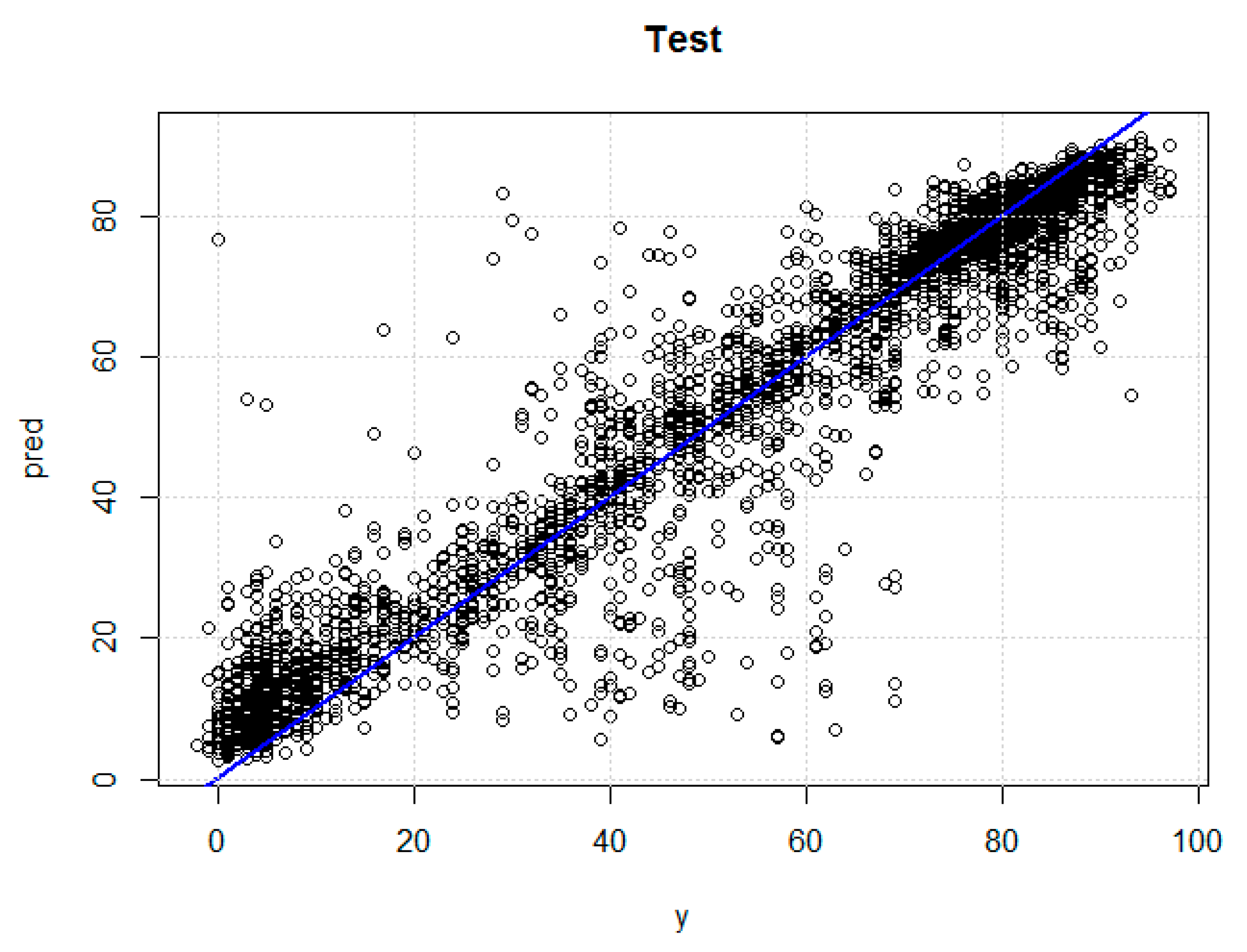
All of the models for the different techniques offered very encouraging results, with correlation coefficients greater than 0.82. Coincident with other referenced authors’ results, Random Forest was the technique providing the best fit, with a linear correlation coefficient of 0.9092 (followed by ANN and SVM). In turn, this technique (RF) gave us as a differential value of the importance of the input variables used in the model, which somehow validates the use of all these variables. In the case study, and by far, the variable resulting with the most affection to production was radiation, followed by the outside temperature, the inverter internal temperature and, finally, the operating hours (which somehow reflects the asset degradation over time).
It is important to mention that these results were obtained using different methods (2) to normalize the variables and to estimate parameters.
Future work could be devoted to the validation of these results by replicating the study at other renewable energy facilities to determine how the improvement in ECM and R2 values affects early detection of failures by quantifying their economic value.
The implementation of these techniques is feasible today thanks to existing computational capacity, so the effort to use any of them is very similar.

 ,
, 







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}