Combustion Optimization for Coal Fired Power Plant Boilers Based on Improved Distributed ELM and Distributed PSO

Abstract
:1. Introduction
2. Review of MapReduce, ELM and PSO
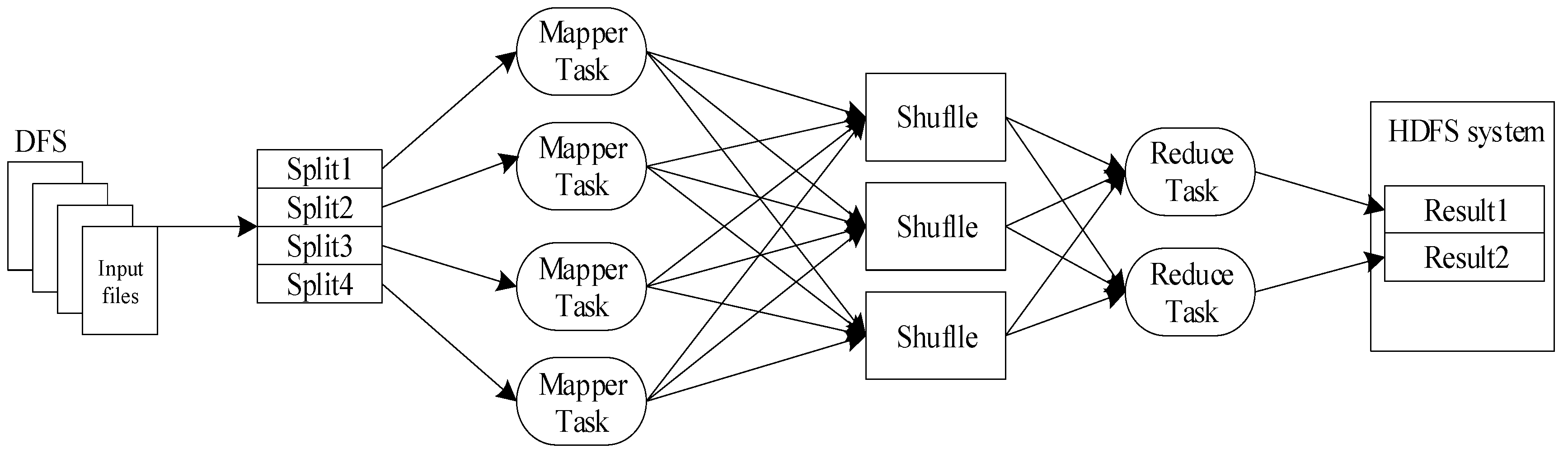
2.1. MapReduce
2.2. Extreme Learning Machine
2.3. Particle Swarm Optimization Algorithm
3. Improved Distributed Extreme Learning Machine (IDELM) Algorithm
3.1. Preliminaries
3.2. IDELM
| Algorithm 1: Improved Distributed ELM (IDELM) S and D calculation steps |
| 1 class SandD |
| 2 // INITIALIZE |
| 3 int L, m |
| 4 s = new ASSOCIATIVEARRAY |
| 5 d = new ASSOCIATIVEARRAY |
| 6 class Mapper |
| 7 h = new ASSOCIATIVEARRAY |
| 8 x = new ASSOCIATIVEARRAY |
| 9 map(context) |
| 10 while (context.nextKeyValue) |
| 11 (x,t) = Parse(contest) |
| 12 for i = 1 to L do |
| 13 h[i] = g(wi ∙x + bi) |
| 14 for i = 1 to L do |
| 15 for j = 1 to L do |
| 16 s[i][j] = s[i][j] + h[i]∙h[j] |
| 17 for i = 1 to m do |
| 18 d[i][j] = d[i][j] + h[i]∙t |
| 19 for i = 1 to L do |
| 20 for j = 1 to L do |
| 21 context.write(triple (‘S’, i, j), s[i, j]) |
| 22 for j = 1 to m do |
| 23 context.write(triple (‘D’, i, j),d[i, j]) |
| 24 method run(context) |
| 25 map(context) |
| 26 class Reduce |
| 27 reduce(context) |
| 28 while (context.nextKey()) |
| 29 sd = 0 |
| 30 for (val : values) |
| 31 sd+=val.get() |
| 32 context.write(key, sd) |
| 33 method run(context) |
| 34 reduce(context) |
- Step 1:
- Initialize the number of hidden layer nodes , label , two arrays and , which are used to store the calculation results of the elements in matrix and (Lines 3–5);
- Step 2:
- In class Mapper, initialize the local variables and (Lines 6–8);
- Step 3:
- In the map method, we first use a while loop to read a sample, and then divide the sample into training data and the corresponding training result . The separated training sample attribute value is brought into the partial result of the loop computation matrix . According to the solved value and Formulas (14) and (15), the partial accumulation of elements in matrices and is calculated, respectively, and the final results are stored in the array and . The role of the while loop is that when all the <key, value> key pairs in the data block are run, the final sum is stored in and (Lines 9–18);
- Step 4:
- Put s and d in the form of key-value pairs in HDFS (Lines 19–23);
- Step 5:
- The run method in the Mapper class is overloaded (Lines 24–25);
- Step 6:
- The reduce method uses a while loop to extract a sample and then initialize a temporary variable. Merge the intermediate results with the same key values in different Mapper to obtain the final accumulated sum of the elements corresponding to the key value (Lines 27–31);
- Step 7:
- Store the result in HDFS (Line 32);
- Step 8:
- The run method in the Reduce class is overloaded (Lines 33–34).
| Algorithm 2: Improved Distributed ELM (IDELM) |
| 1 for i = 1 to L do |
| 2 Randomly generated hidden layer node parameters (wi, bi) |
| 3 In MapReduce,calculate S = HTH, D = HTT |
| 4 Calculate the output weight vector β = (1/A + S)−1D |
| 5 Forecast result f(x) = h(x) β |
3.3. Algorithm Performance Analysis
3.3.1. Experiments Setup
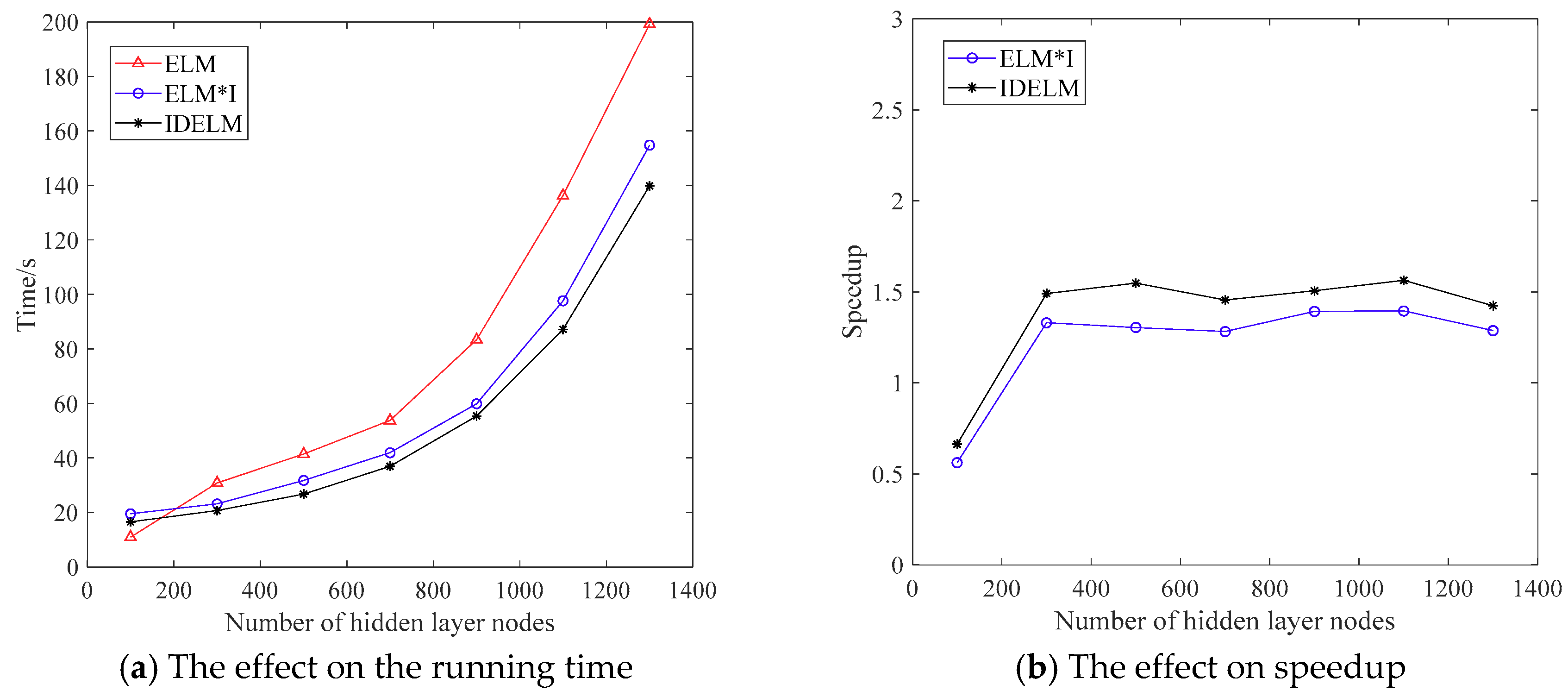
3.3.2. The Effect of Number of Hidden Layer Nodes on the Performance of IDELM Algorithm
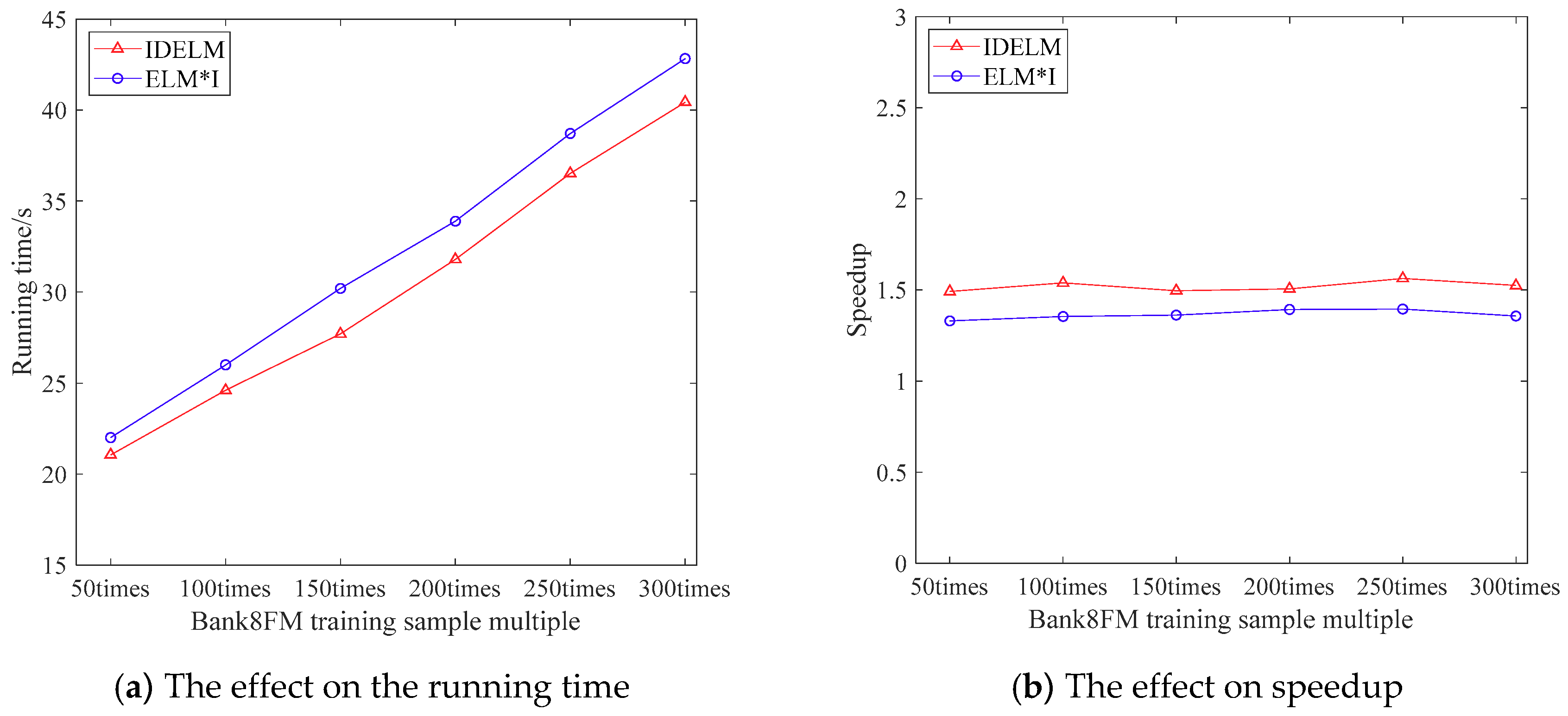
3.3.3. The Effect of Training Sample Number on the Performance of IDELM Algorithm
4. Distributed Particle Swarm Optimization Algorithm
4.1. Initialization Stage
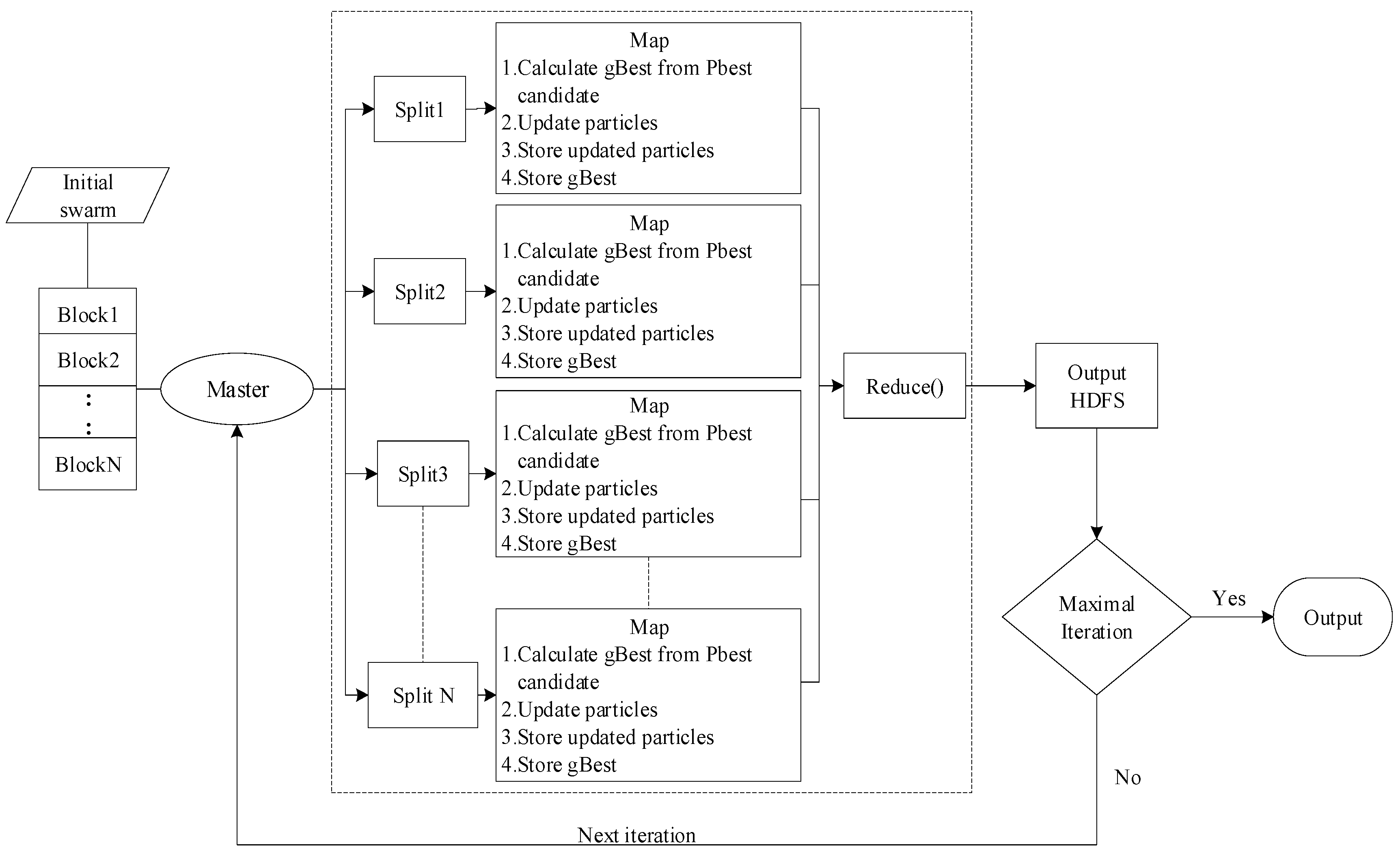
4.2. MapReduce Stage
| Algorithm 3: MR-PSO algorithm steps |
| 1 class MAPPER |
| 2 method INITIALIZE() |
| 3 position = new ASSOCIATIVEARRAY |
| 4 velocity= new ASSOCIATIVEARRAY |
| 5 method Map( Key:ID,Value:particle) |
| 6 lparticleBest = None; |
| 7 (position,velocity,fitness) = Parse(particle); |
| 9 for each particle do |
| 10 positionNew = position.update(position); |
| 11 velocityNew = velocity.update(velocity); |
| 12 positionNew fitness = Fitness(positionNew); |
| 13 if positionNew fitness> Fitness(lparticleBest)then; |
| 14 lparticleBest =positionNew |
| 15 end if |
| 16 context.write(id,positionNew, velocityNew) |
| 17 end for |
| 18 context.write(localbest, lparticleBest) |
| 19 class REDUCE |
| 20 method reduce(Key : localbest,ValList) |
| 21 gBestparticle = None; |
| 22 for each lparticleBest in ValList do |
| 23 lparticleBest = ParticleLocalBest(VslList) |
| 24 if Fitness(lparticleBest) > Fitness(gBestparticle) then |
| 25 gBestparticle= lparticleBest |
| 26 end if |
| 27 end for |
| 28 context.write(gbestID, gBestparticle); |
- (1)
- The input data is divided into a number of data blocks and stored in a distributed file system (HDFS). These data are entered into a MapReduce task as key-value pairs, and then each Map function is assigned a data block;
- (2)
- The program in Mapper will update the velocity and position of each particle in the data block. After the update, it will bring it into the fitness evaluation function to calculate the fitness value;
- (3)
- Compare the fitness value of new and old particles, if the fitness value of new particle is good, replace the position of the original particle with the current particle position and store it in HDFS;
- (4)
- Find the fitness value of the global best particle (lparticleBest) in each Map, and compare with each updated particle fitness value. If the fitness value of the particle is better than the fitness value of lparticleBest, use this particle position and velocity replace lparticleBest position and velocity;
- (5)
- Through the above particle replacement, the local optimal solution in the current map task is finally obtained, and the local optimal solution is stored into the HDFS in the form of <key, value> key-value pairs, where the key is a fixed value, value is the local optimal particle position;
- (6)
- When all Map tasks have finished executing, they will be entered into a Reduce task. The main task of Reduce is to find the global best particle () from the lparticleBest generated from all the Maps, then replace the original global optimal particle and store the final result in HDFS.
4.3. Conditional Judgment Stage
5. Boiler Combustion Model Based on IDELM Algorithm
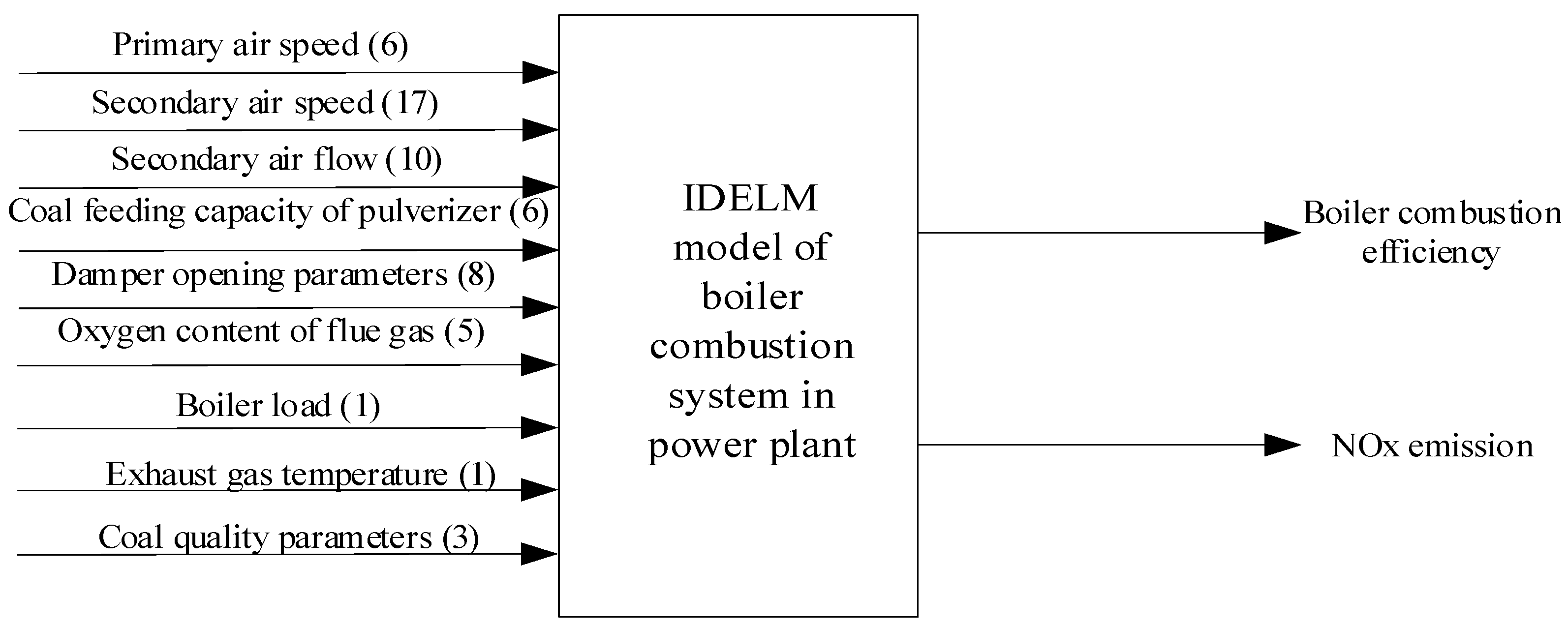
5.1. Model and Experiments Setup
5.2. Parameters L and A on IDELM Model
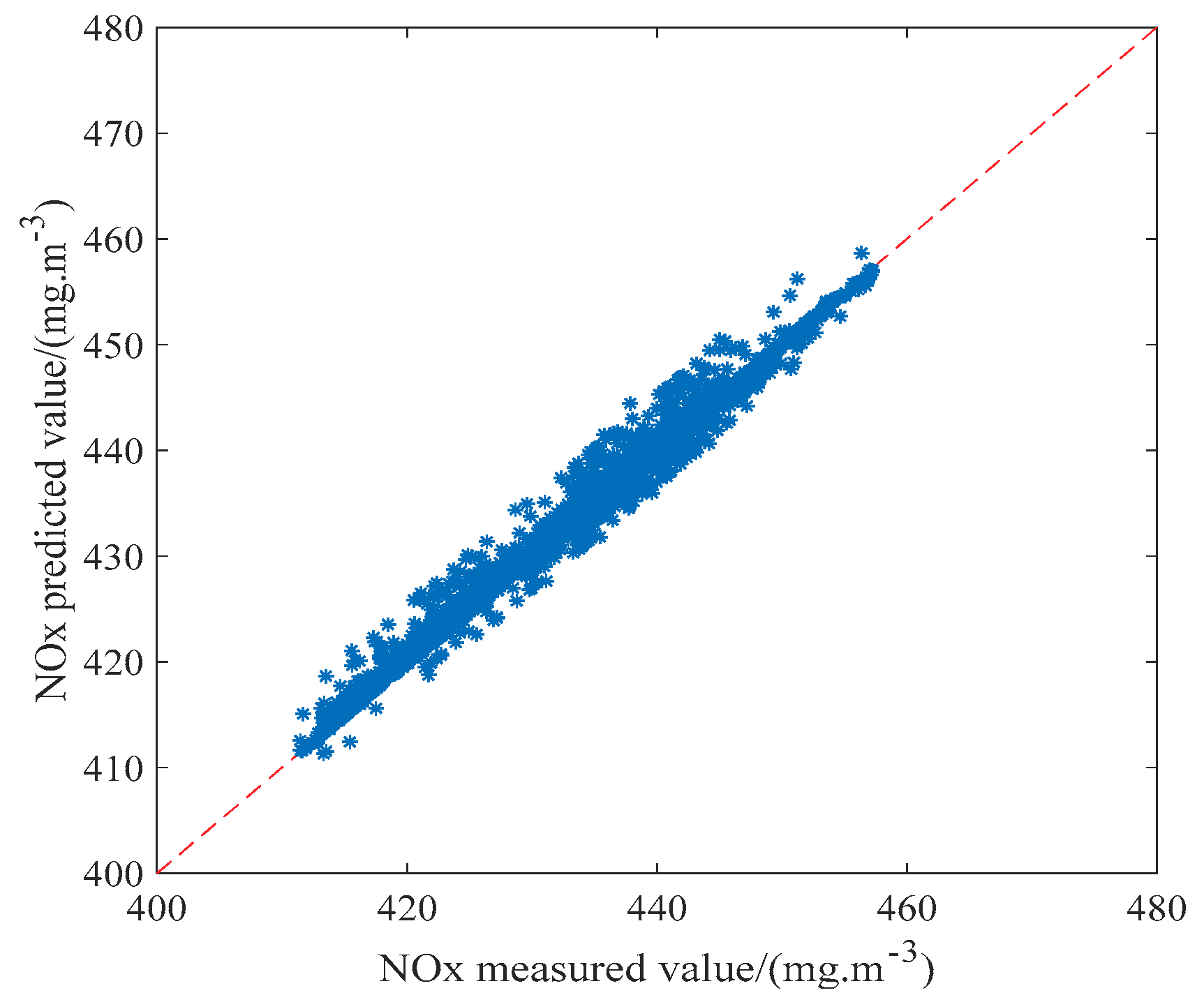
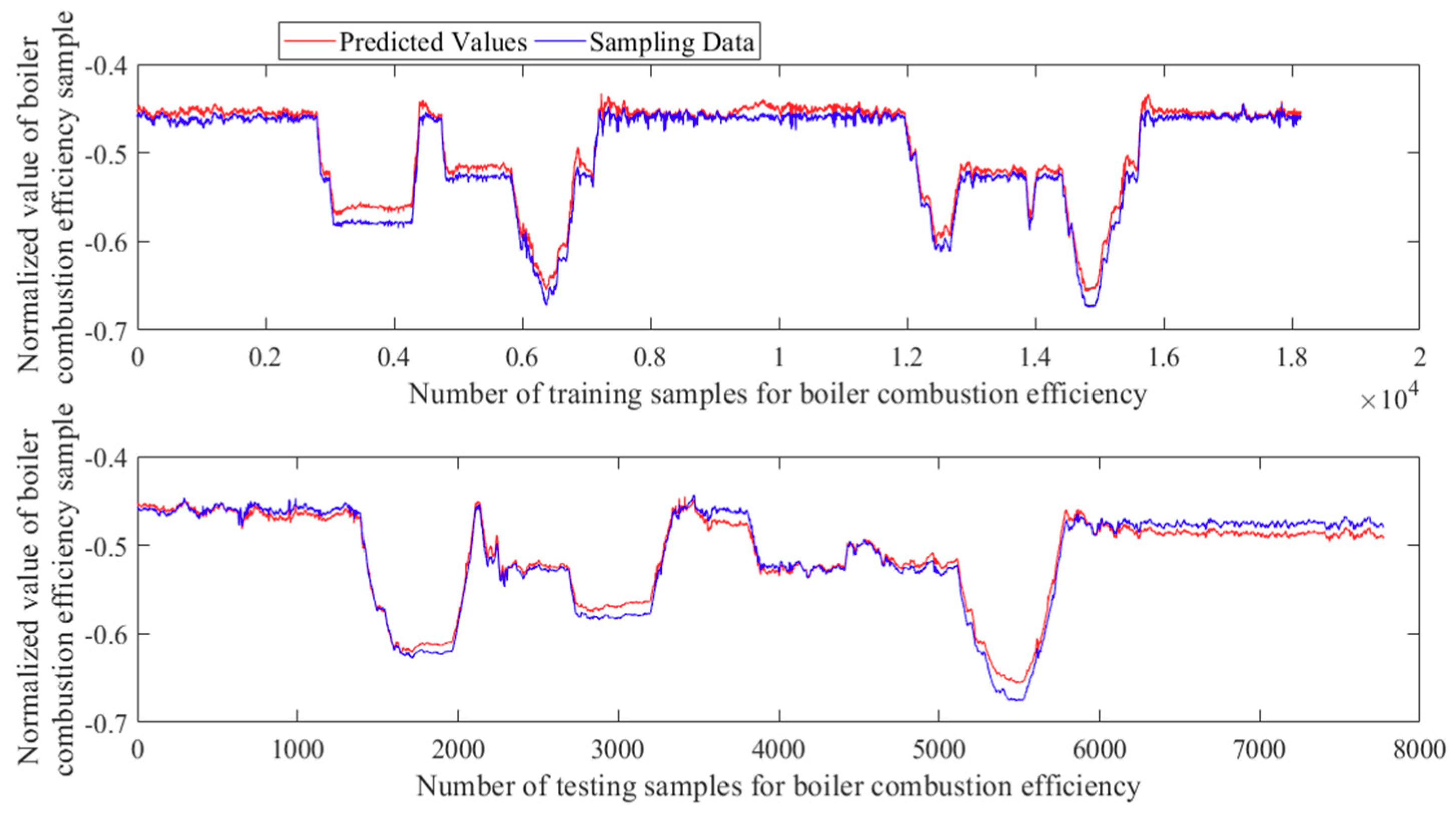
5.3. The Effect of Prediction
6. The Realization of Boiler Combustion Optimization
6.1. Optimization Problem Description
6.1.1. Boiler Combustion Optimization Function Design
6.1.2. Constraints
6.2. Combustion Optimization Based on MR-PSO Algorithm
- (1)
- In the experiment, the initialization range of the initial population should be determined according to the actual operating data of the boiler combustion system collected this time, and then randomly generate n particles within the constraint range according to the uniform distribution function and store them into the distributed File system (HDFS);
- (2)
- The master node shaves input files in HDFS and distributes the sliced data to Map tasks.
- (3)
- The Map task separates and extracts the particle information from the input file, separates the particle velocity and position information respectively, and updates the particle velocity and position according to the velocity Equation (10) and the position Equation (11), and then substitute the updated particle’s position information into the boiler combustion IDELM model to get the prediction result. The Fitness value is obtained by Equation (22), according to the size of the fitness evaluation value, it is determined whether to replace the original particle velocity and position, and store it in HDFS in a certain order. All the particles are compared with the global optimal particle, replace its value if it is better than the original value, and storing it in the HDFS, thereby obtaining the global optimal particle in the map;
- (4)
- The main task of Reduce is to compare the local global optimal particles obtained by each map task before, and get the global optimal position of the entire particle swarm, and store it into the HDFS in key-value pairs;
- (5)
- After the completion of the Reduce task, it is judged whether the maximum number of iterations is satisfied. If the maximum iteration is not satisfied, the Map task is returned to step (3), and the Map task is continued until the maximum number of Iterations is satisfied.
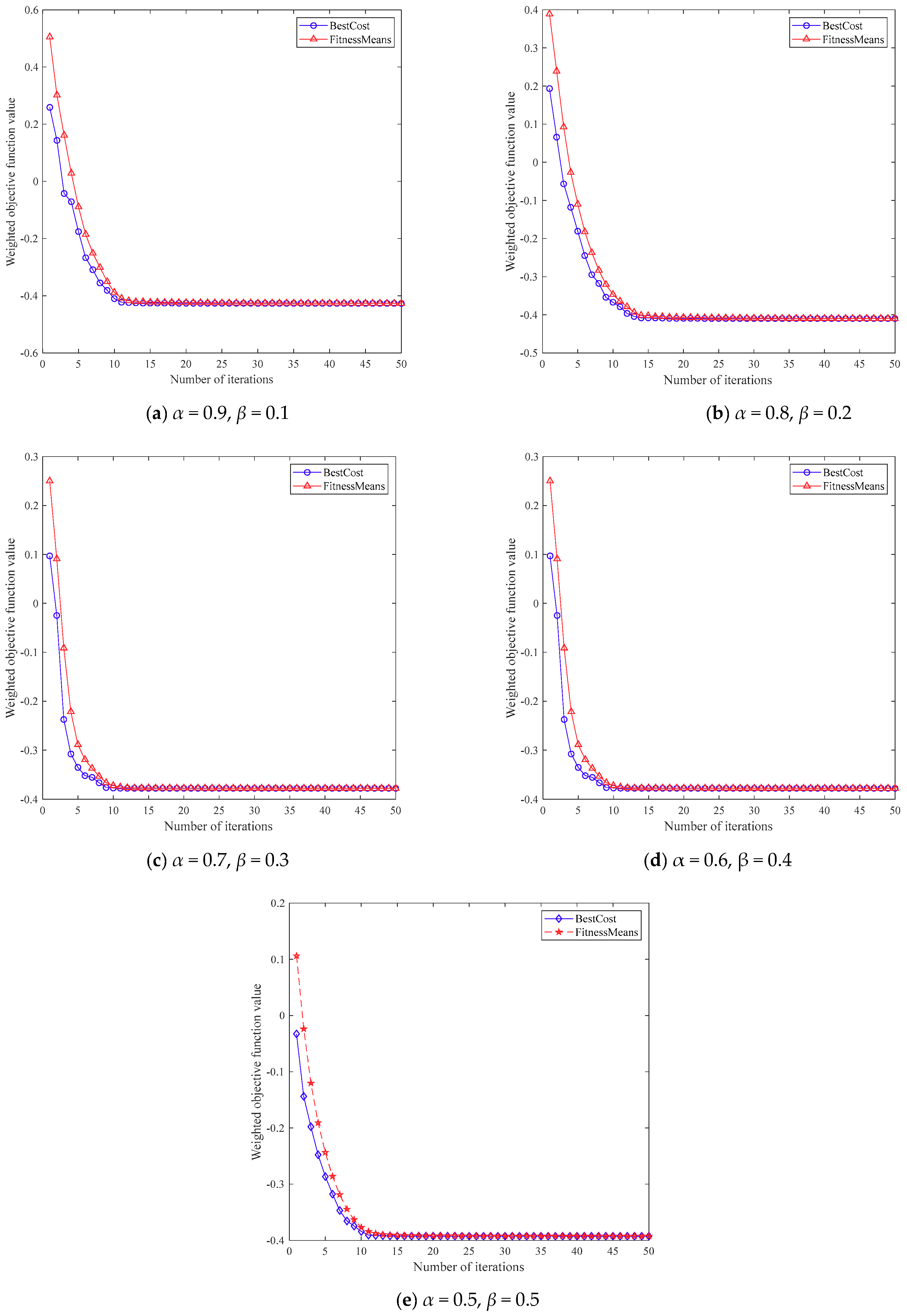
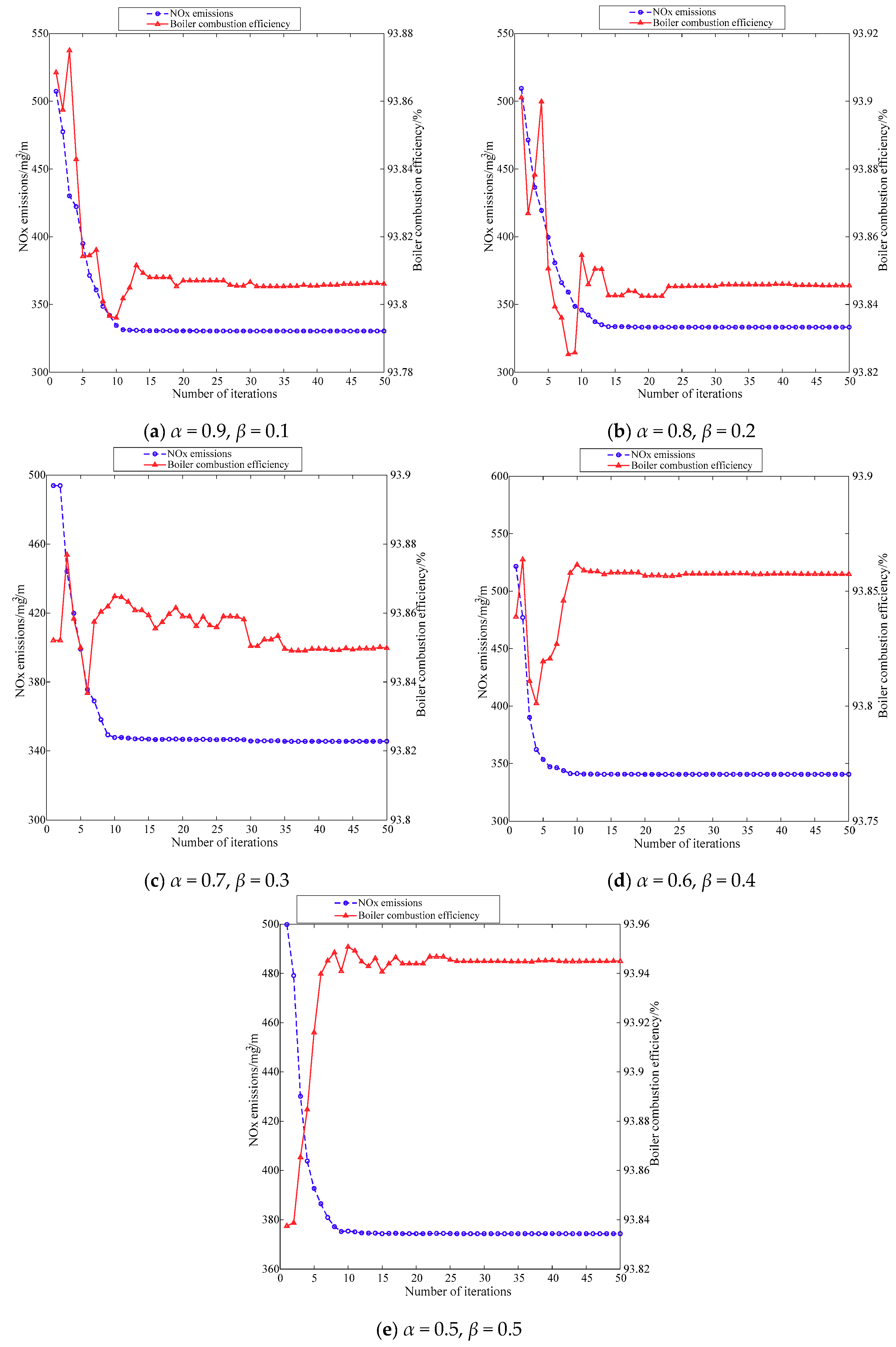
6.3. Analysis of Optimization Results under Different Weights
7. Conclusions
Author Contributions
Funding
Conflicts of Interest
References
- BeloševićaIvan, S.; Tomanović, I.; Beljanski, V.; Tucaković, D.; Živanović, T. Numerical prediction of processes for clean and efficient combustion of pulverized coal in power plants. Appl. Therm. Eng. 2015, 74, 102–110. [Google Scholar] [CrossRef]
- Barnes, D.I. Understanding pulverised coal, biomass and waste combustion—A brief overview. Appl. Therm. Eng. 2015, 74, 89–95. [Google Scholar] [CrossRef]
- Zhou, H.; Zhao, J.P.; Zheng, L.G.; Wang, C.L.; Cen, K.F. Modeling NOx emissions from coal-fired utility boilers using support vector regression with ant colony optimization. Eng. Appl. Artif. Intell. 2012, 25, 147–158. [Google Scholar] [CrossRef]
- Wu, X.Y.; Tang, Z.H.; Cao, S.X. A hybrid least square support vector machine for boiler efficiency prediction. In Proceedings of the 2017 IEEE 3rd Information Technology and Mechatronics Engineering Conference (ITOEC), Chongqing, China, 3–5 October 2017. [Google Scholar] [CrossRef]
- Lu, Y.K.; Peng, X.; Zhao, K. Hybrid Modeling Optimization of Thermal Efficiency and NOx Emission of Utility Boiler. J. Chin. Soc. Electr. Eng. 2011, 31, 16–22. [Google Scholar] [CrossRef]
- Huang, G.B.; Zhu, Q.Y.; Siew, C.K. Extreme learning machine: A new learning scheme of feedforward neural networks. Neural Netw. 2004, 2, 985–990. [Google Scholar] [CrossRef]
- Huang, G.B.; Zhu, Q.Y.; Siew, C.K. Extreme learning machine: Theory and applications. Neurocomputing 2006, 70, 489–501. [Google Scholar] [CrossRef] [Green Version]
- Liu, H.; Li, F.; Xu, X.; Sun, F. Multi-modal local receptive field extreme learning machine for object recognition. Neurocomputing 2018, 277, 4–11. [Google Scholar] [CrossRef]
- Huang, G.B.; Zhou, H.; Ding, X.; Zhang, R. Extreme learning machine for regression and multiclass classification. IEEE Trans. Syst. Man Cybern. Part B 2012, 42, 513–529. [Google Scholar] [CrossRef] [PubMed]
- Huang, G.B.; Chen, L. Enhanced random search based incremental extreme learning machine. Neurocomputing 2008, 71, 3460–3468. [Google Scholar] [CrossRef] [Green Version]
- Feng, G.; Huang, G.B.; Lin, Q.; Gay, R. Error minimized extreme learning machine with growth of hidden nodes and incremental learning. IEEE Trans. Neural Netw. 2009, 20, 1352–1357. [Google Scholar] [CrossRef]
- Zhao, X.; Wang, G.; Bi, X.; Zhao, Y. XML document classification based on ELM. Neurocomputing 2011, 74, 2444–2451. [Google Scholar] [CrossRef]
- Zong, W.; Huang, G.B. Face recognition based on extreme learning machine. Neurocomputing 2011, 74, 2541–2551. [Google Scholar] [CrossRef]
- Mohammed, A.A.; Minhas, R.; Wu, Q.M.J.; Sid-Ahmed, M.A. Human face recognition based on multidimensional PCA and extreme learning machine. Pattern Recognit. 2011, 44, 2588–2597. [Google Scholar] [CrossRef]
- Tan, P.; Xia, J.; Zhang, C.; Fang, Q.Y.; Chen, G. Modeling and reduction of NOx emissions for a 700 MW coal-fired boiler with the advanced machine learning method. Energy 2016, 94, 672–679. [Google Scholar] [CrossRef]
- Li, G.; Niu, P.; Ma, Y.; Wang, H.; Zhang, W. Tuning extreme learning machine by an improved artificial bee colony to model and optimize the boiler efficiency. Knowl. Based Syst. 2014, 67, 278–289. [Google Scholar] [CrossRef]
- Wu, B.; Yan, T.H.; Xu, X.S.; He, B.; Li, W.H. A MapReduce-Based ELM for Regression in Big Data. In Proceedings of the International Conference on Intelligent Data Engineering and Automated Learning, Yangzhou, China, 12–14 October 2016; Springer: Cham, Switzerland, 2016; pp. 164–173. [Google Scholar] [CrossRef]
- Luo, M.; Zhang, L.; Liu, J.; Guo, J.; Zheng, Q. Distributed extreme learning machine with alternating direction method of multiplier. Neurocomputing 2017, 261, 164–170. [Google Scholar] [CrossRef]
- Xin, J.; Wang, Z.; Chen, C.; Ding, L.; Wang, G.; Zhao, Y. ELM*: Distributed extreme learning machine with MapReduce. World Wide Web 2014, 17, 1189–1204. [Google Scholar] [CrossRef]
- Dean, J.; Ghemawat, S. MapReduce: A flexible data processing tool. Commun. ACM 2010, 53, 72–77. [Google Scholar] [CrossRef]
- Dean, J.; Ghemawat, S. MapReduce: Simplified data processing on large clusters. Commun. ACM 2008, 51, 107–113. [Google Scholar] [CrossRef]
- McKenna, A.; Hanna, M.; Sivachenko, E.B.A.; Sivachenko, A.; Cibulskis, K.; Kernytsky, A.; Garimella, K.; Altshuler, D.; Gabriel1, S.; Daly, M.; et al. The Genome Analysis Toolkit: A MapReduce framework for analyzing next-generation DNA sequencing data. Genome Res. 2010, 20, 1297–1303. [Google Scholar] [CrossRef]
- Ramírez-Gallego, S.; Fernández, A.; García, S.; Chen, M.; Herreraa, F. Big data: Tutorial and guidelines on information and process fusion for analytics algorithms with MapReduce. Inf. Fusion 2018, 42, 51–61. [Google Scholar] [CrossRef]
- Afrati, F.; Stasinoppulos, N.; Ullman, J.D.; Vassilakopoulos, A. Sharesskew: An algorithm to handle skew for joins in mapreduce. Inf. Syst. 2018, 77, 129–150. [Google Scholar] [CrossRef]
- Shvachko, K.; Kuang, H.; Radia, S.; Chansler, R. The hadoop distributed file system. Mass storage systems and technologies (MSST). In Proceedings of the 2010 IEEE 26th Symposium on Mass Storage Systems and Technologies (MSST), Incline Village, NV, USA, 3–7 May 2010. [Google Scholar] [CrossRef]
- Eberhart, R.; Kennedy, J. A new optimizer using particle swarm theory. In Proceedings of the Sixth International Symposium on Micro Machine and Human Science, Nagoya, Japan, 4–6 October 1995. [Google Scholar] [CrossRef]
- Shi, Y.; Eberhart, R. A modified particle swarm optimizer. Evolutionary Computation Proceedings, 1998. In Proceedings of the 1998 IEEE International Conference on Evolutionary Computation Proceedings. IEEE World Congress on Computational Intelligence (Cat. No.98TH8360), Anchorage, AK, USA, 4–9 May 1998. [Google Scholar] [CrossRef]
- Duda, P.; Dwornicka, R. Optimization of heating and cooling operations of steam gate valve. Struct. Multidiscip. Optim. 2010, 40, 529. [Google Scholar] [CrossRef]
- Duda, P.; Rząsa, D. Numerical method for determining the allowable medium temperature during the heating operation of a thick-walled boiler element in a supercritical steam power plant. Int. J. Energy Res. 2012, 36, 703–709. [Google Scholar] [CrossRef]












{kind=link}
{kind=link}
{kind=link}
{kind=link}
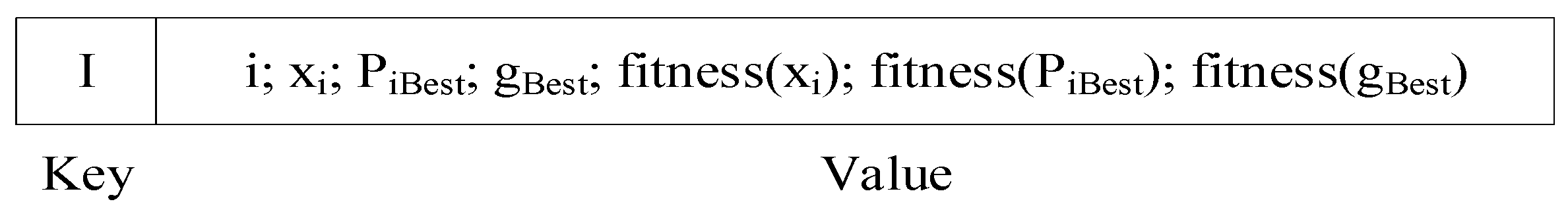{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Parameter | Value | |
|---|---|---|
| NOx emission model | Regularization term (A) | 28 |
| Hidden layer node (L) | 1010 | |
| Boiler combustion efficiency model | Regularization term (A) | 26 |
| Hidden layer node (L) | 1000 |
| NOx | RMSE | MRE | R2 |
|---|---|---|---|
| Training set | 0.0436 | 0.0481 | 0.863 |
| Testing set | 0.0313 | 0.0423 | 0.891 |
| Boiler Combustion Efficiency Data | RMSE | MRE | R2 | ||||||
|---|---|---|---|---|---|---|---|---|---|
| Max | Min | Means | Max | Min | Means | Max | Min | Means | |
| Training set | 0.0189 | 0.0065 | 0.0152 | 0.0361 | 0.0101 | 0.0278 | 0.9876 | 0.8944 | 0.9256 |
| Test set | 0.0153 | 0.0087 | 0.012 | 0.0227 | 0.0141 | 0.0187 | 0.9766 | 0.9275 | 0.9538 |
| Parameter Limit | SAPB/kpa | SAS/m·s−1 | |||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|
| SP | A(R) | A(L) | C(R) | C(L) | C | D(R) | D(L) | D | E(R) | E(L) | |
| Upper | −0.25 | 97.17 | 81.52 | 97.49 | 83.51 | 175.5 | 104.39 | 100.56 | 202.86 | 104.29 | 73.4 |
| Lower | −0.7 | 67.28 | 58.09 | 45.62 | 31.89 | 77.35 | 13.73 | 20.66 | 36.91 | 22.37 | 16.12 |
| Parameter Limit | SAS/m·s−1 | SAT/oC | SAF/t/h | SAPB/kpa | SAF/t/h | |||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| E | F(R) | F(L) | F | A | B | R1 | R2 | R3 | R | L1 | ||
| Upper | 178 | 128 | 91.7 | 216.8 | 28.1 | 34.4 | 328 | 325.7 | 326 | 326.1 | 1.09 | 341.54 |
| Lower | 39.8 | 42.3 | 55.4 | 99.57 | 22.3 | 22.2 | 288 | 290.9 | 288 | 290.9 | 0.3 | 302.53 |
| Parameter Limit | SAF/t/h | SAPB/kpa | CFCP/T·H−1 | PAS/m·s−1 | ||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| L2 | L3 | L | A | B | C | D | E | F | A | B | ||
| Upper | 340 | 339 | 339.2 | 2.06 | 54.95 | 54.63 | 56.79 | 58.69 | 51.91 | 54.12 | 106.6 | 99.73 |
| Lower | 301 | 301 | 301.6 | 0.74 | 20.23 | 31.93 | 0 | 0 | 0 | 0 | 57.62 | 68.9 |
| Parameter Limit | PAS/m·s−1 | DOP/% | ||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| C | D | E | F | R1 | L1 | R2 | L2 | R3 | L3 | R4 | L4 | |
| Upper | 100.06 | 104.2 | 102.1 | 92.02 | 50.18 | 50.58 | 50.31 | 55.29 | 99.25 | 98.7 | 100 | 100 |
| Lower | 56.88 | 59.88 | 50.08 | 55.52 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| Working Condition | Boiler Load/MW | Exhaust Temperature/°C | Coal Quality Parameters | Oxygen Content of Flue Gas/% | ||||||
|---|---|---|---|---|---|---|---|---|---|---|
| Total Moisture/% | Air-Dried Moisture/% | Dry Base Ash/% | Entrance A | Entrance B | Entrance C | Exit A | Exit B | |||
| 18,001 | 349.1 | 129.58 | 10.6 | 2.71 | 31.93 | 5.35 | 5.45 | 5.54 | 8.37 | 6.99 |
| Weights | Pre or Post | NOx Emission/mg/m3 | Boiler Combustion Efficiency/% | SAPB/kpa | SAP/m·s−1 | ||||
|---|---|---|---|---|---|---|---|---|---|
| SP | A(R) | A(L) | C(R) | C(L) | C | ||||
| Pre | 412 | 93.39 | −0.47 | 77.92 | 68.51 | 46.43 | 34.01 | 81.34 | |
| α = 0.9, β = 0.1 | Post | 330.42 | 93.81 | −0.7 | 67.28 | 58.09 | 73.45 | 31.89 | 163.3 |
| α = 0.8, β = 0.2 | Post | 333.29 | 93.84 | −0.25 | 67.28 | 58.09 | 97.49 | 54.53 | 119.8 |
| α = 0.7, β = 0.3 | Post | 345.56 | 93.85 | −0.25 | 67.28 | 58.09 | 45.62 | 31.89 | 147.6 |
| α = 0.6, β = 0.4 | Post | 340.6 | 93.86 | −0.25 | 67.28 | 58.09 | 97.49 | 83.51 | 175.5 |
| α = 0.5, β = 0.5 | Post | 374.35 | 93.945 | −0.47 | 67.28 | 58.09 | 79.57 | 83.51 | 175.5 |
| Weights | Pre or Post | SAS/m·s−1 | ||||||||
|---|---|---|---|---|---|---|---|---|---|---|
| D(R) | D(L) | D | E(R) | E(L) | E | F(R) | F(L) | F | ||
| Pre | 84.99 | 85.84 | 169.39 | 89.63 | 64.62 | 153.6 | 49.28 | 63.08 | 111.39 | |
| α = 0.9, β = 0.1 | Post | 13.73 | 20.66 | 36.91 | 22.37 | 16.12 | 39.78 | 42.29 | 55.4 | 99.57 |
| α = 0.8, β = 0.2 | Post | 13.73 | 20.66 | 36.91 | 22.37 | 16.12 | 39.78 | 42.29 | 55.4 | 99.57 |
| α = 0.7, β = 0.3 | Post | 13.73 | 20.66 | 36.91 | 22.37 | 16.12 | 39.78 | 42.29 | 55.4 | 99.57 |
| α = 0.6, β = 0.4 | Post | 13.73 | 20.66 | 36.91 | 22.37 | 16.12 | 39.78 | 127.78 | 55.4 | 99.57 |
| α = 0.5, β = 0.5 | Post | 13.73 | 100.56 | 36.91 | 22.37 | 16.12 | 39.78 | 42.29 | 55.4 | 99.57 |
| Weights | Pre or Post | SAT/°C | SAF/t/h | SAPB/kpa | SAF/t/h | ||||
|---|---|---|---|---|---|---|---|---|---|
| A | B | R1 | R2 | R3 | R | L1 | |||
| Pre | 23.8 | 24.75 | 308.81 | 308.52 | 307.58 | 308.52 | 0.42 | 317.1 | |
| α = 0.9, β = 0.1 | Post | 22.3 | 22.18 | 288.02 | 290.84 | 287.83 | 290.84 | 0.66 | 341.54 |
| α = 0.8, β = 0.2 | Post | 28.1 | 28.789 | 288.02 | 290.84 | 287.83 | 290.84 | 1.09 | 341.54 |
| α = 0.7, β = 0.3 | Post | 28.1 | 22.18 | 288.02 | 290.84 | 287.83 | 290.84 | 0.82 | 341.54 |
| α = 0.6, β = 0.4 | Post | 27.7 | 22.18 | 288.02 | 290.84 | 287.83 | 290.84 | 0.85 | 341.54 |
| α = 0.5, β = 0.5 | Post | 28.1 | 29.87 | 288.02 | 290.84 | 287.83 | 290.84 | 0.79 | 341.54 |
| Weights | Pre or Post | SAF/t/h | SAPB/ kpa | CFCP/T·H−1 | |||||
|---|---|---|---|---|---|---|---|---|---|
| L2 | L3 | L | A | B | C | D | |||
| Pre | 315.45 | 314.91 | 315.73 | 0.99 | 42.55 | 49.2 | 0 | 53.96 | |
| α = 0.9, β = 0.1 | Post | 339.44 | 338.27 | 339.2 | 1.52 | 20.23 | 51.7 | 56.79 | 20.2 |
| α = 0.8, β = 0.2 | Post | 339.44 | 331.42 | 339.2 | 2.06 | 20.23 | 54.7 | 0 | 18.68 |
| α = 0.7, β = 0.3 | Post | 323.97 | 332.24 | 339.2 | 1.31 | 28.53 | 42 | 56.79 | 0 |
| α = 0.6, β = 0.4 | Post | 339.44 | 301.12 | 339.2 | 2.06 | 20.23 | 53.5 | 0 | 58.69 |
| α = 0.5, β = 0.5 | Post | 333.43 | 338.27 | 339.2 | 0.74 | 54.95 | 54.6 | 56.79 | 18.69 |
| Weights | Pre or Post | CFCP/T·H−1 | PAS/m·s−1 | ||||||
|---|---|---|---|---|---|---|---|---|---|
| E | F | A | B | C | D | E | F | ||
| Pre | 40.56 | 0 | 87.07 | 90.17 | 60.04 | 95.37 | 79.02 | 60.05 | |
| α = 0.9, β = 0.1 | Post | 0 | 38.23 | 106.6 | 68.9 | 100.06 | 104.21 | 50.08 | 80.9 |
| α = 0.8, β = 0.2 | Post | 51.91 | 44.12 | 57.62 | 99.73 | 100.06 | 68.21 | 50.08 | 84.74 |
| α = 0.7, β = 0.3 | Post | 51.91 | 0 | 106.6 | 68.9 | 100.06 | 104.21 | 50.08 | 92.02 |
| α = 0.6, β = 0.4 | Post | 0 | 54.12 | 106.6 | 99.73 | 100.06 | 59.88 | 97.53 | 55.52 |
| α = 0.5, β = 0.5 | Post | 26.9 | 0 | 106.6 | 68.9 | 100.06 | 104.21 | 102.04 | 79.17 |
| Weights | Pre or Post | DOP/% | |||||||
|---|---|---|---|---|---|---|---|---|---|
| R1 | L1 | R2 | L2 | R3 | L3 | R4 | L4 | ||
| Pre | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | |
| α = 0.9, β = 0.1 | Post | 30.43 | 50.58 | 50.31 | 55.29 | 99.25 | 98.7 | 100 | 100 |
| α = 0.8, β = 0.2 | Post | 50.18 | 50.58 | 50.31 | 55.29 | 99.25 | 98.7 | 0 | 100 |
| α = 0.7, β = 0.3 | Post | 50.18 | 50.58 | 50.31 | 55.29 | 99.25 | 98.7 | 100 | 100 |
| α = 0.6, β = 0.4 | Post | 50.18 | 50.58 | 50.31 | 55.29 | 99.25 | 98.7 | 100 | 100 |
| α = 0.5, β = 0.5 | Post | 50.18 | 0 | 50.31 | 55.29 | 99.25 | 98.7 | 0 | 100 |
© 2019 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Xu, X.; Chen, Q.; Ren, M.; Cheng, L.; Xie, J. Combustion Optimization for Coal Fired Power Plant Boilers Based on Improved Distributed ELM and Distributed PSO. Energies 2019, 12, 1036. https://doi.org/10.3390/en12061036
Xu X, Chen Q, Ren M, Cheng L, Xie J. Combustion Optimization for Coal Fired Power Plant Boilers Based on Improved Distributed ELM and Distributed PSO. Energies. 2019; 12(6):1036. https://doi.org/10.3390/en12061036
Chicago/Turabian StyleXu, Xinying, Qi Chen, Mifeng Ren, Lan Cheng, and Jun Xie. 2019. "Combustion Optimization for Coal Fired Power Plant Boilers Based on Improved Distributed ELM and Distributed PSO" Energies 12, no. 6: 1036. https://doi.org/10.3390/en12061036
APA StyleXu, X., Chen, Q., Ren, M., Cheng, L., & Xie, J. (2019). Combustion Optimization for Coal Fired Power Plant Boilers Based on Improved Distributed ELM and Distributed PSO. Energies, 12(6), 1036. https://doi.org/10.3390/en12061036