1. Introduction
In the last several years, an increasing interest on the energy themes focused on the reduction of emissions from fossil sources has led the researchers to develop solutions oriented to improve the users’ energy awareness in everyday life actions, as well as to assist them to better schedule these actions. Among these solutions, Non-Intrusive Load Monitoring (NILM) is surely one of the most studied [
1], in addition to other useful ones, such as energy management and analytic [
2,
3], load task scheduling [
4], or behaviour-based consumption [
5]. These algorithms require high computational burden, since their results could be requested in real time to provide an immediate feedback to the user. In order to limit the computational burden of the algorithms, strategies to reduce the amount of data required by the applications could be taken into account. Focusing on the energy consumption in a domestic scenario, in particular on the measurement of the appliance power signal, many time instants do not present occurrences of noteworthy events, such as the absence of power consumption (or consumption above a minimal threshold), i.e., at night and/or holidays, or time slots with a reduced variation (low variance) of the power consumption profile (steady state of an appliance). Therefore, in such scenarios, a data reduction policy is a possible solution. In contrast, during the active periods, a higher level of detail of the power consumption trace is needed in order to guarantee the reliability of the advanced elaboration service.
Nowadays, data acquisition systems are more and more oriented towards the use of cloud computing resources, where centralized services can handle multiple requests. Such infrastructure topology is directly applicable in the residential energy scenario, where a smart meter samples the power consumption trace on the domestic power supply line and, by means of an Internet connection, sends the data to the elaboration service on cloud. This scenario lies among the Internet of Things (IoT) paradigm, which points toward the development of minimal devices capable of acquiring and pre-process signals keeping a low elaboration power. Specifically, IoT devices are designed to meet low power requirements, in order to have an improved battery life and longer life-span. To pursue this goal, these devices will demand the main data elaborations to dedicated cloud centres with a high computational power. Therefore, the introduction of application-oriented data reduction policies results beneficial also from the point of view of the acquisition infrastructure, i.e., reduce the overall data stream in order to limit the bandwidth requirements and support more data streams towards the cloud service.
State-of-the-Art
In the scientific literature, several techniques have been proposed to deal with the NILM problem, with different purposes, based on the steady states or transient states [
6,
7].
The kind of signal trait used for addressing the task depends on the signal detail needed, which reflects on different sampling frequencies. The authors of [
8] propose a qualitative performance trend of the disaggregation algorithms for different sampling frequencies. Generally, despite the task to be solved depending on the algorithm formulation, the disaggregation accuracy decreases proportionally with the sampling frequency. A detailed study of Hidden Markov Model-based (HMM) algorithms has been conducted in [
9], where the authors evaluated the algorithms performance for sampling rates ranging to 1 s to 6 min by using the REDD dataset. Generally, they found that higher sampling rates provide more accurate disaggregation results. Similarly, the work presented in [
10] evaluates the effects of sampling rate reduction on the performance of Factorial Hidden Markov Model (FHMM) and sparse-matrix-based algorithms for NILM [
11,
12]. The authors evaluated different sampling periods, from 6 s to 15 min, and they showed that the performance degrades nonlinearly as the sampling rate decreases. Basu et al. [
13] evaluated the performance of two event-based algorithms operating at different sampling rates 10 s and 15 min, and they observed that the latter achieves the lowest performance.
These outcomes highlight the need to pursue ad hoc strategies for data reduction in order to maintain details on the signal, otherwise it is reasonable to expect a deterioration in performance with low sampling rates. Indeed, this assumption is confirmed by the strategies of data reduction proposed in the literature that are focused either on the transmission of data only when significant changes are detected, or on the compression of data before transmission. In the former group, the acquired samples are transmitted to the NILM algorithm only when relevant events occur in the aggregate power signal [
14,
15,
16,
17,
18,
19,
20]. Generally, these methods reduce the amount of data during the transmission preserving the details of the original signal, but they depend on the reliability of the event detection method applied to the aggregated power signal. In addition, many state-of-the-art approaches rely on the profile reconstruction before the application of the NILM algorithm. In this sense, the algorithm does not deal with the data reduction of the aggregate power consumption, but it is applied to the signal at original frequency. The reliability of this procedure is strictly dependent on the relevant samples detection, and on the profile reconstruction technique as well.
In the second class of approaches, data reduction is achieved through lossless or lossy compression algorithms, and they are used depending on the transmission requirements to be satisfied. A study on sampling rate reduction of aggregated power signal and its effects on NILM algorithms has been conducted in [
21]. The authors presented a method based on compressed sensing (CS) to reach a lower-than-Nyquist sampling rate. Moreover, the work investigated how the restrictions to the CS sensing matrix associated with random filtering and demodulation affects signal recovery and NILM performance. The experiments have been conducted on the BLUED [
22] dataset, exploiting the voltage and current waveforms of the aggregate signals, and reporting the percentage error rate (PER) of the working state prediction of each appliance. The results have shown that the proposed approaches can give better NILM performance than direct subsampling with a NILM algorithm based on the one proposed in [
23].
As discussed above, the state-of-the-art highlights the lack of direct evaluations of NILM algorithms with data reduction techniques. Indeed, in event-based approaches [
14,
15,
16,
17,
18,
19,
20], the focus is mainly on the evaluation of the transient event, with a resolution on the NILM problem using a classification approach on the events detected or by reconstructing the signal at original rate. On the other hand, in the data-compression based approach [
21], the goal is to analyse the entire signal and to compress the information exploiting its sparsity. Despite the study presenting a similar aim to the one of the authors’ work, its peculiarity lies in the application with a high frequency sampled waveform, with the reconstruction of the signal at the original rate before the application of the NILM algorithm.
The authors’ interest here is on the resolution of the NILM problem with an ad hoc data reduction strategy for a residential environment, i.e., where power consumption signals are acquired by means of smart meters, thus signals at sub-Hz frequencies. The work focus is on the application of an algorithm which allows to easily manage various sampling frequencies of the power consumption signal, as well as without a significant loss of performance. Specifically, up to the authors’ knowledge, none of the studies have evaluated reduction strategies on the Neural NILM approach, proposed in [
24]. Indeed, Neural NILM provides a flexible solution, from the point of view of the subsampling schema, e.g., uniform and non-uniform, which can take advantage of the possibility of characterizing each appliance with a different and dedicated network topology. In addition, this algorithm exploits both the transient and the steady states information for the disaggregation aim, which allows for managing the NILM problem with a higher information level with respect to other approaches. Specifically, the disaggregated outputs carry on the total information of the appliances contribution, i.e., the events occurred and the detailed energy consumption in the observation period.
The outline follows. Problem statement and work motivations are discussed in
Section 2.
Section 3 proposes an overview of the uniform and non-uniform subsampling strategies, and in
Section 3.1 details on the adopted network topology are provided.
Section 4 reports the experimental setup and the adopted evaluation methods. Results’ discussion and advanced considerations are reported in
Section 5. Finally,
Section 6 concludes the paper.
2. Problem Statement and Motivations
The consumption power signal of any appliance is generally composed of a set of different working states (including power off/on states), and it can be represented in terms of portions of signal based on the presence of more or less rapid changes. Therefore, generally speaking, the signal portions can be classified in either steady states or transient states [
6]. Moreover, it is considered that the analogue power signal is sampled at a specific frequency, denoted as original sampling rate from here on.
Under this assumption, it is natural to consider the possibility to apply an ad hoc subsampling strategy in order to preserve a higher level of detail during the transients, e.g., keep the original sampling rate, whereas they downsample the signal during the steady phases. In fact, aiming to create models as generic as possible to represent the different typologies of appliances, the adopted information cannot refer to the consumption levels only, i.e., the steady states, but has to exploit the details contained in the transition states as well. In this way, it is possible to guarantee the ability to discriminate the type of appliance (transient-based features widely use to appliance identification [
6]), as well as to reduce the overall amount of data processed and transmitted to the elaboration service in compliance with the IoT paradigm. For example, in a real system, the smart meter will store in a buffer the data acquired at the original sampling rate, whereas only the sub-sampled data are continuously sent, after proper pre-processing. Whenever a transition state is automatically detected, the appropriate amount of data in the buffer, at the original sampling rate, will be forwarded to the remote system that performs the disaggregation.
Considering the application of this idea to the NILM paradigm, where the system receives as input the aggregated signal and disaggregates it to produce the signals related to each appliance, two main problems arise. On the one hand, the data acquisition system should be capable of exactly discerning between steady and transient states by analysing the aggregated signal only, in order to modulate the subsampling activity. On the other hand, the disaggregation algorithm should be capable of properly operating with subsampled data (thus reduced information), in order to either reach performance equivalent to the system without subsampling (reference system), or to achieve a marked reduction in the data required by the elaboration system against a modest deterioration in performance.
The state-of-the-art discussed in the previous section confirms the practicability to apply a non-uniform subsampling strategy at the aggregated data, keeping a high level of signal detail. On the other hand, up to the authors’ knowledge, the state-of-the-art discussion highlighted a lack of techniques for the data reduction, both based on event-detection or data compression, directly applied and evaluated with NILM algorithms, in order to understand how the data reduction itself can affect the NILM performance. Specifically, neither uniform or non-uniform subsampling approaches have been evaluated in combination with the Neural NILM.
The main objective of this paper is the evaluation of the latter issue by considering the Neural NILM [
24] approach as the disaggregation algorithm. In order to validate the ad hoc subsampling strategy, an extended evaluation study is presented, providing a comparison among the application of different sampling rate on different datasets. In particular, the signal processed by the ad hoc subsampling strategy, called non-uniform subsampling (NUS), can be decomposed in a signal uniformly subsampled (thus applying a uniform subsampling—US), and portions of signal sampled at the original sampling rate (OS). Therefore, in order to provide a comprehensive evaluation, it is needed to compare the NUS performance against the one achieved by applying only a US and the performance at the OS. Moreover, the evaluations will also consider the application of different subsampling rates and different lengths of the transition windows for the NUS.
It should be noted that the detection the appliance states, i.e., steady and transient phases of the power signal, lies outside the scope of this work. Specifically, the aim here is to evaluate the NILM algorithm performance in different US and NUS conditions, minimizing external causes of errors, such as the erroneous detection of a state. However, requiring the knowledge of the appliance state, the algorithm relies on the clustering approach presented in [
25].
Finally, the overall data reductions achievable with different NUS strategies, in contrast to the US ones, are reported and discussed.
3. NUS in Neural NILM
The aggregate power in a household electrical circuit is composed of contributions due to known loads, i.e., the power consumption related to loads modelled in the NILM algorithm, and to unknown contributions or noise components, i.e., the power consumption related to unmodeled loads and noise present in the circuit. Specifically, the total active power,
, can be expressed as:
where
is the number of modelled appliances—known contributions,
denotes the active power signal of the
i-th appliance, and
is the overall noise component—unknown contributions and circuit noise. The NILM paradigm relies on the extraction of the power consumption of the
i-th appliance,
, from the aggregate power signal, removing the remaining components
, and can be formulated as:
Under this assumption, a
denoised condition is expressed as:
where it is assumed that the aggregated power consumption signal is composed of known appliances only, without additional unknown contributions—loads—or sources of noise. Therefore, the noise component
is set equal to zero, and Equation (
2) can be reformulated as shown in Equation (
3). The assumption of a
denoised scenario allows for avoiding undesired signals from masking the small signal fluctuations of a specific appliance out of the aggregated signal. Therefore, working in a
denoised scenario allows the acquisition system to ideally perform an exact detection of the variations in the aggregated signal and discerns the occurrences of steady and transient states. The
noised scenario, on the other hand, represents a more realistic case study and it has been considered in the experimental evaluation. Assuming that the power signal is acquired by a measurement system capable of providing samples at a sub-Hz sampling rate, the expectation is that it is possible to further “downsample” the signal during the appliance steady states without losing essential information, while the sampling rate is kept unchanged in the transition states, in order to preserve the information. Specifically, the sampling rate reduction in a specific portion of the signal (the steady state) allows for reducing the amount of data to be processed by the algorithm, thus lowering the computational burden. On the other hand, this operation decreases the data transmitted from a smart meter to the disaggregation service host.
As discussed in the previous section, in order to keep the original sampling rate during the transition samples, and to apply the downsampling only in the steady phases, an ad hoc non-uniform subsampling strategy is applied. The proposed US and NUS processing operations are used on the aggregated data, already sampled at the OS rate; therefore, the approach differs from the nonuniform sampling theory applied to analogue signals [
26]. Specifically, as depicted in
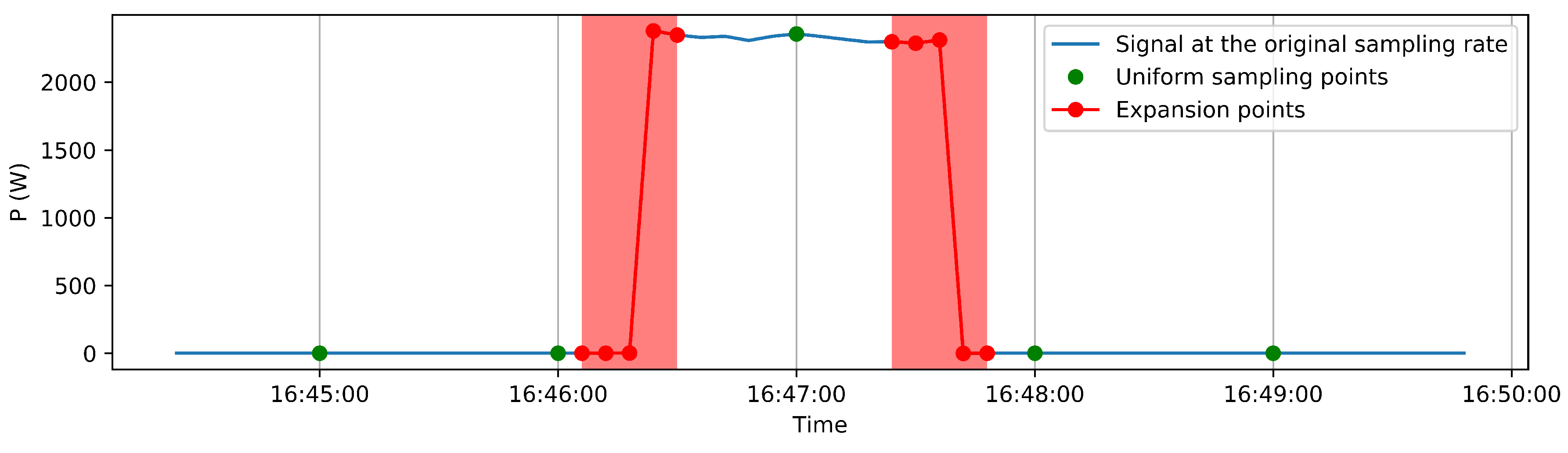
Figure 1, during the subsampling processing, if a transition state is encountered, the algorithm collects a predetermined number of samples at the original sampling rate, creating a selection window centred at the middle of the transition edge, and thus providing a set of equal distributed samples centred on this event. As a result, considering a vector of constant length as network input, depicted in
Figure 2, an overall shorter time interval with respect to the case of uniform subsampled points only, i.e., the green ones, will be represented.
The selection window, which marks the signal portion to be acquired at the original sampling rate, is called expansion window, and its length is expressed in terms of samples number at the original rate, called expansion rate (ER). In fact, considering the majority of the signal being subsampled, from the receiver point of view, the signal is expanded/upsampled, providing additional level of details when a transition phase is met.
Together with the selection window, a uniform subsampling is performed for the remaining data, i.e., the steady states. The general subsampling period applied is expressed by means of the parameter subsampling rate (SR) that specifies the multiplication factor applied to the original sampling rate, which corresponds to the sampling period increasing factor.
Denoting with
, with
where
N is the number of samples, the
n-th sample at the original sampling rate for a given active power signal, the vector
of the original sampling samples is defined as:
Accordingly, the vector
of uniform subsampled samples at SR
is obtained as:
where
is the integer part of
x. Finally, the vector
of non-uniform subsampled samples at
and
is expressed as:
where
, with
L the number of expansion windows, denotes the set of the indices corresponding to each transient state within the
N samples, i.e., the centres of the expansion windows.
The number of elements of , , and are denoted, respectively, as , , and . Essentially, the number of samples at original sampling, , is equal to the total number of samples N, in the US case , whereas, in the NUS case, depends on the parameters used in the subsampling procedure.
The detection of transient states is precomputed for each appliance independently, after which all the detections are gathered over a common time base. This information is provided to the pre-processing algorithm which performs the US and/or NUS on the aggregated data and returns the data to be use as network input. In the transients’ detection, the working state changes as well as the power-on/off switching activities are taken into account as transient states.
3.1. Neural NILM
The neural network architecture used for load disaggregation uses CNN layers, and it is based on the architecture proposed by Kelly et al. [
24], and further studied by the authors [
27,
28].
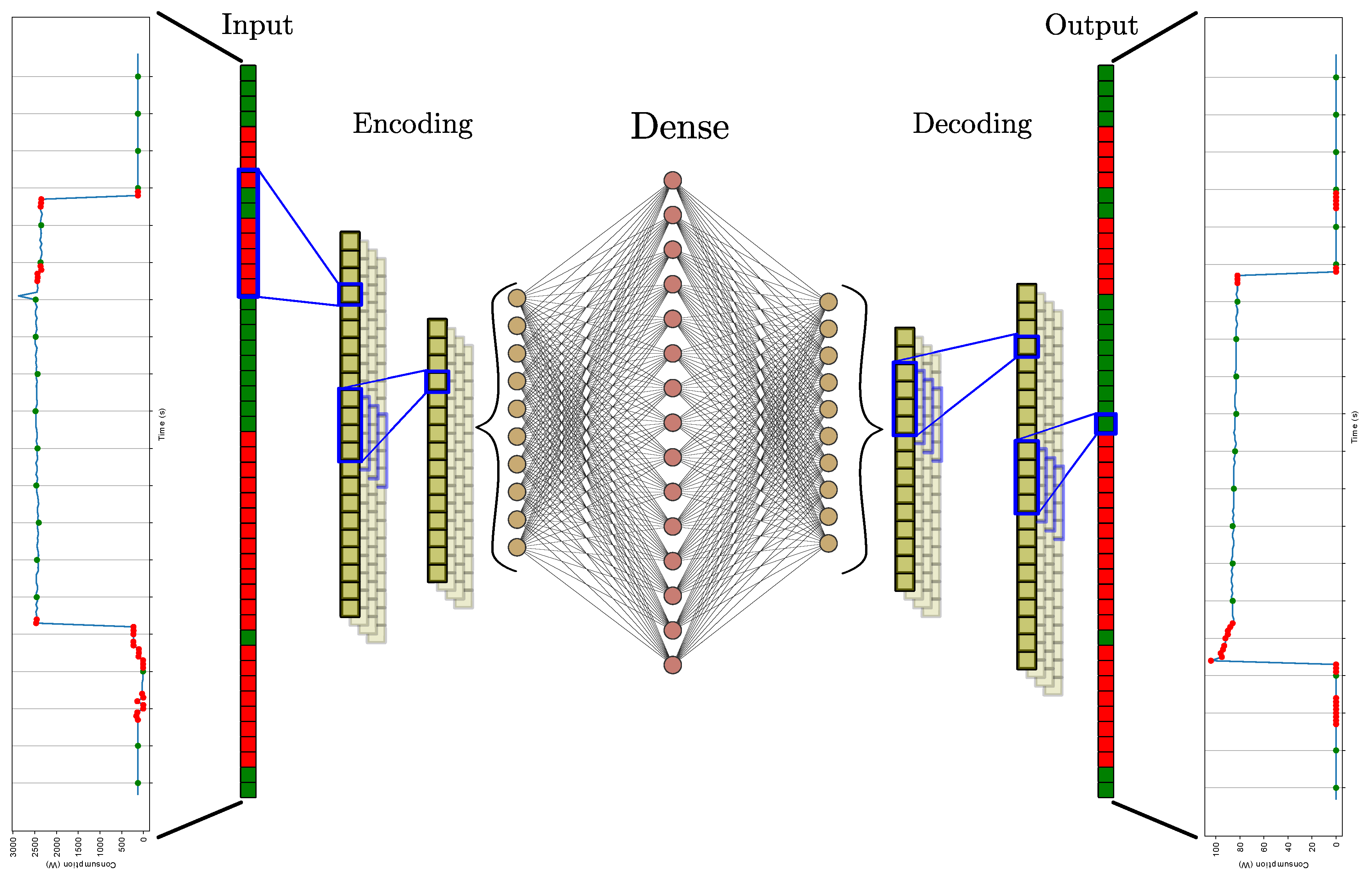
As depicted in
Figure 2, the structure is based on the auto-encoder topology, where both encoding and decoding portions are composed of convolutional layers concatenated to a linear activation function and a max pooling layer. The encoding stage ends with a fully connected network based on ReLU activation function [
29], denoted as dense layer in
Figure 2. Symmetrically, in the decoding stage, the upsampling layers replace the max pooling ones.
The introduction of the max pooling operation allows the network to develop an independent behaviour with respect to location of the activation inside the input window. Moreover, a reduction of the features maps size is achieved, with a consequent reduction of the input neurons number in the dense layer. Additionally, in order to respect the constraint of non-negative active power, a ReLU activation has been adopted.
The Stochastic Gradient Descent (SGD) algorithm with Nesterov momentum [
30] is used in the training phase, and an early stopping technique is adopted in order to prevent overfitting. The network is trained providing an aggregated signal (window) as input and the corresponding disaggregated signal of a specific appliance as output. The loss between input and output is quantifies in terms of mean squared error (MSE).
In the disaggregation phase, the input provided to the network corresponds to a sliding window portion of the aggregated power signal with a specific stride. Therefore, the output/disaggregated signal has to be properly reconstructed, since it presents more or less overlapping windows based on the stride values. Specifically, the lower the stride, the higher the number of windows overlapped. In order to produce the output signal, the samples are recombined by calculating a mean or a median operation at each time instant. Both operations are evaluated because they both present shortcomings. In the case of the mean operation, averaging the overlapped portions could produce an overall underestimated signal. On the contrary, the median operation produces a better estimate, erasing the outliers that are typically near to zero, only in the case of reliable samples statistic.
The approach based on denoising autoencoders used here for disaggregation employs an individual neural network for each appliance of interest [
24]. As will be evident in the experimental evaluation (
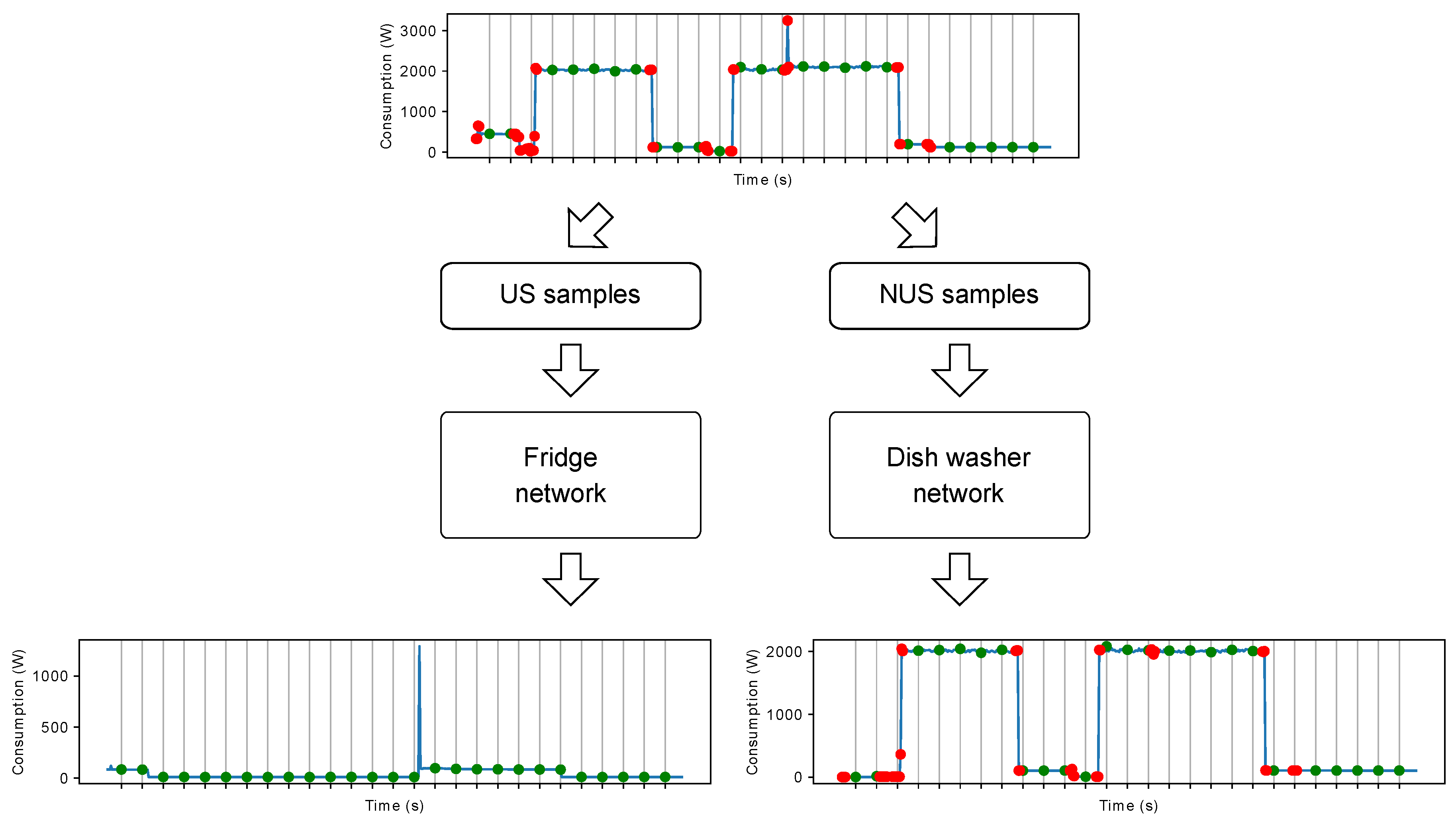
Section 5), the best performing subsampling method can be appliance-dependent, and using an individual network for each appliance allows for combining the US and NUS techniques. An example of this solution applied to the fridge and dishwasher appliances is depicted in
Figure 3. In the example, the fridge network takes as input the US samples (the green points in
Figure 3), while the dishwasher network uses the NUS samples, i.e., both the green and the red points in
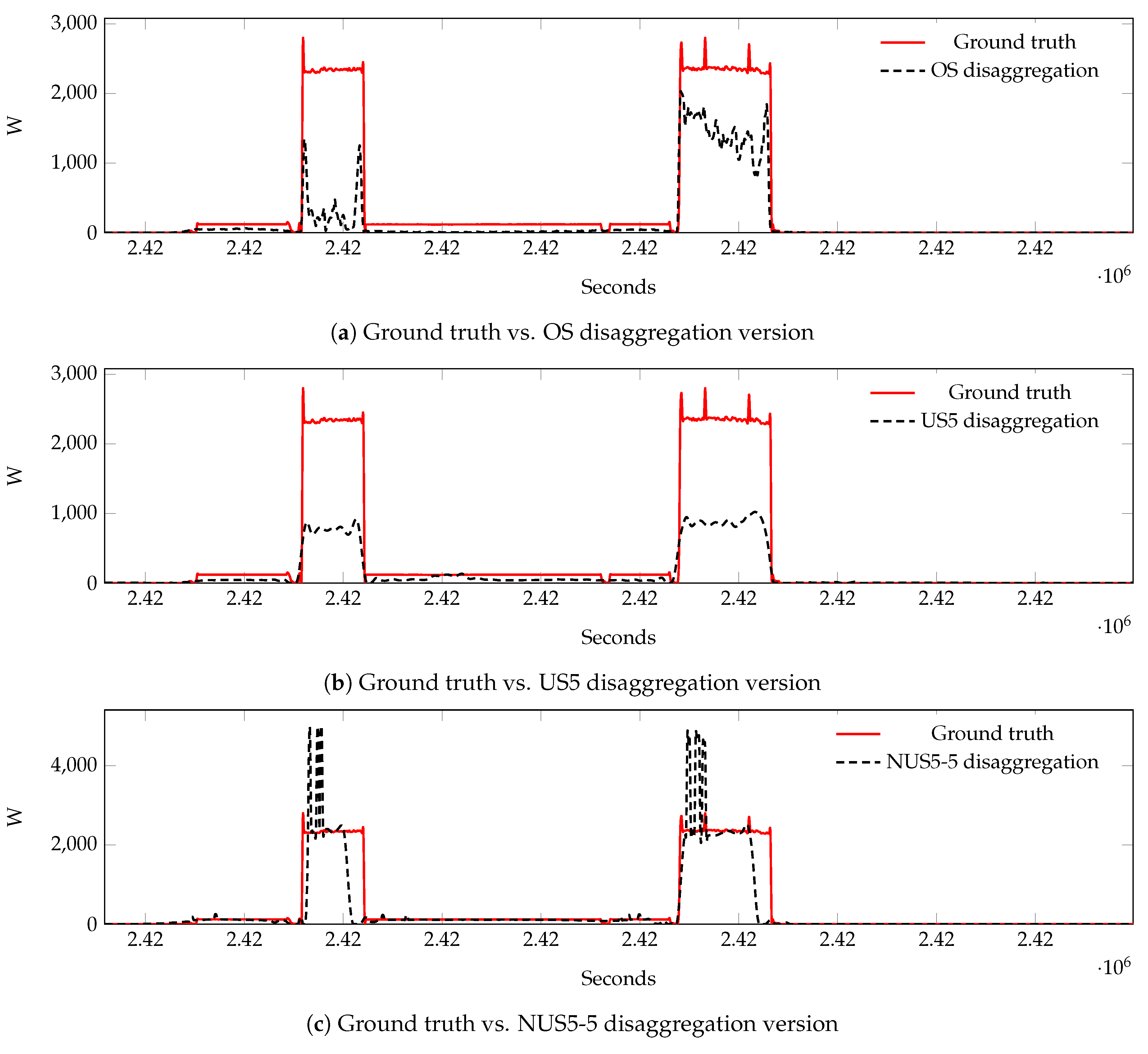
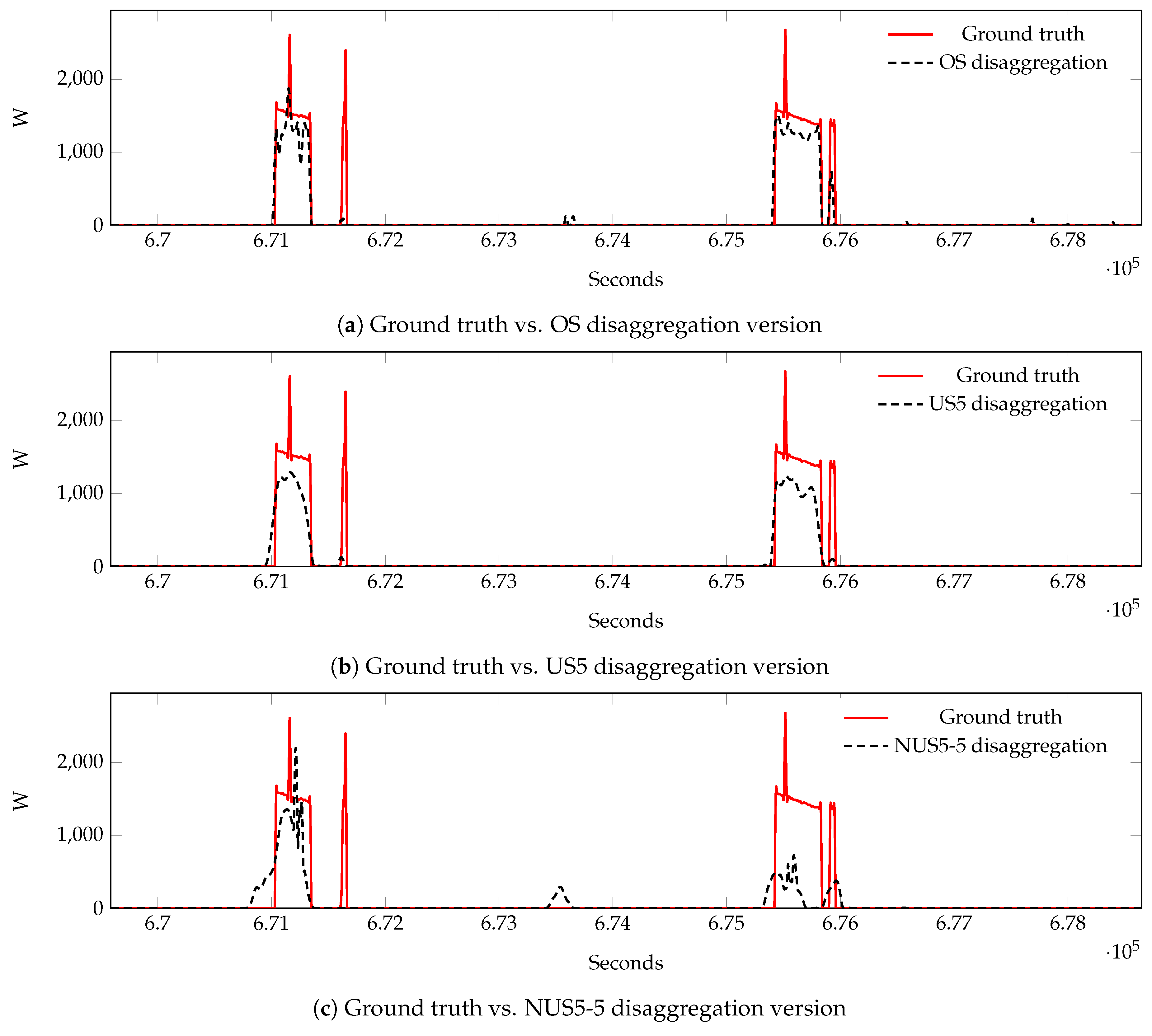
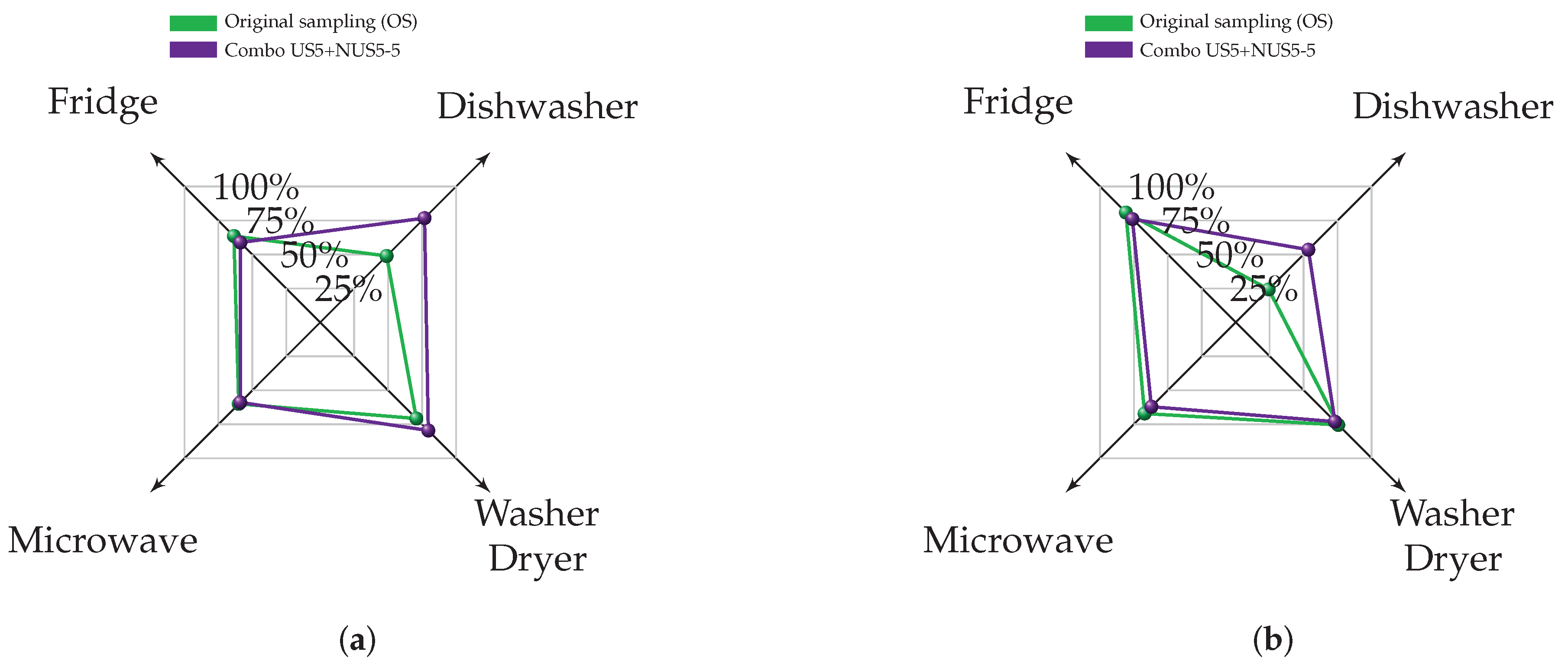
Figure 3. Clearly, each network provides an estimate only for the samples at its input. Assuming that the most performing subsampling method for the fridge is US and for the dishwasher is NUS, this solution allows for achieving a higher disaggregation performance compared to the use of a single technique.
4. Experimental Setup
The experiments have been conducted on active power signals contained in the UK-DALE [
31] and the REDD [
11] datasets both in the
denoised and
noised conditions. The
denoised condition has been considered since it allows for evaluating the algorithms avoiding undesired signals from masking the small signal fluctuations of a specific appliance out of the aggregated signal. On the other hand, the
noised condition represents the common situation encountered in real application scenarios.
Train and test data are extracted using the time intervals adopted in [
28] for the UK-DALE dataset,
Table 1, and the ones assumed in [
27] in the case of REDD dataset,
Table 2. Specifically, within the given intervals, the activations and the corresponding
silence are extracted for each appliance. The first
of the activations are adopted as validation data, whereas the remaining
are combined with
silence to compose the batches for the model training. A mean and variance normalization is applied to each batch, whose parameters (mean and variance) are computed from a random sample of the training set. Differently, a min-max normalization is performed on the target data, adopting the maximum power consumption for the corresponding appliance.
The availability of signals acquired in several buildings allows the evaluation of the algorithm performance in
seen and
unseen conditions. For each appliance, in the case of
seen condition, two buildings are used both for training and testing, whereas, in the case of
unseen condition, the model is trained on the same data used in the
seen condition, then tested over the data related to a different building. The number of buildings used for each dataset has been limited according to the specifications of [
27].
The experiments presented in the following sections are conducted both in US and NUS conditions, as well as at OS. The sampling rate adopted as OS rate is 6 s. In particular, the UK-DALE dataset already provides data at this rate, whereas the REDD dataset has been downsampled. In the case of US, a fixed, reduced sampling rate is applied at the whole data without discrimination of the appliance working state. On the other hand, in case of NUS, both subsampling and expansion window, as discussed above, are applied. As a general notation, for the experiments conducted with US, the subsampling rate is expressed with a number concatenated to the string “US”, for example with a SR = 10 the experiment is denoted as US10. In the case of NUS, both SR and ER are concatenated to the string “NUS” and separated from each other by the symbol “-”, i.e., for SR = 10 and ER = 10, the NUS experiment is marked as NUS10-10.
As discussed above, the NUS experiments require the knowledge of all the possible state transitions of all the appliance in the aggregated signal. However, being the scope of the work to provide an extensive validation of the NUS idea, the evaluations have been performed by assuming an a priori knowledge of the transition points (oracle scenario), therefore minimizing the occurrence of errors (expansion windows badly positioned) due to wrong estimations of the state transition points. A detection as accurate as possible of the state changes has been carried out by processing each appliance separately. The information generated for each appliance, composed of pairs timestamp—state label, is then combined in an aggregated ground-truth. The process relies on the estimation of the different power levels, i.e., working states, by applying a k-means algorithm [
32]. At first, the clustering procedure is executed over the whole train set by setting a predefined number of clusters for the appliance to be evaluated. Gaussian variables, mean and variance, are inferred for each cluster, then exploited in the state classification over the test set. At this point, to reveal the transition instants, the difference between each label and the previous one is performed over the output time series that contains the detected states. More details concerning the whole procedure are available in [
25].
The hyperparameters of the neural networks have been determined by conducting a grid search separately for the two datasets. This procedure allows for determining the most performing configurations, that, however, are specific for the target dataset. This represents a general problem for neural networks-based algorithms [
33,
34], and here it has not been taken into account, since the main focus of this paper is the evaluation of different sampling strategies regardless the network topology.
Regarding the UK-DALE dataset, the experiments have been performed by conducting a grid search within the following sets: for the kernels dimension, [32, 128] for the number of features maps, [2, 4] for the pool size of the pooling layer, [512, 4096] for the number of neurons in the dense layer. Moreover, 2 CNN layers have been adopted in both encoding and decoding stages: in the former stage, the number of feature maps of the second layer is twice the number of feature maps in the first layer, while it is the opposite for the decoder. In the case of REDD dataset, after a preliminary evaluation, only one CNN layer has been taken into account, whereas the grid search has been performed over a wider set for each parameters with respect to the UK-DALE. Specifically, the set has been assumed for the kernels dimension, [8, 16, 32, 128] for the number of features’ maps, [1, 2, 4] for the pool size of the pooling layer, and [128, 512, 4096] for the number of neurons in the dense layer.
For both datasets, in the pooling layers, the pooling stride has been fixed to 1, the max epochs have been set to 20,000, the validation in train has been performed every 10 epochs, the early stopping condition has been evaluated every 2000 validations (thus 20,000 epochs), the batch size is composed of 64 sequences, and the adaptive learning rate has started from 0.1 and reduced by a factor of 10 if the improvement in validation is lower than 0.01.
For each appliance, thus for each dataset, the length of the input window has been set equal to the one in the reference work [
27] in the case of NUS experiments, whereas, in the case of US, the window length is reduced proportionally to the SR factor.
Additionally, the tests for each possible configuration, both network parameters and US/NUS approaches, have been executed adopting different strides of the sliding window (or hop size) of the input data and two different types of data reconstruction: [1, 8, 16, 32] and [mean, median], respectively. Therefore, given nine different sampling configurations (OS, US5, US10, US20, NUS5-5, NUS10-5, NUS10-10, NUS20-10 and NUS20-20) for the UK-DALE dataset a total of 1080 models have been generated, whereas 5184 models for the REDD dataset. Specifically, considering the different sliding window strides and reconstruction techniques, an overall total of 8640 and 41,472 evaluations have been carried out in the case of UK-DALE and REDD datasets, respectively. Furthermore, in contrast with [
27,
28], the
data augmentation procedure, proposed in [
24], has not been adopted during the generation of the batches. Therefore, a comparison against the achieved OS results cannot be carried out.
The experiments have been performed exploiting both a local cluster and an HPC resource. Specifically, the former is composed of two PCs equipped respectively with Intel
[email protected], 32 GB RAM, GTX TITAN X 12 GB, GTX 1080 8 GB, and Intel
[email protected], 32 GB RAM, TITAN X (Pascal) 12 GB, TITAN Xp 12 GB. The latter system is the HPC GALILEO at CINECA, and the experiments have relied on a maximum of 6 nodes, each one equipped with 2x8-cores Intel
[email protected], 128 GB RAM, and 2 Nvidia K80 GPUs.
The project is developed in Python and the neural network is based on the Keras library [
35] using the TensorFlow backend [
36]. All the code is publicly available [
37].
Evaluation Methods
The performance has been evaluated by relying on the metrics proposed in [
38] specific to energy disaggregation. In particular, for the
i-th appliance, with
and
number of appliances,
denotes the disaggregated power signal,
is the ground-truth power signal, and
K is the overall samples number, the energy-based precision and recall are defined as:
Information about the power consumption that has been correctly classified is given by the recall, whereas information about the power correctly assigned to an appliance is given by the precision. The
-score is a geometric mean between precision and recall, and is given as (for the
i-th appliance):
Finally, once the precision and the recall of each appliance are computed, the averaged values of precisions and recalls over the appliances are exploited to compute the overall -score.
A first set of evaluations has been conducted by comparing the outputs generated for each possible configuration of OS, US, and NUS, against the corresponding ground-truth, where also the ground-truth has been re-sampled accordingly. This evaluation will be denoted as specific-rate evaluation from here on.
In this configuration, the metrics in Equation (
7) are calculated using the signal samples taken from the related samples vector:
Moreover, a so-called
max-rate evaluation has been performed, in order to produce evaluations for each tested configuration by reporting the data to the condition of the original sampling. Specifically, the output generated by each US configuration has been up-sampled to the original sampling rate (that is the higher maximum frequency for the signal) by applying the zero-insertion followed by an interpolation filter. In the case of NUS, the same upsampling procedure has been performed over the uniform sampling points (the ones acquired applying the SR parameters), then the points within an expansion window (therefore at original sampling rate) will replace the interpolated data within the same temporal window. In this configuration, the metrics in Equation (
7) are calculated using the signal samples taken from the OS samples vector:
6. Conclusions
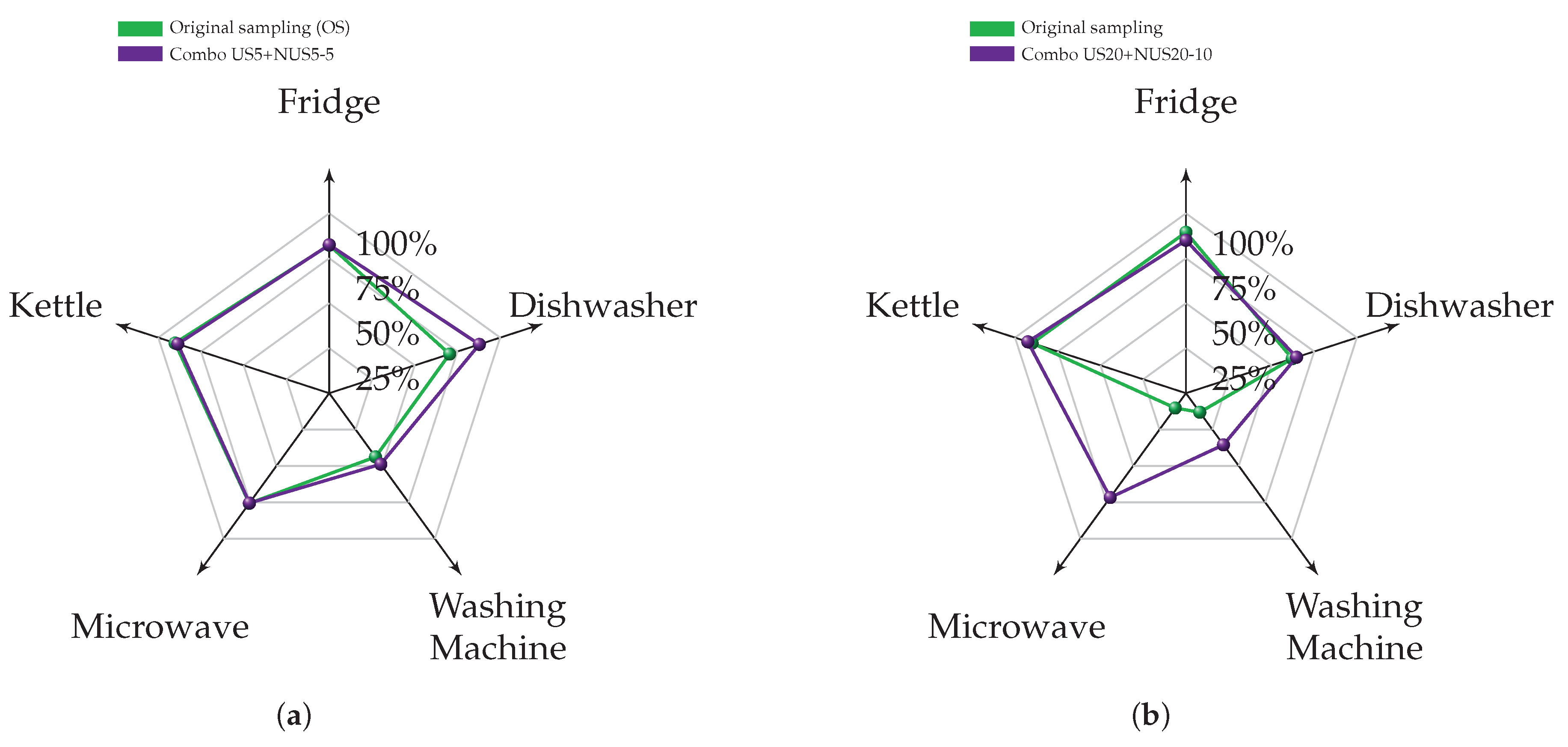
In this work, an extended experimental campaign, in order to perform an advanced analysis and to validate the Neural NILM approach in combination with an ad hoc non-uniform subsampling strategy, has been presented. Two subsampling policies, US and NUS, have also been evaluated using UK-DALE and REDD datasets in both seen and unseen scenarios by assuming a denoised environment, thus signals without contributions from unknown appliances and circuit noise. Exploiting the possibility of the Neural NILM to characterize each appliance with a dedicated network topology and subsampling strategy, different combinations of US+NUS have also been evaluated. Specifically, selecting for each appliance, the best policy between US and NUS, the overall disaggregation results have outperformed the ones achieved at OS, in terms of -score. Moreover, the application of US and NUS strategies achieves a significant reduction of the overall data, i.e., requiring less data to be collected and transmitted by a measurement system—smart meter.
In order to have an insight into the performance in a realistic scenario, additional evaluations have been carried out by assuming a noised scenario for the UK-DALE dataset. Specifically, the best US and NUS configurations in denoised conditions have been evaluated in noised ones as well. The achieved results confirmed the advantage provided, in the general results, by adopting a combination of US+NUS strategies.
As discussed, the NUS evaluations have been executed by assuming an a priori knowledge of the state transition points, aiming to reduce the disaggregation errors due to external causes, i.e., the application of expansion windows for erroneous detection of the signal transitions. Therefore, in future works, the effort will be toward the development of a pre-processing stage to automatically detect the transitions states in the aggregated power signal. Moreover, a further advancement to investigate will regard the possibility to adopt different networks to separately take care of steady and transient phases. The goal is to produce a network to work with slow changes, thus at a lower sampling rate, and another one to work with fast changes, thus at a higher sampling rate. Finally, more extended datasets, e.g., REFIT [
39], will be taken into account for the experimental phase.

 ,
, 









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}