Modeling and Solving of Uncertain Process Abnormity Diagnosis Problem

Abstract
:1. Introduction
2. Uncertain Process Abnormity Diagnosis Model of Fuzzy Relational Equation
3. Solving Scheme for Fuzzy Relational Equation by Use of GA
3.1. Fitness Function
3.2. Coding Scheme
3.3. The Determination of Initial Population
3.4. Selecting Function
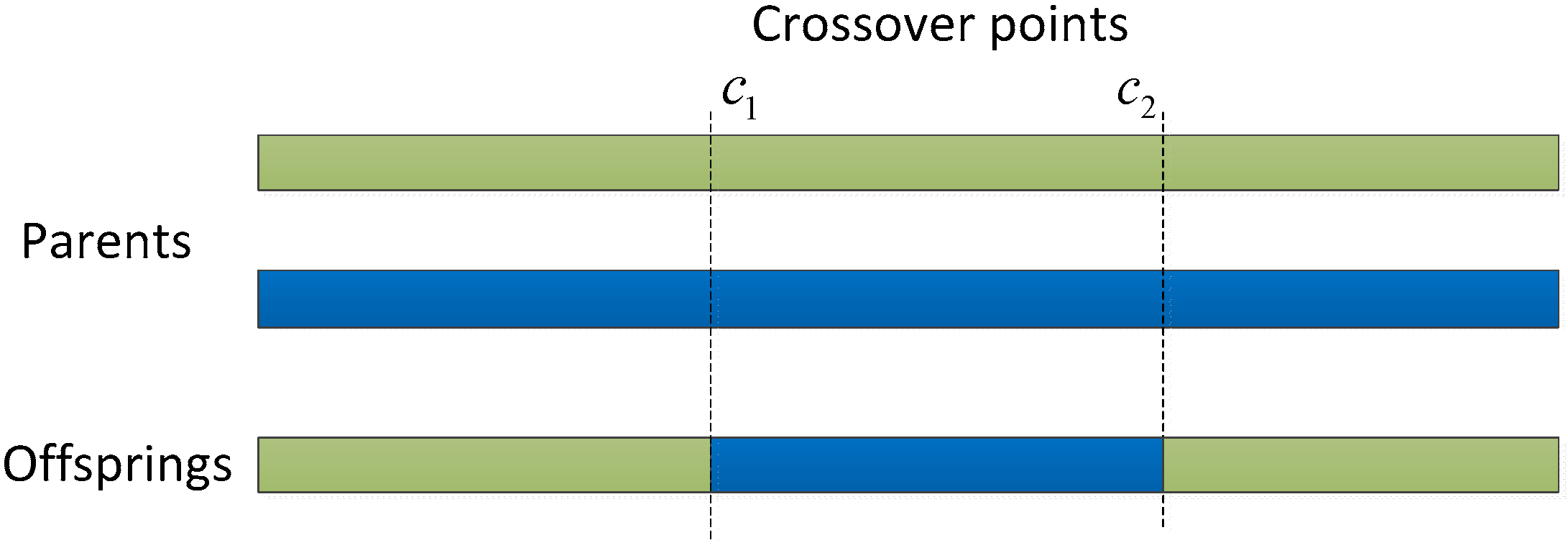
3.5. Crossover and Mutation Operators
3.6. Algorithm Flow
| Algorithm 1: <Solving fuzzy relational equation by GA> |
| Input: e (error criterion of GA), F(A)(objective function optimized by GA), Pk, Pc, popu_size, n(number of possible assignable causes) |
| Output: (i = 1, 2, …, n) |
| 1. k = 0; |
| 2. if F(n+1)(A) − F(n)(A) < e (% F(n)(A) denotes the fitness function of nth generation) |
| 3. ← running result of GA with initial population |
| 4. end if |
| 5. if F(A(k+1)) − F(A(k)) < e |
| 6. ← running result of GA with |
| 7. if <= |
| 8. = , = |
| 9. else = , = |
| 10. end if |
| 11. end if |
4. Case Study
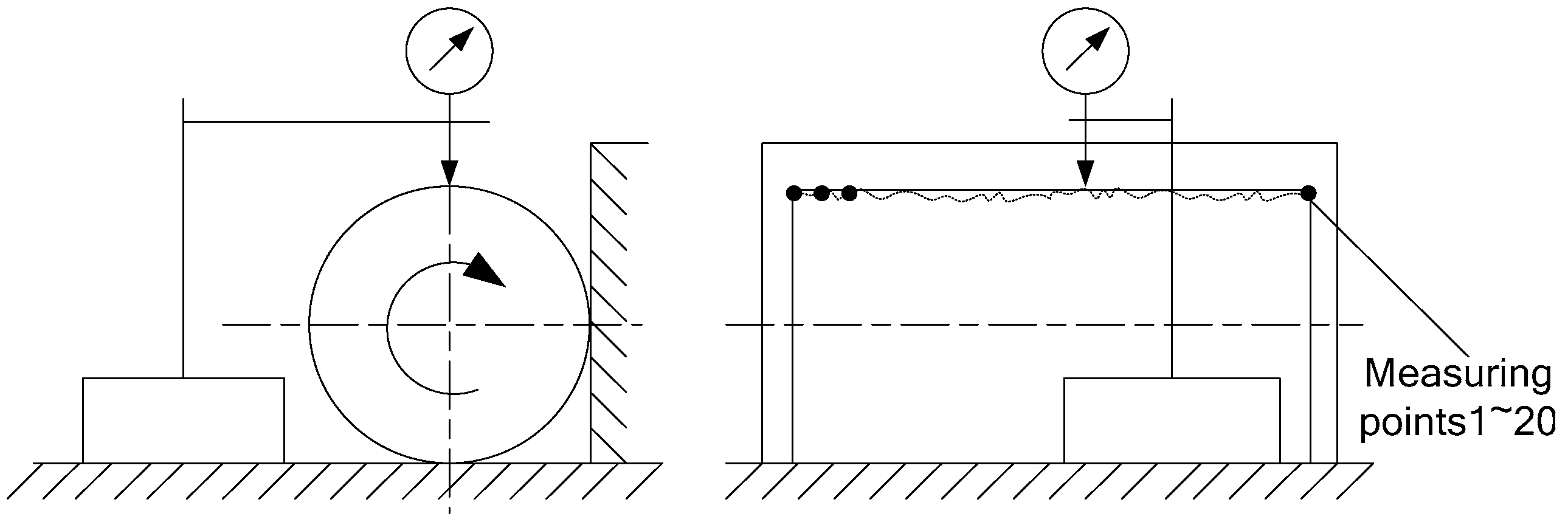
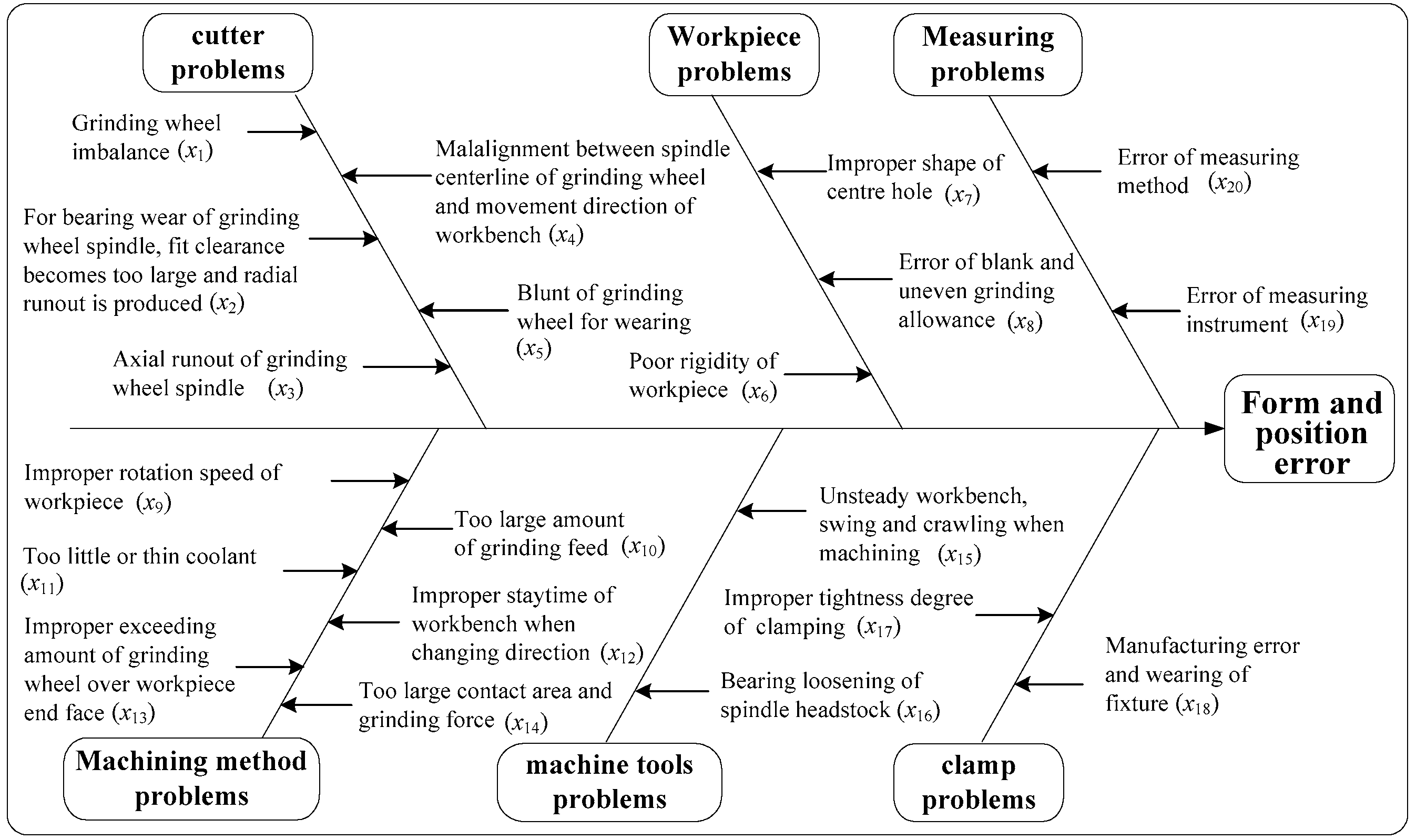
4.1. Problem Description
- (1)
- Elliptical deformation of workpiece;
- (2)
- Drum deformation of workpiece;
- (3)
- Tape of workpiece;
- (4)
- Bending deformation of workpiece;
- (5)
- Bulge of lapped shoulder;
- (1)
- Shift of sample mean, i.e., Shift pattern (y1);
- (2)
- Cycle of plotted point, i.e., Cycle pattern (y2);
- (3)
- Upward or downward trend of plotted point, i.e., Trend pattern (y3);
- (4)
- Freak of plotted point nearby the bending position, i.e., Freak pattern (y4);
- (5)
- Out of control limit for plotted point nearby the lapped shoulder, i.e., OCL pattern (y5).
4.2. GA Based Solution of Fuzzy Relational Equation
4.2.1. Fitness Function and Customer Functions
4.2.2. GA Parameter Setting
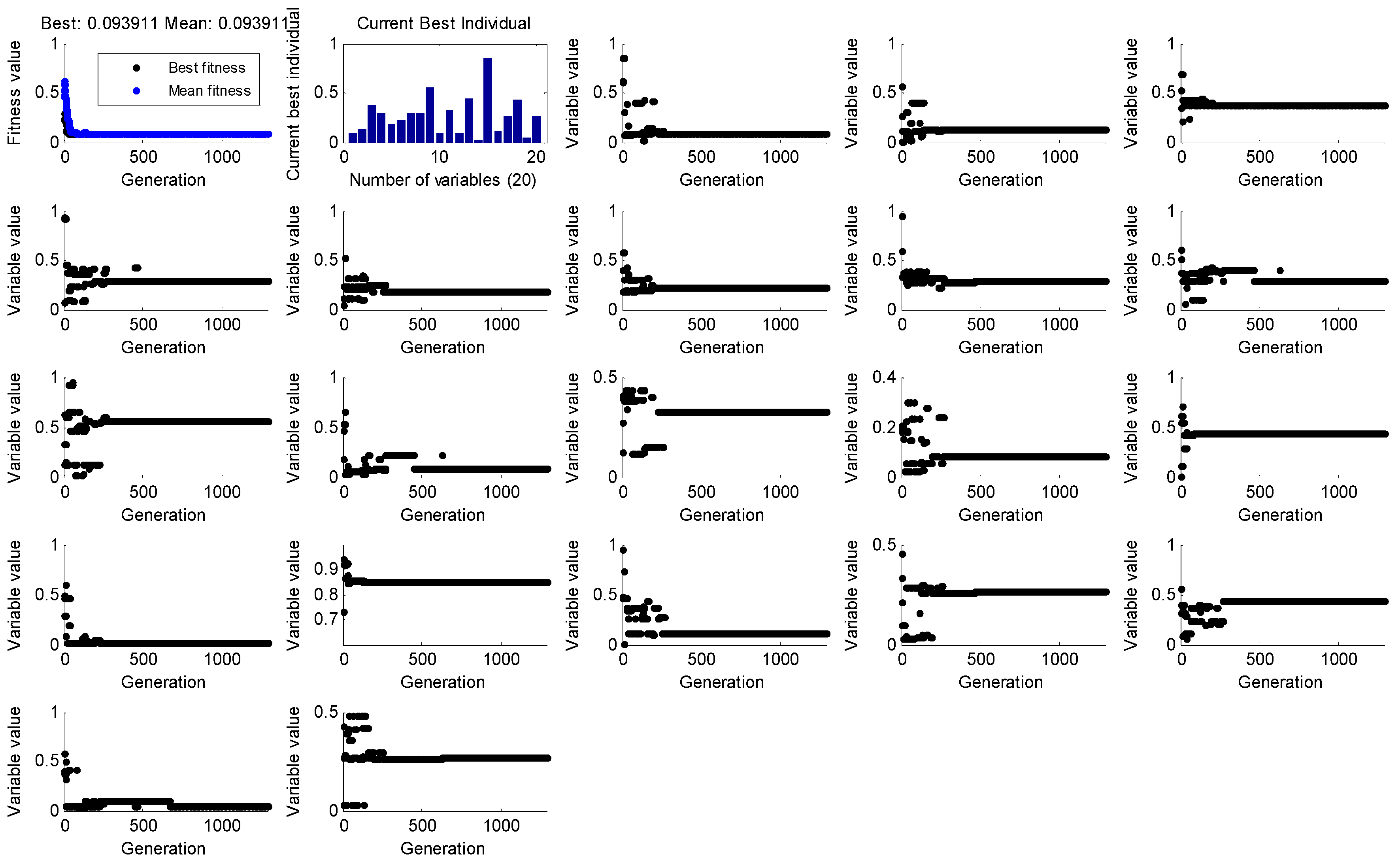
4.2.3. Obtaining the Initial Solution by Running GA
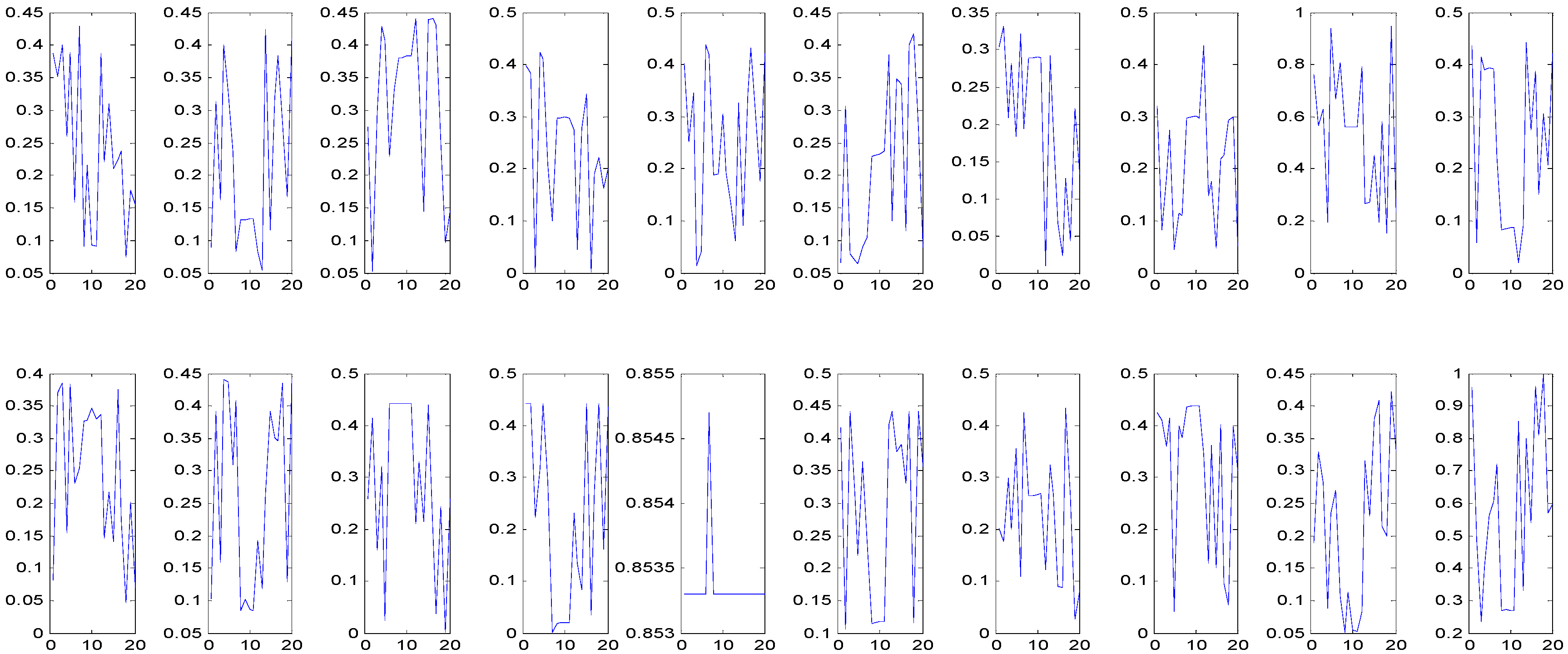
4.2.4. Repeat Running of the GA
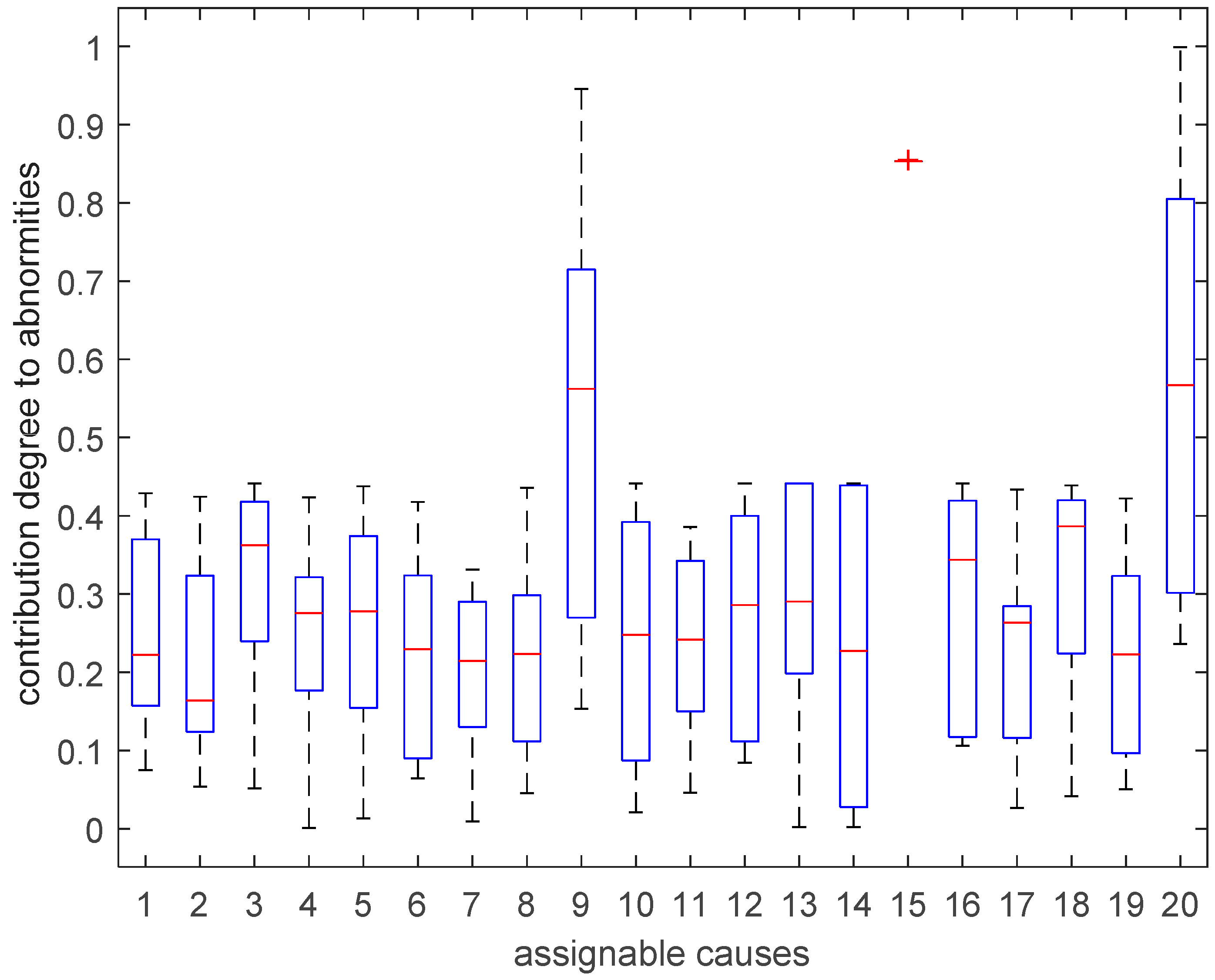
4.2.5. Interval Solution Obtained by GA
4.3. Other Simulating Application Cases
5. Conclusions
Author Contributions
Funding
Conflicts of Interest
Appendix A
Appendix B
Appendix C
References
- Fagarasan, I.; Ploix, S.; Gentil, S. Causal fault detection and isolation based on a set-membership approach. Automatica 2004, 12, 2099–2110. [Google Scholar] [CrossRef]
- Perfilieva, I.; Novak, V. System of fuzzy relation equations as a continuous model of IF–THEN rules. Inf. Sci. 2007, 16, 3218–3227. [Google Scholar] [CrossRef]
- Li, D.Y.; Zhang, G.B.; Li, M.Q. The Diagnosis of Abnormal Assembly Quality Based on Fuzzy Relation Equations. Adv. Mech. 2015, 1, 1–9. [Google Scholar] [CrossRef]
- Rotshtein, A.P.; Rakytyanska, H.B. Optimal Design of Rule-Based Systems by Solving Fuzzy Relational Equations. In issues and Challenges in Artificial Intelligence; Springer: Cham, Switzerland, 2014; pp. 167–178. [Google Scholar]
- Alcalde, C.; Burusco, A.; González, R.F. Application of the L-fuzzy concept analysis in the morphological image and signal processing. Ann. Math. Artif. Intel. 2014, 1‒2, 5–128. [Google Scholar] [CrossRef]
- Pappis, C.P.; Karacapilidis, N.I. Application of a similarity measure of fuzzy sets to fuzzy relational equations. Fuzzy Set Syst. 1995, 2, 135–142. [Google Scholar] [CrossRef]
- Kerre, E.E.; Nachtegael, M. Fuzzy relational calculus and its application to image processing. In Proceedings of the International Workshop on Fuzzy Logic and Applications, Palermo, Italy, 9‒12 June 2009; pp. 179–188. [Google Scholar]
- Dubois, D.; Prade, H. Fuzzy relation equations and causal reasoning. Fuzzy Set Syst. 1995, 2, 119–134. [Google Scholar] [CrossRef]
- Antika, T.; Dhaneshwar, P.; Gaur, S.K. Optimization of linear objective function with max-t fuzzy relation equations. Appl. Soft. Comput. 2009, 3, 1097–1101. [Google Scholar] [CrossRef]
- Shieh, B.S. Solutions of fuzzy relation equations based on continuous t-norms. Inf. Sci. 2007, 19, 4208–4215. [Google Scholar] [CrossRef]
- Perfilieva, I. Fuzzy function as an approximate solution to a system of fuzzy relation equations. Fuzzy Set Syst. 2004, 3, 363–383. [Google Scholar] [CrossRef]
- Luo, R.H.; Guo, C.X. Solving Fuzzy Relation Equation with Sup-Archemedian T Module Copmposite Operator. Math. Practice Theory 2004, 8, 104–107. [Google Scholar] [CrossRef]
- Higashi, M.; Klir, G.J. Resolution of finite fuzzy relation equations. Fuzzy Set Syst. 1984, 1, 65–82. [Google Scholar] [CrossRef]
- Bartl, E. Minimal solutions of generalized fuzzy relational equations: probabilistic algorithm based on greedy approach. Fuzzy Set Syst. 2015, 260, 25–42. [Google Scholar] [CrossRef]
- Díaz, J.C.; Medina, J. Multi-adjoint relation equations: definition, properties and solutions using concept lattices. Inf. Sci. 2013, 253, 100–109. [Google Scholar] [CrossRef]
- Díaz, J.C.; Medina, J. Using concept lattice theory to obtain the set of solutions of multi-adjoint relation equations. Inf. Sci. 2014, 266, 218–225. [Google Scholar] [CrossRef]
- Díaz, J.C.; Medina, J. Solving systems of fuzzy relation equations by fuzzy property-oriented concepts. Inf. Sci. 2013, 222, 405–412. [Google Scholar] [CrossRef]
- Lin, J.L.; Wu, Y.K.; Guu, S.M. On fuzzy relational equations and the covering problem. Inf. Sci. 2011, 14, 2951–2963. [Google Scholar] [CrossRef]
- Markovskii, A. On the relation between equations with max-product composition and the covering problem. Fuzzy Set Syst. 2005, 2, 261–273. [Google Scholar] [CrossRef]
- Shivanian, E. An algorithm for finding solutions of fuzzy relation equations with max-Lukasiewicz composition. Mathware Soft Comput. 2010, 17, 15–26. [Google Scholar]
- Zhou, J.; Yu, Y.; Liu, Y. Solving nonlinear optimization problems with bipolar fuzzy relational equation constraints. J. Inequal. Appl. 2016, 1, 1–10. [Google Scholar] [CrossRef]
- Chang, C.W.; Shieh, B.S. Linear optimization problem constrained by fuzzy max–min relation equations. Inf. Sci. 2013, 234, 71–79. [Google Scholar] [CrossRef]
- Shieh, B.S. Minimizing a linear objective function under a fuzzy max-t norm relation equation constraint. Inf. Sci. 2011, 181, 832–841. [Google Scholar] [CrossRef]
- Yeh, C.T. On the minimal solutions of max-min fuzzy relational equations. Fuzzy Set Syst. 2008, 1, 23–39. [Google Scholar] [CrossRef]
- Chen, L.; Wang, P.P. Fuzzy relation equations (I): The general and specialized solving algorithms. Soft Comput. 2002, 6, 428–435. [Google Scholar] [CrossRef]
- Perfilieva, I.; Gottwald, S. Solvability and approximate solvability of fuzzy relation equations. Int. J. Gen Syst 2003, 4, 361–372. [Google Scholar] [CrossRef]
- Yang, J.H.; Cao, B.Y. Geometric Programming with Fuzzy Relation Equation Constraints. Fuzzy Syst Math. 2006, 3, 110–115. [Google Scholar] [CrossRef]
- Shu, C.F.; Li, G.Z. Solving fuzzy relation equations with a linear objective function. Fuzzy Set Syst. 1999, 1, 107–113. [Google Scholar] [CrossRef]
- Lu, J.J.; Fang, S.C. Solving nonlinear optimization problems with fuzzy relation equation constraints. Fuzzy Set Syst. 2001, 1, 1–20. [Google Scholar] [CrossRef]
- Rotshtein, A. Modification of Saaty method for the construction of fuzzy set membership functions. In Proceedings of the Fuzzy Logic and Its Applications, Zichron, Israel, 18‒21 May 1997; pp. 125–130. [Google Scholar]










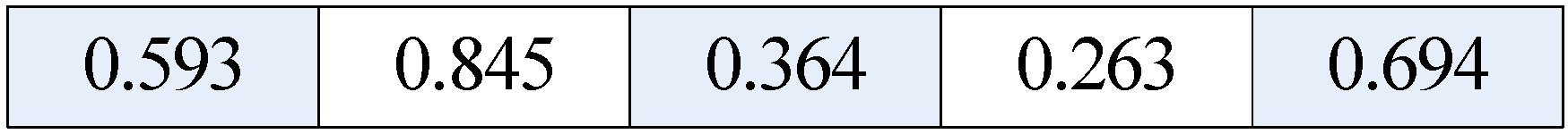{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Parameters of GA | Setting in Matlab | Parameters of GA | Setting in Matlab |
|---|---|---|---|
| PopulationSize | 200 | CreationFcn | @gacreationlinearfeasible |
| MigrationDirection | ‘forward’ | FitnessScalingFcn | @fitscalingprop |
| Generations | Inf | CrossoverFcn | @crossovertwopoint |
| StallGenLimit | Inf | MutationFcn | @mutationgaussian |
| InitialPopulation | [200 × 20 double] | Display | ‘off’ |
| MaxGenerations | 2000 | FunctionTolerance | 1 × 10−6 |
| InitialScores | [200 × 1 double] | PlotFcns | @gaplotbestf @gaplotbestindiv @gaplotchange |
© 2019 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Hou, S.; Wen, H. Modeling and Solving of Uncertain Process Abnormity Diagnosis Problem. Energies 2019, 12, 1580. https://doi.org/10.3390/en12081580
Hou S, Wen H. Modeling and Solving of Uncertain Process Abnormity Diagnosis Problem. Energies. 2019; 12(8):1580. https://doi.org/10.3390/en12081580
Chicago/Turabian StyleHou, Shiwang, and Haijun Wen. 2019. "Modeling and Solving of Uncertain Process Abnormity Diagnosis Problem" Energies 12, no. 8: 1580. https://doi.org/10.3390/en12081580
APA StyleHou, S., & Wen, H. (2019). Modeling and Solving of Uncertain Process Abnormity Diagnosis Problem. Energies, 12(8), 1580. https://doi.org/10.3390/en12081580