Data Driven Natural Gas Spot Price Prediction Models Using Machine Learning Methods


Abstract
:1. Introduction
2. Machine Learning Approaches
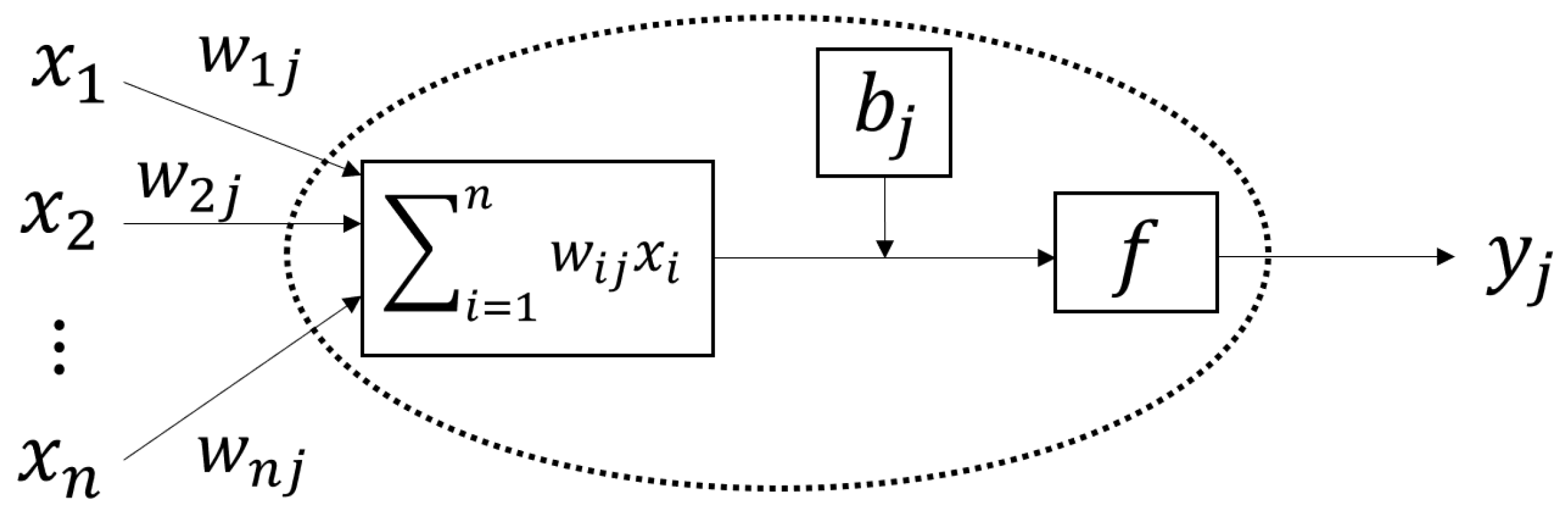
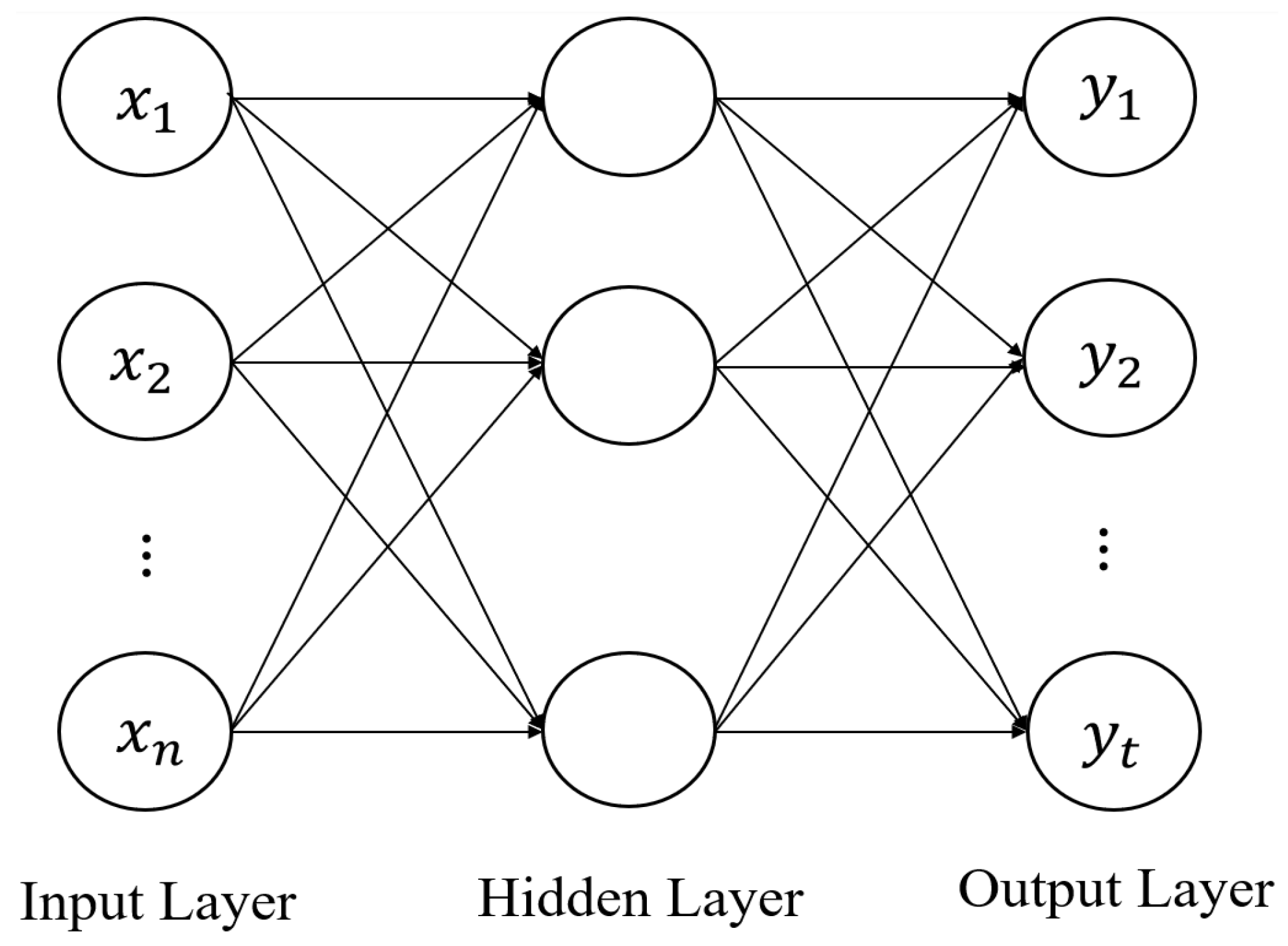
2.1. ANN
2.2. SVM
2.3. GBM
2.4. GPR
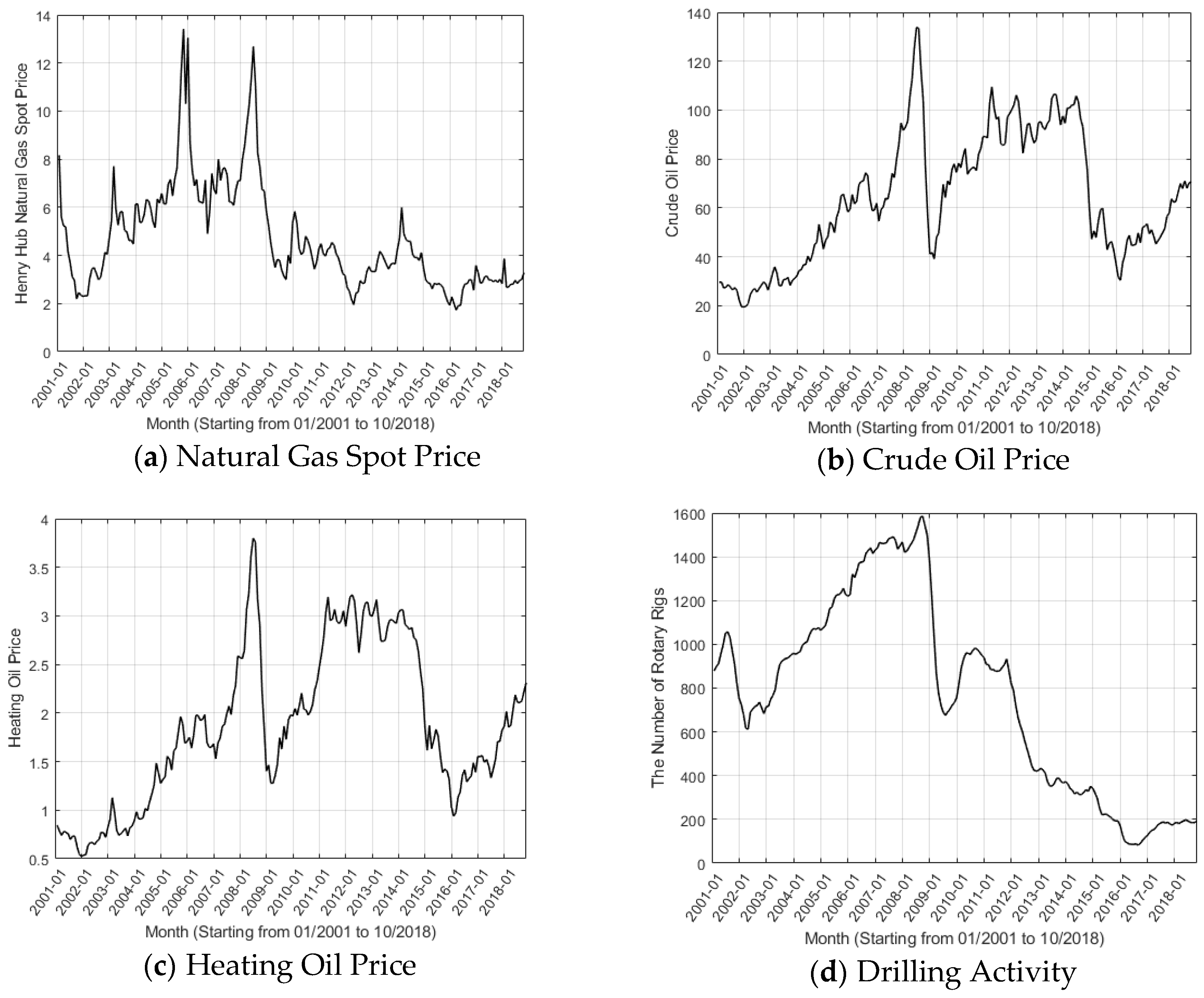
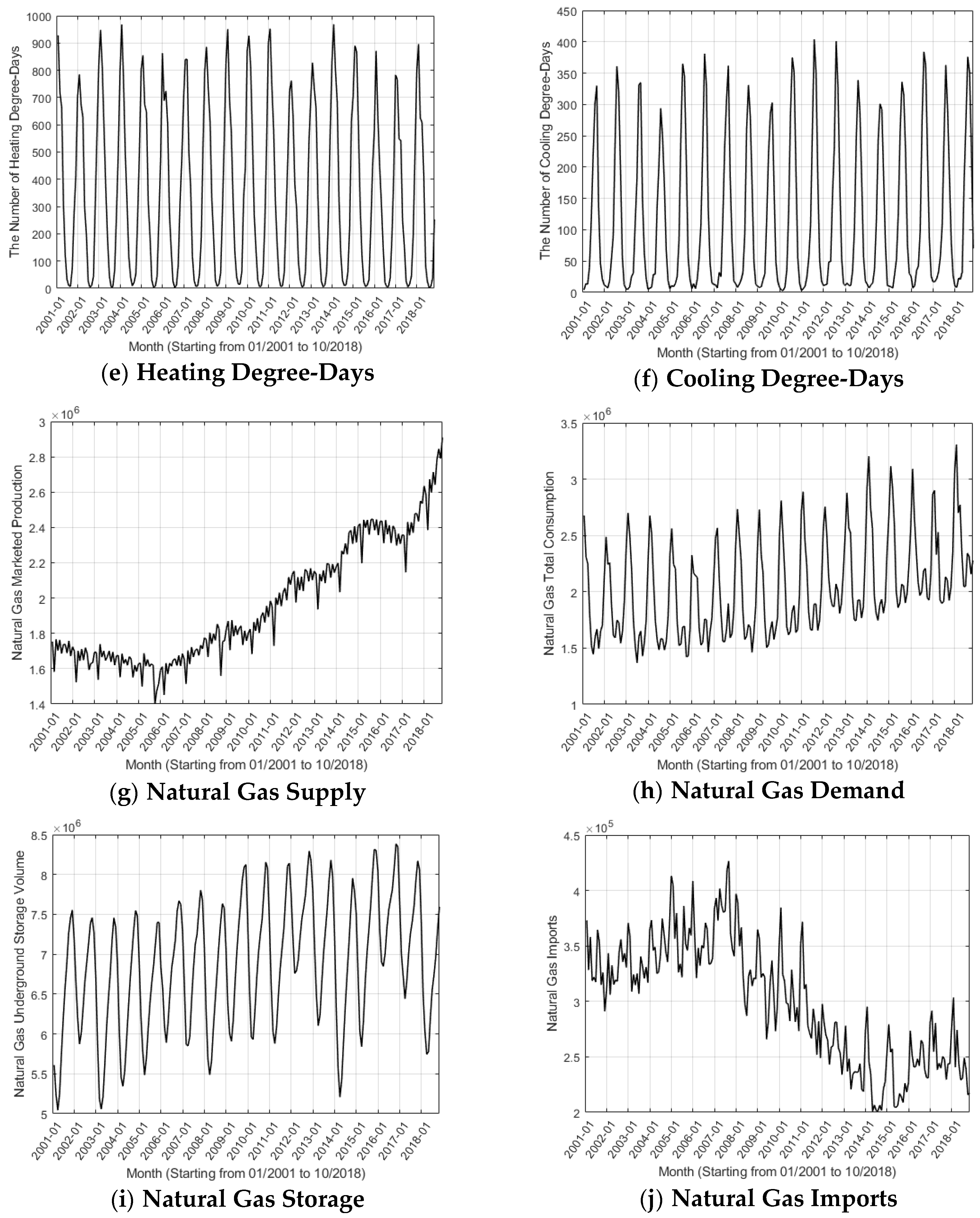
3. Data Preparation and Description
4. Empirical Study
4.1. Forecasting Performance Evaluation Criteria
4.2. Model Validation Technique
4.3. Model Parameter Selection
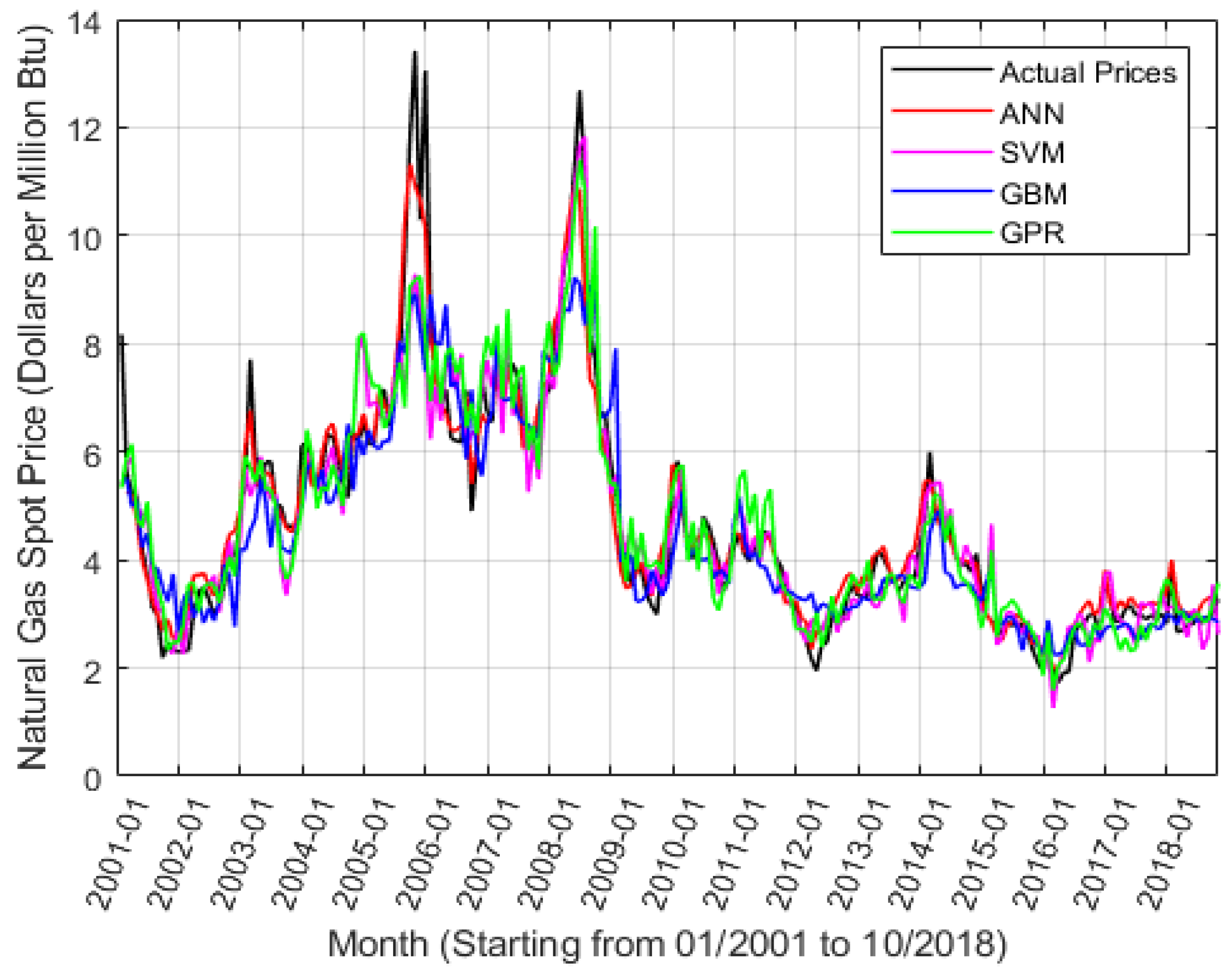
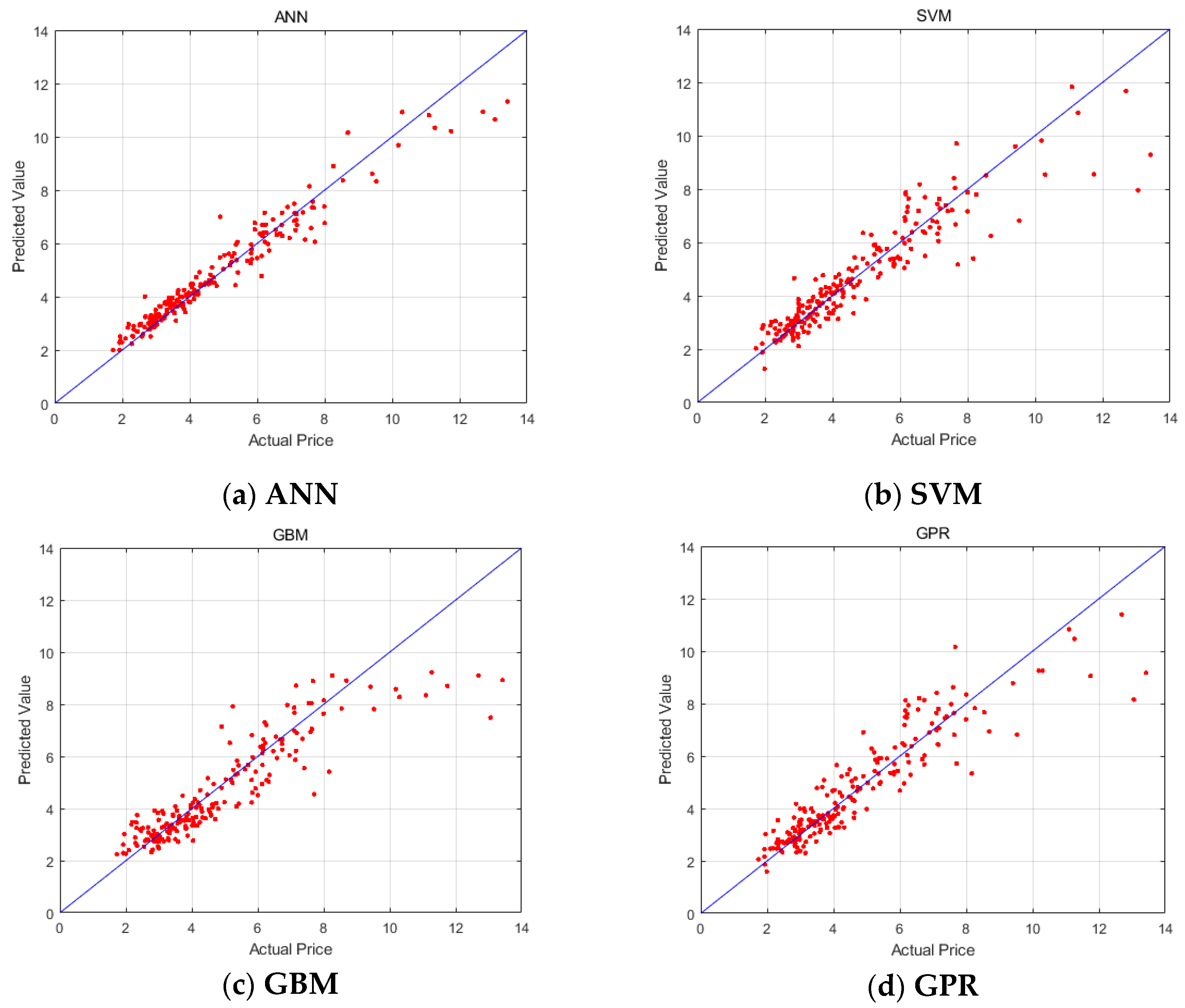
4.4. Empirical Study Results
5. Conclusions
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
References
- International Energy Agency (IEA). Key World Energy Statistics 2018. Available online: https://webstore.iea.org/key-world-energy-statistics-2018 (accessed on 30 April 2019).
- Afgan, N.H.; Pilavachi, P.A.; Carvalho, M.G. Multi-criteria evaluation of natural gas resources. Energy Policy 2007, 35, 704–713. [Google Scholar] [CrossRef]
- Abrishami, H.; Varahrami, V. Different methods for gas price forecasting. Cuad. Econ. 2011, 34, 137–144. [Google Scholar] [CrossRef] [Green Version]
- Busse, S.; Helmholz, P.; Weinmann, M. Forecasting day ahead spot price movements of natural gas—An analysis of potential influence factors on basis of a NARX neural network. In Proceedings of the Tagungsband der Multikonferenz Wirtschaftsinformatik (MKWI), Braunschweig, Germany; Available online: https://publikationsserver.tu-braunschweig.de/servlets/MCRFileNodeServlet/dbbs_derivate_00027726/Beitrag299.pdf (accessed on 30 April 2019).
- Azadeh, A.; Sheikhalishahi, M.; Shahmiri, S. A Hybrid Neuro-Fuzzy Approach for Improvement of Natural Gas Price Forecasting in Vague and Noisy Environments: Domestic and Industrial Sectors. In Proceedings of the International Conference on Trends in Industrial and Mechanical Engineering (ICTIME’2012), Dubai, United Arab Emirates, 24–25 March 2012. [Google Scholar]
- Salehnia, N.; Falahi, M.A.; Seifi, A.; Adeli, M.H.M. Forecasting natural gas spot prices with nonlinear modeling using gamma test analysis. J. Nat. Gas Sci. Eng. 2013, 14, 238–249. [Google Scholar] [CrossRef]
- Čeperić, E.; Žiković, S.; Čeperić, V. Short-term forecasting of natural gas prices using machine learning and feature selection algorithms. Energy 2017, 140, 893–900. [Google Scholar] [CrossRef]
- Su, M.; Zhang, Z.; Zhu, Y.; Zha, D. Data-Driven Natural Gas Spot Price Forecasting with Least Squares Regression Boosting Algorithm. Energies 2019, 12, 1094. [Google Scholar] [CrossRef]
- Lloyd, J.R. GEFCom2012 hierarchical load forecasting: Gradient boosting machines and Gaussian processes. Int. J. Forecast. 2014, 30, 369–374. [Google Scholar] [CrossRef] [Green Version]
- Cossock, D.; Zhang, T. Statistical Analysis of Bayes Optimal Subset Ranking. IEEE Trans. Inf. Theory 2008, 54, 5140–5154. [Google Scholar] [CrossRef] [Green Version]
- Landry, M.; Erlinger, T.P.; Patschke, D.; Varrichio, C. Probabilistic gradient boosting machines for GEFCom2014 wind forecasting. Int. J. Forecast. 2016, 32, 1061–1066. [Google Scholar] [CrossRef]
- Zhang, Y.; Haghani, A. A gradient boosting method to improve travel time prediction. Transp. Res. Part C Emerg. Technol. 2015, 58 Pt B, 308–324. [Google Scholar] [CrossRef]
- Candanedo, L.M.; Feldheim, V.; Deramaix, D. Data driven prediction models of energy use of appliances in a low-energy house. Energy Build. 2017, 140, 81–97. [Google Scholar] [CrossRef]
- Deng, X.; Han, J.; Yin, F. Net Energy, CO2 Emission and Land-Based Cost-Benefit Analyses of Jatropha Biodiesel: A Case Study of the Panzhihua Region of Sichuan Province in China. Energies 2012, 5, 2150–2164. [Google Scholar] [CrossRef]
- Sun, A.Y.; Wang, D.; Xu, X. Monthly streamflow forecasting using Gaussian Process Regression. J. Hydrol. 2014, 511, 72–81. [Google Scholar] [CrossRef]
- Yu, J.; Chen, K.; Mori, J.; Rashid, M.M. A Gaussian mixture copula model based localized Gaussian process regression approach for long-term wind speed prediction. Energy 2013, 61, 673–686. [Google Scholar] [CrossRef]
- Salcedo-Sanz, S.; Casanova-Mateo, C.; Muñoz-Marí, J.; Camps-Valls, G. Prediction of Daily Global Solar Irradiation Using Temporal Gaussian Processes. IEEE Geosci. Remote Sens. Lett. 2014, 11, 1936–1940. [Google Scholar] [CrossRef]
- McCulloch, W.S.; Pitts, W. A Logical Calculus of Ideas Immanent in Nervous Activity. Bull. Math. Biophys. 1943, 5, 115–133. [Google Scholar] [CrossRef]
- Kurbatsky, V.G.; Sidorov, D.N.; Spiryaev, V.A.; Tomin, N.V. Forecasting nonstationary time series based on Hilbert-Huang transform and machine learning. Autom. Remote Control 2014, 75, 922–934. [Google Scholar] [CrossRef]
- Maier, H.R.; Dandy, G.C. Neural networks for the prediction and forecasting of water resources variables: A review of modelling issues and applications. Environ. Model. Softw. 2000, 15, 101–124. [Google Scholar] [CrossRef]
- Magoules, F.; Zhao, H.X. Data Mining and Machine Learning in Building Energy Analysis; ISTE Ltd. and John Wiley & Sons, Inc.: Hoboken, NJ, USA, 2016. [Google Scholar]
- Vapnik, V.N.; Chervonenkis, A.Y. On the uniform convergence of relative frequencies of event to their probabilities. Sov. Math. Dokl. 1968, 9, 915–918. [Google Scholar]
- Boser, B.E.; Guyon, I.M.; Vapnik, V.N. A training algorithm for optimal margin classifiers. In Proceedings of the 5th Annual Workshop on Computational Learning Theory, Pittsburgh, PA, USA, 27–29 July 1992; ACM Press: New York, NY, USA, 1992; pp. 144–152. [Google Scholar] [Green Version]
- Vapnik, V.N. Statistical Learning Theory; Wiley: New York, NY, USA, 1998. [Google Scholar]
- Zhang, W.Y.; Hong, W.C.; Dong, Y.; Tsai, G.; Sung, J.T.; Fan, G.F. Application of SVR with chaotic GASA algorithm in cyclic electric load forecasting. Energy 2012, 45, 850–858. [Google Scholar] [CrossRef]
- Lauret, P.; Voyant, C.; Soubdhan, T.; David, M.; Poggi, P. A benchmarking of machine learning techniques for solar radiation forecasting in an insular context. Sol. Energy 2015, 112, 446–457. [Google Scholar] [CrossRef]
- Taghavifar, H.; Mardani, A. A comparative trend in forecasting ability of artificial neural networks and regressive support vector machine methodologies for energy dissipation modeling of off-road vehicles. Energy 2014, 66, 569–576. [Google Scholar] [CrossRef]
- Hong, W.C. Load forecasting by seasonal recurrent SVR (support vector regression) with chaotic artificial bee colony algorithm. Energy 2011, 36, 5568–5578. [Google Scholar] [CrossRef]
- Zhao, H.X.; Magoulès, F. Parallel support vector machines applied to the prediction of multiple buildings energy consumption. J. Algorithms Comput. Technol. 2010, 4, 231–250. [Google Scholar] [CrossRef]
- Cherkassky, V.; Ma, Y. Practical selection of SVM parameters and noise estimation for SVM regression. Neural Netw. 2004, 17, 113–126. [Google Scholar] [CrossRef] [Green Version]
- Chalimourda, A.; Scholkopf, B.; Smola, A.J. Experimentally optimal in support vector regression for different noise models and parameter settings. Neural Netw. 2004, 17, 127–141. [Google Scholar] [CrossRef]
- Li, Q.; Meng, Q.; Cai, J.; Yoshino, H.; Mochida, A. Predicting hourly cooling load in the building: A comparison of support vector machine and different artificial neural networks. Energy Convers. Manag. 2009, 50, 90–96. [Google Scholar] [CrossRef]
- Freund, Y.; Schapire, R.E. A Decision-Theoretic Generalization of On-Line Learning and an Application to Boosting. J. Comput. Syst. Sci. 1997, 55, 119–139. [Google Scholar] [CrossRef] [Green Version]
- Friedman, J.; Hastie, T.; Tibshirani, R. Additive logistic regression: A statistical view of boosting (With discussion and a rejoinder by the authors). Ann. Stat. 2000, 28, 337–407. [Google Scholar] [CrossRef]
- Friedman, J.H. Greedy Function Approximation: A Gradient Boosting Machine. Ann. Stat. 2001, 29, 1189–1232. [Google Scholar] [CrossRef]
- Williams, C.K.I. Prediction with Gaussian processes: From linear regression to linear prediction and beyond. In Learning in Graphical Models; Springer: Dordrecht, The Netherlands, 1998; pp. 599–621. [Google Scholar]
- Williams, C.K.I.; Rasmussen, C.E. Gaussian processes for regression. Adv. Neural Inf. 1996, 514–520. Available online: http://publications.eng.cam.ac.uk/330944/ (accessed on 30 April 2019).
- Rasmussen, C.E.; Williams, C.K.I. Gaussian Processes for Machine Learning; MIT Press: Cambridge, MA, USA, 2006. [Google Scholar]
- Shi, X.; Variam, H.M.P. East Asia’s gas-market failure and distinctive economics—A case study of low oil prices. Appl. Energy 2017, 195, 800–809. [Google Scholar] [CrossRef]
- Ohana, S. Modeling global and local dependence in a pair of commodity forward curves with an application to the US natural gas and heating oil markets. Energy Econ. 2010, 32, 373–388. [Google Scholar] [CrossRef]
- Ji, Q.; Zhang, H.-Y.; Geng, J.-B. What drives natural gas prices in the United States?—A directed acyclic graph approach. Energy Econ. 2018, 69, 79–88. [Google Scholar] [CrossRef]
- Geng, J.-B.; Ji, Q.; Fan, Y. The behaviour mechanism analysis of regional natural gas prices: A multi-scale perspective. Energy 2016, 101, 266–277. [Google Scholar] [CrossRef]
- EIA. Available online: https://www.eia.gov/ (accessed on 25 March 2019).
- NOAA. Available online: https://www.noaa.gov/ (accessed on 25 March 2019).
- Liu, F.; Li, R.; Li, Y.; Cao, Y.; Panasetsky, D.; Sidorov, D. Short-term wind power forecasting based on T-S fuzzy model. In Proceedings of the 2016 IEEE PES Asia-Pacific Power and Energy Engineering Conference (APPEEC), Xi’an, China, 25–28 October 2016; pp. 414–418. [Google Scholar]
- Cameron, A.C.; Windmeijer, F.A. An r-squared measure of goodness of fit for some common nonlinear regression models. J. Econ. 1997, 77, 329–342. [Google Scholar] [CrossRef]
- Jin, R.; Chen, W.; Simpson, T.W. Comparative studies of metamodelling techniques under multiple modelling criteria. Struct. Multidiscipl. Optim. 2001, 23, 1–13. [Google Scholar] [CrossRef]
- Touzani, S.; Granderson, J.; Fernandes, S. Gradient boosting machine for modeling the energy consumption of commercial buildings. Energy Build. 2018, 158, 1533–1543. [Google Scholar] [CrossRef] [Green Version]
- Willmott, C.J.; Matsuura, K. Advantages of the mean absolute error (MAE) over the root mean square error (RMSE) in assessing average model performance. Clim. Res. 2005, 30, 79–82. [Google Scholar] [CrossRef] [Green Version]
- Chai, T.; Draxler, R.R. Root mean square error (RMSE) or mean absolute error (MAE)?—Arguments against avoiding RMSE in the literature. Geosci. Model Dev. 2014, 7, 1247–1250. [Google Scholar] [CrossRef]
- Willmott, C.J. Some comments on the evaluation of model performance. Bull. Am. Meteorol. Soc. 1982, 63, 1309–1313. [Google Scholar] [CrossRef]
- Hyndman, R.J.; Koehler, A.B. Another look at measures of forecast accuracy. Int. J. Forecast. 2006, 22, 679–688. [Google Scholar] [CrossRef] [Green Version]
- Willmott, C.J. On the validation of models. Phys. Geogr. 1981, 2, 184–194. [Google Scholar] [CrossRef]
- Voyant, C.; Notton, G.; Kalogirou, S.; Nivet, M.L.; Paoli, C.; Motte, F.; Fouilloy, A. Machine learning methods for solar radiation forecasting: A review. Renew. Energy 2017, 105, 569–582. [Google Scholar] [CrossRef]
- De Myttenaere, A.; Golden, B.; le Grand, B.; Rossic, F. Mean Absolute Percentage Error for regression models. Neurocomputing 2016, 192, 38–48. [Google Scholar] [CrossRef] [Green Version]
- Kim, S.; Kim, H. A new metric of absolute percentage error for intermittent demand forecasts. Int. J. Forecast. 2016, 32, 669–679. [Google Scholar] [CrossRef] [Green Version]
- Kohavi, R. A study of cross-validation and bootstrap for accuracy estimation and model selection. In Proceedings of the 14th International Joint Conference on Artificial Intelligence (IJCAI), Montreal, QC, Canada, 20–25 August 1995; pp. 1137–1145. [Google Scholar]
- Kurbatsky, V.G.; Sidorov, D.N.; Spiryaev, V.A.; Tomin, N.V. The hybrid model based on Hilbert-Huang Transform and neural networks for forecasting of short-term operation conditions of power system. In Proceedings of the 2011 IEEE Trondheim PowerTech, Trondheim, Norway, 19–23 June 2011; pp. 1–7. [Google Scholar]
- Khaidem, L.; Saha, S.; Dey, S.R. Predicting the direction of stock market prices using random forest. arXiv 2016, arXiv:1605.00003. [Google Scholar]
- Zhukov, A.V.; Sidorov, D.N.; Foley, A.M. Random forest based approach for concept drift handling. In Proceedings of the International Conference on Analysis of Images, Social Networks and Texts, Yekaterinburg, Russia, 7–9 April 2016; pp. 69–77. [Google Scholar]







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Variables | Data | Unit | Source |
|---|---|---|---|
| Natural gas price | Henry Hub Natural Gas Spot Price | Dollars/million btu | EIA |
| Crude Oil Price | Cushing, OK WTI Spot Price FOB | Dollars/barrel | EIA |
| Heating Oil Price | New York Harbor No. 2 Heating Oil Spot Price FOB | Dollars/gallon | EIA |
| Drilling Activity | U.S. Natural Gas Rotary Rigs in Operation | Count | EIA |
| Temperature | Heating Degree-Days | Number | NOAA |
| Cooling Degree-Days | Number | ||
| Natural Gas Supply | U.S. Natural Gas Marketed Production | Million Cubic Feet | EIA |
| Natural Gas Demand | U.S. Natural Gas Total Consumption | Million Cubic Feet | EIA |
| Natural Gas Storage | U.S. Total Natural Gas Underground Storage Volume | Million Cubic Feet | EIA |
| Natural Gas Imports | U.S. Natural Gas Imports | Million Cubic Feet | EIA |
| Variables | Max | Min | Median | Mean | SD | RSD |
|---|---|---|---|---|---|---|
| NGSP | 13.42 | 1.73 | 4.045 | 4.7064 | 2.2156 | 0.4708 |
| WTI | 133.8 | 19.39 | 61.795 | 63.8696 | 26.5254 | 0.41538 |
| HO | 3.801 | 0.524 | 1.7695 | 1.8602 | 0.806 | 0.4333 |
| NGRR | 1585 | 82 | 792.5 | 762.1682 | 445.8986 | 0.5850 |
| HDD | 969 | 3 | 279.5 | 352.5374 | 313.4179 | 0.8890 |
| CDD | 404 | 3 | 52.5 | 115.9766 | 122.9591 | 1.0602 |
| NGMP | 2,909,415 | 1,400,941 | 1,827,382 | 1,959,300 | 340,660 | 0.1739 |
| NGTC | 3,307,711 | 1,368,369 | 1,926,900 | 2,036,900 | 424,400 | 0.2084 |
| NGUSV | 8,384,087 | 5,041,971 | 6,920,016 | 6,865,600 | 806,420 | 0.1175 |
| NGI | 426,534 | 200,669 | 306,952 | 300,010 | 55,160 | 0.1839 |
| Variables | NGSP | WTI | HO | NGRR | HDD | CDD | NGMP | NGTC | NGUSV | NGI |
|---|---|---|---|---|---|---|---|---|---|---|
| NGSP | 1.0000 | |||||||||
| WTI | 0.1964 | 1.0000 | ||||||||
| HO | 0.1321 | 0.9805 | 1.0000 | |||||||
| NGRR | 0.7504 | 0.0936 | 0.0144 | 1.0000 | ||||||
| HDD | 0.0911 | −0.0860 | −0.0493 | 0.0221 | 1.0000 | |||||
| CDD | −0.0590 | 0.0897 | 0.0592 | −0.0299 | −0.8244 | 1.0000 | ||||
| NGMP | −0.6053 | 0.1976 | 0.2814 | −0.8315 | −0.0872 | 0.1117 | 1.0000 | |||
| NGTC | −0.2021 | 0.0238 | 0.0958 | −0.3744 | 0.8085 | −0.4791 | 0.3956 | 1.0000 | ||
| NGUSV | −0.3099 | 0.1341 | 0.1618 | −0.2203 | −0.2975 | 0.2449 | 0.2933 | −0.1730 | 1.0000 | |
| NGI | 0.6082 | −0.2653 | −0.3319 | 0.8078 | 0.2445 | −0.0989 | −0.8007 | −0.0906 | −0.2951 | 1.0000 |
| Kernel Function | 1 | 2 | 3 | 4 | 5 | 96 | 97 | 98 | 99 | 100 | |
|---|---|---|---|---|---|---|---|---|---|---|---|
| Linear | 1.4296 | 1.4284 | 1.4245 | 1.4373 | 1.4175 | …… | 1.4200 | 1.4262 | 1.4246 | 1.4347 | 1.4175 |
| Quadratic | 1.0052 | 1.0185 | 1.0037 | 1.0274 | 0.9923 | …… | 1.0067 | 1.0153 | 1.0056 | 0.9848 | 1.0319 |
| Cubic | 0.8373 | 0.8401 | 0.8187 | 0.9027 | 0.8367 | …… | 0.8322 | 0.8853 | 0.9418 | 0.8103 | 0.8505 |
| Fine Gaussian | 1.8277 | 1.8442 | 1.8259 | 1.8393 | 1.8154 | …… | 1.8336 | 1.8347 | 1.8400 | 1.8535 | 1.8437 |
| Medium Gaussian | 1.0947 | 1.0996 | 1.0761 | 1.1129 | 1.0653 | …… | 1.0851 | 1.0943 | 1.0947 | 1.0731 | 1.1001 |
| Coarse Gaussian | 1.4394 | 1.4425 | 1.4318 | 1.4414 | 1.4256 | …… | 1.4292 | 1.4283 | 1.4320 | 1.4363 | 1.4261 |
| Model | R-Square | MAE | MSE | RMSE | MAPE |
|---|---|---|---|---|---|
| ANN | 0.8904 | 0.5115 | 0.5363 | 0.7247 | 0.1117 |
| SVM | 0.8437 | 0.5673 | 0.7673 | 0.8757 | 0.1202 |
| GBM | 0.8006 | 0.6490 | 0.9786 | 0.9888 | 0.1366 |
| GPR | 0.8374 | 0.6026 | 0.7980 | 0.8932 | 0.1270 |
© 2019 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Su, M.; Zhang, Z.; Zhu, Y.; Zha, D.; Wen, W. Data Driven Natural Gas Spot Price Prediction Models Using Machine Learning Methods. Energies 2019, 12, 1680. https://doi.org/10.3390/en12091680
Su M, Zhang Z, Zhu Y, Zha D, Wen W. Data Driven Natural Gas Spot Price Prediction Models Using Machine Learning Methods. Energies. 2019; 12(9):1680. https://doi.org/10.3390/en12091680
Chicago/Turabian StyleSu, Moting, Zongyi Zhang, Ye Zhu, Donglan Zha, and Wenying Wen. 2019. "Data Driven Natural Gas Spot Price Prediction Models Using Machine Learning Methods" Energies 12, no. 9: 1680. https://doi.org/10.3390/en12091680
APA StyleSu, M., Zhang, Z., Zhu, Y., Zha, D., & Wen, W. (2019). Data Driven Natural Gas Spot Price Prediction Models Using Machine Learning Methods. Energies, 12(9), 1680. https://doi.org/10.3390/en12091680