Locked Deduplication of Encrypted Data to Counter Identification Attacks in Cloud Storage Platforms



Abstract
:1. Introduction
- Poison attacks. In this attack, an adversary tries to store maliciously manipulated data instead of the original data such that legitimate users obtain the harmed data. The poison attack is the most serious threat to storage services with deduplication because the purpose of an adversary is to store poisoned data instead of the original data. If the server has a poisoned file, clients could lose their data. A more serious problem is that the clients can be infected with malicious codes injected by the adversary into the poisoned file. Hence, security against poison attacks should be guaranteed.
- Dictionary attacks. In this attack, an adversary tries to guess a file by constructing a dictionary of possible data and then tests the correctness of all files in the dictionary. For the correctness test, an adversary can mount an offline dictionary attack where the test can be performed either offline or online, which permits the adversary to check a guessed file by performing an online protocol. An adversary can test a number of guessed files in offline attacks only if they can obtain data stored in a storage server, and, thus, the security against offline attacks are not considered as a real threat to security. Although an adversary can mount an online dictionary attack easily, we have a simple countermeasure against it that limits the number of protocol executions. Note that, in general, private data such as employment contracts are the typical target of dictionary attacks.
- Identification attacks. In this attack, an adversary tries to identify the existence of a specific file. In general, the adversary can check the existence of such file by using conditional protocol executions in client-side deduplication techniques. The objective of identification attacks is to break the privacy of clients based on the measured feature. Although dictionary attacks seem similar to identification attacks in that an adversary makes a set of guessed data and checks the existence of each guess, they are different attacks that should be dealt with separately. The main difference between these two attacks is that dictionary attacks use the existence of a guessed file to check the correctness of the guessed file, whereas identification attacks use the existence of a known file to break the privacy of a client-side deduplication technique. Note that, for security algorithms or protocols, the aim is to prevent any possibility that can cause a security weakness. Identification attacks are considered for the security of storage services because these attacks show the possibility of breaking the file owners’ privacy.
2. Uncertainness for Conditional Responses
2.1. Client-Side Deduplication
- Step 1. To verify the existence of the ciphertext C, Clt generates a tag for the file. In general, a cryptographic hash function is used to generate the tag, and the tag is simply computed as . Then, Clt sends the tag to Srv.
- Step 2. Srv verifies the existence of C using the given . If the file is not stored in its storage, Srv sends N/A to Clt and allows the client to upload the file; otherwise, Srv generates a challenge and sends it to Clt.
- Step 3. If Clt receives N/A from Srv, he/she uploads the ciphertext C, stops the protocol, and deletes the ciphertext C from his/her storage; otherwise, Clt computes as a proof to answer a given challenge by using the ciphertext C. Then, Clt sends to Srv.
- Step 4. Srv verifies the given proof . If it is correct, Srv affirms Clt’s ownership of the ciphertext C; otherwise, Srv sends N/A to Clt.
- Step 5. When Clt receives N/A, Clt uploads the ciphertext C and deletes it from his/her storage; otherwise, Clt deletes the ciphertext C from his/her storage without uploading the file.
2.2. Privacy Leakage in Client-Side Deduplication
2.3. Binary Decision ≠ Binary Information
2.3.1. Providing Uncertainness to a YES Response
2.3.2. Providing Uncertainness to a NO Response
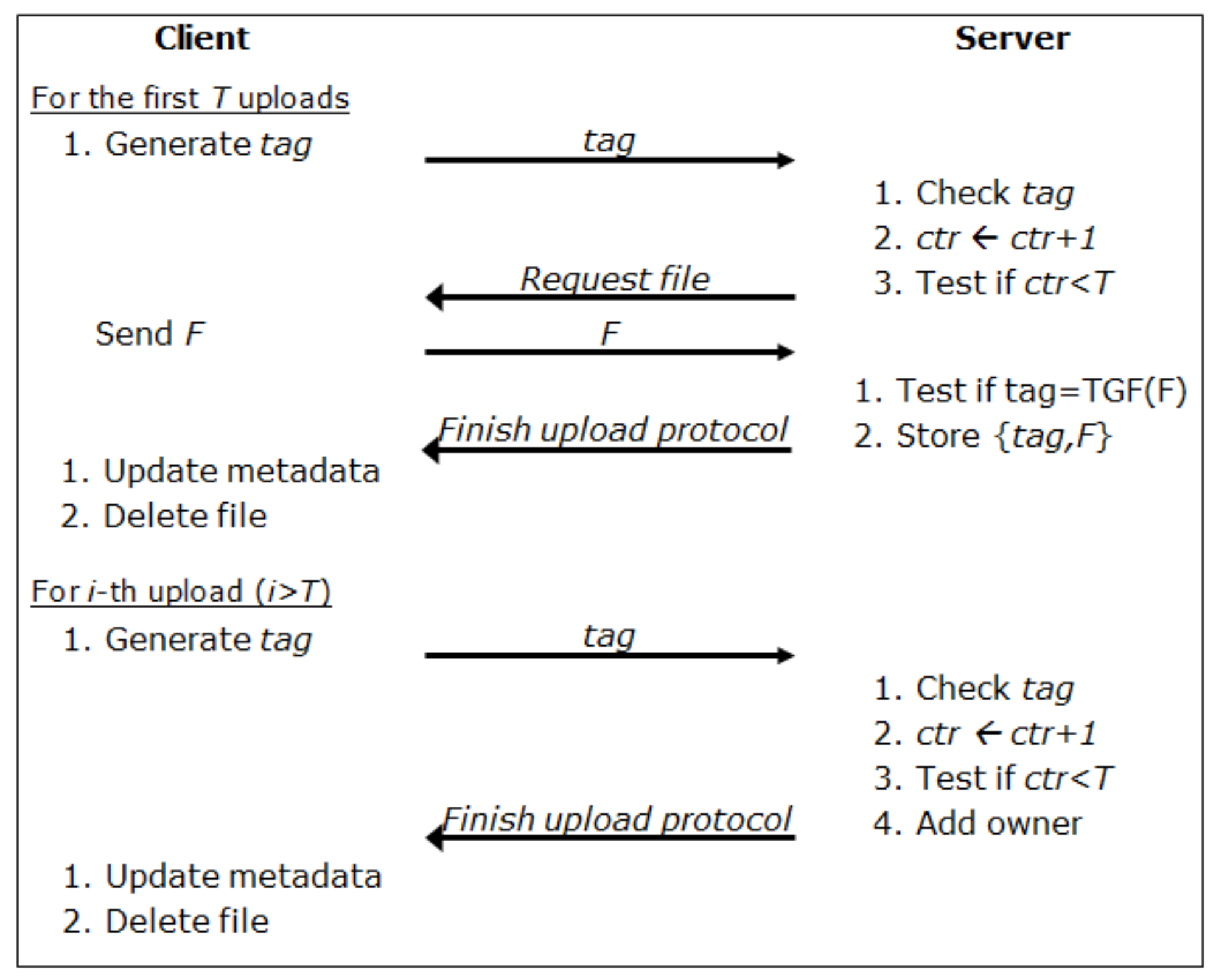
2.4. Conditionally Activated Deduplication System
3. Time-Based Locked Deduplication Technique Using a Pairing Operation
3.1. Design Considerations
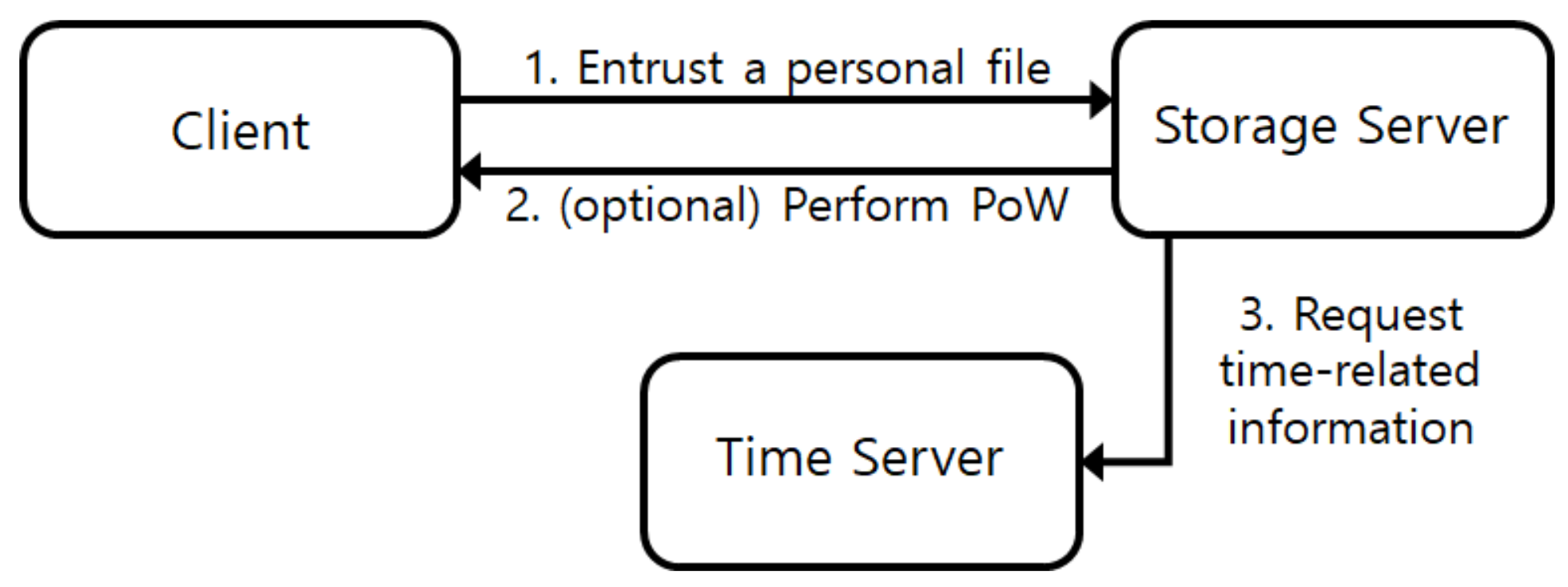
3.1.1. System Model
- Client. This party outsources data to a cloud storage. Before uploading his/her file, the client can lock the file so that it cannot be used in deduplication until a predefined time. The file can be unlocked with the help of the time server after the time when the locked file can be unlocked.
- Cloud Storage Server. This party provides data storage services to users and uses a deduplication mechanism to save cost for supporting services. The server may behave maliciously to save costs if the malicious behavior does not get detected. During the deduplication process, if the file to be stored already exists in the server’s storage, the server can perform a proof-of-ownership protocol with the client to verify that the client really owns the file.
- Time Server. This party generates and publishes time-related information for each time period. We assume that the time server does not collude with a storage server.
3.1.2. Who Locks the Information?
3.1.3. Who Unlocks the Locked Information?
3.1.4. Requirements
- Ordinary functionalities for client-side deduplication services should operate correctly, regardless of the additional functionalities for managing locked information. For this feature, (1) a file uploaded for the first time should be stored in the server’s storage, (2) a client can obtain the ownership of a file without uploading it if the file is already stored in the server’s storage, and (3) a user can retrieve data if the ownership of the file is assigned to the user.
- A locked deduplication mechanism should operate correctly in the sense that (1) locked information should not be unlocked until a predefined time t is reached and (2) the locked information must be unlocked after t is reached.
3.2. Basic Idea: Time-Based Locked Deduplication
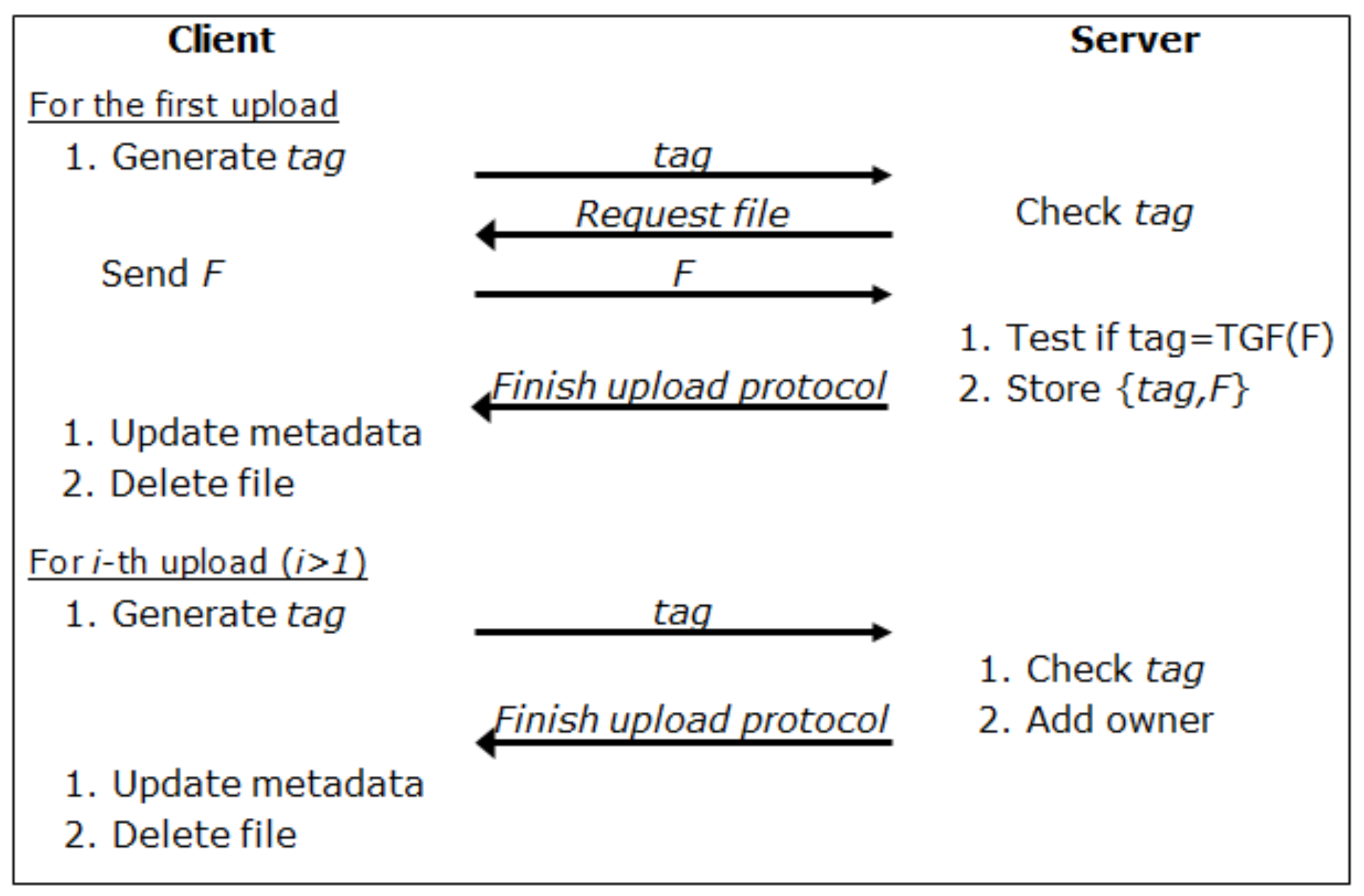
3.3. Basic Construction: Naive Locked Deduplication Scheme
3.3.1. Online Phase
- Step 1. To check the existence of the file F, the client Clt computes the following:Then, the client sends the tag to Srv.
- Step 2. The server Srv searches for a file in its storage using the given tag. If there is a file that is indexed by the tag, Srv assigns the ownership of the searched file to the client and notifies Clt of its existence; otherwise, the server notifies Clt that the file is absent by sending N/A to Clt and allows the client to upload the file.
- Step 3. If Clt receives N/A from Srv, the client chooses a random r and a time t, and computes , , and . Then, he/she generates a locked ciphertext aswhere . Then, the client uploads the time-locked informationto the server and deletes the file F from his/her storage; otherwise, Clt deletes the file F without uploading it.
3.3.2. Offline Phase
- Step 1. For each time t, publishes the time-related value . The time server can transmit time-related values to storage servers by various means; however, we consider the case where the time server publishes the information on a bulletin board. Then, at time t, may publish on its bulletin board.
- Step 2. When the time-related value is published by , the server Srv retrieves the locked information from its storage and computesThen, the storage server can unlock the time-locked ciphertext by computingWhen the file indexed by is first unlocked, the server verifies the correctness of the tag by comparing with . If the two values are the same, the storage server Srv deletes from , sets , and stores to DB. When the file indexed by already exists in the server’s storage, the server tests whether the unlocked ciphertext is identical to the existing one and adds to if the equality test holds. If the equality test does not hold, the server regards the user whose identity is as a malicious user and adds the user’s identity to a black list (If one tag can be used for indexing two or more files, we have to perform the equality test procedure more carefully. However, in this paper, we assume that only one file can be identified by one tag for simplicity of explanation; the assumption is reasonable because of the collision resistance of the hash function that is widely used as a tag generation function. Moreover, we can guarantee the assumption by using a longer hash value as a tag). Regardless of the results of the equality test, the server deletes .
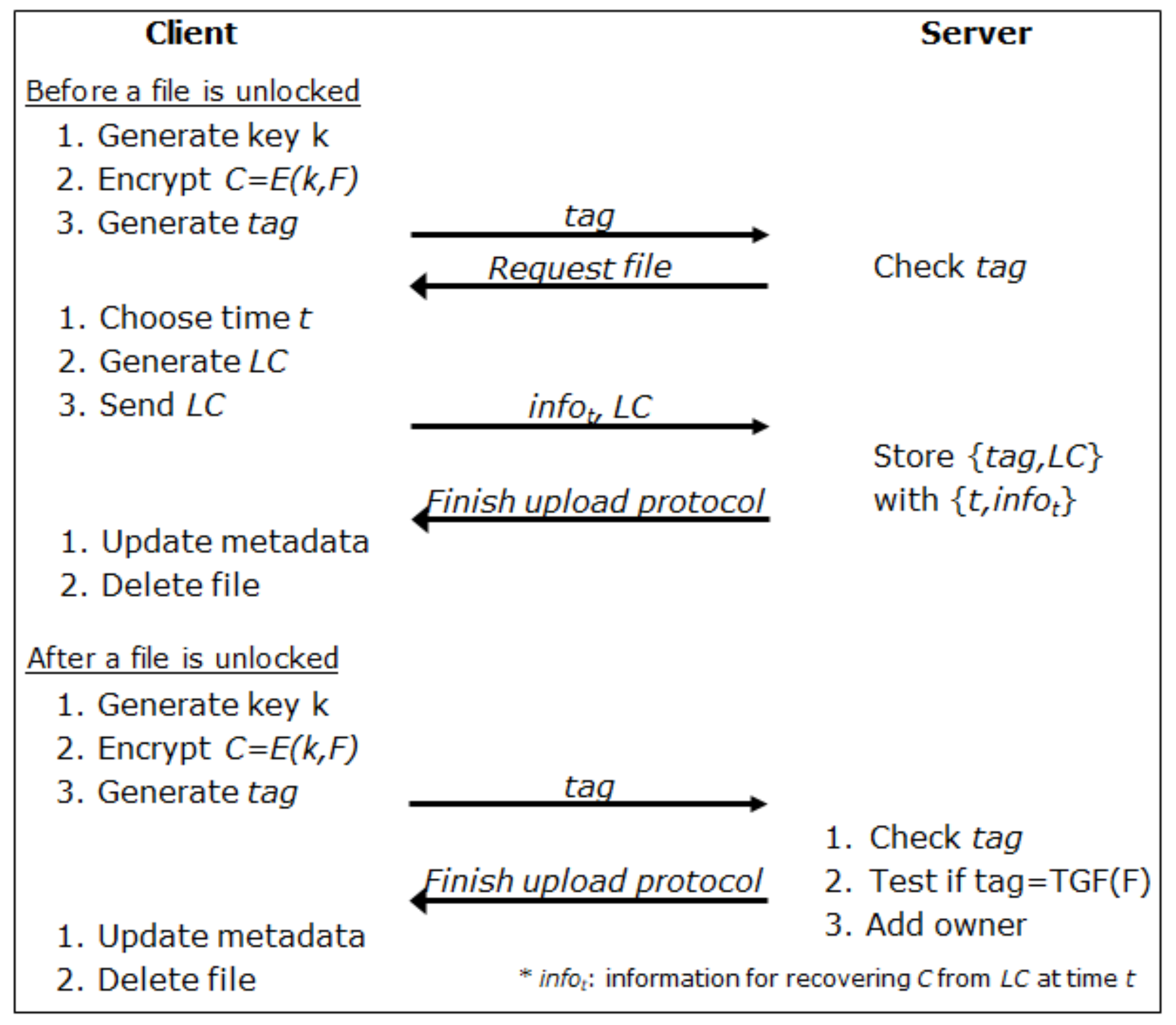
3.4. Secure Locked Deduplication Scheme
Online Phase
- Step 1. First, the client Clt contacts the key server to generate the key k for the file F. Then, the client computes the following:To check the existence of the file F, the client sends the tag to Srv.
- Step 2. The server Srv searches for the file in its storage using the given tag. If the file does not exist in the storage, the server notifies Clt that the file is absent by sending N/A and allows the client to upload the file; otherwise, the server and the client perform the proof-of-ownership protocol to prove that the client really owns the file. If the client passes the test, Srv assigns the ownership of the searched file to the client and informs Clt that the file exists. If the client cannot pass the test, the server terminates the protocol execution.
- Step 3. If Clt receives N/A from Srv, the client chooses a random r and a time t and computes , , and . Then, he/she generates a locked ciphertext aswhere . Then, the client uploads the time-locked informationto the server and deletes the file F from his/her storage; otherwise, Clt deletes the file F without uploading it.
3.5. Proof of Ownership
- Step 1. Srv generates a challenge and sends it to Clt with . Here, the challenge is a set of random indices of the leaf nodes of a Merkle tree for the ciphertext C.
- Step 2. For a given challenge, Clt compares with the last block of C. If the two values are identical, Clt accepts the given challenge as valid and responds to it by generating the sibling paths for all the indices presented as the challenge and sends them to Srv; otherwise, Clt rejects the challenge and terminates the protocol execution.
- Step 3. Based on the correctness of the given sibling paths, Srv determines Clt’s ownership of the ciphertext C.
4. Analysis
- Correct Deduplication
- Repeated copies can be deduplicated without incurring the loss of the original file.
- When predefined conditions hold, the storage server can open a set of locked files and perform a deduplication of repeated files.
- Secure Deduplication
- (For poison attacks) No adversary can break the security of the storage service system by uploading a corrupted file.
- (For dictionary attacks) An adversary cannot obtain any information to mount either offline or online guessing attacks without any limitation in the number of key generations.
- (For identification attacks) The storage server can only deduplicate unlocked files.
- (For identification attacks) Locked files can be unlocked only if the predefined conditions hold, and only the authorized and trusted party (or a set of parties) can control the conditions.
4.1. Security Analysis
- (1) The storage server can perform the deduplication operation only for unlocked files; and
- (2) The storage server cannot unlock any locked file without the help of authorized parties.
4.2. Efficiency
5. Conclusions
Author Contributions
Funding
Conflicts of Interest
References
- Lytras, M.D.; Raghavan, V.; Damiani, E. Big data and data analytics research: From metaphors to value space for collective wisdom in human decision making and smart machines. Int. J. Semant. Web Inf. Syst. IJSWIS 2017, 13, 1–10. [Google Scholar] [CrossRef]
- Storer, M.W.; Greenan, K.; Long, D.D.E.; Miller, E.L. Secure data deduplication. In 4th ACM International Workshop on Storage Security and Survivability; ACM: New York, NY, USA, 2008; pp. 1–10. [Google Scholar]
- Bellare, M.; Keelveedhi, S.; Ristenpart, T. Message-locked encryption and secure deduplication. In Annual International Conference on the Theory and Applications of Cryptographic Techniques; Springer: Berlin/Heidelberg, Germany, 2013. [Google Scholar]
- Chen, R.; Mu, Y.; Yang, G.; Guo, F. BL-MLE: Block-Level Message-Locked Encryption for Secure Large File Deduplication. IEEE Trans. Inf. Forensics Secur. 2015, 10, 2643–2652. [Google Scholar] [CrossRef]
- Zheng, Y.; Yuan, X.; Wang, X.; Jiang, J.; Wang, C.; Gui, X. Toward Encrypted Cloud Media Center With Secure Deduplication. IEEE Trans. Multimed. 2017, 19, 251–265. [Google Scholar]
- Cui, H.; Yuan, X.; Zheng, Y.; Wang, C. Enabling secure and effective near-duplicate detection over encrypted in-network storage. In IEEE INFOCOM 2016—The 35th Annual IEEE International Conference on Computer Communications; IEEE: New York, NY, USA, 2016; pp. 1–9. [Google Scholar]
- Harnik, D.; Pinkas, B.; Shulman-Peleg, A. Side channels in cloud services: Deduplication in cloud storage. IEEE Secur. Priv. Mag. 2010, 8, 40–47. [Google Scholar] [CrossRef]
- Li, J.; Chen, X.; Li, M.; Li, J.; Lee, P.P.C.; Lou, W. Secure deduplication with efficient and reliable convergent key management. IEEE Trans. Parallel Distrib. Syst. 2014, 25, 1615–1625. [Google Scholar] [CrossRef]
- Li, J.; Chen, X.; Xhafa, F.; Barolli, L. Secure deduplication storage systems with keyword search. In Proceedings of the AINA 2014; IEEE: New York, NY, USA, 2014; pp. 971–977. [Google Scholar]
- Li, J.; Li, Y.K.; Chen, X.; Lee, P.P.C.; Lou, W. A hybrid cloud approach for secure authorized deduplication. IEEE Trans. Parallel Distrib. Syst. 2015, 26, 1206–1216. [Google Scholar] [CrossRef]
- Marques, L.; Costa, C. Secure deduplication on mobile devices. In Proceedings of the 2011 Workshop on Open Source and Design of Communication; ACM: New York, NY, USA, 2011; pp. 19–26. [Google Scholar]
- Shin, Y.; Kim, K. Efficient and secure file deduplication in cloud storage. IEICE Trans. Inf. Syst. 2014, E97-D, 184–197. [Google Scholar] [CrossRef] [Green Version]
- Xu, J.; Chang, E.C.; Zhou, J. Weak Leakage-Resilient client-side deduplication of encrypted data in cloud storage. In Proceedings of the ASIA-CCS 2013; ACM: New York, NY, USA, 2013; pp. 195–206. [Google Scholar]
- Bellare, M.; Keelveedhi, S.; Ristenpart, T. DupLESS: Server-aided encryption for deduplicated storage. In Proceedings of the 22nd USENIX Conference on Security; USENIX Association: Washington, DC, USA, 2013; pp. 179–194. [Google Scholar]
- Liu, J.; Asokan, N.; Pinkas, B. Secure Deduplication of Encrypted Data without Additional Independent Servers. In Proceedings of the 22nd ACM SIGSAC Conference on Computer and Communications Security; ACM: New York, NY, USA, 2015; pp. 874–885. [Google Scholar]
- Liu, J.; Duan, L.; Li, Y.; Asokan, N. Secure Deduplication of Encrypted Data: Refined Model and New Constructions. In Proceedings of CT-RSA 2018; Springer: Cham, Switzerland, 2018; pp. 374–393. [Google Scholar]
- Halevi, S.; Harnik, D.; Pinkas, B.; Shulman-Peleg, A. Proofs of ownership in remote storage systems. In Proceedings of the 18th ACM Conference on Computer and Communications Security; ACM Press: New York, NY, USA, 2011; pp. 491–500. [Google Scholar]
- Blasco, J.; di Pietro, R.; Orfila, A.; Sorniotti, A. A tunable proof of ownership scheme for deduplication using bloom filters. In Proceedings of the CNS 2014; IEEE: New York, NY, USA, 2014; pp. 481–489. [Google Scholar]
- Husain, M.I.; Ko, S.Y.; Uurtamo, S.; Rudra, A.; Sridhar, R. Bidirectional data verification for cloud storage. J. Netw. Comput. Appl. 2014, 45, 96–107. [Google Scholar] [CrossRef]
- Di Pietro, R.; Sorniotti, A. Boosting efficiency and security in proof of ownership for deduplication. In Proceedings of the 7th ACM Symposium on Information, Computer and Communications Security; ACM: New York, NY, USA, 2012; pp. 81–82. [Google Scholar]
- Xu, J.; Zhou, J. Leakage resilient proofs of ownership in cloud storage. In International Conference on Applied Cryptography and Network Security; Springer: Cham, Switzerland, 2014; pp. 97–115. [Google Scholar]
- Yu, C.-M.; Chen, C.-Y.; Chao, H.-C. Proof of ownership in deduplicated cloud storage with mobile device efficiency. IEEE Netw. 2015, 29, 51–55. [Google Scholar] [CrossRef]






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Computational Cost | Size of Message | # of Round | |||
|---|---|---|---|---|---|
| Server | Client | Server | Client | ||
| Naive CS-Dedup | - | 4 | |||
| Counter-based CS-Dedup [7] | - | 4 | |||
| Locked-Dedup (Basic Model) | - | 4 | |||
| Condition for Unlock | Computational Cost | Size of Message | # of Round | |||
|---|---|---|---|---|---|---|
| Server | Client | Server | Client | |||
| Naive CS-Dedup | From the second uploader | - | 2 | |||
| Counter-based CS-Dedup [7] | From the T-th uploader | - | 2 | |||
| Locked-Dedup (Basic Model) | After the time | - | 2 | |||
| Encrypted Data | Poison Attacks | Identification Attacks | Dictionary Attacks | Supporting PoWs | |
|---|---|---|---|---|---|
| Naive CS-Dedup | X | O (Can be prevented by performing server-side tag verification) | X | X (Known methods can be applied to encrypted data) | Any PoWs schemes can be used |
| Counter-based CS-Dedup [7] | X | ||||
| Locked-Dedup (Full Model) | O | O | O (Section 3.4) | Proposed PoW (Section 3.5) |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Youn, T.-Y.; Jho, N.-S.; Kim, K.; Chang, K.-Y.; Park, K.-W. Locked Deduplication of Encrypted Data to Counter Identification Attacks in Cloud Storage Platforms. Energies 2020, 13, 2742. https://doi.org/10.3390/en13112742
Youn T-Y, Jho N-S, Kim K, Chang K-Y, Park K-W. Locked Deduplication of Encrypted Data to Counter Identification Attacks in Cloud Storage Platforms. Energies. 2020; 13(11):2742. https://doi.org/10.3390/en13112742
Chicago/Turabian StyleYoun, Taek-Young, Nam-Su Jho, Keonwoo Kim, Ku-Young Chang, and Ki-Woong Park. 2020. "Locked Deduplication of Encrypted Data to Counter Identification Attacks in Cloud Storage Platforms" Energies 13, no. 11: 2742. https://doi.org/10.3390/en13112742
APA StyleYoun, T. -Y., Jho, N. -S., Kim, K., Chang, K. -Y., & Park, K. -W. (2020). Locked Deduplication of Encrypted Data to Counter Identification Attacks in Cloud Storage Platforms. Energies, 13(11), 2742. https://doi.org/10.3390/en13112742