Artificial Learning Dispatch Planning with Probabilistic Forecasts: Using Uncertainties as an Asset


Abstract
:1. Introduction
1.1. Flexible Dispatch Planning Existing Solutions and Challenges
1.2. Weather Forecasts: Predicting RES Resource
1.3. Objectives of the Current Work
2. Materials and Methods
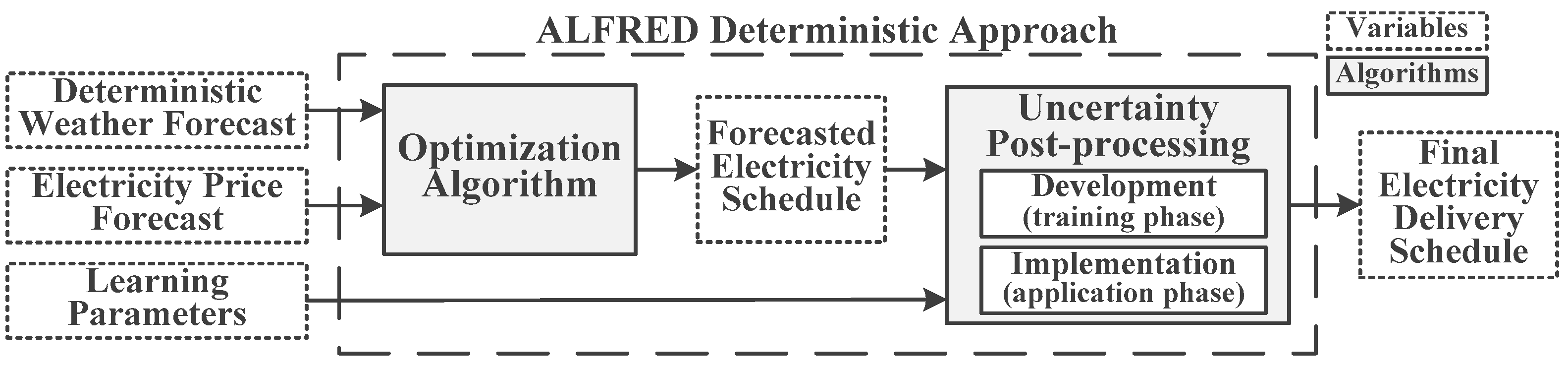
2.1. ALFRED Schedule Planning Based on a Deterministic Forecast
2.2. ALFRED Schedule Planning Based on a Probabilistic Forecast
2.2.1. Learning Parameter Inclusion
2.2.2. Adaptation of UPP Development
- Rule 1
- If deviation from ensemble mean is positive AND deviation from persistence is very negative AND day of the year belongs to spring or winter AND hour priority is high or very high, THEN deviation from perfect is neutral.
- Rule 2
- If deviation from ensemble mean is positive AND deviation from persistence is positive, THEN deviation from perfect is positive.
- Rule 3
- If deviation from ensemble mean is very positive AND deviation from persistence is very positive, THEN deviation from perfect is very positive.
2.2.3. Adaptation of UPP Implementation
3. Results
3.1. Simulations’ Data and Conditions
3.2. General Analysis of Simulation Results
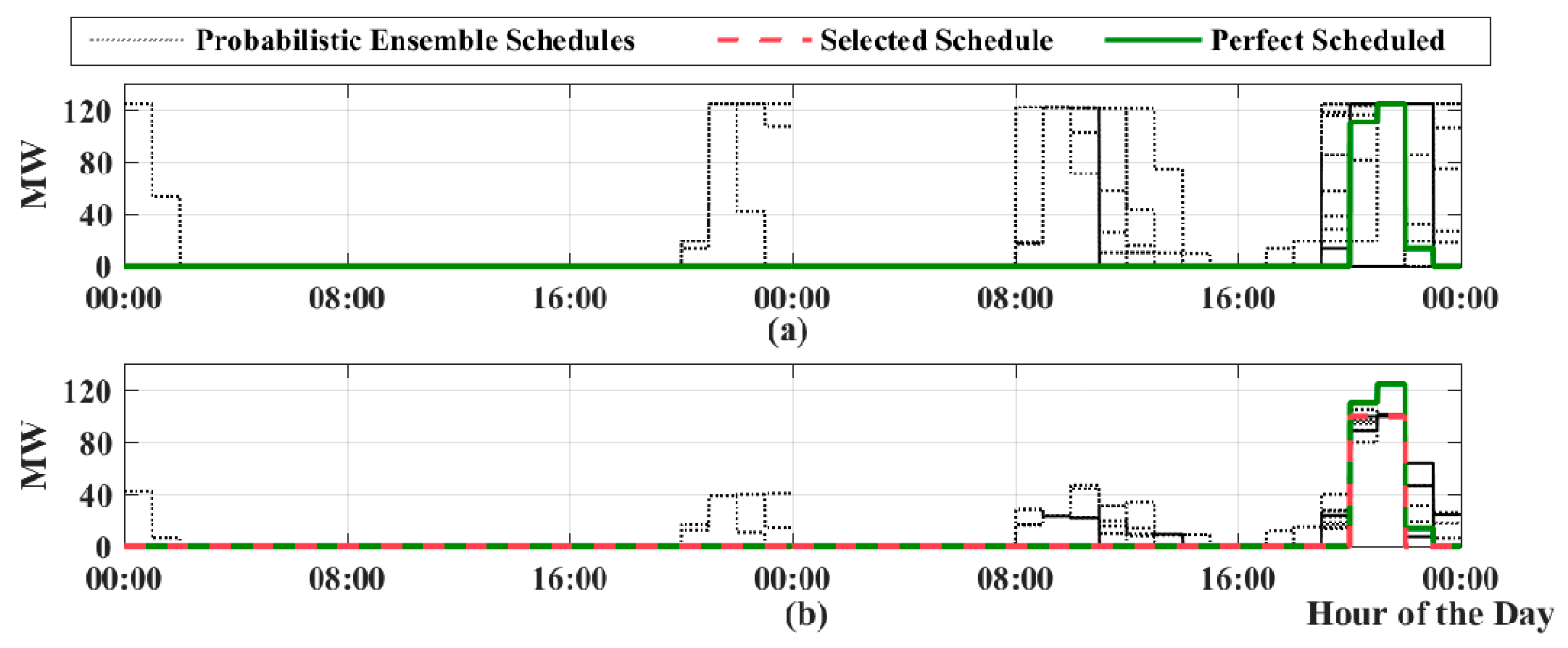
3.3. Detailed Analysis of Probabilistic Dispatch Planning
4. Discussion and Conclusions
Author Contributions
Funding
Conflicts of Interest
Nomenclature
| Final scheduled electrical power to be delivered to grid | |
| Mean value of scheduled electrical power ensemble in the probabilistic case | |
| Scheduled electrical power based on persistence forecast | |
| Scheduled electrical power based on perfect forecast | |
| Forecasted electrical power schedules based on optimization algorithm, where i = 1, 2, …, z and z is the total amount of generated schedules | |
| Adjusted electrical power schedules by the uncertainty-post processing algorithm, where i = 1, 2, …, z and z is the total amount of generated schedules | |
| Deviation from forecasted schedule to ensemble mean, where i = 1, 2, …, z and z is the total amount of generated schedules | |
| Deviation from forecasted schedule to persistence schedule, where i = 1, 2, …, z and z is the total amount of generated schedules | |
| Deviation from forecasted schedule to perfect schedule, where i = 1, 2, …, z and z is the total amount of generated schedules |
References
- Reddy, S.S. Optimal power flow with renewable energy resources including storage. Electr. Eng. 2017, 99, 685–695. [Google Scholar] [CrossRef]
- Lee, D.; Kim, K. Recurrent Neural Network-Based Hourly Prediction of Photovoltaic Power Output Using Meteorological Information. Energies 2019, 12, 215. [Google Scholar] [CrossRef] [Green Version]
- Abdel-Nasser, M.; Mahmoud, K. Accurate photovoltaic power forecasting models using deep LSTM-RNN. Neural Comput. Appl. 2019, 31, 2727–2740. [Google Scholar] [CrossRef]
- Zhang, J.; Verschaex, R.; Nobuhara, S.; Lalonde, J. Deep Photovoltaic Nowcasting. Sol. Energy 2018, 176, 267–276. [Google Scholar] [CrossRef] [Green Version]
- Mathe, J.; Miolane, N.; Sebastien, N.; Lequeux, J. PVNet: A LRCN Architecture for Spatio-Temporal Photovoltaic Power Forecasting from Numerical Weather Prediction. arXiv Preprint 2019, arXiv:1902.01453. [Google Scholar]
- Wang, H.; Li, G.; Wang, G.; Peng, J.; Jiang, H.; Liu, Y. Deep learning based ensemble approach for probabilistic wind power forecasting. Appl. Energy 2017, 188, 56–70. [Google Scholar]
- Zugno, M.; Jonsson, T.; Pinson, P. Trading wind energy on the basis of probabilistic forecasts both of wind generation and of market quantities. Wind Energy 2013, 16, 909–926. [Google Scholar] [CrossRef] [Green Version]
- IRENA. Adapting Market Design to High Shares of Variable Renewable Energy; International Renewable Energy Agency: Abu Dhabi, United Arab Emirates, 2017. [Google Scholar]
- Nottrott, A.; Kleissl, J.; Washom, B. Storage dispatch optimization for grid-connected combined photovoltaic-battery storage systems. In Proceedings of the IEEE Power and Energy Society General Meeting, San Diego, CA, USA, 22–26 July 2012. [Google Scholar]
- Hanna, R.; Kleissl, J.; Nottrott, A.; Ferry, M. Energy dispatch schedule optimization for demand charge reduction using a photovoltaic-battery storage system with solar forecasting. Sol. Energy 2014, 103, 269–287. [Google Scholar] [CrossRef]
- Kraas, B.; Schroedter-Homscheidt, M.; Madlener, R. Economic merits of a state-of-the-art concentrating solar power forecasting system for participation in the Spanish electricity market. Sol. Energy 2013, 93, 244–255. [Google Scholar] [CrossRef]
- Orwig, K.; Ahlstrom, M.; Banunarayanan, V.; Sharp, J.; Wilczak, J.; Freedman, J.; Haupt, S.; Cline, J.; Bartholomy, O.; Hamann, H.; et al. Recent trends in variable generation forecasting and its value to the power system. IEEE Trans. Sustain. Energy 2015, 6, 924–933. [Google Scholar] [CrossRef]
- Vasallo, J.M.; Bravo, M.J. A novel two-model based approach for optimal scheduling in CSP plants. Sol. Energy 2016, 126, 73–92. [Google Scholar] [CrossRef]
- Wagner, M.J.; Newman, A.M.; Hamilton, W.T.; Braun, R.J. Optimized dispatch in a first-principles concentrating solar power production model. Appl. Energy 2017, 959–971. [Google Scholar] [CrossRef]
- Pousinho, H.M.; Contreras, J.; Pinson, P.; Mendes, V.M.F. Robust optimization for self-scheduling and bidding strategies of hybrid CSP-fossil power plants. Electr. Power Energy Syst. 2015, 67, 639–650. [Google Scholar] [CrossRef]
- Dominguez, R.; Baringo, L.; Conejo, A. Optimal offering strategy for a concentrating solar power plant. Appl. Energy 2012, 98, 3297–3318. [Google Scholar] [CrossRef]
- He, G.; Chen, Q.; Kang, C.; Xia, Q. Optimal Offering Strategy for Concentrating Solar Power Plants in Joint Energy Reserve and Regulation Markets. IEEE Trans. Sustain. Energy 2016, 7, 1245–1254. [Google Scholar] [CrossRef]
- Wittmann, M.; Eck, M.; Pitz-Paal, R.; Müller-Steinhagen, H. Methodology for optimized operation strategies of solar thermal power plants with integrated heat storage. Sol. Energy 2011, 85, 653–659. [Google Scholar] [CrossRef]
- do Amaral, A.C.; Burghi, H.; Tobias, P.; Robert, P. FRED: The Flexible Renewable Energy System Dispatch Optimizer. J. Sol. Energy Eng. 2019, 141. [Google Scholar] [CrossRef]
- do Amaral Burghi, A.C.; Hirsch, T.; Pitz-Paal, R. Artificial Learning Dispatch Planning for Flexible Renewable Energy Systems. Energies. submitted for publication.
- Möhrlen, C.; Bessa, R.J.; Barthod, M.; Goretti, G.; Siefert, M. Use of Forecast Uncertainties in the Power Sector: State-of-the-Art of Business Practices. In Proceedings of the 15th International Workshop on Large-Scale Integration of Wind Power into Power Systems as well as on Transmission Networks for Offshore Wind Power Plants, Energynautics, Vienna, Austria, 15–17 November 2016. [Google Scholar]
- Perez, R.; Kivalov, S.; Schlemmer, J.; Hemker, K., Jr.; Renne, D.; Hoff, T.E. Validation of short and medium term operational solar radiation forecasts in the US. Sol. Energy 2010, 84, 2161–2172. [Google Scholar] [CrossRef]
- CENER. Post-Processing for Deterministic and Probabilistic Weather Forecasting in Probabilistic Weather Forecasting; H2020-PreFlexMS project 2015: Madrid, Spain, 2015. [Google Scholar]
- Tracton, M.S.; Kalnay, E. Operational ensemble forecasting prediction at the National Meteorological Centre: Practical aspects. Weather 1993, 8, 379–398. [Google Scholar]
- Leith, C.E. Theoretical skill of Monte Carlo forecast. Mon. Weather Rev. 1974, 102, 409–418. [Google Scholar] [CrossRef] [Green Version]
- Gneiting, T.; Katzfuss, M. Probabilistic Forecasting. Annu. Rev. Stat. Its Appl. 2014, 125–151. [Google Scholar] [CrossRef]
- Tuohy, A.; Zack, J.; Haupt, S.E.; Sharp, J.; Ahlstrom, M.; Dise, S.; Grimit, E.; Mohrlen, C.; Lange, M.; Casado, M.G.; et al. Solar forecasting: Methods challenges and performance. IEEE Power Energy Mag. 2015, 13, 50–59. [Google Scholar] [CrossRef]
- Zhou, Z.; Botterud, A.; Wang, J.; Bessa, R.J.; Keko, H.; Sumaili, J.; Miranda, V. Application of probabilsitic wind power forecasting in electricity markets. Wind Energy 2013, 16, 321–338. [Google Scholar] [CrossRef]
- Gonzalez-Aparicio, I.; Zucker, A. Impact of wind power uncertainty forecasting on the market integration of wind energy in Spain. Appl. Energy 2015, 159, 334–349. [Google Scholar] [CrossRef]
- Appino, R.R.; Ordiano, J.A.G.; Mikut, R.; Faulwasser, T.; Hagenmeyer, V. On the use of probabilistic forecasts in scheduling of renewable energy sources coupled to storages. Appl. Energy 2018, 210, 1207–1218. [Google Scholar] [CrossRef]
- Arriagada, E.; Lopez, E.; Lopez, M.; Blasco-Gimenez, R.; Roa, C.; Poloujadoff, M. A probabilistic economic dispatch model and methodology considering renewable energy, demand and generator uncertainties. Electr. Power Syst. Res. 2015, 121, 325–332. [Google Scholar] [CrossRef]
- Botterud, A. Chapter 10—Forecasting Renewable Energy for Grid Operations. In Renewable Energy Integration (Second Edition)-Practical Management of Variability, Uncertainty, and Flexibility in Power Grids; Academic Press: Cambridge, MA, USA, 2017; pp. 133–143. [Google Scholar]
- Du, E.; Zhang, N.; Hodge, B.-M.; Kang, C.; Kroposki, B. Economic justification of concentrating solar power in high renewable energy penetrated power systems. Appl. Energy 2018, 649–661. [Google Scholar] [CrossRef]
- Quinlan, J.R. C4.5 Programs for Machine Learning; Morgan Kaufmann Publisher, Inc.: San Mateo, CA, USA, 1993. [Google Scholar]
- Breiman, L.; Friedman, J.; Stone, C.J.; Olshen, R.A. Classification and Regression Trees; Taylor & Francis: Abingdon, UK, 1984. [Google Scholar]
- Schroedter-Homscheidt, M.; Benedetti, A.; Killius, N. Verification of ECMWF and ECMWF/MACC’s global and direct irradiance forecasts with respect to solar electricity production forecasts. Meteorol. Z. 2016, 26, 119. [Google Scholar] [CrossRef]
- Kost, C.; Shammugam, S.; Jülch, V.; Huyen-Tran, N.; Schlegl, T. Levelized Cost of Electricity Renewable Energy Technologies. Fraunhofer Inst. Sol. Energy Syst. 2018. [Google Scholar]
- IRENA. Renewable Power Generation Costs in 2017; International Renewable Energy Agency: Abu Dhabi, United Arab Emirates, 2018. [Google Scholar]
- IEA. Re-Powering Markets: Market Design and Regulation During the Transition to Low-Carbon Power Systems; OECD/IEA: Paris, France, 2016. [Google Scholar]
- Eichman, J.; Denholm, P.; Jorgenson, J. Operational Benefits of Meeting California’s Energy Storage Targets; National Renewable Energy Laboratory (NREL): Golden, CO, USA, 2015.
- OMIE. Resultados del Mercado. 2018. Available online: http://www.omie.es/ (accessed on 30 April 2018).
















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Variable | Description | Calculation | Deterministic Approach | Probabilistic Approach |
|---|---|---|---|---|
| Deviation from ensemble mean | The power difference between the forecasted schedule under analysis and the mean of the all the possible schedules. | Not used | Used | |
| Deviation from persistence schedule | The power difference between the forecasted schedule and the schedule developed based on a persistence forecast (the benchmark in forecasting, used when no forecast product is available—it considers that the day tomorrow will be exactly like today). | Used | Used | |
| Day of the year | The number of the day among the year. | Used | Used | |
| Hour priority | The priority of the hour under analysis according to its market price. Higher price hours have higher priority, in a decreasing order until the lowest price. For hours with same price, higher priority is given to the earlier one, as energy losses are expected to be avoided if production occurs earlier, and the meteorological forecast is usually more accurate for prior time instants. | Used | Used | |
| Deviation from perfect schedule | The power difference between the forecasted schedule and the schedule developed based on a perfect forecast (ideal forecast that considers weather observations as the prediction). | Used | Used | |
| Data Set Denomination | Weather Forecast Type | Data Used for Testing | Data Used for Training |
|---|---|---|---|
| det 2016 | deterministic | 2016 (January–December) | 2015 (May–December), 2017 (January–December), 2018 (January–May) |
| det 2017 | deterministic | 2017 (January–December) | 2015 (May–December), 2016 (January–December), 2018 (January–May) |
| eps 2016 | probabilistic | 2016 (January–December) | 2015 (May–December), 2017 (January–December), 2018 (January–May) |
| eps 2017 | probabilistic | 2017 (January–December) | 2015 (May–December), 2016 (January–December), 2018 (January–May) |
| Data Set Denomination | DNI | |
|---|---|---|
| Yearly Sum (kWh/m2) | RMSE | |
| Persistence 2016 | 2030.15 | 231.48 |
| det 2016 | 2093.65 | 162.53 |
| eps 2016 (ensemble mean) | 2287.09 | 158.32 |
| Perfect 2016 | 2032.50 | 0 |
| Persistence 2017 | 2171.37 | 213.80 |
| det 2017 | 2159.04 | 152.66 |
| eps 2017 (ensemble mean) | 2404.19 | 152.60 |
| Perfect 2017 | 2172.25 | 0 |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
do Amaral Burghi, A.C.; Hirsch, T.; Pitz-Paal, R. Artificial Learning Dispatch Planning with Probabilistic Forecasts: Using Uncertainties as an Asset. Energies 2020, 13, 616. https://doi.org/10.3390/en13030616
do Amaral Burghi AC, Hirsch T, Pitz-Paal R. Artificial Learning Dispatch Planning with Probabilistic Forecasts: Using Uncertainties as an Asset. Energies. 2020; 13(3):616. https://doi.org/10.3390/en13030616
Chicago/Turabian Styledo Amaral Burghi, Ana Carolina, Tobias Hirsch, and Robert Pitz-Paal. 2020. "Artificial Learning Dispatch Planning with Probabilistic Forecasts: Using Uncertainties as an Asset" Energies 13, no. 3: 616. https://doi.org/10.3390/en13030616
APA Styledo Amaral Burghi, A. C., Hirsch, T., & Pitz-Paal, R. (2020). Artificial Learning Dispatch Planning with Probabilistic Forecasts: Using Uncertainties as an Asset. Energies, 13(3), 616. https://doi.org/10.3390/en13030616