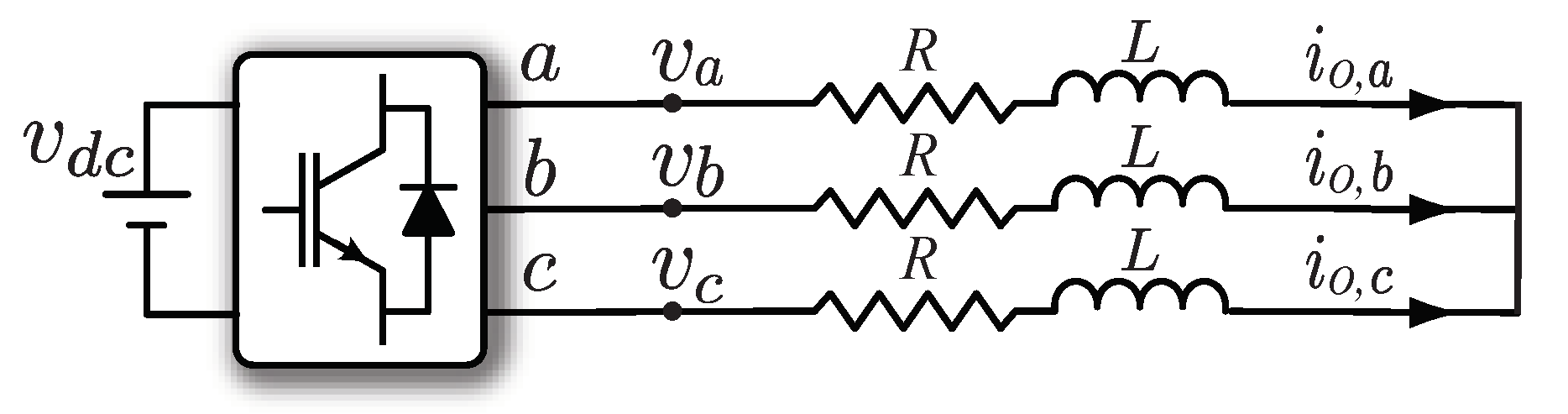
3.1. Configuring FPSoC Resources
As explained in
Section 1, the target platform for this work is a Xilinx Zynq 7000 FPSoC running on a Zedboard evaluation kit [
36]. Care must be taken to distribute tasks between the different resources available in this platform. Basically, the system is composed of a dual-core ARM Cortex-A9 processing system (PS) that can run up to 667 MHz and an Artix-7 FPGA-based programmable logic (PL). Shared memory resources, such as DDR3 Memory and On-Chip Memory (OCM), are available to share information between the FPGA side and the two processors. The data sharing process between the components is handled by a low latency AXI interface [
37].
In this implementation, three main tasks are executed periodically: First, measurements of the electrical magnitudes are sampled in every control interval. An external analog-to-digital converter (ADC) is used for this purpose. Specifically, the 12-bit, 16 sequential channels, SAR, Texas Instruments ADS7953 [
38]. Communications between the ADC and the control platform are based on the SPI protocol. Therefore, management of the ADC through the SPI protocol becomes one of the main tasks to be performed by the system. When all the measurements are available, the second task can be executed, which is the control algorithm itself. Finally, a third task consisting of external communications, which permit the interaction and data transfers from and to the system, has to be performed. The way these three main tasks are addressed is not trivial, as critical tasks like measurements and control algorithm calculations require real-time execution, not ensured by an operating system in general. External communications are not a critical task, thus being able to take advantage of an operating system-based solution without suffering its drawbacks.
To solve this, the structure depicted in
Figure 2 is proposed. One of the ARM cores executes a baremetal application that has access to the SPI peripheral and handles communication with the external ADC. A different design alternative would be to implement a custom peripheral in the programmable logic to handle the SPI communications. This option would be interesting if many parallel ADCs were used in this application, as the FPGA would be capable of implementing many of these SPI blocks in parallel. The decision to use the built-in peripheral in the ARM processor was made to highlight the usefulness of an FPSoC system compared to just an FPGA. Not everything must be designed in the hardware by the programmer, as peripherals included in the SoC can be used, which is usually a simpler solution for the designer and does not occupy extra resources in the FPGA. Also, only one SPI interface is used in this application, which the built-in SPI peripheral is perfectly capable of handling.
The CPU in charge of the baremetal application is interrupted by means of its private interruption channels by a signal from the FPGA. This event triggers the execution of an interrupt service routine where readings from the ADC are performed. When measurements are completed, they are written to specific registers in the shared DDR3 memory through an AXI4-Lite protocol implemented in one of the two 32-bit Master AXI ports available. This interface allows low latency and high bandwidth communications between the PS and the PL. These memory registers are then directly wired to internal signals in the FPGA.
After this, the control algorithm must be calculated. This task is performed by the FPGA. All calculations in the algorithm are performed as fixed point operations; this is because using floating point arithmetics in a FPGA design is much more demanding when it comes to power and resources consumption [
39]. 16-bit word length is used for the calculations of the implemented algorithm. Our quantization error is mostly defined by the 12-bit measurements that can be obtained from the system with the selected ADC. 16-bit fixed-point variables are used to have enough overhead in the calculations, avoiding the introduction of extra errors. The stability and accuracy of the algorithm is tested through MATLAB simulations, before the VHDL implementation for the FPGA. For these simulations, a C-code version of the algorithm is also executed using 16-bit integers. The basic methodology is to internally work with every variable in the algorithm within a desired integer scale, and latter obtain their real number correspondence by re-scaling, only when needed for graphical representation. Using 16-bit variables allows an efficient use of the 32-bit bus width used for memory sharing, as two variables may exactly fit in one register.
The programmable logic side also implements a hardware counter that governs the system’s timing and which is used to interrupt the CPU every sampling interval. The firing pulses are stored in the FPGA when the optimal switching state is selected and applied at the beginning of the next sample interval. A simple Finite-State Machine (FSM) implemented in the FPGA is in charge of operating the system, executing commands sent through a graphical user interface running in a PC.
The other ARM core available in the system takes care of communications. To make full use of the system, a Linux distribution supplied by Xilinx, called Petalinux [
40], is compiled and built making the necessary customizations to work along with the other CPU with no problems. This configuration is called “Asymmetric Multiprocessing” (AMP) and allows each core to run independent software stacks and executables [
41]. Beyond the guidelines proposed in [
41], special care must be taken when configuring the devicetree of the Petalinux OS. Default compilations supplied by Xilinx are made aware of peripherals included in the SoC. In particular, modifications to reserve exclusive access for ARM1 (baremetal application) to the software side GPIOs and one of the SPI controllers were necessary in this case. Detailed instructions to compile and modify the Petalinux OS can be found in [
42].
By running AMP with both a Petalinux OS in CPU0 and a baremetal application in CPU1, this platform becomes a great embedded solution that combines the flexibility of low-level baremetal applications to easily control peripherals and high level solutions provided by an operating system. In particular, an application executes in the Petalinux OS to communicate through TCP/IP protocol, transferring data using an Ethernet connection to the user interface executed in a PC. This user interface is built in order to allow the monitoring of the system and sending commands to the FSM implemented in the FPGA.
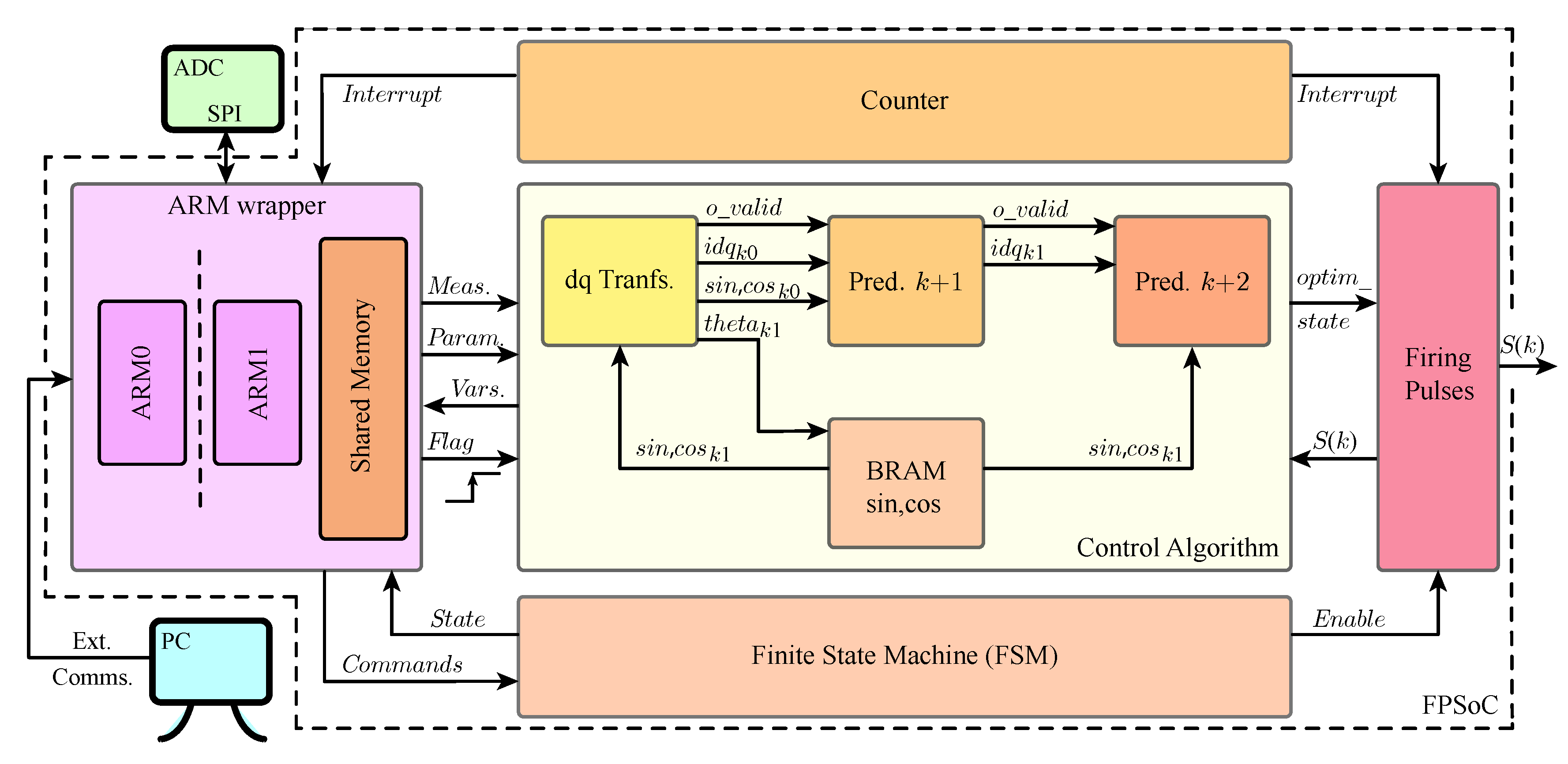
3.2. FPGA Implementation
In this case, an HDL-based solution is carried out to perform the control algorithm. A block diagram of the proposed hardware design is offered in
Figure 3. This diagram includes the FSM block and the counter described in
Section 3.1, together with the rest of the designed blocks.
The first step in the design is to include a wrapper block (“ARM Wrapper”) for the processing system (PS) in the hardware design. In this wrapper, the Zynq PS from the intellectual property cores (IP) library in Vivado must be added alongside all the auxiliary I/O blocks that can be used to interconnect PS ports with FPGA signals. Within this wrapper we define a customized peripheral, created using Vivado’s IP tools, which will be used to solve the data sharing between the PS and PL. This peripheral consists of a series of 32-bit memory registers that are associated to specific addresses in shared memory space, so they can also be read and written by applications executed in the ARM. This peripheral is accessed from both the PL and the PS through an AXI4-Lite interface [
37].
As it was described in
Section 3.1, the FPGA has access to every measurement once they are written to the shared memory. In this application, the FPGA notices this event by toggling a bit of a register in memory (“
”), which triggers a chain of operations until the optimal switching state for the next sampling interval is achieved.
These operations can be organized in three main blocks that must work sequentially as the calculations of the previous block are needed for the next one. These three blocks are shown in
Figure 3. They are from first to last: Clarke and Park’s transformation (“dq Transf.”, see
Figure 4 for more details), Prediction to
(“Pred.
k+1”), and Prediction to
(“Pred.
k+2”). A valid data signal (“
”) is propagated through the datapath to indicate that output data from each block is ready.
Transformation and Prediction to blocks are performed in order to obtain the -frame representation of the system variables and to compensate for the digital delay, respectively.
The implementation of these blocks is straightforward as they consist solely of a series of arithmetic operations. In our fixed-point algorithm, these operations are reduced to a series of simple sums, subtractions and multiplications between 16-bit integer numbers. To calculate sine and cosine functions for the corresponding phase angle, many different alternatives are at the designer’s disposal. IP cores that implement CORDIC algorithms are available in the Xilinx IP library. This option is discarded because of the extra latency introduced in the calculations by this method and because of the extra need for FPGA logic resources. Another option could be the use of a polynomial approximation of these functions, which could simplify the calculation of these trigonometric functions to a series of more simple calculations, but FPGA logic resources should also be spent on these calculations. The proposed solution in this paper is the use of RAM block resources. In particular, a RAM block with 4095 16-bit values is implemented (“BRAM sin,cos”). Several simulations were run through Matlab/Simulink to achieve the minimum number of values to be stored in memory that does not translate into a noticeable degradation of the resulting waveforms due to loss of accuracy. This block is fed with a 12 bits binary radians angle, which corresponds with the phase for the
sampling interval, therefore obtaining sine and cosine values for
(“
”). For the
k sampling interval, sine and cosine (“
”) are obtained introducing a one step digital delay as shown in
Figure 4.
With this solution, we infer a block RAM to store these values, instead of using other types of FPGA resources that would be preferably saved for other tasks. Coding guidelines for RAM blocks proposed in [
43] must be followed to achieve this. Note that logic slices can also be inferred by the synthesis tool to store data (this is known as “distributed RAM”). Therefore, following the [
43] guidelines, it is necessary to help the synthesizer select the required type of resource for our memory block.
The remaining operations can be expressed as a set of sums and multiplications that can be performed as a combinational circuit within each block. A synchronous flip-flop in the output of each block ensures synchronization of the datapath between blocks. The latency for the implemented blocks allows for the calculation of each one of these blocks in one clock cycle, when a 10 ns period clock is used. This ensures the availability of the results for the operation of the following block in the next clock cycle.
The implementation of the
prediction is not so immediate. The optimal state (“
”) must be selected by minimizing the cost function (
4). This optimization is performed by an ESA, which computes the necessary predictions for the
instant and their associated cost. Then, the value of the cost function for every possible candidate state is compared so the minimum can be selected. It is the need for this iteration what causes the high computational burden in the control algorithm, as the number of calculations grow exponentially as the number of prediction horizons increases. Two possible solutions are discussed here.
3.2.1. Parallel Prediction
In this case, a completely parallel implementation for the
prediction will be described. As depicted in
Figure 5, this approach consists of dividing every iteration of the loop that checks every possible state into hardware blocks that are in charge of calculating one prediction for one given state. Therefore, if eight predictions must be made for
, there will be eight identical blocks. Every block calculates the value for the cost function. A combinational comparator reads these values and selects the optimal switching state. Due to the architecture for this method, there is no need for pipelining and synchronous flip-flops placed in the output of every calculation block can be eliminated. This avoids the wait for a clock cycle after each block, decreasing calculation time. Opposed to that, all calculation blocks are inferred as combinational circuits whose results are propagated until a final optimal state for the next sampling interval is achieved.
This is the fastest solution when it comes to calculation time, but a great area consumption is expected from this implementation. Further statistics can be found in
Section 5.
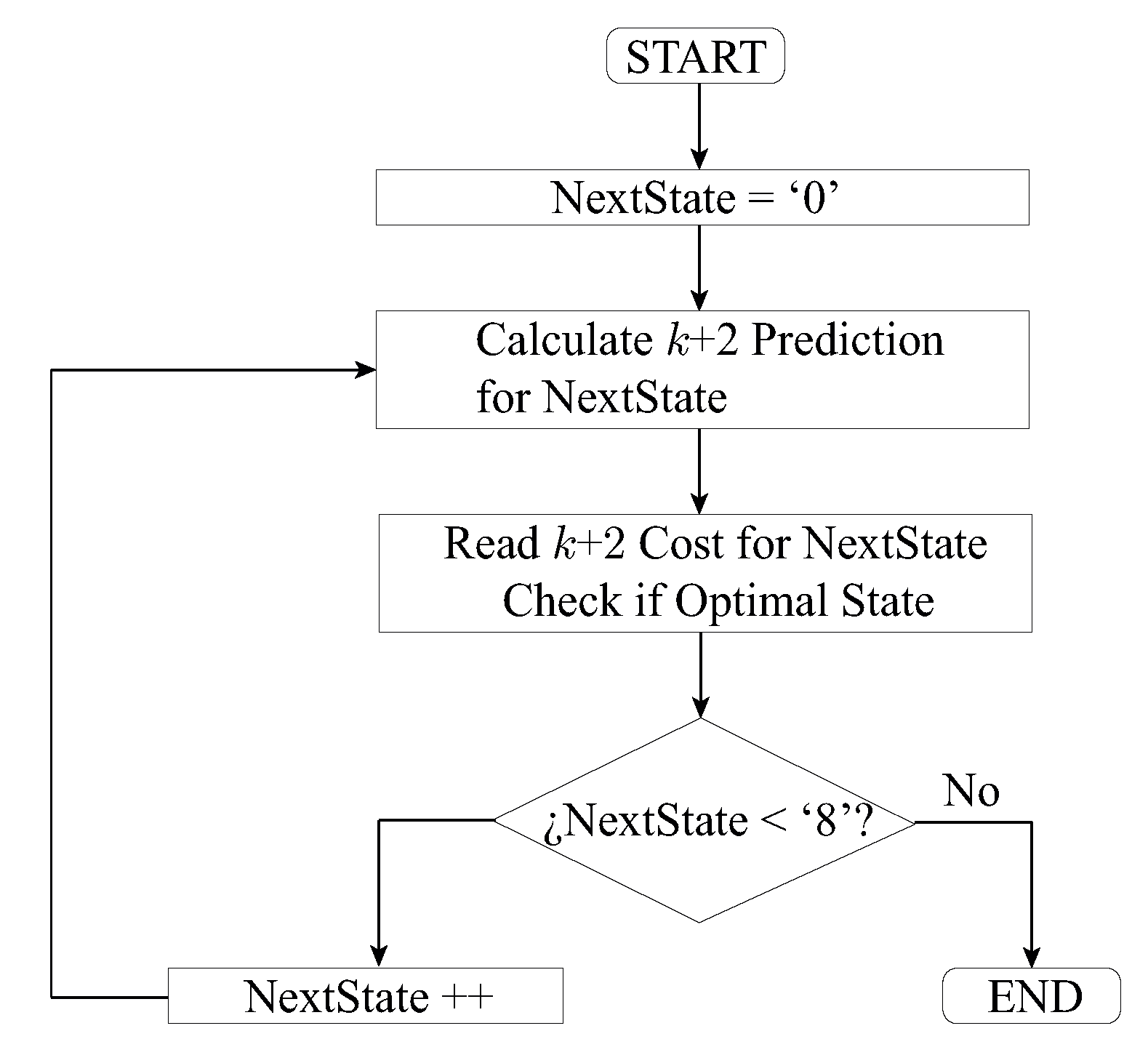
3.2.2. Sequential Prediction
In opposition to the previously described solution, a completely sequential design for the
prediction with only one prediction block could be adopted. Now, a pipeline structure that controls the access to the aforementioned block is necessary to ensure its availability and the validity of the results. This method is implemented with an FSM which is responsible of sequentially checking every possible state by feeding the state to be calculated to the
prediction block. Unlike the parallel solution, synchronous processes must be used to synchronize results with the clock signal. A flowchart for this method can be seen in
Figure 6.
With this solution, area consumption can be greatly reduced by decreasing the number of blocks to just one. Also, a comparator block with eight inputs is not necessary now since one of the states in the FSM can be used to compare every cost to the current optimal cost. The main drawback of this implementation is the longer time required to compute every prediction.
Finally, when the optimal switching state for the next control interval is obtained, this state is stored in a register until the counter, in charge of the system timing, signals the end of the control interval. The block “Firing Pulses” ensures the synchronization of the gate signals, and feeds the system with its current state (“”).

 ,
, 













{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}