1. Introduction
Distribution systems have presented several changes in the last years. Among the most significant ones, there is the integration of distributed energy resources (DER), which has been motivated by advances in power electronics and increased environmental awareness [
1]. High integration of DER makes distribution network operation more complex, requiring the introduction of advanced control functionalities [
2,
3]. The presence of high-level penetration DER and control resources on distribution networks has given rise to a new concept known as microgrid [
4,
5]. A microgrid is defined as a group of interconnected loads and DER, with clearly defined electrical boundaries, acting as a single controllable entity from the grid’s point of view, and operating in both grid-connected or islanded mode [
6]. The use of these systems brings operational, environmental, and economic benefits, such as improved reliability, integration of renewable energies, reduction of network losses, and better voltage profile [
7]. Nevertheless, microgrids present new challenges such as bidirectional power flow, considerable variations on fault currents levels, as well as power intermittency and quality issues, and additionally possible network reconfiguration, due to the presence of renewable energy sources [
8]. Protection systems inside the distribution grid are particularly affected because they are based on the principle of overcurrent and unidirectional power flow [
9]. Thus, traditional overcurrent protection schemes do not adequately protect microgrids [
10].
Several approaches have been proposed in the literature to deal with microgrid protection [
11]. These protection schemes can be classified into three classes: external protection, adaptive protection, and fault detection. The external protection (EP) approach uses additional equipment such as reactances, super-capacitors, or fault current limiters (FCL) for preventing misfiring of the protection devices [
12,
13,
14]. However, these solutions lack flexibility and, therefore, are not suitable for microgrids, where topology changes and DER connection/disconnection is possible [
15]. The adaptive protection (AP) approach works online to dynamically modify protection settings in order to address changes in the microgrid operating conditions [
16]. Some works have been proposed in this area [
17,
18,
19,
20,
21]. However, these methods depend strongly on wide-area measurements and require a significant investment in communication infrastructure. On the other hand, fault detection (FD) approaches allow smart operation under diverse fault and normal operating conditions. The FD systems proposed in [
22,
23] use intelligent micro-grid protection schemes based on data mining. However, typical network characteristics such as imbalance, topology changes, and upstream impedance changes are not considered [
24]. In [
25,
26], a combined Hilbert/S-transform and decision tree-based intelligent scheme for fault detection and classification in microgrids is presented. The proposed method preprocesses the faulted current signals by using the S-transform to extract differential statistical features at the ends of the respective feeder, which are then used to build a decision tree model for final relaying decision. This method requires synchronized measurements at both ends of the line because it uses the principle of differential protection. Such a requirement represents a disadvantage for rural microgrids due to the added complexity of installing and operating a robust communication network in those areas [
27]. Additionally, typical characteristics of the microgrids such as imbalance and topology changes are not considered by this approach. In [
28,
29,
30], the previous FD techniques are improved by considering to topology changes. The authors in [
31,
32] present a fault detector based on morphological techniques, transient content, and zero sequence current for adaptive overcurrent protection in distribution networks with increasing photovoltaic penetration as well as changing load conditions. The algorithm has built-in DC-offset suppression capability as well as recursive least square error filter for current phasor estimation to provide input to the overcurrent fault detector. Nevertheless, this method does not consider alternative operating modes, such as grid-connected versus islanded mode [
6].
Table 1 highlights the main aspects considered by FD state-of-the-art techniques and the proposed FD system and challenges that have not been faced.
From
Table 1, it is possible to remark that the main challenges that have not yet been fully addressed in terms of microgrid protection are the imbalance, dynamic topology, consideration of non-robust communication systems, adaptive coordination, and high-impedance faults occurrence.
This paper proposed a fault detection system for microgrids based on machine learning (ML) techniques. The proposed system formulated a set of organized procedures for database generation and processing, in terms of parameterization, training, and validation of ML techniques for fault detection. With the proposed FD approach, we addressed some weaknesses previously presented in state-of-the-art FD methods, such as network imbalance, synchronization of the measurements, changes in topology, non-robust communication systems, and on-grid/off-grid modes of operation. Aiming to show the main contributions of the proposed system,
Table 1 compares the FD state-of-the-art techniques with the proposed FD system and highlights the main aspects considered.
The following considerations were made for the development of this research:
Only low impedance faults were detected. High impedance faults were beyond the scope of this work.
The device coordination process was not addressed.
It was assumed that the microgrids had robust control functionalities to guarantee their stability after to clean the fault.
The remainder of the paper is structured as follows:
Section 2 presents the proposed fault detection system.
Section 3 describes the case study.
Section 4 contains the validation results and discussion. Finally, the conclusions of this work are presented in
Section 5.
4. Validation and Discussion
The validation of the proposed FD system was carried out by its implementation on the case study and the sensitivity analysis.
Section 4.1 and
Section 4.2 present the obtained results and discussion for the application of each stage of FD system and sensitivity analysis.
4.1. FD System Implementation
4.1.1. Stage I: Database from Simulations
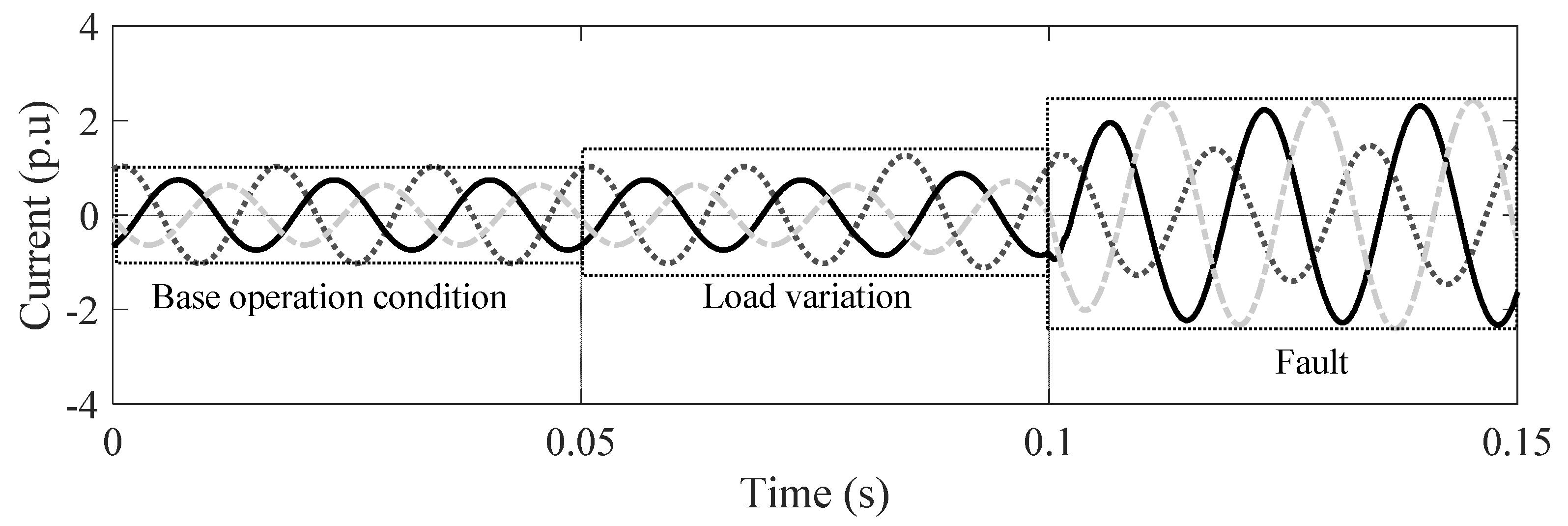
The database from simulations was obtained by simulating the possible operating scenarios of the microgrid. These scenarios were obtained from its operation modes (on-grid/off-grid) and three reference load conditions defined as low-load condition, half-load condition, and nominal-load condition, as presented in
Table 5.
Table A1,
Table A2 and
Table A3 of the
Appendix A show the load values used in the generation of the database.
Several factors for generation of the normal operation conditions and faulted conditions were used.
Table 6 presents the factors used in this stage. For each group (normal condition and faulted-condition), 23,606 scenarios were obtained, because the theory of the ML recommends that each class has the same number of scenarios so as not to bias the technique performance [
51]. For each scenario, voltage and current signals at the installation points of the IEDs were obtained. The location of the IED is illustrated in
Figure 6. Additionally, the labeling process mentioned in
Section 2.1.2 was also carried out. As a result of this stage, a database from simulations composed of the voltage and current signals at the installation points of the IED were obtained.
4.1.2. Stage II: Input Data Adjustment
In this stage, the 49 attributes defined in
Section 2.2 were estimated for each scenario obtained in stage 1. In addition, the randomization of the database was generated by using a random Python function that returns uniformly distributed pseudorandom numbers [
52]. The number of cases selected for the validation process was 7080.
4.1.3. Stage III: Parametrization and Training of ML Techniques
The parameterization process was carried out in the three steps mentioned in
Section 2.3. The following sections present their application to the case study.
Three classic ML techniques were used in the proposed methodology for the case study: random forest (RF), support vector machine (SVM), and K-nearest neighbors (K-NN). The selection of the ML technique was carried out by heuristic adjustment of its hyper-parameters to gain an improvement in its performance, as presented in
Section 2.3.1. The performance of the techniques was given by accuracy, as defined by Equation (3).
where
TF is the number of operation conditions that are true under fault;
TFW is the number of operation conditions that are true in fault with activation;
TNF is the number of operation conditions that are true under no-fault;
FF is the number of operation conditions that wrongly predicted a fault;
FFW is the number of operation conditions that wrongly predicted a fault with activation, and
FNF is the number of operation conditions that wrongly predicted a no-fault.
For this process, the 49 attributes for each database scenario were considered. In the next section, the performances for each ML technique in function of adjustment of their hyper-parameters are presented. These processes are executed for each IED, taking into account the validation dataset.
- ○
Support vector machine (SVM)
This SVM used a radial basis function kernel, which had two hyper-parameters,
and
. To assess the effect of each hyper-parameter individually, one of them was set to 1 and the other hyper-parameter was varied according to the interval of
Table 4.
Figure 7 shows the behavior of the accuracy of the SVM technique when the hyper-parameters were varied independently.
From
Figure 7a,b, it can be observed that ML technique performance improved for all IED as the hyper-parameters increased. However, there was a zone where the increase of the hyper-parameter did not produce an improvement in performance. Hyper-parameters must be adjusted near this zone to avoid overfitting.
- ○
Random forest (RF)
For random forest, the Gini criterion was selected to minimize the probability of misclassification. Therefore, the hyper-parameter to be adjusted was the number of trees.
Figure 8 shows the behavior of the accuracy of the RF technique when the number of trees was modified.
Similar to the previous case,
Figure 8 shows that if the number of trees was increased, a slight increase in accuracy was obtained. However, as the number of trees increased, this improvement tended to be negligible. The above occurred for a number of trees greater than eight, where the accuracy for relays was greater than 90% for RF technique evaluated. The best performance was achieved for relays 1 and 10. The good performance of relay 1 was probably related to the fact that it acted for all faults in on-grid connected mode, whereas in the off-grid mode, it should not detect faults. On the other hand, relay 10 only discriminated the faults that occurred in its line segment.
- ○
K-nearest neighbors (K-NN)
The performance of the K-NN technique in function of adjustment of its hyper-parameters was obtained. In this case, the hyper-parameter was the K neighbors.
Figure 9 presents the behavior of the accuracy of this technique when the number of K neighbors was modified.
For the K-NN technique, the performance decreased for all IED as the hyper-parameters increased. To avoid overfitting problems, the hyper-parameter should be adjusted to a small number of neighbors. For this technique, the number of neighbors’ K was set to 3. Note that it is possible to achieve accuracies greater than 87% for all relays regardless of K value. The accuracy for relays 1 and 10 was similar to that presented in
Figure 8. This supports the assumption that the allocation of these relays influences their performance.
- ○
Hyper-parameter setting for each ML technique
From the results obtained in
Figure 7,
Figure 8 and
Figure 9, the adjustment values of the hyper-parameters were selected by applying an exponential smoothing technique to each curve and taking their inflection point. These values were approximated to the nearest integer value, and the value that was repeated more often was taken as the hyper-parameter setting. The hyper-parameter setting for each ML technique is presented in
Table 7.
- ○
Comparison and selection of the ML technique
Table 7 shows that the best performing technique for the cases evaluated was RF. Additionally, the ML models obtained with this technique are easy to implement. For these reasons, RF was selected in this work.
The selection of representative attributes was carried out by means of PCA clustering and SVD clustering techniques, as presented in
Section 2.3.2.
Table 8 presents the number of representative attributes determined by each technique for each system relay. Additionally, it shows the percentage of information that represents the number of attributes.
Table 8 shows that the combination of 16 features can represent more than 98% of the information of the database. Therefore, 16 was selected as the maximum number of representative features. The above represents a significant reduction of attributes (from 49 to 16), which reduces the computational effort and the presenting of data scarcity [
53].
Once the maximum number of representative attributes was determined, a Chu–Beasly genetic algorithm was used in order to determine the combination of attributes that maximize the performance of the ML technique.
Section 2.3.3 presents the formulation of the algorithm used. The results obtained for each relay with its combination features and accuracy are shown in
Table 9.
These results showed high accuracy of the model obtained in the training process. However, it was necessary to determine the accuracy for events that were not used in the parameterization and training process, which is presented in
Section 4.1.4.
4.1.4. Stage IV: Validation
To validate the performance of the training models obtained in stage III, the 15% of the database generated in stage I, and that which was not used in the training process was considered. This validation considered all factors presented in
Table 6. Additionally, in order to guarantee the statistical validity of the experiment, the proposed FD system was executed 30 times for the tests evaluated.
Table 9 shows the accuracy of the ML models for each relay validated.
The results obtained showed satisfactory performance of the proposed FD system, presenting an accuracy greater than 95% for all cases evaluated. Although similar performances were reported in [
22,
23,
25,
26,
27,
28,
29,
30], in this work, a strategy to select the ML technique, the representative features, and their combination in order to optimize the performance of proposed FD technique were formulated. Additionally, all the stages were presented with enough detail for their understanding and replication, which is not usually observed in the FD state-of-the-art techniques.
However, these tests do not allow for the determination of the factors that affect most the performance of the FD system. In consequence, a sensitivity analysis was performed, as presented in the following section.
4.2. Sensitivity Analysis
In order to know the factors that directly affect the performance of the proposed FD system, a sensitivity analysis by an experimental design was executed. This was composed of a set of five factors, which are presented in
Table 10. For each level, 600 repetitions were executed in order to guarantee the statistical validity of the experiment.
According to the factors, levels, and the number of repetitions, the total number of experiments was 28,800, obtained by where is the number of repetitions and is the number of levels of the factor . Each experiment was represented with the accuracy obtained after each trained model was tested with the validating signals that described the experiment.
The homogeneity between all the populations that were described by the level combinations was validated by the sensitivity analysis. The above was achieved through the following hypothesis test:
where
i represents the level combination that has a different mean in case the null hypothesis was rejected [
54].
An analysis of variance ANOVA was selected as a way to refuse the null hypothesis. ANOVA residues were employed to verify accomplishment with the normality, independence, and homoscedasticity criteria. The above is shown in
Figure 10. In addition, statistical testds such as Jarque–Bera, Durbin–Watson, and Levene were executed as another way to confirm ANOVA assumptions.
The p-values of the statistical tests Jarque–Bera, Durbin–Watson, and Levene were 0.0945, 0.3395, and 0.2642, respectively. For all the tests, the p-values were higher than 0.05. Therefore, the assumptions of normality, homoscedasticity, and independence were validated, and the ANOVA results were truthful.
The results of the ANOVA are presented in
Table 11. Factors with
p-values greater than 0.05 were considered not statistically significant for the model studied.
The above occurred for factors A and C: fault type and load behavior, respectively. Therefore, it is possible to reject that these factors had an influential factor in the sensitivity of the proposed FD system. The above follows the shown behaviors, where each IED was composed of different feature combinations and presented different behavior with respect to the hyper-parameters of the techniques. On the other hand, it was expected that a grid connection such as the fault position had a statistical dependence because this incident affected the protection configuration directly.
5. Conclusions
This paper presented an intelligent fault detection system for microgrids. The obtained results showed a satisfactory performance, with an accuracy greater than 95.7% for the cases evaluated, although only voltage and current measurements registered locally by IED were used and the need for communication systems for the protection process was eliminated.
Additionally, the intelligent FD system presented a methodology composed of four steps that allowed for its implementation on any microgrid. From these steps, the database from simulations generating the process of micro-network operation and parameterization was highlighted.
The database-generating process presented recommendations for the generation of a high-quality database, which would guarantee the success of the use of ML models. The parameterization process showed how to determine the number of representative attributes that represent the largest amount of information in the database, which is valuable in order to reduce computational effort and avoid the presence of data scarcity. In addition, in the same parameterization process, a Chu–Beasley genetic algorithm was used to determine the best combination of attributes that would maximize the performance of ML techniques. Finally, the technique presented performances greater than 95% in both the training and validation process, and the sensitivity analysis showed that factors such as the fault type and load condition did not affect the performance of the proposed fault detection system, whereas other factors such as IED location were significant for the model. This implies that the training process must be executed on all available devices because, depending on this, the performance of the methodology might change.
Finally, we can summarize the main practical and economic benefits of employing the proposed FD system as being
reduction of implementation cost because it does not need a communication system to FD process;
diminishment of computational effort by the implementation of PCA, SVD, and Chu–Beasley techniques to reduce of number of features;
consideration of the main operation condition scenarios in the microgrid, such as connected/islanded mode of the grid, cut-off/cut-on generation, network imbalance, and changes in topology, which reduce the probability of mis-operation in the protection scheme.

 ,
, 


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}









