Understanding and Modeling Climate Impacts on Photosynthetic Dynamics with FLUXNET Data and Neural Networks †


Abstract
:
1. Introduction
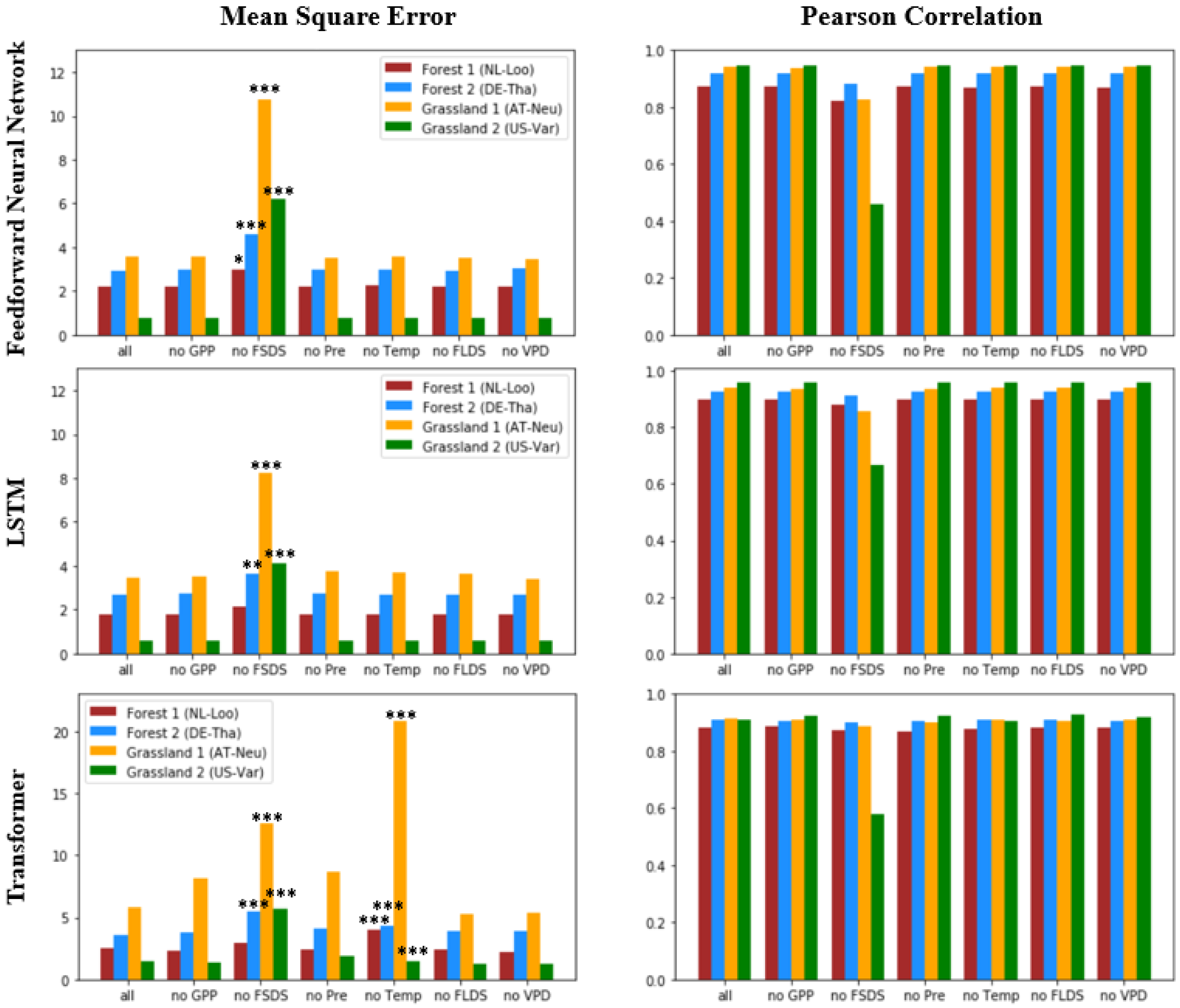
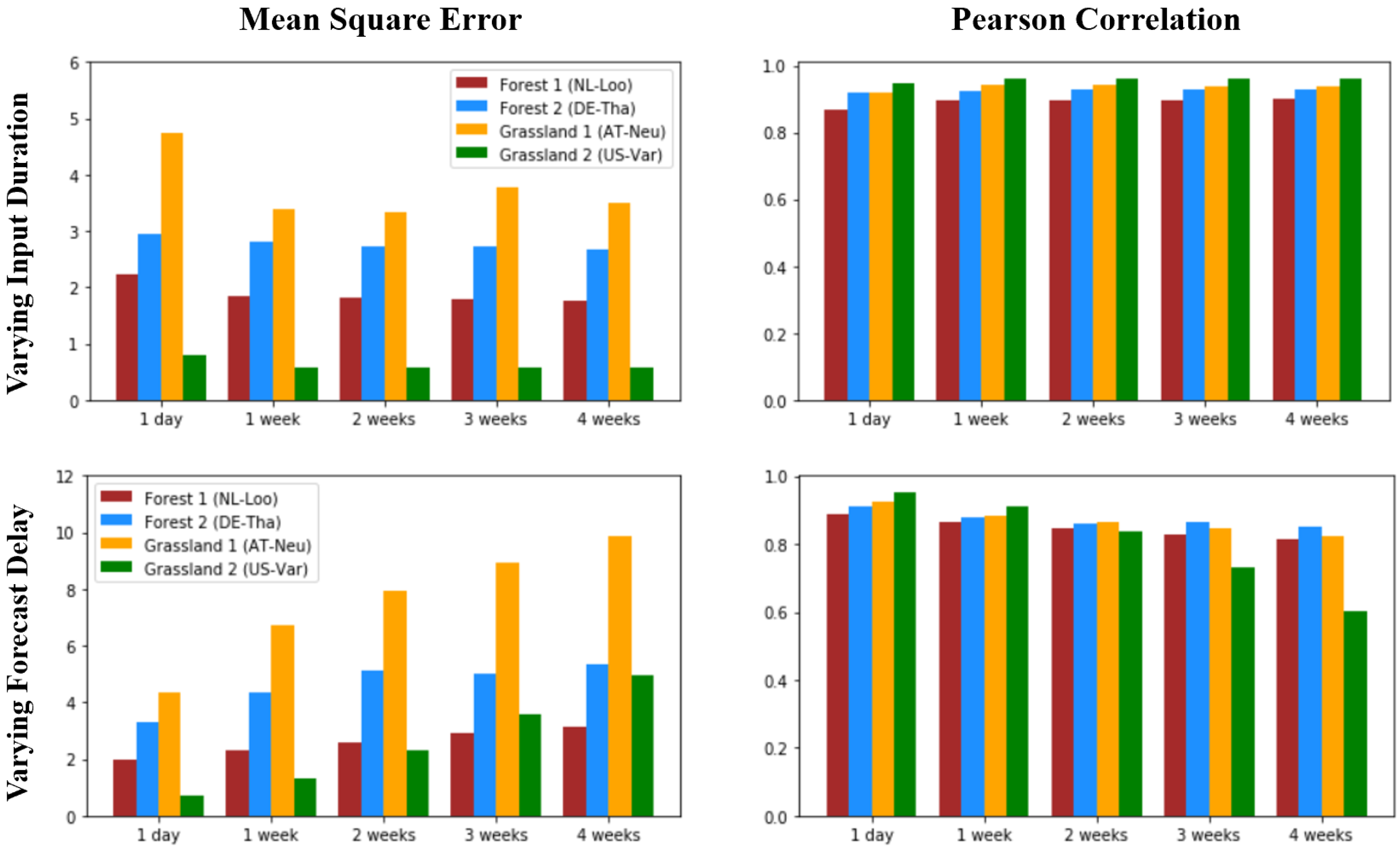
2. Results
3. Discussion
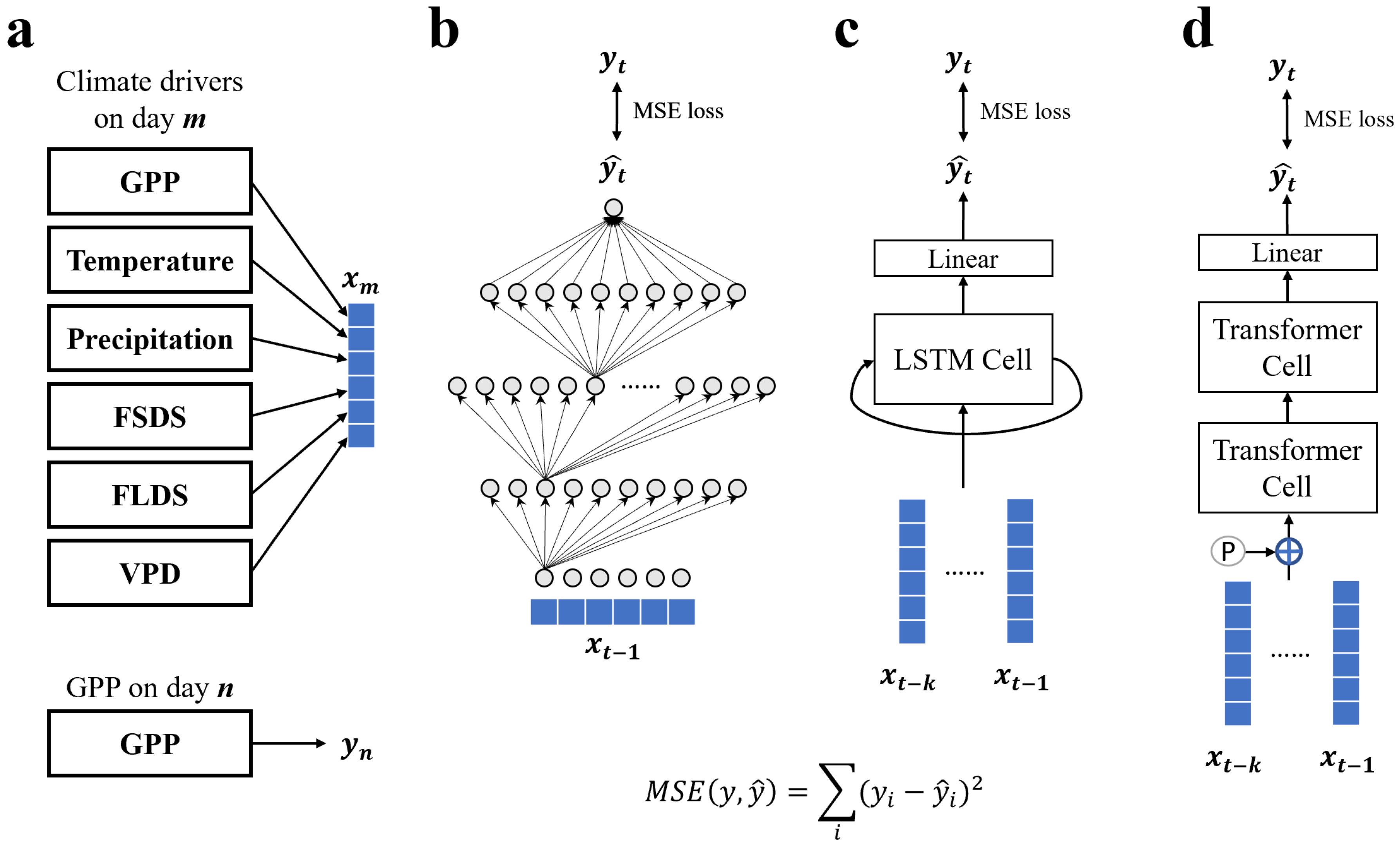
4. Materials and Methods
4.1. FLUXNET Dataset
4.2. Neural Network Architectures and Formulas
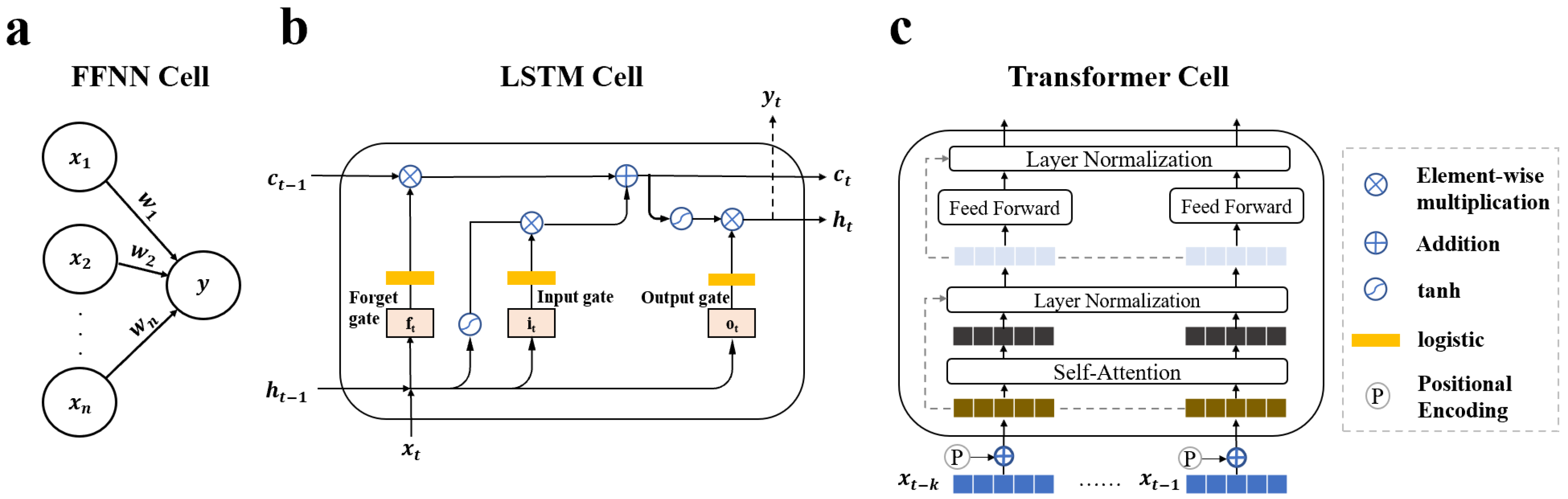
4.2.1. FFNN
4.2.2. LSTM
4.2.3. Transformer
4.3. Neural Network Implementation Details
5. Conclusions
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
Abbreviations
| ANOVA | analysis of variance |
| ATP | adenosine triphosphate |
| CO | carbon dioxide |
| FFNN | feedforward neural network |
| FLDS | longwave radiation |
| FSDS | shortwave/solar radiation |
| GPP | gross primary product |
| HMM | hidden Markov model |
| HSD | honestly significant difference |
| LSTM | long short-term memory |
| MSE | mean square error |
| NADPH | nicotinamide adenine dinucleotide phosphate hydrogen |
| Pre | precipitation |
| RNN | recurrent neural network |
| RuBisCO enzyme | Ribulose-1,5-bisphosphate carboxylase oxygenase |
| VPD | vapor pressure defict |
References
- Stips, A.; Macias, D.; Coughlan, C.; Garcia-Gorriz, E.; San Liang, X. On the causal structure between CO2 and global temperature. Sci. Rep. 2016, 6, 21691. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Falkowski, P.; Scholes, R.; Boyle, E.; Canadell, J.; Canfield, D.; Elser, J.; Gruber, N.; Hibbard, K.; Högberg, P.; Linder, S.; et al. The global carbon cycle: A test of our knowledge of earth as a system. Science 2000, 290, 291–296. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Beer, C.; Reichstein, M.; Tomelleri, E.; Ciais, P.; Jung, M.; Carvalhais, N.; Rödenbeck, C.; Arain, M.A.; Baldocchi, D.; Bonan, G.B.; et al. Terrestrial gross carbon dioxide uptake: Global distribution and covariation with climate. Science 2010, 329, 834–838. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Friedlingstein, P.; Houghton, R.; Marland, G.; Hackler, J.; Boden, T.A.; Conway, T.; Canadell, J.; Raupach, M.; Ciais, P.; Le Quéré, C. Update on CO2 emissions. Nat. Geosci. 2010, 3, 811–812. [Google Scholar] [CrossRef]
- Baldocchi, D.; Falge, E.; Gu, L.; Olson, R.; Hollinger, D.; Running, S.; Anthoni, P.; Bernhofer, C.; Davis, K.; Evans, R.; et al. FLUXNET: A new tool to study the temporal and spatial variability of ecosystem-scale carbon dioxide, water vapor, and energy flux densities. Bull. Am. Meteorol. Soc. 2001, 82, 2415–2434. [Google Scholar] [CrossRef]
- Medlyn, B.E. Physiological basis of the light use efficiency model. Tree Physiol. 1998, 18, 167–176. [Google Scholar] [CrossRef] [PubMed]
- Farquhar, G.D.; von Caemmerer, S.V.; Berry, J.A. A biochemical model of photosynthetic CO2 assimilation in leaves of C3 species. Planta 1980, 149, 78–90. [Google Scholar] [CrossRef] [Green Version]
- Papale, D.; Valentini, R. A new assessment of European forests carbon exchanges by eddy fluxes and artificial neural network spatialization. Glob. Chang. Biol. 2003, 9, 525–535. [Google Scholar] [CrossRef]
- Tramontana, G.; Ichii, K.; Camps-Valls, G.; Tomelleri, E.; Papale, D. Uncertainty analysis of gross primary production upscaling using Random Forests, remote sensing and eddy covariance data. Remote Sens. Environ. 2015, 168, 360–373. [Google Scholar] [CrossRef]
- Jung, M.; Reichstein, M.; Bondeau, A. Towards global empirical upscaling of FLUXNET eddy covariance observations: Validation of a model tree ensemble approach using a biosphere model. Biogeosciences 2009, 6, 2001–2013. [Google Scholar] [CrossRef] [Green Version]
- Xiao, J.; Zhuang, Q.; Baldocchi, D.D.; Law, B.E.; Richardson, A.D.; Chen, J.; Oren, R.; Starr, G.; Noormets, A.; Ma, S.; et al. Estimation of net ecosystem carbon exchange for the conterminous United States by combining MODIS and AmeriFlux data. Agric. Forest Meteorol. 2008, 148, 1827–1847. [Google Scholar] [CrossRef] [Green Version]
- Xiao, J.; Zhuang, Q.; Law, B.E.; Chen, J.; Baldocchi, D.D.; Cook, D.R.; Oren, R.; Richardson, A.D.; Wharton, S.; Ma, S.; et al. A continuous measure of gross primary production for the conterminous United States derived from MODIS and AmeriFlux data. Remote Sens. Environ. 2010, 114, 576–591. [Google Scholar] [CrossRef] [Green Version]
- Yang, F.; White, M.A.; Michaelis, A.R.; Ichii, K.; Hashimoto, H.; Votava, P.; Zhu, A.X.; Nemani, R.R. Prediction of continental-scale evapotranspiration by combining MODIS and AmeriFlux data through support vector machine. IEEE Trans. Geosci. Remote Sens. 2006, 44, 3452–3461. [Google Scholar] [CrossRef]
- Yang, F.; Ichii, K.; White, M.A.; Hashimoto, H.; Michaelis, A.R.; Votava, P.; Zhu, A.X.; Huete, A.; Running, S.W.; Nemani, R.R. Developing a continental-scale measure of gross primary production by combining MODIS and AmeriFlux data through Support Vector Machine approach. Remote Sens. Environ. 2007, 110, 109–122. [Google Scholar] [CrossRef]
- Jung, M.; Reichstein, M.; Ciais, P.; Seneviratne, S.I.; Sheffield, J.; Goulden, M.L.; Bonan, G.; Cescatti, A.; Chen, J.; De Jeu, R.; et al. Recent decline in the global land evapotranspiration trend due to limited moisture supply. Nature 2010, 467, 951–954. [Google Scholar] [CrossRef]
- Jung, M.; Reichstein, M.; Margolis, H.A.; Cescatti, A.; Richardson, A.D.; Arain, M.A.; Arneth, A.; Bernhofer, C.; Bonal, D.; Chen, J.; et al. Global patterns of land-atmosphere fluxes of carbon dioxide, latent heat, and sensible heat derived from eddy covariance, satellite, and meteorological observations. J. Geophys. Res. Biogeosci. 2011, 116. [Google Scholar] [CrossRef] [Green Version]
- Kondo, M.; Ichii, K.; Takagi, H.; Sasakawa, M. Comparison of the data-driven top-down and bottom-up global terrestrial CO2 exchanges: GOSAT CO2 inversion and empirical eddy flux upscaling. J. Geophys. Res. Biogeosci. 2015, 120, 1226–1245. [Google Scholar] [CrossRef]
- Schwalm, C.R.; Williams, C.A.; Schaefer, K.; Arneth, A.; Bonal, D.; Buchmann, N.; Chen, J.; Law, B.E.; Lindroth, A.; Luyssaert, S.; et al. Assimilation exceeds respiration sensitivity to drought: A FLUXNET synthesis. Glob. Chang. Biol. 2010, 16, 657–670. [Google Scholar] [CrossRef]
- Schwalm, C.R.; Williams, C.A.; Schaefer, K.; Baldocchi, D.; Black, T.A.; Goldstein, A.H.; Law, B.E.; Oechel, W.C.; Scott, R.L. Reduction in carbon uptake during turn of the century drought in western North America. Nat. Geosci. 2012, 5, 551–556. [Google Scholar] [CrossRef] [Green Version]
- Dou, X.; Yang, Y.; Luo, J. Estimating Forest Carbon Fluxes Using Machine Learning Techniques Based on Eddy Covariance Measurements. Sustainability 2018, 10, 203. [Google Scholar] [CrossRef] [Green Version]
- Hochreiter, S.; Schmidhuber, J. Long short-term memory. Neural Comput. 1997, 9, 1735–1780. [Google Scholar] [CrossRef] [PubMed]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, Ł.; Polosukhin, I. Attention is all you need. In Advances in Neural Information Processing Systems; The MIT Press: Cambridge, MA, USA, 2017; pp. 5998–6008. [Google Scholar]
- Tukey, J.W. Comparing individual means in the analysis of variance. Biometrics 1949, 5, 99–114. [Google Scholar] [CrossRef] [PubMed]
- Wang, Q.; Li, B.; Xiao, T.; Zhu, J.; Li, C.; Wong, D.F.; Chao, L.S. Learning deep transformer models for machine translation. arXiv 2019, arXiv:1906.01787. [Google Scholar]
- Devlin, J.; Chang, M.W.; Lee, K.; Toutanova, K. Bert: Pre-training of deep bidirectional transformers for language understanding. arXiv 2018, arXiv:1810.04805. [Google Scholar]
- Burba, G. Eddy Covariance Method for Scientific, Industrial, Agricultural and Regulatory Applications: A Field Book on Measuring Ecosystem Gas Exchange and Areal Emission Rates; LI-Cor Biosciences: Lincoln, NE, USA, 2013. [Google Scholar]
- Nair, V.; Hinton, G.E. Rectified linear units improve restricted boltzmann machines. In Proceedings of the 27th International Conference on Machine Learning (ICML-10), Haifa, Israel, 21–24 June 2010; pp. 807–814. [Google Scholar]






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Name | Latitude (N) | Longitude (E) | Elevation (m) | Land Cover Type | AP (mm yr) | Temp (C) | GPP (gC mday) |
|---|---|---|---|---|---|---|---|
| NL-Loo | 52.16 | 5.74 | 25 | Evergreen Needleleaf Forest | 419 ± 829 | 10.1 ± 6.4 | 4.3 ± 3.1 |
| DE-Tha | 50.96 | 13.56 | 385 | Evergreen Needleleaf Forest | 420 ± 988 | 8.8 ± 7.9 | 5.1 ± 4.1 |
| AT-Neu | 47.11 | 11.31 | 970 | Grassland | 334 ± 814 | 6.8 ± 8.2 | 5.9 ± 5.9 |
| US-Var | 38.41 | −120.95 | 129 | Grassland | 282 ± 980 | 15.8 ± 6.8 | 1.8 ± 2.8 |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zhu, N.; Liu, C.; Laine, A.F.; Guo, J. Understanding and Modeling Climate Impacts on Photosynthetic Dynamics with FLUXNET Data and Neural Networks. Energies 2020, 13, 1322. https://doi.org/10.3390/en13061322
Zhu N, Liu C, Laine AF, Guo J. Understanding and Modeling Climate Impacts on Photosynthetic Dynamics with FLUXNET Data and Neural Networks. Energies. 2020; 13(6):1322. https://doi.org/10.3390/en13061322
Chicago/Turabian StyleZhu, Nanyan, Chen Liu, Andrew F. Laine, and Jia Guo. 2020. "Understanding and Modeling Climate Impacts on Photosynthetic Dynamics with FLUXNET Data and Neural Networks" Energies 13, no. 6: 1322. https://doi.org/10.3390/en13061322
APA StyleZhu, N., Liu, C., Laine, A. F., & Guo, J. (2020). Understanding and Modeling Climate Impacts on Photosynthetic Dynamics with FLUXNET Data and Neural Networks. Energies, 13(6), 1322. https://doi.org/10.3390/en13061322