
Dynamic Uncertain Causality Graph Applied to the Intelligent Evaluation of a Shale-Gas Sweet Spot


Abstract
:1. Introduction
2. Methods
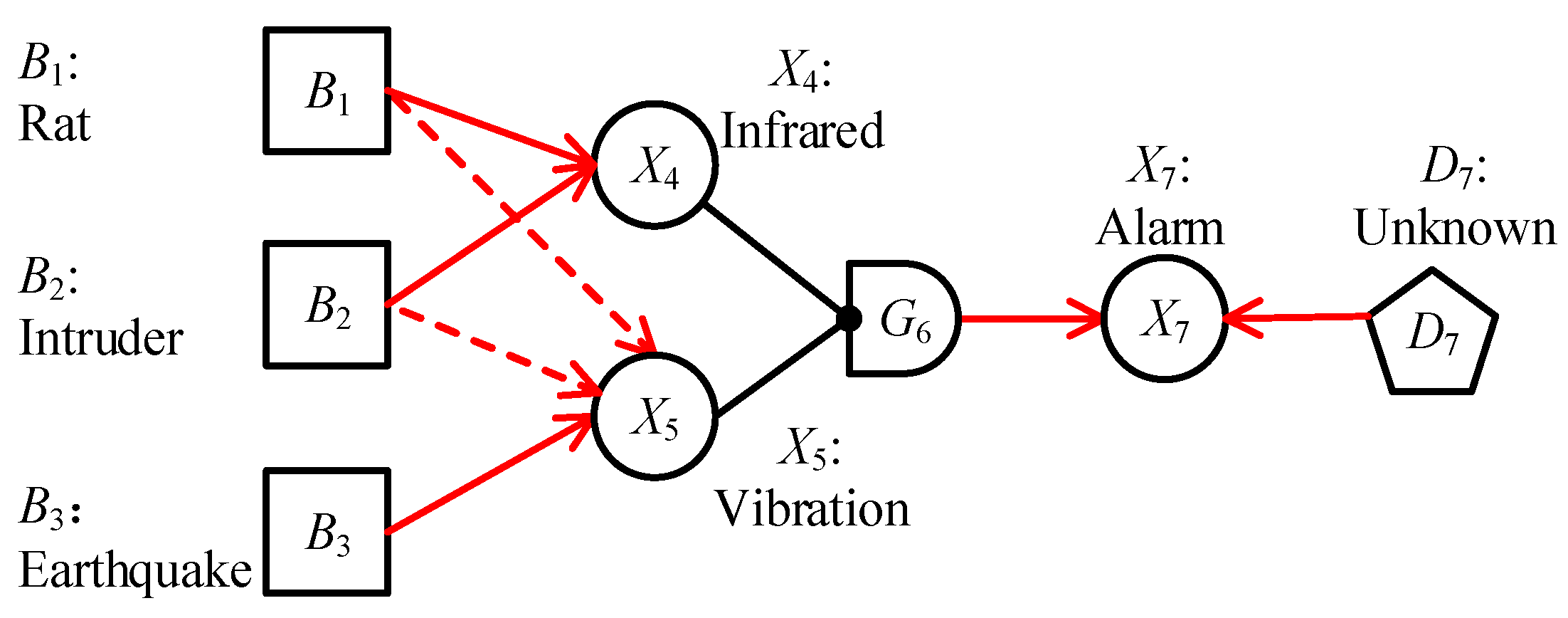
2.1. Causality Representation
2.2. Probabilistic Reasoning
- 1.
- Simplification
- 2.
- Decomposition
- 3.
- Event outspread
- 4.
- Probabilistic calculation
2.3. Extension of DUCG
2.3.1. Multiple Conditional Events
2.3.2. Weighted Graph
3. Evaluation Model Construction
- 1.
- Variable definition
- 2.
- Knowledge representation
- 3.
- Probability reasoning
- 4.
- Comprehensive comparison
3.1. Screening Critical Factors for Shale-Gas Exploration and Development
3.2. Establishment of the Evaluation Model for Shale-Gas Sweet Spots
3.2.1. Define Variables
3.2.2. Determine Causality
3.2.3. Determine Causality Function Parameters
4. Results and Discussion
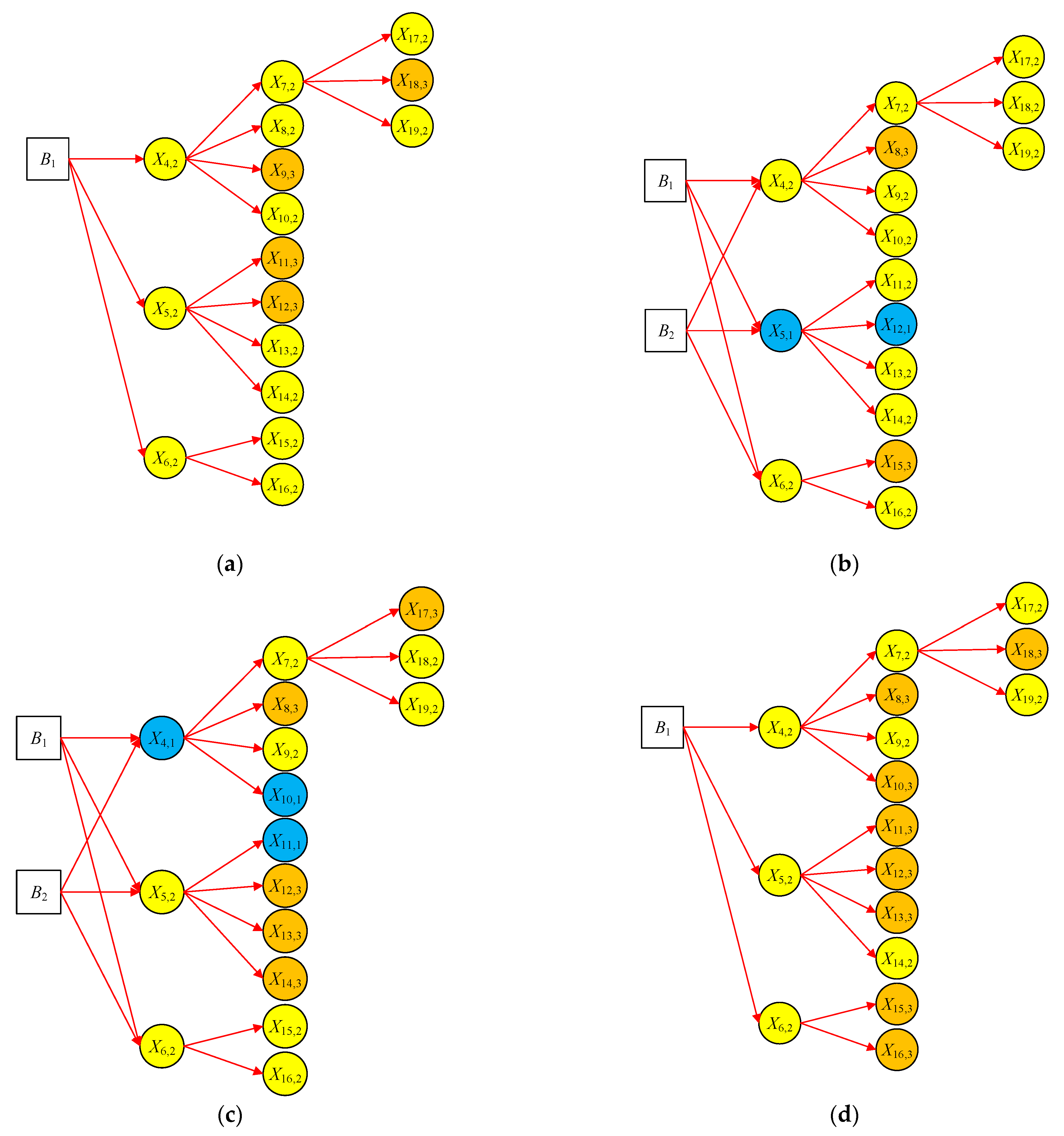
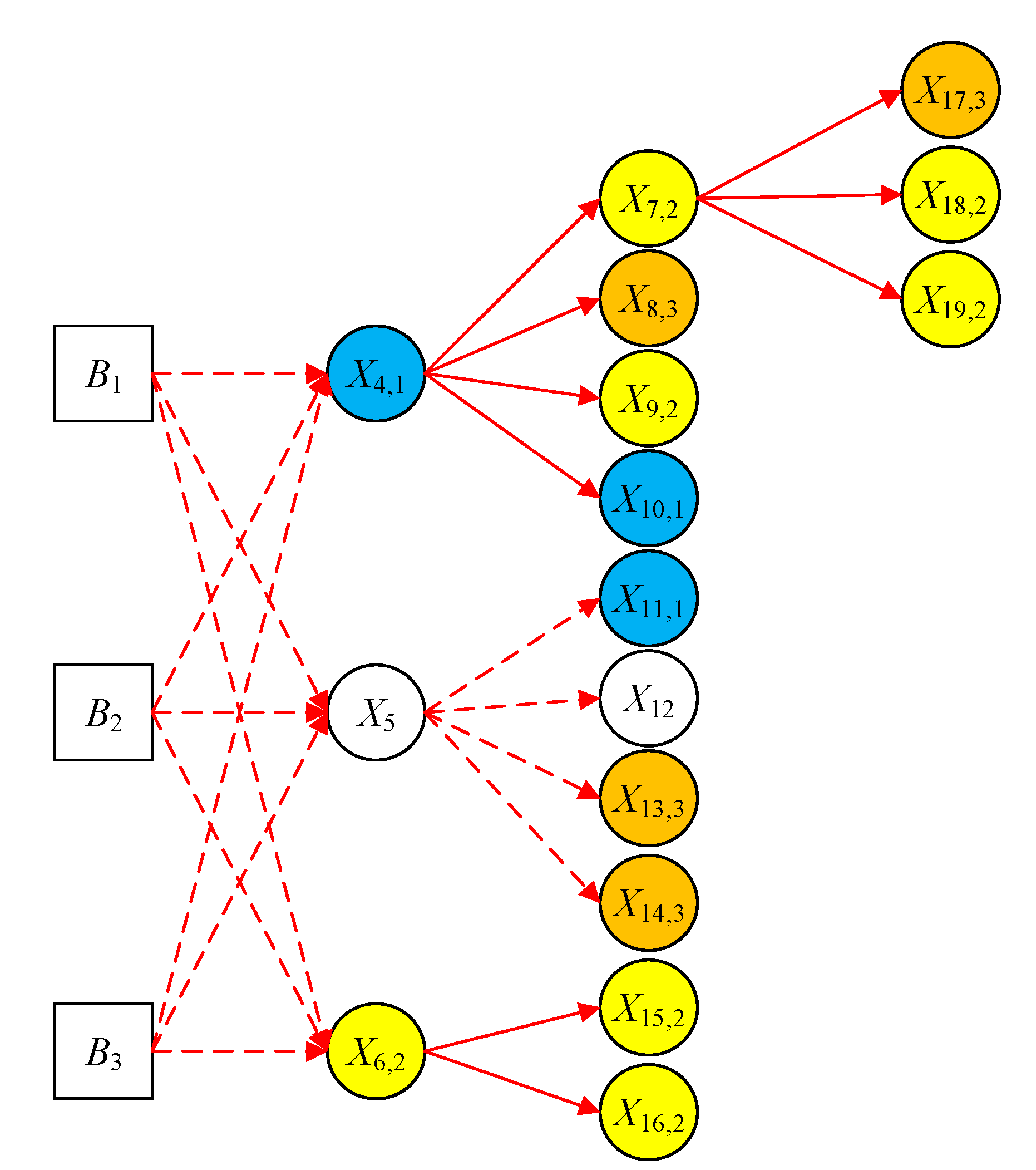
4.1. Results from Complete Data
4.2. Results from Incomplete Data
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Song, Z.; Xu, X.; Wang, B.; Zhao, L.; Yang, G.; Qiu, Q. Advances in shale gas resource assessment methods and their future evolvement. Oil Gas Geol. 2020, 41, 1038–1047. [Google Scholar]
- Zhiliang, H.E.; Haikuan, L.I.E.; Tingxue, J.I.A.N.G. Challenges and countermeasures of effective development with large scale of deep shale gas in Sichuan Basin. Reserv. Eval. Dev. 2021, 11, 1–11. [Google Scholar]
- He, X. Sweet spot evaluation system and enrichment and high yield influential factors of shale gas in Nanchuan area of eastern Sichuan Basin. Nat. Gas Ind. 2021, 41, 59–71. [Google Scholar]
- Wang, S.; Shi, C.; Wang, J. New equations for characterizing water flooding in ultra-high water-cut oilfields. Oil Gas Geol. 2020, 41, 1282–1287. [Google Scholar]
- Zhang, X.; Zhang, M.; Yang, L.; Yang, L.; Zhang, Y.; Zhou, Y. Improved Calculation Method for Shale Gas Reserves. Contemp. Chem. Ind. 2021, 50, 1450–1454. [Google Scholar]
- Jiang, J.; Tomin, P.; Zhou, Y. Inexact methods for sequential fully implicit (SFI) reservoir simulation. Comput. Geosci. 2021, 1–22. [Google Scholar] [CrossRef]
- Zhou, Y.; Zhao, A.; Yu, Q.; Zhang, D.; Zhang, Q.; Lei, Z. A new method for evaluating favorable shale gas exploration areas based on multi-linear regression analysis: A case study of marine shales of Wufeng-Longmaxi Formations, Upper Yangtze Region. Sediment. Geol. Tethyan Geol. 2021, 1–13. [Google Scholar] [CrossRef]
- Chen, G.; Sun, A.; Tang, H.; Tang, C. Water cut predication of water flood oilfield by the application of combined model. Reserv. Eval. Dev. 2016, 6, 11–13+18. [Google Scholar]
- Li, J.; Liu, X.; Shang, B.; Wang, D.; Gao, Z. Study on quantitative reservoir characterization based on geological risk. Xinjiang Oil Gas 2021, 17, 3–4, 50–52, 77. [Google Scholar]
- Zhong, Y.; Wang, S.; Luo, L.; Yang, J.; Qiu, Y. Knowledge Mining for Oilfield Development Index Prediction Model Using deep learning. J. Southwest Pet. Univ. 2020, 42, 63–74. [Google Scholar]
- Otchere, D.; Ganat, A.; Gholami, R.; Ridha, S. Application of supervised machine learning paradigms in the prediction of petrole-um reservoir properties: Comparative analysis of ANN and SVM models. J. Pet. Sci. Eng. 2021, 200, 108182. [Google Scholar] [CrossRef]
- Wang, S.; Li, J.; Guo, Q.; Li, D. Application of AHP Method to Favorable Area Optimization for Tight Oil: A Case Study in Daanzhai Formation, Jurassic, Central of the Sichuan Basin. Adv. Earth Sci. 2015, 30, 715–723. [Google Scholar]
- Shang, Y. Application of the analytic hierarchy process in the low-grade reserves evaluation. Pet. Geol. Oilfield Dev. Daqing 2014, 33, 55–59. [Google Scholar]
- Guan, Q.; Dong, D.; Wang, Y.; Huang, J.; Wang, S. AHP Application to Shale Gas Exploration Areas Assessment in Sichuan Basin. Bull. Geol. Sci. Technol. 2015, 34, 91–97. [Google Scholar]
- Zhang, Q.; Dong, C.; Cui, Y.; Yang, Z. Dynamic Uncertain Causality Graph for Knowledge Representation and Probabilistic Reasoning: Statistics Base, Matrix, and Application. IEEE Trans. Neural Netw. Learn. Syst. 2014, 25, 645. [Google Scholar] [CrossRef] [PubMed]
- Zhou, Z.; Qin, Z. Model Event/Fault Trees with Dynamic Uncertain Causality Graph for Better Probabilistic Safety Assessment. IEEE Trans. Reliab. 2017, 66, 178–188. [Google Scholar] [CrossRef]
- Dong, C.; Zhou, Z.; Zhang, Q. Cubic Dynamic Uncertain Causality Graph: A New Methodology for Modeling and Reasoning about Complex Faults with Negative Feedbacks. IEEE Trans. Reliab. 2018, 67, 920–932. [Google Scholar] [CrossRef]
- Jiao, Y.; Zhang, Z.; Zhang, T.; Shi, W.; Hu, J.; Zhang, Q. Development of an artificial intelligence diagnostic model based on dynamic uncertain causality graph for the differential diagnosis of dyspnea. Front. Med. 2020, 14, 488–497. [Google Scholar] [CrossRef]
- Ning, D.; Zhang, Z.; Qiu, K.; Lu, L.; Zhang, Q.; Zhu, Y.; Wang, R. Efficacy of intelligent diagnosis with a dynamic uncertain causality graph model for rare disorders of sex development. Front. Med. 2020, 14, 498–505. [Google Scholar] [CrossRef]
- Dong, C.; Wang, Y.; Zhou, J.; Zhang, Q.; Wang, N.; Faes, L. Differential Diagnostic Reasoning Method for Benign Paroxysmal Positional Vertigo Based on Dynamic Uncertain Causality Graph. Comput. Math. Methods Med. 2020, 2020, 1541989. [Google Scholar] [CrossRef]
- Zhang, Q.; Bu, X.; Zhang, M.; Zhang, Z.; Hu, J. Dynamic uncertain causality graph for computer-aided general clinical diagnoses with nasal obstruction as an illustration. Artif. Intell. Rev. 2021, 54, 27–61. [Google Scholar] [CrossRef]
- Zhang, Q. Dynamic Uncertain Causal Graph for knowledge repressntation and reasoning: Discrete DAG cases. J. Comput. Sci. Technol. 2012, 27, 1–23. [Google Scholar] [CrossRef]
- Zhang, Q.; Geng, S. Dynamic uncertain causality graph applied to dynamic fault diagnoses of large and complex systems. IEEE Trans. Reliab. 2015, 64, 910–927. [Google Scholar] [CrossRef]
- Wang, M.; Li, J.; Ye, J. Shale Gas Knowledge Book; Science Press: Beijing, China, 2012; pp. 30–32. [Google Scholar]
- Li, D. China’s Multicycle Superimposed Petroliferous Basins: Theory and Explorative Practices. Xinjiang Pet. Geol. 2013, 34, 497–503. [Google Scholar]
- Bao, H.; Liu, X.; Zhou, Y.; Yang, Y.; Guo, X. Favorable Area and Potential Analyses of Tight Oil in Jimsar Sag. Spec. Oil Gas Reserv. 2016, 23, 38–42, 152. [Google Scholar]
- Yang, Z.; Hou, L.; Tao, S.; Cui, J.; Wu, S.; Lin, S.; Pan, S. Formation conditions and “sweet spot” evaluation of tight oil and shale oil. Pet. Explor. Dev. 2015, 42, 555–565. [Google Scholar]













{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Relevant Industry Standard | Standard Number | State |
|---|---|---|
| Method of geological evaluation of natural-gas reserves | SY/T 5601-2009 | Current |
| Technical requirements for economic evaluation of gas field development and adjustment programs | SY/T 6177-2009 | Current |
| Evaluation method of oil and gas reservoirs | SY/T 6285-2011 | Current |
| Sweet Spot | Evaluation Indicator | Target Area | Favorable Area | Prospecting Area |
|---|---|---|---|---|
| Geological sweet spot | Thickness of organic-rich shale/m | >50 | 50–30 | <30 |
| Total organic carbon (TOC)/% | >4 | 4–2 | <2 | |
| Maturity of organic matter (Ro)/% | 1.1–2.5 | 2.5–4 | >4 | |
| Favorable area/km2 | >2500 | 2500–1000 | <1000 | |
| Gas content/(m3·t−1) | >4 | 4–2 | <2 | |
| Tectonic setting | Anticline normal structure | Slope | Syncline negative structure | |
| Engineering sweet spot | Burial depth/km | 1.5–3.5 | 0.5–1.5 | <0.5 or 3.5–4.5 |
| Pressure factor | >1.3 | 1.0–1.3 | <1.0 | |
| Degree of natural cracks | Full development | Interlayer seam development | No development | |
| Surface condition | Plains and hills | Mountains or dams | Lakes or valleys | |
| Economic sweet spot | Market demand | Demand exceeds supply | Balance between supply and demand | Supply exceeds demand |
| Infrastructure | In a pipe network | Close to a pipe network | Away from a pipe network |
| Name | Description | State and State Description |
|---|---|---|
| B1 | Shale-gas target area | 0: false; 1: true |
| B2 | Shale-gas favorable area | 0: false; 1: true |
| B3 | Shale-gas prospective area | 0: false; 1: true |
| X4 | Geological sweet spot | 0: false; 1: common; 2: good |
| X5 | Engineering sweet spot | 0: false; 1: common; 2: good |
| X6 | Economic sweet spot | 0: false; 1: common; 2: good |
| X7 | Organic matter | 0: unknown; 1: common; 2: good |
| X8 | Favorable area (km2) | 0: unknown; 1: <1000; 2: >1000 and <2500; 3: >2500 |
| X9 | Gas content (m3·t−1) | 0: unknown; 1: <2; 2: 2–4; 3: >4 |
| X10 | Tectonic setting | 0: unknown; 1: syncline negative structure; 2: slope; 3: anticline normal structure |
| X11 | Burial depth (km) | 0: unknown; 1: <0.5 or 3.5–4.5; 2: 0.5–1.5; 3: 1.5–3.5 |
| X12 | Pressure factor | 0: unknown; 1: <1.0; 2: 1.0–1.3; 3: >1.3 |
| X13 | Degree of natural cracks | 0: unknown; 1: undeveloped; 2: interlayer seam development; 3: fully developed |
| X14 | Surface condition | 0: unknown; 1: lakes or valleys; 2: mountains or dams; 3: plains and hills |
| X15 | Market demand | 0: unknown; 1: supply exceeds demand; 2: balanced; 3: demand exceeds supply |
| X16 | Infrastructure | 0: unknown; 1: away from a pipe network; 2: close to a pipe network; 3: in a pipe network |
| X17 | Thickness of organic-rich shale (m) | 0: unknown; 1: <30; 2: 30–50; 3: >50 |
| X18 | Total organic carbon (%) | 0: unknown; 1: <2; 2: 2–4; 3: >4 |
| X19 | Organic maturity (%) | 0: unknown; 1: >4; 2: 2–4; 3: 1.1–2.5 |
| No. | Parent Variable | List or Description of Condition Events |
|---|---|---|
| 1 | B1,1 | Z4,2;1,1 = X5,2X6,2 + X5,1X6,2 + X5,2X6,1 Z4,1;1,1 = X5,2X6,2 Z5,2;1,1 = X4,2X6,2 + X4,2X6,1 + X4,1X6,2 Z5,1;1,1 = X4,2X6,2 Z6,2;1,1 = X4,2X5,2 + X4,2X5,1 + X4,1X5,2 Z6,1;1,1 = X4,2X5,2 |
| 2 | B2,1 | Z4,2;2,1 = X5,1X6,2 + X5,2X6,1 + X5,1X6,1 Z4,1;2,1 = X5,2X6,2 + X5,2X6,1 + X5,1X6,2 Z5,2;2,1 = X4,2X6,1 + X4,1X6,2 + X4,1X6,1 Z5,1;2,1 = X4,2X6,2 + X4,2X6,1 + X4,1X6,2 Z6,2;2,1 = X4,2X5,1 + X4,1X5,2 + X4,1X5,1 Z6,1;2,1 = X4,2X5,2 + X4,2X5,1 + X4,1X5,2 |
| 3 | B3,1 | Z4,1;3,1 = X5,1X6,1 + X5,2X6,1 + X5,1X6,2 Z4,2;3,1 = X5,1X6,1 Z5,1;3,1 = X4,1X6,1 + X4,1X6,2 + X4,2X6,1 Z5,2;3,1 = X4,1X6,1 Z6,1;3,1 = X4,1X5,1 + X4,1X5,2 + X4,2X5,1 Z6,2;3,1 = X4,1X5,1 |
| 4 | X4,2 | All child variables of X4 are in state 2 or 3. |
| 5 | X4,1 | |
| 6 | X5,2 | All child variables of X5 are in state 2 or 3, or X11 is state 1, and two of the other three variables are in state 3. |
| 7 | X5,1 | |
| 8 | X6,2 | All child variables of X6 are in state 2 or 3. |
| 9 | X6,1 | |
| 10 | X7,2 | All child variables of X7 are in state 2 or 3. |
| 11 | X7,1 |
| Evaluation Indicator | Changning (E1) | Weiyuan (E2) | Fushun-Yongchuan (E3) | Jiaoshiba (E4) |
|---|---|---|---|---|
| Thickness of organic-rich shale (X17) | 33–46 | 40–50 | 60–100 | 38–44 |
| Total organic carbon (X18) | 1.9–7.3/4.0 | 1.9–6.4/2.7 | 1.6–6.8/3.8 | 1.5–6.1/3.5 |
| Organic maturity (X19) | 2.6 | 2.7 | 2.5–3.0 | 2.6 |
| Favorable area (X8) | 2050 | 4216 | 3900 | 5450 |
| Gas content (X9) | 4.1 | 2.92 | 3.6 | 3.5 |
| Tectonic setting (X10) | Slope | Slope | Syncline negative structure | Anticline normal structure |
| Burial depth (X11) | 2.3–3.2 | 1.3–3.7 | 3.2–4.5 | 2.4–3.5 |
| Pressure factor (X12) | 1.35–2.03 | 0.92–1.77 | 2.0–2.25 | 1.35–1.55 |
| Degree of natural cracks (X13) | Interlayer seam development | Interlayer seam development | Full development | Full development |
| Surface condition (X14) | Mountains or dams | Mountains or dams | Plains or hills | Mountains or dams |
| Market demand (X15) | Medium | Larger | Medium | Larger |
| Infrastructure (X16) | Close to a pipe network | Close to a pipe network | Close to a pipe network | In a pipe network |
| Area | Target Area (Level I) | Favorable Area (Level II) | Prospective Area (Level III) |
|---|---|---|---|
| Jiaoshiba | 100% | ||
| Changning | 100% | ||
| Fushun-Yongchuan | 51.51% | 48.49% | |
| Weiyuan | 41.49% | 58.51% |
| Area | Score | Rank | Level |
|---|---|---|---|
| Jiaoshiba | 72.7670 | 1 | I |
| Changning | 72.2571 | 2 | I |
| Fushun-Yongchuan | 71.3968 | 3 | II |
| Weiyuan | 67.9926 | 4 | III |
| Evaluation Indicator | Variable | Data |
|---|---|---|
| Thickness of organic-rich shale | X17 | 60–100 |
| Total organic carbon | X18 | 1.6–6.8/3.8 |
| Organic maturity | X19 | 2.5–3.0 |
| Favorable area | X8 | 3900 |
| Gas content | X9 | 3.6 |
| Tectonic setting | X10 | Syncline negative structure |
| Burial depth | X11 | 3.2–4.5 |
| Pressure factor | X12 | — |
| Degree of natural cracks | X13 | Fully developed |
| Surface condition | X14 | Plains and hills |
| Market demand | X15 | Balance between supply and demand |
| Infrastructure | X16 | Close to a pipe network |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Yao, Q.; Yang, B.; Zhang, Q. Dynamic Uncertain Causality Graph Applied to the Intelligent Evaluation of a Shale-Gas Sweet Spot. Energies 2021, 14, 5228. https://doi.org/10.3390/en14175228
Yao Q, Yang B, Zhang Q. Dynamic Uncertain Causality Graph Applied to the Intelligent Evaluation of a Shale-Gas Sweet Spot. Energies. 2021; 14(17):5228. https://doi.org/10.3390/en14175228
Chicago/Turabian StyleYao, Quanying, Bo Yang, and Qin Zhang. 2021. "Dynamic Uncertain Causality Graph Applied to the Intelligent Evaluation of a Shale-Gas Sweet Spot" Energies 14, no. 17: 5228. https://doi.org/10.3390/en14175228
APA StyleYao, Q., Yang, B., & Zhang, Q. (2021). Dynamic Uncertain Causality Graph Applied to the Intelligent Evaluation of a Shale-Gas Sweet Spot. Energies, 14(17), 5228. https://doi.org/10.3390/en14175228