
Massive Generation of Customer Load Profiles for Large Scale State Estimation Deployment: An Approach to Exploit AMI Limited Data



Abstract
:1. Introduction
- Analysis of existing DSO informative system, including AMI and DMS
- Definition of a procedure based on limited AMI data for power profile generators
- Formalization of the procedure for the synthesis of customer power profiles
- Validation of the approach on large-scale distribution network (one million customers) and real data from existing AMI system
2. Clustering and Profile Creation at a Glance
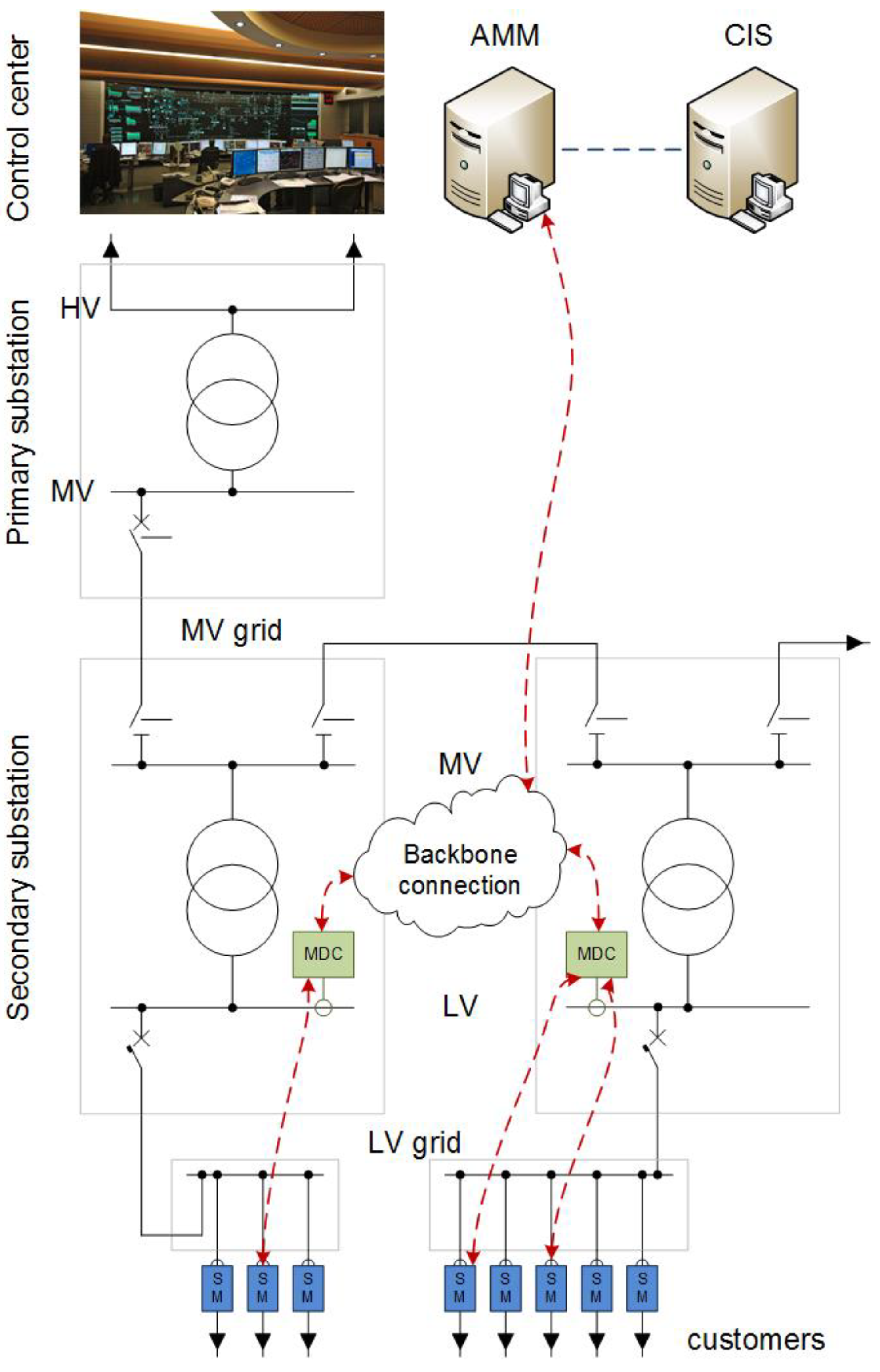
2.1. Review of the 1st Generation AMI in Italy
- Activation/deactivation of contracts
- Contractual power changes
- Power curtailment
- Anti-tampering
- Monthly reading of energy counters for billing
- Electronic meters per each customer
- A Meter Data Concentrator (MDC) collecting customers’ data and installed in secondary substations
- An Automatic Metering Management (AMM) system, collecting data from MDCs
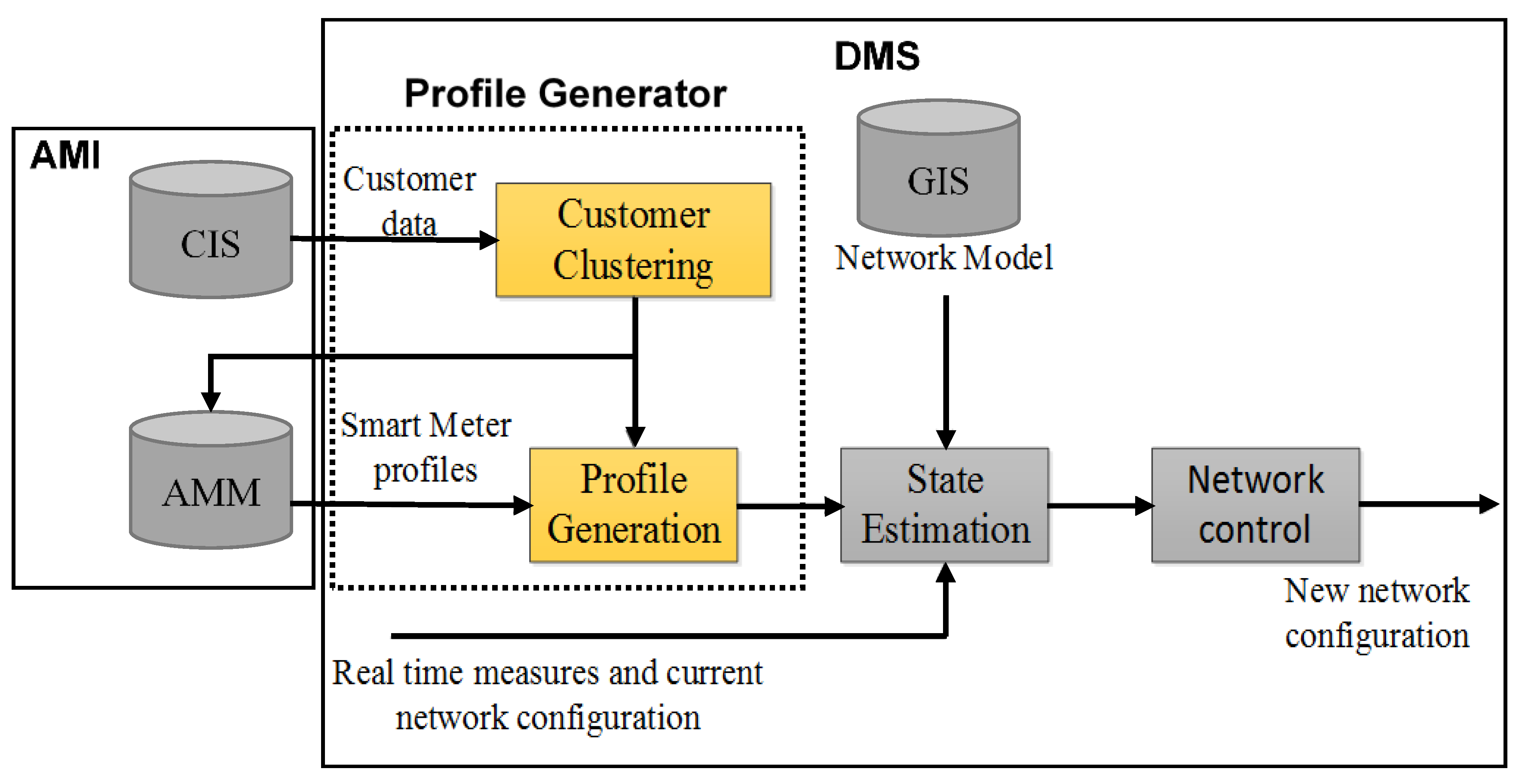
2.2. Profiles Generator
3. The Proposed Approach
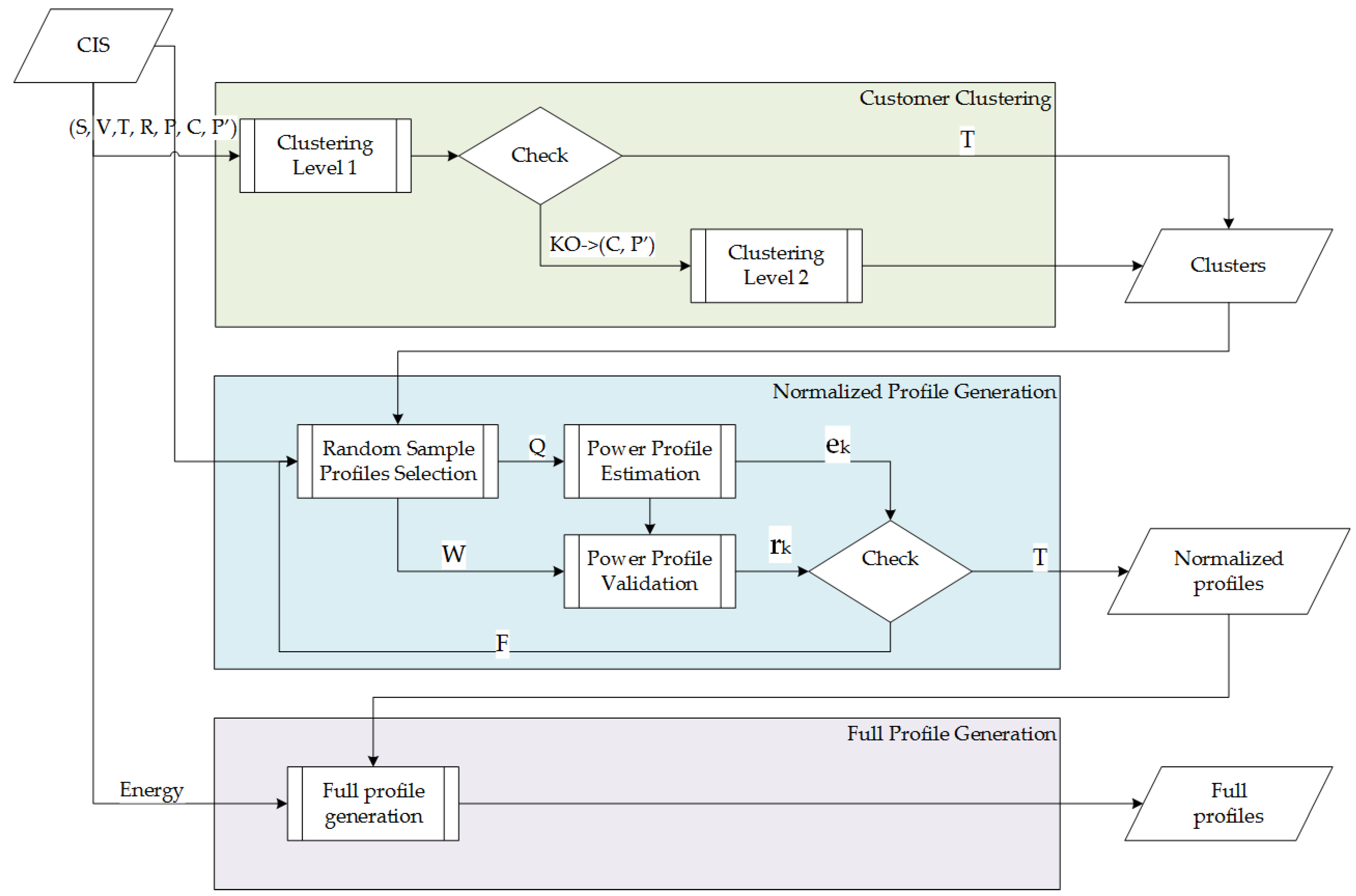
3.1. Customer Clustering
- Customer’s contract status, S = {Connected, Disconnected}
- Voltage level, V = {LV, MV, HV}
- Customer’s Contract Type, T = {Residential, Not Residential}
- Customer’s Type, R = {Consumer, Producer, Prosumer}
- Contract Power, P = {(0.0, 6.6], (6.6, 16.5], (16.5, 55.0], (55.0, ∞)} kW
- These parameters are normally stored in CIS systems, therefore clustering based on them is a straightforward and efficient procedure for real-life applications. Besides the above parameters, for each customer, the total energy consumption in a given month is other information which is available in the CIS. Based on that, the total annual consumption per each customer can also be easily obtained.
- More formally, let us consider a set of N customers; each customer Xi can be described as a couple:
- where
- -
- Hi = (Si, Vi, Ti, Ri, Pi) is the vector of the contract features of the customer; and
- -
- , is the time series of mean active power values every 15 min, on the considered time horizon T.
3.2. Normalized Profile Generation
3.3. Full Profiles Generation
4. Results
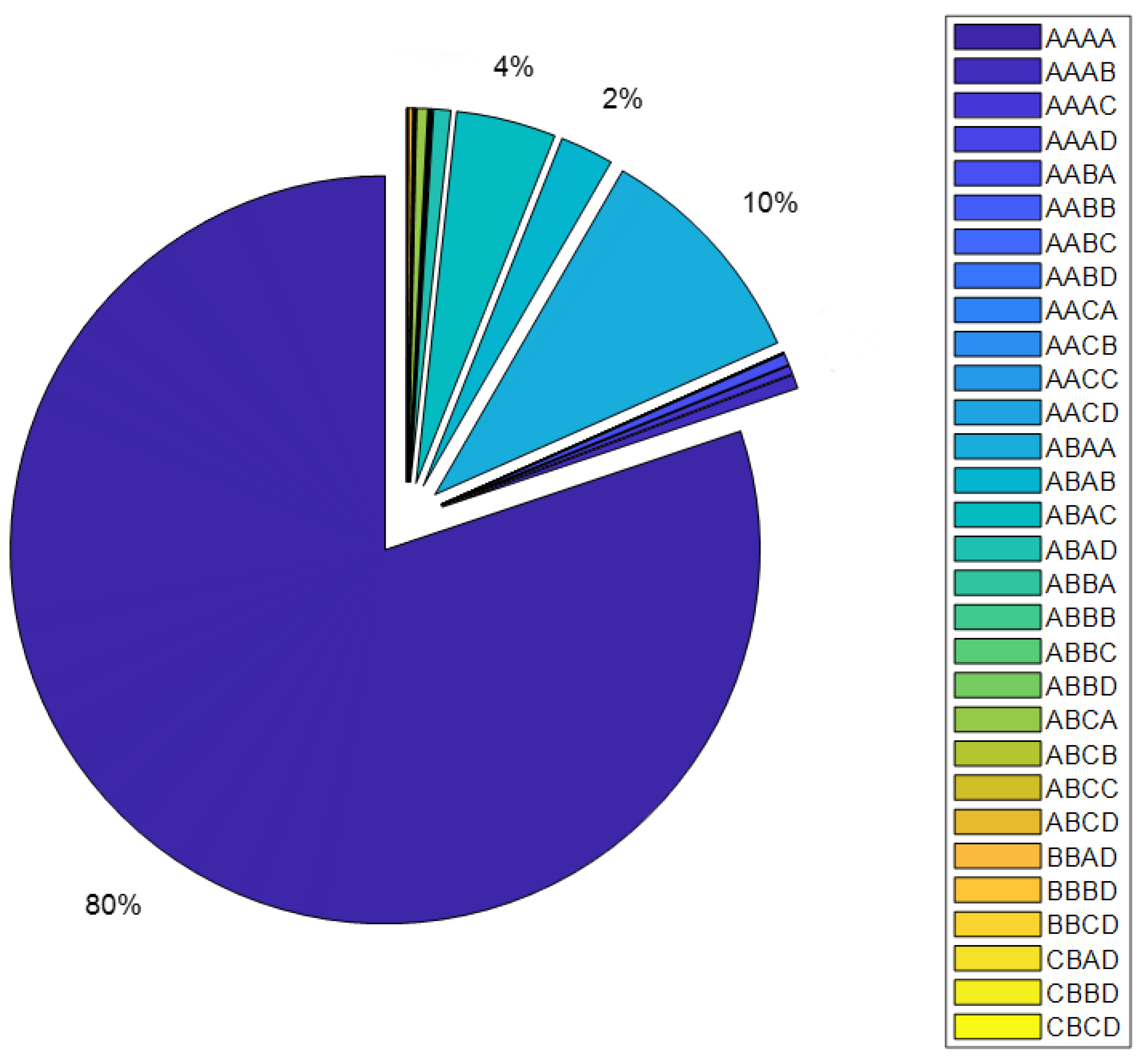
4.1. Customer Clustering
4.1.1. First Level of Clustering
4.1.2. Second Level of Clustering
- City Class based on the density i.e., Number of customers per city C = {
- ○
- (500,000, 1,500,000] (the City of Milano),
- ○
- (10,000, 500,000] (the City of Brescia),
- ○
- (20,000, 100,000] (medium size cities),
- ○
- (5000, 20,000] (small towns near a bigger city),
- ○
- (0, 5000] (villages in rural areas)}
- A more granular set of contract powers: P’ = {
- ○
- (0.0, 3.3];
- ○
- (3.3, 4.4];
- ○
- (4.4, 5.5];
- ○
- (5.5, 6.6]} kW
4.2. Normalized Profile Generation
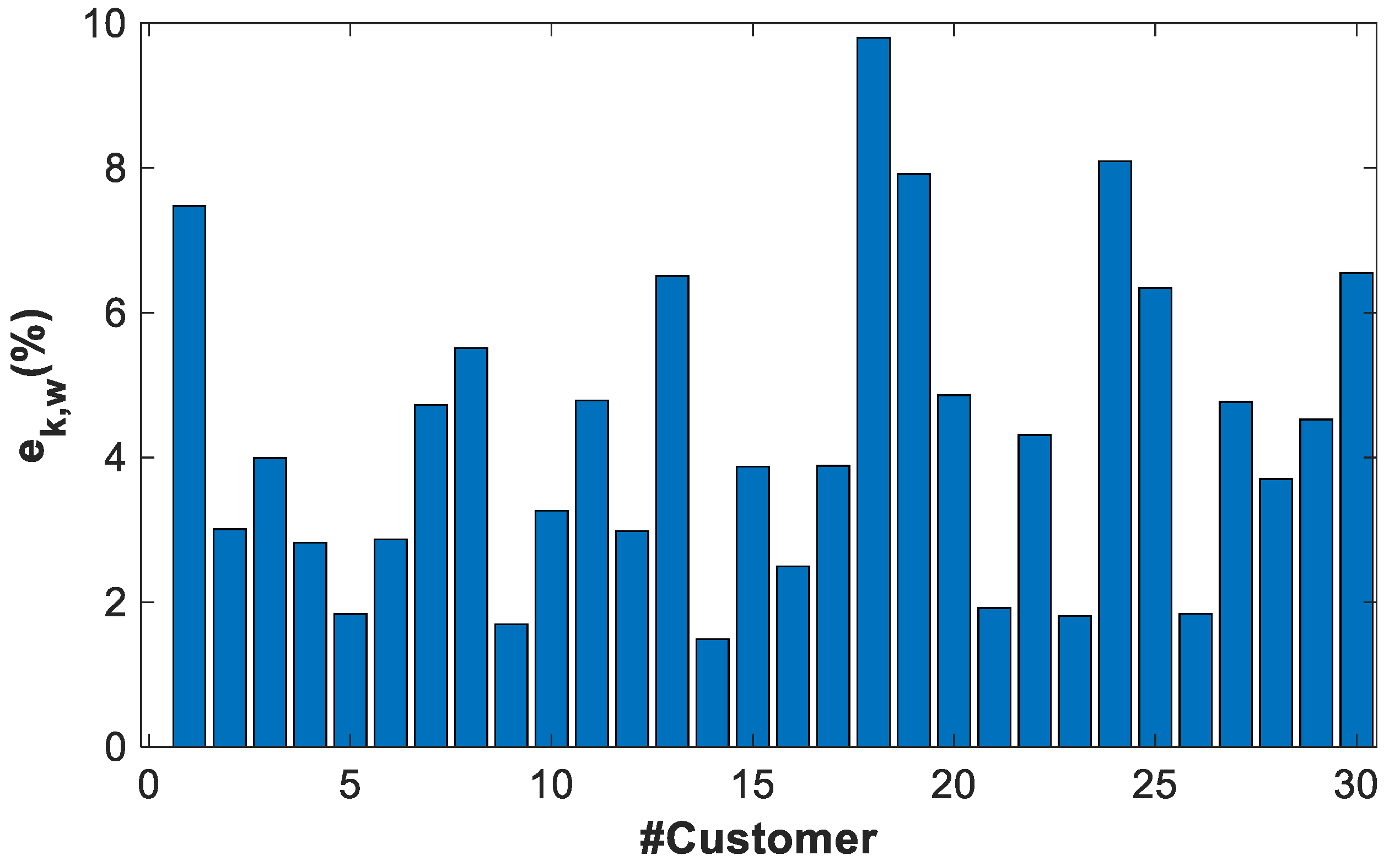
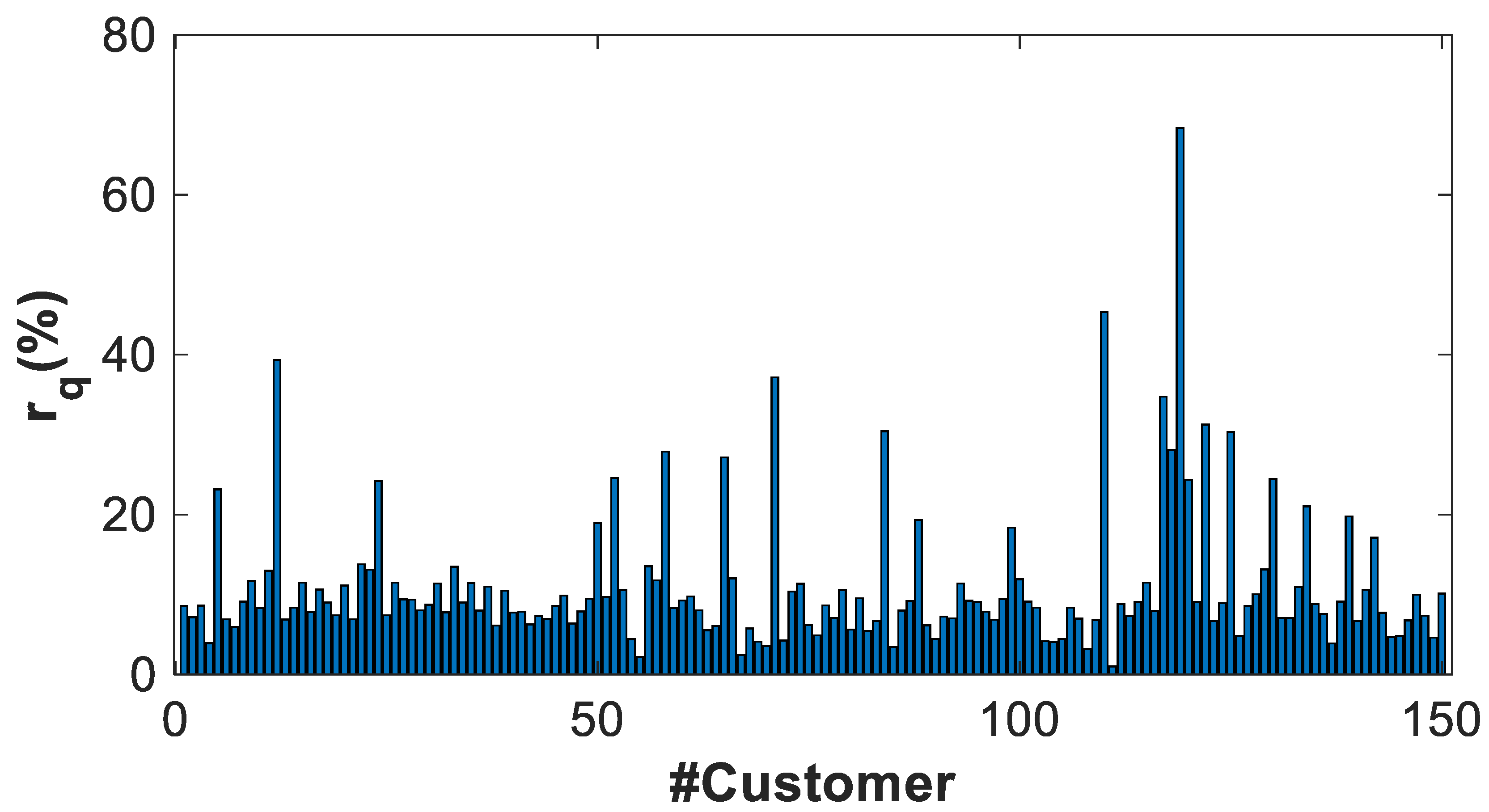
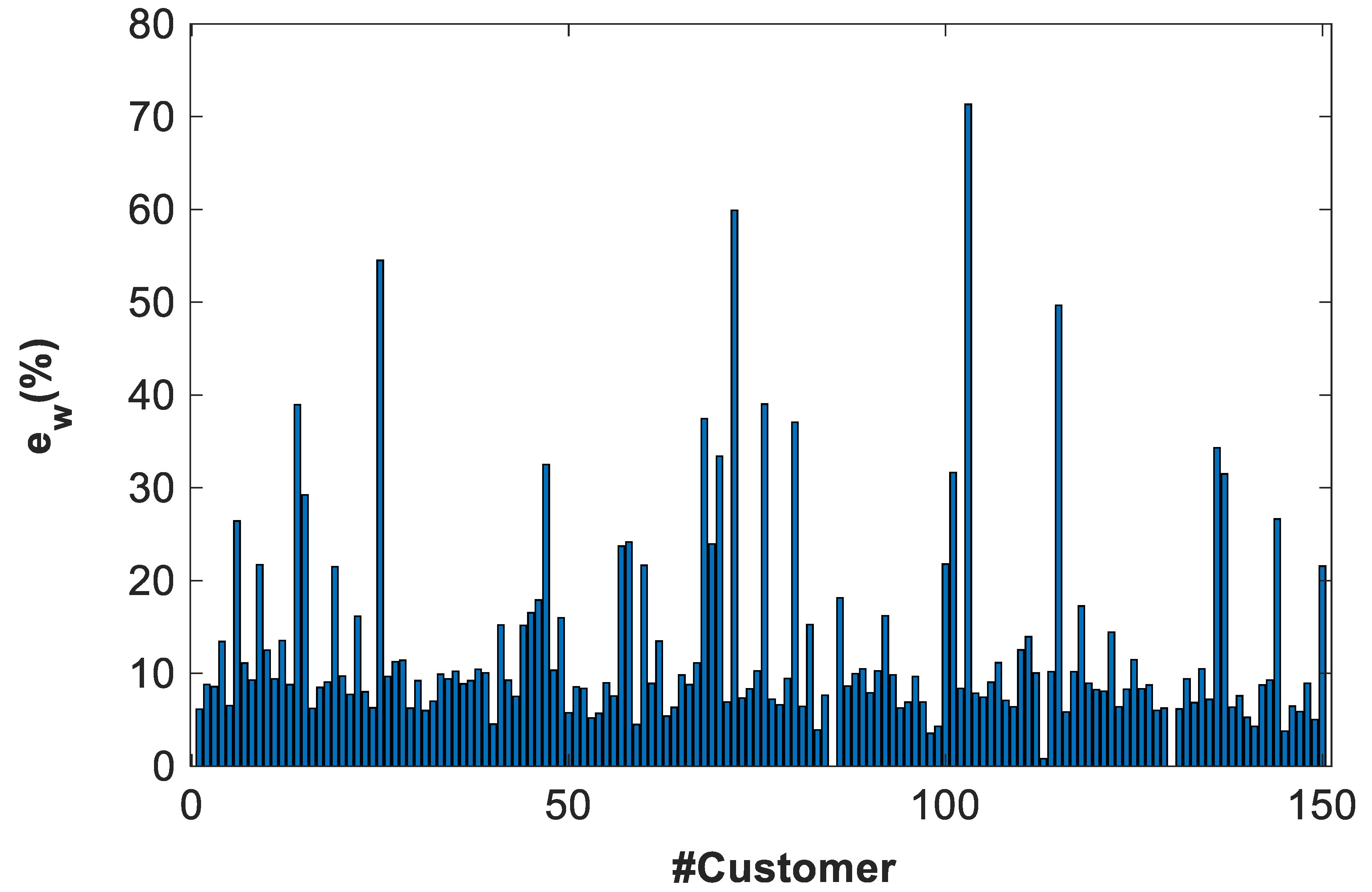
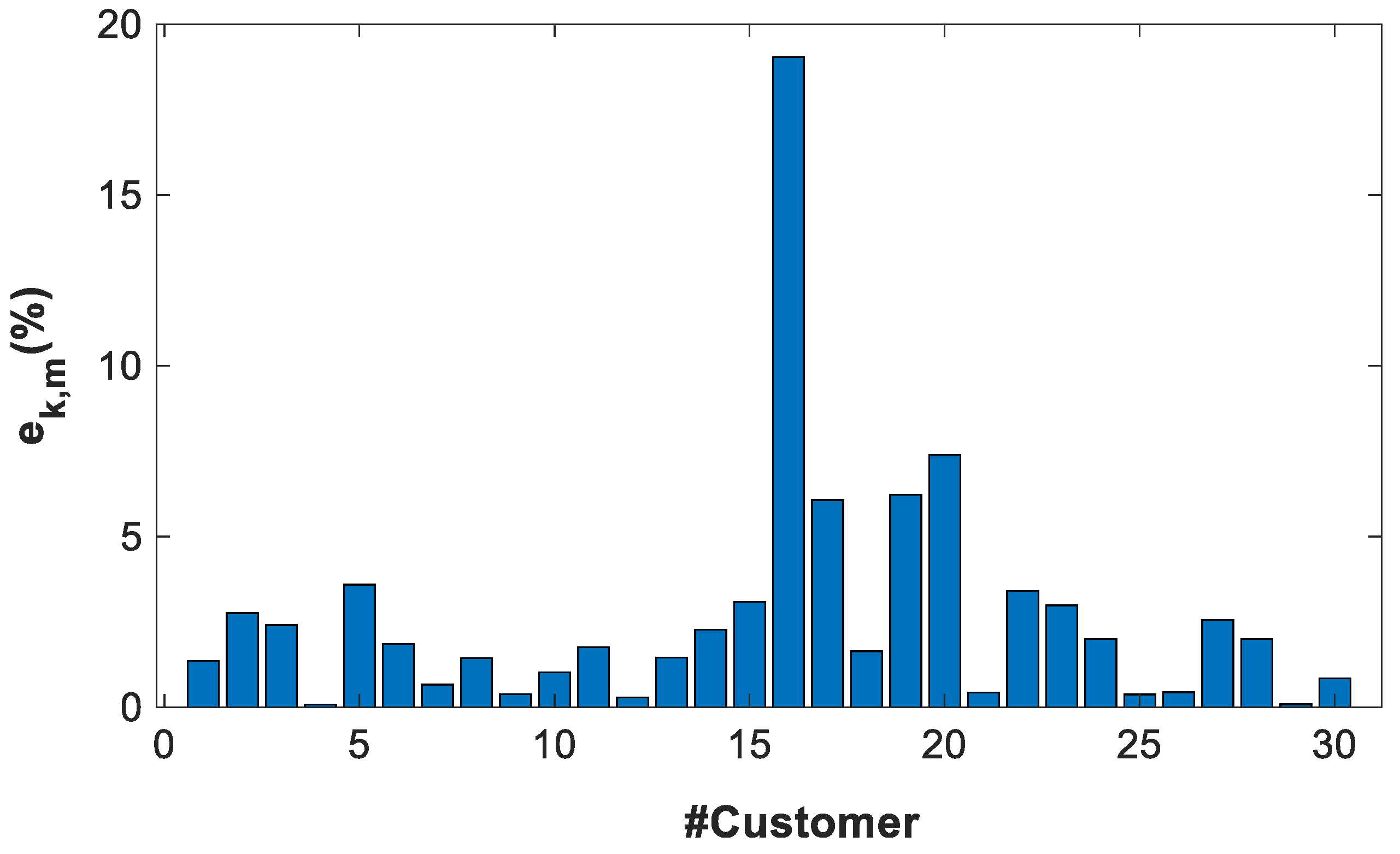
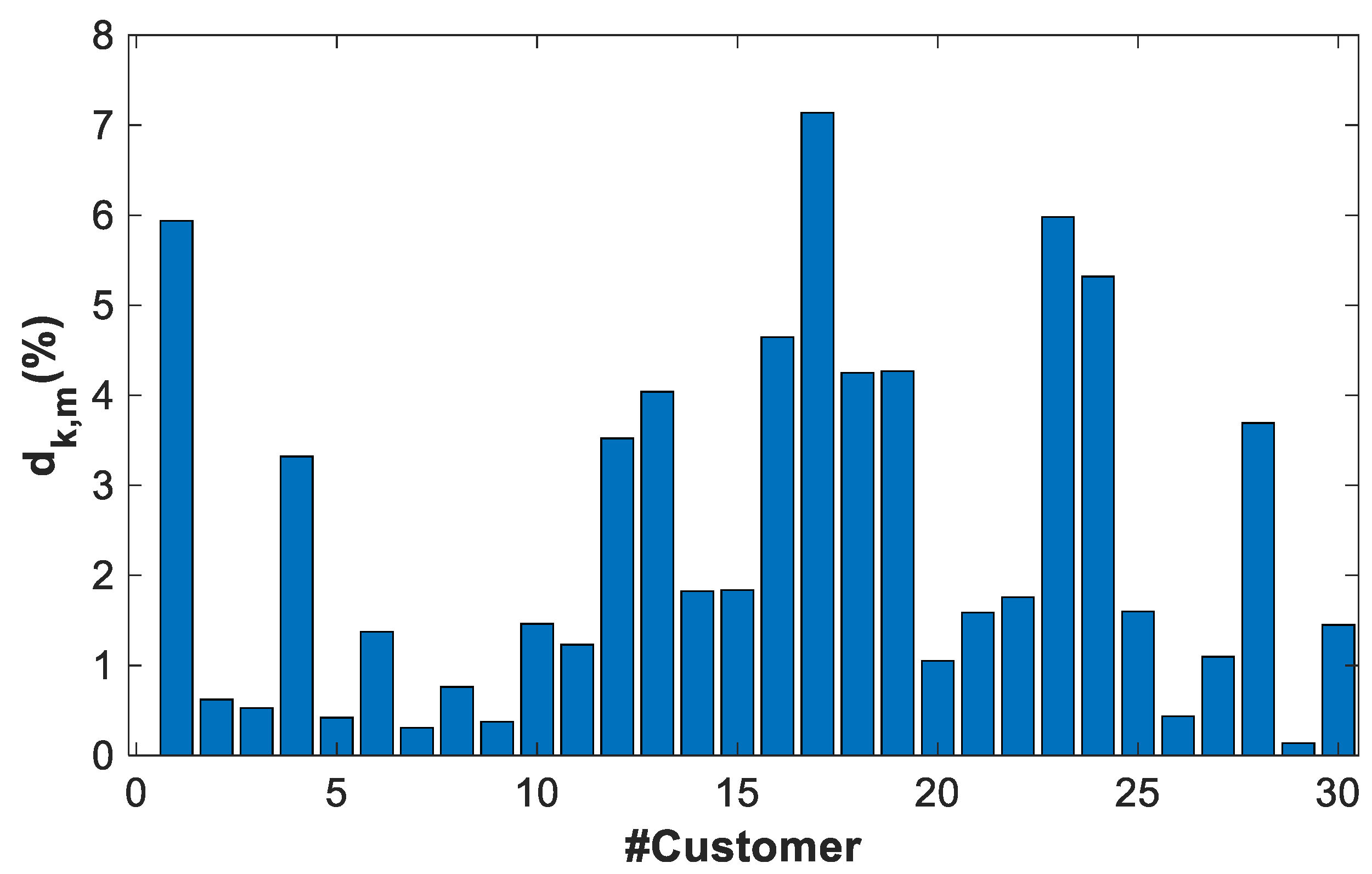
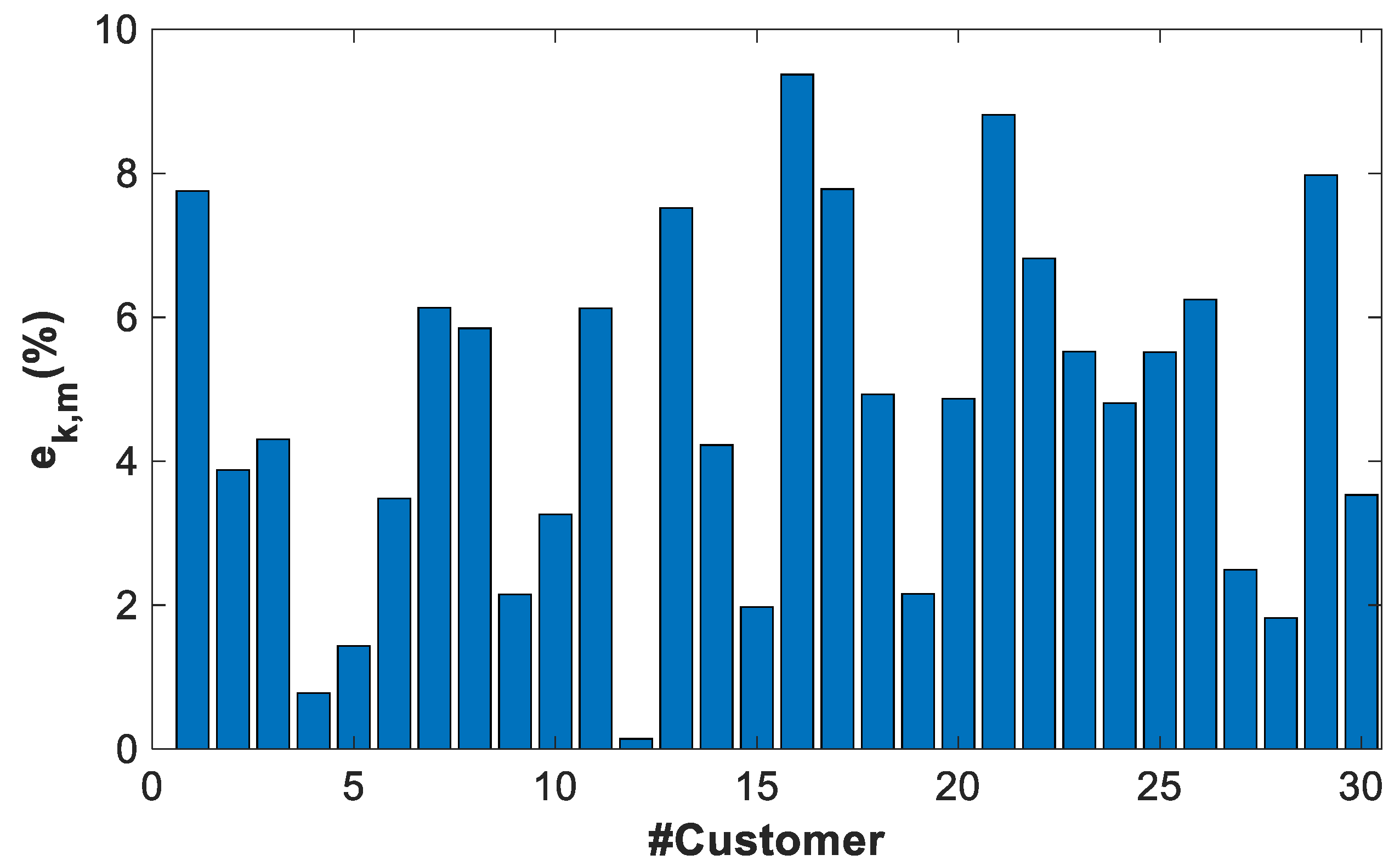
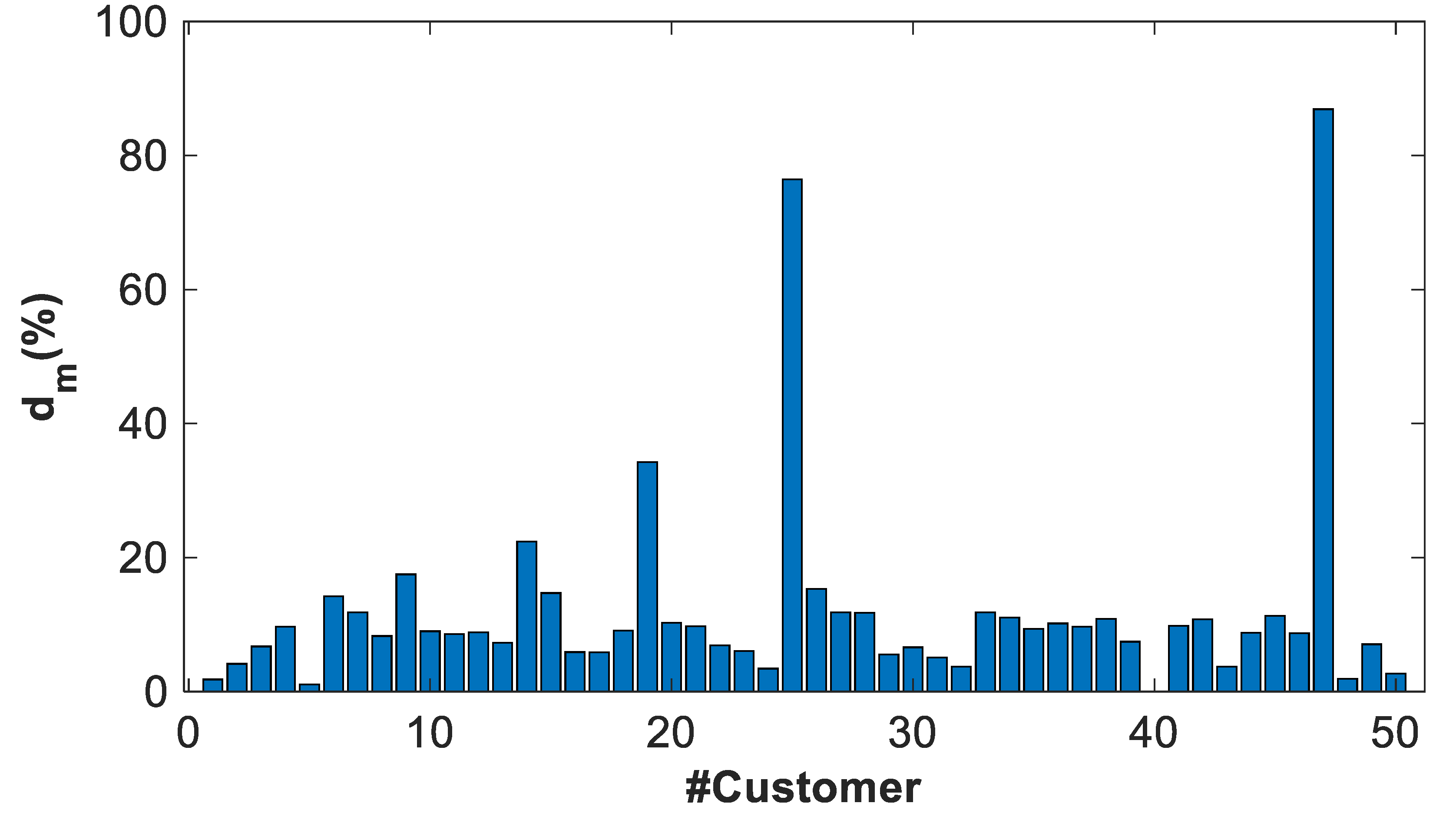
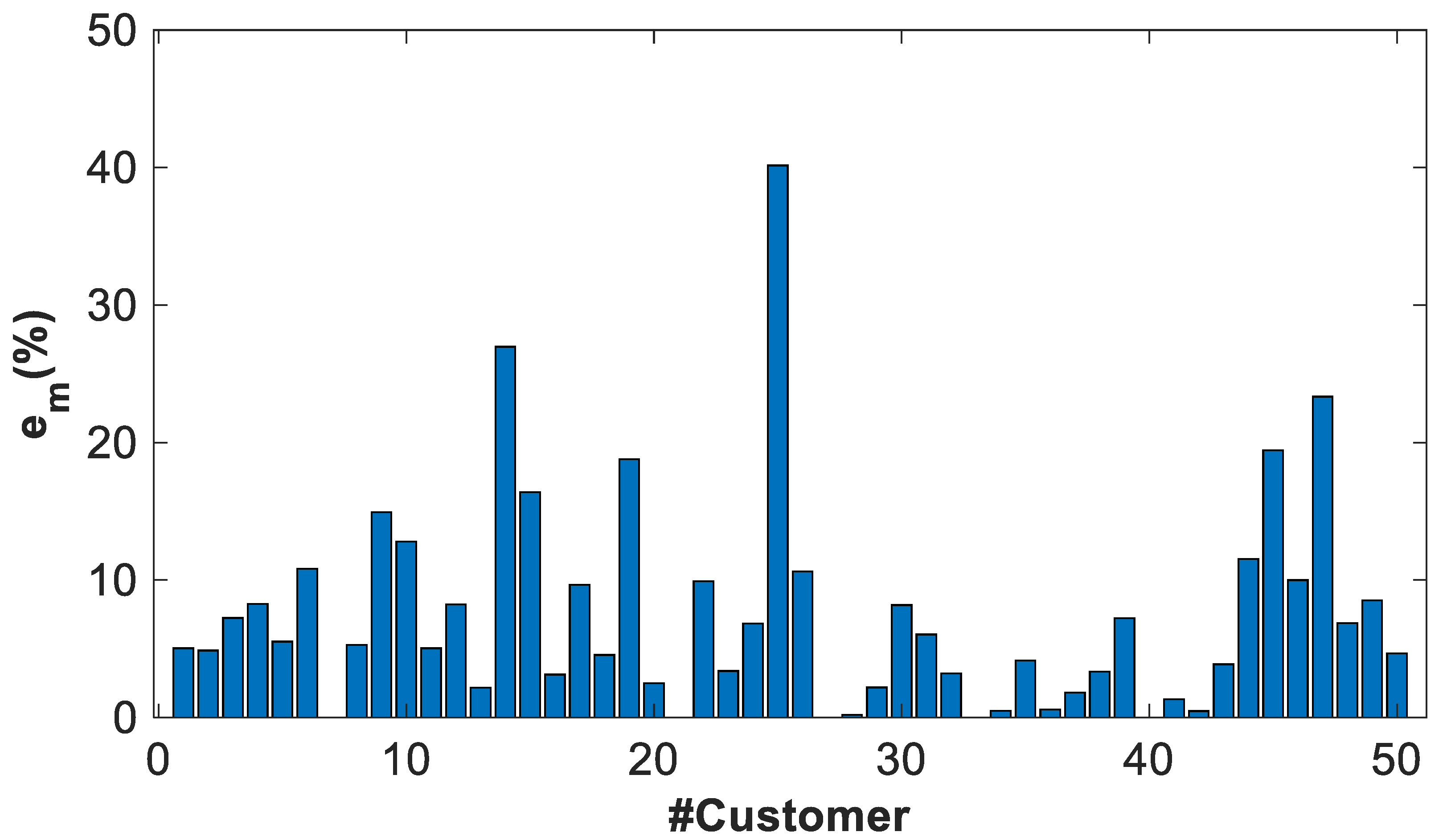
- The residual describes the variability of the power profile estimator with respect to the power profiles used to calculate it.
- The error describes the variability of the power profile estimator with the respect to validation power profiles, different from the previous one.
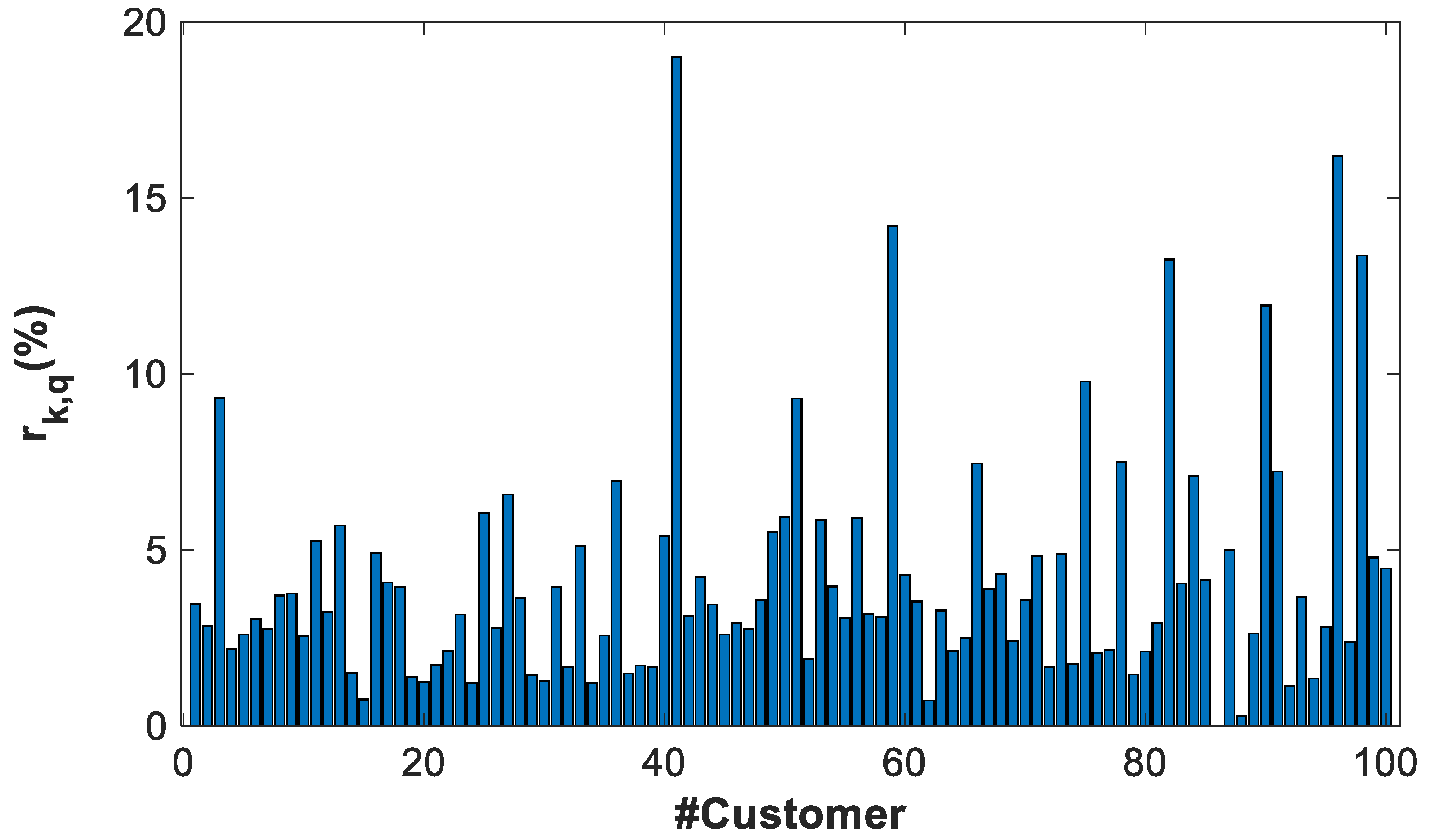
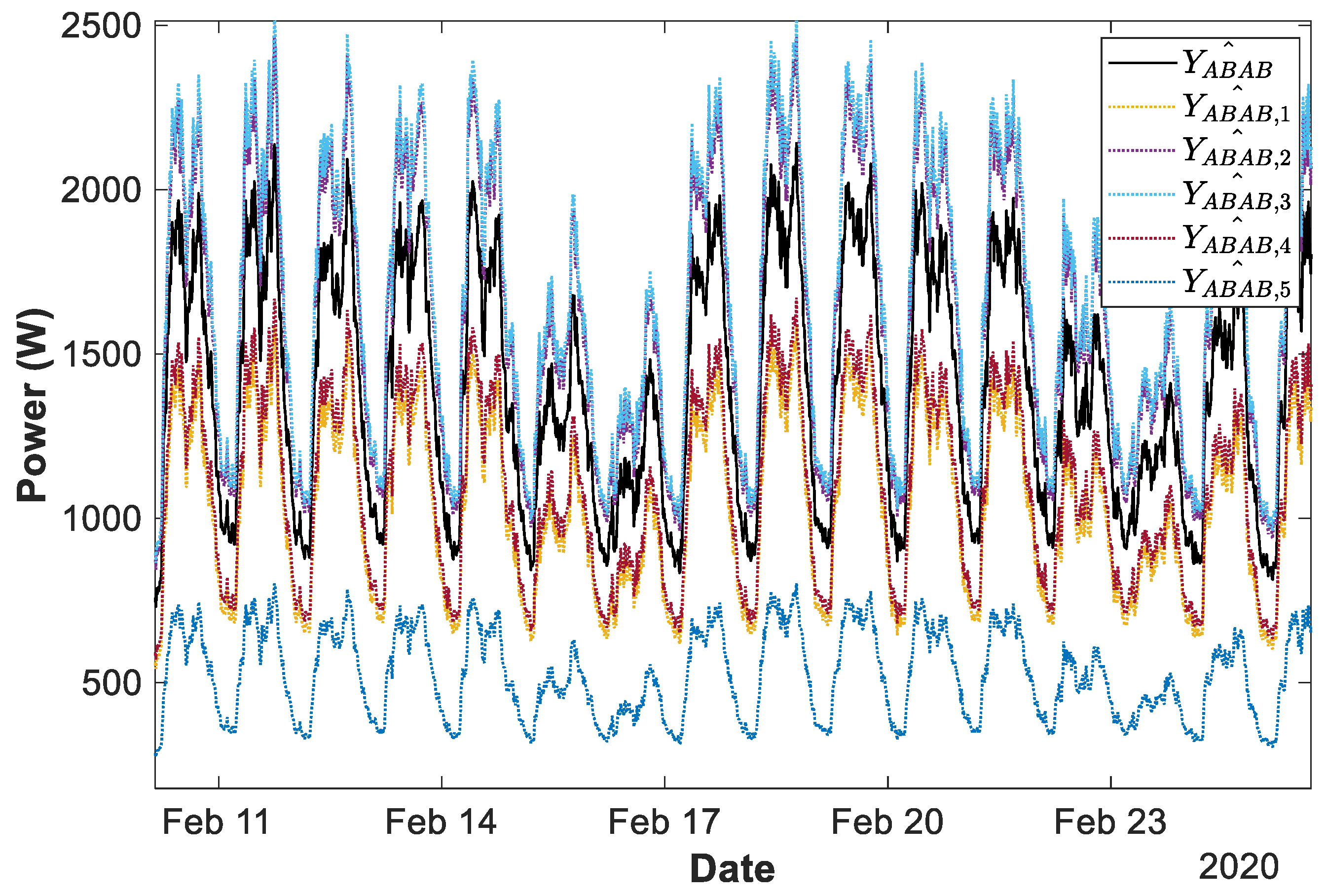
4.2.1. Example of Cluster ABAB
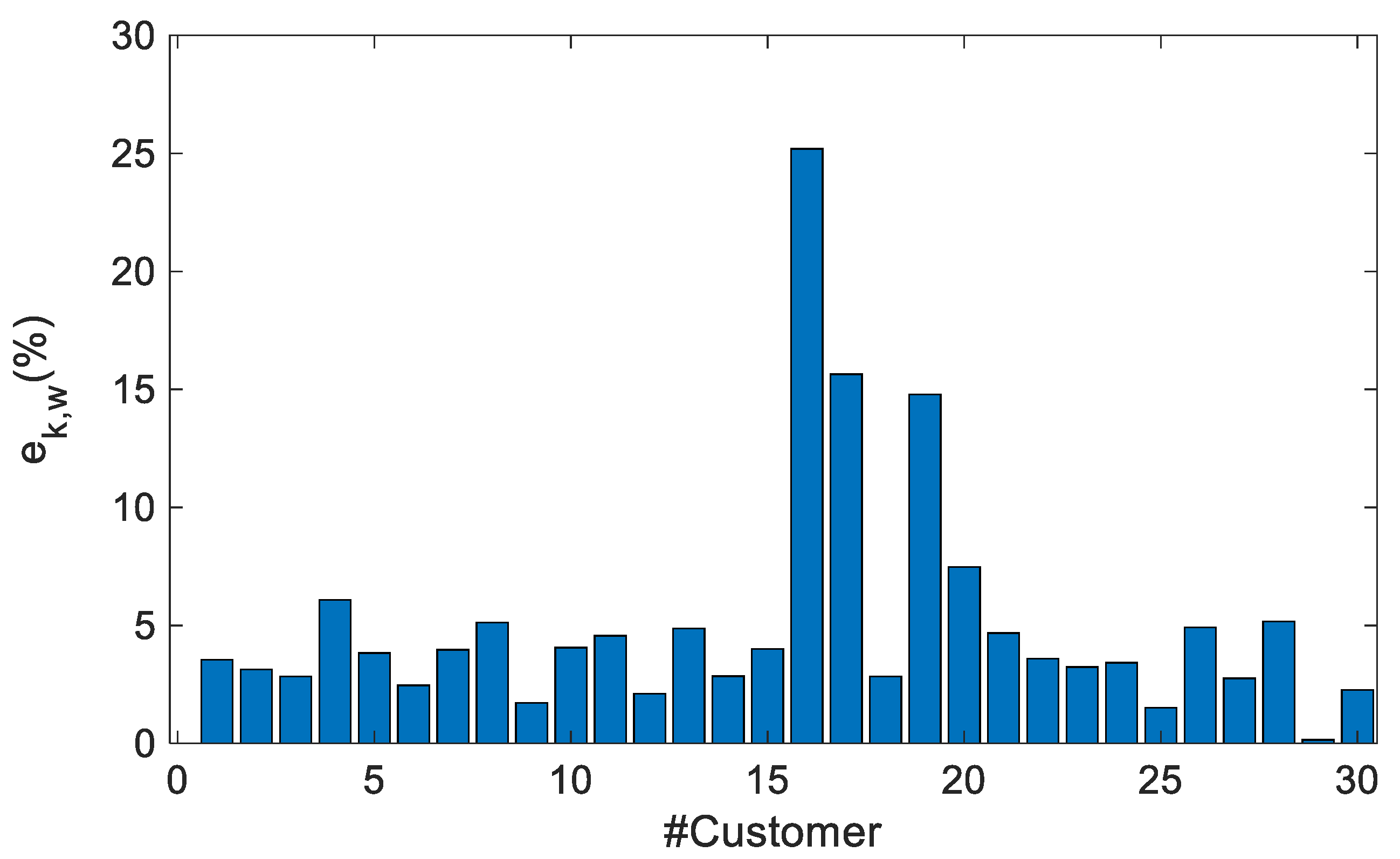
4.2.2. Example of Cluster AAAA-BA
4.2.3. Reference Algorithm
4.2.4. General Results
4.3. Full Profile Generation
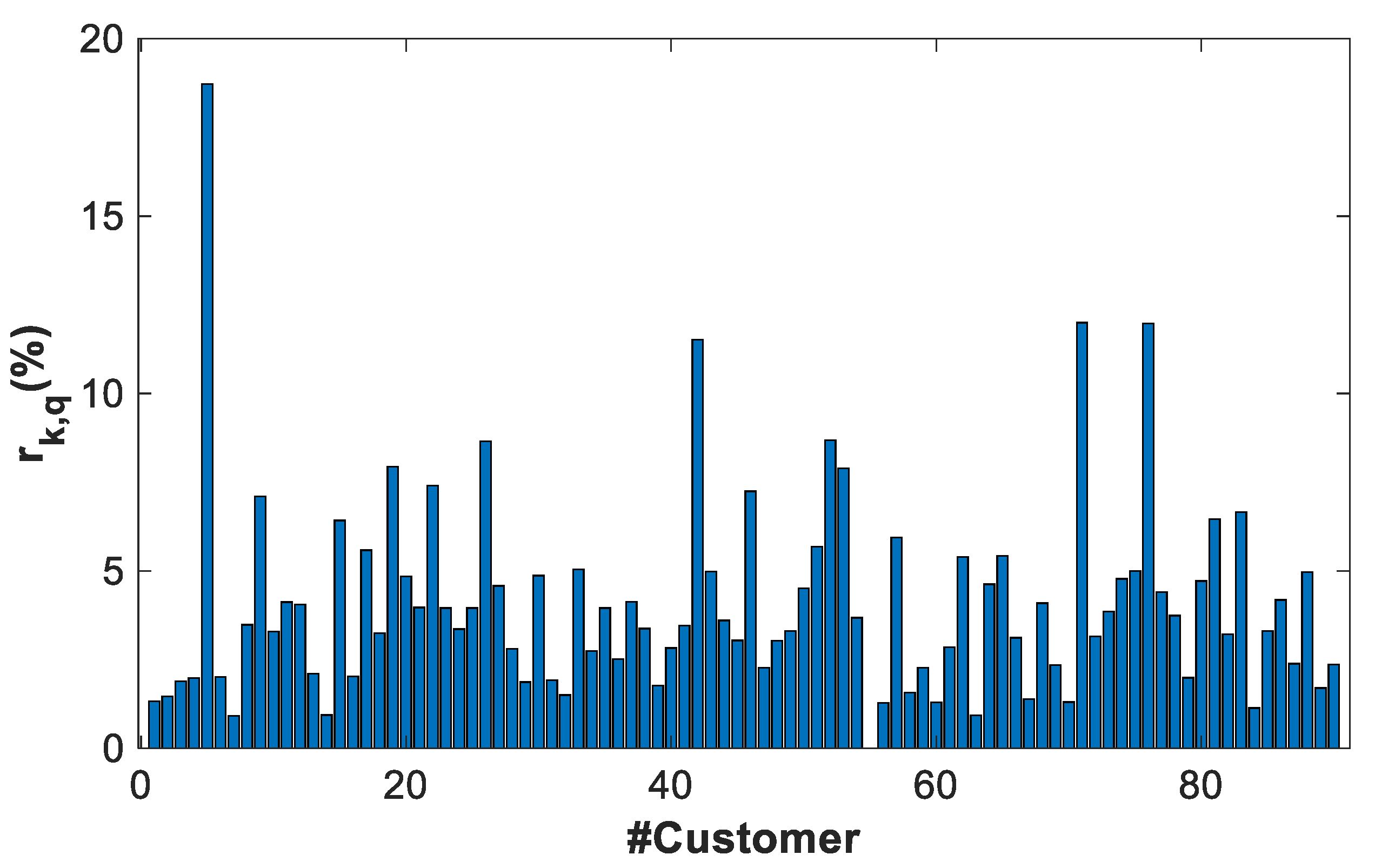
4.3.1. Example of Cluster ABAB
4.3.2. Example of Cluster AAAA-BA
4.3.3. Reference Algorithm
4.3.4. General Results
5. Discussion
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
Nomenclature
| S | Customer’s contract status |
| V | Voltage level |
| T | Customer’s contract type |
| R | Customer’s type |
| P | Contract Power |
| N | Total number of customers |
| Xi | Properties of the ith customer |
| Hi | Vector of the contract features of the customer |
| Yi | Mean Active power profiles |
| T | Time horizon |
| k | Total number of clusters |
| M | Cardinality of a cluster |
| Ek | Total energy associated to a cluster k over the time horizon T |
| Em | Total energy of the mth power profile over the time horizon T |
| Power profile estimator | |
| Q | Sub-set of power profiles used to estimate |
| QS | Design parameter used to define the actual value of Q |
| Pk | Upper bound of contractual power of cluster k |
| The residual of the qth power profile of the cluster k | |
| The normalized total residual of cluster k | |
| Wk | Cardinality of the set of power profiles used for the validation |
| The normalized total error of cluster k | |
| The error of the wth power profile of the cluster k | |
| ε | Tolerated deviation of the validation power profiles with the respect to the estimator |
| Energy of the power profile estimator of cluster k over the time horizon T | |
| Normalized power profile estimator | |
| Full power profile of the m customer of the cluster k | |
| The error of the mth full power profile with the respect to validation power profile | |
| The total error of the cluster k in estimating the full power profiles | |
| The distance of the mth full power profile with the respect to the power profile estimator | |
| The total distance of the full power profiles of the cluster k |
References
- Repo, S.; Maki, K.; Jarventausta, P.; Samuelsson, O. ADINE—EU demonstration project of active distribution network. In Proceedings of the CIRED Seminar 2008: SmartGrids for Distribution, Frankfurt, Germany, 23–24 June 2008; pp. 1–5. [Google Scholar]
- Stanelyte, D.; Radziukynas, V. Review of voltage and reactive power control algorithms in electrical distribution networks. Energies 2019, 13, 58. [Google Scholar] [CrossRef] [Green Version]
- Alonso, M.; Amarís, H.; Rojas, B.; Della Giustina, D.; Dedè, A.; AlJassim, Z. Optimal network reconfiguration for congestion management optimization in active distribution networks. In Proceedings of the International Conference on Renewable Energies and Power Quality (ICREPQ-2016), Madrid, Spain, 4–6 May 2016. [Google Scholar]
- Tran, Q.T.T.; Sanseverino, E.R.; Zizzo, G.; Di Silvestre, M.L.; Nguyen, T.L.; Tran, Q.-T. Real-time minimization power losses by driven primary regulation in islanded microgrids. Energies 2020, 13, 451. [Google Scholar] [CrossRef] [Green Version]
- Kacejko, P.; Adamek, S.; Wydra, M. Optimal voltage control in distribution networks with dispersed generation. In Proceedings of the 2010 IEEE PES Innovative Smart Grid Technologies Conference Europe (ISGT Europe), Gothenberg, Sweden, 11–13 October 2010; pp. 1–4. [Google Scholar] [CrossRef]
- Pasetti, M.; Rinaldi, S.; Flammini, A.; Longo, M.; Foiadelli, F. Assessment of electric vehicle charging costs in presence of distributed photovoltaic generation and variable electricity tariffs. Energies 2019, 12, 499. [Google Scholar] [CrossRef] [Green Version]
- Aslam, S.; Khalid, A.; Javaid, N. Towards efficient energy management in smart grids considering microgrids with day-ahead energy forecasting. Electr. Power Syst. Res. 2020, 182, 106232. [Google Scholar] [CrossRef]
- Pau, M.; Pegoraro, P.A.; Monti, A.; Muscas, C.; Ponci, F.; Sulis, S. Impact of Current and Power Measurements on Distribution System State Estimation Uncertainty. IEEE Trans. Instrum. Meas. 2019, 68, 3992–4002. [Google Scholar] [CrossRef]
- Rinaldi, S.; Della Giustina, D.; Ferrari, P.; Flammini, A. Distributed monitoring system for voltage dip classification over distribution grid. Sustain. Energy Grids Netw. 2016, 6, 70–80. [Google Scholar] [CrossRef]
- Tosato, P.; Macii, D.; Luiso, M.; Brunelli, D.; Gallo, D.; Landi, C. A Tuned Lightweight Estimation Algorithm for Low-Cost Phasor Measurement Units. IEEE Trans. Instrum. Meas. 2018, 67, 1047–1057. [Google Scholar] [CrossRef]
- Leonardi, L.; Battaglia, F.; Bello, L.L. RT-LoRa: A Medium Access Strategy to Support Real-Time Flows over LoRa-Based Networks for Industrial IoT Applications. IEEE Internet Things J. 2019, 6, 10812–10823. [Google Scholar] [CrossRef]
- Pasetti, M.; Sisinni, E.; Ferrari, P.; Rinaldi, S.; Depari, A.; Bellagente, P.; Giustina, D.D.; Flammini, A. Evaluation of the use of class B LoraWAn for the coordination of distributed interface protection systems in smart grids. J. Sens. Actuator Netw. 2020, 9, 13. [Google Scholar] [CrossRef] [Green Version]
- Wydra, M.; Kubaczynski, P.; Mazur, K.; Ksiezopolski, B. Time-aware monitoring of overhead transmission line sag and temperature with lora communication. Energies 2019, 12, 505. [Google Scholar] [CrossRef] [Green Version]
- Hashmi, S.A.; Ali, C.F.; Zafar, S. Internet of things and cloud computing-based energy management system for demand side management in smart grid. Int. J. Energy Res. 2021, 45, 1007–1022. [Google Scholar] [CrossRef]
- Albu, M.M.; Sǎnduleac, M.; Stǎnescu, C. Syncretic Use of Smart Meters for Power Quality Monitoring in Emerging Networks. IEEE Trans. Smart Grid 2017, 8, 485–492. [Google Scholar] [CrossRef]
- Lukocius, R.; Nakutis, Ž.; Daunoras, V.; Deltuva, R.; Kuzas, P.; Rackiene, R. An analysis of the systematic error of a remote method for a wattmeter adjustment gain estimation in smart grids. Energies 2019, 12, 37. [Google Scholar] [CrossRef] [Green Version]
- Nakutis, Z.; Rinaldi, S.; Kuzas, P.; Lukočius, R. A Method for Noninvasive Remote Monitoring of Energy Meter Error Using Power Consumption Profile. IEEE Trans. Instrum. Meas. 2020, 69, 6677–6685. [Google Scholar] [CrossRef]
- Rinaldi, S.; Bonafini, F.; Ferrari, P.; Flammini, A.; Sisinni, E.; Cara, D.D.; Panzavecchia, N.; Tine, G.; Cataliotti, A.; Cosentino, V.; et al. Characterization of IP-Based communication for smart grid using software-defined networking. Trans. Instrum. Meas. 2018, 67, 2410–2419. [Google Scholar] [CrossRef]
- Artale, G.; Cataliotti, A.; Cosentino, V.; Di Cara, D.; Guaiana, S.; Panzavecchia, N.; Tine, G. Real-Time Power Flow Monitoring and Control System for Microgrids Integration in Islanded Scenarios. IEEE Trans. Ind. Appl. 2019, 55, 7186–7197. [Google Scholar] [CrossRef]
- Natale, N.; Pilo, F.; Pisano, G.; Troncia, M.; Bignucolo, F.; Coppo, M.; Pesavento, N.; Turri, R. Assessment of typical residential customers load profiles by using clustering techniques. In Proceedings of the 2017 AEIT International Annual Conference, Cagliari, Italy, 20–22 September 2017; pp. 1–6. [Google Scholar]
- Zhong, S.; Tam, K. Hierarchical Classification of Load Profiles Based on Their Characteristic Attributes in Frequency Domain. IEEE Trans. Power Syst. 2015, 30, 2434–2441. [Google Scholar] [CrossRef]
- Mutanen, A.; Ruska, M.; Repo, S.; Järventausta, P. Customer Classification and Load Profiling Method for Distribution Systems. IEEE Trans. Power Del. 2011, 26, 1755–1763. [Google Scholar] [CrossRef]
- Prahastono, I.; King, D.; Ozveren, C.S. A review of Electricity Load Profile Classification methods. In Proceedings of the 2007 42nd International Universities Power Engineering Conference, Brighton, MA, USA, 4–6 September 2007; pp. 1187–1191. [Google Scholar]
- Vasconcelos, J. Survey of Regulatory and technological Development Concerning Smart Metering in the European Union Electricity Market; Policy Papers, RSCAS 2008/01; European University Institute: Florence, Italy, 2008. [Google Scholar]
- Marcoci, A.; Raffaelli, S.; Galan, J.M.; Cagno, E.; Micheli, G.J.L.; Mauri, G.; Urban, R.; Grids, S.; Fenosa, U.; Gestionale, D.I. The Meter-ON project: How to support the deployment of advanced metering infrastructures in Europe? In Proceedings of the CIRED, Stockholm, Sweden, 10–13 June 2013; pp. 1–4. [Google Scholar]
- Milam, M.; Venayagamoorthy, G.K. Smart meter deployment: US initiatives. In Proceedings of the IEEE ISGT 2014, Washington, DC, USA, 19–22 February 2014; pp. 1–5. [Google Scholar]
- Khan, M.F.; Jain, A.; Arunachalam, V.; Paventhan, A. Roadmap for smart metering deployment for Indian smart grid. In Proceedings of the IEEE PES GMCE, National Harbor, MD, USA, 27–31 July 2014; pp. 1–5. [Google Scholar]
- Brunekreeft, G.; Luhmann, T.; Menz, T.; Müller, S.-U.; Recknagel, P. Regulatory Pathways for Smart Grid Development in China; Springer Vieweg: Wiesbaden, Germany, 2015; pp. 1–163. [Google Scholar]
- Duarte, D.P.; Maia, F.C.; Neto, A.B.; Cesar, L.S.; Kagan, N.; Gouvea, M.R.; Labronici, J.; Guimaraes, D.S.; Bonini, A.; Resende Da Silva, J.F. Brazilian smart grid roadmap—An innovative methodology for proposition and evaluation of smart grid functionalities for highly heterogeneous distribution networks. In Proceedings of the 2013 IEEE PES Conference on Innovative Smart Grid Technologies, Sao Paulo, Brazil, 15–17 April 2013; pp. 1–8. [Google Scholar]
- Dedè, A.; Della Giustina, D.; Rinaldi, S.; Ferrari, P.; Flammini, A.; Vezzoli, A. Smart meters as part of a sensor network for monitoring the low voltage grid. In Proceedings of the IEEE Sensors Applications Symposium (SAS), Zadar, Croatia, 13–15 April 2015; pp. 1–6. [Google Scholar]
- Energy Management System, Schneider Electric. Available online: https://www.se.com/ww/en/work/solutions/for-business/electric-utilities/energy-management-system-ems/ (accessed on 28 January 2021).





















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
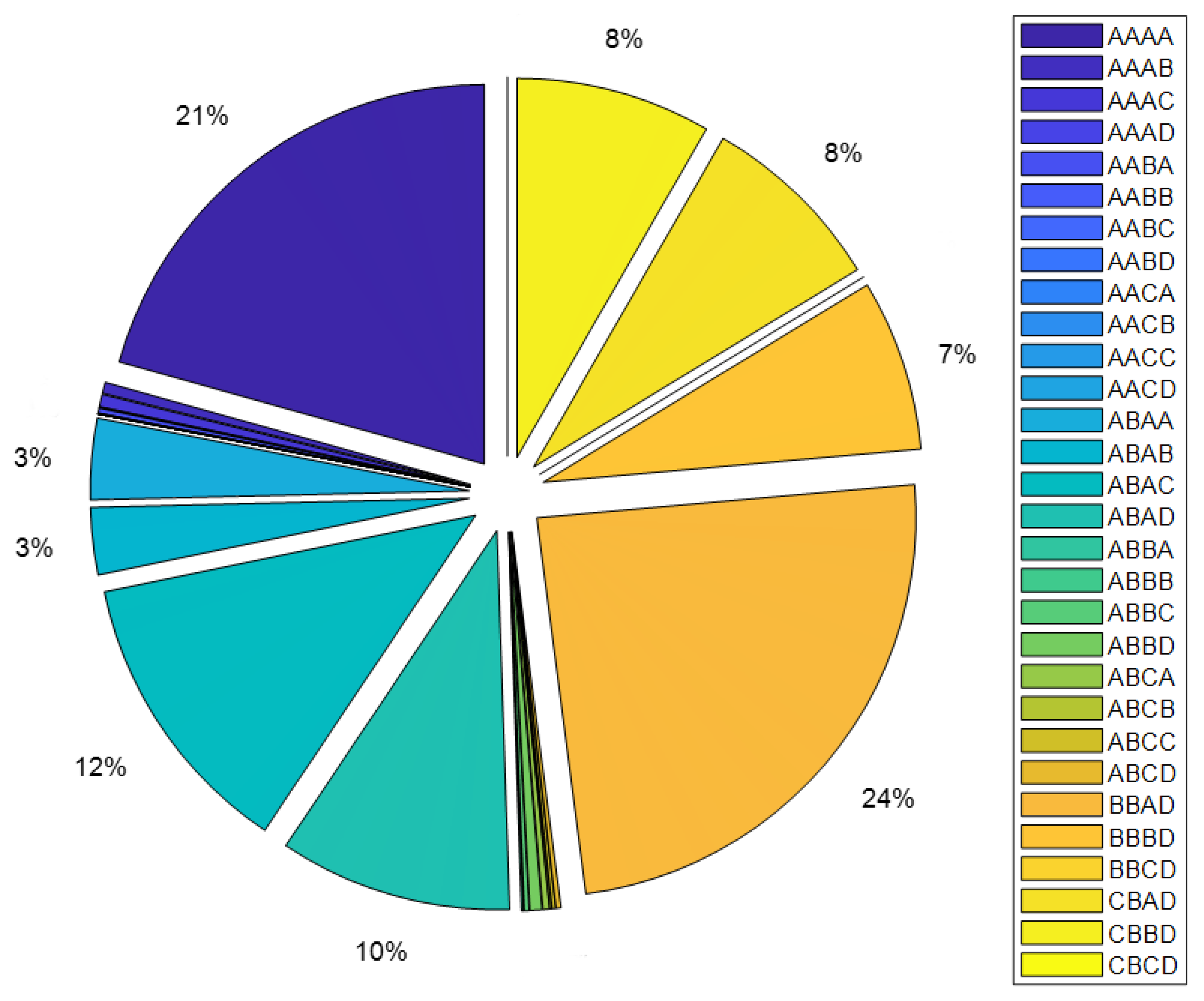
| Cluster | V | T | R | P (kW) | #Customers (%) | Ek (GWh) | Ek (%) |
|---|---|---|---|---|---|---|---|
| * AAAA | LV | Domestic | Consumer | (0.0, 6.6] | 80.1 | 1.58 | 20.7 |
| AAAB | LV | Domestic | Consumer | (6.6, 16.5] | 0.6 | 0.036 | 0.5 |
| AAAC | LV | Domestic | Consumer | (16.5, 55.0] | 0.4 | 0.040 | 0.5 |
| ** AAAD | LV | Domestic | Consumer | (55.0, ∞) | 0.004 | 0.002 | 0.03 |
| AABA | LV | Domestic | Prosumer | (0.0, 6.6] | 0.5 | 0.016 | 0.2 |
| AABB | LV | Domestic | Prosumer | (6.6, 16.5] | 0.02 | 0.0012 | 0.015 |
| AABC | LV | Domestic | Prosumer | (16.5, 55.0] | 0.01 | 0.0016 | 0.02 |
| ** AABD | LV | Domestic | Prosumer | (55.0, ∞) | 0 | 0.00003 | 0 |
| AACA | LV | Domestic | Producer | (0.0, 6.6] | 0 | 0 | 0 |
| AACB | LV | Domestic | Producer | (6.6, 16.5] | 0 | 0 | 0 |
| AACC | LV | Domestic | Producer | (16.5, 55.0] | 0 | 0 | 0 |
| ** AACD | LV | Domestic | Producer | (55.0, ∞) | 0 | 0 | 0 |
| ABAA | LV | Not Domestic | Consumer | (0.0, 6.6] | 10.0 | 0.26 | 3.5 |
| ABAB | LV | Not Domestic | Consumer | (6.6, 16.5] | 2.3 | 0.22 | 2.9 |
| ABAC | LV | Not Domestic | Consumer | (16.5, 55.0] | 4.3 | 0.95 | 12.4 |
| ** ABAD | LV | Not Domestic | Consumer | (55.0, ∞) | 0.74 | 0.76 | 9.9 |
| ABBA | LV | Not Domestic | Prosumer | (0.0, 6.6] | 0.03 | 0.0068 | 0.09 |
| ABBB | LV | Not Domestic | Prosumer | (6.6, 16.5] | 0.02 | 0.0016 | 0.02 |
| ABBC | LV | Not Domestic | Prosumer | (16.5, 55.0] | 0.08 | 0.015 | 0.2 |
| ** ABBD | LV | Not Domestic | Prosumer | (55.0, ∞) | 0.04 | 0.039 | 0.5 |
| ABCA | LV | Not Domestic | Producer | (0.0, 6.6] | 0.48 | 0.021 | 0.2 |
| ABCB | LV | Not Domestic | Producer | (6.6, 16.5] | 0.06 | 0.006 | 0.08 |
| ABCC | LV | Not Domestic | Producer | (16.5, 55.0] | 0.05 | 0.011 | 0.15 |
| ** ABCD | LV | Not Domestic | Producer | (55.0, ∞) | 0.01 | 0.016 | 0.2 |
| *,** BBAD | MV | Not Domestic | Consumer | (55.0, ∞) | 0.19 | 1.86 | 24.3 |
| ** BBBD | MV | Not Domestic | Prosumer | (55.0, ∞) | 0.03 | 0.56 | 7.3 |
| ** BBCD | MV | Not Domestic | Producer | (55.0, ∞) | 0 | 0.0016 | 0.002 |
| ** CBAD | HV | Not Domestic | Consumer | (55.0, ∞) | 0.001 | 0.61 | 7.97 |
| ** CBBD | HV | Not Domestic | Prosumer | (55.0, ∞) | 0.011 | 0.64 | 8.3 |
| ** CBCD | HV | Not Domestic | Producer | (55.0, ∞) | 0. | 0 | 0 |
| CLUSTER | C | P’ (kW) | #Customer (%) | Ek (MWh) | Ek (%) |
|---|---|---|---|---|---|
| AAAA-AA | (500,000, 1,500,000] | (0.0, 3.3] | 0.41 | 2.82 | 0.22 |
| AAAA-AB | (10,000, 500,000] | (0.0, 3.3] | 0.05 | 0.36 | 0.03 |
| AAAA-AC | (20,000, 100,000] | (0.0, 3.3] | 0.04 | 0.20 | 0.02 |
| AAAA-AD | (5000, 20,000] | (0.0, 3.3] | 0.03 | 0.12 | 0.01 |
| AAAA-AE | (0, 5000] | (0.0, 3.3] | 0.10 | 0.22 | 0.02 |
| AAAA-BA | (500,000, 1,500,000] | (3.3, 4.4] | 67.91 | 859 | 65.50 |
| AAAA-BB | (10,000, 500,000] | (3.3, 4.4] | 8.64 | 123 | 9.36 |
| AAAA-BC | (20,000, 100,000] | (3.3, 4.4] | 5.36 | 50.4 | 3.84 |
| AAAA-BD | (5000, 20,000] | (3.3, 4.4] | 4.65 | 62.7 | 4.78 |
| AAAA-BE | (0, 5000] | (3.3, 4.4] | 4.15 | 51.5 | 3.93 |
| AAAA-CA | (500,000, 1,500,000] | (4.4, 5.5] | 0.09 | 1.17 | 0.10 |
| AAAA-CB | (10,000, 500,000] | (4.4, 5.5] | 0.04 | 0.63 | 0.05 |
| AAAA-CC | (20,000, 100,000] | (4.4, 5.5] | 0.01 | 0.10 | 0.01 |
| AAAA-CD | (5000, 20,000] | (4.4, 5.5] | 0.01 | 0.11 | 0.01 |
| AAAA-CE | (0, 5000] | (4.4, 5.5] | 0.01 | 0.06 | 0.01 |
| AAAA-DA | (500,000, 1,500,000] | (5.5, 6.6] | 6.16 | 110 | 8.42 |
| AAAA-DB | (10,000, 500,000] | (5.5, 6.6] | 1.21 | 26.3 | 2.00 |
| AAAA-DC | (20,000, 100,000] | (5.5, 6.6] | 0.38 | 5.33 | 0.41 |
| AAAA-DD | (5000, 20,000] | (5.5, 6.6] | 0.47 | 10.38 | 0.79 |
| AAAA-DE | (0, 5000] | (5.5, 6.6] | 0.31 | 6.82 | 0.52 |
| CLUSTER | rk (%) | ek (%) |
|---|---|---|
| AAAA | 6.4% | 8.3% |
| AAAB | 2.4% | 2.5% |
| ABAB | 5.4% | 6.4% |
| ABAC | 3.7% | 3% |
| ABBA | 10.2% | 15% |
| ABBB | 5.6% | 5.97% |
| AAAA-BA | 4.97% | 4.9% |
| AAAA-BB | 5.4% | 4.9% |
| AAAA-DA | 4.5% | 4.39% |
| CLUSTER | dk (%) | ek (%) |
|---|---|---|
| AAAA | 2.9 | 8.13 |
| AAAB | 1.1 | 2.3 |
| ABAB | 5.1 | 4 |
| ABAC | 3.7 | 2.2 |
| ABBA | 15.6 | 6.3 |
| ABBB | 4.5 | 3.5 |
| AAAA-BA | 2.9 | 4.2 |
| AAAA-BB | 2.2 | 2.9 |
| AAAA-DA | 2.6 | 3.6 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Della Giustina, D.; Rinaldi, S.; Robustelli, S.; Angioni, A. Massive Generation of Customer Load Profiles for Large Scale State Estimation Deployment: An Approach to Exploit AMI Limited Data. Energies 2021, 14, 1277. https://doi.org/10.3390/en14051277
Della Giustina D, Rinaldi S, Robustelli S, Angioni A. Massive Generation of Customer Load Profiles for Large Scale State Estimation Deployment: An Approach to Exploit AMI Limited Data. Energies. 2021; 14(5):1277. https://doi.org/10.3390/en14051277
Chicago/Turabian StyleDella Giustina, Davide, Stefano Rinaldi, Stefano Robustelli, and Andrea Angioni. 2021. "Massive Generation of Customer Load Profiles for Large Scale State Estimation Deployment: An Approach to Exploit AMI Limited Data" Energies 14, no. 5: 1277. https://doi.org/10.3390/en14051277
APA StyleDella Giustina, D., Rinaldi, S., Robustelli, S., & Angioni, A. (2021). Massive Generation of Customer Load Profiles for Large Scale State Estimation Deployment: An Approach to Exploit AMI Limited Data. Energies, 14(5), 1277. https://doi.org/10.3390/en14051277