
Forecasting of 10-Second Power Demand of Highly Variable Loads for Microgrid Operation Control



Abstract
:1. Introduction
1.1. Related Works
1.2. Objective and Contribution
- Conduct statistical analysis of two distinct time series of values of 10 s power demand together with the initial choice of input data with the use of six different selection methods;
- Verify the efficiency of 10 s horizon power demand forecasting with the use of 15 forecasting methods, including ensemble methods; more than 150 various models with different values of parameters/hyperparameters have been tested for this purpose;
- Verify a newly developed strategy of choosing the best four predictors to be included in ensemble methods; the strategy, apart from the criterion of the least RMSE error of forecasts as well as dissimilarity of predictors action, utilizes an additional criterion, with the biggest differences in rests from the forecasts obtained with the use of methods being candidates for inclusion into the ensemble;
- Check whether there are any effective methods for very short-term forecasting of 10 s power demand (characterized by big volatility of loads) which can be used in practice;
- Indicate forecasting methods which are most efficient for this type of time series based on our analysis of forecasting results obtained for the two time series studied here.
- This study has been done using two distinct time series, very difficult in practice to access, of 10 s power demand of highly variable loads, which is a significant novelty in the area of forecasting. It is a new, very promising topic yet to be widely recognized by forecasting researchers;
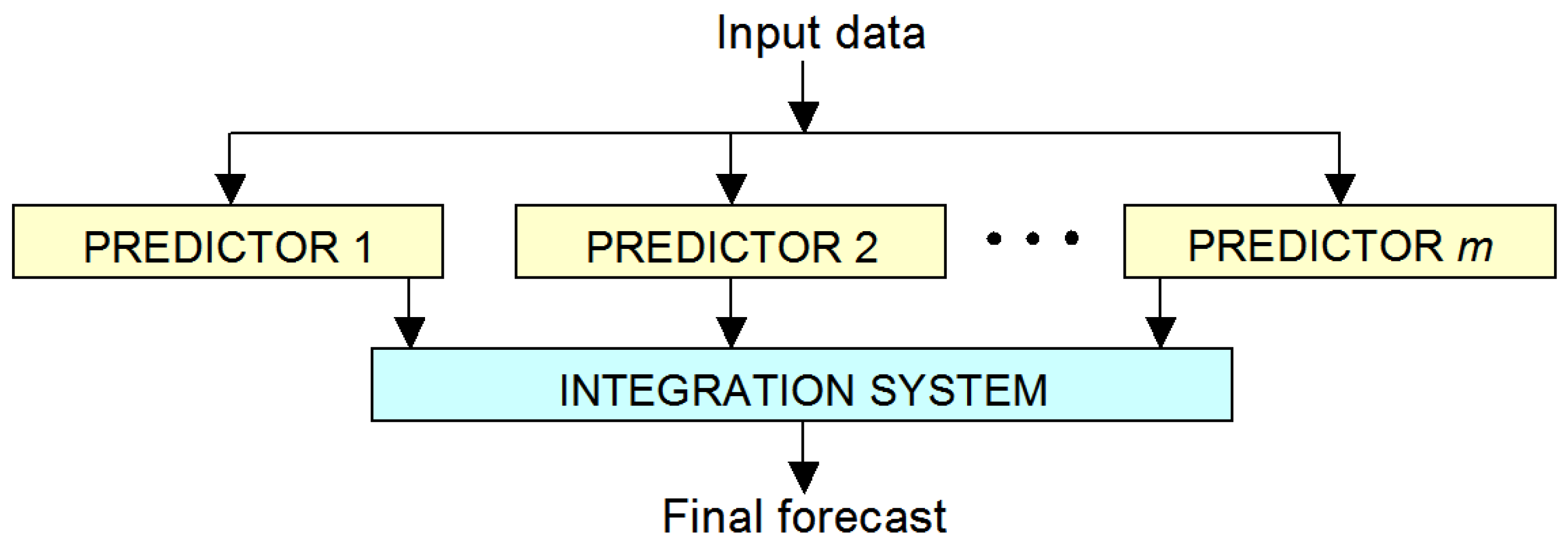
- Very comprehensive analyses concerning usefulness of different forecasting methods have been conducted for two distinct time series—starting from methods utilizing only time series itself, to the newest machine learning techniques, and finally to ensemble methods using additional explanatory variables;
- The authors of the study have developed some of the ensemble models proposed in the range of choice of methods sets constituting the models set;
- Very significant, detailed suggestions concerning the most effective methods for very short-term forecasts of power demand of big dynamics of load changes have been developed; similarly, a list of the least useful methods for this type of time series has also been presented;
- The analysis of usefulness of various forecasting methods for two independent time series of very big dynamics of load changes is an essential, very valuable element of our study. Credibility of conclusions concerning the preferred methods has increased considerably thanks to the mentioned analysis.
2. Data
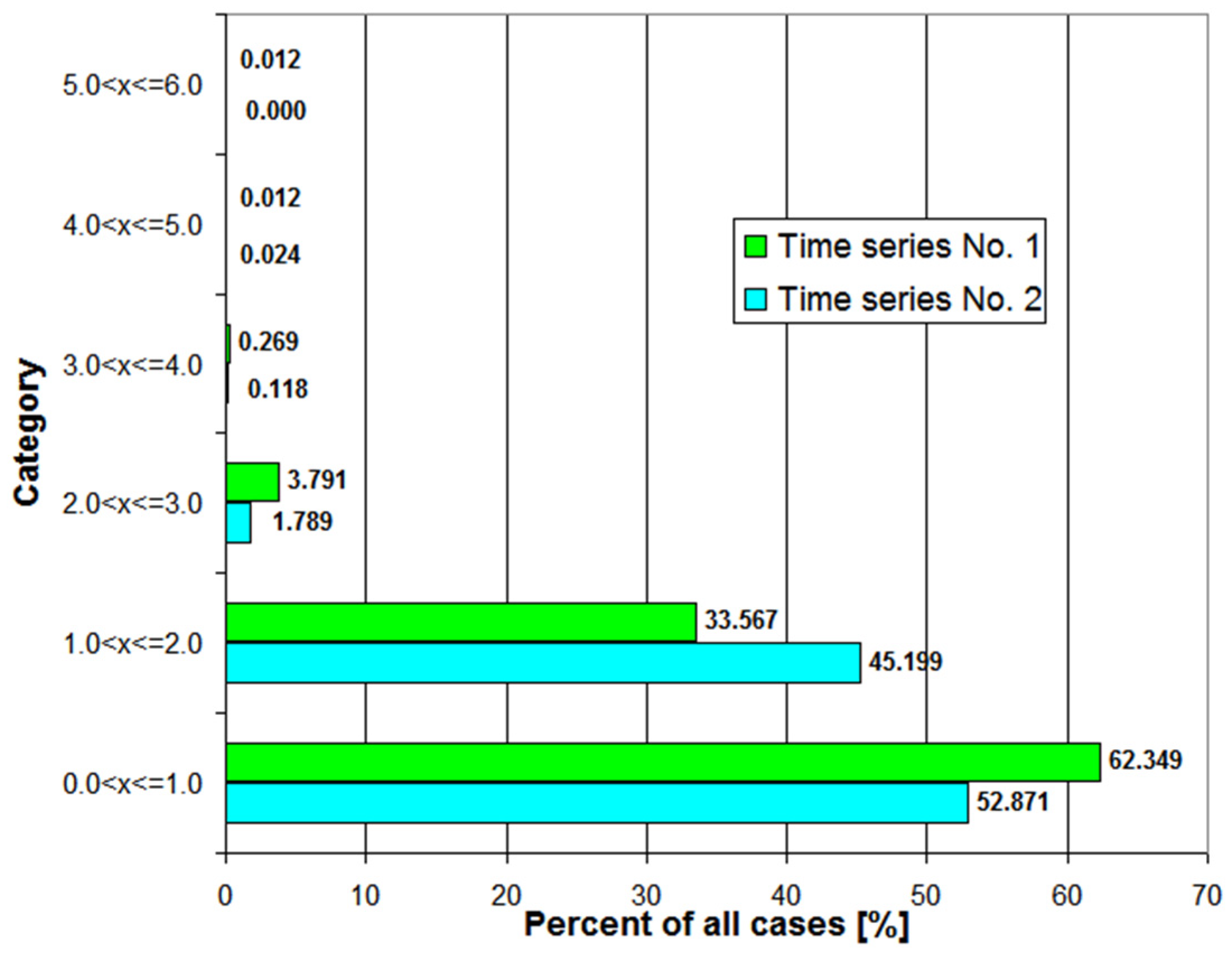
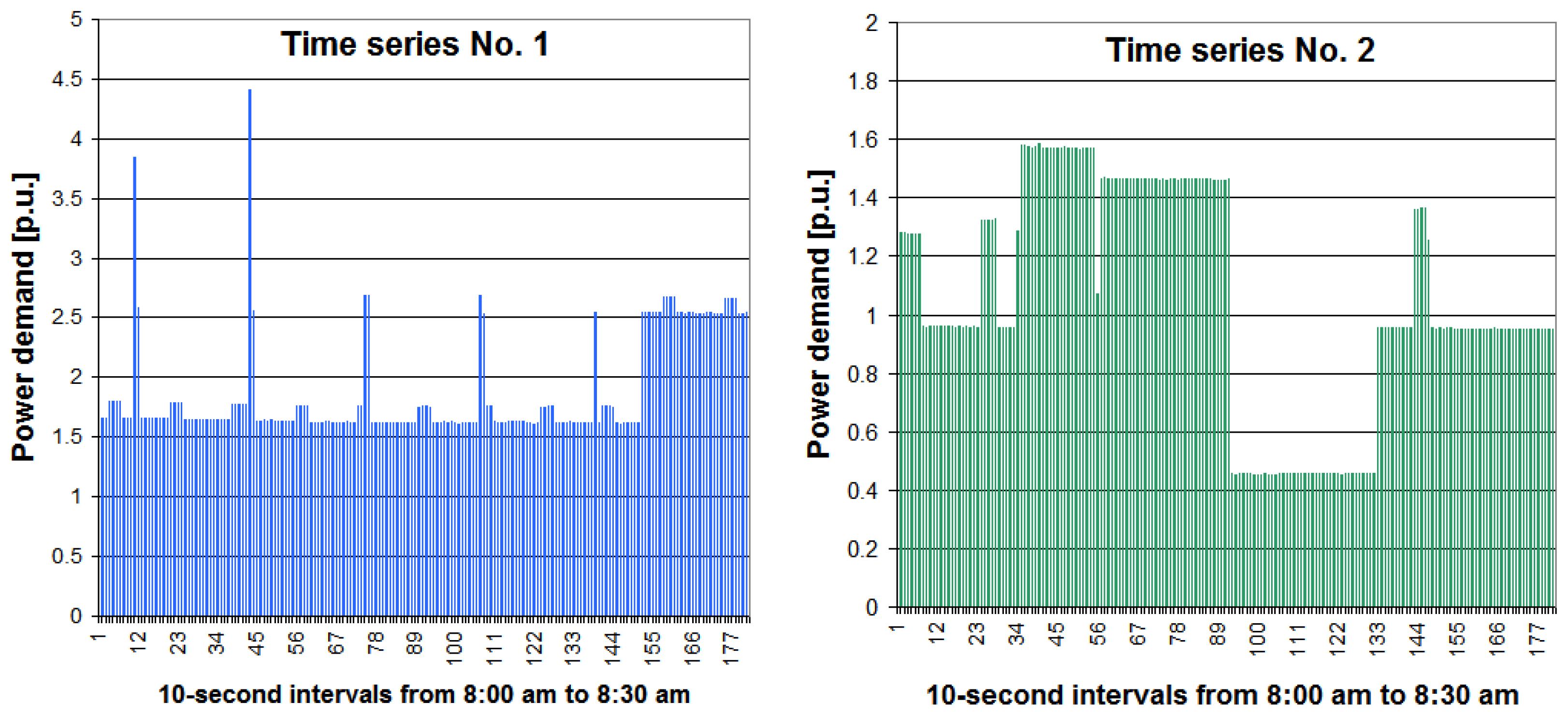
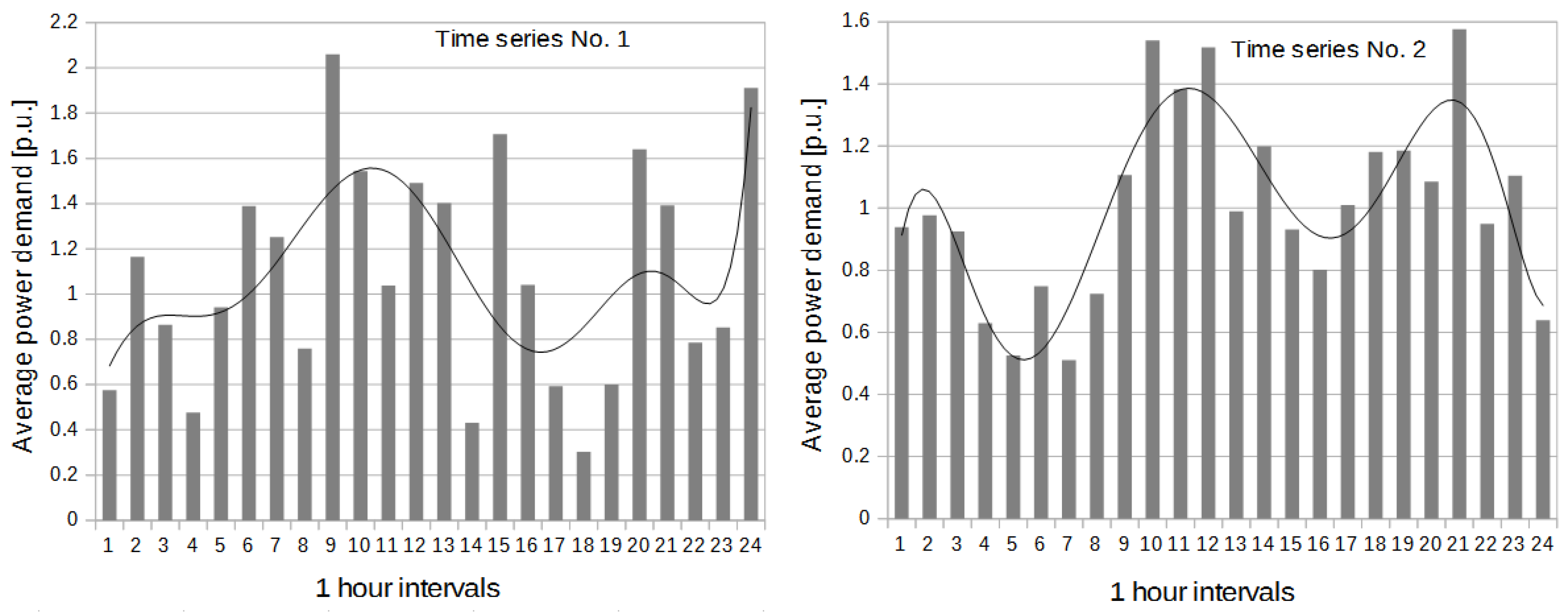
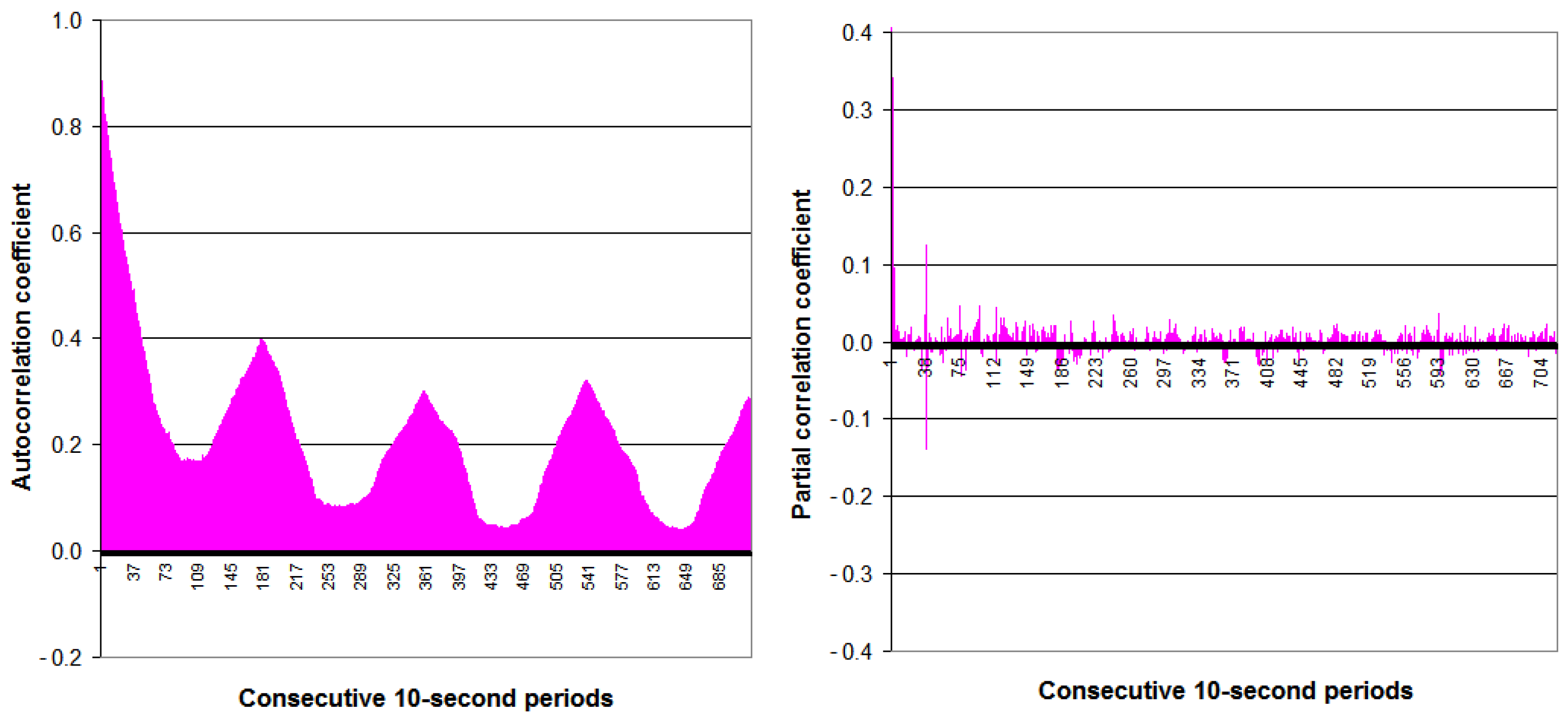
2.1. Statistical Analysis of the Two Time Series of Power Demand Data
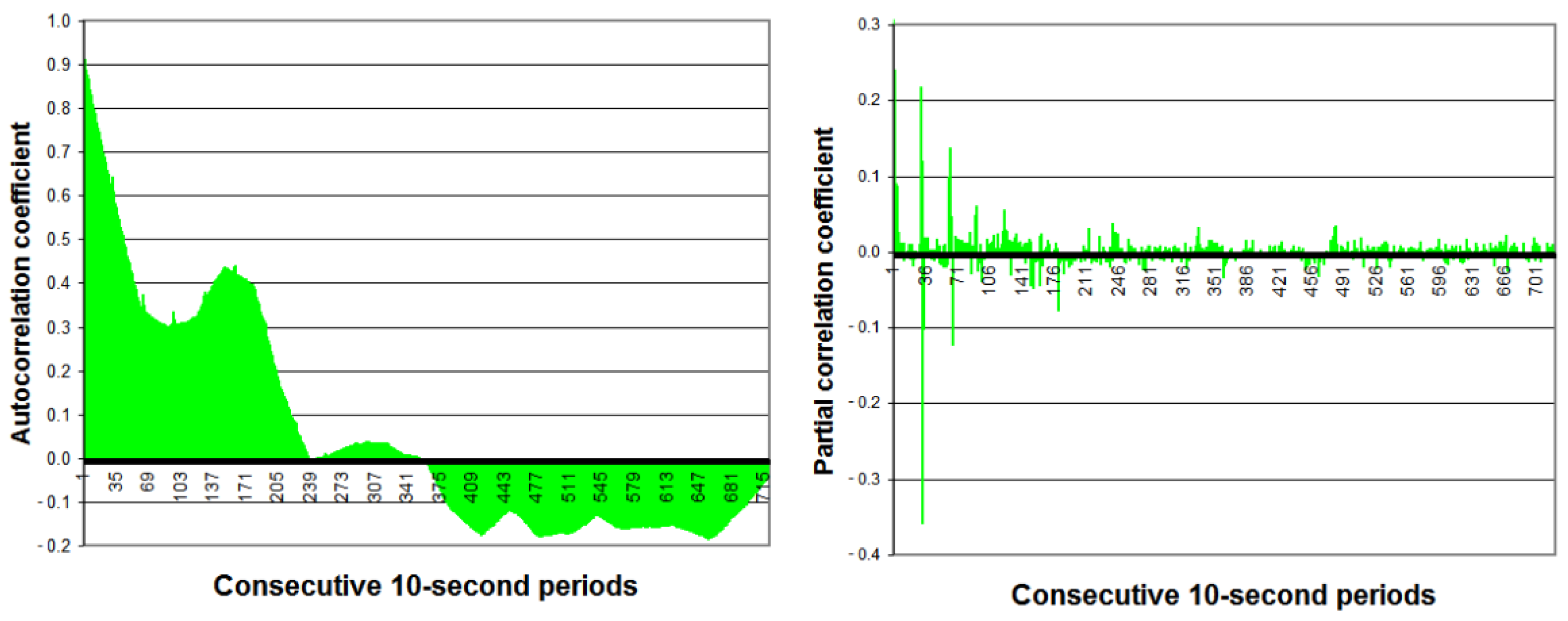
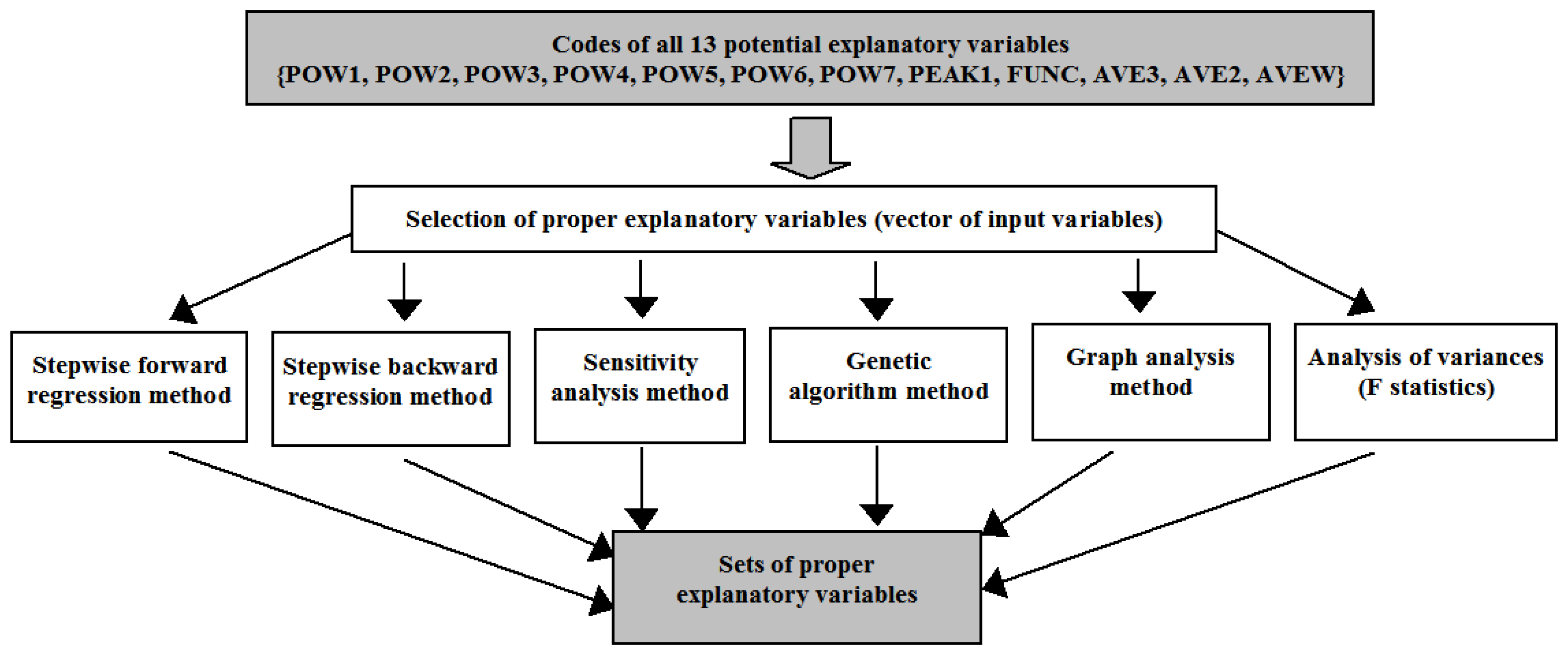
2.2. Analysis of Potential Input Data for Forecasting Methods
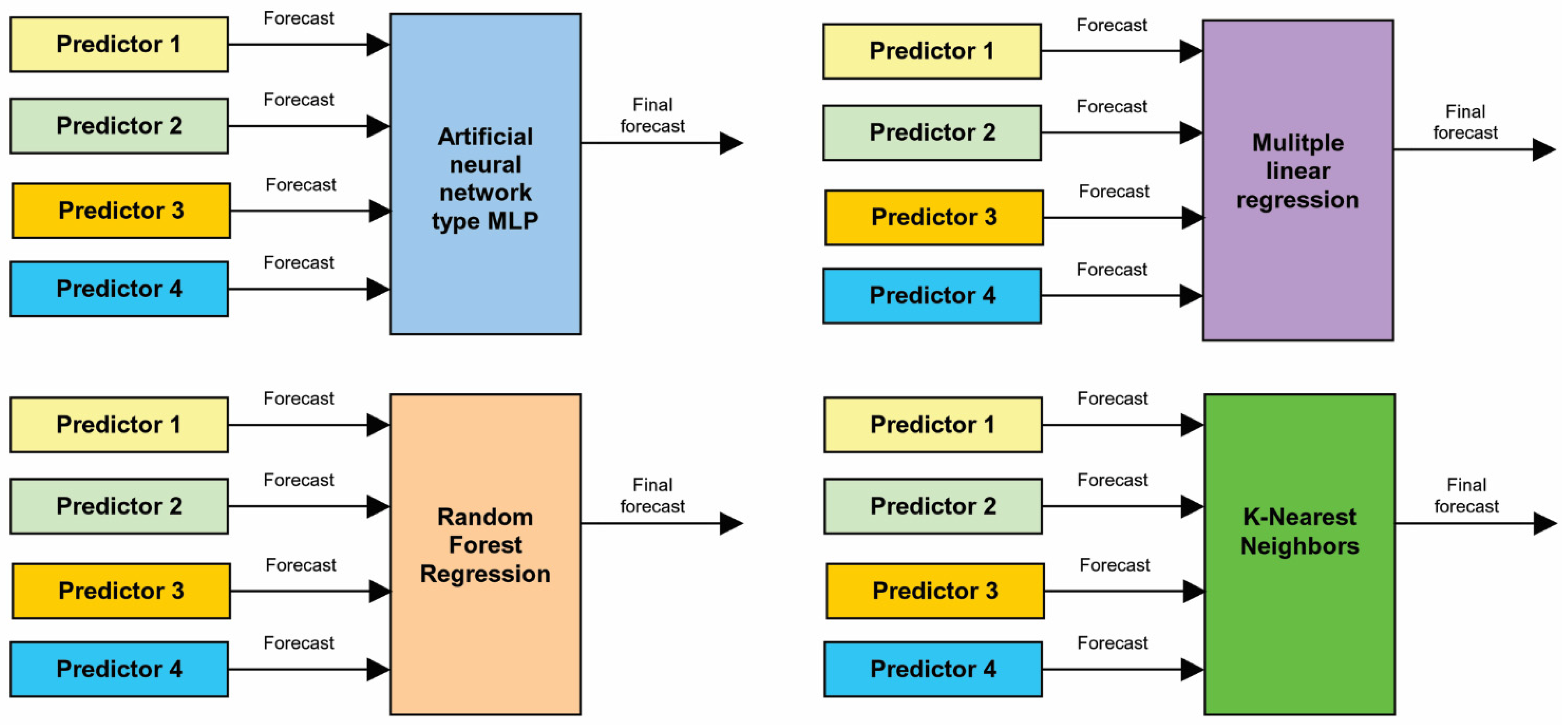
3. Forecasting Methods
- The choice of predictors based on RMSE (code WAE_RMSE). Three or four predictors based on the smallest RMSE errors on validation subset and only predictors of different types are selected to the ensemble;
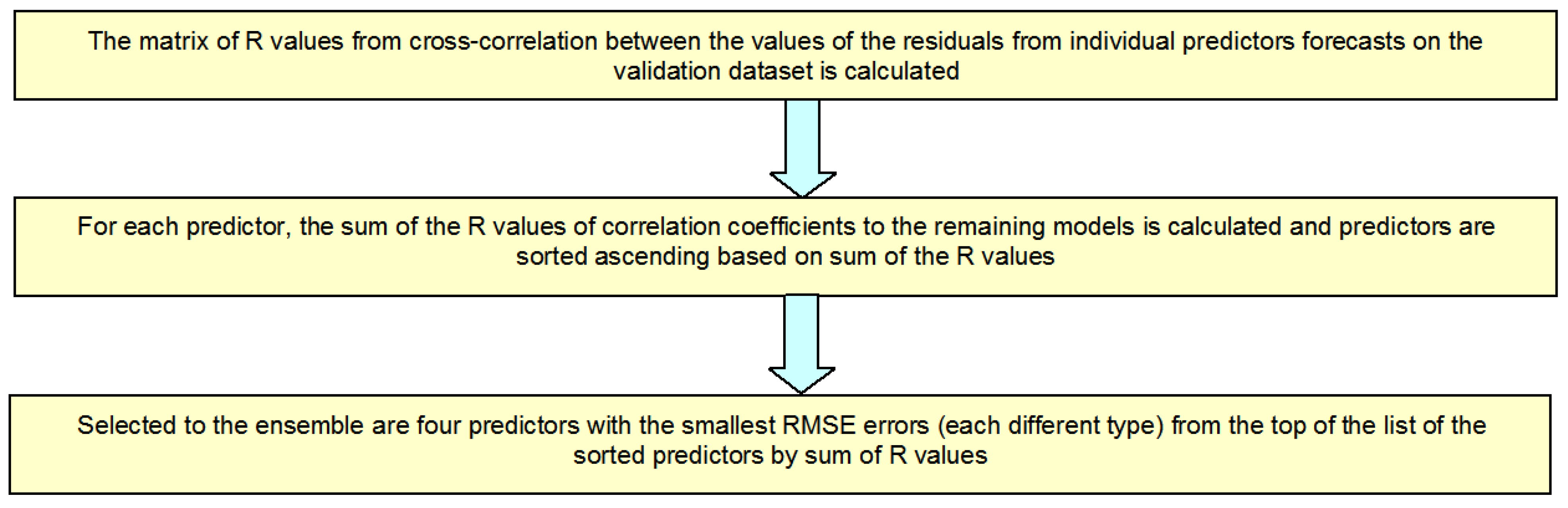
- The choice of predictors based on RMSE and R (code WAE_R/RMSE). The time series of the residues from forecasts should be most different from each other and RMSE error should be small. The choice algorithm of predictors based on RMSE and R is presented in Figure 10.
4. Evaluation Criteria
5. Results
6. Discussion
- The best methods in terms of RMSE value are, respectively: MLP, LR, ARIMA; for MLP and LR, a more favorable solution is to utilize all 11 input data instead of 5 input data selected on the basis of the analysis of variables selection;
- An advantage of the LR method in comparison with MLP is very short time of calculations, low computational complexity and no necessity of proper selection of hyperparameter values which are required by MLP (only selection of the most advantageous input data may be needed);
- Qualitative differences between the best three methods are very small;
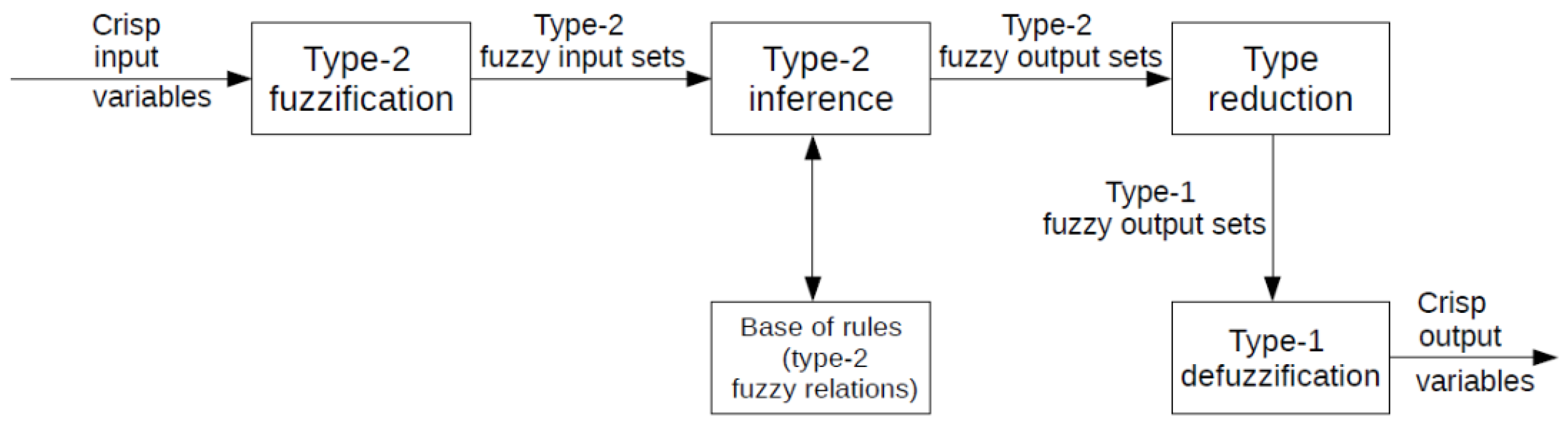
- The worst methods in terms of RMSE value, in comparison with the reference method AR(1), are: SVR, KNN and IT2FLS; for IT2FLS method the use of five input data instead of four last time-lagged values of variables of time series being forecast allowed to decrease RMSE error;
- A disadvantage of IT2FLS is very long time of calculations (the time depends on CPU and RAM memory of computer being used) and the necessity of proper selection of many hyperparameter values; for the KNN method with five input data, the smallest MAPE and sMAPE errors have been obtained from all tested methods, although the RMSE error for the method is significant in comparison with the best methods.
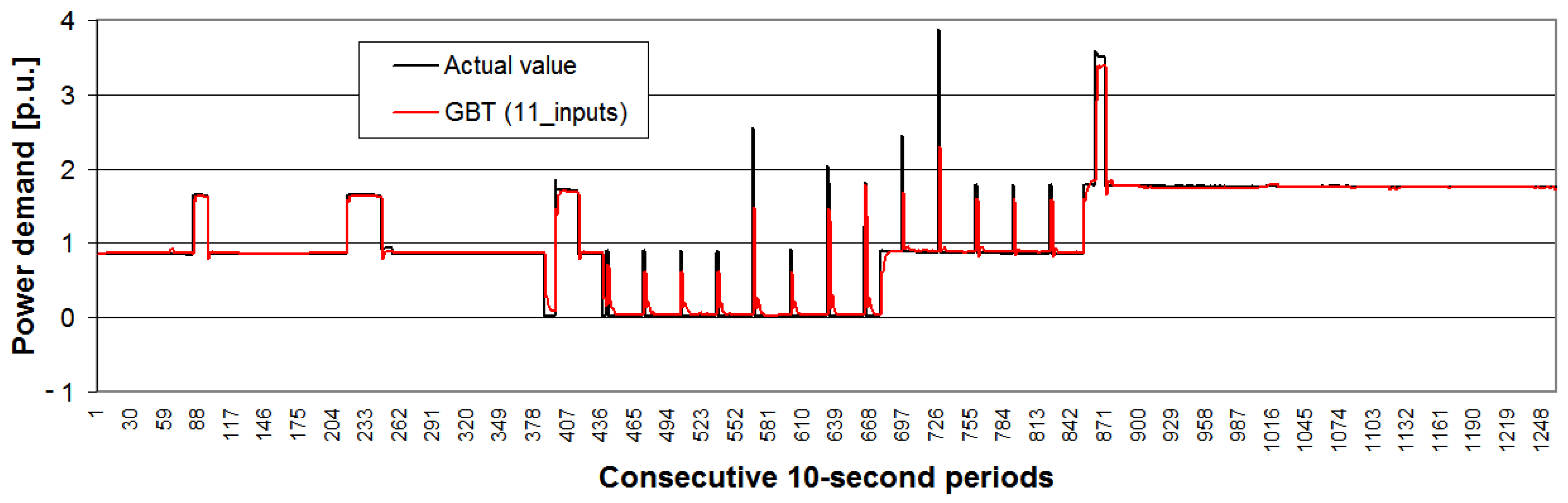
- The best ensemble methods are, respectively: GBT and LR as an integrator of ensemble; for GBT, it is more useful to utilize all 11 input data;
- GBT ensemble method seems to be more useful than LR as an integrator of ensemble, considering greater simplicity of the method (no necessity to integrate four different method types), in which the ensemble is an internal component of the algorithm (single decision trees);
- All ensemble methods have smaller RMSE errors than the reference AR(1) method;
- Among ensemble methods, only RF as an integrator of ensemble has greater RMSE error than the best single method, i.e., MLP; it clearly shows that using ensemble methods (except RF) is justified in this forecasting exercise and allows us to decrease RMSE error in comparison with single methods;
- Similarly, as in the KNN single method, using KNN as an integrator of ensemble allows us to get the smallest MAPE and sMAPE errors of all tested ensemble methods, at the same time the RMSE error for the method is significant in comparison with the best ensemble methods;
- WAE_R/RMSE ensemble method is less advantageous than WAE_RMSE ensemble method;
- RF is the worst of all ensemble methods.
- The best methods in terms of RMSE value are, respectively: LR, ARIMA and MLP; for MLP and for LR, it is more useful to utilize 5 input data, selected on the basis of the analysis of variables selection, instead of all 11 input data;
- Qualitative differences among the best three methods are very small;
- The worst methods in terms of RMSE value, in comparison with the reference method AR(1), are: KNN utilizing 11 input data and IT2FLS; for IT2FLS, the use of five input data instead of four last time-lagged values of variables of time series being forecast allowed us to decrease RMSE error.
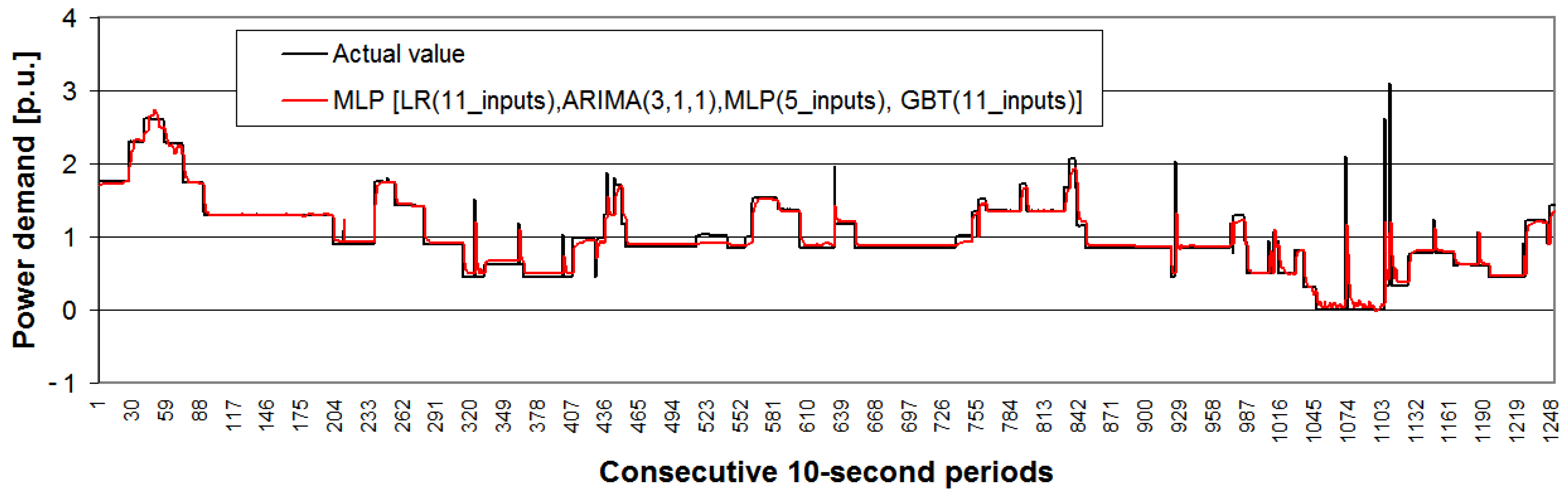
- The best ensemble methods are: MLP, GBT and LR as an integrator of ensemble; for GBT, it is more useful to utilize all 11 input data;
- GBT ensemble method seems to be more useful than MLP as an integrator of ensemble because of the greater simplicity of the method (no necessity to integrate four different method types), in which the ensemble is an internal algorithm component (single decision trees);
- All ensemble methods have smaller RMSE errors than the reference method AR(1);
- Among ensemble methods, only the last four ones in the ranking (as integrators of ensemble) have a greater RMSE error than the best single method, i.e., LR(6); it suggests that using an ensemble method (except for the last four ones) is justified in this forecasting exercise and allows us to decrease RMSE error in comparison with single methods;
- As for the KNN single method, using KNN as an integrator of ensemble resulted in the smallest MAPE and sMAPE errors of all tested ensemble methods, at the same time the RMSE error for the method is significant in comparison with the best ensemble methods;
- WAE_RMSE ensemble method is more useful than WAE_R/RMSE ensemble method;
- RF is the worst of all ensemble methods.
7. Conclusions
- (1)
- The fact that the two time series being forecast are untypical ones means that achieving significantly smaller RMSE errors than in the case of the reference method AR(1) is difficult, but the studies carried out show that it is possible. For time series No. 1, improvement in comparison with the AR(1) method is equal to 10.94%, whereas for time series No. 2, improvement reaches 19.00% for the best methods being tested.
- (2)
- For both time series, the validity of using a vast majority of ensemble methods in comparison with single methods has been demonstrated. It is necessary to pay attention to the great complexity of such methods, their time demand as well as very small differences in RMSE error value for the best eight ensemble methods for both forecast time series.
- (3)
- RF is the worst performing ensemble method in both time series, thus this technique of machine learning should not be preferred as an ensemble method for this forecasting exercise.
- (4)
- Very small MAPE and sMAPE errors for the KNN method, used as a single method or applied as an integrator of ensemble, together with quite large RMSE error at the same time, is a characteristic and recurring phenomenon.
- (5)
- The impact of proper selection of input data varies from case to case; some methods achieved smaller RMSE errors with the use of 5 input data, whereas other methods performed better with the use of 11 input data, depending on time series being forecast, the exception being the GBT method, for which it was more useful to utilize all 11 input data.
- (6)
- For both time series, it was better to use the criterion of the least RMSE errors for selection of the four most beneficial predictors used for constructing the ensemble methods, as well as the rule of dissimilarity of predictor action, rather than to use an additional criterion of the biggest differences in rests from forecasts obtained with the use of methods being candidates to the ensemble.
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
Abbreviation
| ACF | Autocorrelation Function |
| APN AE | Access Point Name Absolute Error |
| EIASC | Enhanced iterative algorithm with stop condition |
| ANN | Artificial Neural Network |
| AR | Autoregressive model |
| ARIMA | Autoregressive Integrated Moving Average |
| BFGS | Broyden–Fletcher–Goldfarb–Shanno algorithm |
| EKM | Enhanced Karnik–Mendel |
| FLS | Fuzzy Logic System |
| GA | Genetic Algorithm |
| GBT | Gradient Boosted Trees |
| IASC | Iterative algorithm with stop condition |
| IT2FLS | Interval Type-2 Fuzzy Logic System |
| KM | Karnik–Mendel |
| KNN | K-Nearest Neighbors |
| MAE | Mean Absolute Error |
| MAPE | Mean Absolute Percentage Error |
| MBE | Mean Bias Error |
| ML MLP | Machine Learning Multi-Layer Perceptron |
| MaxAE | Maximum Absolute Error |
| LR | Linear Regression |
| PACF | Partial Autocorrelation Function |
| PSO | Particle Swarm Optimization |
| R | Pearson linear correlation coefficient |
| R2 | Determination coefficient |
| RBF | Radial Base Function |
| RF | Random Forest |
| RMSE | Root Mean Square Error |
| sMAPE | Symmetric Mean Absolute Percentage Error |
| SVM | Support Vector Machine |
| SVR | Support Vector Regression |
Appendix A

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Method Code | Description of Method, Name and Range of Values of Hyperparameters Tuning and Selected Values | Method for Hyperparameter Tuning |
|---|---|---|
| ARIMA(5,1,1) | The number of time lags p, range: 1–8, selected: 5, degree of differencing d, range: 1–3, selected: 1, order of the moving-average q, range 1–3, selected: 1. | Manual, based on ACF and PACF results |
| SVR(11_inputs) | Regression SVM: Type-1, Type 2, selected: Type-1, kernel type: Gaussian (RBF), width parameter σ: 0.077, regularization constant C, range: 1–20 (step 1), selected: 2, tolerance ε, range: 0.05–2 (step 0.05), selected: 0.1. | Grid search using cross-validation |
| SVR(5_inputs) | Regression SVM: Type-1, Type 2, selected: Type-1, kernel type: Gaussian (RBF), width parameter σ: 0.200, regularization constant C, range: 1–20 (step 1), selected: 3, tolerance ε, range: 0.05–2 (step 0.05), selected: 0,1. | Grid search using cross-validation |
| KNN(11_inputs) | Distance metrics: Euclidean, Manhattan, Minkowski, selected: Euclidean, number of nearest neighbors k, range: 1–50, selected: 9. | Grid search using cross-validation |
| KNN(5_inputs) | Distance metrics: Euclidean, Manhattan, Minkowski, selected: Euclidean, number of nearest neighbors k, range: 1–50, selected: 12. | Grid search using cross-validation |
| MLP(11_inputs) | The number of neurons in hidden layer: 5–20, selected: 13, learning algorithm: BFGS, activation function in hidden layer: linear, hyperbolic tangent, selected: hyperbolic tangent, activation function in output layer: linear. | Manual, supported by cross-validation |
| MLP(5_inputs) | The number of neurons in hidden layer: 5–20, selected: 4, learning algorithm: BFGS, activation function in hidden layer: linear, hyperbolic tangent, selected: hyperbolic tangent, activation function in output layer: linear. | Manual, supported by cross-validation |
| IT2FLS(4_inputs) | Interval Type-2 Sugeno FLS, learning and tuning algorithm: GA, PSO, selected: PSO, initial swarm span: 1500–3000, selected: 1500, minimum neighborhood size: 0.20–0.30, selected: 0.20, inertia range: from [0.10–1.10] to [0.20–2.20], selected: [0.15–1.50], number of iterations in the learning and tuning process: 5–20, selected: 12, type of the membership functions: triangular, Gauss, selected: triangular, the number of output membership functions: 3–81, selected: 81, window size for computing average validation cost: 4–7, selected: 5, maximum allowable increase in validation cost: 0.0–1.0, selected: 0.1, the type-reduction methods: KM, EKM, IASC, EIASC, selected: KM. | Manual, supported by cross-validation |
| IT2FLS(5_inputs) | Interval Type-2 Sugeno FLS, learning and tuning algorithm: GA, PSO, selected: PSO, initial swarm span: 1500–3000, selected: 1500, minimum neighborhood size: 0.20–0.30, selected: 0.20, inertia range: from [0.10–1.10] to [0.20–2.20], selected: [0.15–1.50], number of iterations in learning and tuning process: 5–20, selected: 12, type of the membership functions: triangular, Gauss, selected: triangular, number of output membership functions: 3–243, selected: 243, window size for computing average validation cost: 4–7, selected: 5, maximum allowable increase in cost: 0.0–1.0, selected: 0.1, the type-reduction methods: KM, EKM, IASC, EIASC, selected: KM. | Manual, supported by cross-validation |
| Method Code | Description of Method, Name and Range of Values of Hyperparameters Tuning and Selected Values | Method for Hyperparameter Tuning |
|---|---|---|
| RF(6/12) | The number of predictors chosen at random: 6, number of decision trees: 1–500, selected: 352. Stop parameters: maximum number of levels in each decision tree: 10, minimum number of data points placed in a node before the node is split: 200, min number of data points allowed in a leaf node: 5, maximum number of nodes: 100. | Grid search using cross-validation |
| RF(10/12) | The number of predictors chosen at random: 10, number of decision trees: 1–500, selected: 421. Stop parameters: maximum number of levels in each decision tree: 10, minimum number of data points placed in a node before the node is split: 200, min number of data points allowed in a leaf node: 5, maximum number of nodes: 100. | Grid search using cross-validation |
| GBT(11_inputs) | The learning rate: 0.05, 0.1, 0.5, selected: 0.1, number of decision trees: 1–500, selected: 461. Stop parameters: maximum number of levels in each decision tree: 5, minimum number of data points placed in a node before the node is split: 200, min number of data points allowed in a leaf node: 3, maximum number of nodes: 3. | Grid search using cross-validation, early stopping |
| GBT(5_inputs) | The learning rate: 0.05, 0.1, 0.5, selected: 0.1, number of decision trees: 1–500, selected: 440. Stop parameters: maximum number of levels in each decision tree: 5, minimum number of data points placed in a node before the node is split: 200, min number of data points allowed in a leaf node: 3, maximum number of nodes: 3. | Grid search using cross-validation, early stopping |
| MLP [LR(11_inputs), RF(6/12), MLP(11_inputs), GBT(11_inputs)] | The number of neurons in hidden layer: 3–10, selected: 7, learning algorithm: BFGS, activation function in hidden layer: linear, hyperbolic tangent, selected: linear, activation function in output layer: linear. | Manual, supported by cross-validation |
| KNN [LR(11_inputs), RF(6/12), MLP(11_inputs), GBT(11_inputs)] | Distance metrics: Euclidean, Manhattan, Minkowski, selected: Euclidean, number of nearest neighbors k, range: 1–50, selected: 12. | Grid search using cross-validation |
| RF [LR(11_inputs), RF(6/12), MLP(11_inputs), GBT(11_inputs)] | The number of predictors by random choice: 3 from 4, number of decision trees: 1–400, selected: 241. Stop parameters: maximum number of levels in each decision tree: 10, minimum number of data points placed in a node before the node is split: 200, min number of data points allowed in a leaf node: 5, maximum number of nodes: 100. | Grid search using cross-validation |
| Method Code | Description of Method, the Name and the Range of Values of Hyperparameters Tuning and Selected Values | Method for Hyperparameters Tuning |
|---|---|---|
| ARIMA(3,1,1) | The number of time lags p, range: 1–8, selected: 3, degree of differencing d, range: 1–3, selected: 1, order of the moving-average q, range 1–3, selected: 1. | Manual, based on ACF and PACF results |
| SVR(11_inputs) | Regression SVM: Type-1, Type 2, selected: Type-1, kernel type: Gaussian (RBF), width parameter σ: 0.833, regularization constant C, range: 1–20 (step 1), selected: 7, tolerance ε, range: 0.05–2 (step 0.05), selected: 0,1. | Grid search using cross-validation |
| SVR(5_inputs) | Regression SVM: Type-1, Type 2, selected: Type-1, kernel type: Gaussian (RBF), width parameter σ: 0.200, regularization constant C, range: 1–20 (step 1), selected: 8, tolerance ε, range: 0.05–2 (step 0.05), selected: 0,1. | Grid search using cross-validation |
| KNN(11_inputs) | Distance metrics: Euclidean, Manhattan, Minkowski, selected: Euclidean, number of nearest neighbors k, range: 1–50, selected: 29. | Grid search using cross-validation |
| KNN(5_inputs) | Distance metrics: Euclidean, Manhattan, Minkowski, selected: Euclidean, number of nearest neighbors k, range: 1–50, selected: 14. | Grid search using cross-validation |
| MLP(11_inputs) | The number of neurons in hidden layer: 5–20, selected: 13, learning algorithm: BFGS, activation function in hidden layer: linear, hyperbolic tangent, selected: hyperbolic tangent, activation function in output layer: linear. | Manual, supported by cross-validation |
| MLP(5_inputs) | The number of neurons in hidden layer: 5–20, selected: 4, learning algorithm: BFGS, activation function in hidden layer: linear, hyperbolic tangent, selected: hyperbolic tangent, activation function in output layer: linear. | Manual, supported by cross-validation |
| IT2FLS(4_inputs) | Interval Type-2 Sugeno FLS, learning and tuning algorithm: GA, PSO, selected: PSO, initial swarm span: 1500–3000, selected: 1500, minimum neighborhood size: 0.20–0.30, selected: 0.20, inertia range: from [0.10–1.10] to [0.20–2.20], selected: [0.15–1.50], number of iterations in learning and tuning process: 5–20, selected: 12, type of the membership functions: triangular, Gauss, selected: triangular, number of output membership functions: 3–81, selected: 81, window size for computing average validation cost: 4–7, selected: 5, maximum allowable increase in validation cost: 0.0–1.0, selected: 0.1, type-reduction methods: KM, EKM, IASC, EIASC, selected: KM. | Manual, supported by cross-validation |
| IT2FLS(5_inputs) | Interval Type-2 Sugeno FLS, learning and tuning algorithm: GA, PSO, selected: PSO, initial swarm span: 1500–3000, selected: 1500, number of iterations in learning and tuning process: 5–20, selected: 12, minimum neighborhood size: 0.20–0.30, selected: 0.20, inertia range: from [0.10–1.10] to [0.20–2.20], selected: [0.15–1.50], type of the membership functions: triangular, Gauss, selected: triangular, number of the output membership functions: 3–243, selected: 243, window size for computing average validation cost: 4–7, selected: 5, maximum allowable increase in validation cost: 0.0–1.0, selected: 0.1, type-reduction methods: KM, EKM, IASC, EIASC, selected: KM. | Manual, supported by cross-validation |
| Method Code | Description of Method, the Name and the Range of Values of Hyperparameters Tuning and Selected Values | Method for Hyperparameters Tuning |
|---|---|---|
| RF (6/12) | The number of predictors chosen at random: 6, number of decision trees: 1–500, selected: 245. Stop parameters: maximum number of levels in each decision tree: 10, minimum number of data points placed in a node before the node is split: 200, min number of data points allowed in a leaf node: 5, maximum number of nodes: 100. | Grid search using cross-validation |
| RF (10/12) | The number of predictors chosen at random: 10, number of decision trees: 1–500, selected: 281. Stop parameters: maximum number of levels in each decision tree: 10, minimum number of data points placed in a node before the node is split: 200, min number of data points allowed in a leaf node: 5, maximum number of nodes: 100. | Grid search using cross-validation |
| GBT (11_inputs) | The learning rate: 0.05, 0.1, 0.5, selected: 0.1, number of decision trees: 1–500, selected: 392. Stop parameters: maximum number of levels in each decision tree: 5, minimum number of data points placed in a node before the node is split: 200, min number of data points allowed in a leaf node: 3, maximum number of nodes: 3. | Grid search using cross-validation, early stopping |
| GBT (5_inputs) | The learning rate: 0.05, 0.1, 0.5, selected: 0.1, number of decision trees: 1–500, selected: 448. Stop parameters: maximum number of levels in each decision tree: 5, minimum number of data points placed in a node before the node is split: 200, min number of data points allowed in a leaf node: 3, maximum number of nodes: 3. | Grid search using cross-validation, early stopping |
| MLP [LR(11_inputs), ARIMA(3,1,1), MLP(5_inputs), GBT(11_inputs)] | The number of neurons in hidden layer: 3–10, selected: 8, learning algorithm: BFGS, activation function in hidden layer: linear, hyperbolic tangent, selected: hyperbolic tangent, activation function in output layer: linear. | Manual, supported by cross-validation |
| KNN [LR(11_inputs), ARIMA(3,1,1), MLP(5_inputs), GBT(11_inputs)] | Distance metrics: Euclidean, Manhattan, Minkowski, selected: Euclidean, number of nearest neighbors k, range: 1–50, selected: 11. | Grid search using cross-validation |
| RF [LR(11_inputs), ARIMA(3,1,1), MLP(5_inputs), GBT(11_inputs)] | The number of predictors chosen at random: 3 from 4, number of decision trees: 1–400, selected: 243. Stop parameters: maximum number of levels in each decision tree: 10, minimum number of data points placed in a node before the node is split: 200, min number of data points allowed in a leaf node: 5, maximum number of nodes: 100. | Grid search using cross-validation |
References
- Microgrids 1: Engineering, Economics, & Experience—Capabilities, Benefits, Business Opportunities, and Examples—Microgrids Evolution Roadmap; Study Committee: C6, CIGRÉ Working Group C6.22, Technical Brochure 635; CIGRE: Paris, France, 2015.
- Marnay, C.; Chatzivasileiadis, S.; Abbey, C.; Iravani, R.; Joos, G.; Lombardi, P.; Mancarella, P.; von Appen, J. Microgrid evolution roadmap. Engineering, economics, and experience. In Proceedings of the 2015 Int. Symp. on Smart Electric Distribution Sys-tems and Technologies (EDST15); CIGRE SC C6 Colloquium, Vienna, Austria, 8–11 September 2015. [Google Scholar]
- Hatziargyriou, N.D. (Ed.) Microgrids: Architectures and Control; Wiley-IEEE Press: Hoboken, NJ, USA, 2014. [Google Scholar]
- Low Voltage Microgrids. Joint Publication Edited by Mirosław Parol; Publishing House of the Warsaw University of Technology: Warsaw, Poland, 2013. (In Polish)
- Li, Y.; Nejabatkhah, F. Overview of control, integration and energy management of microgrids. J. Mod. Power Syst. Clean Energy 2014, 2, 212–222. [Google Scholar] [CrossRef] [Green Version]
- Olivares, D.E.; Canizares, C.A.; Kazerani, M. A Centralized Energy Management System for Isolated Microgrids. IEEE Trans. Smart Grid 2014, 5, 1864–1875. [Google Scholar] [CrossRef]
- Han, Y.; Zhang, K.; Li, H.; Coelho, E.A.A.; Guerrero, J.M. MAS-Based Distributed Coordinated Control and Optimization in Microgrid and Microgrid Clusters: A Comprehensive Overview. IEEE Trans. Power Electron. 2018, 33, 6488–6508. [Google Scholar] [CrossRef] [Green Version]
- Morstyn, T.; Hredzak, B.; Agelidis, V.G. Control strategies for microgrids with distributed energy storage systems: An over-view. IEEE Trans. Smart Grid 2018, 9, 3652–3666. [Google Scholar] [CrossRef] [Green Version]
- Li, Q.; Peng, C.; Chen, M.; Chen, F.; Kang, W.; Guerrero, J.M.; Abbott, D. Networked and Distributed Control Method With Optimal Power Dispatch for Islanded Microgrids. IEEE Trans. Ind. Electron. 2016, 64, 493–504. [Google Scholar] [CrossRef] [Green Version]
- Parol, R.; Parol, M.; Rokicki, Ł. Implementation issues concerning optimal operation control algorithms in low voltage mi-crogrids. In Proceedings of the 5th Int. Symp. on Electrical and Electronics Engineering (ISEEE-2017), Galati, Romania, 20–22 October 2017; pp. 1–7. [Google Scholar]
- Lopes, J.A.P.; Moreira, C.L.; Madureira, A.G. Defining Control Strategies for MicroGrids Islanded Operation. IEEE Trans. Power Syst. 2006, 21, 916–924. [Google Scholar] [CrossRef] [Green Version]
- Zhao, H.; Wu, Q.; Wang, C.; Cheng, L.; Rasmussen, C.N. Fuzzy logic based coordinated control of battery energy storage system and dispatchable distributed generation for microgrid. J. Mod. Power Syst. Clean Energy 2015, 3, 422–428. [Google Scholar] [CrossRef] [Green Version]
- Parol, M.; Rokicki, Ł.; Parol, R. Towards optimal operation control in rural low voltage microgrids. Bull. Pol. Ac. Tech. 2019, 67, 799–812. [Google Scholar]
- Parol, M.; Kapler, P.; Marzecki, J.; Parol, R.; Połecki, M.; Rokicki, Ł. Effective approach to distributed optimal operation con-trol in rural low voltage microgrids. Bull. Pol. Ac. Tech. 2020, 68, 661–678. [Google Scholar]
- Niu, D.; Pu, D.; Dai, S. Ultra-Short-Term Wind-Power Forecasting Based on the Weighted Random Forest Optimized by the Niche Immune Lion Algorithm. Energies 2018, 11, 1098. [Google Scholar] [CrossRef] [Green Version]
- Bokde, N.; Feijóo, A.; Villanueva, D.; Kulat, K. A Review on Hybrid Empirical Mode Decomposition Models for Wind Speed and Wind Power Prediction. Energies 2019, 12, 254. [Google Scholar] [CrossRef] [Green Version]
- Adnan, R.M.; Liang, Z.; Yuan, X.; Kisi, O.; Akhlaq, M.; Li, B. Comparison of LSSVR, M5RT, NF-GP, and NF-SC Models for Predictions of Hourly Wind Speed and Wind Power Based on Cross-Validation. Energies 2019, 12, 329. [Google Scholar] [CrossRef] [Green Version]
- Würth, I.; Valldecabres, L.; Simon, E.; Möhrlen, C.; Uzunoğlu, B.; Gilbert, C.; Giebel, G.; Schlipf, D.; Kaifel, A. Minute-Scale Forecasting of Wind Power—Results from the Collaborative Workshop of IEA Wind Task 32 and 36. Energies 2019, 12, 712. [Google Scholar] [CrossRef] [Green Version]
- Liu, F.; Li, R.; Dreglea, A. Wind Speed and Power Ultra Short-Term Robust Forecasting Based on Takagi–Sugeno Fuzzy Model. Energies 2019, 12, 3551. [Google Scholar] [CrossRef] [Green Version]
- Sun, S.; Fu, J.; Li, A. A Compound Wind Power Forecasting Strategy Based on Clustering, Two-Stage Decomposition, Parameter Optimization, and Optimal Combination of Multiple Machine Learning Approaches. Energies 2019, 12, 3586. [Google Scholar] [CrossRef] [Green Version]
- Son, N.; Yang, S.; Na, J. Hybrid Forecasting Model for Short-Term Wind Power Prediction Using Modified Long Short-Term Memory. Energies 2019, 12, 3901. [Google Scholar] [CrossRef] [Green Version]
- Zheng, H.; Wu, Y. A XGBoost Model with Weather Similarity Analysis and Feature Engineering for Short-Term Wind Power Forecasting. Appl. Sci. 2019, 9, 3019. [Google Scholar] [CrossRef] [Green Version]
- Mujeeb, S.; Alghamdi, T.A.; Ullah, S.; Fatima, A.; Javaid, N.; Saba, T. Exploiting Deep Learning for Wind Power Forecasting Based on Big Data Analytics. Appl. Sci. 2019, 9, 4417. [Google Scholar] [CrossRef] [Green Version]
- Wang, K.; Niu, D.; Sun, L.; Zhen, H.; Liu, J.; De, G.; Xu, X. Wind Power Short-Term Forecasting Hybrid Model Based on CEEMD-SE Method. Process. 2019, 7, 843. [Google Scholar] [CrossRef] [Green Version]
- Valldecabres, L.; Nygaard, N.G.; Vera-Tudela, L.; von Bremen, L.; Kühn, M. On the Use of Dual-Doppler Radar Measurements for Very Short-Term Wind Power Forecasts. Remote Sens. 2018, 10, 1701. [Google Scholar] [CrossRef] [Green Version]
- Zhao, H.; Zhao, H.; Guo, S. Short-Term Wind Electric Power Forecasting Using a Novel Multi-Stage Intelligent Algorithm. Sustainability 2018, 10, 881. [Google Scholar] [CrossRef] [Green Version]
- Zhou, J.; Yu, X.; Jin, B. Short-Term Wind Power Forecasting: A New Hybrid Model Combined Extreme-Point Symmetric Mode Decomposition, Extreme Learning Machine and Particle Swarm Optimization. Sustainability 2018, 10, 3202. [Google Scholar] [CrossRef] [Green Version]
- Fu, C.; Li, G.Q.; Lin, K.P.; Zhang, H.J. Short-Term Wind Power Prediction Based on Improved Chicken Algorithm Optimiza-tion Support Vector Machine. Sustainability 2019, 11, 512. [Google Scholar] [CrossRef] [Green Version]
- Meng, X.; Wang, R.; Zhang, X.; Wang, M.; Ma, H.; Wang, Z. Hybrid Neural Network Based on GRU with Uncertain Factors for Forecasting Ultra-short-term Wind Power. In Proceedings of the 2020 2nd International Conference on Industrial Artificial Intelligence (IAI), Shenyang, China, 23–25 October 2020. [Google Scholar]
- Carpinone, A.; Giorgio, M.; Langella, R.; Testa, A. Markov chain modeling for very-short-term wind power forecasting. Electr. Power Syst. Res. 2015, 122, 152–158. [Google Scholar] [CrossRef] [Green Version]
- Tato, J.H.; Brito, M.C. Using Smart Persistence and Random Forests to Predict Photovoltaic Energy Production. Energies 2018, 12, 100. [Google Scholar] [CrossRef] [Green Version]
- Zhu, R.; Guo, W.; Gong, X. Short-Term Photovoltaic Power Output Prediction Based on k-Fold Cross-Validation and an En-semble Model. Energies 2019, 12, 1220. [Google Scholar]
- Xie, T.; Zhang, G.; Liu, H.; Liu, F.; Du, P. A Hybrid Forecasting Method for Solar Output Power Based on Variational Mode Decomposition, Deep Belief Networks and Auto-Regressive Moving Average. Appl. Sci. 2018, 8, 1901. [Google Scholar] [CrossRef] [Green Version]
- Abdullah, N.A.; Rahim, N.A.; Gan, C.K.; Adzman, N.N. Forecasting Solar Power Using Hybrid Firefly and Particle Swarm Optimization (HFPSO) for Optimizing the Parameters in a Wavelet Transform-Adaptive Neuro Fuzzy Inference System (WT-ANFIS). Appl. Sci. 2019, 9, 3214. [Google Scholar] [CrossRef] [Green Version]
- Nespoli, A.; Mussetta, M.; Ogliari, E.; Leva, S.; Fernández-Ramírez, L.; García-Triviño, P. Robust 24 Hours ahead Forecast in a Microgrid: A Real Case Study. Electronics 2019, 8, 1434. [Google Scholar] [CrossRef] [Green Version]
- Huang, J.; Boland, J. Performance Analysis for One-Step-Ahead Forecasting of Hybrid Solar and Wind Energy on Short Time Scales. Energies 2018, 11, 1119. [Google Scholar] [CrossRef] [Green Version]
- Dudek, G. Short-Term Load Forecasting Using Random Forests. In Intelligent Systems’2014. Advances in Intelligent Systems and Computing; Filev, D., Ed.; Springer: Berlin/Heidelberg, Germany, 2015; Volume 323, pp. 821–828. [Google Scholar]
- Kim, C.; Yu, I.; Song, Y.H. Kohonen neural network and wavelet transform based approach to short-term load fore-casting. Electr. Power Syst. Res. 2002, 63, 169–176. [Google Scholar] [CrossRef]
- Dudek, G. Pattern-based local linear regression models for short-term load forecasting. Electr. Power Syst. Res. 2016, 130, 139–147. [Google Scholar] [CrossRef]
- Shamsollahi, P.; Cheung, K.W.; Chen, Q.; Germain, E.H. A neural network based very short term load forecaster for the interim ISO New England electricity market system. In Proceedings of the 2001 Power Industry Computer Applications Conf., Sydney, Australia, 20–24 May 2001; pp. 217–222. [Google Scholar]
- Parol, M.; Piotrowski, P. Very short-term load forecasting for optimum control in microgrids. In Proceedings of the 2nd International Youth Conference on Energetics (IYCE 2009), Budapest, Hungary, 4–6 June 2009; pp. 1–6. [Google Scholar]
- Parol, M.; Piotrowski, P. Electrical energy demand forecasting for 15 minutes forward for needs of control in low voltage electrical networks with installed sources of distributed generation. Przegląd Elektrotechniczny (Electr. Rev.) 2010, 86, 303–309. (In Polish) [Google Scholar]
- Hernandez, L.; Baladron, C.; Aguiar, J.M.; Carro, B.; Sanchez-Esguevillas, A.J.; Lloret, J.; Massana, J. A Survey on Electric Power Demand Forecasting: Future Trends in Smart Grids, Microgrids and Smart Buildings. IEEE Commun. Surv. Tutor. 2014, 16, 1460–1495. [Google Scholar] [CrossRef]
- Parol, M.; Piotrowski, P.; Piotrowski, M. Very short-term forecasting of power demand of big dynamics objects. E3S Web Conf. 2019, 84, 01007. [Google Scholar] [CrossRef]
- Ziegel, E.R.; Box, G.; Jenkins, G.; Reinsel, G. Time Series Analysis, Forecasting, and Control. Technometrics 1995, 37, 238. [Google Scholar] [CrossRef]
- Brockwell, P.J.; Davis, R.A. Introduction to Time Series and Forecasting; Springer: Berlin/Heidelberg, Germany, 2016. [Google Scholar]
- Shumway, R.H.; Stoffer, D.S. Time Series Analysis and Its Applications: With R Examples, 4th ed.; Springer: Berlin/Heidelberg, Germany, 2017. [Google Scholar]
- Rojas, I.; Pomares, H.; Valenzuela, O. (Eds.) Time Series Analysis and Forecasting. Selected Contributions from ITISE 2017; Springer: Berlin/Heidelberg, Germany, 2018. [Google Scholar]
- Géron, A. Hands-on Machine Learning with Scikit-Learn, Keras, and TensorFlow, 2nd ed.; O’Reilly Media, Inc.: Sevastopol, CA, USA, 2019. [Google Scholar]
- Osowski, S.; Siwek, K. Local dynamic integration of ensemble in prediction of time series. Bull. Pol. Acad. Tech. 2019, 67, 517–525. [Google Scholar]
- Piotrowski, P.; Baczyński, D.; Kopyt, M.; Szafranek, K.; Helt, P.; Gulczyński, T. Analysis of forecasted meteorological data (NWP) for efficient spatial forecasting of wind power generation. Electr. Power Syst. Res. 2019, 175, 105891. [Google Scholar] [CrossRef]
- Dudek, G. Multilayer perceptron for short-term load forecasting: From global to local approach. Neural Comput. Appl. 2019, 32, 3695–3707. [Google Scholar] [CrossRef] [Green Version]
- Karnik, N.; Mendel, J.; Liang, Q. Type-2 fuzzy logic systems. IEEE Trans. Fuzzy Syst. 1999, 7, 643–658. [Google Scholar] [CrossRef] [Green Version]
- Karnik, N.N.; Mendel, J.M. Centroid of a type-2 fuzzy set. Inf. Sci. 2001, 132, 195–220. [Google Scholar] [CrossRef]
- Mendel, J.; John, R. Type-2 fuzzy sets made simple. IEEE Trans. Fuzzy Syst. 2002, 10, 117–127. [Google Scholar] [CrossRef]
- Khosravi, A.; Nahavandi, S.; Creighton, D.; Srinivasan, D. Interval Type-2 Fuzzy Logic Systems for Load Forecasting: A Comparative Study. IEEE Trans. Power Syst. 2012, 27, 1274–1282. [Google Scholar] [CrossRef]
- Liang, Q.; Mendel, J.M. Interval type-2 fuzzy logic systems: Theory and design. IEEE Trans. Fuzzy Syst. 2000, 8, 535–550. [Google Scholar] [CrossRef] [Green Version]
- Kam, H.T. The Random Subspace Method for Constructing Decision Forests. IEEE Trans. Pattern Anal. 1998, 20, 832–844. [Google Scholar]
- Berk, R.A. Statistical Learning from a Regression Perspective, 3rd ed.; Springer: Berlin/Heidelberg, Germany, 2020. [Google Scholar]
- Abbasi, R.A.; Javaid, N.; Ghuman, M.N.J.; Khan, Z.A.; Ur Rehman, S. Amanullah Short Term Load Forecasting Using XGBoost. In Web, Artificial Intelligence and Network Applications. WAINA 2019. Advances in Intelligent Systems and Computing; Barolli, L., Takizawa, M., Xhafa, F., Enokido, T., Eds.; Springer: Berlin/Heidelberg, Germany, 2019; Volume 927. [Google Scholar]
- Wang, W.; Shi, Y.; Lyu, G.; Deng, W. Electricity Consumption Prediction Using XGBoost Based on Discrete Wavelet Transform. In Proceedings of the 2017 2nd International Conference on Artificial Intelligence and Engineering Applications (AIEA 2017), Guilin, China, 23–24 September 2017; pp. 716–729. [Google Scholar]
- Friedman, J.H. Stochastic gradient boosting. Comput. Stat. Data Anal. 2002, 38, 367–378. [Google Scholar] [CrossRef]
- Hastie, T.; Tibshirani, R.; Friedman, J.H. The elements of Statistical Learning. Data Mining, Inference, and Prediction, 2nd ed.; Springer: Berlin/Heidelberg, Germany, 2009. [Google Scholar]
- Alpaydin, E. Introduction to Machine Learning, 4th ed.; MIT Press: Cambridge, MA, USA, 2020. [Google Scholar]













| Statistical Measures | Time Series No. 1 | Time Series No. 2 |
|---|---|---|
| Max power [p.u.] | 5.7789 | 4.6195 |
| Min power [p.u.] | 0.0032 | 0.0024 |
| The ratio of maximum power to minimum power | 1806 | 1925 |
| The biggest power ratio between two consecutive 10 s periods [%] | 848 | 1401 |
| Average power [p.u.] | 1 | 1 |
| Median [p.u.] | 0.8580 | 0.9572 |
| Standard deviation [p.u.] | 0.7150 | 0.4867 |
| Variance [-] | 0.5112 | 0.2369 |
| Coefficient of variation [%] | 71.4952 | 48.6662 |
| Skewness [-] | 0.2363 | 0.3138 |
| Kurtosis [-] | −0.3084 | 1.1299 |
| Code of Variable | Potential Explanatory Variables Considered | Pearson Linear Correlation Coefficient | |
|---|---|---|---|
| Time Series No. 1 | Time Series No. 2 | ||
| POW1 | 10 s power demand in period t − 1 | 0.9464 | 0.9100 |
| POW2 | 10 s power demand in period t − 2 | 0.9114 | 0.8868 |
| POW3 | 10 s power demand in period t − 3 | 0.8999 | 0.8707 |
| POW4 | 10 s power demand in period t − 4 | 0.8882 | 0.8538 |
| POW5 | 10 s power demand in period t − 5 | 0.8773 | 0.8412 |
| POW6 | 10 s power demand in period t − 6 | 0.8657 | 0.8234 |
| POW7 | 10 s power demand in period t − 7 | 0.8539 | 0.8092 |
| PEAK1 | 10 s power demand in period t- first_peak, where first_peak is 150 (the first time series), and first_peak is 180 (for the second time series) | 0.439 | 0.400 |
| FUNC | 24 h profile of the variation of power demand—the value of the polynomial function of degree 8 of power demand in a given hour | 0.374 | 0.510 |
| HOUR | The hour (number from the range 1–24) of power demand | 0.0070 | 0.0061 |
| AVE3 | Average value of power demand from periods t − 1, t − 2, and t − 3 | 0.9402 | 0.9199 |
| AVE2 | Average value of power demand from periods t − 1, and t − 2 | 0.9418 | 0.9195 |
| AVEW | Sum of power demand values for period t − 1 with the weight w1, and period t − 2 with weight w2, where w1 is 0.841, w2 is 0.159 (for the first time series), and w1 is 0.636, w2 is 0.364 (for the second time series). | 0.9478 | 0.9211 |
| Method of Selection | Codes of All 13 Potential Explanatory Variables | ||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| PEAK1 | FUNC | HOUR | AVEW | AVE3 | AVE2 | POW1 | POW2 | POW3 | POW4 | POW5 | POW6 | POW7 | |
| 1-Stepwise forward regression | + | + | − | + | + | + | + | + | + | + | + | + | + |
| 2-Stepwise backward regression | + | + | − | + | + | + | + | + | + | + | + | + | + |
| 3-Sensitivity analysis | + | + | − | + | + | + | + | + | + | + | + | + | + |
| 4-Genetic algorithm | + | − | − | + | + | + | + | + | + | + | − | + | + |
| 5a-Graph analysis (strict selection) | + | + | − | + | − | − | − | − | − | − | − | − | − |
| 5b-Graph analysis (inaccurate selection) | + | + | − | + | + | + | + | − | − | − | − | − | − |
| 6-Analysis of variances | − | − | − | + | + | + | + | + | + | + | + | + | + |
| Summary—the number of indications | 6 | 5 | 0 | 7 | 6 | 6 | 6 | 5 | 5 | 5 | 4 | 5 | 5 |
| Method of Selection | Codes of All 13 Potential Explanatory Variables | ||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| PEAK1 | FUNC | HOUR | AVEW | AVE3 | AVE2 | POW1 | POW2 | POW3 | POW4 | POW5 | POW6 | POW7 | |
| 1-Stepwise forward regression | − | + | − | + | + | + | + | + | + | + | + | + | + |
| 2-Stepwise backward regression | + | + | + | + | + | + | + | + | + | + | + | + | + |
| 3-Sensitivity analysis | − | − | − | + | + | + | + | + | + | + | + | − | − |
| 4-Genetic algorithm | + | + | + | + | + | − | + | + | + | + | − | − | + |
| 5a-Graph analysis (strict selection) | + | + | − | + | − | − | − | − | − | − | − | − | − |
| 5b-Graph analysis (inaccurate selection) | + | + | − | + | + | + | + | − | − | − | − | − | − |
| 6-Analysis of variances | − | − | − | + | + | + | + | + | + | + | + | + | + |
| Summary—the number of indications | 4 | 5 | 2 | 7 | 6 | 6 | 6 | 5 | 5 | 5 | 4 | 3 | 3 |
| Name of Method | Method Code | Category | Complexity (the Number of Predictors) | Type of Input Data |
|---|---|---|---|---|
| Autoregressive model | AR(1) | Linear/ parametric | Single | Time series |
| Autoregressive Integrated Moving Average | ARIMA(p,d,q) | Linear/ parametric | Single | Time series |
| Multiple Linear Regression model | LR | Linear/ parametric | Single | Time series and exogenous variables |
| Type MLP artificial neural network | MLP | Non-linear or linear/ parametric | Single | Time series and exogenous variables |
| Interval Type-2 Fuzzy Logic System | IT2FLS | Non-linear/ parametric | Single | Time series and exogenous variables |
| K-Nearest Neighbors | KNN | Non-linear/ non-parametric | Single | Time series and exogenous variables |
| Support Vector Regression | SVR | Non-linear/ non-parametric | Single | Time series and exogenous variables |
| Random Forest Regression | RF | Non-linear/ non-parametric | Ensemble | Time series and exogenous variables |
| Gradient Boosted Trees for regression | GBT | Non-linear/ non-parametric | Ensemble | Time series and exogenous variables |
| MLP as an Integrator of Ensemble | MLP [p1 *,…,p4] | Non-linear or linear/ parametric | Ensemble | Forecasts from 4 predictors |
| RF as an Integrator of Ensemble | RF [p1,...,p4] | Non-linear/ non-parametric | Ensemble | Forecasts from 4 predictors |
| KNN as an Integrator of Ensemble | KNN [p1,...,p4] | Non-linear or linear/ non-parametric | Ensemble | Forecasts from 4 predictors |
| LR as an Integrator of Ensemble | LR [p1,…,p4] | linear/ parametric | Ensemble | Forecasts from 4 predictors |
| Weighted Averaging Ensemble based on RMSE | WAE_RMSE [p1,…,pm] | Non-linear/ parametric | Ensemble | Forecasts from m predictors |
| Weighted Averaging Ensemble based on R and RMSE | WAE_R/RMSE [p1,..,p4] | Non-linear/ parametric | Ensemble | Forecasts from 4 predictors |
| Method Code | Input Data Codes | RMSE | MAE | MaxAE | R | MBE | MAPE [%] | sMAPE [%] |
|---|---|---|---|---|---|---|---|---|
| MLP(11_inputs) | PEAK1, FUNC, AVEW, AVE3, AVE2, POW1—POW6 | 0.2196 | 0.0641 | 3.0142 | 0.9454 | −0.0019 | 123.71 | 25.25 |
| LR(11_inputs) | PEAK1, FUNC, AVEW, AVE3, AVE2, POW1—POW6 | 0.2197 | 0.0638 | 3.0195 | 0.9454 | −0.0014 | 135.51 | 27.32 |
| LR(6_inputs) | PEAK1, POW1, POW2, POW3, POW5, POW7 (the choice based on backward stepwise regression from all input data) | 0.2198 | 0.0663 | 3.0201 | 0.9453 | 0.0009 | 134.20 | 27.31 |
| ARIMA(5,1,1) | POW1—POW5 | 0.2200 | 0.0640 | 3.0020 | 0.9455 | 0.0030 | 129.44 | 26.46 |
| MLP(5_inputs) | PEAK1, AVEW, AVE3, AVE2, POW1 | 0.2204 | 0.0733 | 2.9908 | 0.9450 | 0.0018 | 116.39 | 25.97 |
| IT2FLS(5_inputs) | PEAK1, AVEW, AVE3, AVE2, POW1 | 0.2321 | 0.0715 | 2.9976 | 0.9360 | −0.0035 | 204.83 | 33.29 |
| AR(1) | POW1 | 0.2332 | 0.0661 | 3.0214 | 0.9396 | 0.0199 | 143.23 | 29.40 |
| KNN(5_inputs) | PEAK1, AVEW, AVE3, AVE2, POW1 | 0.2347 | 0.0653 | 3.0036 | 0.9377 | 0.0160 | 94.15 | 14.94 |
| KNN(11_inputs) | PEAK1, FUNC, AVEW, AVE3, AVE2, POW1—POW6 | 0.2372 | 0.0908 | 3.0361 | 0.9376 | 0.0249 | 140.24 | 30.14 |
| SVR(5_inputs) | PEAK1, AVEW, AVE3, AVE2, POW1 (the choice based on initial selection from Table 3) | 0.2441 | 0.1278 | 3.0397 | 0.9425 | −0.0186 | 447.35 | 39.30 |
| SVR(11_inputs) | PEAK1, FUNC, AVEW, AVE3, AVE2, POW1—POW6 | 0.2510 | 0.1484 | 3.0087 | 0.9401 | −0.0914 | 462.63 | 41.21 |
| IT2FLS(4_inputs) | POW1-POW4 | 0.2936 | 0.0924 | 3.0033 | 0.9012 | 0.0191 | 167.17 | 22.03 |
| METHOD CODE | Input Data Codes | RMSE | MAE | MaxAE | R | MBE | MAPE [%] | sMAPE [%] |
|---|---|---|---|---|---|---|---|---|
| GBT(11_inputs) | PEAK1, FUNC, AVEW, AVE3, AVE2, POW1—POW6 | 0.2102 | 0.0591 | 2.9823 | 0.9501 | 0.0016 | 121.35 | 25.55 |
| LR [LR(11_inputs), RF(6/12), MLP(11_inputs), GBT(11_inputs)] | Different, it depends on predictor in ensemble * | 0.2126 | 0.0537 | 2.9968 | 0.9490 | 0.0034 | 108.63 | 24.50 |
| GBT (5_inputs) | PEAK1, AVEW, AVE3, AVE2, POW1 | 0.2134 | 0.0536 | 2.9967 | 0.9487 | 0.0047 | 97.75 | 22.81 |
| MLP [LR(11_inputs), RF(6/12), MLP(11_inputs, GBT(11_inputs)] | Different, it depends on predictor in ensemble | 0.2140 | 0.0526 | 3.0011 | 0.9483 | 0.0047 | 94.22 | 20.45 |
| WAE_RMSE [LR(11_inputs), RF(6/12), MLP(11_inputs), GBT(11_inputs)] | Different, it depends on predictor in ensemble | 0.2147 | 0.0587 | 3.0073 | 0.9479 | 0.0013 | 119.43 | 25.66 |
| WAE_RMSE [LR(11_inputs), MLP(11_inputs), GBT(11_inputs)] | Different, it depends on predictor in ensemble | 0.2147 | 0.0608 | 3.0054 | 0.9479 | −0.0006 | 126.71 | 26.09 |
| WAE_R/RMSE [KNN(5_inputs), RF(10/12), AR(1), GBT(11_inputs)] | Different, it depends on predictor in ensemble | 0.2181 | 0.0583 | 3.0004 | 0.9462 | 0.0066 | 111.85 | 25.29 |
| RF [LR(11_inputs), RF(6/12), MLP(11_inputs), GBT(11_inputs)] | Different, it depends on predictor in ensemble | 0.2185 | 0.0569 | 2.9998 | 0.9460 | 0.0047 | 79.20 | 18.41 |
| KNN [LR(11_inputs), RF(6/12), MLP(11_inputs), GBT(11_inputs)] | Different, it depends on predictor in ensemble | 0.2191 | 0.0583 | 3.0002 | 0.9458 | 0.0039 | 67.12 | 10.23 |
| RF(10/12) | For each tree random choice of 10 inputs from 12: PEAK1, FUNC, AVEW, AVE3, AVE2, POW1—POW7 | 0.2261 | 0.0582 | 3.0170 | 0.9421 | 0.0051 | 89.83 | 22.58 |
| RF(6/12) | For each tree random choice of 6 inputs from 12: PEAK1, FUNC, AVEW, AVE3, AVE2, POW1—POW7 | 0.2261 | 0.0567 | 3.0131 | 0.9421 | 0.0070 | 97.87 | 23.53 |
| Method Code | Input Data Codes | RMSE | MAE | MaxAE | R | MBE | MAPE [%] | sMAPE [%] |
|---|---|---|---|---|---|---|---|---|
| LR(6_inputs) | FUNC, AVE2, POW1, POW3, POW4, POW5 (the choice based on backward stepwise regression from all input data) | 0.1827 | 0.0652 | 2.5893 | 0.9318 | 0.0008 | 94.83 | 14.04 |
| LR(11_inputs) | PEAK1, FUNC, AVEW, AVE3, AVE2, POW1—POW6 | 0.1832 | 0.0658 | 2.6106 | 0.9314 | −0.0011 | 98.19 | 14.22 |
| ARIMA(3,1,1) | POW1—POW3 | 0.1841 | 0.0640 | 2.6843 | 0.9330 | −0.0001 | 96.08 | 13.96 |
| MLP(5_inputs) | FUNC, AVEW, AVE3, AVE2, POW1 | 0.1859 | 0.0686 | 2.7409 | 0.9293 | −0.0026 | 129.88 | 14.89 |
| MLP(11_inputs) | PEAK1, FUNC, AVEW, AVE3, AVE2, POW1—POW6 | 0.1861 | 0.0691 | 2.7101 | 0.9291 | −0.0010 | 87.81 | 14.18 |
| SVR(5_inputs) | FUNC, AVEW, AVE3, AVE2, POW1 (the choice based on initial selection from Table 3) | 0.1893 | 0.0960 | 2.7513 | 0.9269 | −0.0118 | 61.78 | 16.38 |
| SVR(11_inputs) | PEAK1, FUNC, AVEW, AVE3, AVE2, POW1—POW6 | 0.1992 | 0.1178 | 2.6727 | 0.9293 | −0.0416 | 286.28 | 20.36 |
| KNN(5_inputs) | FUNC, AVEW, AVE3, AVE2, POW1 | 0.2017 | 0.0998 | 2.7910 | 0.9179 | 0.0045 | 282.84 | 18.16 |
| IT2FLS(5_inputs) | FUNC, AVEW, AVE3, AVE2, POW1 | 0.2035 | 0.0778 | 2.8036 | 0.9048 | 0.0033 | 218.13 | 14.86 |
| AR(1) | POW1 | 0.2048 | 0.0700 | 2.7143 | 0.9173 | 0.0007 | 129.19 | 14.69 |
| KNN(11_inputs) | PEAK1, FUNC, AVEW, AVE3, AVE2, POW1—POW6 | 0.2080 | 0.1064 | 2.6502 | 0.9119 | 0.0180 | 231.56 | 18.21 |
| IT2FLS(4_inputs) | POW1-POW4 | 0.2410 | 0.1033 | 2.8139 | 0.8799 | 0.0048 | 197.56 | 17.34 |
| Method Code | Input Data Codes | RMSE | MAE | MaxAE | R | MBE | MAPE [%] | sMAPE [%] |
|---|---|---|---|---|---|---|---|---|
| MLP [LR(11_inputs), ARIMA(3,1,1), MLP(5_inputs), GBT(11_inputs)] | Different, depends on predictor in ensemble * | 0.1721 | 0.0693 | 2.5275 | 0.9398 | −0.0043 | 96.95 | 13.93 |
| GBT (11_inputs) | PEAK1, FUNC, AVEW, AVE3, AVE2, POW1—POW6 | 0.1723 | 0.0660 | 2.5283 | 0.9397 | 0.0028 | 92.90 | 13.35 |
| LR [LR(11_inputs), ARIMA(3,1,1), MLP(5_inputs), GBT(11_inputs)] | Different, it depends on predictor in ensemble | 0.1726 | 0.0645 | 2.5364 | 0.9394 | 0.0032 | 89.47 | 13.11 |
| WAE_RMSE [LR(11_inputs), MLP(5_inputs), GBT(11_inputs)] | Different, it depends on predictor in ensemble | 0.1777 | 0.0635 | 2.5455 | 0.9356 | 0.0003 | 104.84 | 14.15 |
| WAE_RMSE [LR(11_inputs), ARIMA(3,1,1), MLP(5_inputs), GBT(11_inputs)] | Different, it depends on predictor in ensemble | 0.1790 | 0.0632 | 2.5520 | 0.9346 | 0.0002 | 102.60 | 14.07 |
| GBT (5_inputs) | FUNC, AVEW, AVE3, AVE2, POW1 | 0.1808 | 0.0647 | 2.6952 | 0.9332 | 0.0045 | 125.21 | 14.31 |
| WAE_R/RMSE [MLP(5_inputs), RF(10/12), AR(1), GBT(11_inputs)] | Different, it depends on predictor in ensemble | 0.1815 | 0.0635 | 2.5485 | 0.9330 | 0.0034 | 108.46 | 13.96 |
| KNN [LR(11_inputs), ARIMA(3,1,1), MLP(5_inputs), GBT(11_inputs)] | Different, it depends on predictor in ensemble | 0.1848 | 0.0689 | 2.5961 | 0.9309 | 0.0135 | 75.77 | 12.79 |
| RF [LR(11_inputs), ARIMA(3,1,1), MLP(5_inputs), GBT(11_inputs)] | Different, it depends on predictor in ensemble | 0.1929 | 0.0762 | 2.5664 | 0.9257 | 0.0202 | 87.51 | 14.64 |
| RF (10/12) | For each tree random choice of 10 inputs from 12: PEAK1, FUNC, AVEW, AVE3, AVE2, POW1 –POW7 | 0.2008 | 0.0746 | 2.7032 | 0.9182 | 0.0127 | 87.79 | 14.26 |
| RF (6/12) | For each tree random choice of 6 inputs from 12: PEAK1, FUNC, AVEW, AVE3, AVE2, POW1 –POW7 | 0.2024 | 0.0741 | 2.7194 | 0.9177 | 0.0175 | 93.98 | 14.19 |
| Results for Time Series No. 1 | Results for Time Series No. 2 | ||||
|---|---|---|---|---|---|
| Method Code | RMSE | Difference [%] | Method Code | RMSE | Difference [%] |
| GBT (11_inputs) | 0.2102 | - | MLP [LR(11_inputs), ARIMA(3,1,1), MLP(5_inputs), GBT(11_inputs)] | 0.1721 | - |
| LR [LR(11_inputs),RF(6/12), MLP(11_inputs), GBT(11_inputs)] | 0.2126 | 0.24 | GBT (11_inputs) | 0.1723 | 0.02 |
| GBT (5_inputs) | 0.2134 | 0.32 | LR [LR(11_inputs), ARIMA(3,1,1), MLP(5_inputs), GBT(11_inputs)] | 0.1726 | 0.05 |
| MLP [LR(11_inputs), RF(6/12), MLP(11_inputs, GBT(11_inputs)] | 0.2140 | 0.38 | WAE_RMSE [LR(11_inputs), MLP(5_inputs), GBT(11_inputs)] | 0.1777 | 0.56 |
| WAE_RMSE [LR(11_inputs), RF(6/12), MLP(11_inputs), GBT(11_inputs)] | 0.2147 | 0.45 | WAE_RMSE [LR(11_inputs), ARIMA(3,1,1), MLP(5_inputs), GBT(11_inputs)] | 0.1790 | 0.69 |
| WAE_RMSE [LR(11_inputs), MLP(11_inputs), GBT(11_inputs)] | 0.2147 | 0.45 | GBT (5_inputs) | 0.1808 | 0.87 |
| WAE_R/RMSE [KNN(5_inputs), RF(10/12), AR(1), GBT(11_inputs)] | 0.2181 | 0.79 | WAE_R/RMSE [MLP(5_inputs), RF(10/12), AR(1), GBT(11_inputs)] | 0.1815 | 0.94 |
| RF [LR(11_inputs), RF(6/12), MLP(11_inputs), GBT(11_inputs)] | 0.2185 | 0.83 | LR(6_inputs) | 0.1827 | 1.06 |
| AR(1)—basic (reference) method | 0.2332 | 10.94 | AR(1)—basic (reference) method | 0.2048 | 19.00 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Parol, M.; Piotrowski, P.; Kapler, P.; Piotrowski, M. Forecasting of 10-Second Power Demand of Highly Variable Loads for Microgrid Operation Control. Energies 2021, 14, 1290. https://doi.org/10.3390/en14051290
Parol M, Piotrowski P, Kapler P, Piotrowski M. Forecasting of 10-Second Power Demand of Highly Variable Loads for Microgrid Operation Control. Energies. 2021; 14(5):1290. https://doi.org/10.3390/en14051290
Chicago/Turabian StyleParol, Mirosław, Paweł Piotrowski, Piotr Kapler, and Mariusz Piotrowski. 2021. "Forecasting of 10-Second Power Demand of Highly Variable Loads for Microgrid Operation Control" Energies 14, no. 5: 1290. https://doi.org/10.3390/en14051290
APA StyleParol, M., Piotrowski, P., Kapler, P., & Piotrowski, M. (2021). Forecasting of 10-Second Power Demand of Highly Variable Loads for Microgrid Operation Control. Energies, 14(5), 1290. https://doi.org/10.3390/en14051290