Each experiment with a certain configuration (20 TCLs or 40 TCLs in the feeder) was repeated five times to make sure the results are consistent and robust. Each repeated experiment included 200 episodes of the RL-driven controller training in a stochastic environment and 100 episodes of testing. Testing was always performed on the same 100 episodes. In all the experiments that were conducted, the episode was performed for a simulation time interval of 0–200 s. A time step of 1 s was used to measure actual and reference power level in order to apply the control.
The performance of a controller was measured as a mean of squared differences MSE between APL and RPL measured during an episode. That is, for the whole experiment testing phase, 100 values are received-1 for each testing episode. Because of that, the performance in different experiments was compared using mean, median, and standard deviation for these 100 values, as well as qualitative comparison of two distributions using distribution plots.
3.1. Evaluation of the DDQN Algorithm’s Performance and Applicability for Providing the Voltage-Based Ancillary Service (20 TCLs Setup)
The setup to evaluate the DDQN performance was made for a lesser number of TCLs to ease the observability and tracking of the learning process, as well to speed up the process itself. When the hypothesis that the state-of-the-art method in the reinforcement learning-double deep Q-network is capable of solving the task is verified, the experiment can be scaled further.
To maximize the DDQN algorithm’s performance to find an optimal combination of hyperparameters values, the hyperparameters tuning was performed. The size and the number of hidden layers were considered as the hyperparameters, as the capacity of the neural network change may influence the performance of the algorithm. The double DQN algorithm was tested with different target network update intervals. The hyperparameters tuning was performed in the following manner:
A set of possible values was chosen for each hyperparameter using knowledge transfer from other deep learning and reinforcement learning applications. If possible, values in a range of possible values were taken in a logarithmic scale, e.g., 1, 10, 100, 1000, 10,000 for an interval of [1;10,000] for target network update steps.
An experiment was run with one updated hyperparameter’s value, while other parameters were set to default values. The performance of the solution was measured for 100 episodes, as the mean squared difference between APL and RPL measured at discrete timesteps during each episode.
The value of a hyperparameter that minimizes the measured median performance was chosen as an optimal value for a considered hyperparameter.
The chosen hyperparameters after the tuning procedure are listed in
Table 1. It is worth mentioning that the hyperparameters tuning for a target update step parameter produced interesting results. According to the received results (see
Table 1), the optimal value for this parameter equals 10. The higher values of the target update step seem to decrease performance, while smaller values of the parameter decrease the time efficiency of the algorithm without any benefits in performance. These results are on the contrary to, for example, Atari games solved with DDQN [
38]. An optimal value of the target update step for the Atari games was measured in the thousands. This is due to a much higher level of complexity and dimensionality of a set of measured environmental variables in the case of the Atari games.
The convergence of the controller training can be observed in
Figure 9. It is a line chart of a controller performance metric (MSE) versus the number of training episodes. The performance of the proposed solution was evaluated by using an MSE between values of actual power consumption and reference power level measured each second during the considered time interval. These values were sampled at the time steps when control action is applied. The line chart is smoothed with an average in the window of size 20 to account for the stochasticity of each episode caused by stochastic TCLs’ initialization. It can be observed that the smoothed MSE of the episode declined until it reached a certain level, meaning that the algorithm converges to a solution. Grey lines on a line chart correspond to the individual experiments, whereas the red one is an average value. An ideal, but usually not achievable, value of the MSE performance metric is equal to zero. It is observed that during the controller’s training, MSE decreased significantly compared to the initial level. This indicates that the controller is actually learning efficient control policy. At a certain training episode, the controller reached a plateau and its performance fluctuated around that level due to the stochasticity of each training episode.
An example of system behavior after the controller was trained, that is, power measurements during one of the test episodes, can be observed in
Figure 10, where the grey line corresponds to the reference power level, the red line corresponds to the actual power level when a trained RL-driven controller is utilized, and the blue line corresponds to when the competing approach is applied. When the trained RL-driven controller is utilized, the actual power consumption profile is much closer to the reference power level, while the competing approach produces much bigger deviations both on average and in the extreme.
Each testing episode in an experiment produces one value of the performance metric (i.e., MSE), therefore, the whole experiment produces a set of MSE values. To compare performance achieved with different parameters or control strategy, both qualitative and quantitative analyses were performed. For the quantitative analysis, a set of MSE values was considered as a performance metric that is sampled with corresponding sample statistics metrics: mean, median, and standard deviation (std). These aggregated performance measures for the experiment with optimal hyperparameters is given in
Table 2. The competing approach, in this case, has chosen parameter
as optimal control. For the first result in
Table 2, median, mean, and std are very high when no control is applied, that is, the voltage controller is removed from the system. For the RL-driven controller case (best DDQN in
Table 2), the median of MSE is more than four times smaller and the mean MSE is more than two times smaller, compared to the competing approach. This means that on average proposed RL-driven controller outperforms the competing approach by two to four times.
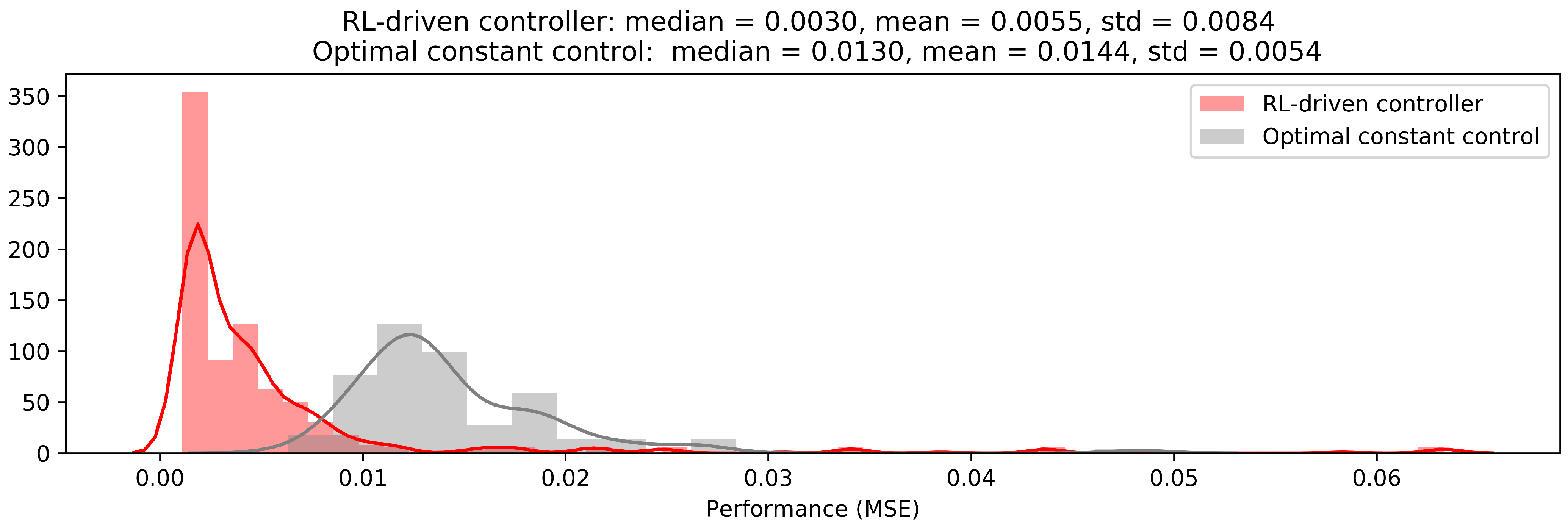
The quantitative analysis was supported by a qualitative analysis. To this end, the distributions of MSE samples for the presented and competing approaches were compared using the distribution plot visualization technique. As an ideal value of performance metric (MSE) equals 0, the more samples are close to 0, the better. A comparison of the performance distribution for the presented solution and the competing approach is in
Figure 11. It can be observed that a MSE distribution is located much closer to zero than the distribution for the competing approach. That is, it can be stated that on average (in most cases) the presented solution performs much better than the competing approach.
The developed RL-based ancillary service has shown the capability to work efficiently in a stochastic environment. This allows for the successful application in a previously unseen environment, using the following approach: the controller is trained in the stochastic environment that is similar to the planned utilization environment using a simulation of a power system. Then, it is deployed to the power system and utilizes the optimal control policy learned from many similar environments. As was shown with a qualitative and quantitative analysis, this leads to significantly better performance than the performance of a competing approach for most cases. Although, the RL-driven controller has never observed those specific environments that were used for testing.
However, a standard deviation of the MSE sample for the RL-driven controller is approximately
times higher and a long right tail is observed in the performance distribution (
Figure 11) for some cases. This long right tail of the distribution consists of just several observations with high MSE. This indicates that for these rare cases, the RL-driven approach is not as efficient as the competing approach. Because of that, the stability of the performance may require improvement and should be treated carefully in applications. The performance is still comparable with a competing approach, although the controller was not trained to act in that particular environments.
One of the possible solutions to a stability problem can be additional controller calibration after its deployment to the target system. That is, after the controller learned a more general version of an optimal control strategy from interactions with similar environments, it is deployed to the power system of interest and is calibrated with a short period of additional training. This way, the controller preserves general knowledge learned from many environments and, at the same time, adapts to the particularities of the environment where it should operate.
Another option to tackle the stability problem can be provided with an ensembling technique—by combining several models one can smooth the effect of one model erroneous decisions and therefore avoid clearly bad scenarios. In addition, such an ensemble can be enriched with domain knowledge serving the same purpose—avoiding performance worse than classic competing approaches. This way, in that rare cases, if the RL-driven controller will not be significantly more efficient than the competing approach, it will not cause any inefficiencies. In other words, it will provide benefits in most cases, and for rare cases it will show the same performance as existing solutions.
Although most likely by combining all these techniques, one can achieve high performing solution, the domain expertise and/or some safety rules should always be involved in a system including machine learning algorithms. This is due to the risk that unstable behavior will still be present even for well-studied machine learning models. A good example of such a case are adversarial attacks in the computer vision domain, when models are intentionally confused with very little perturbations of the input, although their production performance remains excellent [
42,
43].
3.2. Evaluation of the DDQN Generalization Capability (40 TCLs Setup)
To test the generalization capabilities of the developed RL controller, a setup with a bigger number of TCLs was organized. A comparison of the RL controller’s performance with the competing approach (proportional control) was made using both qualitative and quantitative analyses. Statistical measures (mean, median, and std) collected in the process of the quantitative analysis are presented in
Table 3. The competing approach, in this case, has chosen
as optimal control. The median of the MSE distribution for the proposed solution is more than two times smaller than for the competing approach, the mean is almost two times smaller and even standard deviation is approximately
times smaller for the proposed RL controller. This indicates that the performance of the proposed approach is significantly better than the proportional control. Moreover, high standard deviation is not observed in the 40 TCLs setup in contrast to the 20 TCLs setup, and thus it can be stated that these observations with high MSE are very rare.
The qualitative analysis represented by the visualization of MSE sample distributions are given in
Figure 12. It can be observed that the distribution of MSE samples for the proposed approach (red) is shifted to the left, closer to zero, compared to the distribution of proportional control performance samples (grey). This confirms that the received results of the controller application are aligned with the initial goal because the control goal is to reduce MSE.
The results of the qualitative and quantitative analyses confirm that the presented solution performance is significantly better than the performance of the competing approach for the 40 TCLs setup. A rough estimate is that a proposed solution shows two times better results. Thus, the proposed RL-driven controller works efficiently not only in the 20 TCLs setup, where it was finetuned, but also in the 40 TCLs setup, where it was applied without additional tuning. This is the evidence of the generalization capabilities of the proposed solution.
3.3. Evaluation of the Expected Decrease in Costs
The evaluation of the achieved decrease in costs for considered setups was done to give an intuition of the possible impact of the proposed solution. To calculate the expected decrease in costs, the following assumptions were made: 1 p.u. in the simulated power system equals 1 kW; 1 kWh cost equals USD 0.18—peak hours pricing according to [
8]. That is, each 1 kWh of deviation from the reference power profile causes inefficiency in costs equal to USD 0.18.
First, deviation of the actual power consumption and reference power profile was measured in kWh for both the proposed and the competing approaches. The case with no control in the system was not considered, as it is strongly inferior to the competing approach. Second, the positive impact of the RL-driven controller was measured as a decrease in deviation compared to the competing approach. The calculated decrease in deviation of power consumption compared to the competing approach is presented in
Table 4. According to the received data, utilization of the RL-driven controller instead of the proportional controller allows us to achieve a 56% decrease in deviation from the planned power profile for the 20 TCLs setup and approximately 39% for the 40 TCLs setup, i.e., after the proposed controller’s application, the actual power consumption is significantly closer to the reference power profile. For a power system setup with 40 TCLs, the change is more modest than for a setup with 20 TCLs. This is due to finetuning that was done for 20 TCLs case, while exactly the same model was applied to the 40 TCLs case and no finetuning was performed.
After calculating the decrease in deviation from the planned power profile, a corresponding decrease in costs was calculated. There may be other improvements in cost efficiency implicitly caused by improvements in a profile of actual power consumption, but this evaluation accounts only for an explicit positive effect of having a power consumption close to the planned profile. The calculated decrease in cost compared to the competing approach is presented in
Table 5. Numbers are given in USD
for readability, as calculated costs for a 200 s interval considered in the experiment are small.
A significant decrease of costs is achieved for both cases, according to the results. It is important to emphasize that this efficiency is achieved without any significant influence to customers comfort or overriding consumers decisions. This is because of the chosen problem formulation that excludes direct interventions to the consumer side processes and operates using only customer-agnostic information.
However, it can be observed that the decrease of costs for the 40 TCLs setup is smaller than for the 20 TCLs setup. This is because the RL-driven controller was not finetuned for the 40 TCLs case and thus achieved an approximately 17% smaller decrease in the deviation from the planned power profile. This can be improved with additional calibration of the RL-driven controller. Such a calibration can be done by performing hyperparameters tuning for a particular power system setup or performing calibration via a short period of additional training in the power system of interest. Both options are likely to improve performance and, thus, help to achieve higher costs decrease.





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}











