1. Introduction
To address complex challenges in power systems associated with the presence of distributed energy resources (DERs), wide application of power electronic devices, increasing number of price-responsive demand participants, and increasing connection of flexible load, e.g., electric vehicles (EV) and energy storage systems (ESS), recent studies have adopted artificial intelligence (AI) and machine learning (ML) methods as problem solvers [
1]. AI can help overcome the aforementioned challenges by directly learning from data. With the spread of advanced smart meters and sensors, power system operators are producing massive amounts of data that can be employed to optimize the operation and planning of the power system. There has been increasing interest in autonomous AI-based solutions. The AI methods require little human interaction while improving themselves and becoming more resilient to risks that have not been seen before.
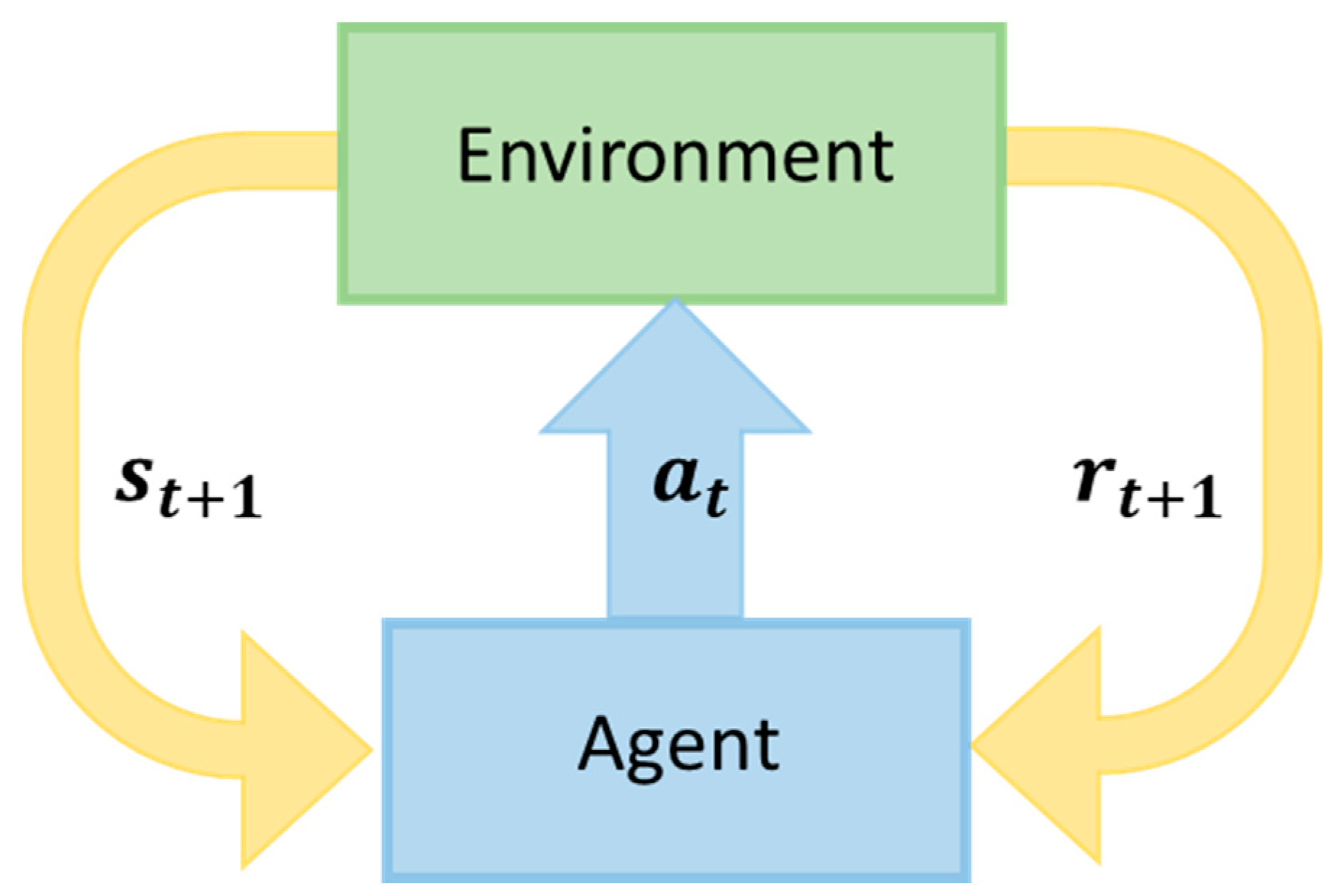
Recently, reinforcement learning (RL) and deep reinforcement learning (DRL) have become popular approaches to optimize and control the power system operation, including demand-side management [
2], the electricity market [
3], and operational control [
4], among others. RL learns the optimal actions from data through continuous interactions with the environment, while the global optimum is unknown. It eliminates the dependency on accurate physical models by learning a surrogate model. It identifies what works better with a particular environment by assigning a numeric reward or penalty to the action taken after receiving feedback from the environment. In contrast to the performance of RL, the conventional and model-based DR approaches, such as mixed interlinear programming [
5,
6], mixed integer non-linear programming (MINLP) [
7], particle swarm optimization (PSO) [
8], and Stackelberg PSO [
9], require accurate mathematical models and parameters, the construction of which is challenging because of the increasing system complexities and uncertainties.
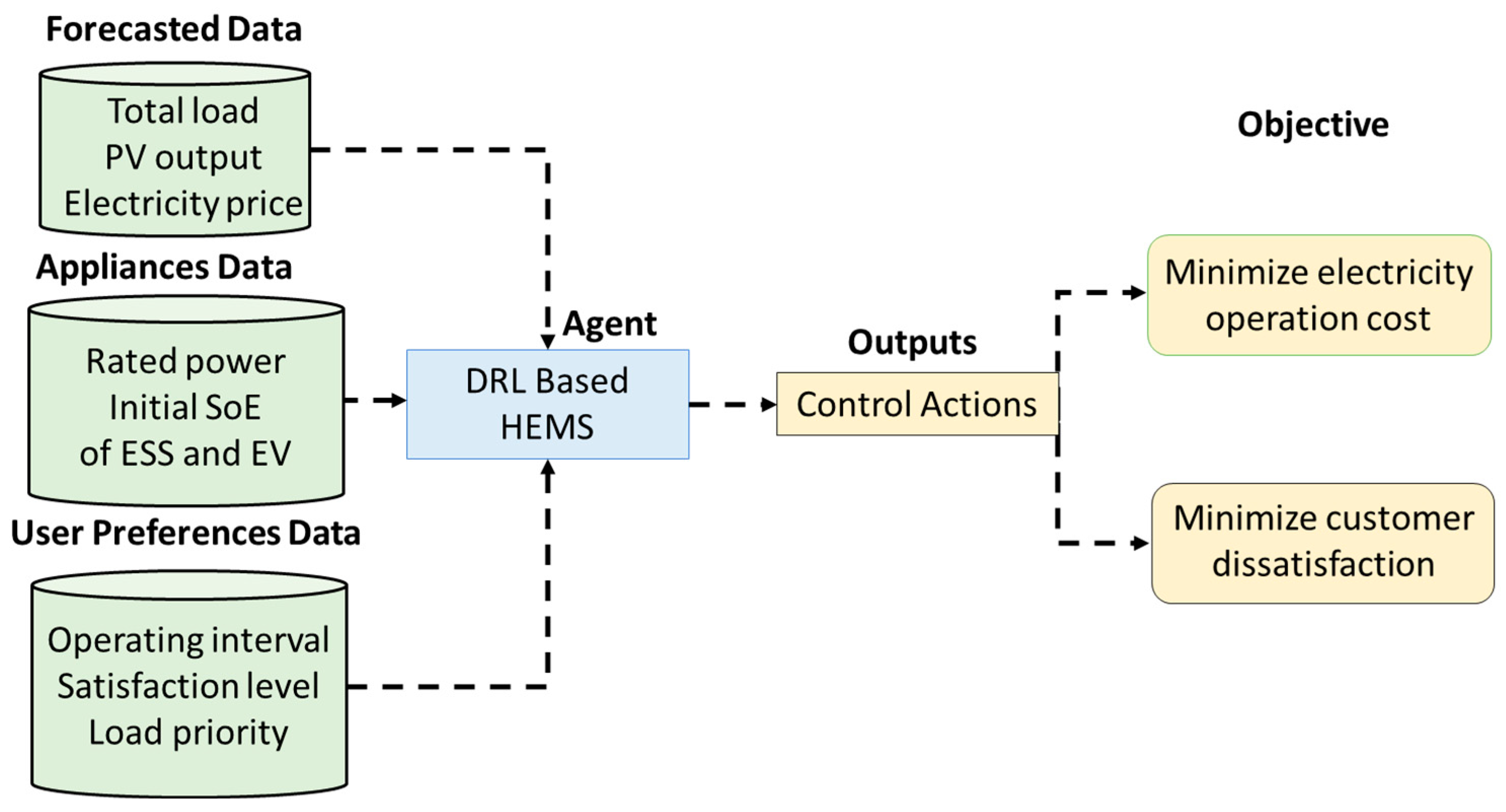
In demand response (DR), RL has shown effectiveness by optimizing the energy consumption for households via home energy management systems (HEMSs) [
10]. The motivation behind applying DRL for DR arises mainly from the need to optimize a large number of variables in real time. The deployment of smart appliances in households is rapidly growing, increasing the number of variables that need to be optimized by the HEMS. In addition, the demand is highly fluctuant due to the penetration of EVs and RESs in the residential sector [
11]. Thus, new load scheduling plans must be processed in real-time to satisfy the users’ needs and adapt to their lifestyles by utilizing their past experiences. RL has been proposed for HEMSs, demonstrating the potential to outperform other existing models. Initial studies focused on proof of concept, with research such as [
12,
13] advocating for its ability to achieve better performance than traditional optimization methods such as MILP [
14], genetic algorithms [
15], and PSO [
16].
More recent studies focused on utilizing different learning algorithms for HEMS problems, including deep Q-networks (DQN) [
17], double DQN [
18], deep deterministic policy gradients [
19], and a mixed DRL [
20]. In [
21], the authors proposed a multi-agent RL methodology to guarantee optimal and decentralized decision-making. To optimize their energy consumption, each agent corresponded to a household appliance type, such as fixed, time-shiftable, and controllable appliances. Additionally, RL was utilized to control heating, ventilation, and air conditioning (HVAC) loads in the absence of thermal modeling to reduce electricity cost [
22,
23]. Work in [
24] introduces an RL-based HEMS model that optimizes energy usage considering DERs such as ESS and a rooftop PV system. Lastly, many studies have focused on obtaining an energy consumption plan for EVs [
25,
26]. However, most of these studies only look at improving their performance compared to other approaches without providing precise details, such as the different configurations of the HEMS agent based on an RL concept or hyperparameter tuning for a more efficient training process. Such design, execution, and implementation details can significantly influence HEMS performance. DRL algorithms are quite sensitive to their design choices, such as action and state spaces, and their hyperparameters, such as neural network size, learning and exploration rates, and others [
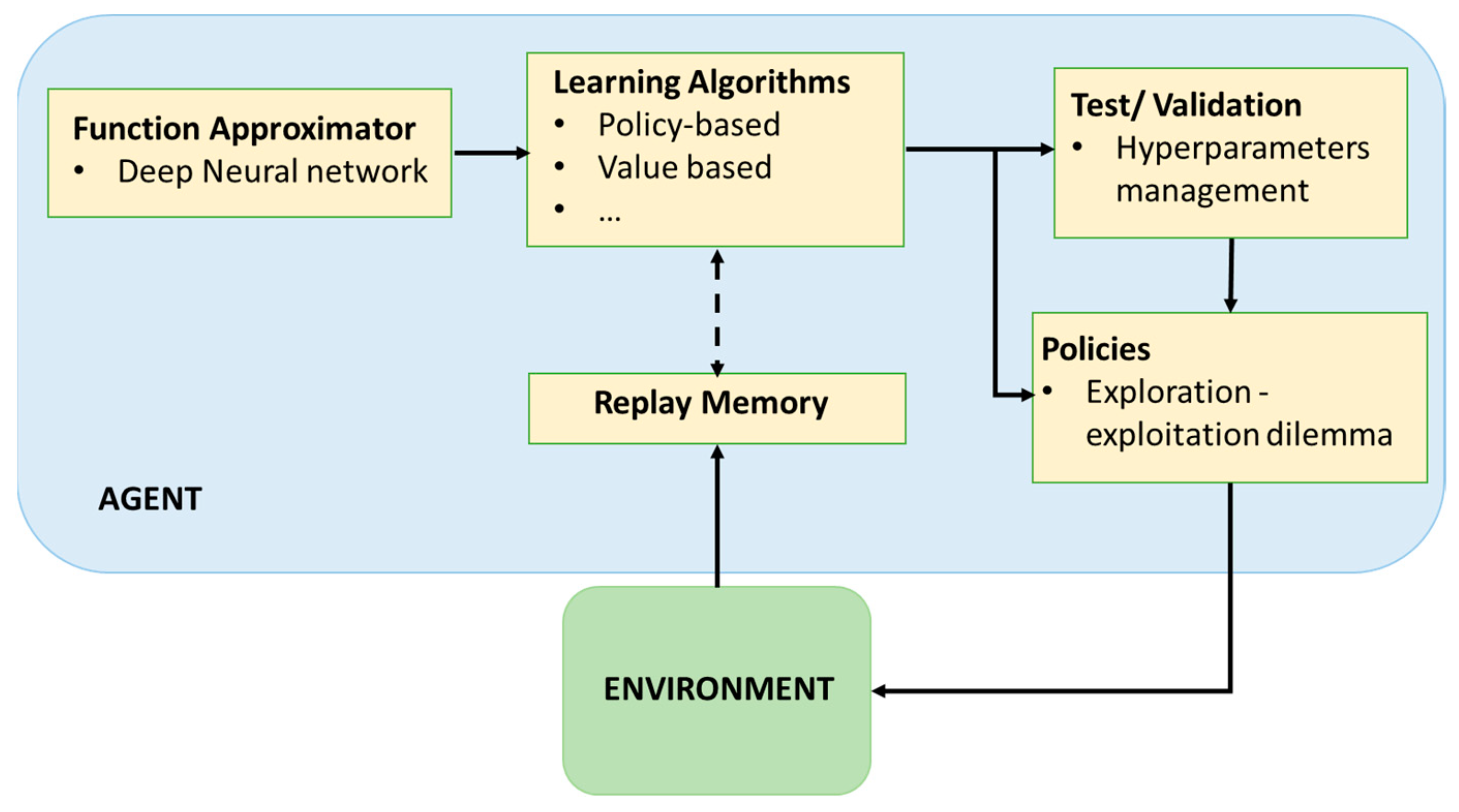
27].
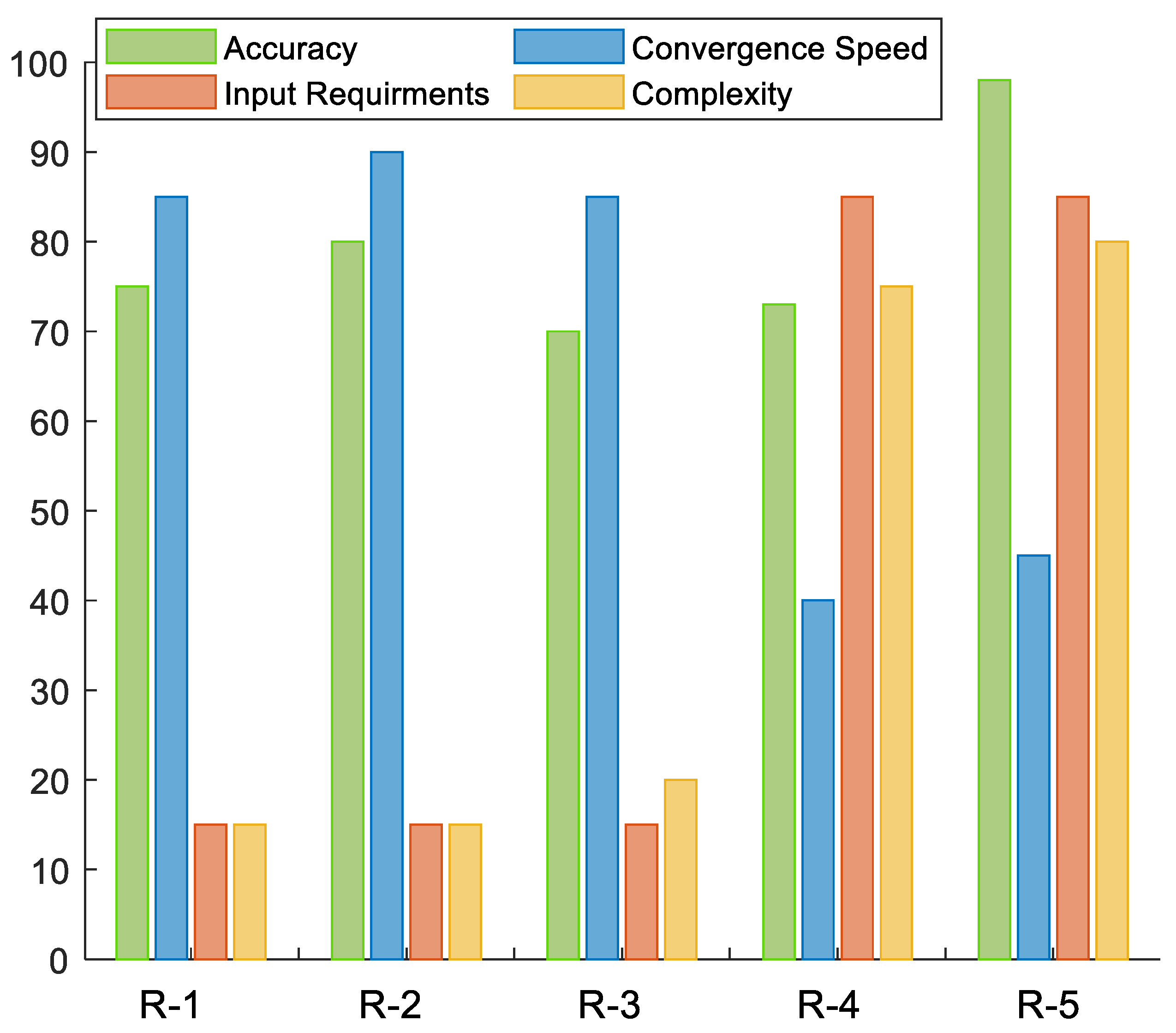
The DRL adoption in real-world tasks is limited because of the reward design and safe learning. There is a lack in the literature of in-depth technical and quantitative descriptions and implementation details of DRL in HEMSs. Despite the expert knowledge required in DR and HEMS, DRL-based HEMSs pose extra challenges. Hence, a performance analysis of these systems needs to be conducted to avoid bias and gain insight into the challenges and the trade-offs. The compromise between the best performance metrics and the limiting characteristics of interfacing with different types of household appliances, EV, and ESS models will facilitate the successful implementation of DRL in DR and HEMS. Further, there is a gap in the literature regarding the choice of reward function configuration in HEMSs, which is crucial for their successful deployment.
In this paper, we compare different reward functions for DRL-HEMS and test them using real-world data. In addition, we examine various configuration settings of DRL and their contributions to the interpretability of these algorithms in HEMS for robust performance. Further, we discuss the fundamental elements of DRL and the methods used to fine-tune the DRL-HEMS agents. We focus on DRL sensitivity to specific parameters to better understand their empirical performance in HEMS. The main contributions of this work are summarized as follows:
A study of the relationship between training and deployment of DRL is presented. The implementation of the DRL algorithm is described in detail with different configurations regarding four aspects: environment, reward function, action space, and hyperparameters.
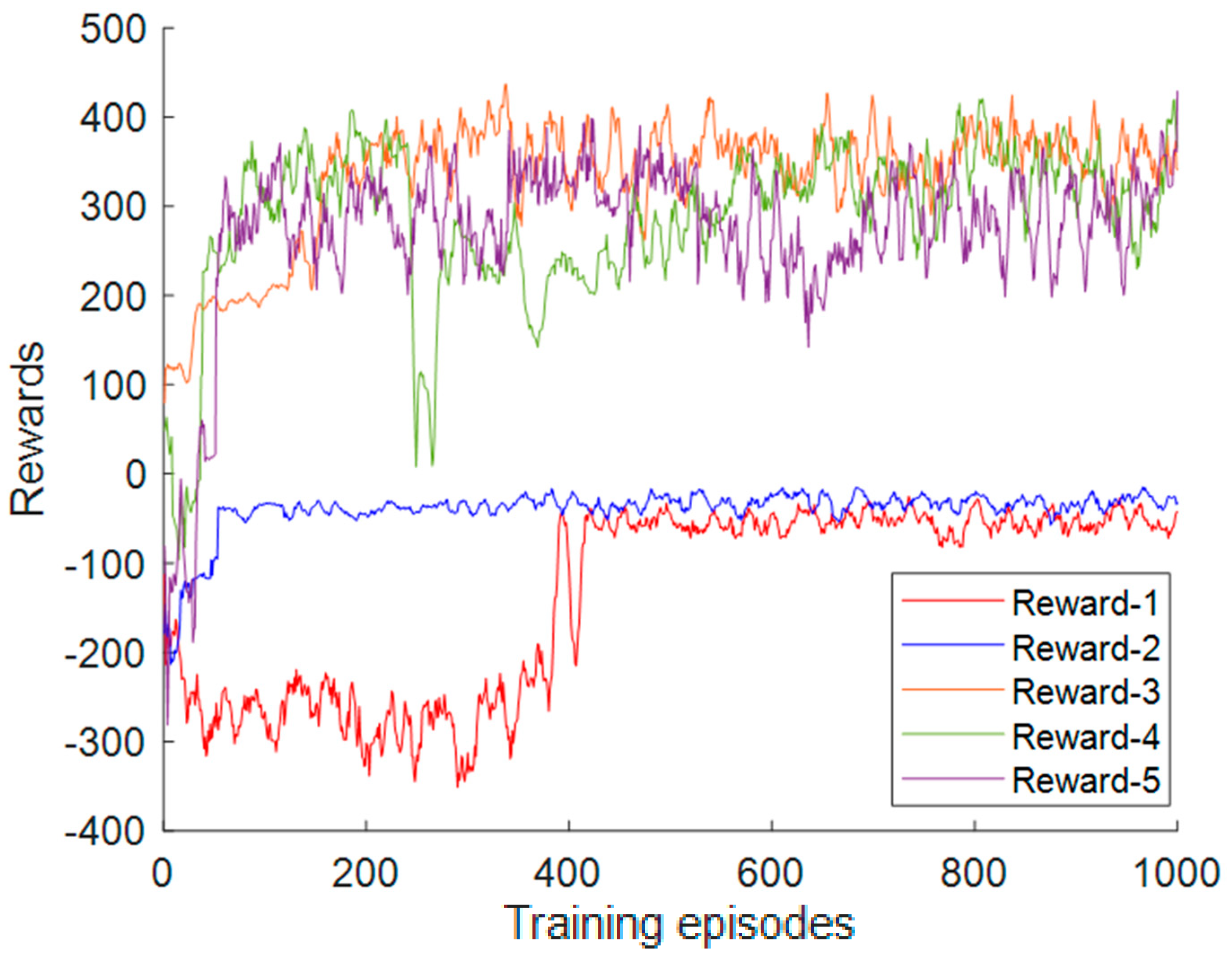
We have considered a comprehensive view of how the agent performance depends on the scenario considered to facilitate real-world implementation. Various environments account for several scenarios in which the state-action pair dimensions are varied or the environment is made non-stationary by changing the user’s behavior.
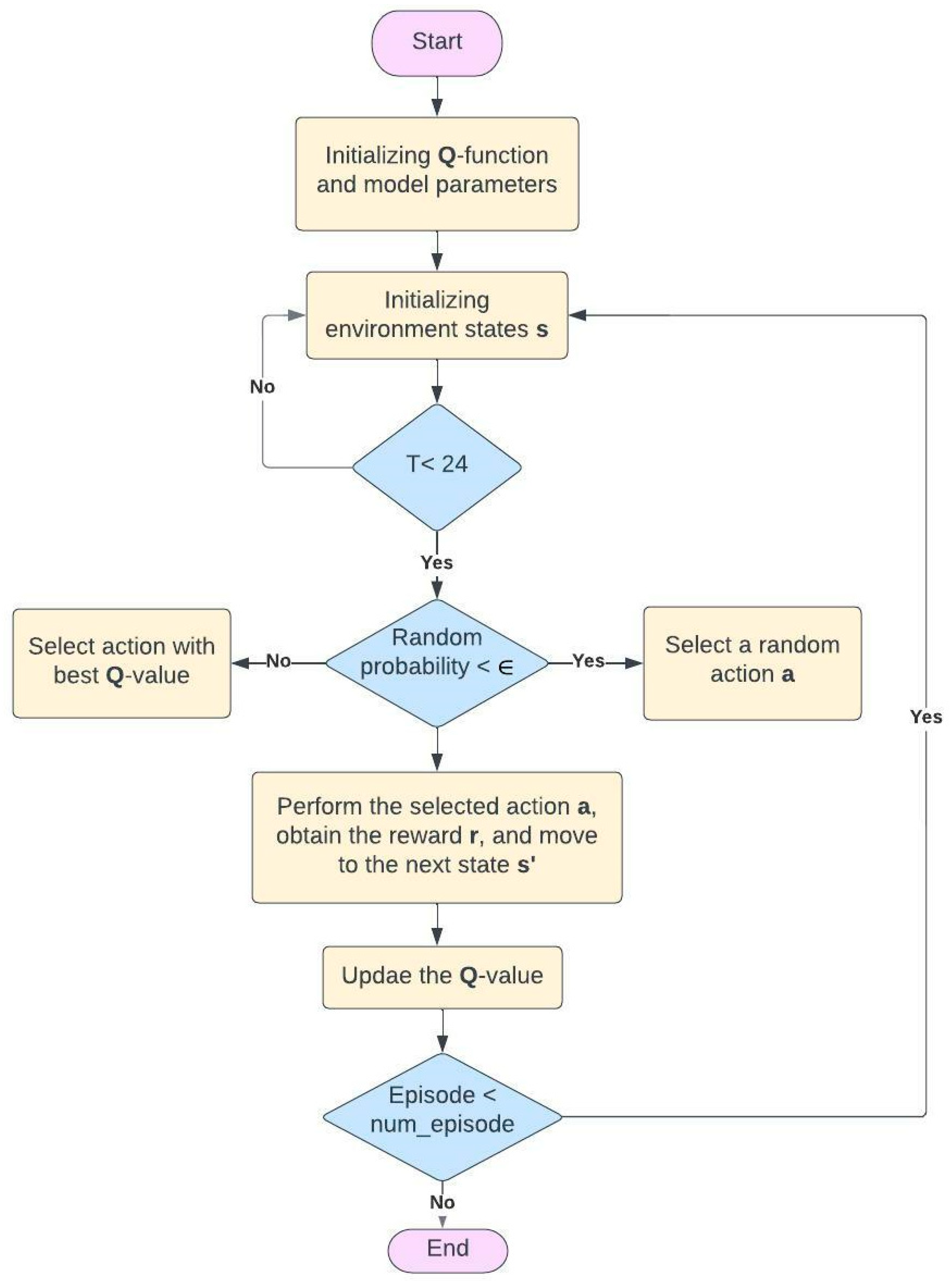
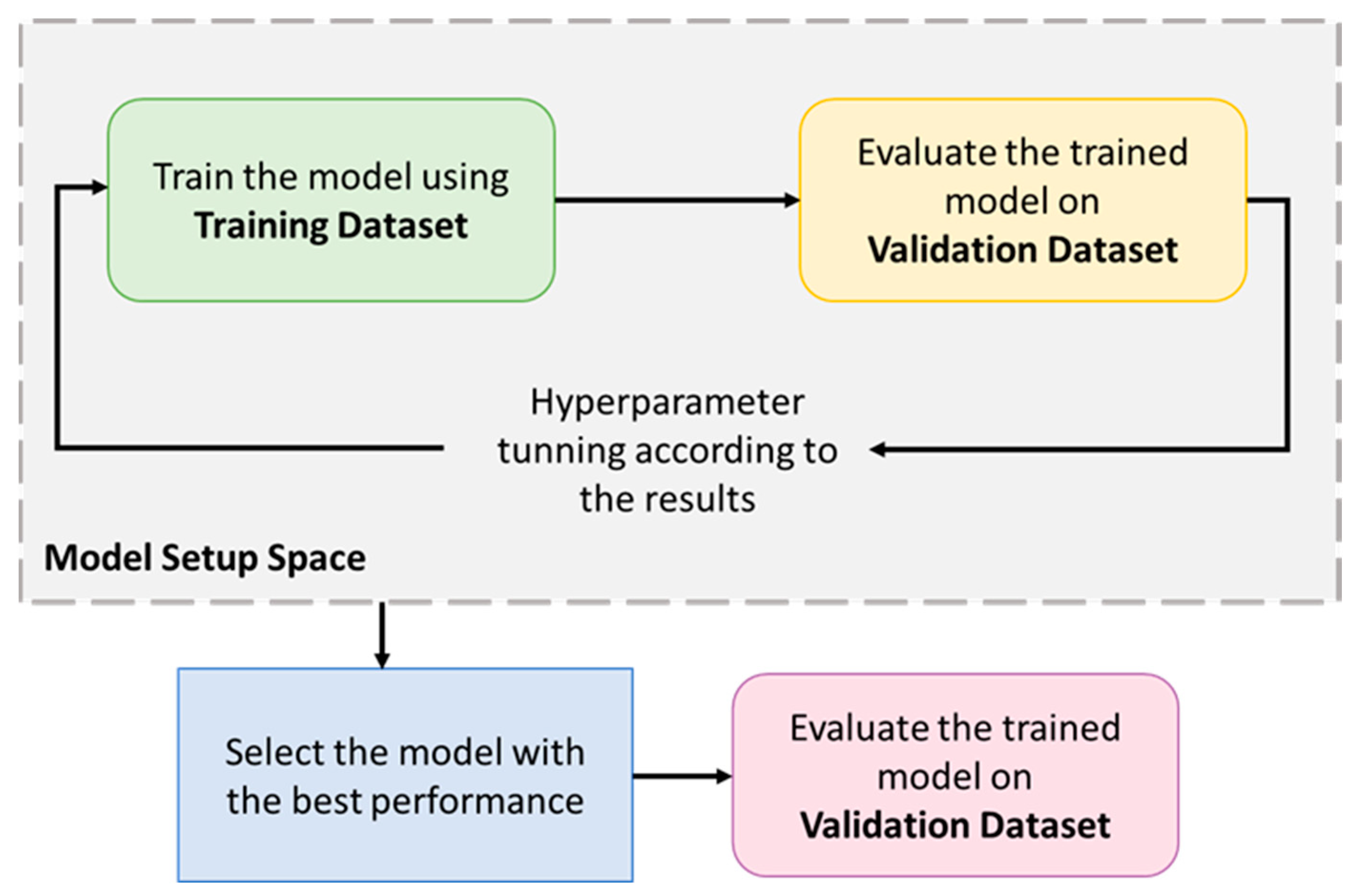
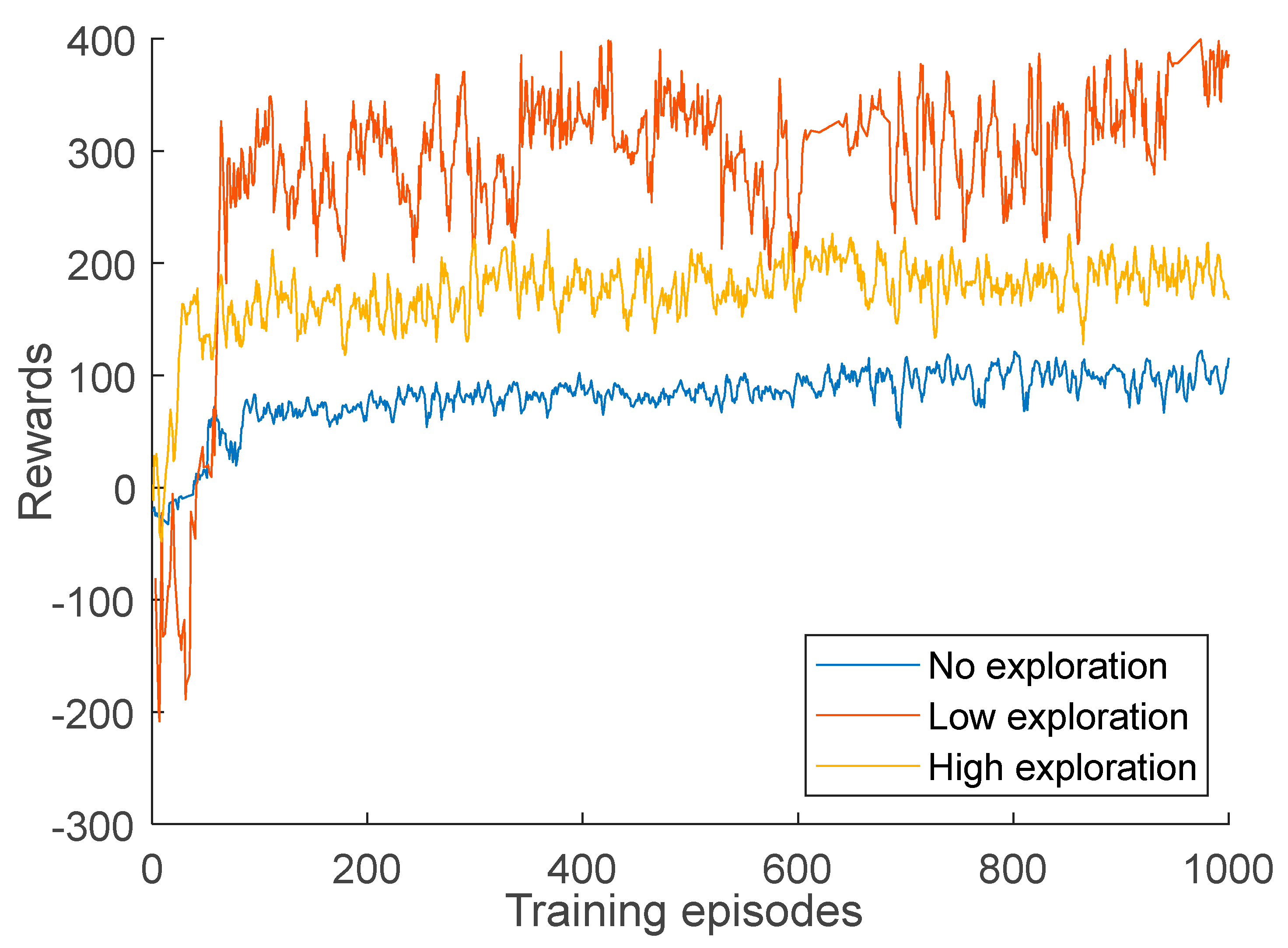
Extensive simulations are conducted to analyze the performance when the model hyperparameters are changed (e.g., learning rates and discount factor). This verifies the validity of having the model representation as an additional hyperparameter in applying DRL. To this end, we choose the DR problem in the context of HEMS as a use case and propose a DQN model to address it.
The remainder of this paper is structured as follows. The DR problem formulation with various household appliances is presented in
Section 2.
Section 3 presents the DRL framework, different configurations to solve the DR problem, and the DRL implementation process. Evaluation and analysis of the DRL performance results are discussed in
Section 4. Concluding along with the future work and limitation remarks are presented in
Section 5.
5. Conclusions
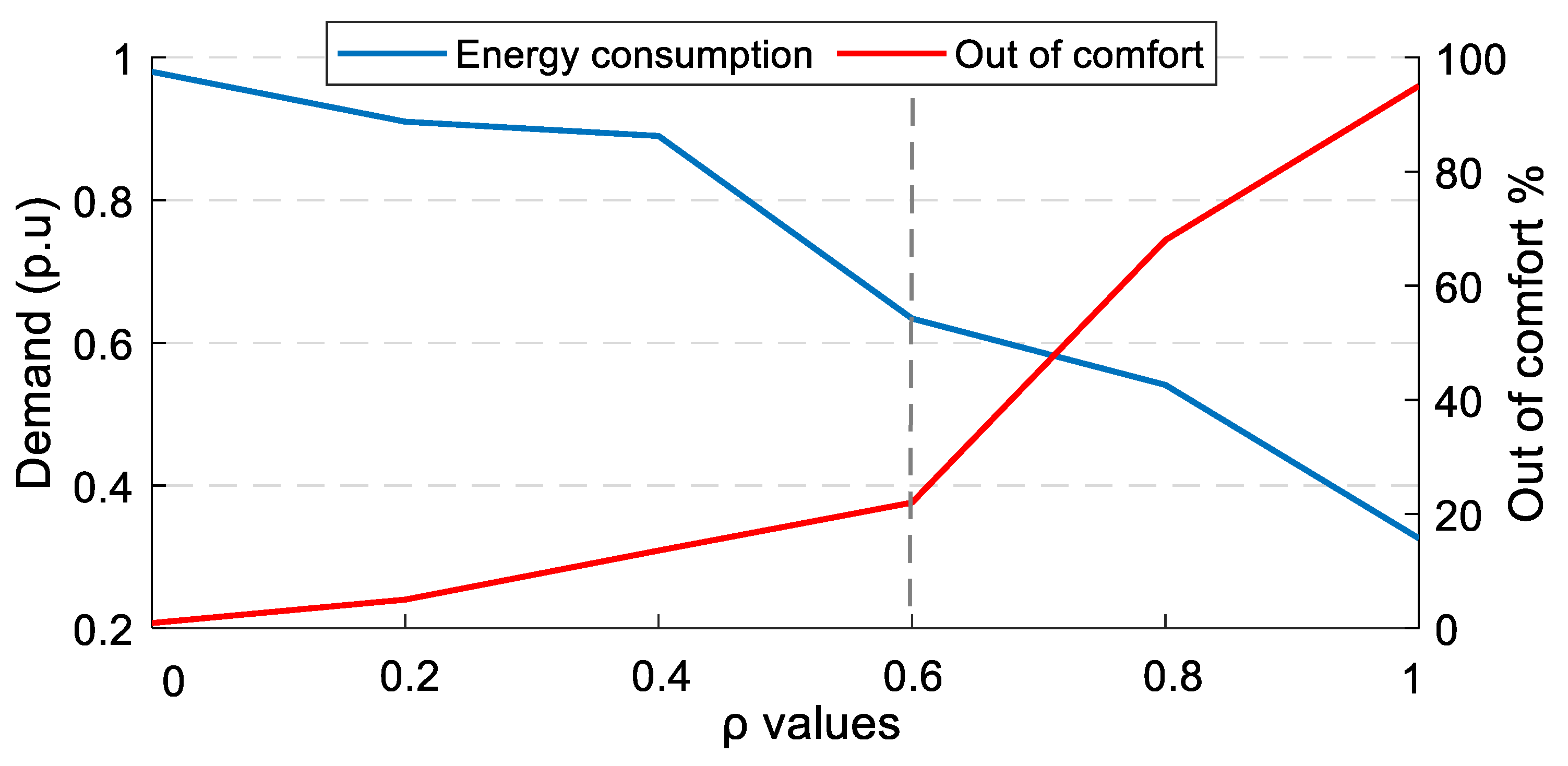
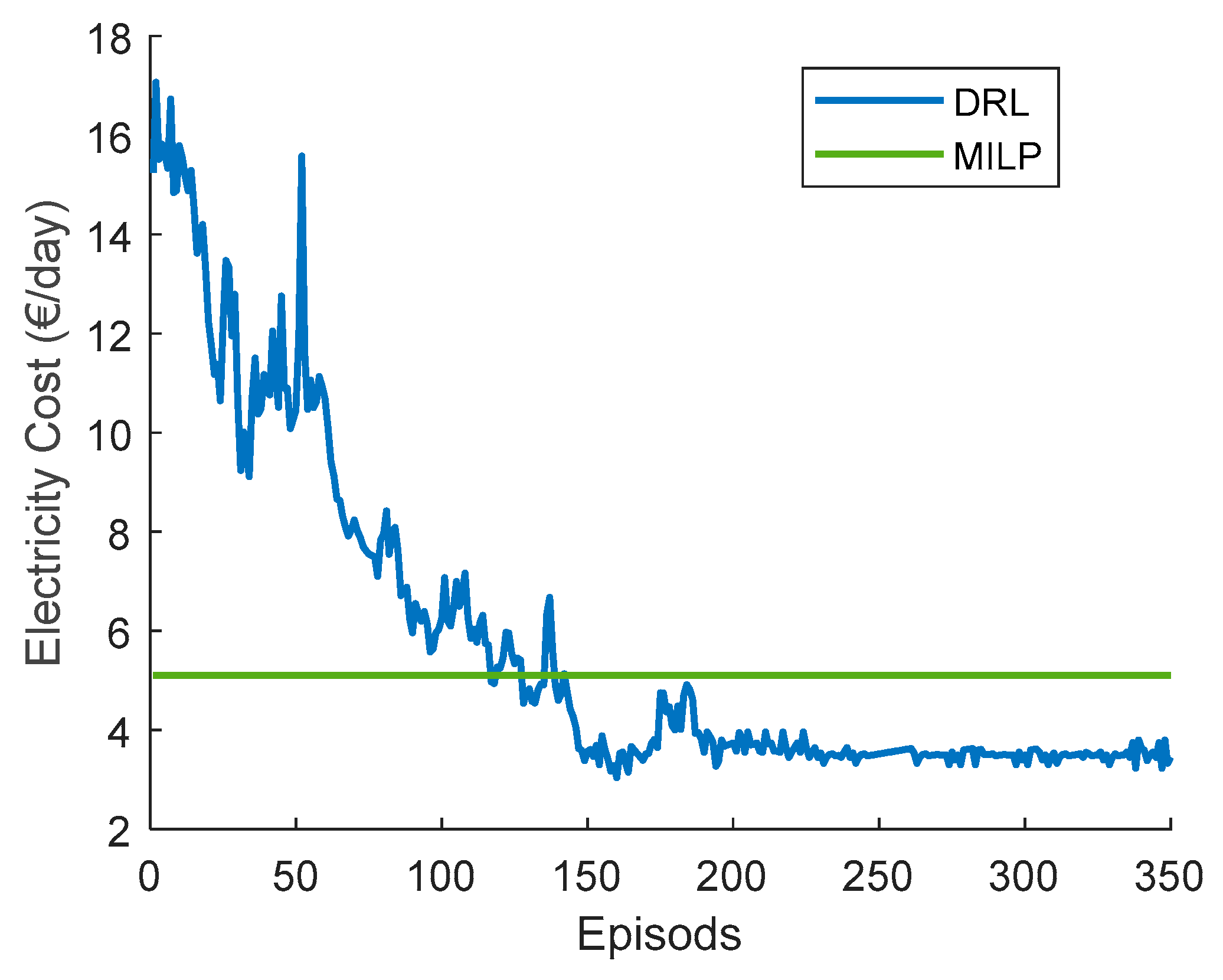
This paper addresses DRL’s technical design and implementation trade-offs for DR problems in a residential household. Recently, DRL-HEMS models have been attracting attention because of their efficient decision-making and ability to adapt to the residential user lifestyle. The performance of DRL-based HEMS models is driven by different elements, including the action–state pairs, the reward representation, and the training hyperparameters. We analyzed the impacts of these elements when using the DQN agent as the policy approximator. We developed different scenarios for each of these elements and compared the performance variations in each case. The results show that DRL can address the DR problem since it successfully minimizes electricity and discomfort costs for a single household user. It schedules from 73% to 98% of the appliances in different cases and minimizes the electricity cost by 19% to 47%. We have also reflected on different considerations usually left out of DRL-HEMS studies, for example, different reward configurations. The considered reward metrics are based on their complexity, required input variables, convergence speed, and policy robustness. The performance of the reward functions is evaluated and compared in terms of minimizing the electricity cost and the user discomfort cost. In addition, the main HEMS challenges related to environmental changes and high dimensionality are investigated. The proposed DRL-HEMS shows different performances in each scenario, taking advantage of different informative states and rewards. These results highlight the importance of choosing the model configurations as an extra variable in the DRL-HEMS application. Understanding the gaps and the limitations of different DRL-HEMS configurations is necessary to make them deployable and reliable in real environments.
This work can be extended by considering the uncertainty of appliance energy usage patterns and working time. Additionally, network fluctuations and congestion impacts should be considered when implementing the presented DRL-HEMS in real-world environments. One limitation of this work is that the discussed results only relate to the DQN agent training and do not necessarily represent the performance for other types of network, such as policy gradient methods.


















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}