1. Introduction
The safety and success of hydrocarbon resource exploration depend on the accurate estimation of the geomechanical properties. Geomechanical properties thus play an essential role in developing conventional and unconventional reservoirs [
1]. However, accurate estimation is challenging due to complexities in geologic structure, heterogeneity, and insufficient borehole information [
2]. Existing analytical methods are time-consuming and very expensive, requiring extensive transformations and lengthy laboratory tests. In addition, reliable target zone identification during the exploration requires accurate location identification [
3].
Geomechanical properties locate the sweet spots for fracturing, which is crucial for hydrocarbon recovery from complex formations [
4]. They are obtained from the compressional and shear wave slowness data, which augments the accuracy of hydrocarbon production and fluid detection prediction. Geomechanical properties calculation requires acoustic logs, including compressional travel time (DTC) and shear travel time (DTS). The sonic data are usually acquired through an acoustic log or from core samples using laboratory testing.
However, the complication of the process, along with the lack of information on the borehole, makes it very challenging and time-consuming to obtain reliable logging data, resulting in higher recovery costs and incomplete data sets with a log deficiency [
5,
6]. Different empirical and petrophysical models are used for predicting shear wave velocity for different types of reservoirs, including mudstone structures [
7,
8,
9,
10], requiring robust data sets that include mineral composition, pore structure, and fluid parameters. However, due to several factors and limitations, empirical correlations cannot be easily selected. Poor prediction of sonic logs using the empirical correlations and elastic parameters of rocks estimation will be erroneous, leading to big financial issues [
11]. Therefore, it is important to reconstruct missing and/or distorted log sections during formation evaluation and reservoir characterization.
During logging operations, broken or faulty tools can lead to many errors. It could take measurements of a few zones, thereby avoiding other potential pay zones; thus, contributing entirely erroneous data suite. So, it is necessary to rebuild missing and/or inaccurate log sections during reservoir characterization and prospect evaluation. According to Castagna, using formation-specific and regression-based correlations, shear wave velocity (Vs) can be estimated from the compressional velocity (Vp) [
8]. On the other hand, Brocher predicted vs. from the Vp, but there is a limitation for the Vp range [
12], which trigger more investigation on acoustic logging.
In recent years, the use of artificial intelligence (AI) has been increasing extensively for a wide range of engineering and industrial purposes [
13,
14]. Among them, one of the fastest-growing sectors is the petroleum industry. This tool is predominantly used for the estimation and optimization of petrophysical properties [
15,
16,
17,
18,
19], geomechanical properties [
20,
21,
22], reservoir fluid properties [
23,
24,
25,
26,
27,
28], and parameters related to drilling [
29,
30,
31,
32,
33,
34,
35,
36,
37]. Researchers employed different ML methods, including an artificial neural network, fuzzy logic, functional network, etc. to predict and analyze geomechanical properties [
38,
39,
40,
41,
42,
43,
44,
45,
46]. The studies reveal that different types of formation differ significantly in behavior, and rock mechanical properties are more complex than ideal materials.
There is a knowledge gap in terms of the unavailability of algorithms for predicting DTS, especially for the formation with distinct geologic heterogeneity, even with the advances in the data-driven artificial neural networks applied in the petroleum field. However, for the effective prediction of sequential data, the use of the Bi-LSTM model has been reported [
47].
The Permian Basin located in the West Texas region become one of the most productive energy regions in the world. The geographic region is shown in
Figure 1. The basin reserve is reported about 92.3 billion barrels of oil and 300 trillion cubic feet of natural gas which is 38 times Alaska’s reserves and forecasted capable of meeting U.S. energy demand for 60 years [
48]. However, the basin continuously faces severe technical challenges during the drilling, completion, and fracturing. In addition, there is a knowledge gap in terms of the lack of an accurate method for estimating the elastic characteristics of the formation, which is vital for safely and efficiently executing the drilling and completion program [
49].
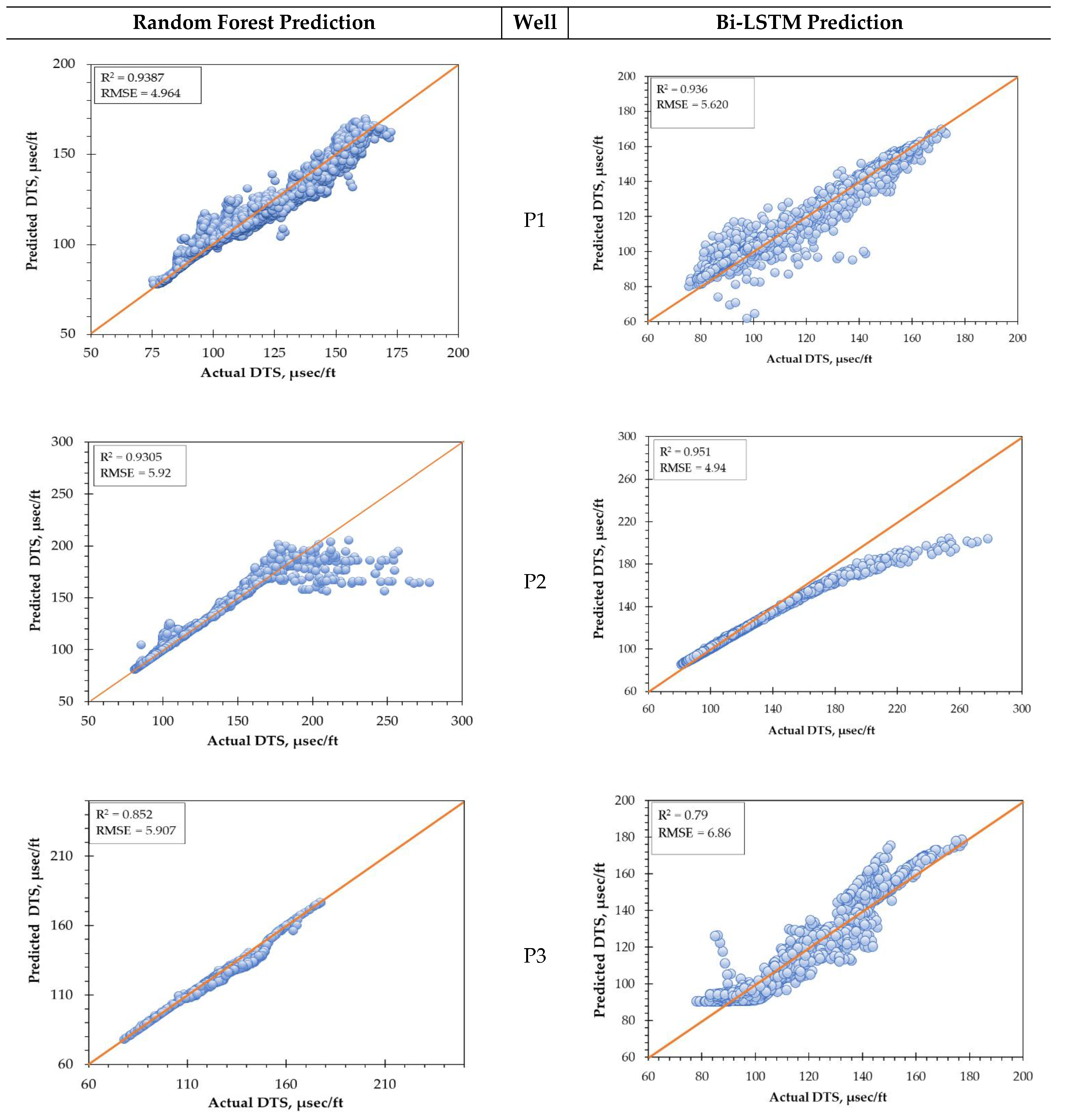
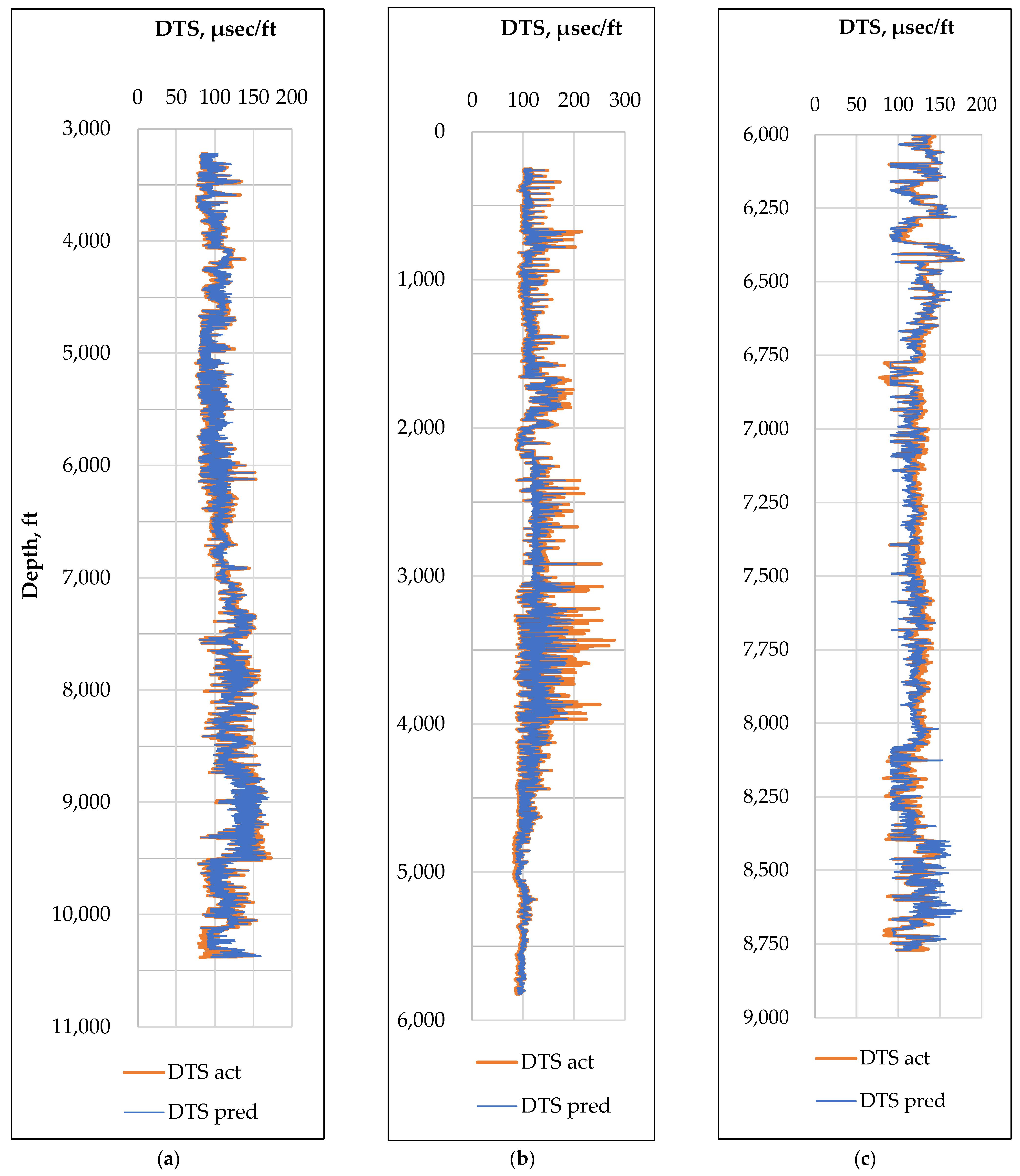
This study focuses on a handy and easy-to-use artificial neural network (ANN) model that is capable of predicting missing or incomplete information. To accomplish this objective, two ANN models were applied to forecast shear travel slowness (DTS) from different input log data. Supervised deep neural network, Bi-LSTM, and classical ML model random forest (RF) algorithm were employed to predict the shear wave slowness.
Prediction of the acoustic data accurately will give dependable data on the reservoirs’ elastic properties. This study elaborates an ancillary method for forecasting reservoir elastic properties using the predicted acoustic data when data sets are incomplete or absent. The model results of the two models were then compared to examine the model’s efficacy.
Therefore, accurate prediction of the ANN-based models developed in this study will address the knowledge gap. There is a significant improvement in both the treatment design and the role of the geomechanicist with the adoption of the ML algorithms developed in this study. Further, the operator can utilize the ML or AI models to audit the fracture interpretations, saving costs and reducing time.
2. Methodology
ANN is an effective tool for constructing relationships between non-linear constraints in the absence of abundant data in its structure. The log-derived prediction algorithm includes porosity, bulk density, compressional travel time, gamma-ray, and resistivity as input to predict shear travel time. Then, ML and deep learning algorithms were used to predict DTS. Finally, dynamic Young’s modulus, Poisson’s ratio, and minimum horizontal stress are estimated using the petrophysical correlation with predicted DTS value and compared. A total of two prediction methods are used to predict DTS value: single well and cross well prediction.
- (a)
In a single-well prediction, from the log data, 75% is used for training, and the remaining 25% for testing, as illustrated from the workflow in
Figure 2.
- (b)
Similarly, for a grouped or cross-well prediction (a group of wells from an identical region), the data from two wells were used for training and the remaining third well for testing. The three Permian Basin wells’ log data used for this study are illustrated by the workflow in
Figure 3. In this case, the test data are completely unknown to trained models since the model is trained by another two wells from two different regions.
Figure 2.
Workflow for estimating geomechanical properties.
Figure 2.
Workflow for estimating geomechanical properties.
Figure 3.
Algorithm for cross-well prediction.
Figure 3.
Algorithm for cross-well prediction.
We used both the ML algorithm random forest (RF) and a Bi-LSTM to examine and compare the effectiveness of the prediction of geomechanical properties. Finally, we calculated the average of both ML models’ results to generate a safe and realistic prediction.
2.1. Machine Learning Algorithm
Random Forest: RF is an algorithm based on the decision tree which is used particularly for providing precise and easy-to-interpret outcomes which are fit for purpose.
RF operates by constructing several decision trees from various subsets of data. The model prediction is achieved by voting on the outcomes of multiple decision trees. (RF) is implemented using the standard Python library [
51]. We used the “RandomizedSearchCV” library from Sklearn to optimize our hyperparameters for RF and found the optimized parameter, where the estimator = 50, max features = ‘sqrt’ cross well, and max depth = 260. We also changed these hyper-parameters for single wells and reported the results.
2.2. Deep Learning Mechanism
Bidirectional long short-term memory (Bi-LSTM): The current study's dataset is depth-wise sequential. The prediction of the new dataset requires long-term dependencies. The architecture of the LSTM model can learn patterns with long dependencies where the conventional RNN models are not capable to perform for long-term relationships and patterns [
52,
53,
54]. During time series data prediction, LSTM has usually been found to outperform RNNs. Thus, here, the LSTM model is employed as it is capable of capturing both the temporal and spatial characteristics of the selected wells.
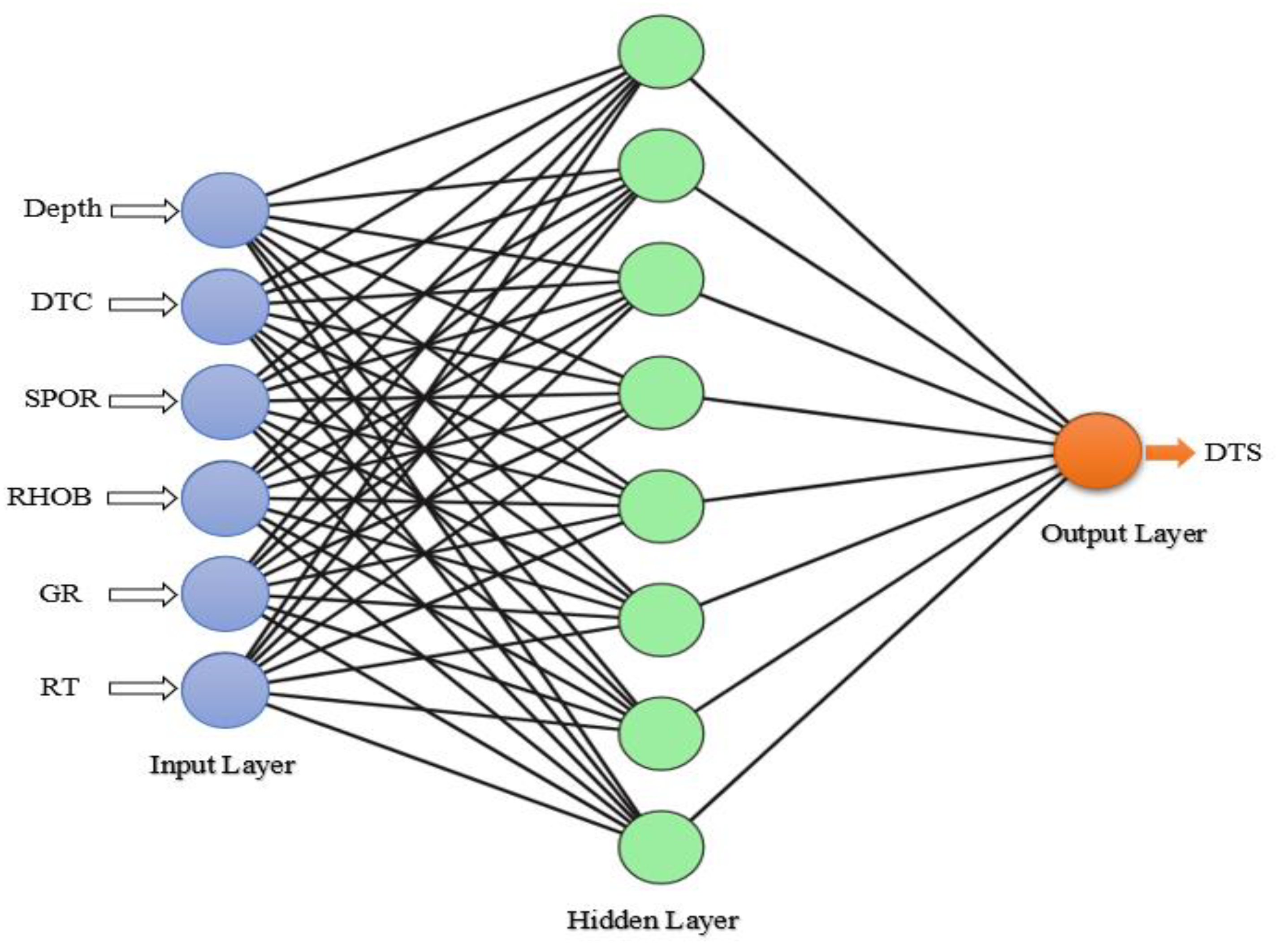
We defined a bi-directional LSTM layer with 50 neurons and set the batch size to 5. To reduce the overfitting of the data, a dropout layer of 25% is applied after the first layer of the Bi-LSTM model. ReLU is employed as the activation function. For the number one layer, the Adam optimizer and MSE loss function are used in the current model and one predicted output was in the last dense layer. During the training of the data, the model iterated over 20 epochs. The ANN model employed in this study is presented in
Figure 4.
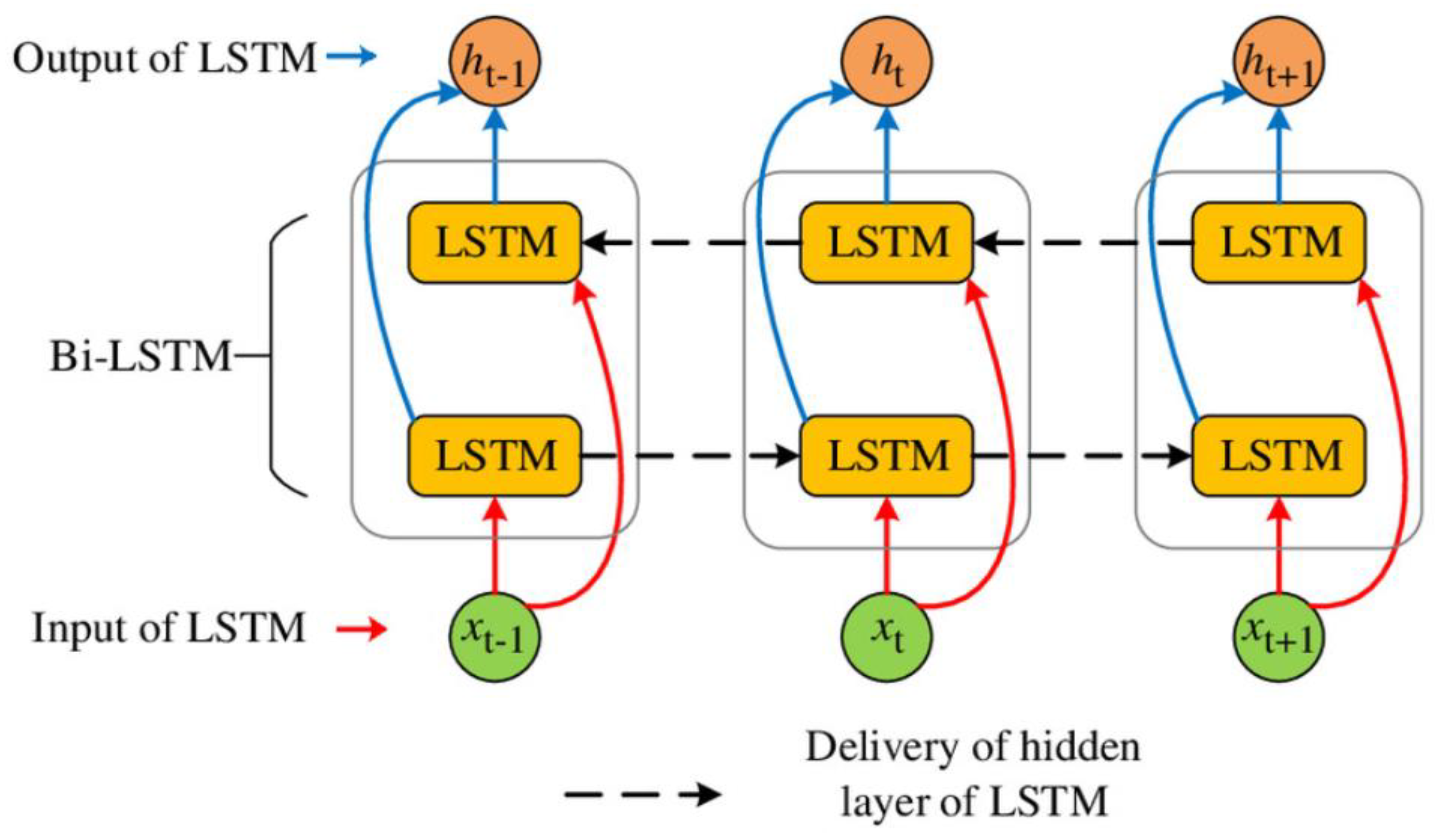
The Bi-LSTM architecture used in this study is shown in
Figure 5. Where the LSTM model has only a hidden layer and it predicts output based on previous information, the Bi-LSTM model predicts based on the previous and subsequent data points. The well data contextual in nature are sequential and can be used as bidirectional during the entire training process. The hyperparameters are the same as the LSTM model mentioned above.
2.3. Processing of Data Set
The log data of the Permian Basin for the three wells studied in the work are numbered from P1 to P3. Out of all unconventional formations in the USA, Permian Basin is the most prolific hydrocarbon field that encompasses an area exceeding 86 thousand square miles in West Texas. The well depth found in this study ranges from 3000 to 12,000 feet. The well location and the lithologic characteristics are presented in
Table 1.
During the processing of the data, depth-wise acoustic data were recorded with other logs. During the initial inspection of the raw, all the outliers were removed manually from the data. The data source for this study is the Railroad Commission (RRC), Texas.
To predict acoustic velocity, for all three wells, the data points used are described in
Table 2,
Table 3 and
Table 4. To construct the model, a 75:25 ratio is used for training and testing the data. About 3500 data points from three selected wells were made unseen from RF and Bi-LSTM models and utilized later to validate. Each depth point has a total of six log parameters utilized as input and the DTS value targeted an output.
Table 2,
Table 3 and
Table 4 presented the statistical parameters of the dataset used to construct the models. The logging inputs below were obtained from Permian Basin wells and used in constructing this model:
Depth, (D) in ft
Porosity (POR) in %
Bulk density, (RHOB) in g/cm3
Compressional travel time (DTC) in µsec/ft
Gamma Ray (GR), in API
Formation Resistivity (RT) in Ω-m
To avoid overfitting, AI algorithms employed have an early stopping nature. The losses during training and validation events are assessed at each iteration, which is shown in
Figure 6 for three wells.
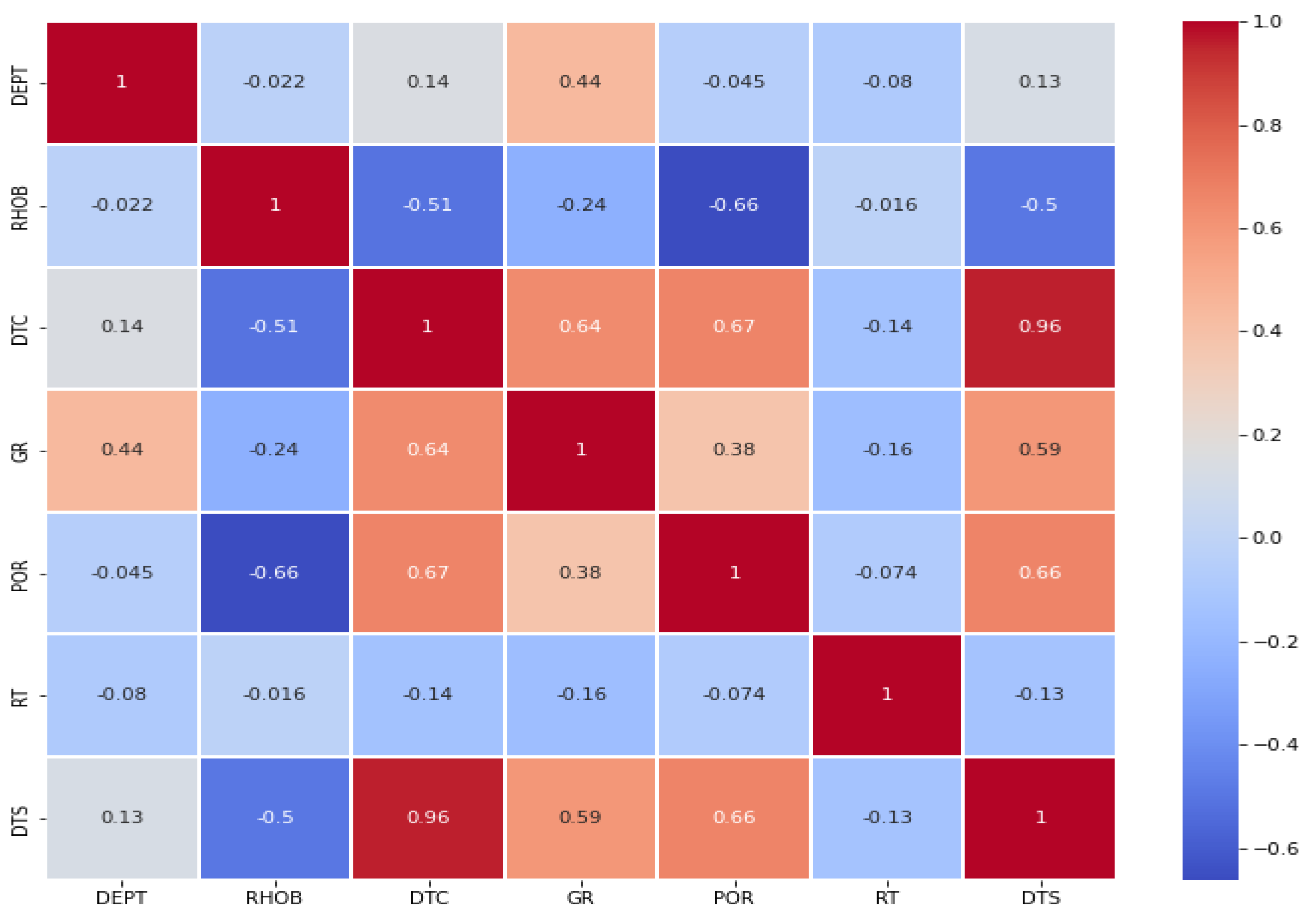
The correlation matrix from the initial input data is shown in
Figure 7 and
Figure 8 for single-well and grouped-well cases respectively. These heatmaps show how each feature is correlated with other well parameters. From
Figure 7 and
Figure 8, it is evident that all input parameters are positively correlated with each other, except for RT and RHOB values. This inconsistency more likely happened due to the regional difference and bad quality of the data obtained from the publicly shared domain, RRC. The parameters RT and RHOB are negatively or weakly correlated, as shown in the heatmap, which impacted the predictions made for both methods.
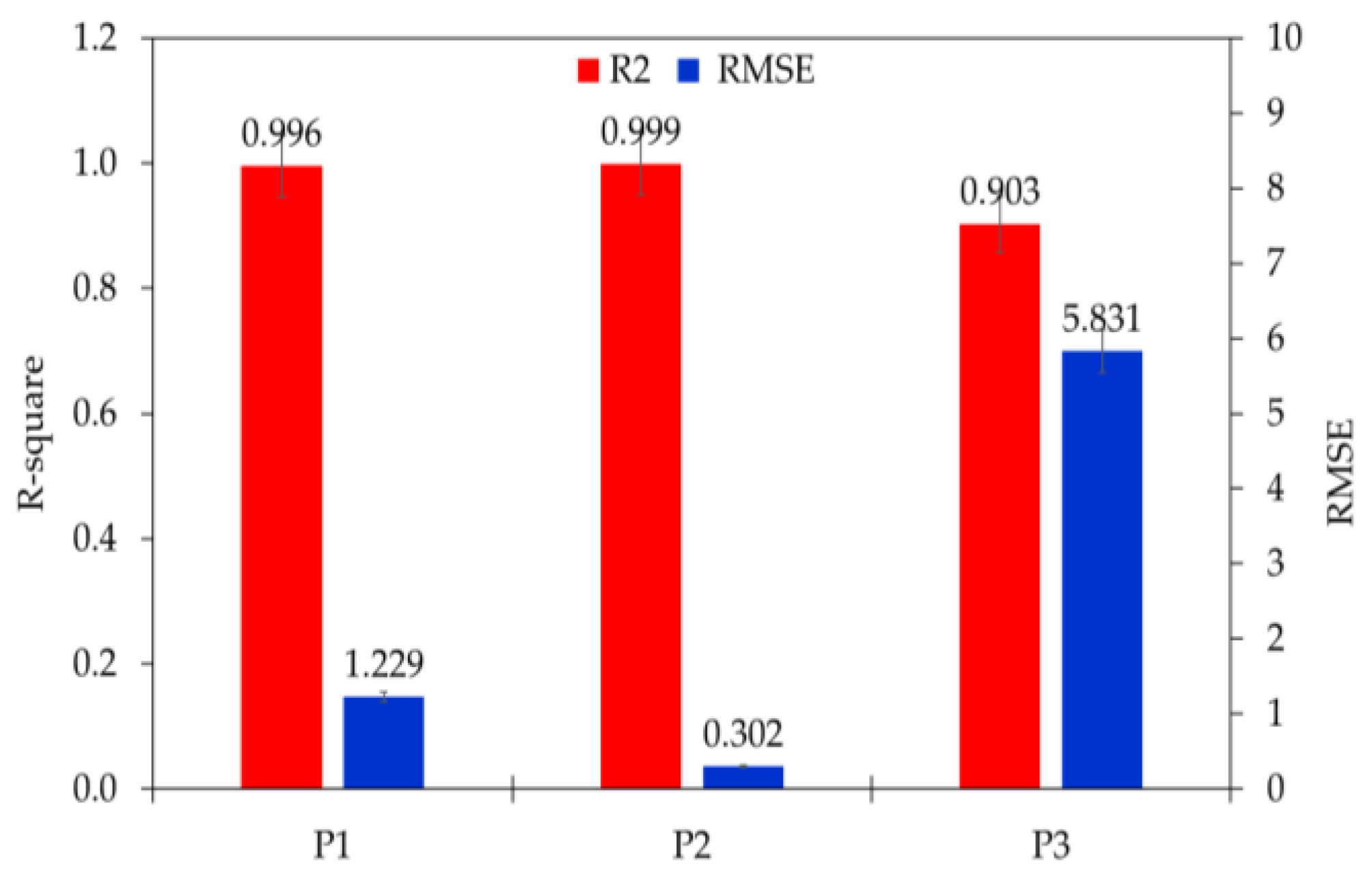
2.4. Performance Evaluation
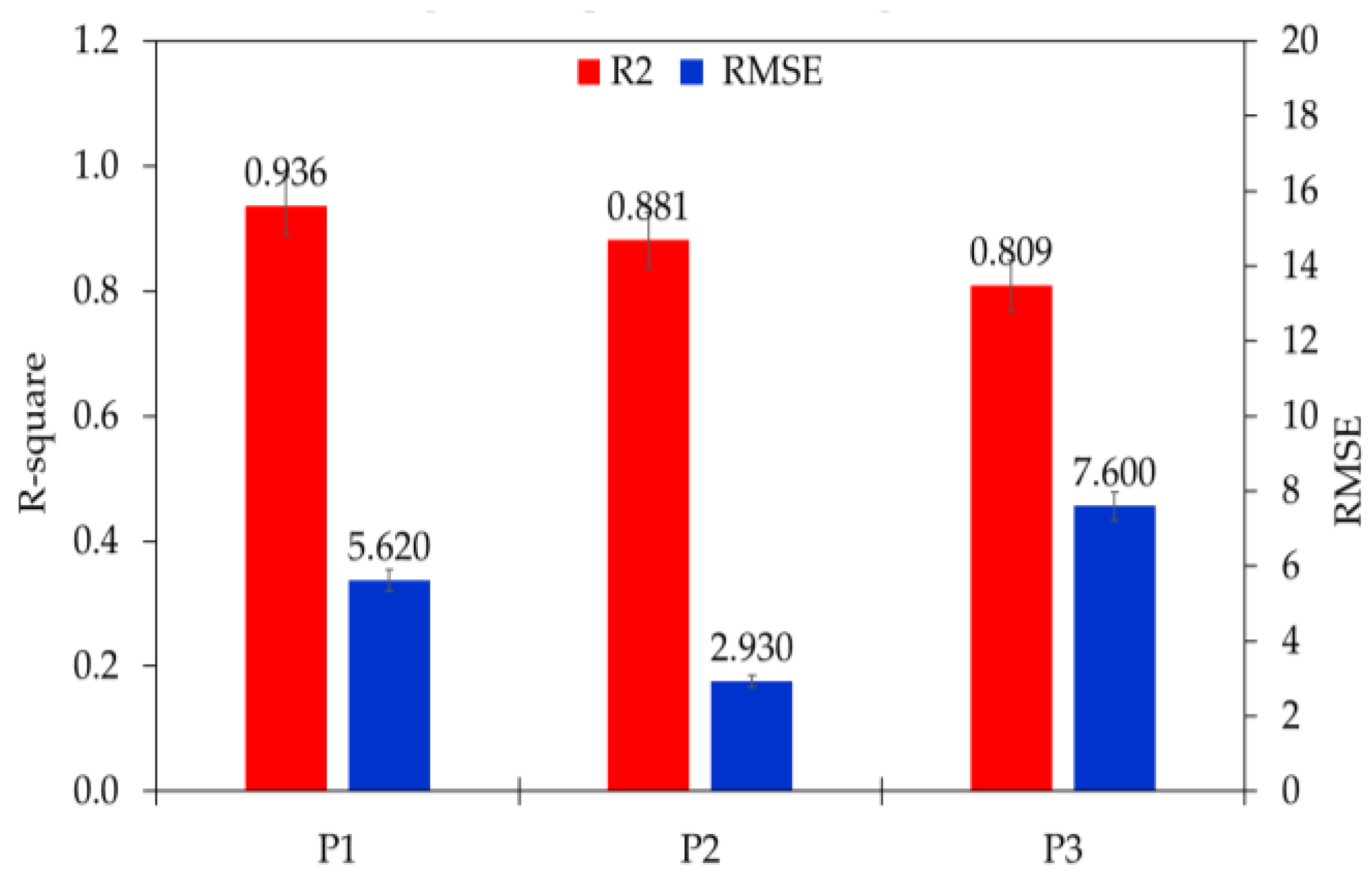
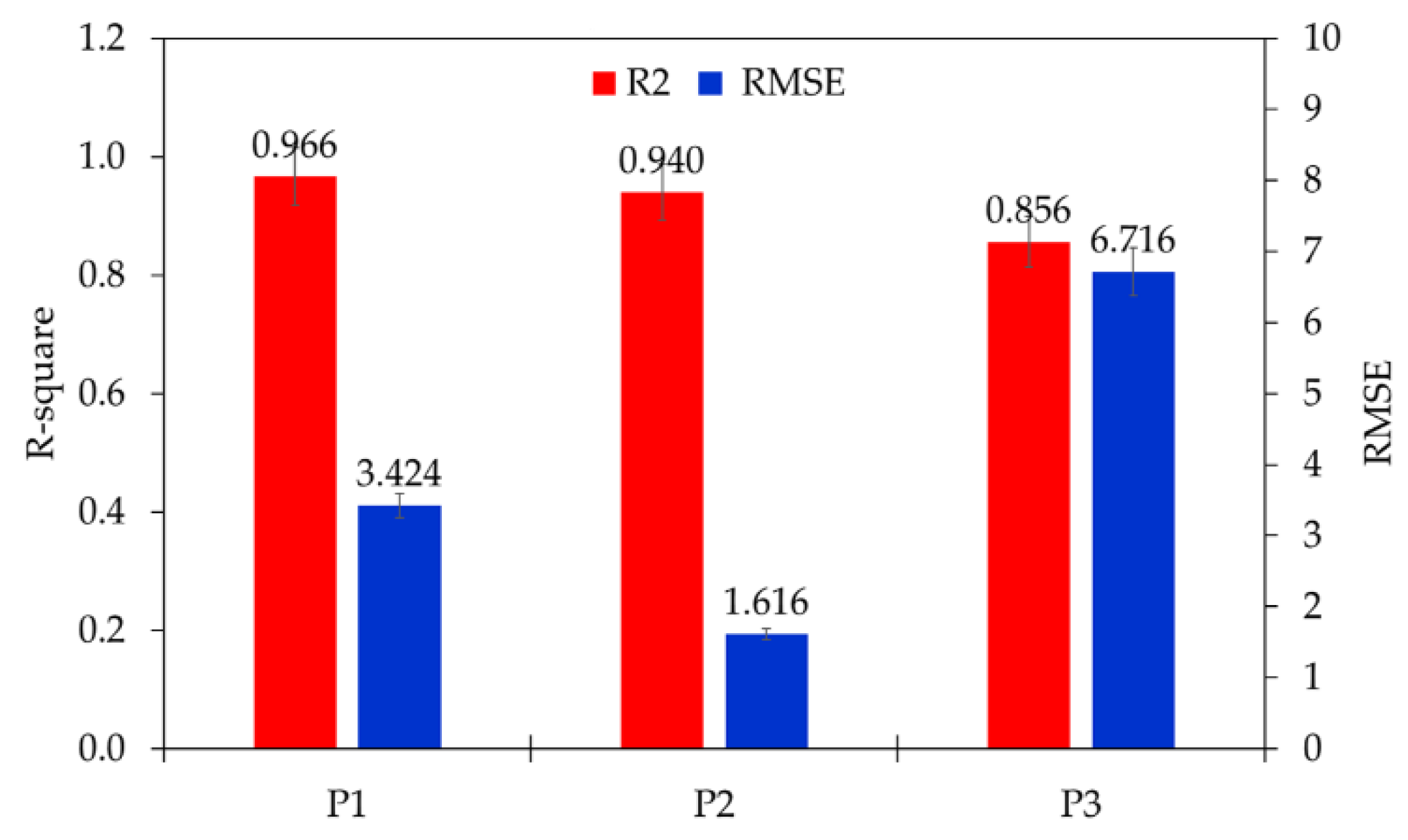
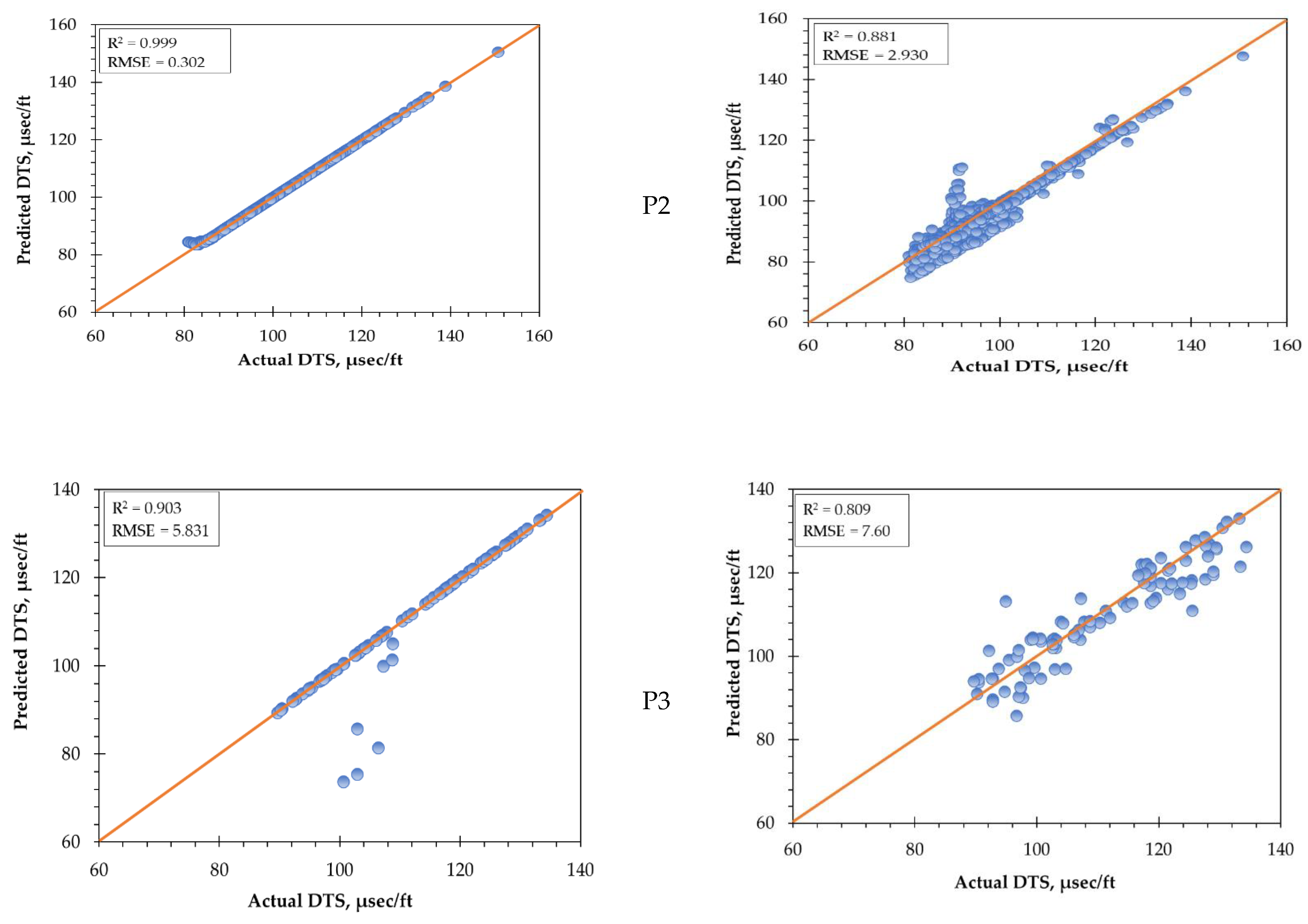
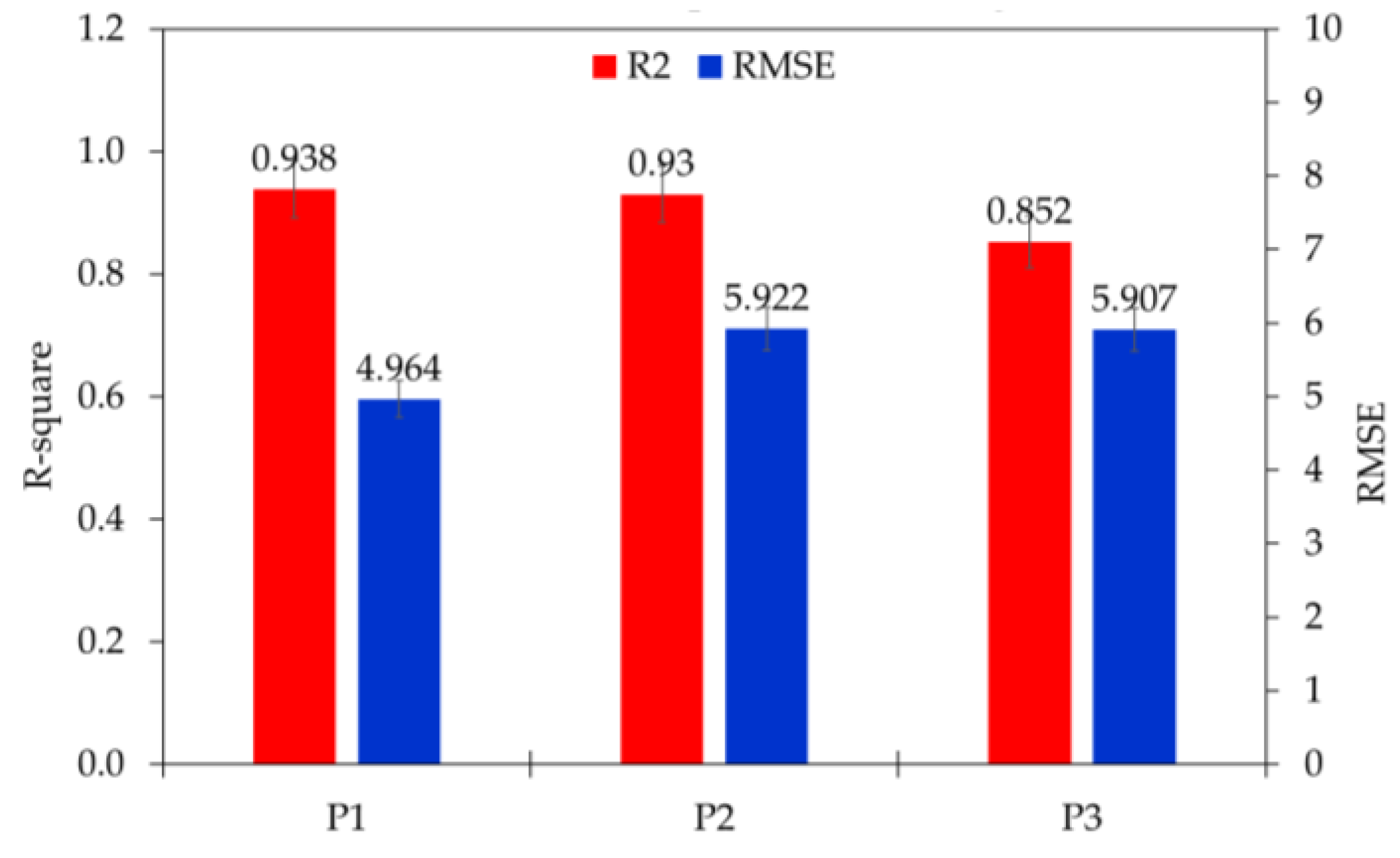
This study presented an open-source Python-based Keras machine learning and deep learning application. Two statistical parameters were employed to compute and measure the target and estimated value, accuracy (R
2) and root mean square error (RMSE) [
49]. These parameters can be expressed by Equations (1) and (2):
where
is the original value; predicted value is
, and
is the arithmetic average of all original values.



 ,
, 





















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}