1. Introduction
It is well documented that the power supply system is a composite network comprising several customers, i.e., residential, industrial, etc., operating at distinct voltage levels [
1,
2]. This distinct voltage level is facilitated using power and distribution transformers [
2]. Consequently, the high degree of operational reliability and lucrative operation of the electrical transformers and, thereby, the power system are of considerable engineering significance. It is recognized that the performance and planned life span of a transformer is assignable to the decomposition of the dielectric system [
3]. Moreover, this chain of events requires efficacious condition-monitoring procedures and diagnostic tools. For this reason, condition monitoring of dielectric oil and cellulosic paper insulation is an absolute priority to achieve a planned operational lifetime and to evade destructive failures of electrical transformers. Dissolved gas analysis (DGA) is a robust and generally acknowledged diagnostic tool in the transformer manufacturing industry. This is because DGA has the potential to divulge the electrical and thermal stresses predominating with transformer dielectric oil and cellulosic paper insulation. Prospective examination approaches for DGA fault diagnosis are reported in [
4]. By and large, DGA fault diagnostic methods demonstrate high equivocation in examining the fault gases, given the nonlinear comportment of the fault gases and various problems with DGA fault diagnosis methods. The production of dissolved gases has a nonsequential connection with transformer duration of operation and insulation aging indicators, i.e., interfacial tension, furan, acidity, etc. [
5]. This nonsequential comportment gives rise to intricacy in fault recognition when artificial intelligence algorithms are employed.
A handful of investigators have employed diverse intelligent methods comprising artificial neural networks (ANNs), fuzzy logic (FL), decision trees, etc. for diagnosing DGA faults [
6,
7]. As a result of the dubious accuracy and high equivocation in the classification of DGA faults, modern computational methods have been reported in recent years. These methods comprise machine learning algorithms and optimization algorithms. It is recognized that multidimensional and astronomical data samples are necessitated for training these algorithms to be efficacious. A handful of researchers have adopted these algorithms for diagnosing transformer DGA faults [
8,
9,
10].
The current research contribution—This work presents a detailed investigation of transformer fault identification. Various open issues and research challenges in transformer fault identification using classical methods have been highlighted. The contributions of this research work are indicated as follows.
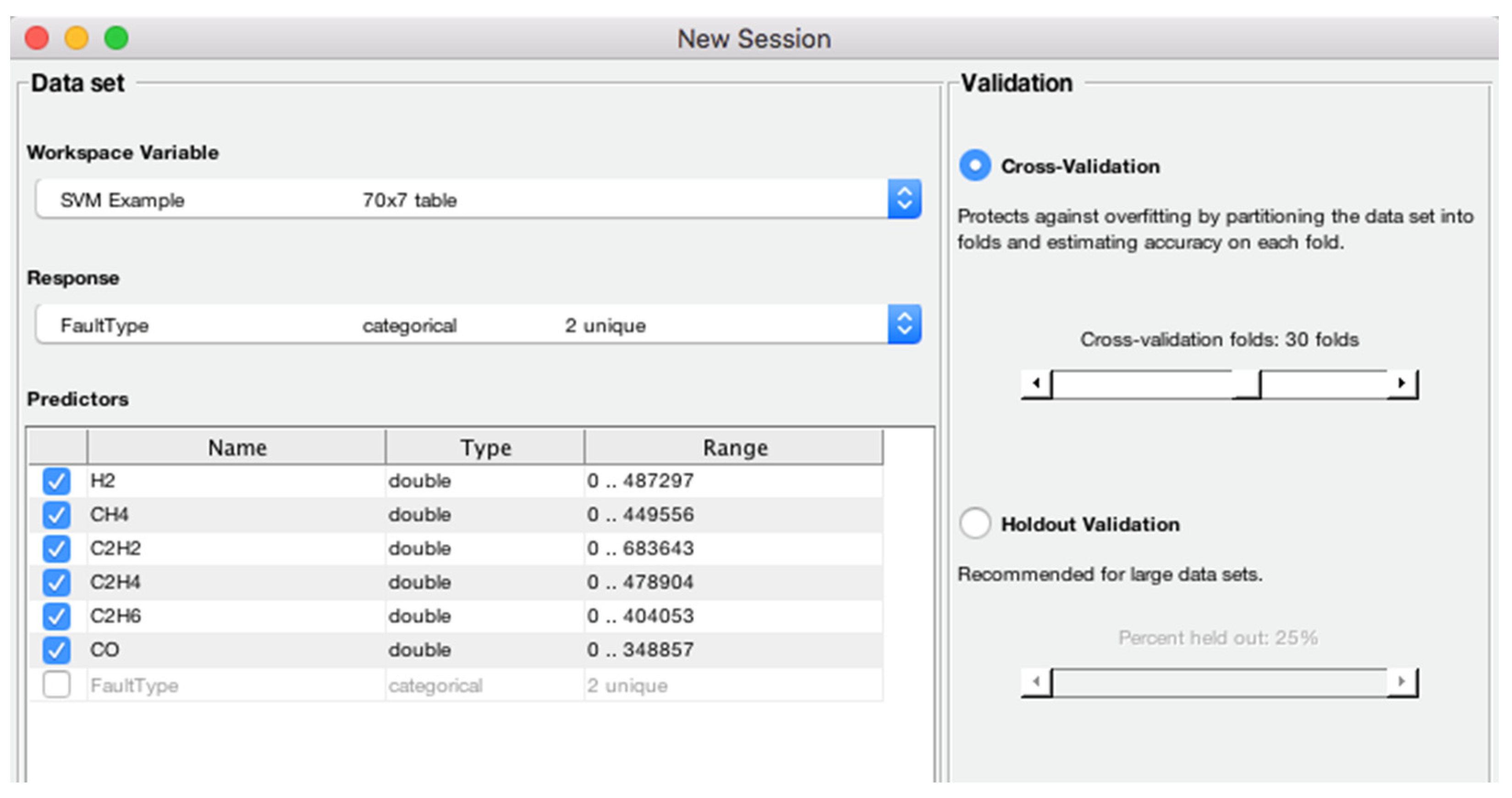
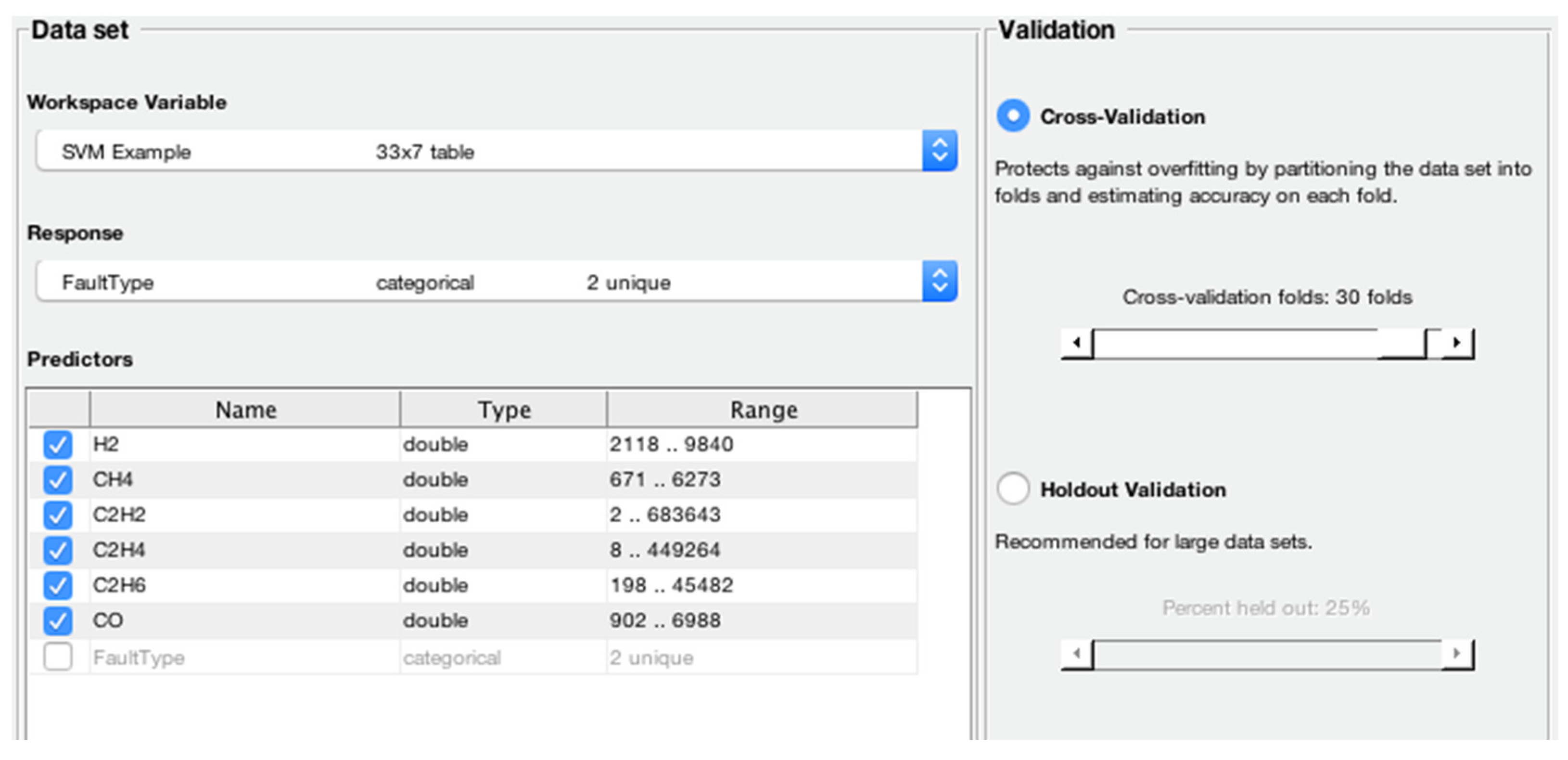
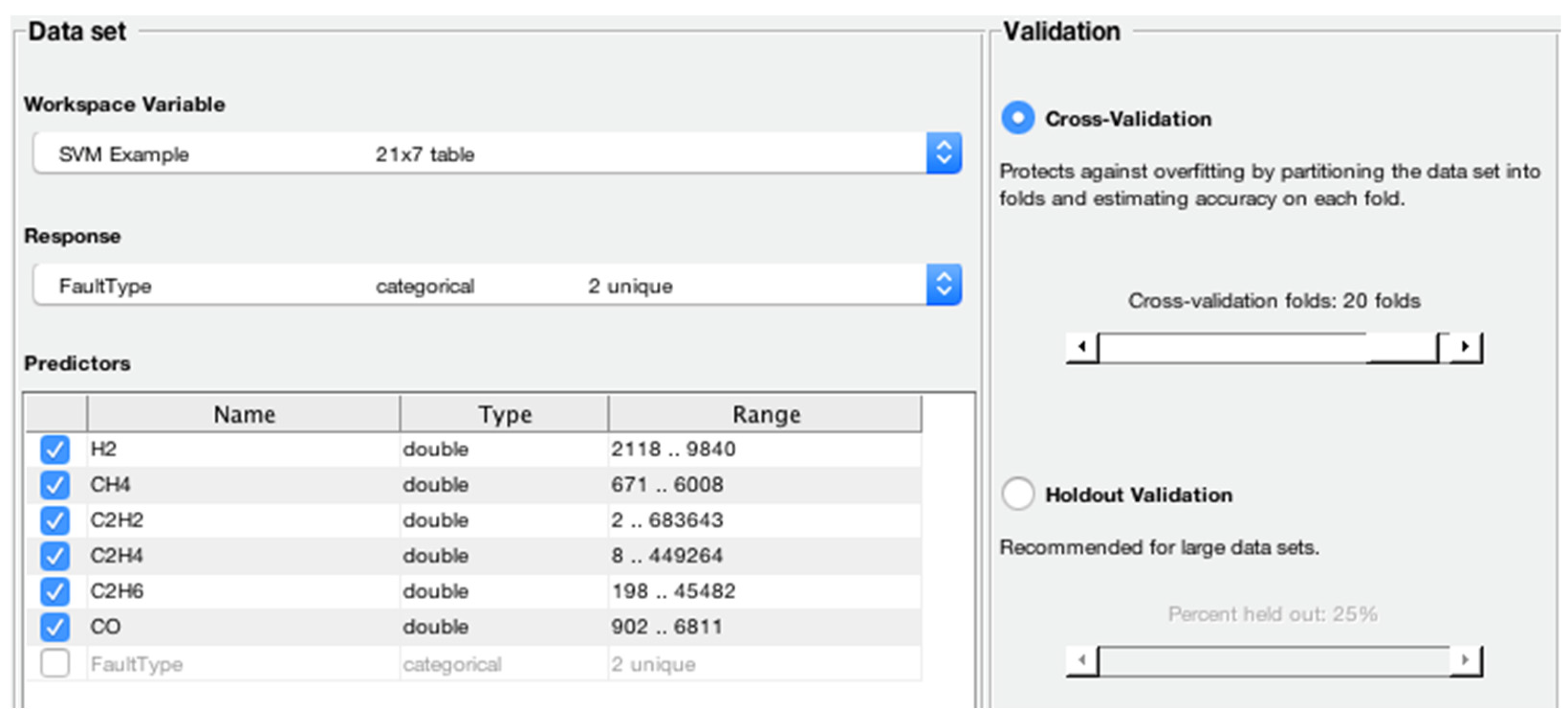
A BCSVM is proposed for identifying a set of five transformer faults using 70% of the oil samples for training and 30% for training the proposed model, with 30-fold cross-validation applied in the training dataset. The proposed approach yields higher accuracy than ANN and the IEC method.
The classification accuracy of the considered DGA samples is investigated by considering various machine learning algorithms, i.e., linear SVM, quadratic SVM, cubic SVM, fine Gaussian SVM, medium Gaussian SVM, and coarse Gaussian SVM, and comparing them in terms of accuracy (in percentage), prediction speed (objects/second) and training time (in seconds).
A case study based on 14 transformer samples is presented using practical DGA data sets supplied by a South African manufacturer to comprehend fault classification proficiency in terms of accuracy of ANN and IEC methods and practical data versus the accuracy obtained in recent works.
The novelty of the current research—The fundamental purpose of this study is to ascertain a reliable transformer fault diagnosis approach using DGA and the application of the artificial intelligence technique for fault diagnosis in power transformers. Notwithstanding that numerous research workers have worked on the application of AI to diagnose transformer faults, as shown in
Table 1, very seldom has research been published on fault diagnoses using BCSVM, particularly in transformer condition assessment. A reliable fault classification and prediction algorithm are crucial criteria for developing an efficient fault identification system. Three methods are considered a benchmark of the proposed method, and it was found that the IECGR method yields a “not detectable” response to some of the set of studied case studies and ANN yields a higher fault class than the actual fault in some oil samples due to model overfitting. However after the application of the proposed BCSVM algorithm, the “not detectable” samples were effectively identified.
Many works compared the classical DGA methods in their investigations. Though there is similar work, in the current investigation, various machine learning (ML) algorithms, i.e., linear SVM, quadratic SVM, cubic SVM, fine Gaussian SVM, medium Gaussian SVM, and coarse Gaussian SVM, are compared in terms of accuracy (%), prediction Speed (objects/sec) and training time (sec). In the current study, the effect of the dissolved gas concentration levels is studied exclusively. This parameter is adopted for examining the performance of ML algorithms and two different diagnostic methods. From this investigation, it may be concluded that the proposed BCSVM algorithm is reliable in accurately diagnosing transformer faults using dissolved gas concentration levels in parts per million (ppm).
The manuscript organization—This research has been structured as follows.
Section 2 presents the fundamental principle of the SVM algorithm and proposed BCSVM.
Section 3 presents the results and discussion of the proposed algorithm for fault diagnosis of transformers. A corroboration of the proposed algorithm with the real sample datasets from local transformer companies in South Africa is presented. Lastly,
Section 4 provides a conclusion of the manuscript.
2. Materials and Methods
2.1. Transformer Fault Classification Procedure
Transformer faults can be recognized in conformity with the dissolved gases proliferated attributable to the heating of the dielectric oil and the gases that are prevailing at diverse temperatures, i.e., hydrogen (), carbon monoxide (), methane (), ethane (), ethylene (), acetylene (), and carbon dioxide (). Nevertheless, five gases, i.e., , , , , and , are considered in this research in classifying transformer faults. A set of five transformer conditions, including no fault (NF), partial discharge (PD), and thermal fault conditions, are discerned.
2.2. The Fundamental Principle of the SVM Algorithm
SVM is a vigorous supervised learning technique for developing a dataset classifier. SVM purports to establish a decision boundary among two classes of datasets that facilitate the forecasting of data labels from one or several feature vectors [
11,
12,
13,
14,
15,
16,
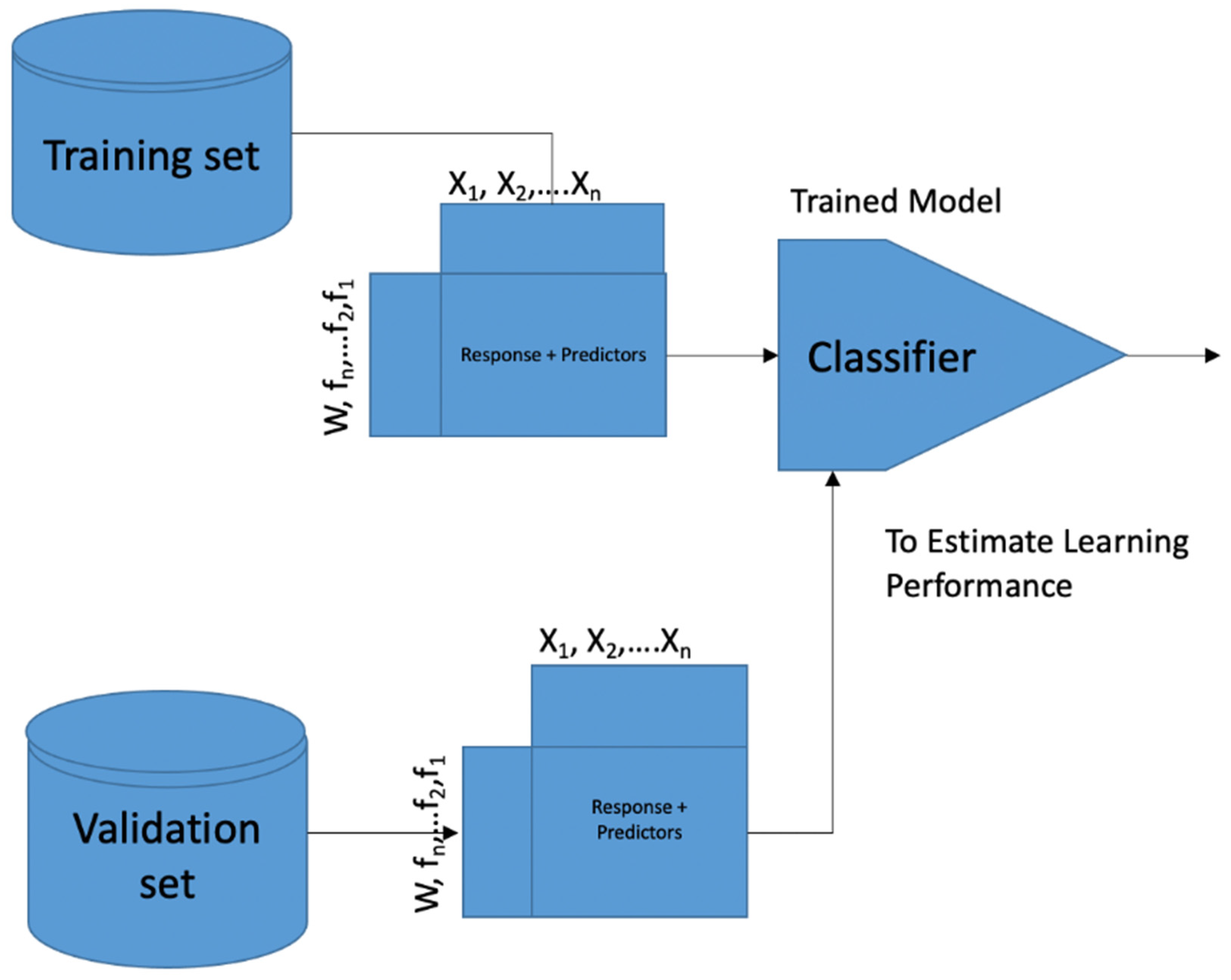
17]. A decision boundary can be described as the area of a problem space whereupon the output dataset label of a classifier is equivocal. This decision boundary is referred to as the hyperplane, and it is positioned such that it is furthest from the nearest datasets from other classes. These nearest data points are so-called support vectors. The learning procedure of the SVM is illustrated in
Figure 1. The SVM learns based on the training dataset entered. Then, the validation dataset is applied to determine the learning performance of the trained SVM algorithm. The trained SVM algorithm model is then applied to classifying samples of unknown test datasets.
Considering a tagged SVM training dataset, the latter can be expressed as follows in Equation (1).
Here,
Training compound
Feature vector (predictors)
Class label
An optimal hyperplane can therefore be expressed as follows in Equation (2).
Here,
Weight vector
Input feature vector,
is the bias.
For all elements of the training dataset, the values of
and
must fulfill the conditions of the inequalities expressed in Equations (3) and (4).
The purpose of training an SVM algorithm is to ascertain the
and
such that the hyperplane isolates the data points and makes the best use of the margin
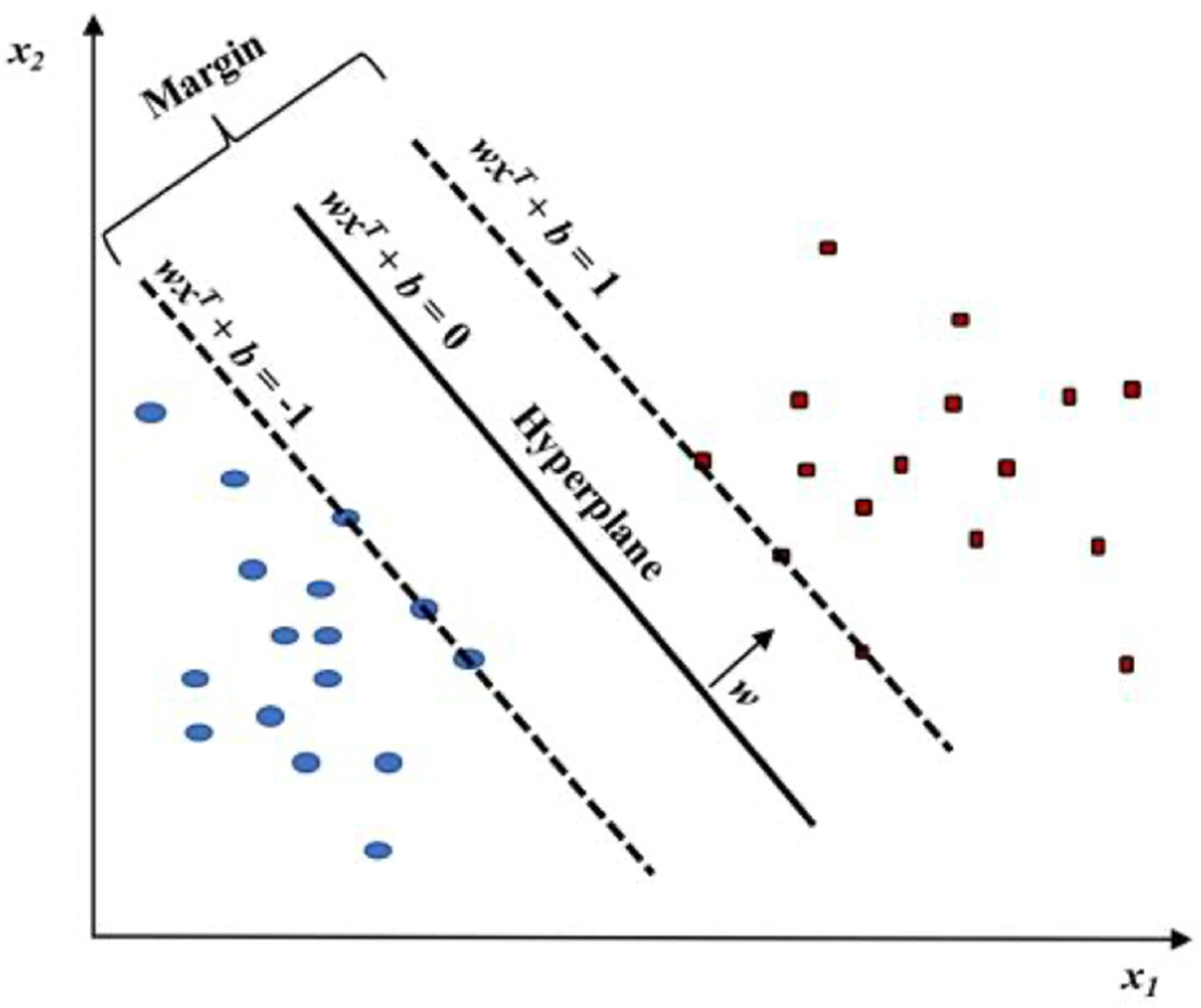
. In
Figure 2, the vectors
with the property that
= 1 will be appellate as support vectors [
12].
An alternative to a linear SVM classifier for the nonlinear application of the SVM is the kernel technique, which allows the modelling of higher dimensional and nonlinear models [
11,
12,
13,
14,
15,
16]. For a nonlinear problem, a kernel function can be employed to append supplemental dimensions to the coarse data and therefore create a linear problem in the eventuating higher dimensional space. In a nutshell, a kernel function, which is expressed as shown in Equation (5), can facilitate carrying computations rapidly, which would in other respects necessitate high dimensional space computations.
Here,
Kernel function
dimensional inputs
Map function of the input from dimensional to dimensional space
Indicate the dot product
Using kernel functions, the computation of the scalar product of data points in a higher dimensional space except specifically evaluating the mapping from the input space to the higher dimensional space can be conducted. In many instances, calculating the kernel is straightforward whereas in the high dimensional space, calculating the inner product of feature vectors is complex. The feature vector for even straightforward kernels can inflate in dimensions, and kernels such as the radial basis function (RBF) kernel can be expressed as follows in Equation (6).
The proportionate feature vector is incalculable dimensionally. Even so, calculating the kernel is nearly insignificant. Contingent on the essence of the problem, it is likely that one kernel can be a whole lot better than other kernels. An optimum kernel function can be chosen from an established set of kernels numerically in an extremely thorough and careful manner by applying cross-validation.
2.3. Proposed BCSVM Algorithm
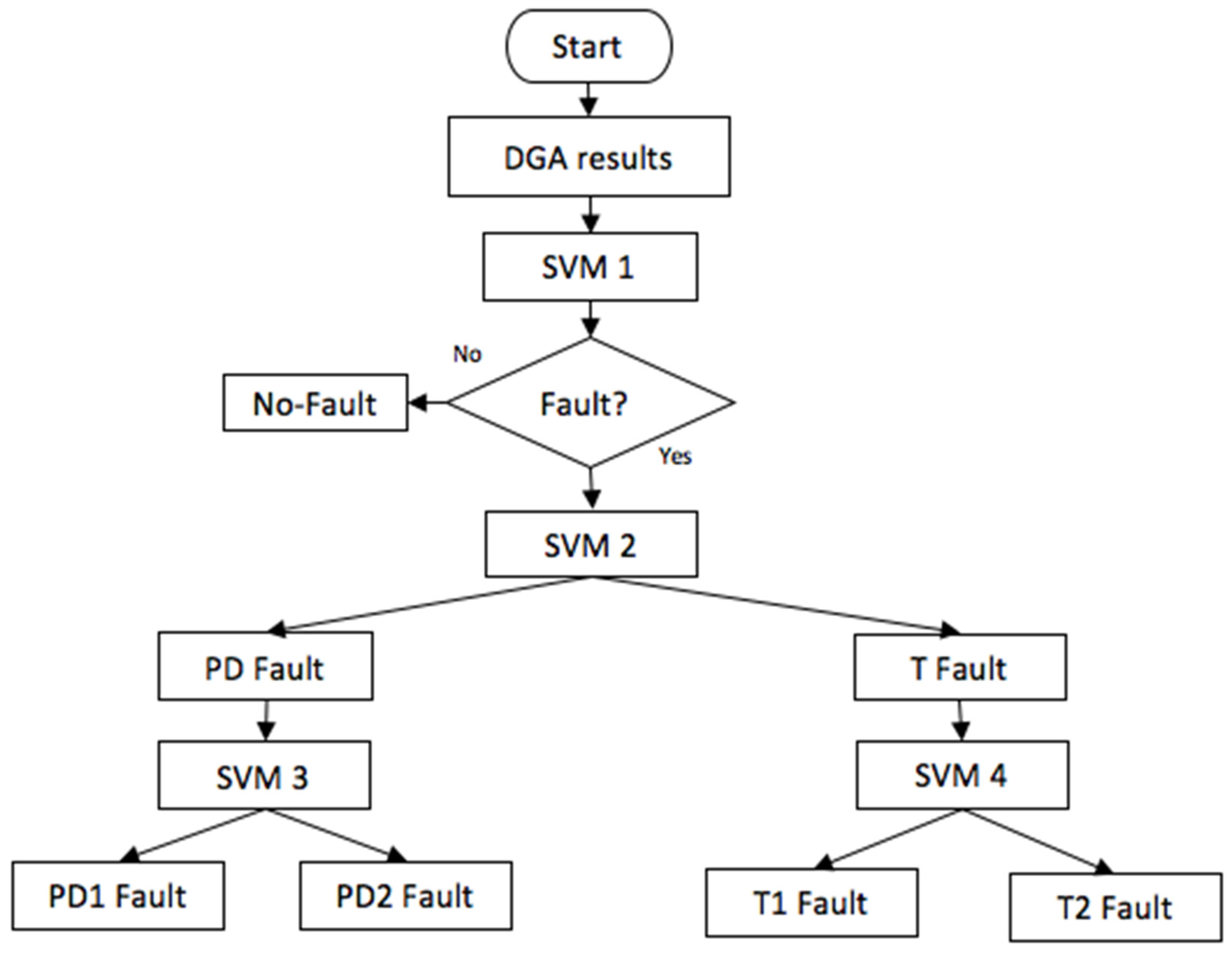
In the current study, DGA oil samples were obtained from mineral oil-immersed transformers in the field owned by different local independent power utilities. The comprehensive flow diagram of the proposed BCSVM is illustrated in
Figure 3.
Initially, the concentration levels of five feature gases are ingested as inputs to the first SVM (SVM 1). It will distinguish whether the oil samples represent a normal or faulty condition. If the sample is in normal condition, the algorithm ends.
Secondly, if the SVM1 output has identified a fault condition, it is further ingested as input to the second SMV (SVM 2) which then distinguishes whether the fault is a thermal fault class or an electric discharge fault.
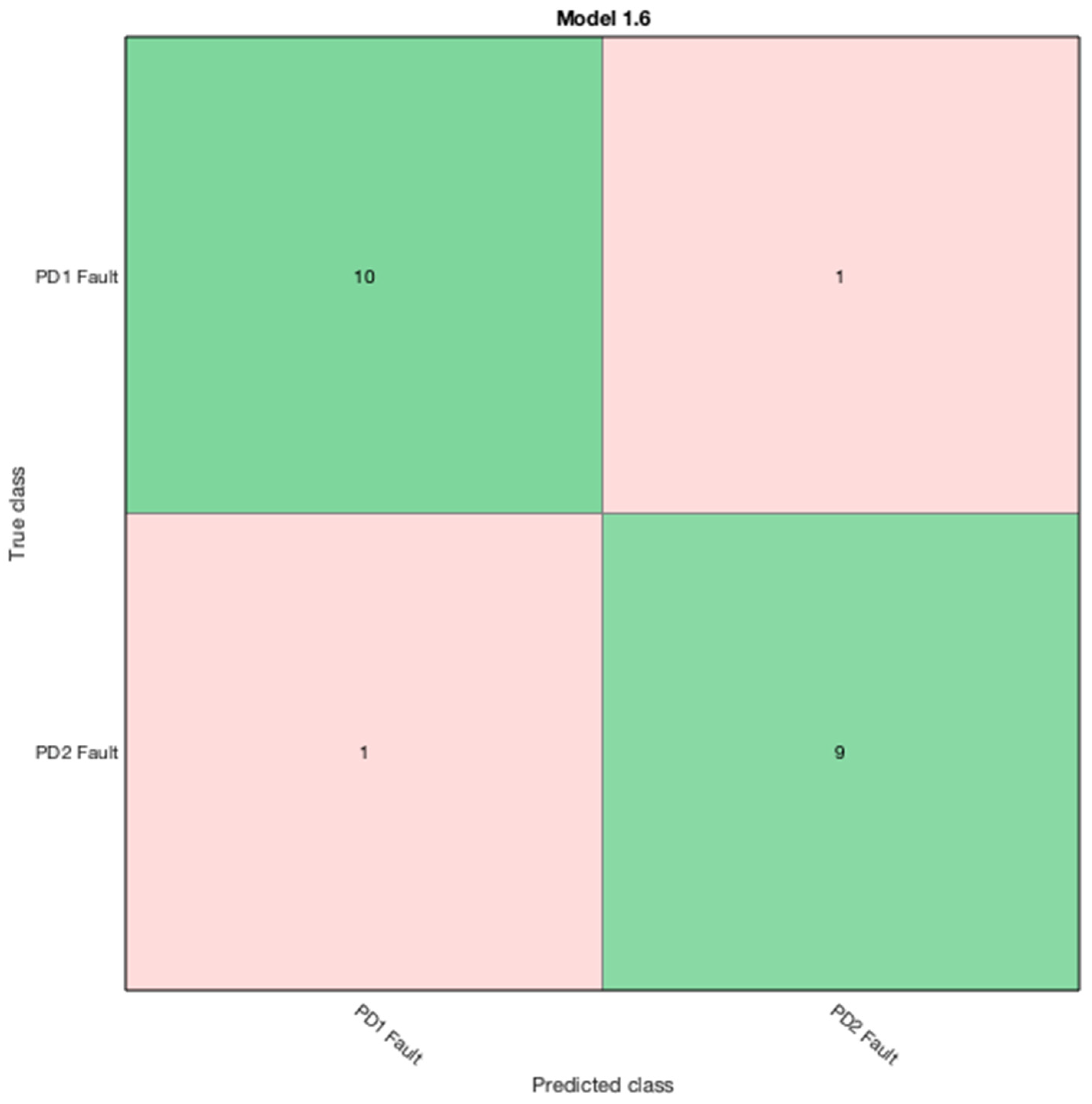
Thirdly, if the fault class is pigeonholed as a PD fault, then it will be ingested as input to the third SVM (SVM 3), which will then distinguish whether the fault is PD1 or PD2.
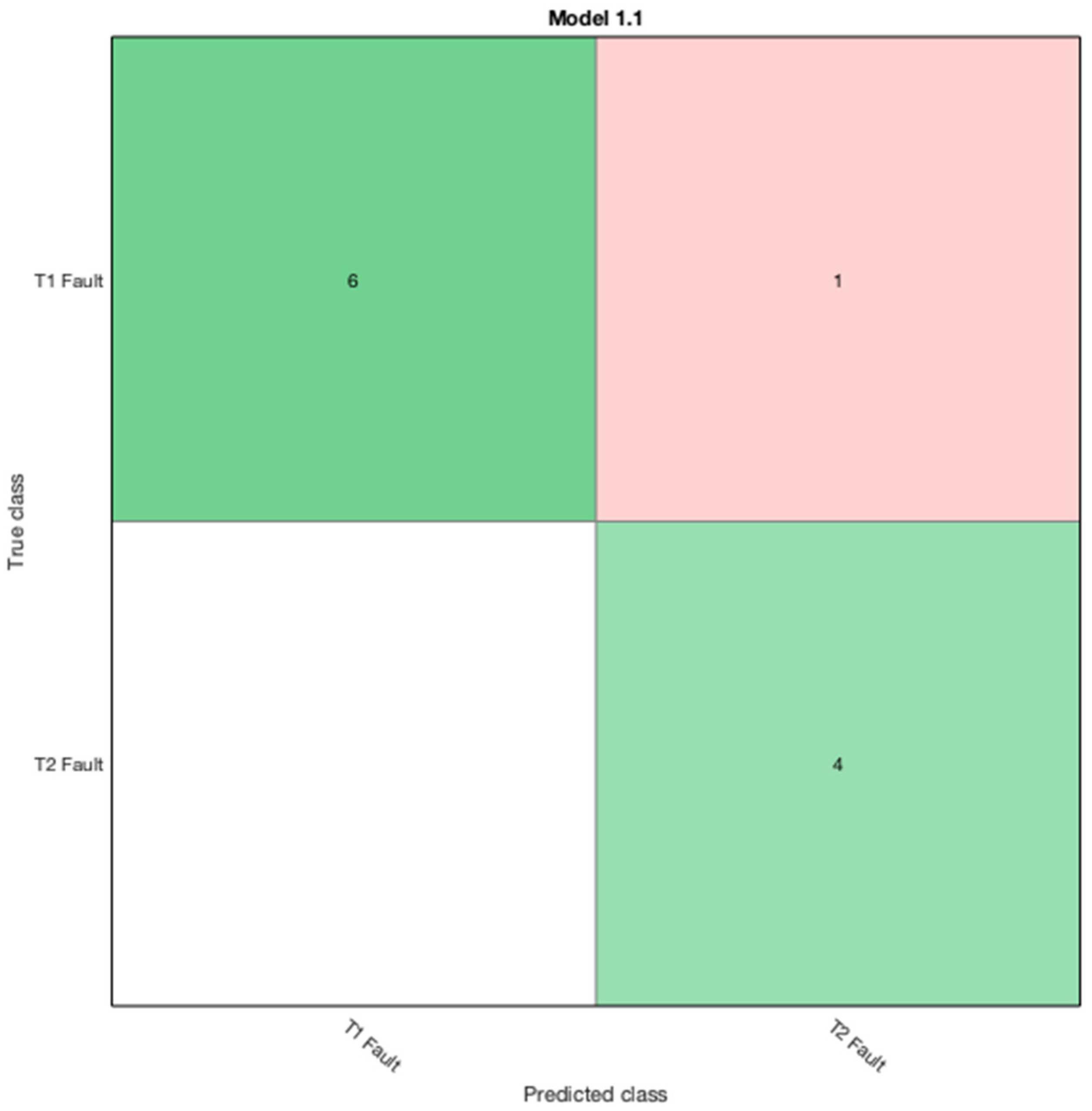
At the same time, if the fault is categorized as a thermal (T) fault, then it will be ingested as input to the fourth SVM (SVM 4) which will distinguish whether the fault is a T1 or T2 fault as demonstrated.
To evaluate the statistical significance of the experimental DGA dataset, a single-factor ANOVA was employed. The results are illustrated in
Table 2.
It can be observed from the p-value of 9.1433 × 10−5 (<α = 0.05), that the experimental DGA results are statistically significant.
The sensitivity analysis of the input gases was carried out by adopting descriptive statistics analysis (DSSA), as shown in
Table 3. DSSA examines the quantitative performance of the input dataset features.
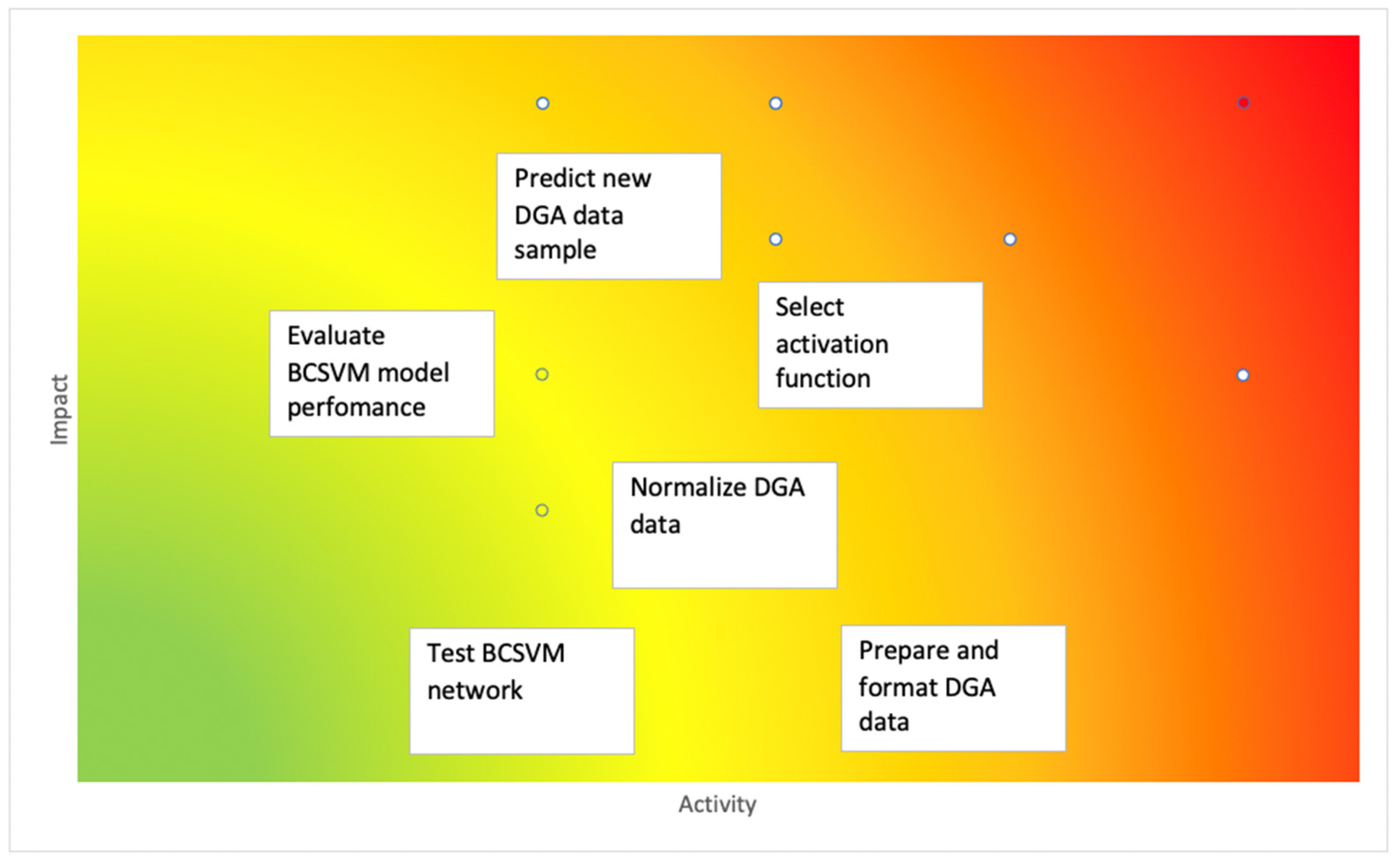
The complexity of the proposed solution design is demonstrated in
Figure 4. The latter is partially based upon the related state of the problem diagnosing transformer faults and solution of DGA and artificial intelligence knowledge. Additionally, this can be illustrated in terms of a solution design complexity heatmap comprising all the main activities undertaken.
The red regions reveal locales of conceivably sheer complexity. The green regions denote locales of conceivably little complexity.
4. Case Studies
In this section, various transformer case studies are presented to corroborate the efficacy of the proposed BCSVM algorithm in identifying faults of an unknown dataset to the proposed algorithm learning process. The training and testing of the datasets were not examined from the same utility. The training data adopted from service field oil sample data and the testing oil sample dataset were established by physical unit inspection, as shown in
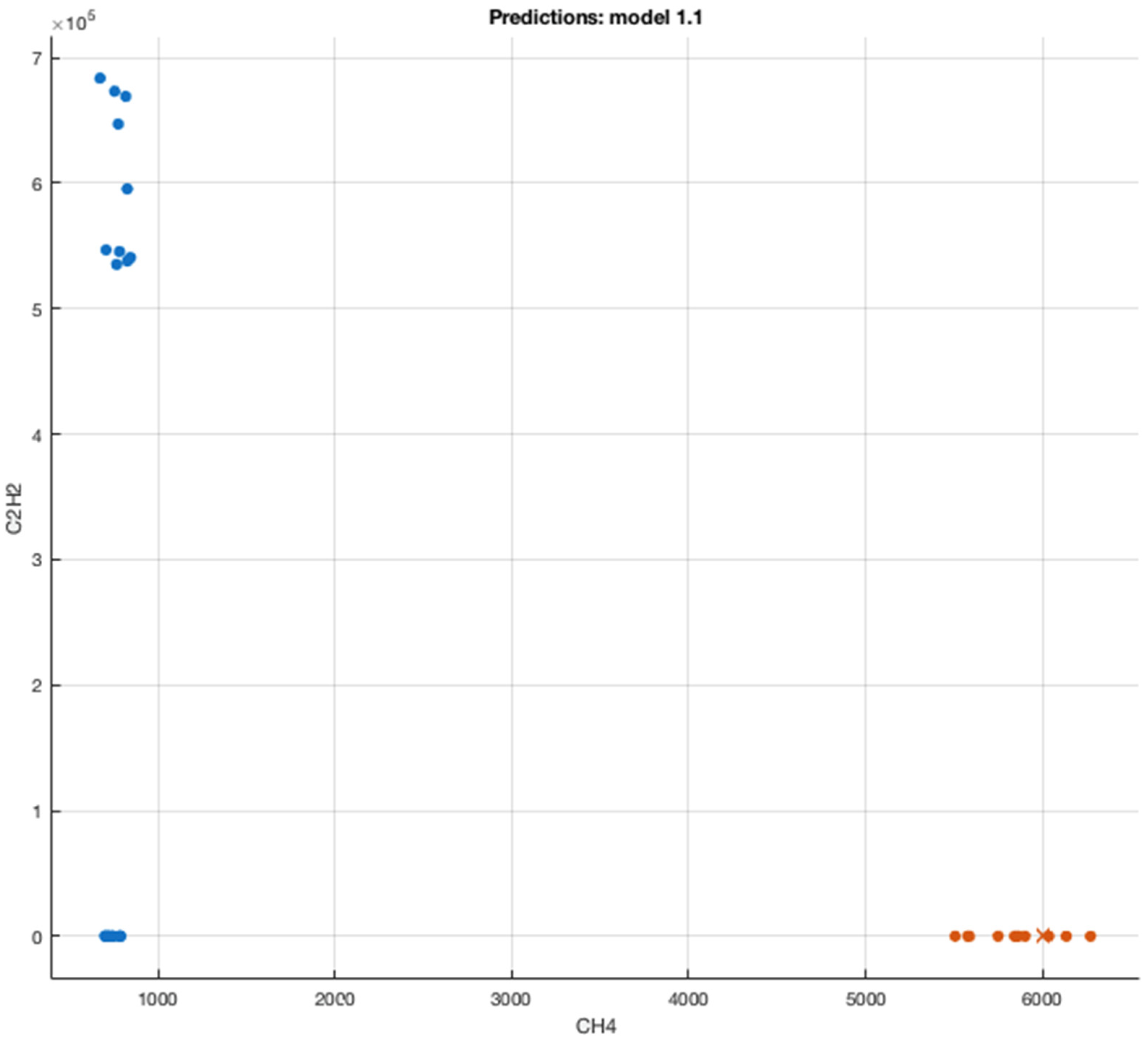
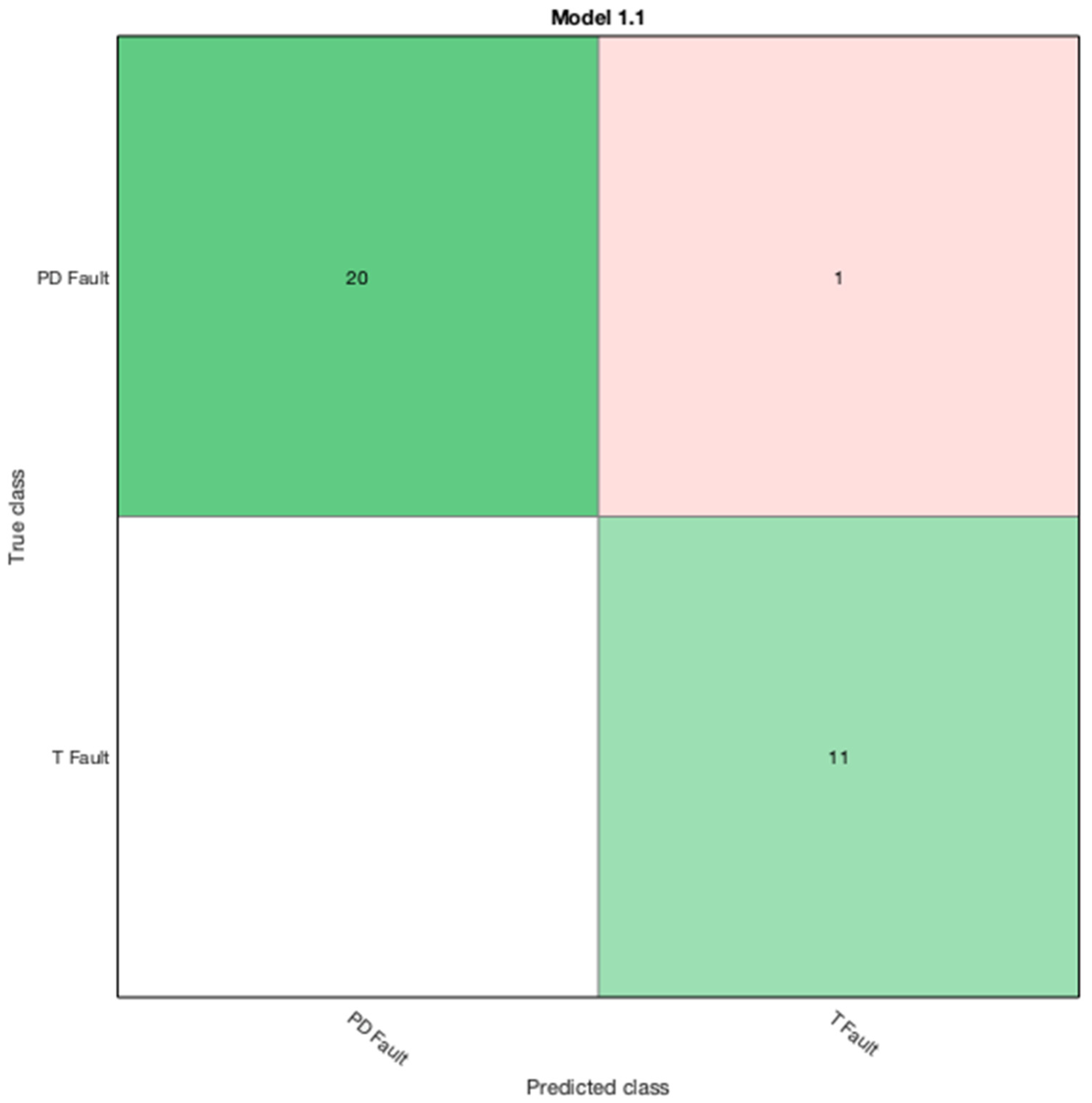
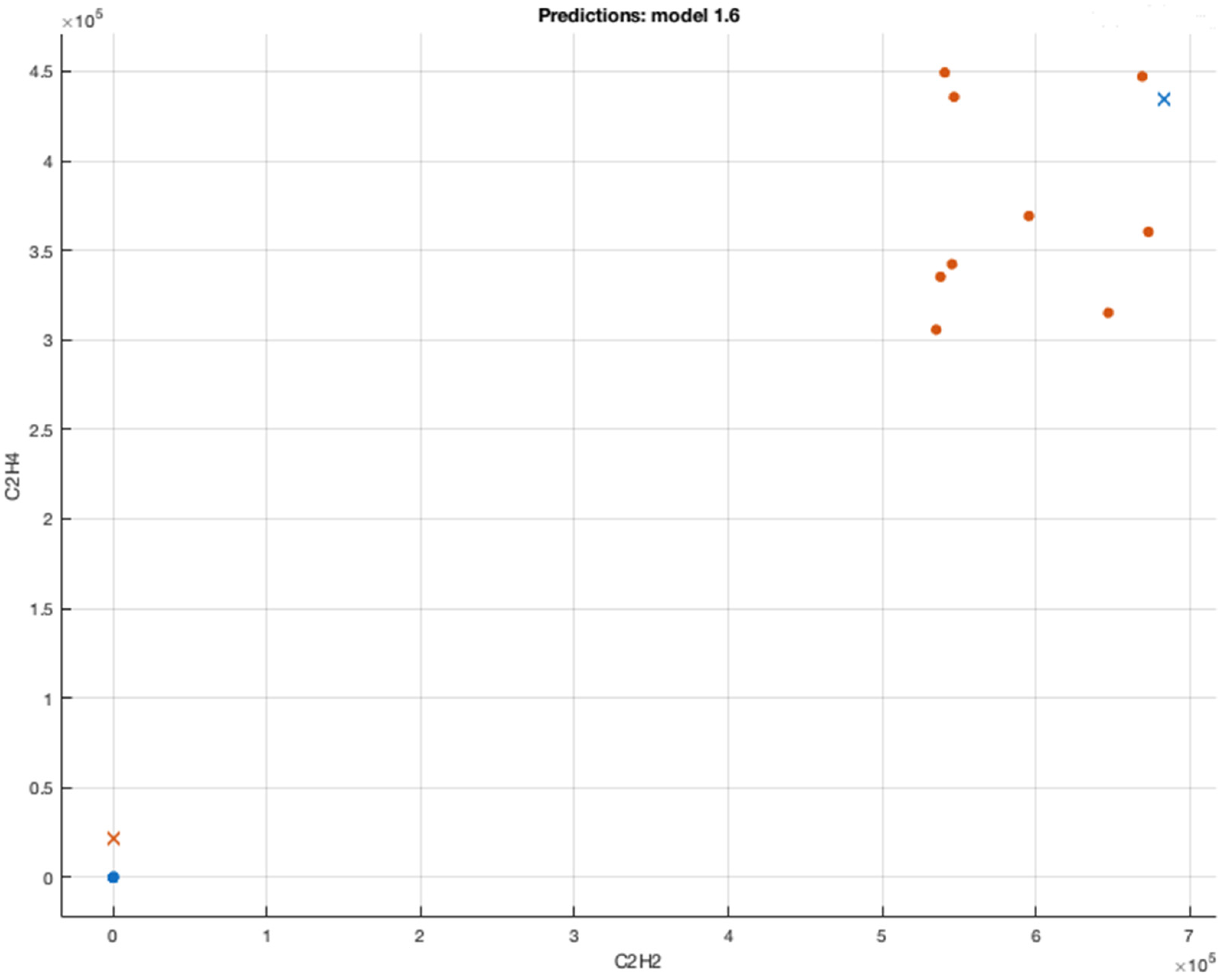
Table 6. The latter will be an opportunity for examination of the proposed algorithm in a more indubitable approach and realizing the capability to development of an efficacious ML algorithm for field data enactment. In the proposed approach, six ML algorithms are assessed for examining the correlation between the response and predictors.
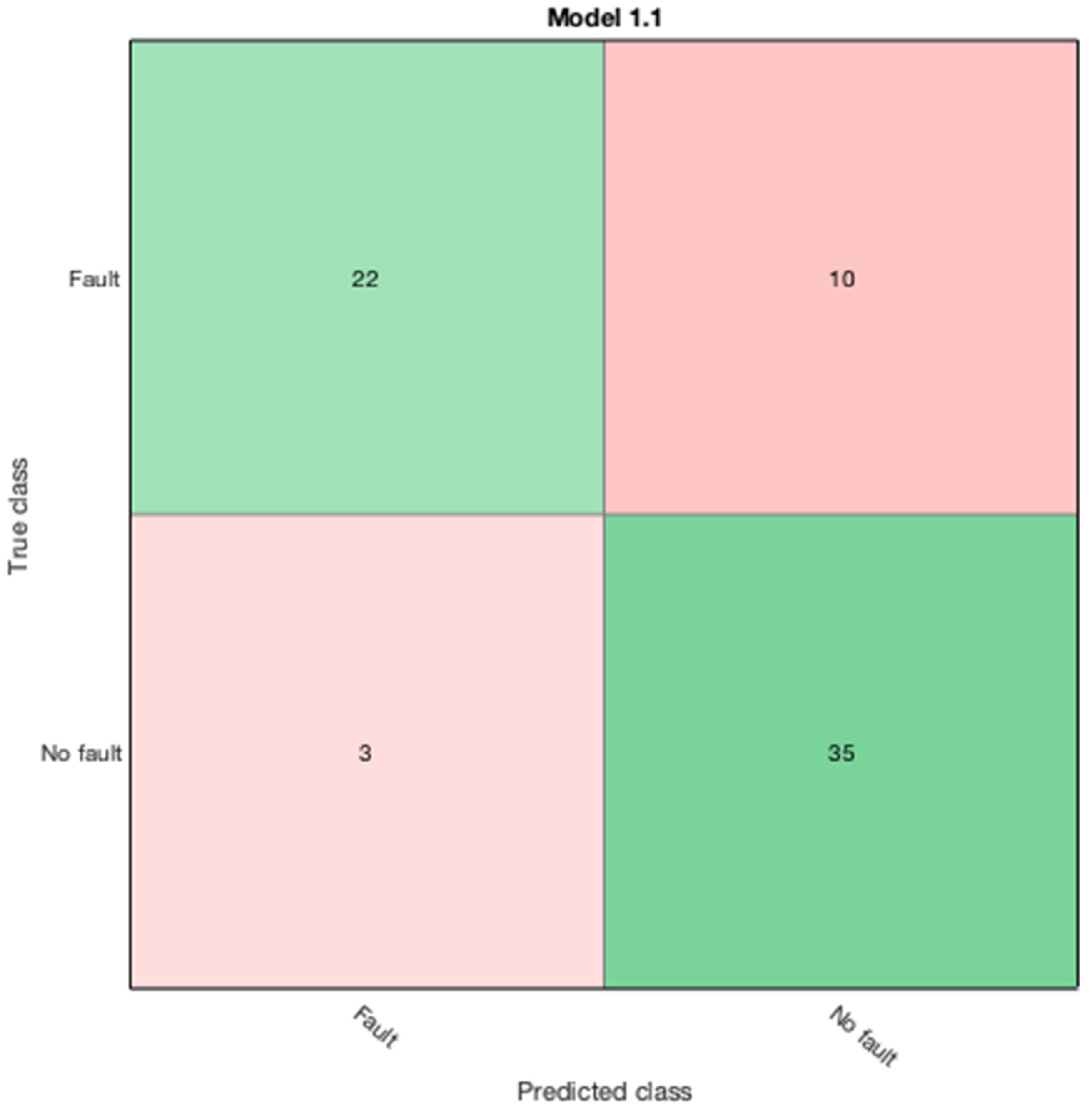
The proposed BCSVM is evaluated in
Table 8 against the actual, ANN and IECGR techniques on a set of transformers’ DGA data that was not included in the training of the proposed algorithm. A major strength of BCSVM is the 30-fold cross-validation performance to circumvent overfitting problems.
From
Table 6, it is observed that the fault class tag T2 has low accuracy against the actual data. Intriguingly, all other fault class tags performed well in the context of accuracy. Additionally, the IECGR was unable to conclusively diagnose some of the faults due to the limitations of the code ratios. Further, the proposed technique constitutes proof that it can be reliably applied in the prediction of unknown oil sample datasets, predicting all the case studies accurately.
5. Conclusions
The BCSVM construction for fault diagnosis of power transformers has been represented. Several faults are unpredictable by the IEC gas ratio (IECGR) method, which results in an undetectable conclusion. When using ANN, given that it is excellent at learning, the restraint of the inability of fuzzy logic to adapt the created rule base with the varying system for indivisible and irregular data is eradicated. Nonetheless, ANN has the hindrance of overfitting; therefore, it has lower generalization capability and provides circumscribed precision to fault identification. To circumvent all these challenges, in this work, power transformer fault identification was conducted by employing a binary classification support vector machine (BCSVM). The case study results demonstrate that the proposed BCSVM technique has a higher degree of diagnostic accuracy than the IECGR and ANN methods owing to its enhanced generalization capability, and it can classify indivisible DGA datasets by utilizing the kernel function.























{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}