
Automated Detection of Electric Energy Consumption Load Profile Patterns


Abstract
:1. Introduction
- Initially, the expert or data analyst studies the dataset and makes an assumption or states a hypothesis regarding the objective of the knowledge discovery process, or the model or relationship that may be found among the different variables or features of the data objects. The subsequent analysis of the data will be based on these initial hypotheses, which would at the end be validated upon the results obtained, or not. If the results are not satisfactory, the expert will perform new assumptions or hypotheses, therefore starting the KDD process again.
- Then, the data warehousing process [5] is performed. This step of the analysis comprises all the techniques and procedures to process erroneous or missing values in the data, filter noise, produce specific queries to access the data, and rearrange the information in the desired format to be analysed.
- Then, the selected data mining technique or techniques are applied, with the objective of extracting valuable relations or information from the data, in the form of patterns, models, association rules or other things.
- The next step is the visualisation of results, along with numerical and/or categorical indicators and information to help the expert to identify and evaluate the results.
- Finally, the expert has to perform an interpretation of the results. In this step, the expert will validate the initial hypothesis made concerning the underneath models or patterns able to summarize the data, obtain conclusions and extract knowledge from the results. In the case these results are not satisfactory, new hypotheses can be formulated, which will imply the need for further data mining analyses, therefore starting the KDD process again.
2. Clustering Techniques
2.1. Taxonomy of Clustering Techniques
- The dynamic nature of data and classes. This criterion classifies algorithms based on whether they are designed for dynamic or static data, and for a fixed or time-varying number of classes.
- The way the data are analysed. This criterion classifies the algorithms according to the strategy or technique they use to analyse the data, and specifically if they carry out an initial transformation of the same into another set of data on which they perform the analysis.
- The number of dimensions or characteristics of the data. This criterion classifies algorithms according to the number of dimensions of the data they analyse.
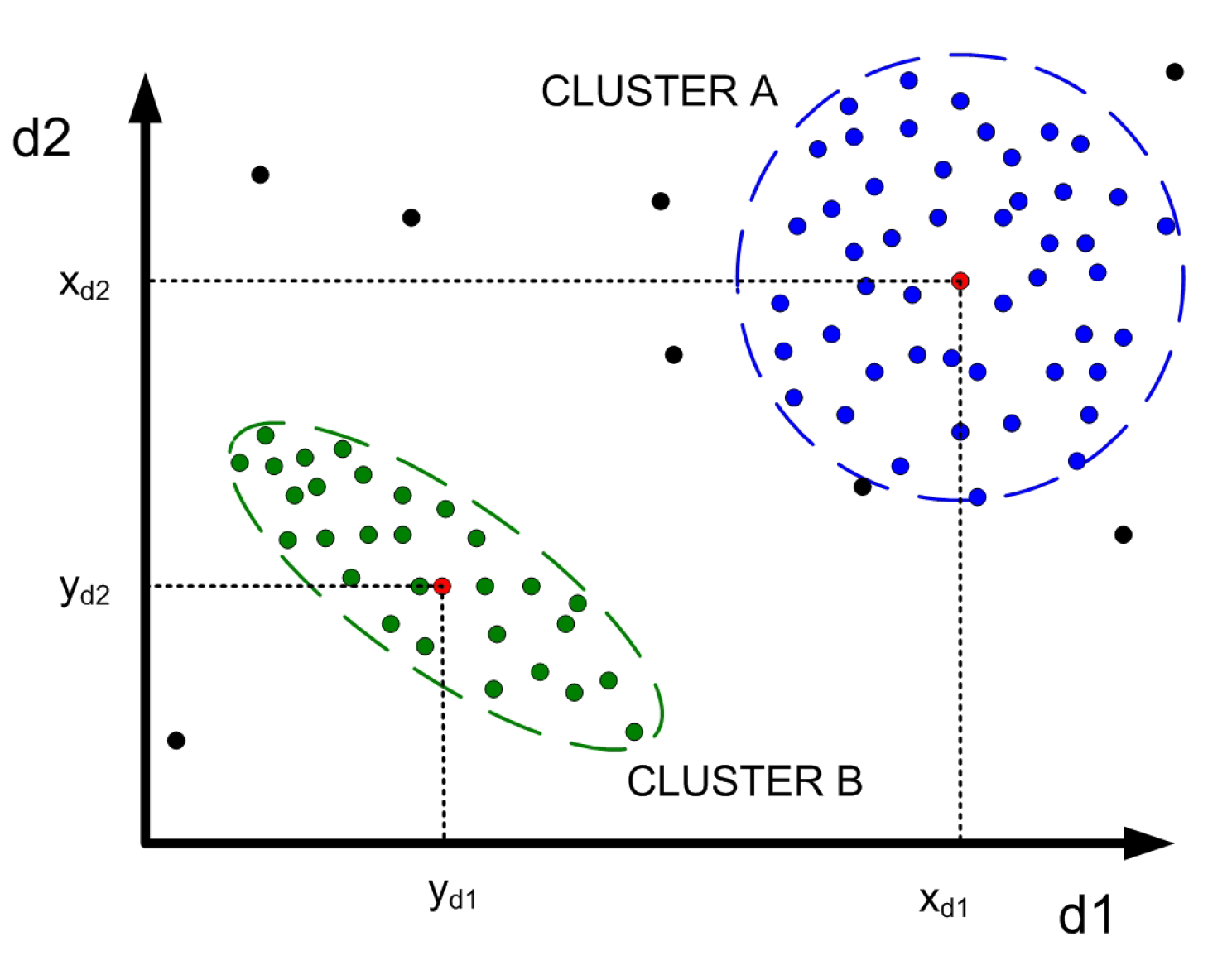
- The data, although they can be time series, are treated as static. The segmentation algorithms are therefore focused on static analysis. This is the case of the example shown in Figure 1.
- While they can be time series, the data are treated as static. The number of classes, however, is variable. This is the case when the database is partitioned and batch processed sequentially, as the example in Figure 2 indicates. With each batch the number of classes may vary, showing a variation in the trend of the data and its composition. Therefore, it is necessary to implement techniques that make a correspondence between the classes of one batch and the next [9], taking into account the possibility of the formation of new classes, the disappearance of classes that had been formed previously, the merge of two or more classes, and the separation of a class into smaller classes.
- The data is treated as dynamic, varying with time; therefore the objects become trajectories of each characteristic of the object or data. The number of classes is fixed. The resulting centroids are defined by the trajectories of their dimensions, which represent the evolution in time of the objects belonging to each class. An example of this segmentation analysis is shown in Figure 3.
- The data is treated as dynamic, varying over time, as in Type 3. The number of classes is not fixed, and can vary with each batch or cycle. Therefore, the same techniques for Type 2 must be taken into account. Figure 4 shows an example of this type of analysis.
2.2. Similarity for Static Data
- If the objects include qualitative features or values selected from a list of categories, then previously described quantitative distances are not suitable to evaluate the similarity among the objects. In this case, a specific distance for qualitative data similarity must be used. For example, a measure can be used from the matching or coincident coefficient family of distances, which can only take two possible values (0 or 1) if the characteristics of both objects are coincident or not. Two of these distance measures are the simple matching coefficient [10], and the Jaccard distance [11].
- If all the characteristics or dimensions of the objects are quantitative or numerical, then quantitative similarity measures can be used, and the two more used are described next.
2.2.1. The Minkowski Metric
2.2.2. The Mahalanobis Distance
2.2.3. Selection of a Suitable Distance Measure
2.3. Similarity for Dynamic Data: Time Series Clustering
2.3.1. Correlation
2.3.2. Dynamic Time Warping
- Delimitation: This condition establishes the principle and the end of the alignment in the vertices of the matrix , i.e., and .
- Continuity: Given and , then 1 and 1. This condition ensures that the elements of the alignment are adjacent.
- Monotonicity: Given and , then and , having to fulfil at least a strict inequality. This condition forces the alignment to advance towards the vertex of the matrix of distances.
2.3.3. Kullback–Leibler Distance
2.3.4. Other Similarity Measures for Dynamic Data
3. Clustering Algorithms for Static Analysis
3.1. K-Means
- Select c objects of the dataset, which will be the initial centroids. This selection influences the final result. Therefore, a suitable representation of the existing patterns must be done for the algorithm convergence to a global optimum [6]. In order to do so, a heuristic selection or based on previous knowledge of the patterns must be done, or algorithms adapted for the initial selection of prototypes can be used, such as the algorithm K-means ++ [24].
- Compute all the Euclidean distances of the remaining objects to the centroids, and assign each object to the cluster with a lower distance.
- Recompute centroids as the mean value of all the objects belonging to each class.
- Go back to step 2, until some ending condition is fulfilled, like achieving a maximum number of iterations, or that the value of the cost function does not vary above some predefined threshold between two consecutive iterations.
3.2. Fuzzy C-Means (FCM)
- Initialise fuzzy membership matrix U with random values.
- Calculate the centroids as described in (16).
- Calculate the distances of objects to the centroids of each class, according to the measure of similarity described in (14).
- Recompute fuzzy membership matrix U, according to (15).
- Go back to step 2, until some ending condition is fulfilled, like achieving a maximum number of iterations, or that the value of the fuzzy memberships do not vary above some predefined threshold between two consecutive iterations.
3.3. Selection of the Static Clustering Algorithm According to the Application
4. Clustering Algorithms for Dynamic Analysis
4.1. Raw Time Series Data Clustering
- Define the fuzzy membership function “almost zero” . This membership function is symmetric, and achieves the maximum value of 1 when x equals zero. The form of the function can vary, although Weber defines a Gaussian function whose value rapidly decreases as the value of x increases.
- Compute the similarity function between two trajectories f and g, as the fuzzification of the difference between them, i.e., .
- Compute the distance between the two trajectories f and g as the inverse of the similarity, i.e., 1.
4.2. Feature-Based Time Series Data Clustering
4.3. Model-Based Time Series Data Clustering
- The number of clusters in a partition.
- The structure for a given partition size.
- The HMM structure for each cluster.
- The parameters for each HMM structure.
4.4. Selection of the Dynamic Clustering Algorithm According to the Application
5. Comparative Analysis of Clustering Algorithms for Load Profile Pattern Analysis
5.1. Framework for Similarity Measures Comparison
5.2. Data and Analysis Description
5.3. Results
- The first type of client (see classes 1, 5, 6 and 8 in the Figure) represents the majority of energy consumption residential users in Spain. It is characterised by a daily profile of energy consumption with three ascending peaks of energy consumption: One in the morning (about 8:00), another one at lunchtime (about 15 h), and the highest one at night, at approximately 22:00. The clustering technique groups these clients according to the shape of these peaks and the energy consumption level. Therefore this type of clients can be represented by two or more clusters that group clients of low and medium energy consumption (500–1500 Wh maximum).
- The second type of client (see classes 4, 7, and 9) represents a minority of users with a high level of energy consumption through the day. There are two different patterns in this type of client: One with the typical shape of energy consumption, described above, but with higher energy levels (from 2500 to 7000 Wh), and another group of users that present (more or less) an elevated energy consumption through the day, or other non-typical patterns of energy use.
- The third type comprehends a small group of clients with a higher consumption of energy at night, due to thermal energy accumulators used mainly at night, or in valley hours where the price of the energy is cheaper.
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Mitra, S.; Pal, S.K.; Mitra, P. Data Mining in Soft Computing Framework: A Survey. IEEE Trans. Neural Netw. 2002, 13, 3–14. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Tsai, C.W.; Lai, C.F.; Chiang, M.C.; Yang, L. Data Mining for Internet of Things: A Survey. Commun. Surv. Tutor. 2014, 16, 77–97. [Google Scholar] [CrossRef]
- Herland, M.; Khoshgoftaar, T.M.; Wald, R. A review of data mining using Big Data in health informatics. J. Big Data 2014, 1, 2. [Google Scholar] [CrossRef] [Green Version]
- Han, J.; Kamber, M. Data Mining: Concepts and Techniques; Morgan Kaufmann: Burlington, MA, USA, 2006. [Google Scholar]
- Chaudhuri, S.; Dayal, U. An overview of data warehousing and OLAP technology. SIGMOD Rec. 1997, 26, 65–74. [Google Scholar] [CrossRef]
- Bishop, C.M. Pattern Recognition and Machine Learning (Information Science and Statistics); Springer New York, Inc.: Secaucus, NJ, USA, 2006. [Google Scholar]
- Wu, X.; Zhu, X.; Wu, G.Q.; Ding, W. Data mining with Big Data. Knowl. Data Eng. IEEE Trans. 2014, 26, 97–107. [Google Scholar]
- de Oliveira, J.V.; Pedrycz, W. (Eds.) Advances in Fuzzy Clustering and Its Applications; John Wiley & Sons, Ltd.: Hoboken, NJ, USA, 2007. [Google Scholar]
- Benítez, I.; Díez, J.L.; Albertos, P. Applying Dynamic Mining on Multi-Agent Systems. In Proceedings of the 17th World Congress, The International Federation of Automatic Control (IFAC), Seoul, Korea, 6–11 July 2008. [Google Scholar]
- Sokal, R.; Michener, C. A statistical method for evaluating systematic relationships. Univ. Kans. Sci. Bull. 1958, 38, 1409–1438. [Google Scholar]
- Sneath, P. Some thoughts on bacterial classification. J. Gen. Microbiol. 1957, 17, 184–200. [Google Scholar] [CrossRef] [Green Version]
- Díez, J.L.; Navarro, J.L.; Sala, A. Algoritmos de Agrupamiento en la Identificación de Modelos Borrosos. RIAII 2004, 1, 32–41. [Google Scholar]
- Gustafson, E.E.; Kessel, W.C. Fuzzy clustering with a fuzzy covariance matrix. In Proceedings of the IEEE Conference on Decision and Control, San Diego, CA, USA, 10–12 January 1979; pp. 761–766. [Google Scholar]
- Berndt, D.; Clifford, J. Using dynamic time warping to find patterns in time series. In Proceedings of the AAAI 1994 Workshop on Knowledge Discovery in Databases, Seattle, WA, USA, 31 July–1 August 1994. [Google Scholar]
- Górecki, T.; Luczak, M. Non-isometric transforms in time series classification using {DTW}. Knowl.-Based Syst. 2014, 61, 98–108. [Google Scholar] [CrossRef]
- Capitani, P.; Ciaccia, P. Warping the time on data streams. Data Knowl. Eng. 2007, 62, 438–458. [Google Scholar] [CrossRef]
- Kullback, S.; Leibler, R.A. On Information and Sufficiency. Ann. Math. Statist. 1951, 22, 79–86. [Google Scholar] [CrossRef]
- McClean, S.; Scotney, B.; Greer, K.; Páircéir, R. Conceptual Clustering of Heterogeneous Distributed Databases. In Workshop on Distributed and Parallel Knowledge Discovery; ACM: New York, NY, USA, 2000. [Google Scholar]
- Kim, N.; Park, S.; Lee, J.; Choi, J.K. Load Profile Extraction by Mean-Shift Clustering with Sample Pearson Correlation Coefficient Distance. Energies 2018, 11, 2397. [Google Scholar] [CrossRef] [Green Version]
- Mares, J.J.; Navarro, L.; Quintero M., C.G.; Pardo, M. Dynamic Time Warp as a similarity measure integrated with Artificial Neural Networks. Clustering. Energies 2020, 13, 4040. [Google Scholar]
- Serrà, J.; Arcos, J.L. An empirical evaluation of similarity measures for time series classification. Knowl.-Based Syst. 2014, 67, 305–314. [Google Scholar] [CrossRef] [Green Version]
- Jain, A.K.; Murty, M.N.; Flynn, P.J. Data Clustering: A Review. ACM Comput. Surv. 1999, 31, 264–323. [Google Scholar] [CrossRef]
- MacQueen, J.B. Some methods for classification and analysis of multivariate observations. In Proceedings of the 5th Berkeley Symposium on Mathematical Statistics and Probability, Los Angeles, CA, USA, 21 June–18 July 1967; University of California: Los Angeles, CA, USA, 1967; pp. 281–297. [Google Scholar]
- Arthur, D.; Vassilvitskii, S. K-means++: The advantages of careful seeding. In Proceedings of the Eighteenth Annual ACM-SIAM Symposium on Discrete Algorithms, SODA’07, New Orleans, LA, USA, 7–9 January 2007; Society for Industrial and Applied Mathematics: Philadelphia, PA, USA, 2007; pp. 1027–1035. [Google Scholar]
- Bezdek, J.C. Fuzzy Mathematics in Pattern Classification. Ph.D. Thesis, Faculty of the Gradual School of Cornell University, Ithaca, NY, USA, 1973. [Google Scholar]
- Dunn, J. A Fuzzy Relative of the ISODATA Process and Its Use in Detecting Compact Well-Separated Clusters. J. Cybern. 1974, 3, 32–57. [Google Scholar] [CrossRef]
- Zadeh, L. Fuzzy Sets. J. Inf. Control 1965, 8, 338–353. [Google Scholar] [CrossRef] [Green Version]
- Díez, J.L. Técnicas de Agrupamiento para Identificación y Control por Modelos locales. Ph.D. Thesis, Universidad Politécnica de Valencia, Valencia, Spain, 2003. (In Spanish). [Google Scholar]
- Martínez, B.; Herrera, F.; Fernández, J.; Marichal, E. Método de Agrupamiento en Línea para la Identificación de Modelos Borrosos Takagi-Sugeno. Rev. Iberoam. De Automática E Inform. Ind. 2008, 5, 63–69. [Google Scholar] [CrossRef] [Green Version]
- Benítez Sánchez, I.; Delgado Espinós, I.; Moreno Sarrión, L.; Quijano López, A.; Navalón Burgos, I. Clients segmentation according to their domestic energy consumption by the use of self-organizing maps. In Proceedings of the EEM 2009, 6th International Conference on the European Energy Market, Lodz, Poland, 27–29 May 2009; pp. 1–6. [Google Scholar]
- Kohonen, T. Self-Organizing Maps; Springer: Berlin/Heidelberg, Germany, 2001. [Google Scholar]
- Li, C.; Sun, L.; Jia, J.; Cai, Y.; Wang, X. Risk assessment of water pollution sources based on an integrated K-means clustering and set pair analysis method in the region of Shiyan, China. Sci. Total Environ. 2016, 557, 307–316. [Google Scholar] [CrossRef]
- Jeong, H.; Jang, M.; Kim, T.; Joo, S.K. Clustering of Load Profiles of Residential Customers Using Extreme Points and Demographic Characteristics. Electronics 2021, 10, 290. [Google Scholar] [CrossRef]
- Yanto, I.T.R.; Ismail, M.A.; Herawan, T. A modified Fuzzy k-Partition based on indiscernibility relation for categorical data clustering. Eng. Appl. Artif. Intell. 2016, 53, 41–52. [Google Scholar] [CrossRef]
- Yang, M.S.; Chiang, Y.H.; Chen, C.C.; Lai, C.Y. Theme: Information Processing A fuzzy k-partitions model for categorical data and its comparison to the GoM model. Fuzzy Sets Syst. 2008, 159, 390–405. [Google Scholar] [CrossRef]
- Ramírez-Pedraza, A.; González-Barbosa, J.J.; Ornelas-Rodríguez, F.J.; García-Moreno, A.I.; Salazar-Garibay, A.; González-Barbosa, E.A. Detección de Automóviles en Escenarios Urbanos Escaneados por un Lidar. Rev. Iberoam. De Autom. E Inform. Ind. 2015, 12, 189–198. [Google Scholar] [CrossRef] [Green Version]
- Fukunaga, K.; Hostetler, L. The estimation of the gradient of a density function, with applications in pattern recognition. IEEE Trans. Inf. Theory 1975, 21, 32–40. [Google Scholar] [CrossRef] [Green Version]
- Gao, B.; Wang, J. Multi-Objective Fuzzy Clustering for Synthetic Aperture Radar Imagery. IEEE Geosci. Remote Sens. Lett. 2015, 12, 2341–2345. [Google Scholar] [CrossRef]
- Cai, W.; Chen, S.; Zhang, D. Fast and robust fuzzy c-means clustering algorithms incorporating local information for image segmentation. Pattern Recognit. 2007, 40, 825–838. [Google Scholar] [CrossRef] [Green Version]
- Xie, X.L.; Beni, G. A validity measure for fuzzy clustering. IEEE Trans. Pattern Anal. Mach. Intell. 1991, 13, 841–847. [Google Scholar] [CrossRef]
- Liao, T.W. Clustering of time series data—A survey. Pattern Recognit. 2005, 38, 1857–1874. [Google Scholar] [CrossRef]
- Rani, S.; Sikka, G. Recent Techniques of Clustering of Time Series Data: A Survey. Int. J. Comput. Appl. 2012, 52, 1–9. [Google Scholar] [CrossRef]
- Esling, P.; Agon, C. Time-series Data Mining. ACM Comput. Surv. 2012, 45, 1–34. [Google Scholar] [CrossRef] [Green Version]
- Fu, T.C. A review on time series data mining. Eng. Appl. Artif. Intell. 2011, 24, 164–181. [Google Scholar] [CrossRef]
- Kosmelj, K.; Batagelj, V. Cross-sectional approach for clustering time varying data. J. Classif. 1990, 7, 99–109. [Google Scholar] [CrossRef]
- Batagelj, V. Generalized Ward and Related Clustering Problems. In Classification and Related Methods of Data Analysis; Bock, H.H., Ed.; NorthHolland: Amsterdam, The Netherland, 1988; pp. 67–74. [Google Scholar]
- Liao, T.; Bolt, B.; Forester, J.; Hailman, E.; Hansen, C.; Kaste, R.; O’May, J. Understanding and projecting the battle state. In Proceedings of the 23rd Army Science Conference, Orlando, FL, USA, 2–5 December 2002. [Google Scholar]
- Golay, X.; Kollias, S.; Stoll, G.; Meier, D.; Valavanis, A.; Boesiger, P. A new correlation-based fuzzy logic clustering algorithm for FMRI. Magn. Reson. Med. 1998, 40, 249–260. [Google Scholar] [CrossRef] [PubMed]
- Kakizawa, Y.; Shumway, R.; Taniguchi, M. Discrimination and Clustering for Multivariate Time Series. J. Am. Stat. Assoc. 1998, 93, 328–340. [Google Scholar] [CrossRef]
- van Wijk, J.; van Selow, E. Cluster and calendar based visualization of time series data. In Proceedings of the 1999 IEEE Symposium on Information Visualization (Info Vis’99), San Francisco, CA, USA, 24–29 October 1999; 140, pp. 4–9. [Google Scholar]
- Kumar, M.; Patel, N.R.; Woo, J. Clustering Seasonality Patterns in the Presence of Errors. In Proceedings of the Eighth ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, KDD’02, Edmonton, AB, Canada, 23–26 July 2002; ACM: New York, NY, USA, 2002; pp. 557–563. [Google Scholar]
- Wismüller, A.; Lange, O.; Dersch, D.; Leinsinger, G.; Hahn, K.; Pütz, B.; Auer, D. Cluster Analysis of Biomedical Image Time-Series. Int. J. Comput. Vis. 2002, 46, 103–128. [Google Scholar] [CrossRef]
- Zhang, M.; Yang, T. Application of computational verb theory to analysis of stock market data. Anti-Counterfeiting Security and Identification in Communication (ASID). In Proceedings of the 2010 International Conference on Machine Learning, Haifa, Israel, 21–24 June 2010; pp. 261–264. [Google Scholar]
- Yang, T. Computational Verb Theory: From Engineering, Dynamic Systems to Physical Linguistics; YangSky.com (Yang’s); Yang’s Scientific Research Institute: Yangjiang, China, 2002. [Google Scholar]
- Möller-Levet, C.S.; Klawonn, F.; Cho, K.H.; Wolkenhauer, O. Fuzzy Clustering of Short Time-Series and Unevenly Distributed Sampling Points. In Advances in Intelligent Data Analysis V; Lecture Notes in Computer Science; Berthold, R.M., Lenz, H.J., Bradley, E., Kruse, R., Borgelt, C., Eds.; Springer: Berlin/Heidelberg, Germany, 2003; Volume 2810, pp. 330–340. [Google Scholar]
- Liao, T.W. A clustering procedure for exploratory mining of vector time series. Pattern Recognit. 2007, 40, 2550–2562. [Google Scholar] [CrossRef]
- Meesrikamolkul, W.; Niennattrakul, V.; Ratanamahatana, C. Shape-Based Clustering for Time Series Data. In Advances in Knowledge Discovery and Data Mining; Lecture Notes in Computer Science; Tan, P.N., Chawla, S., Ho, C., Bailey, J., Eds.; Springer: Berlin/Heidelberg, Germany, 2012; Volume 7301, pp. 530–541. [Google Scholar]
- Ji, M.; Xie, F.; Ping, Y. A Dynamic Fuzzy Cluster Algorithm for Time Series. Abstr. Appl. Anal. 2013, 2013, 183410. [Google Scholar] [CrossRef] [Green Version]
- Izakian, H.; Pedrycz, W.; Jamal, I. Clustering Spatiotemporal Data: An Augmented Fuzzy C-Means. Fuzzy Syst. IEEE Trans. 2013, 21, 855–868. [Google Scholar] [CrossRef]
- Izakian, H.; Pedrycz, W. Agreement-based fuzzy C-means for clustering data with blocks of features. Neurocomputing 2014, 127, 266–280. [Google Scholar] [CrossRef]
- Kennedy, J.; Eberhart, R. Particle swarm optimization. Neural Networks. In Proceedings of the IEEE International Conference on Robotics and Automation, Nagoya, Japan, 21–27 May 1995; Volume 4, pp. 1942–1948. [Google Scholar]
- Izakian, H.; Pedrycz, W.; Jamal, I. Fuzzy clustering of time series data using dynamic time warping distance. Eng. Appl. Artif. Intell. 2015, 39, 235–244. [Google Scholar] [CrossRef]
- Krishnapuram, R.; Joshi, A.; Nasraoui, O.; Yi, L. Low-complexity fuzzy relational clustering algorithms for Web mining. Fuzzy Syst. IEEE Trans. 2001, 9, 595–607. [Google Scholar] [CrossRef] [Green Version]
- Benítez, I. Dynamic Segmentation Techniques Applied to Load Profiles of Electric Energy Consumption from Domestic Users. Ph.D. Thesis, Universitat Politècnica de València, Valencia, Spain, 2015. [Google Scholar]
- Wilpon, J.; Rabiner, L. A modified K-means clustering algorithm for use in isolated word recognition. Acoust. Speech Signal Process. IEEE Trans. 1985, 33, 587–594. [Google Scholar] [CrossRef]
- Itakura, F. Minimum prediction residual principle applied to speech recognition. Acoust. Speech Signal Process. IEEE Trans. 1975, 23, 67–72. [Google Scholar] [CrossRef]
- Owsley, L.; Atlas, L.; Bernard, G. Self-organizing feature maps and hidden Markov models for machine-tool monitoring. Signal Process. IEEE Trans. 1997, 45, 2787–2798. [Google Scholar] [CrossRef]
- Goutte, C.; Hansen, L.; Liptrot, M.; Rostrup, E. Feature-space clustering for fMRI meta-analysis. Hum. Brain Ma 2001, 13, 165–183. [Google Scholar] [CrossRef] [PubMed]
- Goutte, C.; Toft, P.; Rostrup, E.; Nielsen, F.; Hansen, L. On clustering fMRI time series. Neuroimage 1999, 9, 298–310. [Google Scholar] [CrossRef] [Green Version]
- Fu, T.; Chung, F.; Ng, V.; Luk, R. Pattern Discovery from Stock Time Series Using Self-Organizing Maps. In Proceedings of the KDD 2001 Workshop on Temporal Data Mining, San Francisco, CA, USA, 26–29 August 2001; pp. 27–37. [Google Scholar]
- Vlachos, M.; Lin, J.; Keogh, E.; Gunopulos, D. A wavelet based anytime algorithm for K-means clustering of time series. In Proceedings of the Third SIAM International Conference on Data Mining, San Francisco, CA, USA, 1–3 May 2003. [Google Scholar]
- Aghabozorgi, S.; Saybani, M.R.; Wah, T.Y. Incremental clustering of time-series by fuzzy clustering. J. Inf. Sci. Eng. 2012, 28, 671–688. [Google Scholar]
- Nystrup, P.; Madsen, H.; Blomgren, E.M.V.; de Zotti, G. Clustering commercial and industrial load patterns for long-term energy planning. Smart Energy 2021, 2, 100010. [Google Scholar] [CrossRef]
- Lin, J.; Vlachos, M.; Keogh, E.; Gunopulos, D.; Liu, J.; Yu, S.; Le, J. A MPAA-Based Iterative Clustering Algorithm Augmented by Nearest Neighbors Search for Time-Series Data Streams. In Advances in Knowledge Discovery and Data Mining; Lecture Notes in Computer Science; Ho, T., Cheung, D., Liu, H., Eds.; Springer: Berlin/Heidelberg, Germany, 2005; Volume 3518, pp. 333–342. [Google Scholar]
- Hoeffding, W. Probability Inequalities for Sums of Bounded Random Variables. J. Am. Stat. Assoc. 1963, 58, 13–30. [Google Scholar] [CrossRef]
- Chandrakala, S.; Sekhar, C. A density based method for multivariate time series clustering in kernel feature space. In Proceedings of the IJCNN 2008, (IEEE World Congress on Computational Intelligence), IEEE International Joint Conference on Neural Networks, Hong Kong, China, 1–8 June 2008; pp. 1885–1890. [Google Scholar]
- Ester, M.; Kriegel, H.P.; Sander, J.; Xu, X. A Density-Based Algorithm for Discovering Clusters in Large Spatial Databases with Noise. In Proceedings of the KDD’96, Portland, OR, USA, 2–4 August 1996; pp. 226–231. [Google Scholar]
- Guo, C.; Jia, H.; Zhang, N. Time Series Clustering Based on ICA for Stock Data Analysis. In Proceedings of the Wireless Communications, Networking and Mobile Computing, 2008, WiCOM ’08, 4th International Conference on Information and Automation for Sustainability, Washington, DC, USA, 20–22 October 2008; pp. 1–4. [Google Scholar] [CrossRef]
- Pearson, K. LIII. On lines and planes of closest fit to systems of points in space. Philos. Mag. Ser. 6 1901, 2, 559–572. [Google Scholar] [CrossRef] [Green Version]
- Lin, J.; Li, Y. Finding Structural Similarity in Time Series Data Using Bag-of-Patterns Representation. In Scientific and Statistical Database Management; Lecture Notes in Computer Science; Winslett, M., Ed.; Springer: Berlin/Heidelberg, Germany, 2009; Volume 5566, pp. 461–477. [Google Scholar]
- Keogh, E.; Lin, J.; Truppel, W. Clustering of time series subsequences is meaningless: Implications for previous and future research. In Proceedings of the Data Mining, 2003, ICDM 2003, Third IEEE International Conference on Data Mining, Washington, DC, USA, 19–22 November 2003; pp. 115–122. [Google Scholar] [CrossRef]
- D’Urso, P.; Maharaj, E.A. Autocorrelation-based fuzzy clustering of time series. Fuzzy Sets Syst. 2009, 160, 3565–3589. [Google Scholar] [CrossRef]
- Lai, C.P.; Chung, P.C.; Tseng, V.S. A novel two-level clustering method for time series data analysis. Expert Syst. Appl. 2010, 37, 6319–6326. [Google Scholar] [CrossRef]
- Ben-Dor, A.; Shamir, R.; Yakhini, Z. Clustering gene expression patterns. J. Comput. Biol. 1999, 6, 281–297. [Google Scholar] [CrossRef]
- Benítez, I.; Blasco, C.; Mocholí, A.; Quijano, A. A Two-Step Process for Clustering Electric Vehicle Trajectories. In Proceedings of the IEEE International Electric Vehicle Conference (IEVC 2014), Florence, Italy, 16 December 2014. [Google Scholar]
- Li, H.; Guo, C. Piecewise cloud approximation for time series mining. Knowl.-Based Syst. 2011, 24, 492–500. [Google Scholar] [CrossRef]
- Fulcher, B.; Jones, N. Highly comparative feature-based time-series classification. In Proceedings of the IEEE Transactions on Knowledge and Data Engineering, Piscataway, NJ, USA, 2–5 January 2014; pp. 3026–3037. [Google Scholar]
- Irpino, A.; Verde, R.; de A.T. De Carvalho, F. Dynamic clustering of histogram data based on adaptive squared Wasserstein distances. Expert Syst. Appl. 2014, 41, 3351–3366. [Google Scholar] [CrossRef] [Green Version]
- Rüschendorf, L. The Wasserstein distance and approximation theorems. Z. Für Wahrscheinlichkeitstheorie Und Verwandte Geb. 1985, 70, 117–129. [Google Scholar] [CrossRef]
- Li, C.; Biswas, G. Temporal Pattern Generation Using Hidden Markov Model Based Unsupervised Classification. In Proceedings of the Third International Symposium on Advances in Intelligent Data Analysis, Amsterdam, The Netherlands, 9–11 August 1999; Springer: London, UK, 1999; IDA ’99, pp. 245–256. [Google Scholar]
- Oates, T.; Firoiu, L.; Cohen, P. Clustering time series with hidden Markov models and dynamic time warping. In Proceedings of the IJCAI-99 Workshop on Neural, Symbolic and Reinforcement Learning Methods for Sequence Learning, Stockholm, Sweden, 31 July–2 August 1999. [Google Scholar]
- Maharaj, E. Cluster of Time Series. J. Classif. 2000, 17, 297–314. [Google Scholar] [CrossRef]
- Ramoni, M.; Sebastiani, P.; Cohen, P. Bayesian Clustering by Dynamics. Mach. Learn. 2002, 47, 91–121. [Google Scholar] [CrossRef] [Green Version]
- Ramoni, M.; Sebastiani, P.; Cohen, P. Multivariate clustering by dynamics. In Proceedings of the 2000 National Conference on Artificial Intelligence (AAAI 2000), Austin, TX, USA, 30 July–3 August 2000; pp. 633–638. [Google Scholar]
- Xiong, Y.; Yeung, D.Y. Time series clustering with ARMA mixtures. Pattern Recognit. 2004, 37, 1675–1689. [Google Scholar] [CrossRef]
- Bagnall, A.J.; Janacek, G.J. Clustering Time Series from ARMA Models with Clipped Data. In Proceedings of the Tenth ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, KDD’04, Seattle, WA, USA, 22–25 August 2004; ACM: New York, NY, USA, 2004; pp. 49–58. [Google Scholar]
- Savvides, A.; Promponas, V.J.; Fokianos, K. Clustering of biological time series by cepstral coefficients based distances. Pattern Recognit. 2008, 41, 2398–2412. [Google Scholar] [CrossRef]
- Kalpakis, K.; Gada, D.; Puttagunta, V. Distance measures for effective clustering of ARIMA time-series. In Proceedings of the ICDM 2001, IEEE International Conference on Data Mining, San Jose, CA, USA, 29 November–2 December 2001; pp. 273–280. [Google Scholar]
- Kaufman, L.; Rousseeuw, P.J. Finding Groups in Data: An Introduction to Cluster Analysis; John Wiley & Sons: Hoboken, NJ, USA, 1990. [Google Scholar]
- Zhang, W.F.; Liu, C.C.; Yan, H. Clustering of Temporal Gene Expression Data by Regularized Spline Regression and an Energy Based Similarity Measure. Pattern Recogn. 2010, 43, 3969–3976. [Google Scholar] [CrossRef]
- Boudraa, A.O.; Cexus, J.C.; Groussat, M.; Brunagel, P. An Energy-based Similarity Measure for Time Series. EURASIP J. Adv. Signal Process 2008, 2008, 135892. [Google Scholar] [CrossRef] [Green Version]
- Li, L.; Prakash, B.A. Time Series Clustering: Complex is Simpler ICML; Getoor, L., Scheffer, T., Eds.; Omnipress: Madison, WI, USA, 2011; pp. 185–192. [Google Scholar]
- Dempster, A.P.; Laird, N.M.; Rubin, D.B. Maximum Likelihood from Incomplete Data via the EM Algorithm. J. R. Stat. Soc. Ser. B (Methodol.) 1977, 39, 1–38. [Google Scholar]
- Corduas, M. Clustering streamflow time series for regional classification. J. Hydrol. 2011, 407, 73–80. [Google Scholar] [CrossRef]
- Maharaj, E.A.; D’Urso, P. Fuzzy clustering of time series in the frequency domain. Inf. Sci. 2011, 181, 1187–1211. [Google Scholar] [CrossRef]
- Hausdorff, F. Grundzüge der Mengenlehre; Veit and Company: Leipzig, Germany, 1914. [Google Scholar]
- Palumbo, F.; Irpino, A. Multidimensional interval-data: Metrics and factorial analysis. In Proceedings of the ASMDA, Brest, France, 17–20 May 2005; pp. 689–698. [Google Scholar]
- Benítez, I.; Quijano, A.; Díez, J.L.; Delgado, I. Dynamic clustering segmentation applied to load profiles of energy consumption from Spanish customers. Int. J. Electr. Power Energy Syst. 2014, 55, 437–448. [Google Scholar] [CrossRef]
- Gosh, S.; Dubey, S.K. Comparative Analysis of K-Means and Fuzzy C-Means Algorithms. Int. J. Adv. Comput. Sci. Appl. 2013, 4, 35–39. [Google Scholar] [CrossRef] [Green Version]
- Davies, D.L.; Bouldin, D.W. Cluster Separation Measure. IEEE Trans. Pattern Anal. Mach. Intell. 1979, 1, 95–104. [Google Scholar] [CrossRef]
- Toussaint, W.; Moodley, D. Comparison of Clustering Techniques for Residential Load Profiles in South Africa. of the South African Forum for Artificial Intelligence Research (FAIR), Cape Town, South Africa, 4–6 December 2019. [Google Scholar]
- Damayanti, R.; Abdullah, A.G.; Purnama, W.; Nandiyanto, A.B.D. Electrical Load Profile Analysis Using Clustering Techniques. In Proceedings of the 1st Annual Applied Science and Engineering Conference, Dubai, United Arab Emirates, 21–22 November 2017. [Google Scholar] [CrossRef] [Green Version]
- Gan, W.; Ma, C.; Wu, J. Data Clustering: Theory, Algorithms, and Applications; ASA-SIAM Series on Statistics and Applied Probability; Society for Industrial and Applied Mathematics: Philadelphia, PA, USA, 2007. [Google Scholar]
- Gordon, A.D. Data Science, Classification, and Related Methods; Springer New York, Inc.: Secaucus, NJ, USA, 1998; Chapter Cluster Validation; pp. 22–39. [Google Scholar]
- Li, H.; Zhang, S.; Ding, X.; Zhang, C.; Dale, P. Performance evaluation of cluster validity indices (cvis) on multi/hyperspectral remote sensing datasets. Remote Sens. 2016, 8, 295. [Google Scholar] [CrossRef] [Green Version]
- Jang, M.; Jeong, H.C.; Kim, T.; Joo, S.K. Load Profile-Based Residential Customer Segmentation for Analyzing Customer Preferred Time-of-Use (TOU) Tariffs. Energies 2021, 14, 6130. [Google Scholar] [CrossRef]






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| characteristic j of object i | |
| characteristic j of centroid k | |
| N | number of objects |
| c | numer of centroids |
| function distance among two objects, i and k | |
| d | number of characteristics (dimension) of the objects |
| fuzzy membership of the object i to the cluster k | |
| U | fuzzy membership matrix, with c rows and N columns |
| m | fuzziness index, higher than 1 (usually 2) |
| J | cost index to minimize |
| p | total number of samples or time instants |
| mean value (or vector of mean values per dimension) of a series x of objects or data |
| Type | Data | Classes | Segmentation Type |
|---|---|---|---|
| 1 | Static | Static | Static (classic) |
| 2 | Static | Dynamic | Dynamic. Centroids and classes are updated with each new cycle |
| 3 | Dynamic | Static | Dynamic. The centroids are represented by trajectories of their dimensions. Fixed number of classes |
| 4 | Dynamic | Dynamic | Dynamic. The centroids are represented by trajectories of their dimensions. The number of classes is updated with each new cycle |
| No. | Base Clustering Technique | Dynamic Similarity Measure | Clustering Algorithm |
|---|---|---|---|
| 1 | K-means | Euclidean distance | END-KME |
| 2 | K-means | Correlation | END-KMC |
| 3 | K-means | Distance Hausdorff | END-KMH |
| 4 | K-means | Euclidean distance | K-means (modified) |
| 5 | FCM | Euclidean distance | END-FCME |
| 6 | FCM | Correlation | END-FCMC |
| 7 | FCM | Hausdorff Distance | END-FCMH |
| 8 | FCM | Fuzzy membership functions | FFCM |
| Cycle | END-KME | END-KMC | END-KMH | K-Means | END-FCME | END-FCMC | END-FCMH | FFCM |
|---|---|---|---|---|---|---|---|---|
| 1 | 2.348 | 5.918 | 3.204 | NaN | 4.131 | NaN | 6.181 | 8.114 |
| 2 | 3.151 | 5.650 | 2.680 | 2.285 | 3.848 | NaN | 7.449 | 7.050 |
| 3 | 2.314 | 5.836 | 3.039 | 1.594 | 2.792 | NaN | 5.201 | NaN |
| 4 | 1.894 | 5.674 | 3.759 | NaN | 5.801 | NaN | 5.103 | NaN |
| 5 | 2.967 | 5.674 | 3.136 | 2.421 | 3.699 | NaN | 4.184 | NaN |
| 6 | 2.589 | 5.267 | 3.049 | NaN | 3.175 | NaN | 6.444 | 6.527 |
| 7 | 2.336 | 5.951 | 3.497 | 2.183 | 8.750 | NaN | 6.552 | NaN |
| 8 | 2.501 | 5.854 | 3.202 | NaN | 4.143 | NaN | 5.881 | NaN |
| 9 | 2.483 | 5.758 | 3.204 | 1.390 | 4.866 | NaN | 16.863 | 9.270 |
| 10 | 2.689 | 5.878 | 2.995 | NaN | 2.909 | NaN | 4.738 | NaN |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Benítez, I.; Díez, J.-L. Automated Detection of Electric Energy Consumption Load Profile Patterns. Energies 2022, 15, 2176. https://doi.org/10.3390/en15062176
Benítez I, Díez J-L. Automated Detection of Electric Energy Consumption Load Profile Patterns. Energies. 2022; 15(6):2176. https://doi.org/10.3390/en15062176
Chicago/Turabian StyleBenítez, Ignacio, and José-Luis Díez. 2022. "Automated Detection of Electric Energy Consumption Load Profile Patterns" Energies 15, no. 6: 2176. https://doi.org/10.3390/en15062176
APA StyleBenítez, I., & Díez, J.-L. (2022). Automated Detection of Electric Energy Consumption Load Profile Patterns. Energies, 15(6), 2176. https://doi.org/10.3390/en15062176