
Predicting Biomass Yields of Advanced Switchgrass Cultivars for Bioenergy and Ecosystem Services Using Machine Learning

 , , , , ,
, , , , ,
Abstract
:1. Introduction
2. Materials and Methods
2.1. ML Modeling Workflow
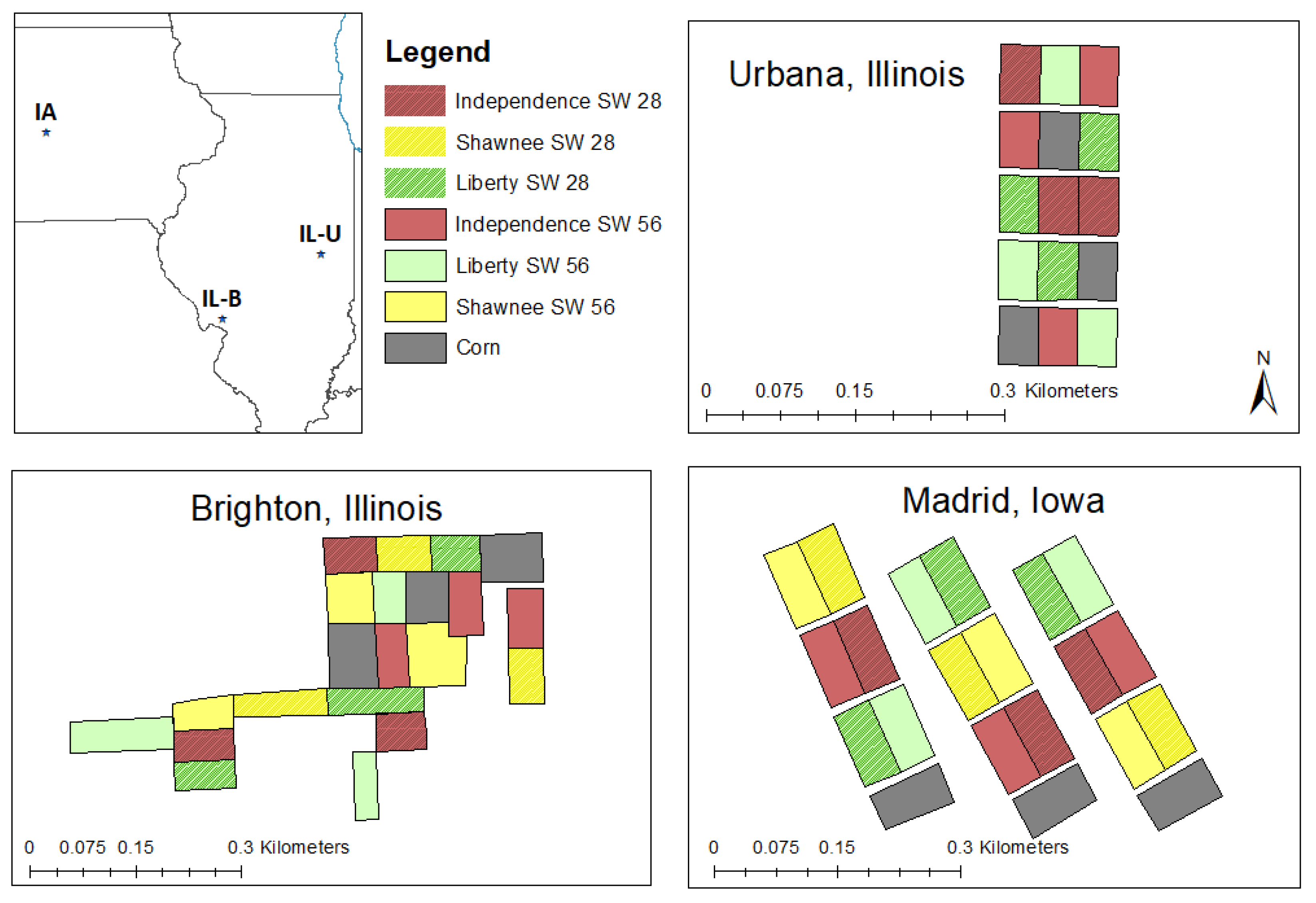
2.2. Description of Field Study Sites and Experimental Setup
2.3. Data and Sources
2.3.1. Climatic Factors
2.3.2. Land Marginality
2.3.3. Soil Properties
2.3.4. Topography
2.3.5. Crop Management and Biomass Yield
2.4. ML Algorithms
2.4.1. Random Forests
2.4.2. Gradient Boosting Machines
2.4.3. Artificial Neural Networks
2.4.4. AdaBoost Regression
2.4.5. K-Nearest Neighbors Regression
2.4.6. Partial Least Squares Regression
2.5. Machine Learning Model Performance Assessment
Model Training and Testing
3. Results and Discussion
4. Summary and Conclusions
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
Appendix A

{kind=link}
{kind=link}
{kind=link}
| Variable | Description | Value Type | Units |
|---|---|---|---|
| cltvr | Switchgrass cultivar | Text | |
| indp | Independence cultivar | Text | |
| libert | Liberty cultivar | Text | |
| shaw | Shawnee cultivar | Text | |
| nccp_idx | National Commodity Crop Index | Binary/Integer | |
| pnd_freq | Ponding frequency | Binary/Integer | |
| fld_freq | Flooding frequency | Binary/Integer | |
| sol_drain | Soil drainage class | Binary/Integer | |
| bulk_d | Soil bulk density | Float | g cm−3 |
| avwater_cap | Soil-available water capacity | Float | Proportion of soil-available water |
| cationex_cap | Soil cation exchange capacity | Float | meq 100 g−1 |
| sand_prcnt | Percentage of sand | Float | % |
| silt_prcnt | Percentage of silt | Float | % |
| clay_prcnt | Percentage of clay | Float | % |
| som_prcnt | Percentage of soil organic matter | Float | % |
| pH | Soil pH | Float | |
| elev | Soil surface elevation | Float | m |
| Slope | Soil surface slope | Float | % |
| crvture | Soil surface curvature | Float | 10−2 m |
| pcpAM_sum | Total precipitation from April to May | Float | mm |
| pcpJS_sum | Total precipitation from June to September | Float | mm |
| tmpGS_avg | Growing season temperature average | Float | °C |
| tmpYR_avg | Annual temperature average | Float | °C |
| n_rate | Nitrogen fertilization rate | Float | kg/N ha |
| yld | Biomass yield (dry) | Float | Mg/ha |
| Study Site | Station Name | Latitude | Longitude | Elevation (m) |
|---|---|---|---|---|
| Brighton, Illinois | Switchgrass Atmos Station | 39.056060 | −90.18573 | 191.00 |
| Alton Melvin Price Lock and Dam, IL, USA | 38.867020 | −90.14890 | 123.40 | |
| Jerseyville 2 SW, IL, USA | 39.102460 | −90.34320 | 192.00 | |
| Medora 1 S, IL, USA | 39.156160 | −90.13920 | 185.00 | |
| St. Charles Co. Airport, MO, USA | 38.930430 | −90.43900 | 131.80 | |
| Urbana, Illinois | Champaign MESONET Station 1 | 40.084000 | −88.24040 | 219.63 |
| Champaign 3 S, IL, USA | 40.084080 | −88.24040 | 220.10 | |
| Champaign 9 SW, IL, USA | 40.052800 | −88.37290 | −213.40 | |
| Champaign Urbana Willard Airport, IL, USA | 40.032400 | −88.27550 | 226.50 | |
| Ogden, IL, USA | 40.110100 | −87.95670 | 205.70 | |
| Madrid, Iowa | Corn Atmos Station | 41.929088 | −93.760687 | 317.98 |
| Switchgrass Atmos Station | 41.931356 | −93.762419 | 318.38 | |
| AEEI4 (MESONET Station) 2 | 42.106710 | −93.584820 | 301.99 | |
| Boone MESONET Station | 42.020940 | −93.774300 | 335.00 | |
| Ames 5 SE, IA, USA | 41.951900 | −93.565500 | 265.20 | |
| Ames 8 WSW, IA, USA | 42.020800 | −93.774100 | 335.00 | |
| Ames Municipal Airport, IA, USA | 41.990450 | −93.618500 | 281.50 | |
| Boone, IA, USA | 42.041670 | −93.890900 | 315.50 | |
| Des Moines 17E, IA, USA | 41.556200 | −93.285500 | 280.70 | |
| Des Moines International Airport, IA, USA | 41.533950 | −93.653100 | 286.30 | |
| Des Moines WSFO Johnston, IA, USA | 41.736600 | −93.723600 | 292.30 | |
| Eldora, IA, USA | 42.365200 | −93.097100 | 327.10 | |
| Guthrie Center, IA, USA | 41.668600 | −94.497200 | 324.60 | |
| Marshalltown Municipal Airport, IA, USA | 42.110610 | −92.916400 | 259.30 | |
| Marshalltown, IA, USA | 42.064700 | −92.924400 | 265.20 | |
| Newton, IA, USA | 41.711600 | −93.029700 | 292.60 |
| Hyperparameter | Type | Range | Condition (OR) |
|---|---|---|---|
| Regressor | Categorical | Linear, KNR 1, RF, GDM, ADR | None |
| Maximum depth | Integer, log scale | [2, 100] |
|
| Number of estimators | Integer, log scale | [10, 10,000] |
|
| Number of neighbors | Integer | [1, 100] |
|
| Hyperparameter | Type | Range |
|---|---|---|
| Activation | Categorical | ELU 1, GELU, RELU, SELU, TANH, hard sigmoid, sigmoid, linear, soft plus, soft sign, swish |
| Batch size | Integer | [32, 256] |
| Dropout | Float | [0, 0.6] |
| Learning rate | Float | [0.001, 0.1] |
| Number of layers | Integer | [2, 10] |
| Units per layer | Integer | [8, 128] |
References
- Englund, O.; Dimitriou, I.; Dale, V.H.; Kline, K.L.; Mola-Yudego, B.; Murphy, F.; English, B.; McGrath, J.; Busch, G.; Negri, M.C.; et al. Multifunctional perennial production systems for bioenergy: Performance and progress. Wiley Interdiscip. Rev. Energy Environ. 2020, 9, e375. [Google Scholar] [CrossRef]
- Ssegane, H.; Negri, M.C. An integrated landscape designed for commodity and bioenergy crops for a tile-drained agricultural watershed. J. Environ. Qual. 2016, 45, 1588–1596. [Google Scholar] [CrossRef]
- Cacho, J.F.; Negri, M.C.; Zumpf, C.R.; Campbell, P. Introducing perennial biomass crops into agricultural landscapes to address water quality challenges and provide other environmental services. Wiley Interdiscip. Rev. Energy Environ. 2018, 7, e275. [Google Scholar] [CrossRef]
- Ssegane, H.; Negri, M.C.; Quinn, J.; Urgun-Demirtas, M. Multifunctional landscapes: Site characterization and field-scale design to incorporate biomass production into an agricultural system. Biomass Bioenergy 2015, 80, 179–190. [Google Scholar] [CrossRef]
- Daioglou, V.; Woltjer, G.; Strengers, B.; Elbersen, B.; Barberena Ibañez, G.; Sánchez Gonzalez, D.; Gil Barno, J.; van Vuuren, D.P. Progress and barriers in understanding and preventing indirect land-use change. Biofuels Bioprod. Biorefin. 2020, 14, 924–934. [Google Scholar] [CrossRef]
- Dahmen, N.; Lewandowski, I.; Zibek, S.; Weidtmann, A. Integrated lignocellulosic value chains in a growing bioeconomy: Status quo and perspectives. GCB Bioenergy 2019, 11, 107–117. [Google Scholar] [CrossRef]
- Zumpf, C.; Ssegane, H.; Negri, M.C.; Campbell, P.; Cacho, J. Yield and water quality impacts of field-scale integration of willow into a continuous corn rotation system. J. Environ. Qual. 2018, 46, 811–818. [Google Scholar] [CrossRef]
- Ferrarini, A.; Serra, P.; Almagro, M.; Trevisan, M.; Amaducci, S. Multiple ecosystem services provision and biomass logistics management in bioenergy buffers: A state-of-the-art review. Renew. Sustain. Energy Rev. 2017, 73, 277–290. [Google Scholar] [CrossRef]
- Stoof, C.R.; Richards, B.K.; Woodbury, P.B.; Fabio, E.S.; Brumbach, A.R.; Cherney, J.; Das, S.; Geohring, L.; Hansen, J.; Hornesky, J.; et al. Untapped potential: Opportunities and challenges for sustainable bioenergy production from marginal lands in the Northeast USA. BioEnergy Res. 2015, 8, 482–501. [Google Scholar] [CrossRef]
- Robertson, G.P.; Hamilton, S.K.; Barham, B.L.; Dale, B.E.; Izaurralde, R.C.; Jackson, R.D.; Landis, D.A.; Swinton, S.M.; Thelen, K.D.; Tiedje, J.M. Cellulosic biofuel contributions to a sustainable energy future: Choices and outcomes. Science 2017, 356, eaal2324. [Google Scholar] [CrossRef]
- Daly, C.; Halbleib, M.D.; Hannaway, D.B.; Eaton, L.M. Environmental limitation mapping of potential biomass resources across the conterminous United S tates. GCB Bioenergy 2018, 10, 717–734. [Google Scholar] [CrossRef]
- Haberzettl, J.; Hilgert, P.; von Cossel, M. A critical review on lignocellulosic biomass yield modeling and the bioenergy potential from marginal land. Agronomy 2021, 11, 2397. [Google Scholar] [CrossRef]
- Bali, N.; Singla, A. Emerging trends in machine learning to predict crop yield and study its influential factors: A survey. Arch. Comput. Methods Eng. 2022, 29, 95–112. [Google Scholar] [CrossRef]
- Mitchell, R.B.; Schmer, M.R.; Anderson, W.F.; Jin, V.; Balkcom, K.S.; Kiniry, J.; Coffin, A.; White, P. Dedicated energy crops and crop residues for bioenergy feedstocks in the central and eastern USA. Bioenergy Res. 2016, 9, 384–398. [Google Scholar] [CrossRef]
- Huntington, T.; Cui, X.; Mishra, U.; Scown, C.D. Machine learning to predict biomass sorghum yields under future climate scenarios. Biofuel Bioprod. Biorefin. 2020, 14, 566–577. [Google Scholar] [CrossRef]
- Samuel, A.L. Some studies in machine learning using the game of checkers. II-Recent progress. IBM J. Res. Dev. 1967, 11, 601–617. [Google Scholar] [CrossRef]
- Kaul, M.; Hill, R.L.; Walthall, C. Artificial neural networks for corn and soybean yield prediction. Agric. Syst. 2005, 85, 1–18. [Google Scholar] [CrossRef]
- Pantazi, X.E.; Moshou, D.; Alexandridis, T.; Whetton, R.L.; Mouazen, A.M. Wheat yield prediction using machine learning and advanced sensing techniques. Comput. Electron. Agric. 2016, 121, 57–65. [Google Scholar] [CrossRef]
- Gonzalez-Sanchez, A.; Frausto-Solis, J.; Ojeda-Bustamante, W. Predictive ability of machine learning methods for massive crop yield prediction. Span. J. Agric. Res. 2014, 12, 313–328. [Google Scholar] [CrossRef]
- Van Klompenburg, T.; Kassahun, A.; Catal, C. Crop yield prediction using machine learning: A systematic literature review. Comput. Electron. Agric. 2020, 177, 105709. [Google Scholar] [CrossRef]
- Yang, P.; Zhao, Q.; Cai, X. Machine learning based estimation of land productivity in the contiguous US using biophysical predictors. Environ. Res. Lett. 2020, 15, 074013. [Google Scholar] [CrossRef]
- Wullschleger, S.D.; Davis, E.B.; Borsuk, M.E.; Gunderson, C.A.; Lynd, L.R. Biomass production in switchgrass across the United States: Database description and determinants of yield. J. Agron. 2010, 102, 1158–1168. [Google Scholar] [CrossRef]
- Hastie, T.; Tibshirani, R. Generalized Additive Models; Chapman and Hall: London, UK, 1990. [Google Scholar]
- Tulbure, M.G.; Wimberly, M.C.; Boe, A.; Owens, V.N. Climatic and genetic controls of yields of switchgrass, a model bioenergy species. Agric. Ecosyst. Environ. 2012, 146, 121–129. [Google Scholar] [CrossRef]
- Zhang, L.; Juenger, T.E.; Lowry, D.B.; Behrman, K.D. Climatic impact, future biomass production, and local adaptation of four switchgrass cultivars. GCB Bioenergy 2019, 11, 956–970. [Google Scholar] [CrossRef]
- Van Rossum, G.; Drake, F.L., Jr. The Python Language Reference; Python Software Foundation: Wilmington, DE, USA, 2014. [Google Scholar]
- McKinney, W. Data structures for statistical computing in python. In Proceedings of the 9th Python in Science Conference, Austin, TX, USA, 28 June–3 July 2010; Volume 445, pp. 51–56. [Google Scholar]
- Harris, C.R.; Millman, K.J.; van der Walt, S.J.; Gommers, R.; Virtanen, P.; Cournapeau, D.; Wieser, E.; Taylor, J.; Berg, S.; Smith, N.J.; et al. Array programming with NumPy. Nature 2020, 585, 357–362. [Google Scholar] [CrossRef] [PubMed]
- Pedregosa, F.; Varoquaux, G.; Gramfort, A.; Michel, V.; Thirion, B.; Grisel, O.; Blondel, M.; Prettenhofer, P.; Weiss, R.; Dubourg, V.; et al. Scikit-learn: Machine learning in Python. J. Mach. Learn. Res. 2011, 12, 2825–2830. [Google Scholar]
- Hamada, Y.; Zumpf, C.R.; Cacho, J.F.; Lee, D.; Lin, C.H.; Boe, A.; Heaton, E.; Mitchell, R.; Negri, M.C. Remote sensing-based estimation of advanced perennial grass biomass yields for bioenergy. Land 2021, 10, 1221. [Google Scholar] [CrossRef]
- Gunderson, C.A.; Davis, E.B.; Jager, H.I.; West, T.O.; Perlack, R.D.; Brandt, C.C.; Wullschleger, S.; Baskaran, L.; Wilkerson, E.; Downing, M. Exploring Potential U.S. Switchgrass Production for Lignocellulosic Ethanol; ORNL/TM-2007/183; Oak Ridge National Laboratory: Oak Ridge, TN, USA, 2008. [Google Scholar]
- Shepard, D. A two-dimensional interpolation function for irregularly-spaced data. In Proceedings of the 1968 23rd ACM National Conference, New York, NY, USA, 27–29 August 1968; pp. 517–524. [Google Scholar]
- Ly, S.; Charles, C.; Degré, A. Different methods for spatial interpolation of rainfall data for operational hydrology and hydrological modeling at watershed scale. A review. Biotechnol. Agron. Soc. Environ. 2013, 17, 392–406. [Google Scholar]
- Schmer, M.R.; Vogel, K.P.; Mitchell, R.B.; Perrin, R.K. Net energy of cellulosic ethanol from switchgrass. Proc. Natl. Acad. Sci. USA 2008, 105, 464–469. [Google Scholar] [CrossRef] [PubMed]
- Sanderson, M.A.; Adler, P.R.; Boateng, A.A.; Casler, M.D.; Sarath, G. Switchgrass as a biofuels feedstock in the USA. Can. J. Plant Sci. 2006, 86, 1315–1325. [Google Scholar] [CrossRef]
- Waldrop, M.P.; Zak, D.R.; Sinsabaugh, R.L.; Gallo, M.; Lauber, C. Nitrogen deposition modifies soil carbon storage through changes in microbial enzymatic activity. Ecol. Appl. 2004, 14, 1172–1177. [Google Scholar] [CrossRef]
- Kravchenko, A.N.; Bullock, D.G. Correlation of corn and soybean grain yield with topography and soil properties. J. Agron. 2000, 92, 75–83. [Google Scholar] [CrossRef]
- Jiang, P.; Thelen, K.D. Effect of soil and topographic properties on crop yield in a North-Central corn–soybean cropping system. J. Agron. 2004, 96, 252–258. [Google Scholar] [CrossRef]
- (Dataset) USDA, Natural Resources Conservation Service (NRCS); USDA, Farm Service Agency (FSA); USDA, Rural Development. 2016; Geospatial Data Gateway. USDA-NRCS. Available online: https://datagateway.nrcs.usda.gov/ (accessed on 15 December 2020).
- Gitelson, A.; Merzlyak, M.N. Spectral reflectance changes associated with autumn senescence of Aesculus hippocastanum L. and Acer platanoides L. leaves: Spectral features and relation to chlorophyll estimation. J. Plant Physiol. 1994, 143, 286–292. [Google Scholar] [CrossRef]
- Gitelson, A.A.; Merzlyak, M.N. Remote sensing of chlorophyll concentration in higher plant leaves. Adv. Space Res. 1998, 22, 689–692. [Google Scholar] [CrossRef]
- Gitelson, A.A.; Kaufman, Y.J.; Merzlyak, M.N. Use of a green channel in remote sensing of global vegetation from EOS-MODIS. Remote Sens. Environ. 1996, 58, 289–298. [Google Scholar] [CrossRef]
- Kaufman, Y.J.; Tanre, D. Atmospherically resistant vegetation index (ARVI) for EOS-MODIS. IEEE Trans. Geosci. Remote Sens. 1992, 30, 261–270. [Google Scholar] [CrossRef]
- Rumelhart, D.E.; Hinton, G.E.; Williams, R.J. Learning Internal Representations by Error Propagation (No. ICS-8506); California University of San Diego, La Jolla Institute for Cognitive Science: San Diego, CA, USA, 1985. [Google Scholar]
- Efron, B. How biased is the apparent error rate of a prediction rule? J. Am. Stat. Assoc. 1986, 81, 461–470. [Google Scholar] [CrossRef]
- Efron, B.; Gong, G. A leisurely look at the bootstrap, the jackknife, and cross-validation. Am. Stat. 1983, 37, 36–48. [Google Scholar]
- Balaprakash, P.; Salim, M.; Uram, T.D.; Vishwanath, V.; Wild, S.M. DeepHyper: Asynchronous hyperparameter search for deep neural networks. In Proceedings of the 2018 IEEE 25th International Conference on High Performance Computing (HiPC), Bengaluru, India, 17–20 December 2018; pp. 42–51. [Google Scholar]
- Feng, L.; Li, Y.; Wang, Y.; Du, Q. Estimating hourly and continuous ground-level PM2. 5 concentrations using an ensemble learning algorithm: The ST-stacking model. Atmos. Environ. 2020, 223, 117242. [Google Scholar] [CrossRef]
- Chlingaryan, A.; Sukkarieh, S.; Whelan, B. Machine learning approaches for crop yield prediction and nitrogen status estimation in precision agriculture: A review. Comput. Electron. Agric. 2018, 151, 61–69. [Google Scholar] [CrossRef]
- Zhang, Z.; Jin, Y.; Chen, B.; Brown, P. California almond yield prediction at the orchard level with a machine learning approach. Front. Plant Sci. 2018, 10, 809. [Google Scholar] [CrossRef] [PubMed]
- Kang, H.W.; Kang, H.B. Prediction of crime occurrence from multi-modal data using deep learning. PLoS ONE 2017, 12, e0176244. [Google Scholar] [CrossRef] [PubMed]
- Borchani, H.; Varando, G.; Bielza, C.; Larranaga, P. A survey on multi-output regression. Wiley Interdiscip. Rev. Data Min. Knowl. Discov. 2015, 5, 216–233. [Google Scholar] [CrossRef]
- Moot, D.J.; Scott, W.R.; Roy, A.M.; Nicholls, A.C. Base temperature and thermal time requirements for germination and emergence of temperate pasture species. N. Z. J. Agric. Res. 2000, 43, 15–25. [Google Scholar] [CrossRef]
- Parrish, D.J.; Fike, J.H. The biology and agronomy of switchgrass for biofuels. BPTS 2005, 24, 423–459. [Google Scholar] [CrossRef]
- Lee, D.K.; Boe, A. Biomass production of switchgrass in central South Dakota. Crop Sci. 2005, 45, 2583–2590. [Google Scholar] [CrossRef]
- Reynolds, J.H.; Walker, C.L.; Kirchner, M.J. Nitrogen removal in switchgrass biomass under two harvest systems. Biomass Bioenergy 2000, 19, 281–286. [Google Scholar] [CrossRef]
- Tian, S.; Fischer, M.; Chescheir, G.M.; Youssef, M.A.; Cacho, J.F.; King, J.S. Microtopography-induced transient waterlogging affects switchgrass (Alamo) growth in the lower coastal plain of North Carolina, USA. GCB Bioenergy 2018, 10, 577–591. [Google Scholar] [CrossRef]
- Water and Atmospheric Resources Monitoring Program: Illinois Climate Network; Illinois State Water Survey: Champaign, IL, USA, 2022. [CrossRef]
- Iowa Environmental Mesonet: Iowa State University. Available online: https://mesonet.agron.iastate.edu/agclimate/hist/daily.php (accessed on 15 January 2023).



| Madrid, Iowa | Brighton, Illinois | Urbana, Illinois | |
|---|---|---|---|
| Field Location | 41°55′52.17″ N, 93°45′49.28″ W | 39°3′23.23″ N, 90°11′7.62″ W | 40°4′7.68″ N, 88°11′26.78″ W |
| Field Size (Plot Size) | 8.5 ha (0.4 ha) | 8.5 ha (0.4 ha) | 6.1 ha (0.2 ha) |
| Cropping History | Corn/Soybean Rotation | Corn/Soybean Rotation | Perennial Grass Plots/Soybean/Corn |
| Switchgrass Cultivars |
|
|
|
| Planting Date | 13 June 2019 | 28 May 2019 | 30 May 2020–1 June 2020 |
| Harvest Dates (2020–2022) | 20 November 2020 8 November 2021 2 December 2022 | 9 December 2020 17 November 2021 17 November 2022 | 7 December 2020 2 December 2021 14 November 2022 |
| Field | Year | Sentinel-2 Imagery Date | Harvest Date | Index Used |
|---|---|---|---|---|
| Iowa | 2020 | 25 June 2020 | 20 November 2020 | GNDVI * |
| 2021 | 5 July 2021 | 8 November 2021 | GNDVI | |
| 2022 | 4 August 2022 | 2 December 2022 | GNDVI | |
| Illinois–Brighton | 2020 | 17 June 2020 | 9 December 2020 | GNDVI |
| 2021 | 26 August 2021 | 17 November 2021 | GARI ꭞ | |
| 2022 | 15 October 2022 | 17 November 2022 | ARVI ᶲ | |
| Illinois–Urbana | 2020 | 7 October 2020 | 7 December 2020 | GNDVI |
| 2021 | 4 July 2021 | 2 December 2021 | GNDVI | |
| 2022 | 29 June 2022 | 14 November 2022 | GNDVI |
| Cultivar | Total Number of Samples |
|---|---|
| Independence | 2104 |
| Liberty | 2037 |
| Shawnee | 1705 |
| Performance | ||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Features | Engineered | Full | ||||||||||||
| Algorithm | ABR | GBM | KNR | ANN | OLS | RF | ABR | GBM | KNR | ANN | OLS | RF | PLS | |
| Cultivar | Metric | |||||||||||||
| Independence | MAE | 1.19 | 0.66 | 1.3 | 0.84 | 1.43 | 0.63 | 1.15 | 0.66 | 1.17 | 0.83 | 1.21 | 0.62 | 1.21 |
| R2 | 0.62 | 0.85 | 0.54 | 0.76 | 0.43 | 0.85 | 0.64 | 0.85 | 0.61 | 0.77 | 0.57 | 0.86 | 0.57 | |
| Liberty | MAE | 1.14 | 0.59 | 1.65 | 0.84 | 1.97 | 0.58 | 1.06 | 0.57 | 1.38 | 0.76 | 1.48 | 0.57 | 1.48 |
| R2 | 0.68 | 0.88 | 0.47 | 0.8 | 0.28 | 0.88 | 0.72 | 0.88 | 0.58 | 0.83 | 0.52 | 0.88 | 0.52 | |
| Shawnee | MAE | 1.11 | 0.7 | 1.4 | 0.91 | 1.55 | 0.7 | 1.06 | 0.66 | 1.24 | 0.83 | 0.98 | 0.67 | 0.98 |
| R2 | 0.53 | 0.75 | 0.36 | 0.62 | 0.23 | 0.74 | 0.55 | 0.78 | 0.45 | 0.68 | 0.57 | 0.76 | 0.57 | |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Cacho, J.F.; Feinstein, J.; Zumpf, C.R.; Hamada, Y.; Lee, D.J.; Namoi, N.L.; Lee, D.; Boersma, N.N.; Heaton, E.A.; Quinn, J.J.; et al. Predicting Biomass Yields of Advanced Switchgrass Cultivars for Bioenergy and Ecosystem Services Using Machine Learning. Energies 2023, 16, 4168. https://doi.org/10.3390/en16104168
Cacho JF, Feinstein J, Zumpf CR, Hamada Y, Lee DJ, Namoi NL, Lee D, Boersma NN, Heaton EA, Quinn JJ, et al. Predicting Biomass Yields of Advanced Switchgrass Cultivars for Bioenergy and Ecosystem Services Using Machine Learning. Energies. 2023; 16(10):4168. https://doi.org/10.3390/en16104168
Chicago/Turabian StyleCacho, Jules F., Jeremy Feinstein, Colleen R. Zumpf, Yuki Hamada, Daniel J. Lee, Nictor L. Namoi, DoKyoung Lee, Nicholas N. Boersma, Emily A. Heaton, John J. Quinn, and et al. 2023. "Predicting Biomass Yields of Advanced Switchgrass Cultivars for Bioenergy and Ecosystem Services Using Machine Learning" Energies 16, no. 10: 4168. https://doi.org/10.3390/en16104168
APA StyleCacho, J. F., Feinstein, J., Zumpf, C. R., Hamada, Y., Lee, D. J., Namoi, N. L., Lee, D., Boersma, N. N., Heaton, E. A., Quinn, J. J., & Negri, C. (2023). Predicting Biomass Yields of Advanced Switchgrass Cultivars for Bioenergy and Ecosystem Services Using Machine Learning. Energies, 16(10), 4168. https://doi.org/10.3390/en16104168